以前にもSpark関連の練習ドキュメントを書いていたのですが、アップしていなかったので、今日はSparkパートの関連練習内容とマインドマップを更新します。この記事には、 RDDと広範な依存関係と狭い依存関係の作成のみが含まれます。
演習 1: RDD の作成
タスク 1: 配列とリストを使用して作成する
// 1. 通过列表创建RDD
val list = sc.parallelize(List("ab","cd","ef"))
// 2. 通过数组创建RDD
val array = sc.parallelize(Array(1,2,3))
タスク 2: ファイルから作成する
// 从windows本地加载数据,此时操作并未真正执行
val lines = sc.textFile("file:///F:/04Spark/dataset/hello.txt")
演習 2: 一般的に使用される RDD 変換演算子メソッド
タスク 1: 狭く依存する操作 (マップ、フィルター、フラットマップなど)
mapメソッド
マップは非常に分かりやすく、呼び出しメソッドにソースJavaRDDの要素を渡し、それをアルゴリズム後に一つずつ返して新しいJavaRDDを生成するというものです。
// 1. 创建原始RDD
val x = sc.parallelize(Array(1,2,3))
// 2. 对RDD的每个元素做操作 ----- 方式1
val mapRDD1 = x.map(ele => ele * 10)
// 2. 方式2
val mapRDD2 = x.map(_*10)
// 3. 查看x 与mapRDD
x.collect().mkString(",")
mapRDD1.collect().mkString(",")
mapRDD2.collect().mkString(",")
// 1. 创建原始RDD
val strRDD = sc.parallelize(Array("ab","cd","ef"))
// 2. 对每个元素增加一个属性
val tupleRDD = strRDD.map(ele => (ele,1))
// 3. 查看strRDD 与tupleRDD
strRDD.collect().mkString(",")
tupleRDD.collect().mkString(",")
filter方法
val intRDD = sc.parallelize(Array(1,2,3))
val filterRDD = intRDD.filter(ele => ele%2==0)
filterRDD.collect().mkString(",")
flatMapflatMapメソッドは
、RDD内の要素を一つずつcallメソッドに渡すmapと同じで、callメソッドに渡した要素の後に任意の数の要素を追加できる点でmapより多くの機能を持っています。これは、パラメータが順番に渡されるため、正確に達成できます。
val flatMapRDD = intRDD.flatMap(ele => Array(ele,ele*100,42))
intRDD.collect().mkString(",")
flatMap の特性により、この演算子は、リークをチェックしたり、ソース RDD の空きを埋める場合など、いつでも要素を追加する必要がある場合に非常に便利です。
タスク 2: 広く依存する操作 (groupby、distinct、coalesce など)
groupby方法
// 1. 创建原始RDD
val namesRDD = sc.parallelize(Array("Jack","Alice","Card","Jackson"))
// 2. 按照首字母来进行分组
val groupRDD = namesRDD.groupBy(ele => ele.charAt(0))
groupRDD.collect().mkString(",")
distinct方法
val x = sc.parallelize(Array(1,2,3,3,4))
// 去掉重复元素
val y = x.distinct()
x.collect().mkString(",")
y.collect().mkString(",")
coalesce
coalesceメソッドはデフォルトではシャッフルをトリガーしませんが、repartitionメソッドは確実に shuffle をトリガーし、すべて再パーティション化できます。
// 将数据划分为3个分区
val x = sc.parallelize(Array(1,2,3,4,5),3)
// 调用coalesce方法,重新进行分区,减小分区数量使之变为2个分区
val y = x.coalesce(2)
x.glom().collect()
y.glom().collect()
reduceByKeyとgroupByKey
-
reduceByKey()マージ操作は各キーに対応する複数の値に対して実行されます。最も重要なことは、最初にマージ操作をローカルで実行できることです。ローカル データは最初にマージされ、次にマージのためにさまざまなノードに送信され、最終的に最終結果が得られます。マージをローカルで実行する利点は、マップ側でリデュースが実行された後、データ量が大幅に削減されるため、送信が削減され、リデュース側で結果をより速く計算できるようになることです。
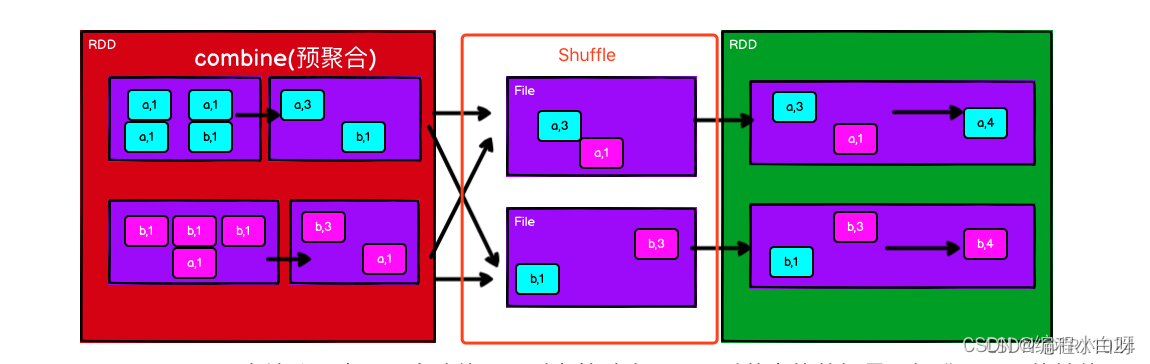
-
groupByKey()また、各キーに対応する複数の値を操作しますが、集計してシーケンスを生成するだけで、関数自体をカスタマイズすることはできません。最初はローカルマージを行わず、すべてのデータを送信し、すべてのデータを取得した後にすべてのデータをシーケンスに集約するため、必然的にすべてのデータがネットワーク経由で送信され、無駄が発生します。同時に、データ量が非常に大きい場合、OutOfMemoryError が発生する可能性もあります。したがって、オーバーヘッドは比較的大きくなります。
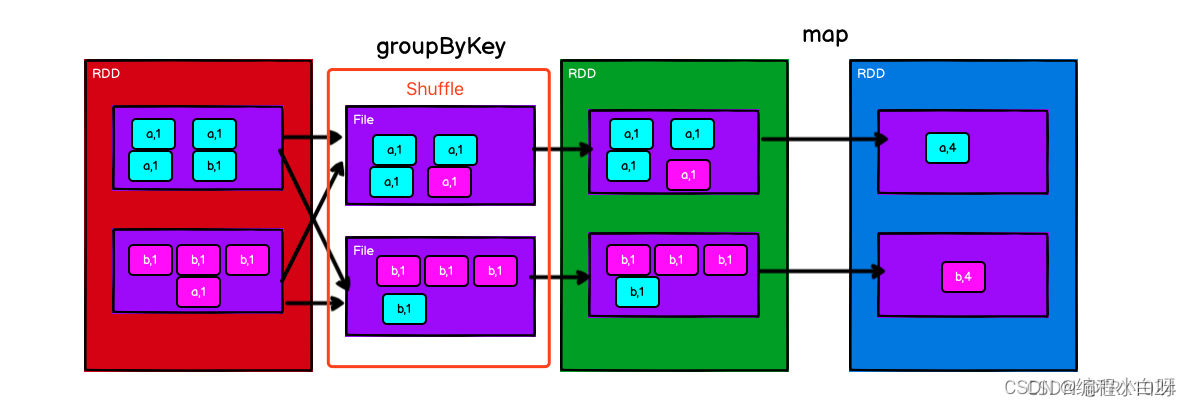
-
(キー, 値) の形式のデータの場合、._1、._2 を通じてキーと値にアクセスでき、プレースホルダーは _.1、._ 2です。2 つのアンダースコアの意味は異なります。プレースホルダーの後にアクセスが続きます。
val words = Array("one", "two", "two", "three", "three", "three")
// 1. 进行map,增加一个属性
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val wordCountsWithReduce = wordPairsRDD.reduceByKey(_ + _)
// 2. groupByKey()后调用map遍历每个分组,然后通过t => (t._1,t._2.sum)对每个分组的值进行累加。
//因为groupByKey()操作是把具有相同类型的key收集到一起聚合成一个集合,集合中有个sum方法,对所有元素进行求和。
val wordCountsWithGroup = wordPairsRDD.groupByKey().map(t => (t._1, t._2.sum))
補充する
1. アクション演算子
foreachPartition
foreachPartition メソッドは、メソッドにイテレータを渡す方法です (関数はパーティションごとに 1 回実行され、イテレータを取得した後、自分で反復処理を行う必要があります)。
// 1. 分区 2个分区
val rdd = sc.parallelize(1 to 6,2)
rdd.foreachPartition(x =>{
println("data")
println(x)
while(x.hasNext){
println(x.next())}
})
count、mean、min、max
val rdd1 = sc.parallelize(List('A','B','c'))
// 1. 统计计数
rdd1.count()
// 2. 求平均值
val rdd = sc.parallelize(List(1,2,3,4))
rdd.mean()
// 3. 求最大值
rdd.max()
// 4. 求最小值
rdd.min()
reduce
val rdd = sc.parallelize(List(1,2,3,4))
// 求和,将各个数累加
rdd.reduce(_+_)
変換演算子
union 、intersection、cartesian、subtract
// 1.创建2个RDD
val rdd1=sc.parallelize(List('A','B'))
val rdd2=sc.parallelize(List('B','C'))
// 2. 取并集
rdd1.union(rdd2).collect().mkString(",")
// 3. 取交集
rdd1.intersection(rdd2).collect().mkString(",")
// 4. 笛卡尔积
rdd1.cartesian(rdd2).collect().mkString(",")
//5. 相减
rdd1.subtract(rdd2).collect().mkString(",")
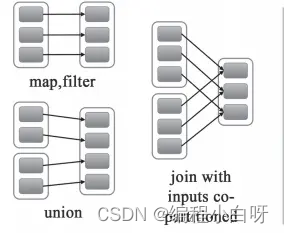
概要 - 幅広い依存関係と狭い依存関係
-
広い依存関係は直列、狭い依存関係は並列です
-
幅広い依存関係: 親 RDD のパーティションは、子 RDD の複数のパーティションによって使用されます。たとえば、groupByKey、reduceByKey、sortByKey などの操作では、幅広い依存関係とシャッフルが生成されます。
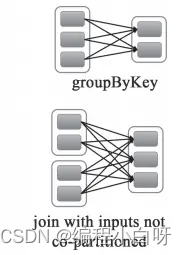
-
狭い依存関係: 親 RDD の各パーティションは、子 RDD の 1 つのパーティションによってのみ使用されます。マップ、フィルター、ユニオンなどの操作により狭い依存関係が生成されます。