テキストの手がかりに基づいてリアルな画像を生成する拡散モデルの機能は、生成人工知能の普及に貢献しました。データ合成やコンテンツ作成など、いくつかのアプリケーション ドメインでこれらのモデルが使用され始めています。Hugging Face Hub には、5,000 を超える事前トレーニング済みのヴィンセン グラフ モデルが含まれています。これらのモデルをディフューザー ライブラリと組み合わせると、画像生成ワークフローの構築やさまざまな画像生成ワークフローの実験が驚くほど簡単になります。
トランスフォーマー モデルと同様に、拡散モデルを微調整して、特定のビジネス ニーズに適したコンテンツを生成することができます。最初は GPU で微調整することしかできませんでしたが、状況は変わりつつあります。数カ月前、Intel はコード名 Sapphire Rapids という第 4 世代 Xeon CPU を発売しました。Sapphire Rapids には、ディープ ラーニング ワークロード用の新しいハードウェア アクセラレータである Intel の Advanced Matrix eXtension (AMX) が含まれています。これまでのいくつかのブログ投稿で、 NLP 変換モデルの微調整、NLP 変換モデルの推論、安定拡散モデルの推論など、 AMX の利点を示しました。
この記事では、Intel 第 4 世代 Xeon CPU クラスターで安定拡散モデルを微調整する方法を説明します。微調整に使用するのは Textual Inversion 手法です。これは、モデルを効果的に微調整するために少数のトレーニング サンプルのみを必要とします。この記事ではサンプルが5つあれば大丈夫!
始めましょう。
クラスターを構成する
Intel の小規模パートナーは、Intel Developer Cloud (Intel Developer Cloud、IDC) 上でホストされる 4 台のサーバーを提供してくれました。IDC は、クラウド サービス プラットフォームとして、インテルによって徹底的に最適化され、最新のインテル プロセッサーと最適なパフォーマンスのソフトウェア スタックを統合した展開環境を提供し、ユーザーはこの環境上でワークロードを簡単に開発および実行できます。
私たちが入手した各サーバーには、それぞれ 56 個の物理コアと 112 個のスレッドを備えた Intel 第 4 世代 Xeon CPU が 2 個搭載されていました。そのlscpu出力は次のとおりです。
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 52 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 224
On-line CPU(s) list: 0-223
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) Platinum 8480+
CPU family: 6
Model: 143
Thread(s) per core: 2
Core(s) per socket: 56
Socket(s): 2
Stepping: 8
CPU max MHz: 3800.0000
CPU min MHz: 800.0000
BogoMIPS: 4000.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_per fmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cat_l2 cdp_l3 invpcid_single intel_ppin cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local split_lock_detect avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg tme avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b enqcmd fsrm md_clear serialize tsxldtrk pconfig arch_lbr amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities4 つのサーバーの IP アドレスをnodefileファイルに書き込みます。最初の行はメイン サーバーです。
cat << EOF > nodefile
192.168.20.2
192.168.21.2
192.168.22.2
192.168.23.2
EOF分散トレーニングでは、sshマスター ノードと他のノード間のパスワードなしの通信が必要です。これにあまり慣れていない場合は、この記事を参照し、手順に従ってパスワードなしを設定できますssh。
次に、動作環境を設定し、各ノードに必要なソフトウェアをインストールします。特に、分散通信を管理するための oneCCL と、Sapphire Rapids のハードウェア アクセラレーションを最大限に活用するためのソフトウェア最適化を含む Intel Extension for PyTorch (IPEX) の 2 つの Intel に最適化されたライブラリをインストールしました。またlibtcmalloc、高性能メモリ割り当てライブラリである とそのソフトウェア依存関係もインストールしましたgperftools。
conda create -n diffuser python==3.9
conda activate diffuser
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
pip3 install transformers accelerate==0.19.0
pip3 install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable-cpu
pip3 install intel_extension_for_pytorch
conda install gperftools -c conda-forge -y次に、各ノードでディフューザー リポジトリのクローンを作成し、ソースからインストールします。
git clone https://github.com/huggingface/diffusers.git
cd diffusers
pip install .次に、IPEX を使用して、推論モデルに対するdiffusers/examples/textual_inversionIPEX の最適化を組み込むために、微調整スクリプトでいくつかの最適化を行う必要があります。diffusersそのサブモデルの推論の最適化は、ライブラリでは実行できず、スクリプト コードでのみ実行できます。また、Clip-Text モデルの微調整は) によって行うことができます。IPEX をインポートし、U-Net および変分オートエンコーダー (VAE) モデルでの推論用に最適化します。最後に、この変更はすべてのノードのコードで行う必要があることを忘れないでください。pipelinepipelineaccelerateaccelerate
diff --git a/examples/textual_inversion/textual_inversion.py b/examples/textual_inversion/textual_inversion.py
index 4a193abc..91c2edd1 100644
--- a/examples/textual_inversion/textual_inversion.py
+++ b/examples/textual_inversion/textual_inversion.py
@@ -765,6 +765,10 @@ def main():
unet.to(accelerator.device, dtype=weight_dtype)
vae.to(accelerator.device, dtype=weight_dtype)
+ import intel_extension_for_pytorch as ipex
+ unet = ipex.optimize(unet, dtype=weight_dtype)
+ vae = ipex.optimize(vae, dtype=weight_dtype)
+
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:最後のステップは、トレーニング イメージをダウンロードすることです。通常は共有 NFS フォルダーを使用しますが、ここでは簡単にするために各ノードにイメージをダウンロードすることを選択します。トレーニング イメージのディレクトリにすべてのノードで同じパス () があることを確認してください/home/devcloud/dicoo。
mkdir /home/devcloud/dicoo
cd /home/devcloud/dicoo
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/0.jpeg
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/1.jpeg
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/2.jpeg
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/3.jpeg
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/4.jpeg使用するトレーニング画像を以下に示します。





この時点で、システム構成は完了です。次に、トレーニング タスクの構成を開始します。
微調整環境の構成
加速ライブラリを使用すると、分散トレーニングが容易になります。各ノードで実行し、いくつかの簡単な質問に答える必要がありますacclerate config。
以下はマスター ノードのスクリーンショットです。他のノードでは、rank1、2、および 3 に設定する必要があり、他の回答は同じままにしておきます。
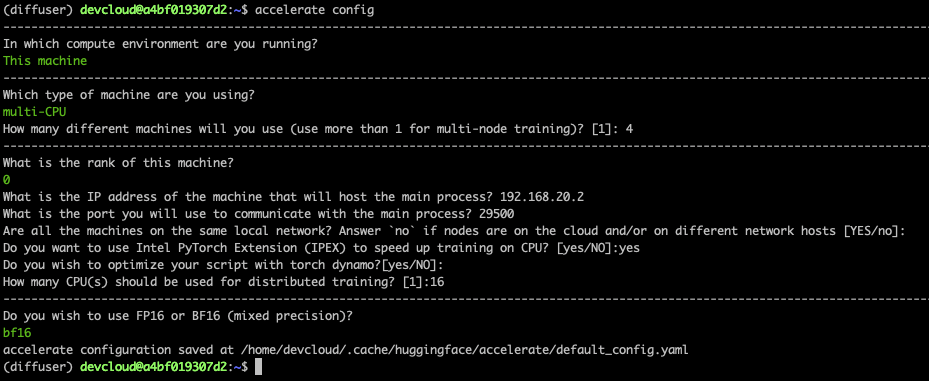
最後に、マスター ノードでいくつかの環境変数を設定する必要があります。これらの環境変数は、微調整タスクの開始時に他のノードに伝播されます。最初の行は、すべてのノードが実行されるローカル ネットワークに接続されているネットワーク インターフェイスの名前を設定します。ifconfig必要に応じて、ネットワーク インターフェイス名を適切に設定するために使用する必要があります。
export I_MPI_HYDRA_IFACE=ens786f1
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libiomp5.so
export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libtcmalloc.so
export CCL_ATL_TRANSPORT=ofi
export CCL_WORKER_COUNT=1
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATA_DIR="/home/devcloud/dicoo"さて、微調整を始めましょう。
モデルの微調整
mpirunで微調整を開始します。これにより、 にリストされているノード間の分散通信が自動的に設定nodefileされます。ここでは、-n各ノード ( ) で 4 つのプロセスが実行され、16 のプロセス ( ) を実行します-ppn。Accelerateライブラリは、すべてのプロセスにわたる分散トレーニングを自動的にセットアップします。
以下のコマンドを開始して 200 ステップをトレーニングします。所要時間はわずか 5 分です。
mpirun -f nodefile -n 16 -ppn 4 \
accelerate launch diffusers/examples/textual_inversion/textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME --train_data_dir=$DATA_DIR \
--learnable_property="object" --placeholder_token="<dicoo>" --initializer_token="toy" \
--resolution=512 --train_batch_size=1 --seed=7 --gradient_accumulation_steps=1 \
--max_train_steps=200 --learning_rate=2.0e-03 --scale_lr --lr_scheduler="constant" \
--lr_warmup_steps=0 --output_dir=./textual_inversion_output --mixed_precision bf16 \
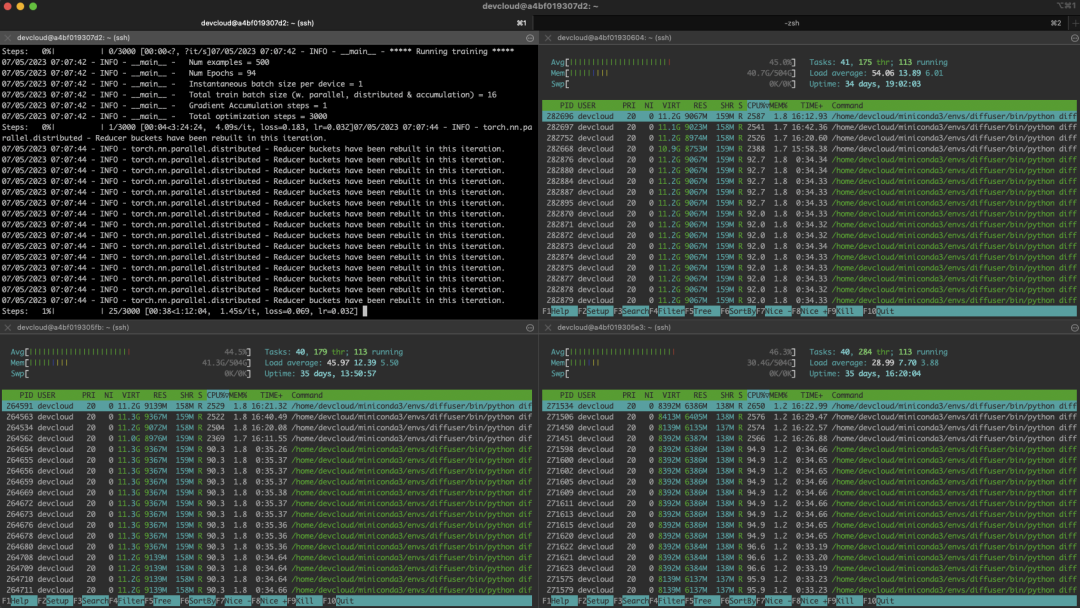
--save_as_full_pipeline以下のスクリーンショットは、トレーニング中のクラスターの状態を示しています。
トラブルシューティング
分散トレーニングは、特に初心者の場合、難しい場合があります。依存関係の欠落、イメージの別の場所への保存など、単一ノード上の小さな構成ミスが最も可能性の高い問題です。
各ノードにログインしてローカルでトレーニングし、問題をすばやく特定できます。まず、マスター ノードと同じ環境をセットアップし、次を実行します。
python diffusers/examples/textual_inversion/textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME --train_data_dir=$DATA_DIR \
--learnable_property="object" --placeholder_token="<dicoo>" --initializer_token="toy" \
--resolution=512 --train_batch_size=1 --seed=7 --gradient_accumulation_steps=1 \
--max_train_steps=200 --learning_rate=2.0e-03 --scale_lr --lr_scheduler="constant" \
--lr_warmup_steps=0 --output_dir=./textual_inversion_output --mixed_precision bf16 \
--save_as_full_pipelineトレーニングが正常に開始された場合は、トレーニングを停止し、次のノードに進みます。すべてのノードでトレーニングが正常に開始されたら、メインノードに戻り、nodefile環境やmpirunコマンドに問題がないかをよく確認してください。心配しないでください、問題は最終的に見つかります:)。
微調整されたモデルを使用して画像を生成する
5 分間のトレーニング後、トレーニングされたモデルはローカルに保存され、 を直接使用してモデルをdiffusersロードし、画像を生成できます。pipelineただし、ここでは、Optimum Intel と OpenVINO を使用して、推論用モデルをさらに最適化します。前の記事で説明したように、単一の CPU で 5 秒未満でイメージを生成できるように最適化されています。
pip install optimum[openvino]次のコードを使用してモデルを読み込み、固定出力形状に合わせて最適化し、最後に最適化されたモデルを保存します。
from optimum.intel.openvino import OVStableDiffusionPipeline
model_id = "./textual_inversion_output"
ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
ov_pipe.reshape(batch_size=5, height=512, width=512, num_images_per_prompt=1)
ov_pipe.save_pretrained("./textual_inversion_output_ov")次に、最適化されたモデルをロードし、5 つの異なる画像を生成して保存します。
from optimum.intel.openvino import OVStableDiffusionPipeline
model_id = "./textual_inversion_output_ov"
ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, num_inference_steps=20)
prompt = ["a yellow <dicoo> robot at the beach, high quality"]*5
images = ov_pipe(prompt).images
print(images)
for idx,img in enumerate(images):
img.save(f"image{idx}.png")以下はそれが生成する画像です。驚くべきことに、モデルがdicooメガネをかけていることを知るのに必要な画像は 5 枚だけでした。

より良い結果を得るためにモデルをさらに微調整することもできます。以下は、3k ステップ (約 1 時間) に微調整されたモデルによって生成された画像です。これは非常にうまく機能します。

要約する
Hugging Face とインテルの緊密な協力のおかげで、Xeon CPU サーバーを使用してビジネス ニーズを満たす高品質の画像を生成できるようになりました。一般に CPU は GPU などの特殊なハードウェアよりも安価で容易に入手できますが、Xeon CPU は Web サーバーやデータベースなどの他の生産的なタスクにも簡単に使用できる汎用性の高い CPU でもあります。そのため、フル機能を備えた柔軟な IT インフラストラクチャには、CPU が論理的な選択肢となります。
次のリソースを利用して開始し、必要に応じて使用できます。
ディフューザーのドキュメント
最適なインテルのドキュメント
GitHub 上のインテル IPEX
Intel と Hugging Face の開発者リソース
IDC、AWS、GCP、Alibaba Cloud 上の第 4 世代 Xeon CPU インスタンス
ご質問やフィードバックがございましたら、Hugging Face フォーラムにお気軽にメッセージを残してください。
読んでくれてありがとう!
英文原文: https://hf.co/blog/stable-diffusion-finetuning-intel
著者: ジュリアン・サイモン
翻訳者: Intel ディープラーニング エンジニアである Matrix Yao (Yao Weifeng) は、さまざまなモーダル データに対するトランスフォーマー ファミリ モデルの適用と、大規模モデルのトレーニングと推論に取り組んでいます。
校正・組版:中東儀(阿东)