
「
7 月 31 日、Llama 中国語コミュニティが主導権を握り、初の Llama2-13B 大型モデルの本格的な中国語バージョンをさせました。これにより、モデルの根本から Llama2 の中国語機能が大幅に最適化され、改善されました。 Llama2の中国版がリリースされ、国産大型モデルの新時代を切り開く!
|世界最強だけど中国語が足りない
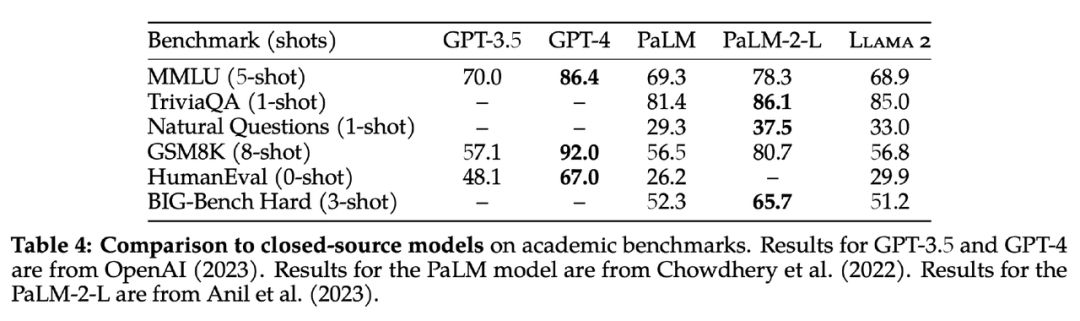
Llama2 は現在、世界で最も強力なオープンソースの大型モデルですが、中国語能力を 改善する必要があります 。Meta は期待に応えました。7 月 19 日の早朝、LLaMA の第 1 世代のアップグレード バージョンがオープンしました。出典: Llama2、7B、13B、70B の 3 サイズのモデル完全にオープンで商用利用は無料。 AI 分野で最も強力なオープンソースの大規模モデルとして、Llama2 は 2 兆のトークン データで事前トレーニングされ、人間がラベル付けした 100 万のデータで微調整されて対話モデルを取得します。推論、プログラミング、対話、知識テストを含む多くのベンチマーク テストでは、MPT、Falcon、LLaMA の第 1 世代などのオープンソースの大規模言語モデルよりも大幅に優れた結果が得られ、商用 GPT-3.5 にも匹敵します。オープンソースモデルの中でもユニーク。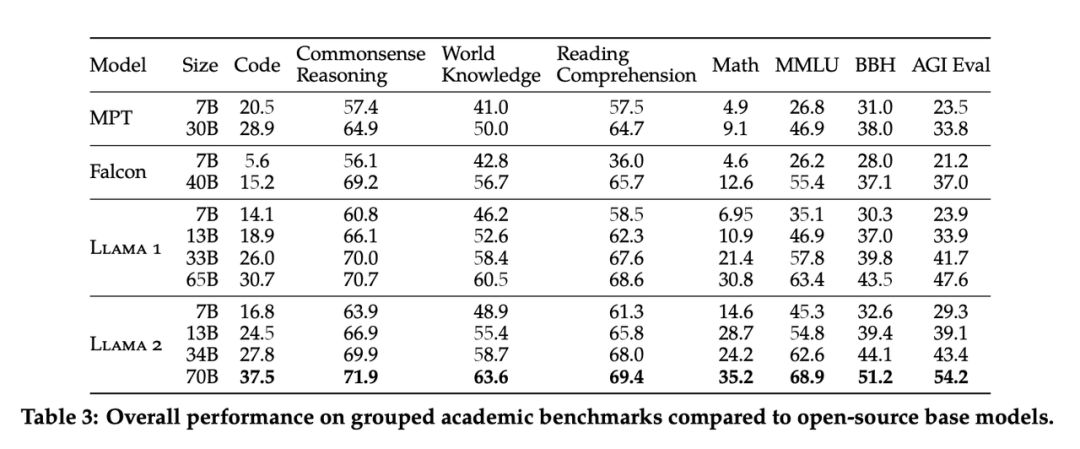
 Llama2 の事前学習データは初代と比べて 2 倍になりましたが、中国語の事前学習データの割合はまだ非常に小さく、わずか
0.13
%
であり、これがオリジナルの Llama2 の中国語能力の弱さにつながっています。
いくつか中国語の質問をしましたが、ほとんどの場合、Llama2 は中国語で答えることができなかったり、中国語と英語が混在した形式で質問に答えたりすることがわかりました。したがって、
Llama2 の中国語機能を向上させるために、大規模な中国語データに基づいて Llama2 を最適化する必要があります。
Llama2 の事前学習データは初代と比べて 2 倍になりましたが、中国語の事前学習データの割合はまだ非常に小さく、わずか
0.13
%
であり、これがオリジナルの Llama2 の中国語能力の弱さにつながっています。
いくつか中国語の質問をしましたが、ほとんどの場合、Llama2 は中国語で答えることができなかったり、中国語と英語が混在した形式で質問に答えたりすることがわかりました。したがって、
Llama2 の中国語機能を向上させるために、大規模な中国語データに基づいて Llama2 を最適化する必要があります。

このため、中国の一流大学の大規模モデル博士チームはLlama 中国語コミュニティを設立し、Llama2 中国語大規模モデルのトレーニングを開始しました。
|主要なラマ中国人コミュニティ
Llama 中国語コミュニティは、中国を 代表するオープンソースの大規模モデル中国語コミュニティ です。Github は2 週間以内に2.4,000 のスターに達しました。Llama は、清華大学、交通大学、浙江大学の博士チームによって率いられています。AI 分野で 60 人以上の上級エンジニアが集まっています。さまざまな業界の 2,000 人以上の優秀な人材。
https://github.com/FlagAlpha/Llama2-English
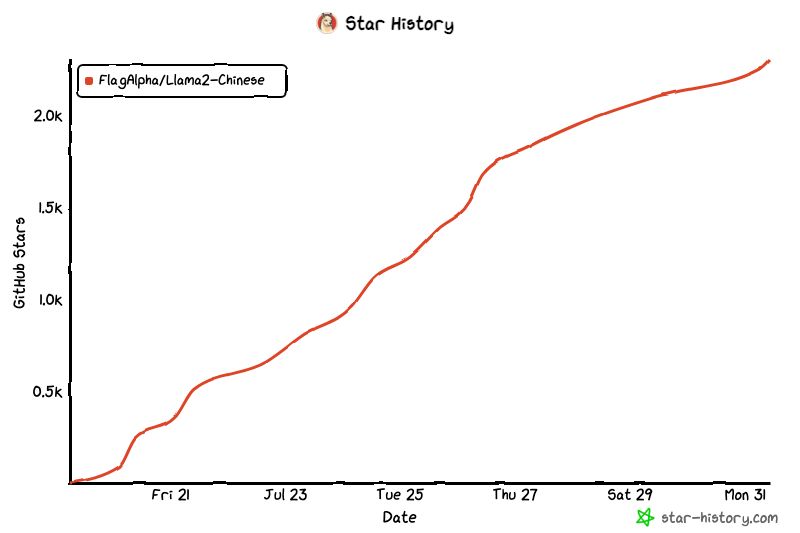
コミュニティの歴史:

| Llama2 モデルの最初の事前トレーニング済み中国語バージョンがリリースされました。
スピナーじゃないよ!200B の中国語コーパスの事前トレーニングに基づいています。
7 月 31 日、Llama 中国語コミュニティは、中国初の 13B Llama2 モデルの本格的な中国語バージョンである Llama2- Chinese-13B の完成を主導しました。これにより、Llama2 の中国語能力がモデルの根本から大幅に最適化され、改善されました。 Llama2 の中国語文化は、およそ 2 つのルートを採用できます。 1. 既存の中国語命令データ セットに基づいて、ベース モデルが中国語の質疑応答能力に合わせられるように、事前トレーニング モデルの命令を微調整します 。 このルートの利点は、コストが低く、命令微調整データの量が少なく、必要な計算能力リソースが少なく、中国のラマのプロトタイプを迅速に実現できることです。 しかし、欠点も明らかで、微調整は基本モデルの既存の中国語能力を刺激することしかできませんが、Llama2 自体の中国語トレーニング データが少ないため、刺激できる能力も限られており、事前トレーニングから始める必要があります。 2. 大規模な中国語コーパスに基づく事前トレーニング。このルートの欠点はコストが高いことです。大規模で高品質な中国データが必要であるだけでなく、大規模なコンピューティングリソースも必要です。しかし、利点も明らかです。つまり、モデルの最下層から中国語能力を最適化し、根本原因を解決する効果を真に達成し、強力な中国語能力をコアから大型モデルに注入できます。カーネルから徹底した中華大型モデルを実現するために、私たちは2番目の道を選択しました。私たちは高品質の中国語コーパス データセットをバッチ収集し、事前トレーニングから始めて Llama2 の大規模モデルを最適化しました。事前トレーニング データの一部は次のとおりです。 種類 説明 ネットワーク データ インターネット上のパブリック ネットワーク データ、百科事典、書籍、ブログ、ニュース、お知らせ、小説などの高品質な長文データを含む、厳選された高品質な中国語データ 200G データ ClueClue のオープン中国語事前学習データ、クリーニング後の高品質の中国語長文データ コンペティション データセット、近年の中国語自然言語処理マルチタスク コンペティション データセット、約 150 個の MNBVCMNBVC からクリーンアップされた一部のデータセット Llama2 の第 1 段階 - 中国語 13B モデルの事前トレーニング データ将来的には、Llama2-中国語の更新を繰り返して、事前トレーニング データを徐々に 1T トークンに増やしていきます。さらに、70Bモデルの中国事前訓練バージョンも徐々に公開していきますので、ご期待ください。 一般知識、言語理解、創造力、論理的推論、コードプログラミング、仕事スキルなど、さまざまな側面から大きなモデルに疑問を呈し、満足のいく結果を得ました。
いくつかの効果を以下に示します。
一般知識、言語理解、創造力、論理的推論、コードプログラミング、仕事スキルなど、さまざまな側面から大きなモデルに疑問を呈し、満足のいく結果を得ました。
いくつかの効果を以下に示します。
- 一般知識

- 言語理解

- 創造力

- 論理的推論
- コードプログラミング

- 作業能力
