この記事では、「大規模なクエリでメモリ不足にならないか」という観点から、MySQL クエリ結果をクライアントに送信するプロセスを紹介します。関連する知識ポイントには、MySQL サーバーのクエリ結果送信プロセス (読み取り中の送信)、MySQL スレッド状態の送信などが含まれます。クライアントとデータの送信、innoDB バッファプールへの大量のデータ クエリの影響、メモリ削除アルゴリズム LRU、および innoDB 改善された LRU。
質問: 大規模なクエリによってデータベース ホストのメモリが「使い果たされる」ことはありますか?
例: ホスト メモリは100Gしかありませんが、 200G の大きなテーブルでフル テーブル スキャンを実行したいのですが、データベース ホストのメモリは使い果たされてしまいますか?
——答えはノーです!たとえば、論理的にバックアップする場合、データベース全体をスキャンするだけではありませんか? したがって、大きなテーブルに対してフルテーブルスキャンを実行しても問題ないと思われますが、そのプロセスはどのようなものでしょうか?
一般的なアイデアはすでに存在しているかもしれません。つまり、複数のクエリがメモリにロードされて MySQL クライアントに送信されるバッチ処理のアイデアです。サーバー層がそれをどのように処理するかを見てみましょう。
MySQL Serverのクエリ結果の送信処理
次のようなコマンドを使用して、200G InnoDB テーブルでテーブル全体のスキャンを実行し、スキャン結果をクライアントに保存するとします。
mysql -h$host -P$port -u$user -p$pwd -e "select * from db1.t" > $target_fileInnoDB データは主キー インデックスに格納されるため、テーブル全体のスキャンは実際にはテーブル t の主キー インデックスを直接スキャンします。このクエリ ステートメントには他の判断条件がないため、見つかった各行は「結果セット」に直接配置できます。そしてクライアントに返された場合、この「結果セット」はどこに存在するのでしょうか?
——実際には、サーバーは完全な結果セットを保存する必要はありません。データのフェッチと送信のプロセスは次のとおりです。
1. ラインを取得して net_buffer に書き込みます。net_buffer がいっぱいになるまで繰り返しラインを取得し、ネットワーク インターフェイスを呼び出して送信します。2. 送信が成功した場合は、
net_buffer をクリアし、次のラインのフェッチと書き込みを続けます。 into net_buffer;
3. 送信の場合 関数が EAGAIN または WSAEWOULDBLOCK を返した場合は、ローカル ネットワーク スタック (ソケット送信バッファ) がいっぱいで、ネットワーク スタックが再び書き込み可能になるまで待機してから送信を続行することを意味します。
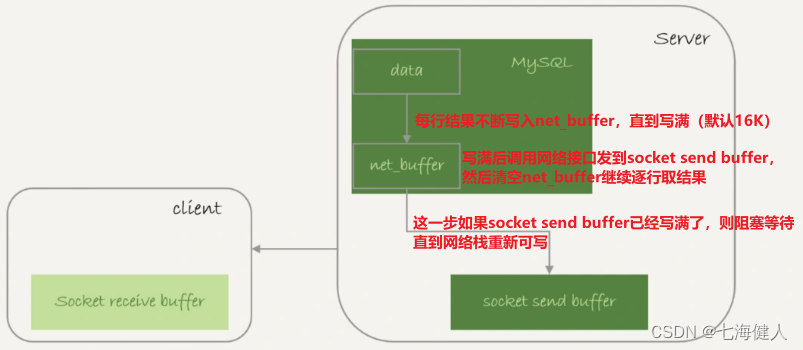
このプロセスから、次のことがわかります。
(1) MySQL クエリ結果はバッチで送信されます。バッチのサイズは net_buffer のサイズです (デフォルトは 16K)。すべての結果を一度にチェックするのではなく、すべてパッケージ化して一度に送信します。代わりに、それらはチェックされます。バッチで送信されます。
(2) ソケットの送信バッファがいっぱいかどうかも、MySQL の結果の戻りに影響します。これは、クライアントの受信が遅い場合、結果を送信できないためMySQL サーバーが送信ブロックに入り、結果として実行時間が長くなります。このトランザクションの時刻。
つまり、MySQL は「読みながらパブリッシュする」ということですが、この概念は非常に重要です。これは、クライアントの受信が遅い場合、MySQL サーバーは結果を送信できず、このトランザクションの実行時間が長くなるということを意味します。
MySQL スレッドのステータス クライアントへの送信&データの送信
クライアントに送信中
状況をシミュレートします。クライアントがソケット受信バッファ内のコンテンツを意図的に読み取らないようにし、サーバー上で processlist を表示して結果を表示します。

State の値が常に「クライアントに送信中」であることがわかります。これは、サーバー側のネットワーク スタックがいっぱいであることを意味します。より複雑なビジネス ロジックがあり、各行の後で処理されるロジックがあると仮定します。データの読み取りが非常に遅いため、クライアントが次のデータ行をフェッチするのに長い時間がかかり、上記の状況が発生する可能性があります。
したがって、通常のオンライン ビジネスでは、クエリが多くの結果を返さない場合は、mysql_store_result インターフェイス (MySQL クライアントで使用されるデフォルトのメソッドでもあります) を使用してクエリ結果をローカル メモリに直接保存することをお勧めします。クライアントが 20G 近くのメモリを占有するような大規模なクエリの実行など、型破りなビジネスのクエリ データの量が非常に多く、クライアントのローカル キャッシュを一度に保存できない場合、この場合、mysql_use_result インターフェイス代わりに使用する必要があります。
データの送信
「クライアントに送信中」とよく似た状態は「データ送信中」ですが、実際には、MyAQL クライアントがデータを受信することとはほとんど関係がありません。
実際、クエリ ステートメントの状態変化は次のようになります。
- MySQL クエリ ステートメントが実行フェーズに入ったら、まずステータスを「データ送信中」に設定します。
- そして、実行結果のカラム関連情報(メタデータ)をクライアントに送信します。
- ステートメントのフローの実行を続行します。
- 実行が完了したら、状態を空の文字列に設定します。
つまり、「データの送信」は必ずしも「データの送信」を意味するわけではなく、エグゼキュータ プロセスのどの段階でも構いません。たとえば、ロック待機シーンを構築したり、データ送信のステータスを確認したりできます。
つまり、 「クライアントに送信中」と表示されるのはスレッドが「クライアントの結果受信待ち」状態の場合のみで、「データ送信中」と表示されていれば「実行中」を意味します。
上記の分析から、サーバー層の場合、クエリ結果はバッチでクライアントに送信されることがわかります。したがって、テーブル全体をスキャンしてクエリから大量のデータを返しても、メモリが大量に消費されることはありません。
バッファプールによりクエリが高速化されます
メモリのデータ ページは BufferPool で管理されます。WAL では、BufferPool は更新を高速化する役割を果たします (ランダム ストレージではなく最初に redolog を書き込み、ディスク IO のランダムな書き込み圧力を軽減します)。実際、BufferPool にはより重要な役割があります。クエリを高速化するため。
WAL の後にデータを読み取る場合、ディスクを読み取る必要があるのか、それとも戻る前に redolog からデータを更新する必要があるのかという疑問があるかもしれません。実際には、これは必要ありません。この時点では、最新のデータはメモリ内にあり (メモリ内のデータがまだそこにある場合)、以前のデータはまだディスク上にあります。クエリは「ダーティ」データを直接返すことができます。ページ」はメモリ内にあります。
クエリに対するバッファ プールの高速化効果は、メモリ ヒット率という重要な指標に依存します。
show Engine innodb status の結果でシステムの現在の BP ヒット率を確認できます。一般に、サービスが安定しているオンライン システムの場合、応答時間が要件を満たしている場合、メモリ ヒット率は 99% を超えている必要があります。
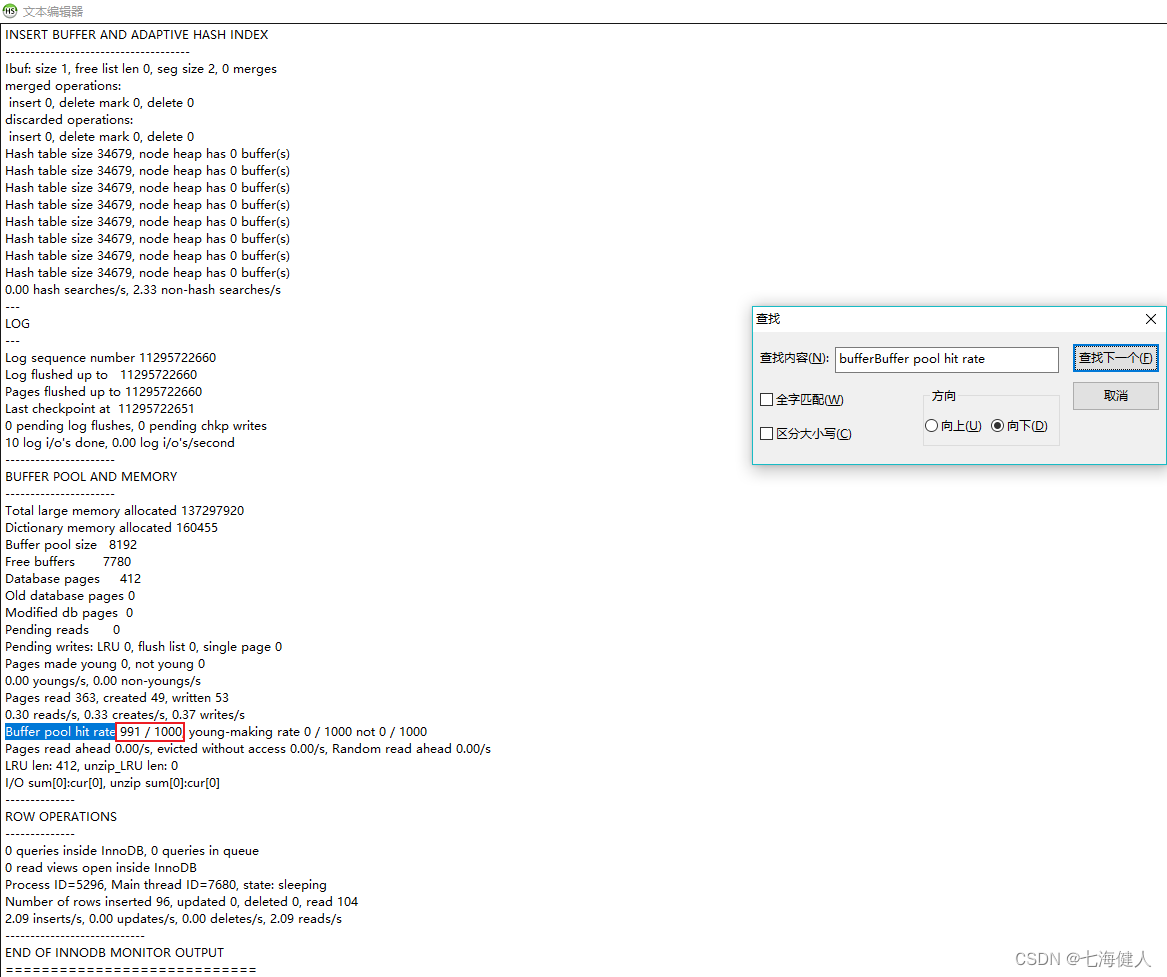
たとえば、図のヒット率は 99.1% です。
クエリで必要なすべてのデータ ページをメモリから直接取得できればそれが最良であり、対応するヒット率は 100% ですが、メモリ サイズは一般にメモリ サイズよりも小さいため、実際の運用環境でこれを達成することは困難です。合計データ サイズ はい。バッファ プールがいっぱいでデータ ページをディスクから読み取る必要がある場合は、古いデータ ページを削除する必要があります。
補足:REDOログと変更バッファ
REDO ログと変更バッファの 2 つの概念は確かに混同しやすいですが、ここで変更バッファのタイミングを追加します。変更バッファ メカニズムは常に適用されるわけではありません。操作対象のデータ ページが現在メモリにない場合にのみ適用されます。最初にディスクから読み取ってロードする必要があります。変更バッファはデータ ページにのみ役立ちます。その目的は、更新前にディスクからメモリにデータを読み取る必要を回避し、それによってランダム IO 読み取りの負荷を軽減することです。 ; データの読み取りが本当に必要な場合は、IO 読み取りがトリガーされ、メモリ内でマージが完了し、ダーティ ページが生成され、更新が REDO ログに記録されます (すぐにディスクをフラッシュする必要はないことに注意してください)スケジュールされたタスクはディスクのフラッシュを担当します); 詳細については、以前の記事「MySQL 実践実戦 45 講座」——学習ノート 09の最終セクション参照してください。 " ;
メモリ削除アルゴリズム LRU と innoDB の改良された LRU
InnoDB のメモリ管理では、最も長く使用されていないデータを削除することが最も重要なアルゴリズムです。
古典的な LRU アルゴリズム モデル
次の図は、従来の LRU アルゴリズムの基本モデルです。
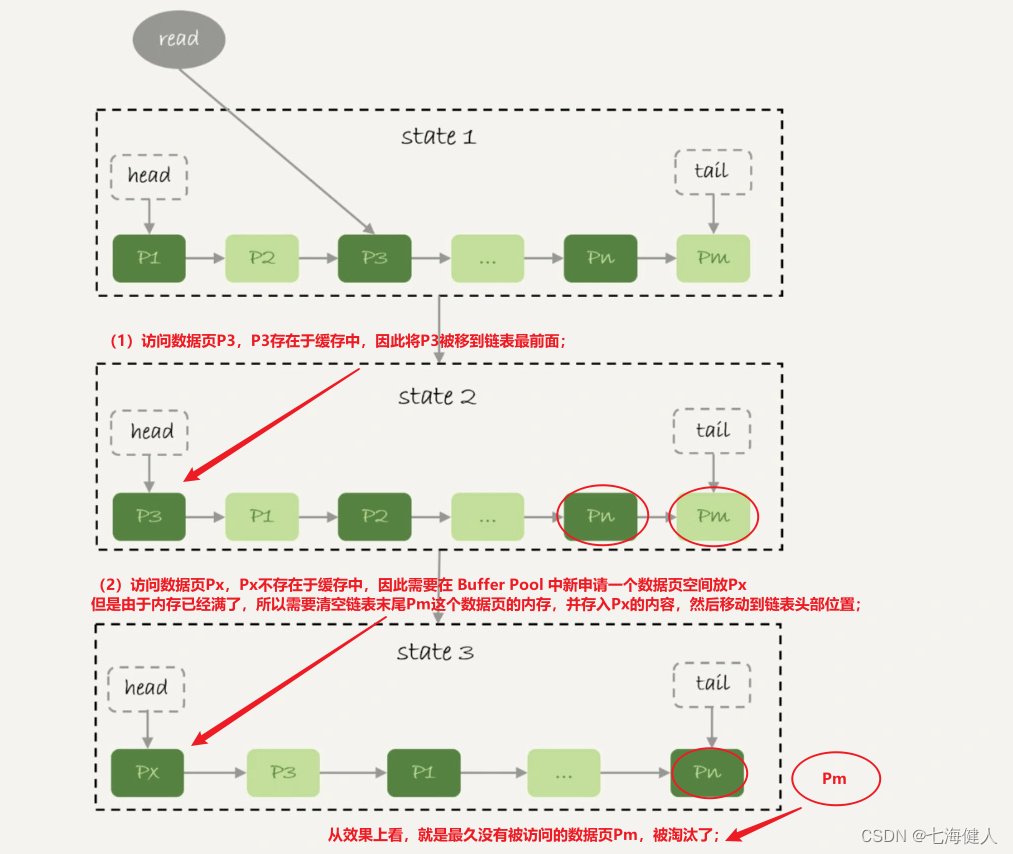
(1) アクセス データ ページ P3、P3 はキャッシュに存在するため、P3 はリンク リストの先頭に移動します
(2) アクセス データ ページ Px、Px はキャッシュに存在しないため、新しいデータ ページを作成する必要があります。 Pxのバッファプール空間に申請しましたが、メモリがいっぱいのため、リンクリストの最後尾のデータページPmのメモリをクリアし、Pxの内容を格納して先頭に移動する必要があります。リンクされたリスト。
効果の観点からは、最も長い間アクセスされていないデータページPmが削除される。
InnoDB によるフル テーブル スキャン時の LRU の改善
このアルゴリズムは一見すると問題ないように見えますが、テーブル全体のスキャンを考慮した場合、何か問題があるでしょうか? ——はい、メモリ内のデータは常に更新されており、全体的なメモリのヒット率は低くなります。
たとえば、このアルゴリズムに従って 200G テーブルをスキャンしたい場合、このアルゴリズムに従ってスキャンすると、現在の BufferPool 内のすべてのデータが削除され、スキャン プロセス中にアクセスされたデータ ページのコンテンツに保存されます。一度アクセスすると、メモリ領域が不足しているため、LRU によってすぐに削除されます。
これは、ビジネス サービスを実行するライブラリに大きな影響を及ぼします。BufferPool のメモリ ヒット率が急激に低下し、ディスクの負荷が増加し、SQL ステートメントの応答が遅くなることがわかります。
したがって、InnoDB はこの LRU アルゴリズムを直接使用できません。実際、InnoDB は LRU アルゴリズムを改良しました。
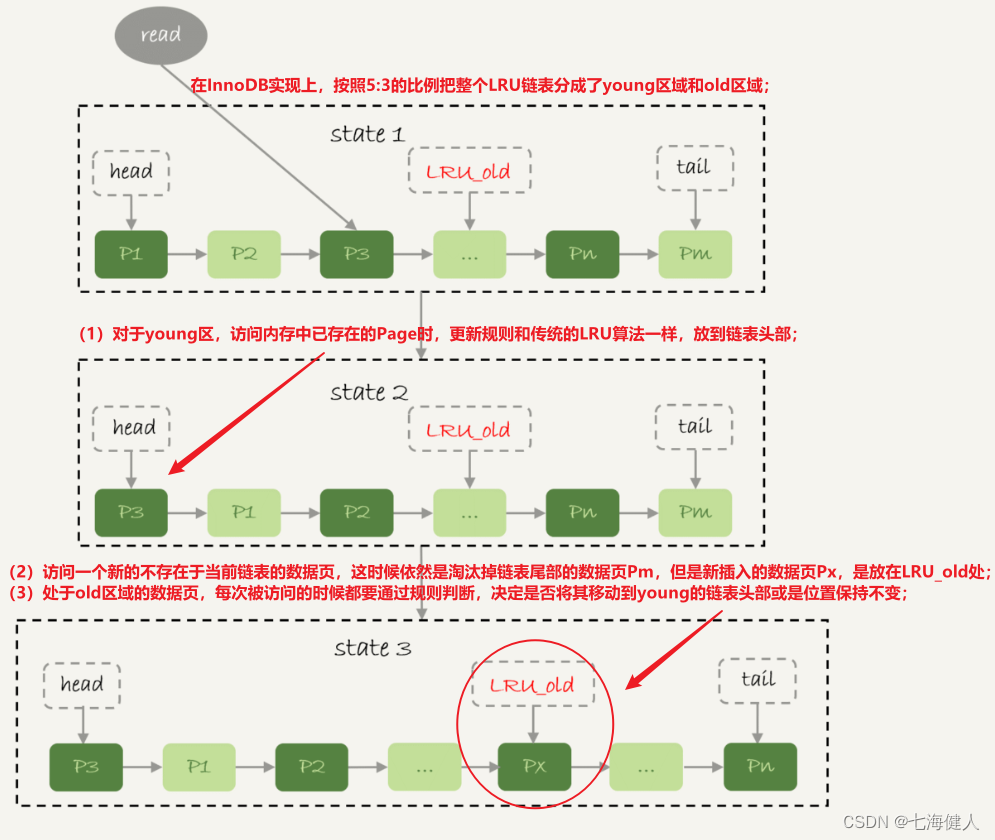
InnoDB の実装では、LRU リンク リスト全体が5:3 の比率に従って若い領域と古い領域に分割されます。
(1) ヤング領域の場合、メモリ内の既存のページにアクセスする場合、更新ルールは従来の LRU アルゴリズムと同じで、リンク リストの先頭に配置されます (2) 新しいデータ ページにアクセスする場合
、現在のリンクリストには存在せず、まだ存在しますリンクリストの最後尾のデータページPmを削除しますが、新たに挿入されたデータページPxはLRU_oldに配置されます; (3)古い領域のデータ
ページアクセスするたびに次の判断を行う必要があります。
a. データ ページが LRU リスト内に 1000ms を超えて存在する場合、データ ページをリストの先頭に移動します; b
. データ ページが LRU リスト内に 1000ms 未満存在する場合、位置は変更されません。
1000 ミリ秒の時間はパラメータ innodb_old_blocks_time によって制御され、デフォルト値はミリ秒単位の 1000 です。
この戦略は、テーブル全体のスキャンなどの操作を処理するために調整されているようです。
改善された LRU アルゴリズムの動作ロジックを確認するために、今スキャンした 200G の履歴データ テーブルを例として取り上げます。
- スキャン プロセス中、新しく挿入する必要があるデータ ページは最初に古い領域に配置されます。
- データ ページには複数のレコードがあるため、このデータ ページは複数回アクセスされます。ただし、順次スキャンにより、同じページ上のデータのスキャン速度は非常に速く、最初と最後にデータ ページにアクセスされます。アクセス間隔は 1000 ミリ秒を超えないため、このデータ ページは古い領域に保持されます。
- 後続のデータのスキャンを続行すると、前のデータ ページには再度アクセスされないため、リンク リストの先頭 (つまり、若い領域) に移動する機会がなく、キャッシュが限られているため、すぐに LRU によって削除されます。空;
この戦略の最大の改善点は、「最新の使用」の意味を再定義したことであることがわかります。これを防ぐために、従来の訪問数の特性に加えて、アクセスまでに少し長い時間が必要になります。フルテーブルスキャンの一種で、キャッシュ全体をブラッシングする状況。
改良されたアルゴリズムの最大の利点は、この大きなテーブルをスキャンするプロセスで、BufferPool も使用されますが、若い領域にはまったく影響を及ぼさないため、通常のビジネスに応じて BufferPool のクエリ ヒット率が確保されることです。
次の記事:未定