記事ディレクトリ
序文
この記事はスタンフォード大学 CS229 機械学習コースの学習ノートです
この記事の主要部分は黄海光博士からの転載です.リンクは記事の最後にあります. 興味がある場合は、ノートのホームページに直接アクセスして、対応するコース教材と宿題コードをダウンロードできます。
コース公式 Web サイト: CS229: 機械学習 (stanford.edu)
コースビデオ:スタンフォード CS229: 機械学習コース、講義 1 - Andrew Ng (2018 年秋) - YouTube
ノートの概要:ノートの概要 | Stanford CS229 Machine Learning_ReturnTmp のブログ - CSDN ブログ
10週目
17. 大規模な機械学習
17.1 大規模なデータセットからの学習
参考ビデオ: 17 - 1 - 大規模なデータセットを使用した学習 (6 分).mkv
分散が低いモデルの場合、データセットのサイズを増やすと、より良い結果が得られる可能性があります。100 万レコードのトレーニング セットをどのように扱うべきでしょうか?
線形回帰モデルを例にとると、勾配降下法の反復ごとにトレーニング セットの誤差の二乗和を計算する必要があります。学習アルゴリズムに 20 回の反復が必要な場合、これはすでに非常に大きな計算コストになります。
最初にすべきことは、そのような大規模なトレーニング セットが本当に必要かどうかを確認することです。おそらく 1000 個のトレーニング セットだけでもより良い結果が得られるでしょう。判断するために学習曲線を描くことができます。

17.2 確率的勾配降下法
参考ビデオ: 17 - 2 - 確率的勾配降下法 (13 分).mkv
どうしても大規模なトレーニング セットが必要な場合は、バッチ勾配降下法の代わりに確率的勾配降下法を試すことができます。
確率的勾配降下法では、コスト関数を単一のトレーニング インスタンスのコストとして定義します。
コスト( θ , ( x ( i ) , y ( i ) ) ) = 1 2 ( h θ ( x ( i ) ) − y ( i ) ) 2 コスト\left( \theta, \left( {x}^ {(i)} , {y}^{(i)} \right) \right) = \frac{1}{2}\left( {h}_{\theta}\left({x}^{( i)}\right)-{y}^{ {(i)}} \right)^{2}コスト_(私、( ×( i )、y( i ) )_=21( h私( ×( i ) )−y( i ) )2
確率的勾配降下法アルゴリズムは次のとおりです: まずトレーニング セットをランダムに「シャッフル」し、次に:
繰り返します (通常は 1 ~ 10 の間の任意の場所){
i = 1 : mi = 1:mの場合私=1:m {
θ : = θ j − α ( h θ ( x ( i ) ) − y ( i ) ) xj ( i ) \theta:={\theta}_{j}-\alpha\left( {h}_{ \theta}\left({x}^{(i)}\right)-{y}^{(i)} \right){ {x }_{j}}^{(i)}私:=私j−ある( h私( ×( i ) )−y( i ) )バツj(私)
( j = 0の場合 : nj=0:nj=0:n )
}
}
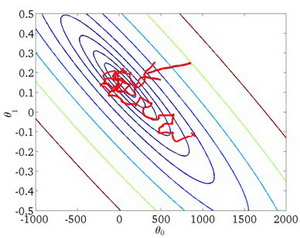
確率的勾配降下法アルゴリズムは、各計算後にパラメーターθ { { {\theta }}を更新します。θ、最初にすべてのトレーニング セットを合計しないと、確率的勾配降下法アルゴリズムは、反復が完了するずっと前に実行されてしまいます。しかし、このようなアルゴリズムの問題は、すべてのステップが「正しい」方向に進むわけではないことです。したがって、アルゴリズムは徐々に極小値の位置に向かって移動しますが、極小値の点に立つことができず、極小点の周囲をさまよっている可能性があります。
17.3 ミニバッチ勾配降下法
参考ビデオ: 17 - 3 - ミニバッチ勾配降下法 (6 分).mkv
ミニバッチ勾配降下アルゴリズムは、バッチ勾配降下アルゴリズムと確率的勾配降下アルゴリズムの間のアルゴリズムであり、各計算定数bbbトレーニング インスタンスの場合、パラメーターθ {
{{\theta }}θ
を繰り返します。{
i = 1 : mi = 1:mの場合私=1:m {
KaTeX解析エラー: 位置 43 の '_' の後に予期されるグループ: …\frac{1}{b}\sum_̲\limits{k=i}^{i…
( j = 0の場合 : nj=0:nj=0:n )
$ i +=10 $
}
}
通常はbbを作りますbは2〜100の間です。この利点は、ベクトル化された方法でbbbトレーニング例では、使用する線形代数関数ライブラリがより優れており、並列処理をサポートできる場合、アルゴリズムの全体的なパフォーマンスは影響を受けません (確率的勾配降下法と同じ)。
17.4 確率的勾配降下法収束
参考ビデオ: 17 - 4 - 確率的勾配降下法収束 (12 分).mkv
ここで、確率的勾配降下法アルゴリズムと学習率αの調整を導入します。αの選択。
バッチ勾配降下法では、コスト関数JJを作成できます。Jは反復回数の関数であり、グラフを描き、そのグラフに従って勾配降下法が収束しているかどうかを判断します。ただし、大規模なトレーニング セットの場合、計算コストが高すぎるため、これは現実的ではありません。
確率的勾配降下法では、 θ { {{\theta }}を更新します。 コストはθ の前に 1 回計算され、その後はxxx回繰り返した後、xx をトレーニング インスタンスにわたるコストの平均をx回計算し、これらの平均をxxx回の反復間の関数のグラフ。
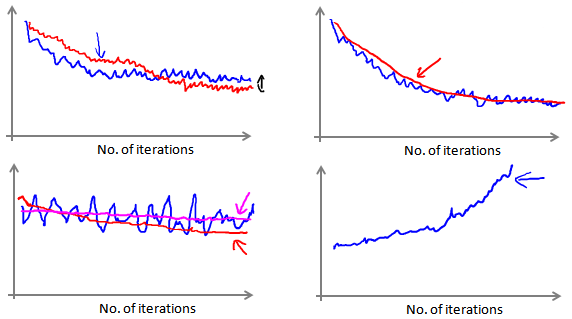
このようなグラフをプロットすると、でこぼこはあるものの、それほど減少していない関数のイメージが得られる可能性があります(上記の左下のプロットの青い線で示されています)。ααを増やせるαを加えて関数を滑らかにすると、下降傾向が見られるかもしれません (上の左下の図の赤い線で示されているように)、または関数グラフがまだでこぼこしていて下降していないかもしれません (マゼンタの線で示されています)。モデル自体に多少の誤差がある場合がございます。
得られた曲線が、上の右下に示すように連続的に上昇している場合は、より小さい学習率α αを選択する必要があるかもしれません。。 _
反復回数が増加するにつれて学習率を低下させることもできます。たとえば、次のようにします。
α = const 1 反復数 + const 2 \alpha = \frac{const1}{iterationNumber + const2}ある=反復回数_ _ _ _ _ _ _ _ _ _+定数2 _ _ _定数1 _ _ _
大域的最小値に近づくにつれて、学習率を下げることで、アルゴリズムが最小値の周囲を移動するのではなく、強制的に収束します。
しかし、通常、非常に良い結果を得るためにこれを行う必要はありません。αを調整するための計算コストは

要約すると、このビデオでは、最適コスト関数における確率的勾配降下法アルゴリズムのパフォーマンスをおおよそ監視する方法を紹介します。この方法では、サンプルセット全体の値を計算するためにトレーニング セット全体を定期的にスキャンする必要はありません。コスト関数ですが、計算する必要があるのは、最後の 1000 個の平均値または毎回のサンプル数だけです。このアプローチを使用すると、確率的勾配降下法が機能し収束していることを確認したり、確率的勾配降下法を使用して学習率αを調整したりできます。αのサイズ。
17.5 オンライン学習
参考ビデオ: 17 - 5 - オンライン学習 (13 分).mkv
このビデオでは、オンライン学習メカニズムと呼ばれる新しい大規模機械学習メカニズムについて説明します。オンライン学習メカニズムにより、問題をモデル化することができます。
現在、多くの大規模な Web サイト、または多くの大規模なインターネット企業は、Web サイトに出入りするユーザーの流入から学習するために、さまざまなバージョンのオンライン学習アルゴリズムを使用しています。特に、サイトにアクセスするユーザーの継続的なストリームからの継続的なデータ ストリームがある場合、できることは、オンライン学習メカニズムを使用してストリームからユーザーの好みを学習し、この情報を使用して、いくつかの最適化を行うことです。ウェブサイトに関する決定。
運送会社があり、ユーザーがA地点からB地点への荷物の発送について尋ねてくるとします。Webサイトでユーザーが複数回ログインし、荷物の送り先を尋ねたいと伝えるとします。荷物の発送先、つまり出発地と目的地を入力すると、Web サイトで輸送パッケージのサービス価格が表示されます。たとえば、荷物の発送に 50 ドル請求します。20 ドルなどを請求します。その後、ユーザーに請求する価格に応じて、ユーザーがこの配送サービスを受け入れる場合もあります。これは良い例ですが、場合によっては、彼らは立ち去ってしまい、配送サービスの購入を拒否するでしょう。そこで、ユーザーに請求する価格を最適化するのに役立つ学習アルゴリズムが必要だとします。
アルゴリズムは、問題から学習しながら問題をモデル化します。オンライン学習アルゴリズムとは、オフラインの静的データセットではなく、データのストリームでの学習を指します。多くのオンライン サイトにはユーザーが絶えず流入しており、サイトはデータをデータベースに保存することなく、ユーザーごとにアルゴリズムをスムーズに学習できることを望んでいます。
私たちが物流会社を経営していると仮定します。ユーザーが地点 A から地点 B までの特急料金について質問するたびに、私たちはユーザーに見積もりを提示します。ユーザーは受け入れることを選択できます ( y = 1 y= 1y=1 ) かどうか (y = 0 y=0y=0)。
ここで、ユーザーが配送サービスの利用オファーを受け入れる可能性を予測するモデルを構築したいと思います。したがって、見積もりは
当社の機能の 1 つであり、その他の機能には、距離、出発地、目的地、および特定のユーザー データがあります。モデルの出力は次のとおりです: p ( y = 1 ) p(y=1)p (と=1 )。
オンライン学習アルゴリズムは、事前定義されたトレーニング セットをループするのではなく、単一のインスタンスで学習するという点で、確率的勾配降下法アルゴリズムに似ています。
永久に繰り返します (Web サイトが実行されている限り) { Get ( x , y ) \left(x,y\right)
( x ,y )現在のユーザーに対応
θ : = θ j − α ( h θ ( x ) − y ) xj \theta:={\theta}_{j}-\alpha\left( {h}_{\theta } \left({x}\right)-{y}\right){
{x}_{j}}私:=私j−ある( h私( × )−y )バツj
( j = 0の場合 : nj=0:nj=0:n )
}
データの一部の学習が完了すると、そのデータは破棄できるため、それ以上保存する必要はありません。このアプローチの利点は、アルゴリズムがユーザーの傾向にうまく適応でき、ユーザーの現在の行動に適応するためにモデルを継続的に更新できることです。
各インタラクション イベントはデータ セットを生成するだけではありません。たとえば、一度に 3 つの物流オプションをユーザーに提供し、ユーザーが 2 つのアイテムを選択すると、実際に 3 つの新しいトレーニング インスタンスを取得できるため、アルゴリズムは 3 つのインスタンスから学習できます。モデルを一度に学習して更新します。
これらの問題はいずれも、固定サンプル セットを使用した標準的な機械学習の問題として分類できます。おそらく、独自の Web サイトを運営し、数日間実行してから、データセット (固定データセット) を保存し、その上で学習アルゴリズムを実行することができます。しかし、これらは実際的な問題であり、大企業が非常に多くのデータを取得しているため、固定データセットを保持する必要は実際にはありません。その代わりに、オンライン学習アルゴリズムを使用して、ユーザーが継続的に学習しているデータから継続的に学習することができます。生成しています。これはオンライン学習メカニズムであり、見てわかるように、使用するアルゴリズムは確率的勾配降下法アルゴリズムに非常によく似ています。唯一の違いは、固定データセットを使用しないことです。私たちが行うことは、サンプルを採取することです。ユーザーは、そのサンプルから学習し、その後そのサンプルを破棄して続行します。また、ある種のアプリケーションで継続的なデータ ストリームがある場合、そのようなアルゴリズムは検討する価値があるかもしれません。もちろん、オンライン学習の利点の 1 つは、ユーザー ベースが変化している場合、またはユーザーの好みがゆっくりと変化しているのと同じように、ゆっくりと変化していることを予測しようとしている場合、このオンライン学習アルゴリズムはゆっくりと継続的に実行できることです。学習した仮定をデバッグし、最新のユーザーの行動に合わせて調整します。
17.6 マップ削減とデータ並列処理
参考ビデオ: 17 - 6 - Map Reduce とデータ並列処理 (14 分).mkv
マップ削減とデータ並列処理は、大規模な機械学習の問題にとって非常に重要な概念です。前に述べたように、バッチ勾配降下法アルゴリズムを使用して大規模データセットの最適解を解く場合、トレーニングセット全体を循環させ、偏導関数とコストを計算してから合計する必要があります。計算コストは次のようになります。非常に高い。データ セットをあまり多くのコンピューターに分散できない場合は、各コンピューターにデータ セットのサブセットを処理させ、すべての結果を合計に集約します。このような方法を地図の単純化と呼びます。
具体的には、学習アルゴリズムをトレーニング セットにわたる関数の合計として表現できる場合、このタスクを複数のコンピューター (または同じコンピューターの異なる CPU コア) に割り当てて処理を高速化できます。
たとえば、400 のトレーニング インスタンスがある場合、バッチ勾配降下法の合計タスクを 4 台のコンピューターに分散して処理できます。

高度な線形代数関数ライブラリの多くは、マルチコアCPUの複数のコアを使用して行列演算を並列処理できます。そのため、アルゴリズムのベクトル化された実装が非常に重要です (ループを呼び出すよりも高速です) 。
18. 応用例:画像文字認識(応用例:写真OCR)
18.1 問題の説明とフローチャート
参考ビデオ: 18 - 1 - 問題の説明とパイプライン (7 分).mkv
画像からテキストへの認識アプリケーションは、指定された画像からテキストを認識します。これは、スキャンした文書から単語を認識するよりも複雑です。

これを行うには、次の手順を実行する必要があります。
-
テキスト検出 (テキスト検出) - 画像上のテキストを他の環境オブジェクトから分離します。
-
文字セグメンテーション (文字セグメンテーション) - テキストを 1 つの文字に分割します。
-
文字の分類 (文字の分類) - 各文字が何であるかを決定します。
この問題はタスク フロー図として表現でき、各タスクは別個のチームによって解決できます。

18.2 引き違い窓
参考ビデオ: 18 - 2 - スライディング ウィンドウ (15 分).mkv
スライディング ウィンドウは、画像からオブジェクトを抽出するために使用される手法です。写真内の歩行者を識別する必要がある場合、最初に行うことは、多数の固定サイズの写真を使用して、歩行者を正確に識別できるモデルをトレーニングすることです。次に、前のトレーニングで歩行者を識別するために使用した画像のサイズを使用して、識別したい画像をトリミングし、カットされたスライスをモデルに渡し、モデルが歩行者であるかどうかを判断させ、モデル上をスライドさせます。画像 切り取られた領域が再度切り取られ、新しく切り取られたスライスもモデルに渡されて判定され、すべての画像が検出されるまでこのサイクルが続きます。
完了したら、トリミングされた領域を拡大し、画像を新しいサイズでトリミングし、新しくトリミングされたスライスをモデルが採用するサイズに縮小し、判断のためにモデルに渡します。

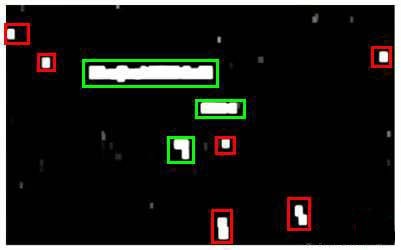
スライディング ウィンドウ技術はテキスト認識にも使用されています。まず、文字と非文字を区別するようにモデルを学習します。次に、スライディング ウィンドウ技術を使用して文字を認識します。文字認識が完了したら、認識領域を拡大し、次に、重複領域がマージされます。次に、アスペクト比をフィルター条件として使用して、幅よりも高さの大きい領域をフィルターで除外します(通常、単語は高さよりも長いと考えられます)。以下の図の緑色の領域は、これらの手順の後にテキストとみなされる領域であり、赤色の領域は無視されます。
上記はテキスト検出段階です。次のステップは、テキストを文字にセグメント化する
タスクを完了するためにモデルをトレーニングすることです。モデルをトレーニングするために必要なトレーニング セットは、単一の文字の画像と、接続された 2 つの文字間の画像で構成されます。
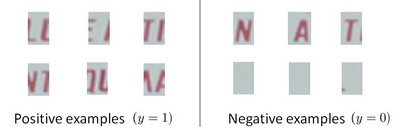

モデルがトレーニングされた後も、文字認識にスライディング ウィンドウ手法を使用します。
以上が文字分割の段階です。
最後の段階は文字分類段階であり、ニューラル ネットワーク、サポート ベクター マシン、またはロジスティック回帰アルゴリズムを使用して分類器をトレーニングできます。
18.3 大量のデータと人工データの取得
参考ビデオ: 18 - 3 - 大量のデータと人工データの取得 (16 分).mkv
モデルの分散が低い場合、モデルをトレーニングするためにより多くのデータを取得すると、より良い結果が得られる可能性があります。問題は、データをどのように取得するかです。データは常に直接利用できるとは限らず、人工的にデータを作成する必要がある場合があります。
テキスト認識アプリケーションを例にとると、フォント Web サイトからさまざまなフォントをダウンロードし、これらのさまざまなフォントをさまざまなランダムな背景画像とともに使用して、トレーニング用のサンプルをいくつか作成できます。これにより、無限のトレーニング セットを取得できます。これはインスタンスを最初から作成することです。
既存のデータを利用し、既存のキャラクターの絵を歪めたり、回転させたり、ぼかしたりするなどの加工を施す方法もあります。実際のデータが加工データと類似していると考えられる限り、この方法を使用して大量のデータを作成できます。
より多くのデータを取得するには、いくつかの方法があります。
1. **人工数据合成**
2. **手动收集、标记数据**
3. **众包(众包就是外包的大众化,交给专业团队得任务改为将任务交给有兴趣的个体,做到低廉成本解决专业问题。)**
18.4 上限分析: 次にパイプラインのどの部分を実行するか
参考视频: 18 - 4 - Ceiling Analysis_ What Part of the Pipeline to Work on Next
(14 min).mkv
機械学習の応用では、通常、最終的な予測を行うためにいくつかのステップを経る必要がありますが、どの部分を改善するのに最も時間と労力を費やす価値があるかをどのように判断すればよいでしょうか? この質問は、上限分析によって答えることができます。
テキスト認識アプリケーションに戻ると、フローチャートは次のとおりです。

フローチャートの各部分の出力は、次の部分の入力となりますが、上限分析では、部分を選択し、100%正しい出力結果を手動で提供し、アプリケーション全体の効果がどの程度向上したかを確認します。この例の全体的なパフォーマンスが 72% 正しいとします。
テキスト検出部分の出力を 100% 正確にすると、システムの全体的な有効性が 72% から 89% に増加することがわかります。これは、おそらくテキスト検出部分の改善に時間とエネルギーを投資する必要があることを意味します。
次に、文字分割出力の結果が 100% 正確になるようにデータを手動で選択しましたが、システムの全体的な効果は 1% しか改善されなかったことがわかりました。これは、文字分割部分が十分である可能性があることを意味します。
最終的に、データを手動で選択したため、文字分類出力の結果は 100% 正しくなり、システムの全体的な効果はさらに 10% 改善されました。これは、改善にさらに多くの時間とエネルギーを投資する必要があることを意味します。アプリケーションの全体的なパフォーマンス。

19. 結論
19.1 要約と謝辞
参考動画:19 - 1 - まとめとお礼(5分).mkv
機械学習クラスの最後のビデオへようこそ。私たちは長い間一緒に勉強してきました。この最後のビデオでは、このコースの主要な内容を簡単に復習し、それから簡単にいくつかお話ししたいと思います。
このコースの終わりとして、私たちは何を学びましたか? このクラスでは、線形回帰、ロジスティック回帰、ニューラル ネットワーク、サポート ベクター マシンなどの教師あり学習アルゴリズムの導入に多くの時間を費やします。これらのアルゴリズムには、 x(i) { {x}^などのラベル付きデータとサンプルが含まれます。{\left( i \right)}} バツ( i )、y ( i ) { {y}^{\left( i \right)}}y( i )。
さらに、教師なし学習の導入にも多くの時間を費やしています。例としては、K 平均法クラスタリング、次元削減のための主成分分析、および一連のラベルなしデータx ( i ) { {x}^{\left( i \right)}} のみがある場合などが挙げられます。バツ( i )の異常検出アルゴリズム。
もちろん、ラベル付きデータを異常検出アルゴリズムの評価に使用できる場合もあります。さらに、推奨システムなどの特別なアプリケーションや特別なトピックについても時間をかけて議論しました。他の特殊なアプリケーションの中でも特に、並列システムやマップリデュース手法を含む大規模な機械学習システム。たとえば、コンピュータ ビジョン技術で使用されるスライディング ウィンドウ分類アルゴリズムです。
最後に、機械学習システムの構築に関する多くの実践的なアドバイスについても触れました。これには、機械学習アルゴリズムが機能しているかどうかを理解する方法が含まれているため、バイアスと分散について話し、分散の問題を解決するための正則化について話し、次に何をすべきかを決定する方法についても話しました。 , 機械学習システムを開発するとき、次に優先すべき作業は何ですか。そこで、学習アルゴリズムの評価方法について説明します。適合率、再現率、F1スコアなどの評価マトリクスと、学習アルゴリズムの評価により実践的なトレーニングセット、相互検証セット、テストセットを紹介します。また、学習アルゴリズムのデバッグと学習アルゴリズムの正常な動作を保証する方法についても紹介し、学習曲線などのいくつかの診断方法を紹介し、エラー分析、上限分析などについても説明しました。
これらのツールはすべて、次に何をすべきかを決定する際に効果的にガイドしてくれるため、貴重な時間を賢く使うことができます。これで、教師あり学習アルゴリズムや教師なし学習アルゴリズムなど、多くの機械学習ツールを習得できました。
しかし、これらに加えて、これらのツールを理解するだけでなく、さらに重要なことに、これらのツールを効果的に使用して強力な機械学習システムを構築する方法を習得してほしいと思います。それでは、このクラスはこれで終わりです。私たちのコースを最後まで受講したのであれば、もうすでに機械学習の専門家になったと感じているはずですよね?
機械学習がテクノロジーと業界に大きな影響を与える重要なテーマであることは誰もが知っています。これで、これらの機械学習ツールを適用して大きな成果を生み出すための準備が整いました。多くの皆さんが、学んだ機械学習ツールを該当分野に応用し、完璧な機械学習システムを構築し、比類のない製品やアプリケーションを開発できることを願っています。また、機械学習の応用を通じて、あなた自身の生活が変わるだけでなく、いつかはより多くの人々の生活がより良くなることを願っています。
また、私にとってこの授業を教えることは一種の楽しみであることを皆さんに伝えたいです。それでは、皆さん、ありがとうございました!
最後に、閉じる前にもう 1 点付け加えておきたいと思います。つまり、それほど昔ではないかもしれませんが、私は学生でした。そして今でも、時間を見つけてはいくつかの講義に出席し、何か新しいことを学ぶようにしています。したがって、このコースを完了するには粘り強く時間がかかることは承知しています。おそらくあなたは非常に忙しい人であり、人生で対処しなければならないことがたくさんあることは承知しています。このため、今でも時間を作ってこれらのコースビデオを視聴することができます。ビデオの多くは数時間にも及びますが、それでもこのような復習用の質問に多くの時間を費やしていることは承知しています。皆さんの多くは、これらのプログラミング演習、長くて複雑なプログラミング演習を勉強することに今でも喜んで時間を費やしています。皆様に心より感謝申し上げます。皆さんの多くがこのクラスで非常に熱心に取り組み、多くの時間をこのクラスに費やし、多くのエネルギーをこのクラスに捧げてきたことを私は知っています。したがって、このコースから何かを学んでいただけることを心から願っています。
最後に言いたい!この度はこの講座をご受講いただき誠にありがとうございました!
アンデュー・ン