一般的な NER データセット形式から JSON 形式への変換 Daquan
序文
最近、大規模モデルの一般的な抽出に関連するタスクを行っているのですが、命令の微調整データ セットの構築を容易にするために、すべてのデータ セットを同じ形式に変換する必要があります。データを加工する際には、異なる形式のNERデータセットを扱いやすいjson形式のデータに変換する必要があり、非常に煩雑な作業となります。NER の分野では、統一された形式仕様はありません。ブロガーは 30 近くの NER データセットを収集し、一般的な NER データセット形式には BIO、BIEO、Excel 形式の BIO、データタグ分離、埋め込み JSON などが含まれると結論付けました。それぞれの形式に 2 つまたは 3 つのデータセットがあり、それらを個別にエンコードすると多大な労力がかかり、作業が遅くなります。github には json 形式に加工されたオープンソースのデータセットが多数ありますが、すべての NER データセットを網羅しているわけではありません。人に釣りを教えるよりも、釣りを教えたほうが良いです。この記事では、一般的なデータセットをまとめます。 NER フィールドの形式を指定します。また、読者が入手できるようにデータ セットを JSON 形式に変換するコードを提供します。さらに、処理されたデータ セットはここからダウンロードできます。役に立った場合は、ブロガーに「いいね!」と励ましをお願いします~
1. NER データセットの概要
NER ドメインには多くの種類のデータセットがあり、一般的なデータセット形式を次の表に示します。
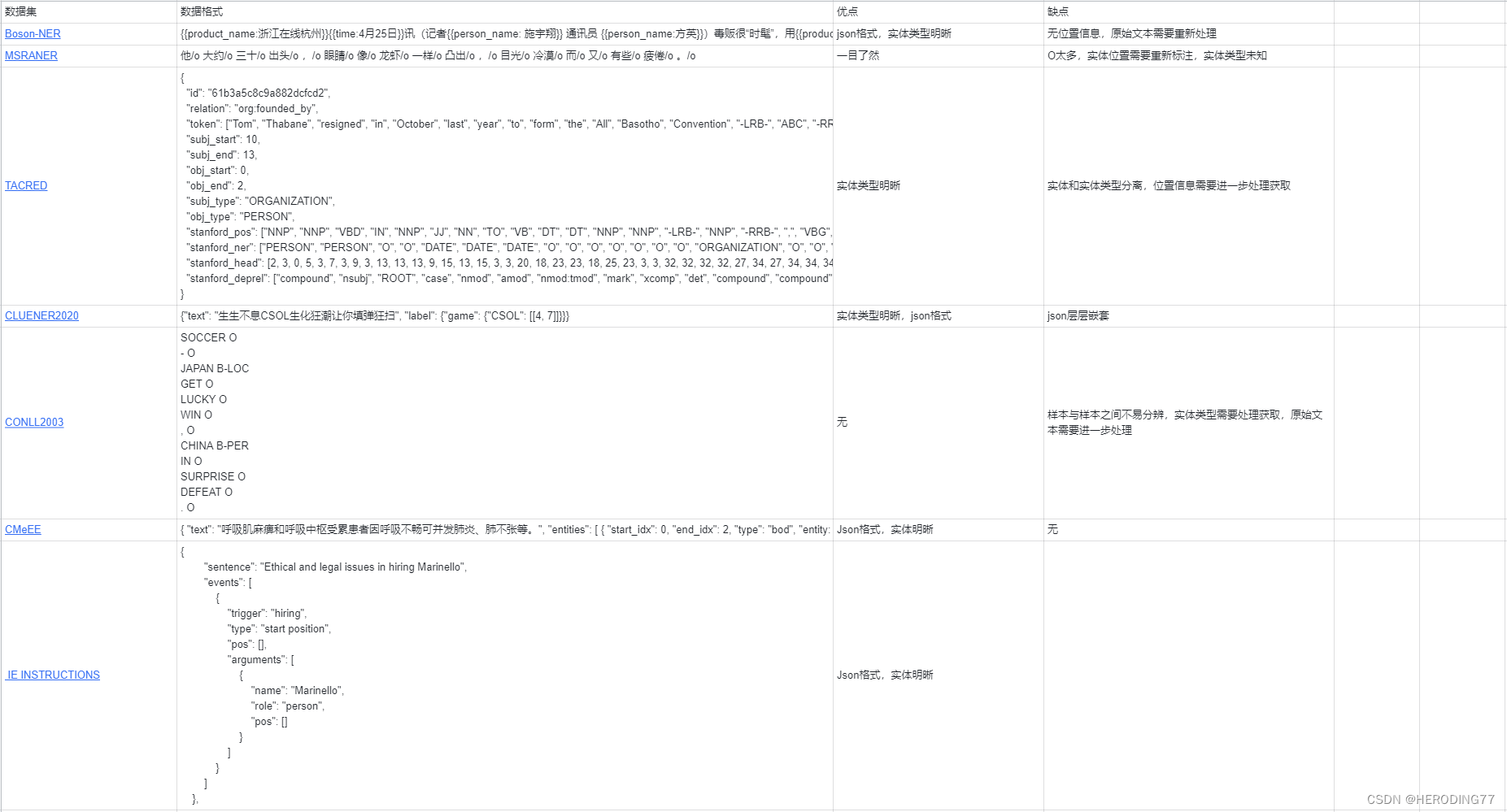
ここではまず、さまざまなデータセット形式の長所と短所を分析し、json 形式を選択する理由を説明します。
1.1 埋め込みjson
1 つ目は、json が埋め込まれた代表的な Boson-NER データセットで、エンティティ情報がテキスト内にマークされています。エンティティの種類は非常に明確ですが、位置情報はマークされておらず、サンプルの場合は知ることができません。エンティティの種類がいくつあるかを直接取得することは困難です。
1.2 略歴
BIO の種類はさらに細分化できます。1 つは、txt ファイル内で 1 行にトークンが 1 つだけ存在し、トークンの後にその種類が続く形式です。全体の内容を縦方向に読む必要があります。もう 1 つの形式は、次の形式に基づいています。各トークンの背後にある元のテキスト エンティティ タイプと組み合わせると、そのようなタイプは読みやすくなりますが、処理はより複雑になります。
1.3 階層化された JSON
階層型 JSON 形式は、均一に処理する必要がある最終形式とより一致しています。各サンプルは、テキスト コンテンツとラベル コンテンツを含む一対の中かっこでネストされていますが、ラベル、メンション、および位置情報はネストされたレイヤーですレイヤーごとに抽出するため不便です。
1.4 BIEO
BIEO の形式は BIO の形式と似ていますが、終了という特殊記号が追加されていることと、処理時に特殊文字を個別に考慮する必要がある点が異なります。
1.5 データラベルの分離
データラベルを分離したデータ形式は最悪です。エンティティを直接見ることも、エンティティの位置情報を取得することもできませんが、両者の対応する位置を比較するだけで済むため、扱いが便利であるという利点があります。ファイルを使用して、対応するエンティティと位置情報を抽出します。
1.6標準json
ここでの標準は、最終的に変換する json データ形式タイプです。次のデータ サンプルを例にとります。

各サンプルには文とエンティティ コレクションが含まれており、文はサンプルのコンテンツであり、エンティティ コレクションには各エンティティ、タイプ、位置情報について言及すると、このデータ形式は私が最もよく処理されると思う形式であり、このブログのコードによって処理される形式でもあります。
2.BIO_to_JSON
プリミティブデータ型:
相 O
比 O
之 O
下 O
, O
青 B-ORG
岛 I-ORG
海 I-ORG
牛 I-ORG
队 I-ORG
和 O
广 B-ORG
州 I-ORG
松 I-ORG
日 I-ORG
队 I-ORG
的 O
雨 O
中 O
之 O
战 O
虽 O
然 O
也 O
是 O
0 O
∶ O
0 O
, O
但 O
乏 O
善 O
可 O
陈 O
。 O
コード:
import json
import sys
import os
sys.path.append("..")
def bio_to_json(input_files, output_files, label_output_file):
label_set = set()
for input_file, output_file in zip(input_files, output_files):
data = []
with open(input_file, 'r', encoding='utf-8', errors='ignore') as f:
lines = f.readlines()
sentence = ""
entities = []
entity_name = ""
entity_type = ""
start_position = 0
for line in lines:
if line == '\n':
# if there's an entity already being processed, append it to entities
if entity_name:
entities.append({
'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
# append the processed sentence to data
data.append({
'sentence': sentence, 'entities': entities})
sentence = ""
entities = []
else:
print(line)
word, tag = line.rstrip('\n').split(' ')
if tag.startswith('B'):
# if there's an entity already being processed, append it to entities
if entity_name:
entities.append({
'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = word
entity_type = tag.split('-')[1]
label_set.add(entity_type) # add this entity type to the set
start_position = len(sentence)
elif tag.startswith('I'):
entity_name += word
else:
# if there's an entity already being processed, append it to entities
if entity_name:
entities.append({
'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
sentence += word
# for the last entity of the last sentence
if entity_name:
entities.append({
'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
if sentence:
data.append({
'sentence': sentence, 'entities': entities})
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
with open(label_output_file, 'w', encoding='utf-8') as f:
json.dump(list(label_set), f, ensure_ascii=False, indent=4)
currPath = os.path.join("datasets", "Weibo")
input_files = [os.path.join(currPath, "train.txt"), os.path.join(currPath, "test.txt"), os.path.join(currPath, "dev.txt")]
output_files = [os.path.join(currPath, "train.json"), os.path.join(currPath, "test.json"), os.path.join(currPath, "dev.json")]
label_output_file = os.path.join(currPath, "label.json")
bio_to_json(input_files, output_files, label_output_file)
json 形式を生成します。
{
"sentence": "相比之下,青岛海牛队和广州松日队的雨中之战虽然也是0∶0,但乏善可陈。",
"entities": [
{
"name": "青岛海牛队",
"type": "机构",
"pos": [
5,
10
]
},
{
"name": "广州松日队",
"type": "机构",
"pos": [
11,
16
]
}
]
},
3.BIEO_to_JSON
プリミティブデータ型:
中 B-GPE
国 E-GPE
将 O
加 O
快 O
人 O
才 O
市 O
场 O
体 O
系 O
建 O
设 O
コード:
import json
def bieo_to_json(input_files, output_files, label_output_file):
num = 0
label_set = set()
for input_file, output_file in zip(input_files, output_files):
data = []
with open(input_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
sentence = ""
entities = []
entity_name = ""
entity_type = ""
start_position = 0
for line in lines:
if line == '\n':
# if there's an entity already being processed, append it to entities
if entity_name:
entities.append({
'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
# append the processed sentence to data
data.append({
'sentence': sentence, 'entities': entities})
num += 1
sentence = ""
entities = []
else:
word, mid, tag = line.rstrip('\n').split(' ')
if tag.startswith('B'):
entity_name = word
entity_type = tag.split('-')[1]
label_set.add(entity_type) # add this entity type to the set
start_position = len(sentence)
elif tag.startswith('I'):
entity_name += word
elif tag.startswith('E'):
entity_name += word
entities.append({
'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
elif tag.startswith('S'):
entity_name = word
entity_type = tag.split('-')[1]
label_set.add(entity_type) # add this entity type to the set
start_position = len(sentence)
entities.append({
'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
else:
# if there's an entity already being processed, append it to entities
if entity_name:
entities.append({
'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
sentence += word
# for the last entity of the last sentence
if entity_name:
entities.append({
'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
if sentence:
data.append({
'sentence': sentence, 'entities': entities})
num += 1
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
with open(label_output_file, 'w', encoding='utf-8') as f:
json.dump(list(label_set), f, ensure_ascii=False, indent=4)
print(num)
import sys
import os
sys.path.append("..")
currPath = os.path.join( "datasets", "CCKS2017-NER")
input_files = [os.path.join(currPath, "train.txt"), os.path.join(currPath, "test.txt")]
output_files = [os.path.join(currPath, "train.json"), os.path.join(currPath, "test.json")]
label_output_file = os.path.join(currPath, "label.json")
bieo_to_json(input_files, output_files, label_output_file)
json 形式を生成します。
{
"sentence": "中国将加快人才市场体系建设。",
"entities": [
{
"name": "中国",
"type": "国家",
"pos": [
0,
2
]
}
]
},
4.BMEO_to_JSON
プリミティブデータ型:
高 B-NAME
勇 E-NAME
: O
男 O
, O
中 B-CONT
国 M-CONT
国 M-CONT
籍 E-CONT
, O
无 O
境 O
外 O
居 O
留 O
权 O
, O
コード:
import json
import sys
import os
sys.path.append("..")
def bmeo_to_json(input_files, output_files, label_output_file):
label_set = set()
for input_file, output_file in zip(input_files, output_files):
data = []
with open(input_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
sentence = ""
entities = []
entity_name = ""
entity_type = ""
start_position = 0
for line in lines:
if line == '\n':
# if there's an entity already being processed, append it to entities
if entity_name:
entities.append({
'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
# append the processed sentence to data
data.append({
'sentence': sentence, 'entities': entities})
sentence = ""
entities = []
else:
word, tag = line.rstrip('\n').split(' ')
if tag.startswith('B'):
entity_name = word
entity_type = tag.split('-')[1]
label_set.add(entity_type) # add this entity type to the set
start_position = len(sentence)
elif tag.startswith('M'):
entity_name += word
elif tag.startswith('E'):
entity_name += word
entities.append({
'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
elif tag.startswith('S'):
entity_name = word
entity_type = tag.split('-')[1]
label_set.add(entity_type) # add this entity type to the set
start_position = len(sentence)
entities.append({
'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
else:
# if there's an entity already being processed, append it to entities
if entity_name:
entities.append({
'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
entity_name = ""
entity_type = ""
sentence += word
# for the last entity of the last sentence
if entity_name:
entities.append({
'name': entity_name, 'type': entity_type, 'pos': [start_position, start_position + len(entity_name)]})
if sentence:
data.append({
'sentence': sentence, 'entities': entities})
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
with open(label_output_file, 'w', encoding='utf-8') as f:
json.dump(list(label_set), f, ensure_ascii=False, indent=4)
currPath = os.path.join( "datasets", "简历-NER")
input_files = [os.path.join(currPath, "train.txt"), os.path.join(currPath, "test.txt"), os.path.join(currPath, "dev.txt")]
output_files = [os.path.join(currPath, "train.json"), os.path.join(currPath, "test.json"), os.path.join(currPath, "dev.json")]
label_output_file = os.path.join(currPath, "label.json")
bmeo_to_json(input_files, output_files, label_output_file)
json 形式を生成します。
{
"sentence": "高勇:男,中国国籍,无境外居留权,",
"entities": [
{
"name": "高勇",
"type": "姓名",
"pos": [
0,
2
]
},
{
"name": "中国国籍",
"type": "国籍",
"pos": [
5,
9
]
}
]
},
5.D_BIO_JSON
プリミティブデータ型:
交行14年用过,半年准备提额,却直接被降到1K,半年期间只T过一次三千,其它全部真实消费,第六个月的时候为了增加评分提额,还特意分期两万,但降额后电话投诉,申请提...
B-BANK I-BANK O O O O O O O O O O B-COMMENTS_N I-COMMENTS_N O O O O O B-COMMENTS_ADJ I-COMMENTS_ADJ O O O O O O O O O O O O O O O O O O O O O B-COMMENTS_N I-COMMENTS_N O O O O O O O O O O B-COMMENTS_N I-COMMENTS_N O O B-COMMENTS_N I-COMMENTS_N O O O O B-PRODUCT I-PRODUCT O O O O B-COMMENTS_ADJ O O O O O O O O O O O O O
コード:
import json
import os
import sys
sys.path.append("..")
def d_bio_to_json(text_file, label_file, output_file, output_label_file):
with open(text_file, 'r', encoding='utf-8') as f_text, open(label_file, 'r', encoding='utf-8') as f_label:
texts = f_text.read().splitlines()
labels = f_label.read().splitlines()
num = 0
data = []
label_set = set()
for text, label in zip(texts, labels):
entities = []
entity = None
start_idx = None
tokens = text.split()
tags = label.split()
for i, (token, tag) in enumerate(zip(tokens, tags)):
if tag.startswith('B'):
if entity is not None:
entities.append(entity)
entity = {
"name": token,
"type": tag[2:],
"pos": [i, i + 1]
}
start_idx = i
label_set.add(tag[2:])
elif tag.startswith('I'):
if entity is None:
entity = {
"name": token,
"type": tag[2:],
"pos": [i, i + 1]
}
start_idx = i
label_set.add(tag[2:])
else:
entity["name"] += token
entity["pos"][1] = i + 1
elif tag == 'O':
if entity is not None:
entities.append(entity)
entity = None
if entity is not None:
entities.append(entity)
sentence = ''.join(tokens) # 去除空格
data.append({
"sentence": sentence,
"entities": entities
})
num += 1
with open(output_file, 'w', encoding='utf-8') as f_out:
json.dump(data, f_out, ensure_ascii=False, indent=4)
with open(output_label_file, 'w', encoding='utf-8') as f_label:
json.dump(list(label_set), f_label, ensure_ascii=False, indent=4)
print(num)
currPath = os.path.join( "datasets", "人民日报2014")
text_file = os.path.join(currPath, "source.txt")
label_file = os.path.join(currPath, "target.txt")
output_file = os.path.join(currPath, "train.json")
output_label_file = os.path.join(currPath, "label.json")
d_bio_to_json(text_file, label_file, output_file, output_label_file)
json 形式を生成します。
{
"sentence": "交行14年用过,半年准备提额,却直接被降到1K,半年期间只T过一次三千,其它全部真实消费,第六个月的时候为了增加评分提额,还特意分期两万,但降额后电话投诉,申请提...",
"entities": [
{
"name": "交行",
"type": "银行",
"pos": [
0,
2
]
},
{
"name": "提额",
"type": "金融操作",
"pos": [
12,
14
]
},
{
"name": "降到",
"type": "形容词",
"pos": [
19,
21
]
},
{
"name": "消费",
"type": "金融操作",
"pos": [
42,
44
]
},
{
"name": "增加",
"type": "金融操作",
"pos": [
54,
56
]
},
{
"name": "提额",
"type": "金融操作",
"pos": [
58,
60
]
},
{
"name": "分期",
"type": "产品",
"pos": [
64,
66
]
},
{
"name": "降",
"type": "形容词",
"pos": [
70,
71
]
}
]
},
6.BIO_JSON_to_JSON
プリミティブデータ型:
{
"text": "来一首周华健的花心", "labels": ["O", "O", "O", "B-singer", "I-singer", "I-singer", "O", "B-song", "I-song"]}
コード:
import json
def bio_json_to_json(input_file, output_file, label_file):
num = 0
label_set = set()
with open(input_file, 'r', encoding='utf-8') as f:
data = f.read().splitlines()
converted_data = []
for sample in data:
sample = json.loads(sample)
sentence = sample['text']
labels = sample['labels']
entities = []
entity_name = ""
entity_start = None
entity_type = None
for i, label in enumerate(labels):
if label.startswith('B-'):
if entity_name:
entities.append({
'name': entity_name,
'type': entity_type,
'pos': [entity_start, i]
})
label_set.add(entity_type)
entity_name = sentence[i]
entity_start = i
entity_type = label[2:]
elif label.startswith('I-'):
if entity_name:
entity_name += sentence[i]
else:
if entity_name:
entities.append({
'name': entity_name,
'type': entity_type,
'pos': [entity_start, i]
})
label_set.add(entity_type)
entity_name = ""
entity_start = None
entity_type = None
if entity_name:
entities.append({
'name': entity_name,
'type': entity_type,
'pos': [entity_start, len(labels)]
})
label_set.add(entity_type)
converted_data.append({
'sentence': sentence,
'entities': entities
})
num += 1
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(converted_data, f, ensure_ascii=False, indent=2)
with open(label_file, 'w', encoding='utf-8') as f_label:
json.dump(list(label_set), f_label, ensure_ascii=False, indent=4)
json 形式を生成します。
{
"sentence": "来一首周华健的花心",
"entities": [
{
"name": "周华健",
"type": "歌手",
"pos": [
3,
6
]
},
{
"name": "花心",
"type": "歌曲",
"pos": [
7,
9
]
}
]
},
7. JSON_to_JSON
プリミティブデータ型:
{
"text": "呼吸肌麻痹和呼吸中枢受累患者因呼吸不畅可并发肺炎、肺不张等。", "entities": [ {
"start_idx": 0, "end_idx": 2, "type": "bod", "entity: "呼吸肌" }, { "start_idx": 0, "end_idx": 4, "type": "sym", "entity: "呼吸肌麻痹" }, {
"start_idx": 6, "end_idx": 9, "type": "bod", "entity: "呼吸中枢" }, { "start_idx": 6, "end_idx": 11, "type": "sym", "entity: "呼吸中枢受累" }, {
"start_idx": 15, "end_idx": 18, "type": "sym", "entity: "呼吸不畅" }, { "start_idx": 22, "end_idx": 23, "type": "dis", "entity: "肺炎" }, {
"start_idx": 25, "end_idx": 27, "type": "dis", "entity: "肺不张" } ] }
コード:
import json
import os
import sys
sys.path.append("..")
def json_to_json(input_files, output_files, label_output_file):
label_set = set()
for input_file, output_file in zip(input_files, output_files):
with open(input_file, 'r', encoding='utf-8') as f_in:
data = json.load(f_in)
converted_data = []
for item in data:
sentence = item['text']
entities = []
for entity in item['entities']:
start_idx = entity['start_idx']
end_idx = entity['end_idx']
entity_type = entity['type']
entity_name = entity['entity']
entities.append({
'name': entity_name,
'type': entity_type,
'pos': [start_idx, end_idx]
})
label_set.add(entity_type)
converted_data.append({
'sentence': sentence,
'entities': entities
})
with open(output_file, 'w', encoding='utf-8') as f_out:
json.dump(converted_data, f_out, ensure_ascii=False, indent=4)
with open(label_output_file, 'w', encoding='utf-8') as f_label:
json.dump(list(label_set), f_label, ensure_ascii=False, indent=4)
currPath = os.path.join( "datasets", "CMeEE-V2")
input_files = [os.path.join(currPath, "CMeEE-V2_train.json"), os.path.join(currPath, "CMeEE-V2_test.json"), os.path.join(currPath, "CMeEE-V2_dev.json")]
output_files = [os.path.join(currPath, "train.json"), os.path.join(currPath, "test.json"), os.path.join(currPath, "dev.json")]
label_output_file = os.path.join(currPath, "label.json")
json_to_json(input_files, output_files, label_output_file)
json 形式を生成します。
{
"sentence": "呼吸肌麻痹和呼吸中枢受累患者因呼吸不畅可并发肺炎、肺不张等。",
"entities": [
{
"name": "呼吸肌麻痹",
"type": "疾病",
"pos": [
0,
5
]
},
{
"name": "呼吸中枢",
"type": "部位",
"pos": [
6,
10
]
},
{
"name": "呼吸中枢受累",
"type": "症状",
"pos": [
6,
12
]
},
{
"name": "呼吸不畅",
"type": "症状",
"pos": [
15,
19
]
},
{
"name": "肺炎",
"type": "疾病",
"pos": [
22,
24
]
},
{
"name": "肺不张",
"type": "疾病",
"pos": [
25,
28
]
}
]
},
8. JSON_to_JSON
プリミティブデータ型:
{
"text": "生生不息CSOL生化狂潮让你填弹狂扫", "label": {
"game": {
"CSOL": [[4, 7]]}}}
コード:
import json
def nested_json_to_json(input_files, output_files, label_output_file):
num = 0
label_set = set()
for input_file, output_file in zip(input_files, output_files):
with open(input_file, 'r', encoding='utf-8') as f_in:
data = f_in.read().splitlines()
converted_data = []
for item in data:
item = json.loads(item)
sentence = item['text']
entities = []
for label, entity in item['label'].items():
entity_type = label
entity_name = list(entity.keys())[0]
start_idx = list(entity.values())[0][0][0]
end_idx = list(entity.values())[0][0][1]
entities.append({
'name': entity_name,
'type': entity_type,
'pos': [start_idx, end_idx]
})
label_set.add(entity_type)
converted_data.append({
'sentence': sentence,
'entities': entities
})
num += 1
with open(output_file, 'w', encoding='utf-8') as f_out:
json.dump(converted_data, f_out, ensure_ascii=False, indent=4)
with open(label_output_file, 'w', encoding='utf-8') as f_label:
json.dump(list(label_set), f_label, ensure_ascii=False, indent=4)
print(num)
import os
import sys
sys.path.append("..")
currPath = os.path.join( "datasets", "CLUENER")
input_files = [os.path.join(currPath, "CLUENER_train.json"),os.path.join(currPath, "CLUENER_dev.json")]
output_files = [os.path.join(currPath, "train.json"), os.path.join(currPath, "dev.json")]
label_output_file = os.path.join(currPath, "label.json")
nested_json_to_json(input_files, output_files, label_output_file)
json 形式を生成します。
{
"sentence": "生生不息CSOL生化狂潮让你填弹狂扫",
"entities": [
{
"name": "CSOL",
"type": "游戏",
"pos": [
4,
7
]
}
]
},
要約する
これは、NER 分野における比較的包括的なデータ セット形式変換の記事です。ほとんどすべてのデータ セットは、形式変換に上記のコード ホイールを使用できます。いくつかの特別なタグがある場合があります。たとえば、BIO の "B-" 形式は、" B_"、またはトークンとラベルがスペースで区切られていません。これを解決するにはコードを変更するだけで済みます。このブログが読者のお役に立てれば幸いです。補足のデータ形式がある場合は、ブロガーに連絡してください~