0 まえがき
これまで canal のさまざまなアプリケーションについて説明してきましたが、実稼働環境では、高いサービス可用性が保証されなければなりません。したがって、単一の運河ノードではニーズを満たすことができません。運河クラスターを構築する必要があります。
1. カナルクラスターモード
アーキテクチャの観点から見ると、サービスの高可用性を確保するために使用する手段は、主にマスター/スレーブ アーキテクチャとクラスタ アーキテクチャです。マスター/スレーブをクラスター アーキテクチャに帰することもありますが、厳密に言えば、クラスター アーキテクチャは複数のノードの同時動作を指しますが、マスター/スレーブ アーキテクチャでは同時に実行されるノードは 1 つだけで、もう 1 つのノードは実行されます。マスター ノードがダウンしている場合にのみバックアップとして使用され、スタンバイ ノードが有効になります。
canal のクラスター モードはどれですか?
まず、canal のデータ同期は binlog と mysql dump コマンドに依存していることを理解する必要があります。binlog 自体の特性には、データの原子性、分離、順序性が必要です。同時に、mysql dump コマンドは、mysql サーバー上のより多くのリソースを占有します。このため、運河サーバーは、同期のためにバイナリログを読み取るために一度に 1 つのノードしか持つことができません。
したがって、これに基づくと、canal のクラスター モードは実際にはマスター/スレーブ モードになります。次に、構築したいのはマスター/スレーブです。
canal にはサーバー側のデプロイヤーとクライアント側のアダプターがあることがわかっています。サーバーは mysql から binlog を読み取る責任を負い、クライアントはサーバーから同期された binlog データを読み取る責任を負います。処理後、同期されたデータが送信されますRedis、ES、その他のリレーショナル データベースなどのターゲット サーバーに送信します。
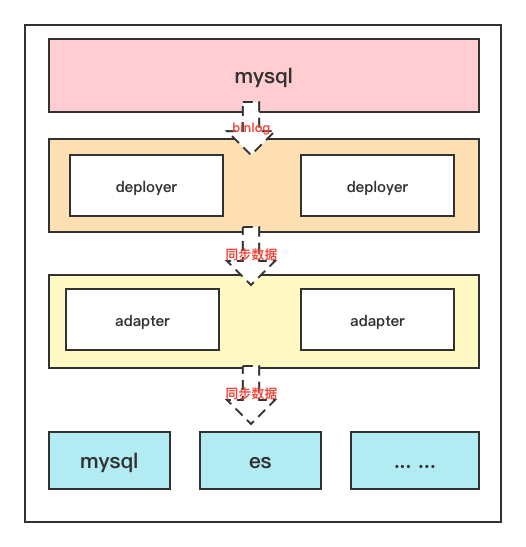
この点は公式文書でも説明されていますので、皆様の理解を助けるために引用させていただきます。
Canal の ha は 2 つの部分に分かれており、canal サーバーと canal クライアントにはそれぞれ対応する ha 実装があります。
canal サーバー: mysql ダンプのリクエストを減らすために、異なるサーバー上のインスタンスでは 1 つのサーバーのみを同時に実行し、他のサーバーはスタンバイ状態にする必要があります。
canal クライアント: 順序性を確保するために、インスタンスに対して一度に 1 つの canal クライアントのみが get/ack/rollback 操作を実行できます。そうでない場合、クライアントが受信する順序は保証されません。
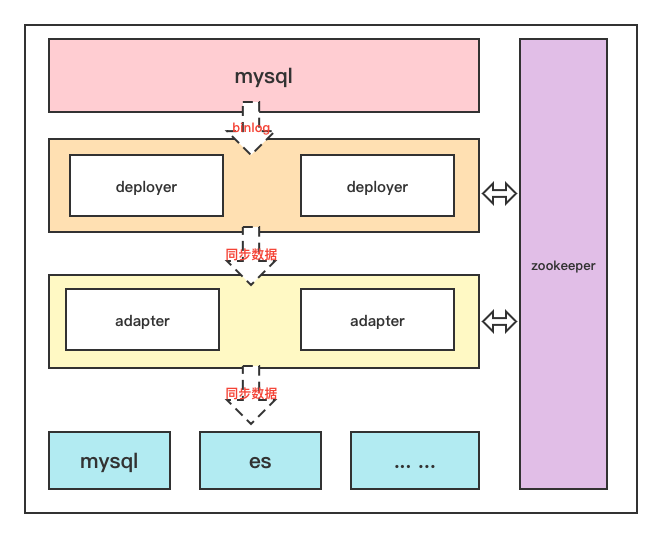
マスターノードとスレーブノードの間でどのように調整し、協力するか?
クラスター アーキテクチャが決定された後、別の問題が発生します。スレーブ ノードはマスター ノードがダウンしていることをどのようにして認識し、いつ動作を開始するかをどのように認識するのでしょうか。同時に、スレーブ ノードはマスター ノードのデータ同期の進行状況をどのようにして知るのでしょうか? スレーブ ノードがデータを最初から再度同期することは不可能ですか?
1 つ目はハートビート パケットを送信して実現すること、2 つ目は同期の進行状況を保存するサードパーティが必要であることを考えて、この 2 点を組み合わせて、どのようなサードパーティ コンポーネントが必要かを考えてみましょう。ハートビートメンテナンス機能(つまり、登録サービスの機能)があり、ファイルストレージと同期の機能もあります
これは飼育員の当然の財産ではないでしょうか。したがって、マスター/スレーブ ノードを制御するサードパーティ コンポーネントとして zk が必要です。登録センターや設定センターの役割に相当します。
そうすると構造はこうなります
2. カナルクラスター建設
原理を整理した後、実際に構築する方法を見てみましょう
2.1 環境の準備
デモンストレーションの整合性を確保するために、運河クラスター構築のデモンストレーションに加えて、クラスター モードを通じて mysql データを es に同期します。
したがって、事前に準備する必要があります。
- mysql データベース、binlog を開き、canal アカウントを作成し、権限を付与します。
- es+kibana サービス
- 動物園の飼育員サービス
- canal を展開するための 2 台のサーバー
mysql で binlog を開き、ユーザーを作成し、ユーザーに権限を与える方法については、すでに述べたので繰り返しませんが、必要に応じて次のブログ投稿を参照してください。
canal1.1.5を介してmysql8.0データのelasticsearch7.xへの増分/完全同期を実現します。
2.2 クラスターの構築
2.2.1 飼育員の建設
ここでは、デモンストレーションの便宜上、docker を使用して zk をビルドします。
docker run -d -e TZ="Asia/Shanghai" -p 2181:2181 --name zookeeper zookeeper
2.2.2 ビルドサーバーデプロイヤ
1. データソース mysql サービスのバイナリログの場所をクエリします。
# 源mysql服务器中登陆mysql执行
show binary logs;
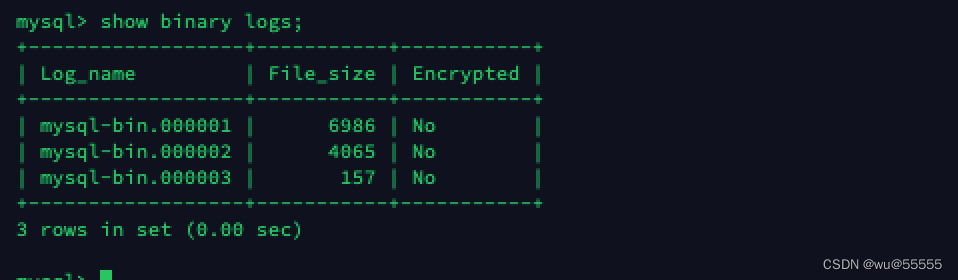
クエリ結果を覚えておいてください。後続の設定で使用します。
2. この記事の時点で、canal の最新バージョンは 1.1.6 であるため、本文ではデモ用にこのバージョンを使用します。Canal1.1.6 バージョンには jdk11+ が必要で、canal1.1.5 以下には jdk1.8+ が必要です。
または、wget コマンドを使用してサーバーに直接ダウンロードします。
wget https://github.com/alibaba/canal/releases/download/canal-1.1.6/canal.deployer-1.1.6.tar.gz
3. インストールパッケージを解凍します。
tar -zxvf canal.deployer-1.1.6.tar.gz
cluster4.このデモンストレーション用の新しいインスタンスを作成します
cd deployer
cp -R conf/example conf/cluster
5. 設定ファイル canal.properties を変更します。
vim conf/canal.properties
コンテンツの変更
# 设置canal服务端IP
canal.ip =192.168.244.25
# zk地址,多个地址用逗号隔开
canal.zkServers =192.168.244.1:2181
# 实例名称
canal.destinations = cluster
# 持久化模式采用zk
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
6. 構成ファイルinstance.propertiesを変更します。
vim conf/cluster/instance.properties
変更点:
# 每个canal节点的slaveId保持唯一,在1.0.26版本后已经能够自动生成了, 无需设置
# canal.instance.mysql.slaveId=1
# 设置binlog同步开始位置
canal.instance.master.address=192.168.244.17:3306
canal.instance.master.journal.name=mysql-bin.000001
canal.instance.master.position=0
canal.instance.master.timestamp=1665038153854
# 数据源账号密码
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
mysql データ同期の開始点の説明:
- canal.instance.master.journal.name + canal.instance.master.position : 開始するバイナリログの位置を正確に指定します
- canal.instance.master.timestamp : タイムスタンプを指定すると、canal は自動的に mysql バイナリを走査し、タイムスタンプに対応するバイナリログの場所を見つけて開始します。
- 情報を指定しないでください。デフォルトでは、現在のデータベースの場所から開始します。(マスターステータスを表示)
7. 上記の構成を参照して、デプロイヤー ノード 2 を調整します。デプロイヤー サービスの IP が現在のノードの IP に調整されることに注意してください。
8. 2 つのノードを起動します。2 番目のノードを起動するときは、正常に起動しないことに注意してください。上で述べたように、同時に実行される運河サービスは 1 つだけです。もう 1 つの運河サービスがダウンすると、バックアップが実行されます。ノードが自動的に起動します
./bin/startup.sh
2.2.3 クライアントアダプタの設定
1. アダプターのインストール パッケージをダウンロードします。これは、上記の github ページからダウンロードするか、手順に従ってダウンロードできます。
wget https://github.com/alibaba/canal/releases/download/canal-1.1.6/canal.adapter-1.1.6.tar.gz
2. 圧縮パッケージを解凍します。
tar -zxvf canal.adapter-1.1.6.tar.gz
3. 設定ファイルを変更するapplication.yml
vim conf/application.yml
【】必要な調整項目に が付いている内容を変更します。
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
# zk地址【1】
zookeeperHosts: 192.168.244.1:2181
syncBatchSize: 1000
# 出现报错时的重试次数
retries: 0
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
# deployer服务端地【2】
# canal.tcp.server.host: 127.0.0.1:11111
# zk地址【3】
canal.tcp.zookeeper.hosts: 192.168.244.1:2181
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
srcDataSources:
# 源数据库地址,可配置多个
canalDs: # 命名自定义【4】
url: jdbc:mysql://192.168.244.17:3306/canal_test?useUnicode=true
username: canal
password: canal
canalAdapters:
- instance: cluster # 服务端配置的实例名称【5】
groups:
- groupId: g1
outerAdapters:
# 开启日志打印
- name: logger
# 配置目标数据源【5】
-
key: es
# es7 or es6
name: es7
hosts: http://192.168.244.11:9200 # 127.0.0.1:9300 for transport mode
properties:
mode: rest # or rest or transport
# es账号密码
security.auth: elastic:elastic # only used for rest mode
# es集群名称
cluster.name: blade-cluster
4. 同期設定ファイルの作成user.yml
vim conf/es7/user.yml
文書の内容
注意事项: ここには落とし穴があります。つまり、記述された SQL でテーブル名を囲むために「``」記号を使用しないでください。そうしないと、エラーは発生しませんが、データは同期されません。
dataSourceKey: canalDs # 这里的key与上述application.yml中配置的数据源保持一致
outerAdapterKey: es # 与上述application.yml中配置的outerAdapters.key一直
destination: cluster # 默认为example,与application.yml中配置的instance保持一致
groupId:
esMapping:
_index: user
_type: _doc
_id: id
sql: "SELECT
id,
seq_no,
name,
age,
address
FROM
user"
# etlCondition: "where t.update_time>='{0}'"
commitBatch: 3000
ここでは、独自のデータベース テーブルに従って、対応するファイルを作成できます。ここでは 1 つのテーブルのみを同期しました。es のインデックス マッピングは次のとおりです。同期する前に、事前にインデックスを作成してください。
{
"user" : {
"mappings" : {
"properties" : {
"address" : {
"type" : "text",
"analyzer" : "ik_smart"
},
"age" : {
"type" : "integer"
},
"name" : {
"type" : "keyword"
},
"seq_no" : {
"type" : "keyword"
}
}
}
}
}
5. 他のアダプター ノードも同様に構成されます
6. アダプターを起動します
./bin/startup.sh

2.2.4 テスト
1. データベースにデータを追加します
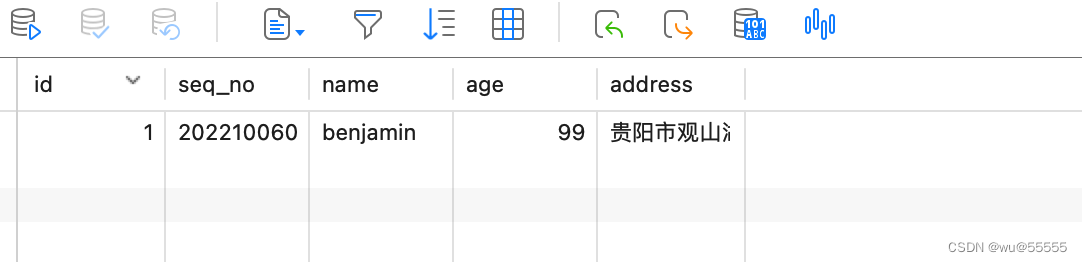
2. アダプターノードのログを確認します。
tail -f logs/adapter/adapter.log
ノード 1:

ノード 2:

ノード 1 にデータが同期的に配信されていることがわかります。同期が成功すると、ログの後に次のようなAffected indexes: xxx文字が表示されます。
3. kibana でデータをクエリします
GET user/_search
結果は、同期が正常に行われていることを示しています

4. ここで、ダウンタイムをシミュレートするために動作しているデプロイヤ サービスをシャットダウンします。
どのデプロイヤが動作しているかわからない場合は、ログを確認してください。継続的にログが出力されているデプロイヤが動作しています。
cd ../deployer
./bin/stop.sh
5. スタンバイ デプロイヤー ノードのログを表示します。
cat logs/cluster/cluster.log
6. 別のデータを追加して、正常に同期できるかどうかを確認します
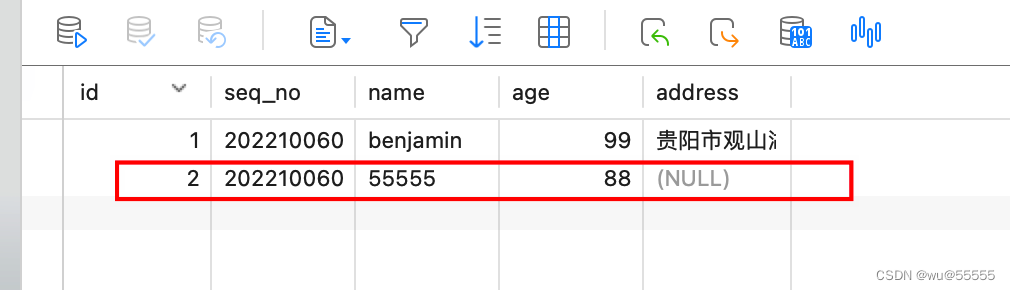
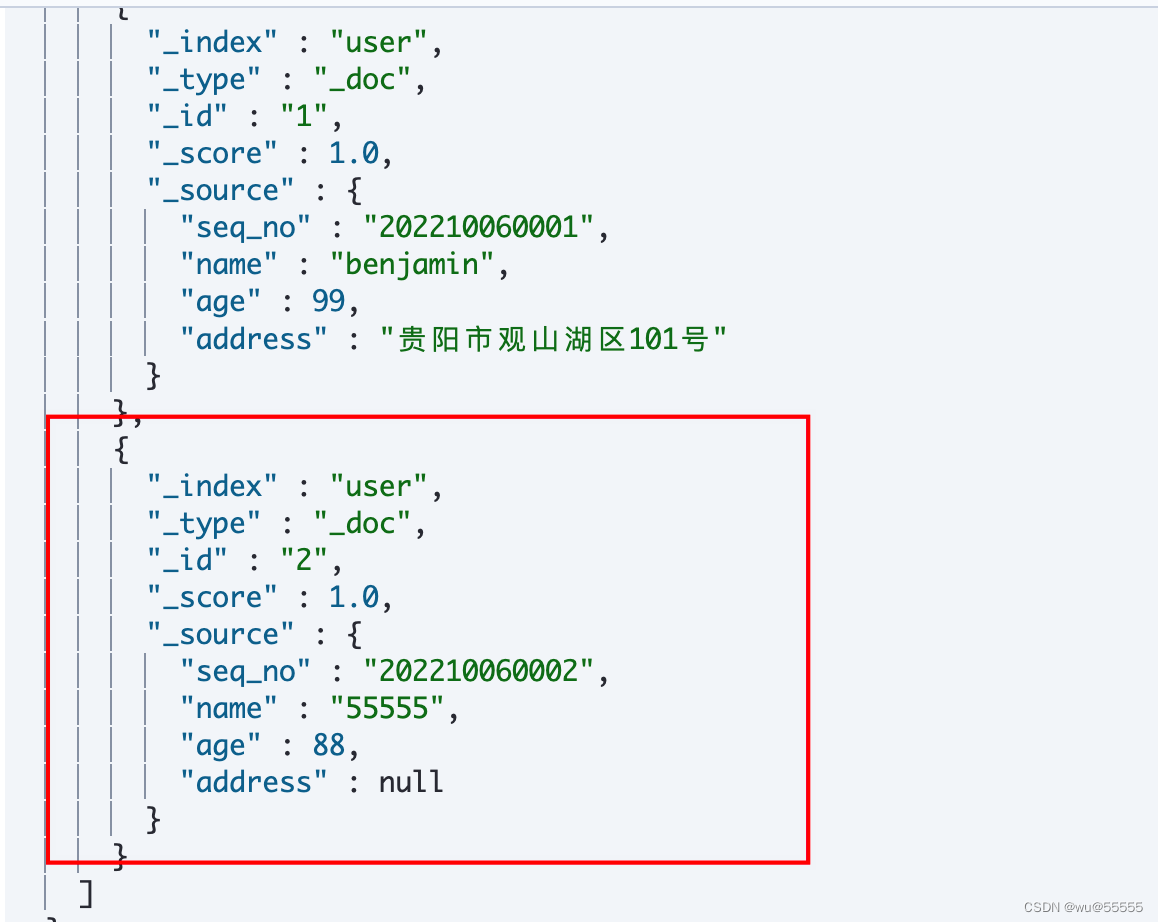
7. kibana のデータを確認すると、データの同期が成功し、デプロイヤー ノードが自動的に正常に切り替わったことがわかります。
8. 次に、アダプター ノードのダウンタイムをシミュレートしましょう。アダプター ノードの 1 つをシャットダウンします。
9. データを追加する
10. kibana を表示、データは正常に同期されています

要約する
デプロイヤ ノードは同時に 1 つだけ実行されますが、アダプタ ノードはサービス分散メカニズムを採用し、複数のノードが同時に機能し、zk はリクエストを特定のアダプタ ノードに分散してデータ同期タスクを実行します。
次回も引き続き、canal-admin と組み合わせてクラスターノードを管理する方法について説明します。