
概要
Elasticsearch (ES) は、オープンソースの分散検索および分析エンジンとして推奨されており、一連のシステムを通じてリアルタイムのログ分析、全文検索、時系列データ分析などのユーザーのさまざまなニーズを簡単に満たすことができ、コストを大幅に削減できます。ビッグデータ時代におけるデータの価値を発見するコスト。
Tencent は、同社の豊富なシナリオで ES を大規模に使用すると同時に、Elastic と協力して Tencent Cloud 上でカーネル強化された ES クラウド サービスを提供します。大規模で豊富な実用的なシナリオが、ES カーネルの安定性、コスト、パフォーマンスの面で Tencent の継続的な進化を後押しします
Tencent は、実行エンジンの最適化、ストレージの再構築、線形拡張などの一連の技術ソリューションを通じて、高性能、低コスト、スケーラビリティの観点からネイティブ ES カーネルを徹底的に最適化しました。
概要
- Tencent における ES の幅広い応用: 電子商取引レベルの検索から兆レベルの時系列データ処理まで
- 兆レベルのストレージシステムのアーキテクチャ設計
- ECレベル検索サービスのプラットフォーム構築
- オープンソース コミュニティへの貢献と将来の探求
利点
- 兆レベルのストレージ システムのパフォーマンスとコスト設計の経験。
- 大規模で直線的に拡張可能な分散システムを構築した実務経験。
- オープンソース コミュニティでの共同構築の経験。

文章
今日私が皆さんと共有するトピックは、Tencent の兆レベルの Elasticsearch アーキテクチャの実践です。一方では Elasticsearch を紹介し、他方では、分散システムにおけるこの革新的な実践の経験を皆さんと共有します。設計プロセス。
主な内容は次の 4 つの部分で構成されます。
- パートは Elasticsearch の紹介です
- 2 番目の部分は技術的な課題です
- 第三部は建築実践の取り組みです。
- 4 番目の部分は最終的なまとめです
1. Elasticsearch の概要
まず、Elasticsearch の概要を見てみましょう Elasticsearch (別名 ES) は、3 つのフィールドを使用する高性能分散ストレージ システムです。
0. 応用分野

検索エンジン
たとえば、一般的なアプリ検索、サイト検索、電子商取引検索などは、内部反転、インデックス、さまざまな単語分割プラグインに基づいており、あらゆるユーザーの検索ニーズに対応します。
可観測性
可観測性とは何ですか?
基本的にアプリケーション開発プロセスにおけるすべてのデータをカバーするのは、運用・開発プロセスにおけるログ、監視、アプリケーションのパフォーマンスですが、ESはログの収集、分析、可視化を含めた完全なソリューションを誰もが利用できるように提供します。 。また、ES はログ シナリオをカバーするため、ログの量が非常に多くなり、ES の急速な開発が促進されます。
安全検査
ES は SIEM を提供し、Endpoint Security は集中型とターミナルの 2 つの側面からセキュリティの検出と防御を支援します。これらが ES で使用される 3 つのシナリオです。
開発状況
ESも現在非常に急速に発展しています
- まず第一に、過去 6 年間で DB-Engines で 7 位にランクされたシステムになりました。
- その後、一年中検索フィールドで1位になります
- オープンソースのログのリアルタイム分析も有利な立場にあります
- オープンソースのステータスに関しては 51,000 のスターがあり、アプリケーション ステータスのダウンロードに関しては 4 億以上があり、複数のクラウド ベンダーと協力しています。
1. システムアーキテクチャ
次に、ES のシステム アーキテクチャを見てみましょう。
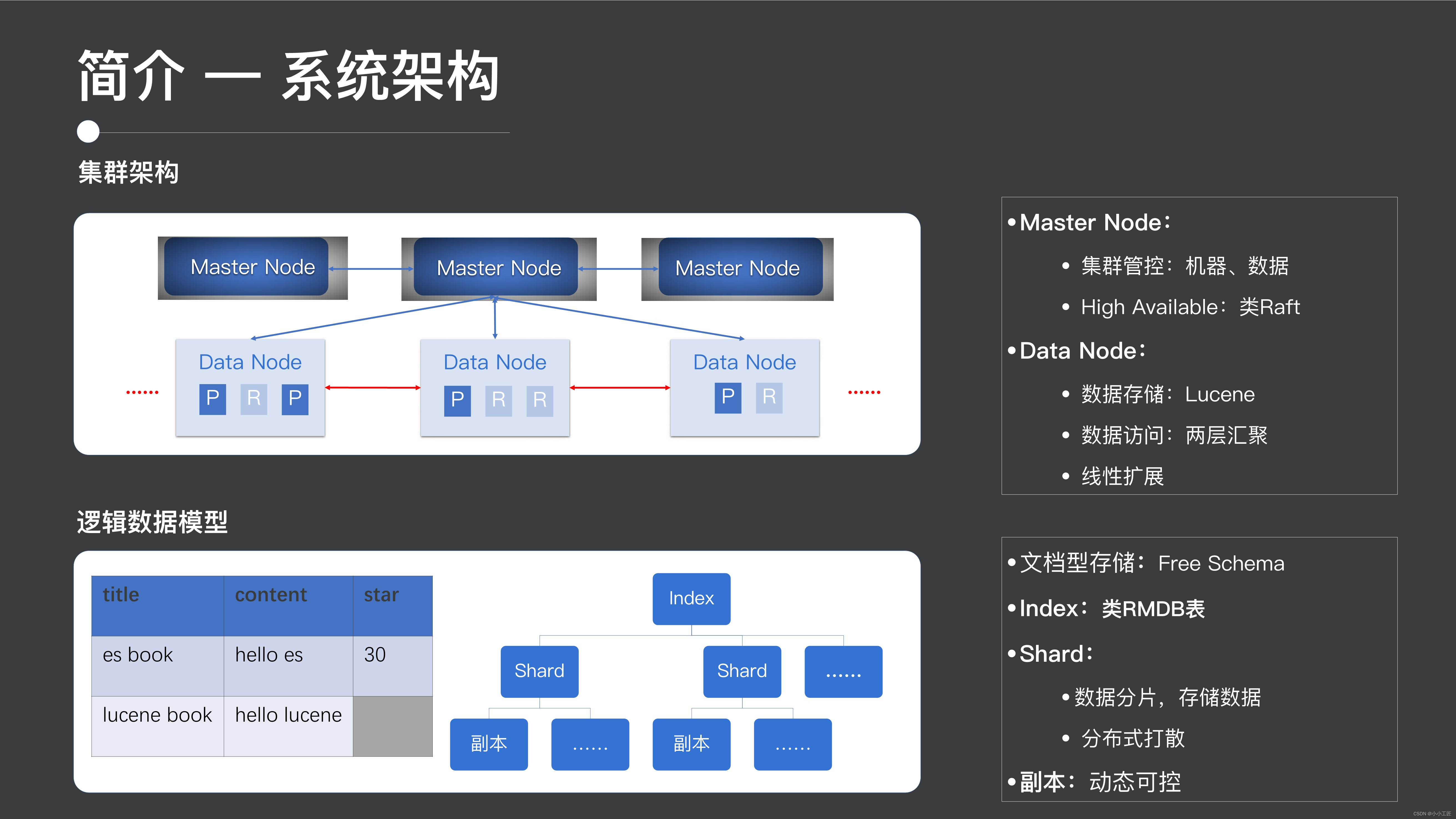
クラスタアーキテクチャ
1 つ目はクラスター アーキテクチャです。ES のクラスター アーキテクチャは典型的な集中型アーキテクチャです。クラスターにはマスター ノードが含まれており、分散型コンセンサス プロトコルを通じてマスター HA を保証し、クラスター全体を制御します。データ ノードはデータ ストレージとアクセスを提供するために使用されます。データ ノードは線形にスケーラブルです。
次に、物理データ モデルです。物理データ モデルの観点から見ると、ES は実際にはドキュメント データベースです。インデックスと呼ばれる、データベースに関するテーブルに似た構造を持っています。インデックスはシャードに分割できます。シャードには複数のコピーが含まれており、データのスケーラビリティを確保するために、クラスタ全体に分散されます。
さらに、ES クラスター内のレプリカは、可用性とコストのバランスに合わせて動的に調整できます。
物理データモデル
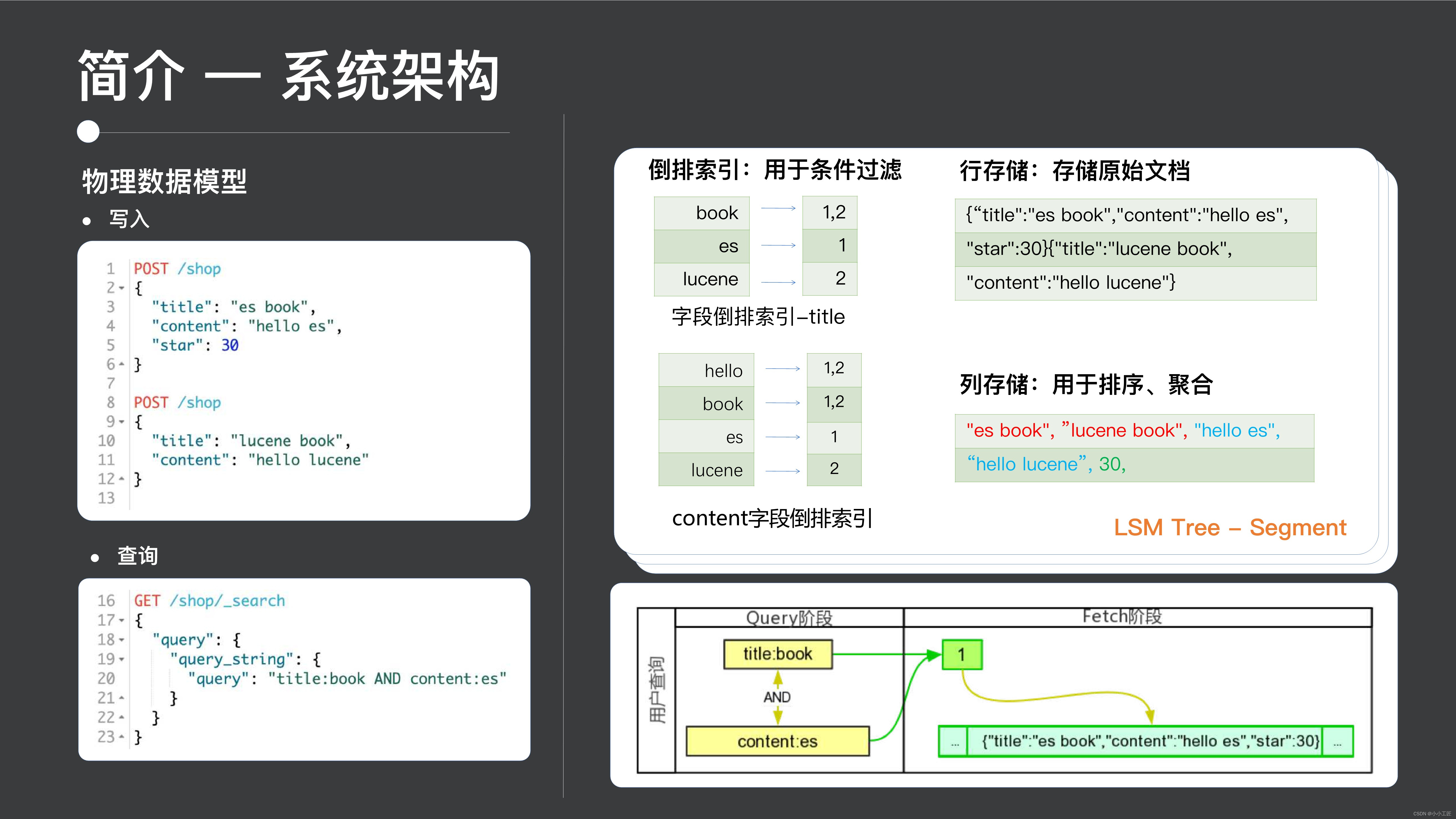
次に物理データ モデルですが、物理データ モデルの ES に書き込まれたデータはシャード内にどのように保存されるのでしょうか?
見てみましょう。ES は実際にはLSM ツリー アーキテクチャ システムであり、書き込まれたデータは最下層に小さなツリーを生成します。各小さなツリー ES はセグメントと呼ばれます。
セグメントには 3 つの典型的なデータ構造が含まれています。
- 銀行預金
- カラムストレージ
- 最後のカテゴリは転置インデックスです
逆インデックスの機能は、条件付きフィルタリングです。たとえば、クエリを実行するとき、アクセスを高速化するためにインデックスを使用する必要があります。たとえば、タイトル フィールドのインデックスを構築すると、単語の分割が実行されます。と書くと、1番と2番の文書には存在できず、1番の文書にはesが存在する、このような処理は転置インデックスに属します。
行ストレージは生データの保存に使用され、ユーザーが表示できる元のログ監視情報を返すために使用されます。列ストレージは並べ替えと集計に使用されます。これにより、集計プロセス中に必要な列のみを読み取ることができ、高速化されます。パフォーマンス:これは ES の基礎となる物理データ モデルです。
お問い合わせ
次に、クエリ レベルでは、実際、ES は典型的な非クエリ モードを提供します。検索エンジンと同じように、タイトルに book が含まれ、内容に es が含まれる書籍を検索できます。その後、es がその中でそれに続きます。逆インデックス。条件を満たすドキュメント ID のセットを見つけて、ドキュメント ID のこの部分を処理する。これは、これまで見てきたシステム アーキテクチャ全体の紹介です。
2. Tencent アプリケーションの現在の状況

ES は、テンセント内にパブリック クラウド、プライベート クラウド、社内クラウドなど、非常に幅広いアプリケーション環境を備えています。
- パブリッククラウド環境の場合、実際には中小規模のユーザー向けのさまざまな利用シーンが数多く含まれており、ESの隅々まで成熟したレベルにまで磨き上げることができます。
- 内部クラウドにはこれほど大規模なクラスターと高圧が存在するため、潜在的なボトルネックや ES の潜在的なニーズを発見するのに役立ちます。
- プライベート クラウドのシナリオでは、実際にはネットワークの分離が原因であり、全員が標準化された対話と自動化された操作を実現する必要があるため、ES の自動化された操作は良好な状態にあります。
いくつかの特定のアプリケーション分野における Tencent の ES の適用を見てみましょう。
検索首輪
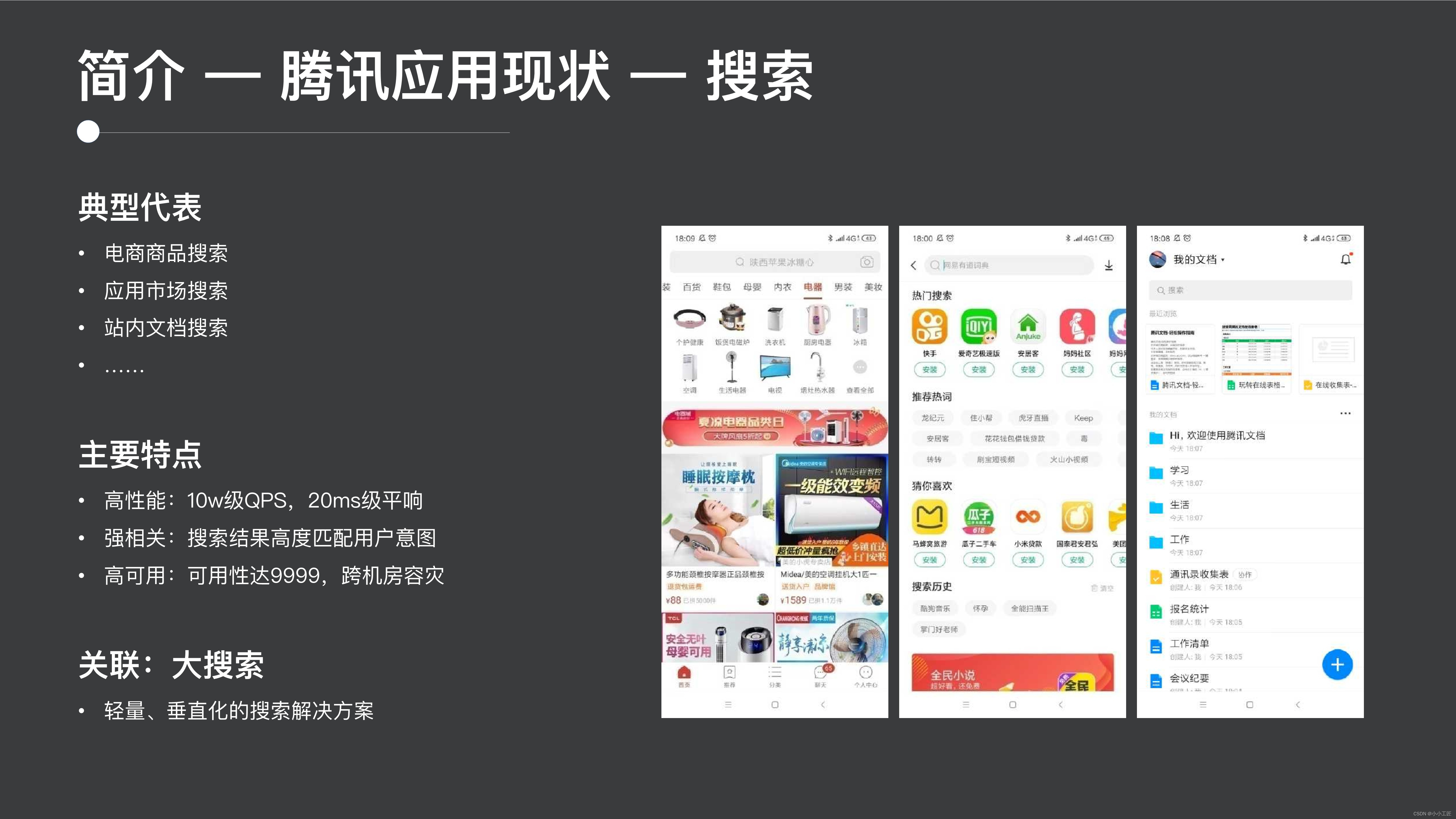
1 つ目は検索フィールドです。検索フィールドには、電子商取引製品の検索、ドキュメントの検索、アプリケーション マーケットのアプリの検索の 3 種類の代表的なアプリケーションが含まれています。アプリケーションシナリオ。
検索シーンの非常に明らかな特徴は次のとおりです。
- まず第一に、高いパフォーマンスが必要であり、100,000 レベルの QPS と 10ms のフラットなサウンドが必要です。
- 2 つ目は、強い相関です。検索結果はユーザーの意図と高度に一致する必要があります。これは、ユーザーがリンゴを検索した場合、それはリンゴまたは Apple の携帯電話を意味する可能性がありますが、ユーザーのオレンジを返すことはできないのと同じです。
- 3 番目は、高可用性です。ユーザーは、検索シナリオで非常に高い可用性を必要とします。通常、9 は 4 つあります。ダブル 11 がもうすぐ始まります。実際、どの電子商取引会社も、自社のサービスが 1 時間切断されることを受け入れることはできません。高可用性を実現するには、非常に要求が厳しい。
ES は軽量の垂直検索ソリューションであり、ES に基づいてさまざまな電子商取引レベルの検索アプリケーションを構築できます。
ログのリアルタイム分析
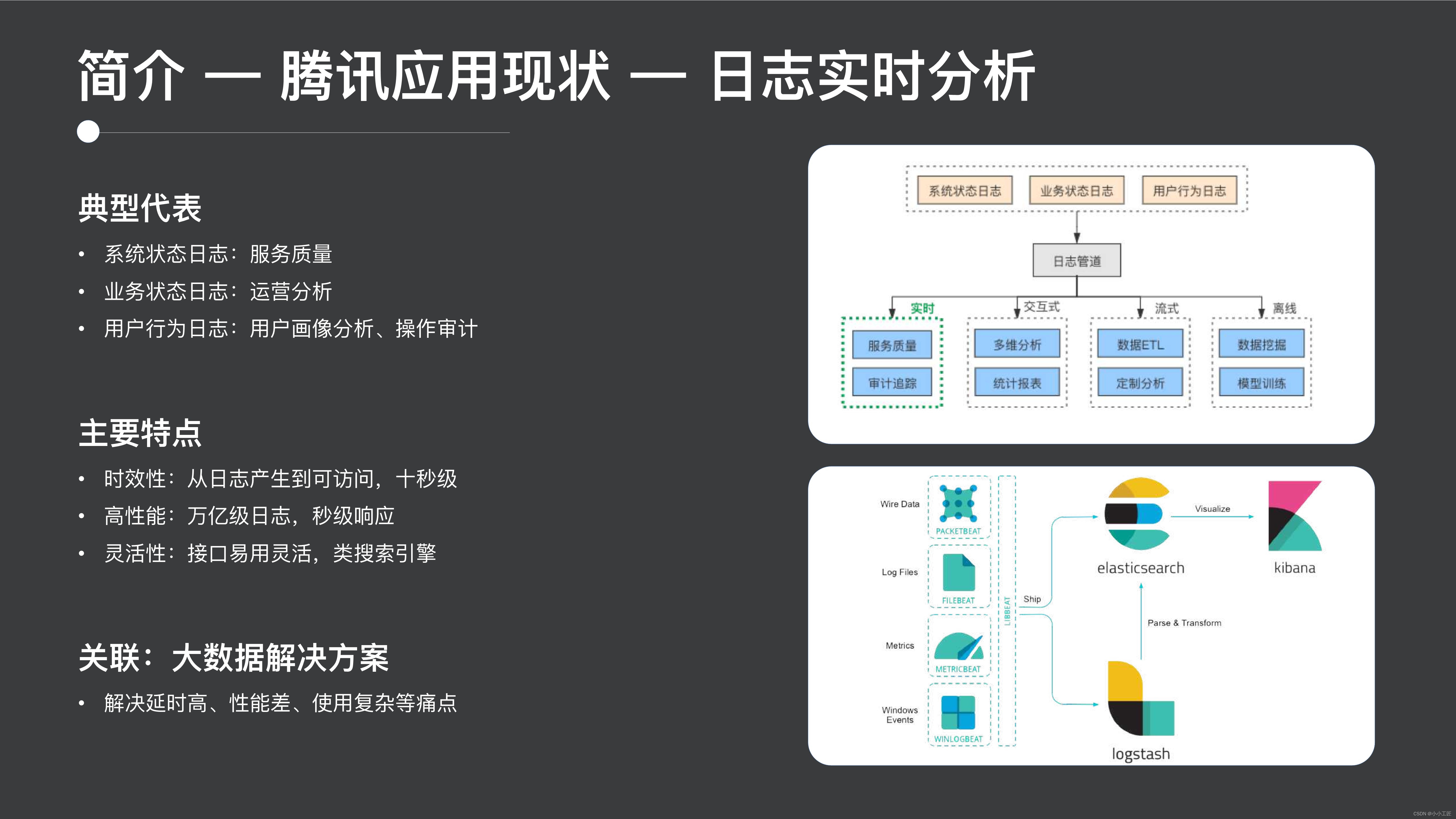
次に、ES の 2 番目の典型的なアプリケーション シナリオであるリアルタイム ログ分析を見てみましょう。これは、ES の最も広く使用されているシナリオでもあります。
システムログに基づくサービス品質監視、業務状況ログに基づく運用管理、ユーザー行動ログに基づくユーザー像分析や運用分析など、ログシナリオにおいては明らかな機能を備えています。
時系列データ
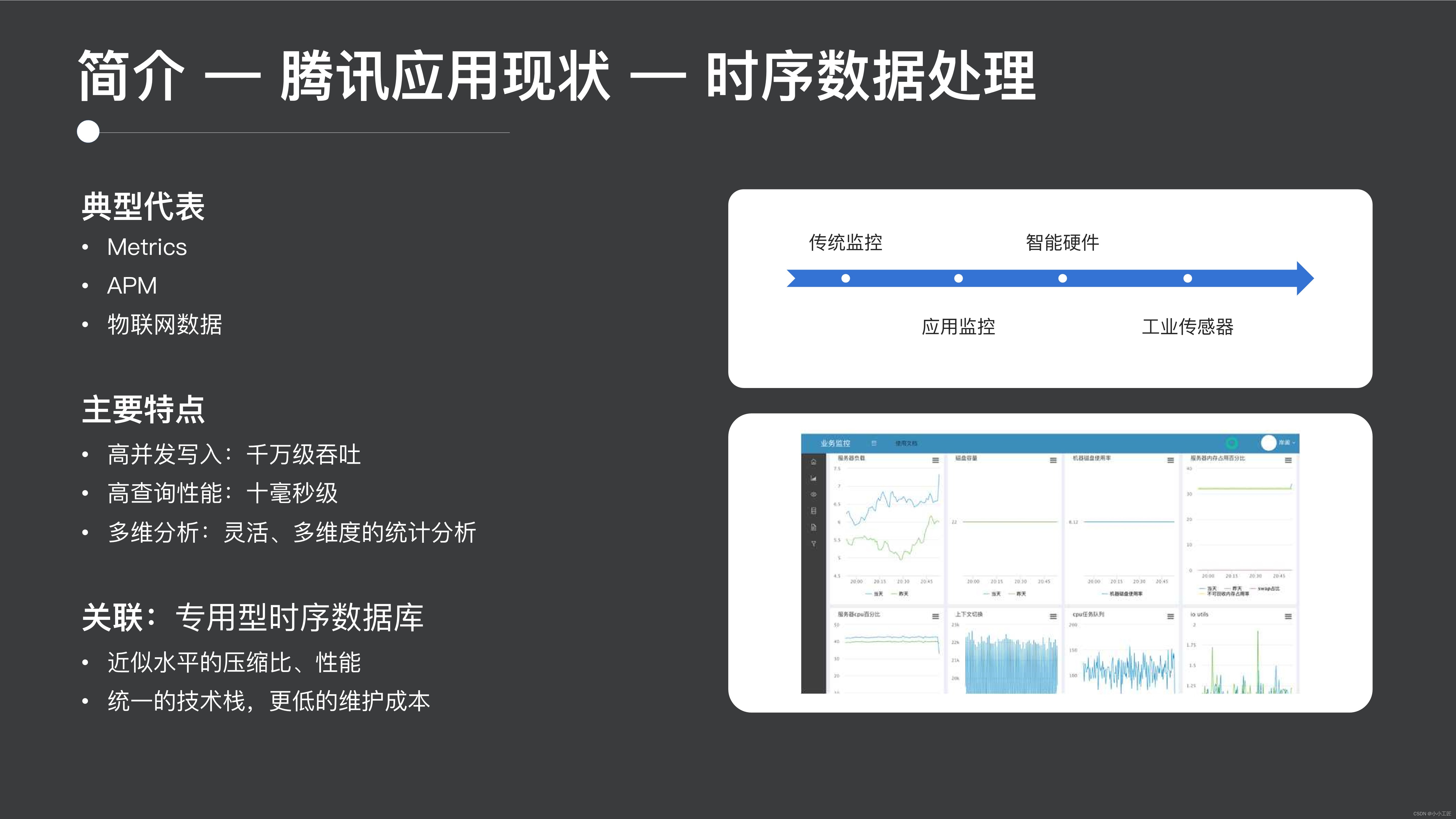
3 番目のセクションでは、時系列データのアプリケーションを見てみましょう。これも、Tencent が内部的に開始した非常に大規模なアプリケーション シナリオです。典型的なアプリケーションには、メトリクス、アプリケーション パフォーマンスの監視、および最新の IoT データが含まれます。
タイミングシーンの特徴としては以下のようなものが挙げられます。
- 非常に高いスループットが必要なため、CPU リソースの消費量が比較的多くなります。
- 2 つ目は、比較的高いクエリ パフォーマンスが必要であるということです。たとえば、通常描画される監視曲線を見ると、通常、描画に 10 ミリ秒から数十ミリ秒かかる場合があり、あまり長く遅延させることはできません。
- 3 つ目は、柔軟な多次元分析です。監視やこの種の IoT データに関しては、この種の柔軟な多次元分析機能が必要であることは明らかです。
専用の時系列データベースと比較すると、ES には、実際にこの専用のデータベースと同様の圧縮率とパフォーマンスを達成できると同時に、ユーザーの技術スタックを簡素化してユーザーの運用コストを削減できるという明らかな特徴があります。 . コスト、リソースコスト、その他の側面。
2. 技術的な課題
2 番目のセクションでは、この大規模なアプリケーション環境で発生する技術的な課題を検討します。
1. 可用性
1 つ目は可用性です。可用性はすべての分散システムに共通する問題です。どのシステムでも最初に直面するのは可用性です。可能性を無視してコストやパフォーマンスについて話すのは無意味です。そこで、可用性の問題を見てみましょう。
可用性の点で言えば、オープンソース ES は実際、初期の頃は非常に不安定で、可用性は 2/9 しかなく、動作圧力も非常に高かったです。
コミュニティ全体の開発状況からも、ES の開発ペースは非常に速いのですが、比較的バグが多いことが分かります。
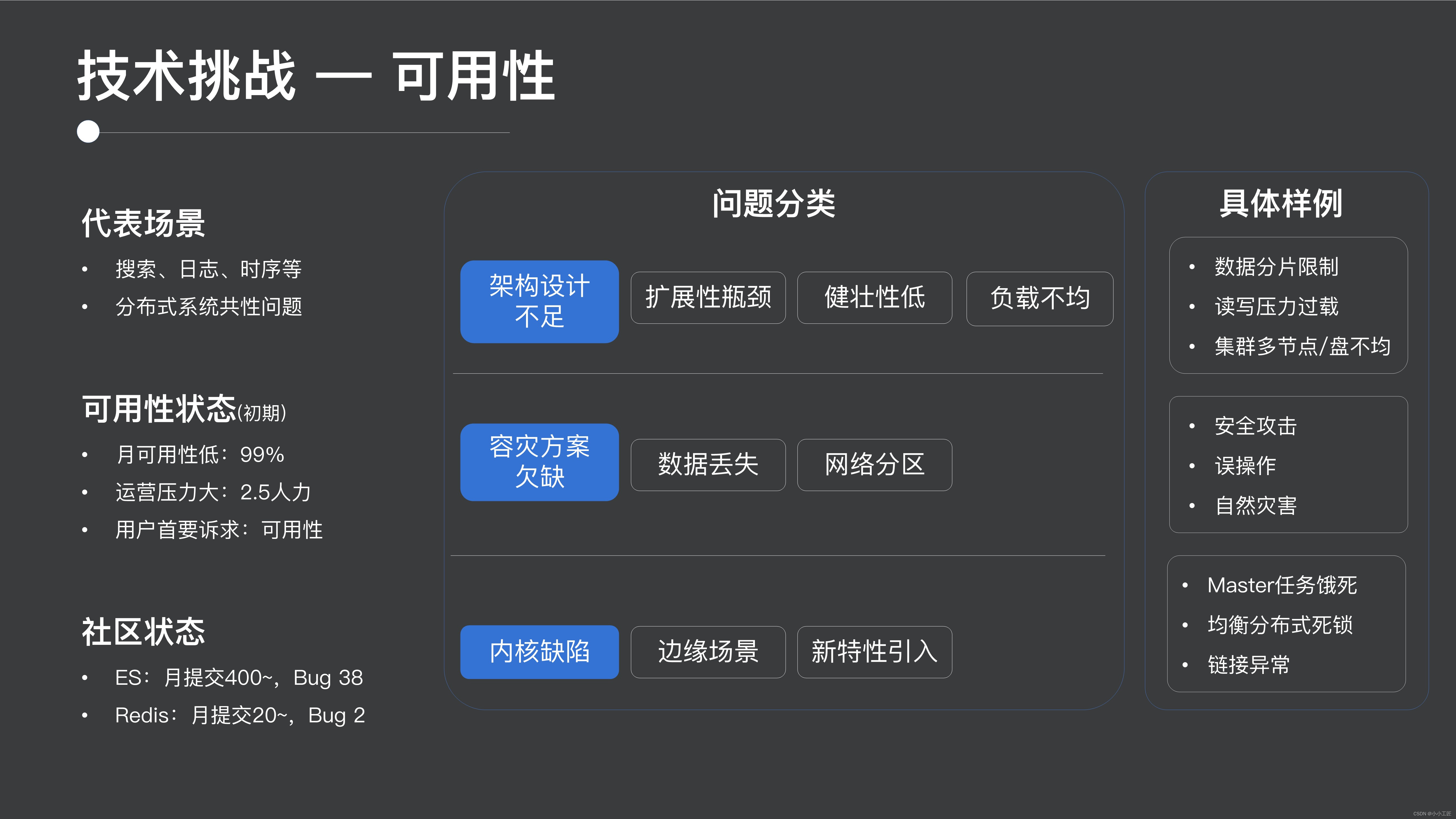
ユーザビリティの問題全体を分類すると、次のようになります。
- 1 つ目はアーキテクチャ設計の欠如であり、多数のシャード、高い読み取りおよび書き込み圧力、分散クラスタでの負荷分散など、これらは実際にはアーキテクチャ設計の内容に属します。
- 2 番目の部分では、セキュリティ攻撃、誤操作、自然災害によるデータ損失やネットワーク分断などの災害復旧ソリューションについて説明します。
- 3 番目の部分は、分散デッドロック、一部のマスター タスクの枯渇、およびこれらのエッジ シナリオまたは新機能の開発中に導入されるカーネルの欠陥です。
実は ES に対するジョークもあって、昨年かそれ以前にデータが乗っ取られたり、誤って削除されたりするシナリオがコミュニティでよく暴露されていました。実際、Mongo と ES はその典型であり、これはユーザビリティに関するものです。要件は非常に高いです。
2. コスト
2 番目の技術的課題はコストにあり、代表的なものはログとタイミングのシナリオです。
ログおよび時系列のシナリオでは、通常、数百万、さらには数千万の TPSを達成できますが、時間の蓄積により、ストレージ コストが PB レベルに達する可能性があり、これは非常に高額です。そして、ログと監視のシナリオでは、その価値が比較的低いことは誰もがはっきりと感じることができるため、全体として非常に明らかな矛盾が生じます。つまり、リソースの消費量は非常に多いのに、ビジネス価値は比較的低いということです。
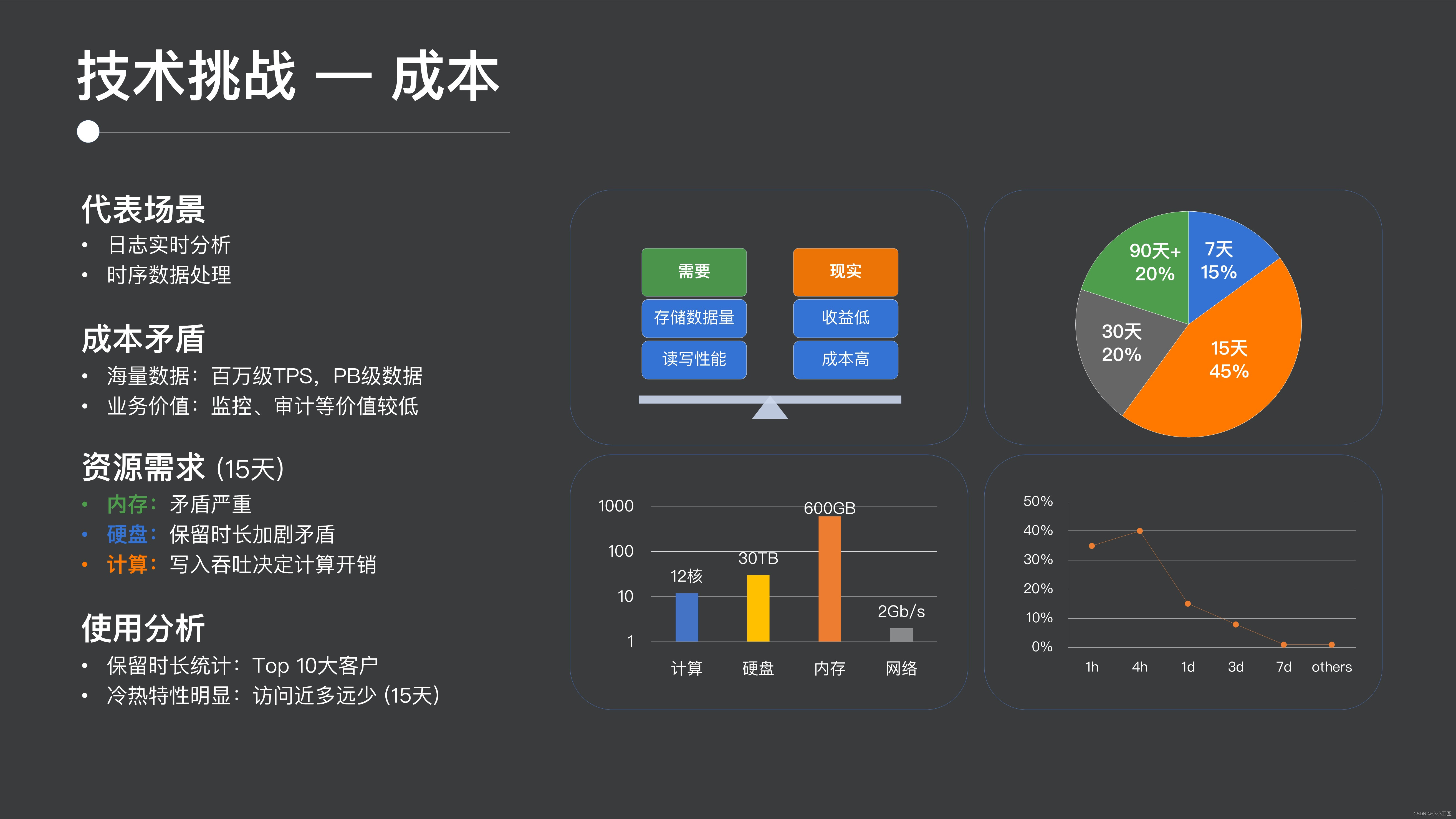
リソースがどこで消費されているかを分析してみましょう。当社の上位オンライン顧客の統計分析を実施したところ、上位顧客の約 45% は 15 日間データを保持し、ユーザーの 40% はそれよりも長期間データを保持することがわかりました。例として、資源消費の状況を見てみましょう。
通常、このタイプのシナリオでは、スタンドアロン モデルが例として使用されます。スタンドアロン マシンには、12 コアのコンピューティング リソース、30 TB のストレージ リソース、600 GB のメモリ リソース、および 2 GB/秒のネットワーク リソースが必要であると予想されます。
この比率から判断すると、メモリのボトルネックが最も顕著であり、既存の主流モデルの一部の構成を上回り、コストが最も高い箇所でもあります。2 番目はストレージ コストで、これも非常に高く、30 TB のストレージであり、ストレージ コストは時間とともに直線的に増加していることがわかります。最後に、計算コストがあります。ログ シナリオと時系列シナリオでは、履歴データへのアクセスが実際には比較的小さいことがわかります。このシナリオでは、アクセスが少なく、コストが非常に高いと感じるでしょう。プレッシャーは次のとおりです。すごく高い。
3. パフォーマンス
3 番目に注目するのはパフォーマンスの課題であり、主な代表的なシナリオは検索シナリオです。
検索シーンでは明らかな状況があり、通常は100,000 のスループット、10 秒の QPS、および低グリッチが必要です。
低グリッチの要件の主な理由は、たとえば、検索シーンのクエリの 99.5% が 100 ミリ秒未満であり、良好なユーザー エクスペリエンスを保証するためです。3つ目は「高スループット」、このような大中規模の電子商取引の検索ニーズを満たすためには、10万レベルのQPSを達成する必要がある、この3つが要件となります。

ただし、ユーザーがオープンソース ES を直接使用すると、いくつかの問題が発生します。
- まず、パフォーマンスの点で、ランダム I/O とスキャン実行速度の低下により、比較的高い遅延が発生します。
- 2 番目の側面では、ハードウェアの異常、バックグラウンド リソースのプリエンプション、GC ネットワーク ジッターなどの制御不能な要因により、ロングテールが非常に明白になります。
- 3 番目は、スループットが期待に応えられないということです。まず、単一ノードのスループットがすでに上限に達しており、クラスターのスケーラビリティがより良いレベルの線形拡張に達していません。
これら 3 つが私たちの主な課題です。
3. アーキテクチャ設計の実践
次に、これらの課題に対処するために私たちが行ったアーキテクチャの実践をいくつか見てみましょう。実際、これには多くの分散システムの設計プロセスに共通する問題も含まれています。
1. ユーザビリティの最適化
まず第一に、ユーザビリティの問題を見てみましょう。可能性の問題は実際には非常に豊富です。最初に全体的な解決策を見てから、後でいくつかの内容を紹介します。
1.1 解決策
ユーザビリティの問題は、まずアーキテクチャ設計の点で、ES は段階的に開発される新しいシステムであるため、アーキテクチャ設計におけるユーザビリティへの考慮が十分ではありませんでした。
- 最初の可用性は明らかに ES クラスターのスケーラビリティの可用性にあります。そのため、この使いやすさの面で 100,000 レベルのテーブルと 100 万レベルのシャードをサポートしました。
- その後、圧力過負荷やハードウェア障害などのシナリオにおけるクラスターの可用性の向上を建設的にサポートします。
- 3 つ目はクラスターのバランシングです。これは、クラスター内の複数のノードとノード内の複数のディスク間の圧力バランスをより適切に行うことです。
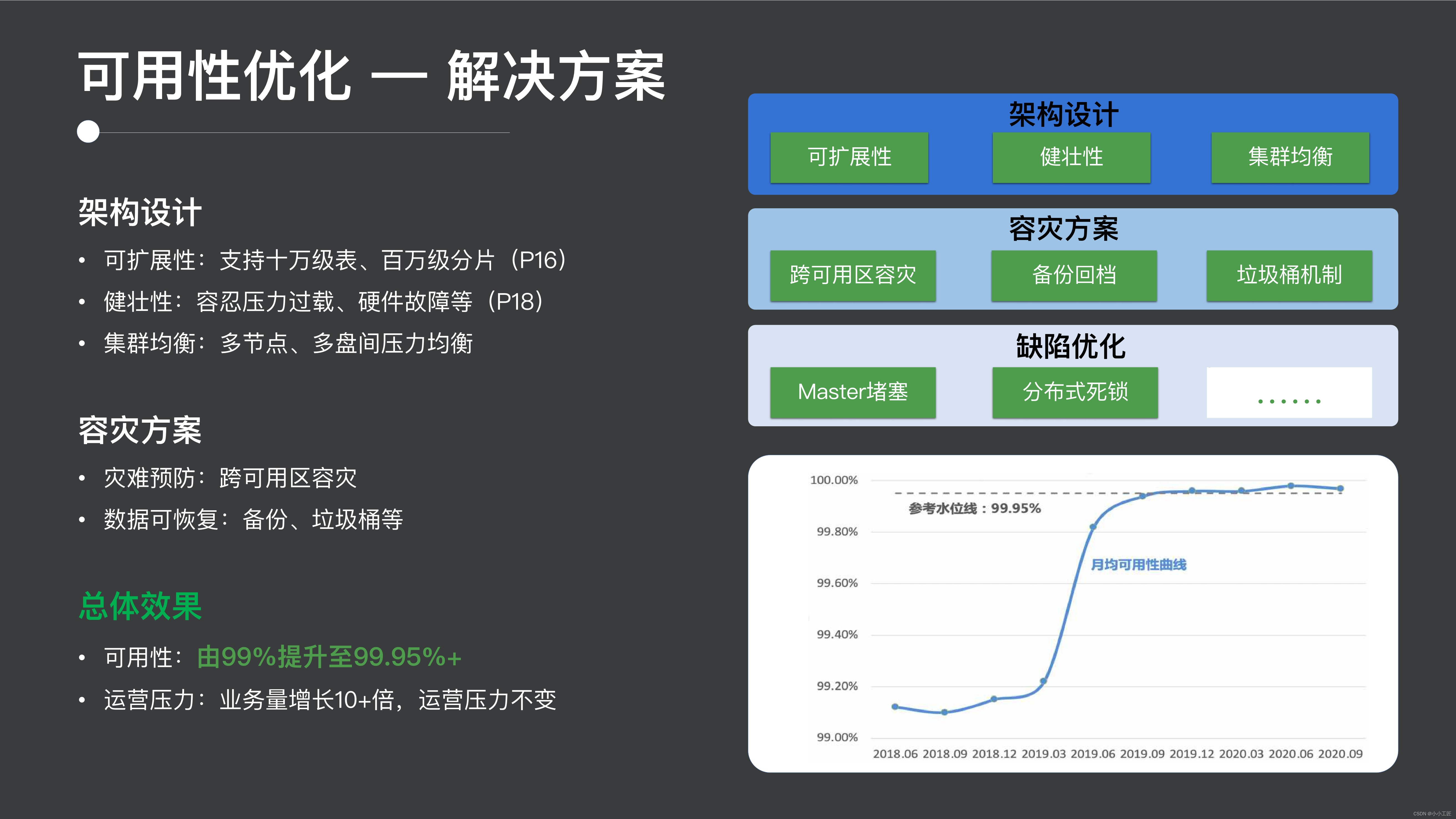
さらに、災害復旧ソリューションの欠陥を修正することでサービス全体の可用性を向上させ、最終的には可用性が 2 9 から現在の 3 9 と 1 5 に向上し、ビジネス全体が 10 倍に発展しました。 、ただし動作圧力は一定です。
2.2 クラスターのスケーラビリティ
クラスターの可用性に関するいくつかの具体的な取り組みを拡張して紹介しましょう。
1つ目はクラスタのスケーラビリティの内容です 1つ目は分散拡張のボトルネックです 実際ESのスケーラビリティのボトルネックはコミュニティでも報告されています 一方でシャーディングの拡張です 通常30,000シャードに達すると、管理操作の実行には 15 秒かかります。また、クラスターサイズが 100 ノードに達すると、いくつかの不安定な要因が現れる可能性があります。
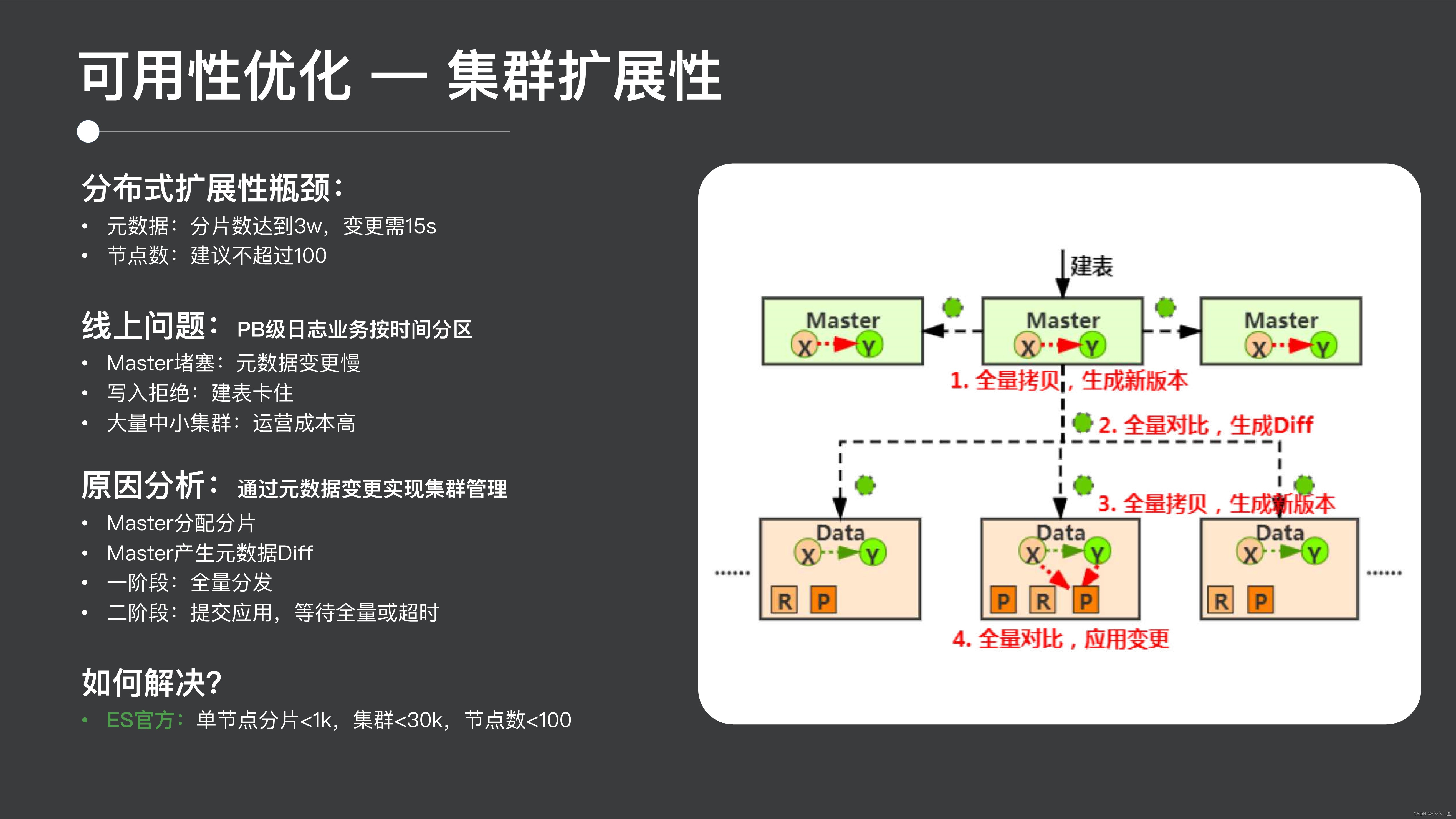
ただし、Tencent 内の一部の大規模な使用シナリオでは、これらの使用上限のボトルネックが簡単に引き起こされるため、典型的な特定のトリガー現象を解決する必要があります。
-
1 つは、たとえば、マスターがブロックされていることです。メタデータの変更が遅いため、フラグメントの作成、テーブルの作成、テーブルの削除、クラスターのバランス調整、クラスター内のノードの削除などのすべての作業が実際にはスタック状態になります。マスターはほぼ崩壊状態です。
-
もう 1 つは、テーブルの作成が書き込み拒否につながることです。ES は従来のデータベースとは異なります。ES の使用方法は、書き込み中にテーブルを構築することです。テーブルの作成がスタックすると、書き込みリクエストがメモリに蓄積されます。これにより、拒絶。コミュニティからの提案によると、クラスタを多数の中小規模のクラスタに分割して運用・保守するのが一般的ですが、この方法では運用コストが高く、リソースの利用率が高くならないというデメリットがあります。改善されました。
ES がなぜこのような強力なスケーラビリティ ボトルネックを抱えているかは、実は ES の設計に関係しており、ES はメタデータの管理を通じてクラスター全体の管理を実現します。ES にこれほど大きなスケーラビリティのボトルネックがある理由を分析して理解するために、テーブルを構築するプロセスを例に挙げてみましょう。
-
テーブル作成リクエストはクラスターのマスター ノードに送信されます。マスター ノードがリクエストを受信した後、最初に行うジョブは、元のメタデータ状態をコピーし、完全にコピーし、新しいメタデータ状態を生成して、メタデータの状態 全員がシャードを割り当てます。次に、メタデータ Diffを生成します。これは、後続のメタデータの同期と配布に使用されます。このプロセスは、実際には、新しいバージョンのメタデータと古いバージョンのメタデータの完全な比較です。
-
これに続いて、誰もがよく知っている2 段階の送信プロセスが続きます。最初の段階は配布で、すべてのノードが Diff を受信した後、古いメタデータをコピーして新しいメタデータを生成します。2 番目の段階は送信で、ノードは受信 リクエストが送信された後、古いバージョンと新しいバージョンのメタデータが比較され、変更を適用するための完全な比較プロセスが行われます。結局のところ、クラスター全体のメタデータ変更プロセスには大量のメタデータのコピーと走査が含まれており、これにより ES クラスターのメタデータ拡張機能が制限されることがわかります。
-
さらに、2 フェーズ コミット中は、すべてのノードが応答するか、タイムアウトになるまで待機する必要があるため、クラスターのスケーラビリティも制限され、この問題を解決する方法についても多くの検討を行いました。
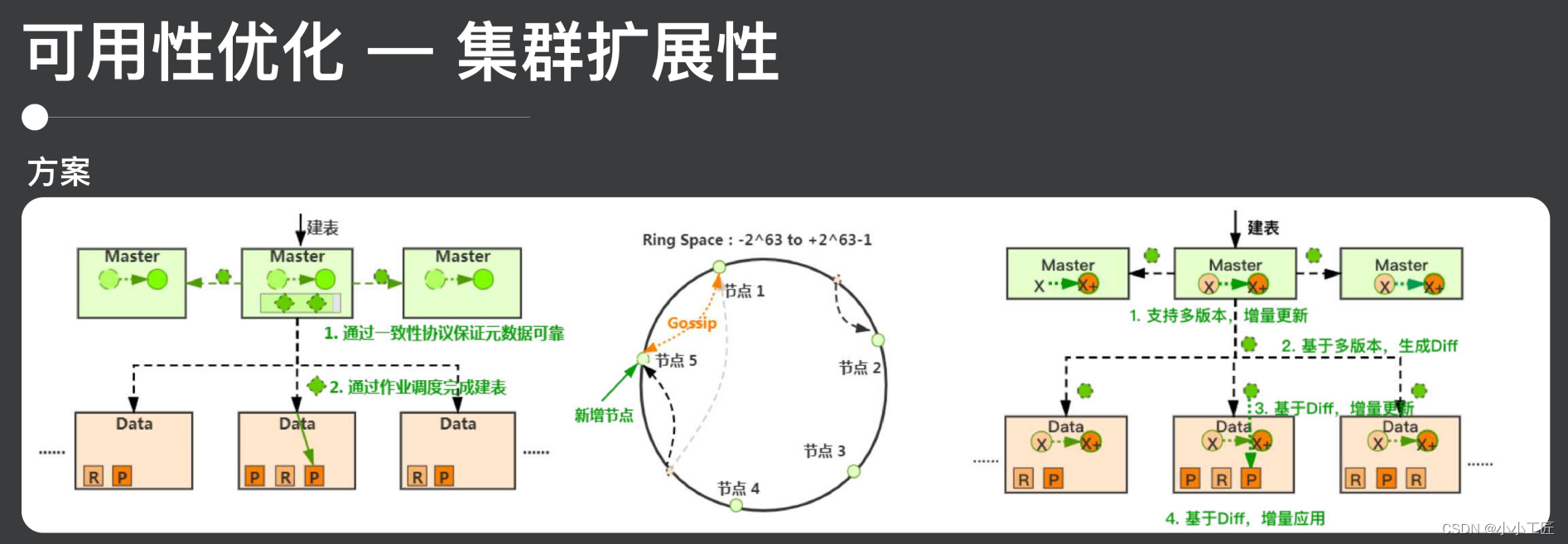
実際、業界にはクラスターのスケーラビリティの 2 つの典型的な実装があり、典型的な実装は、BigTable や Kudu などの製品に似た集中型アーキテクチャであり、HA を確保するためのプロトコルです。
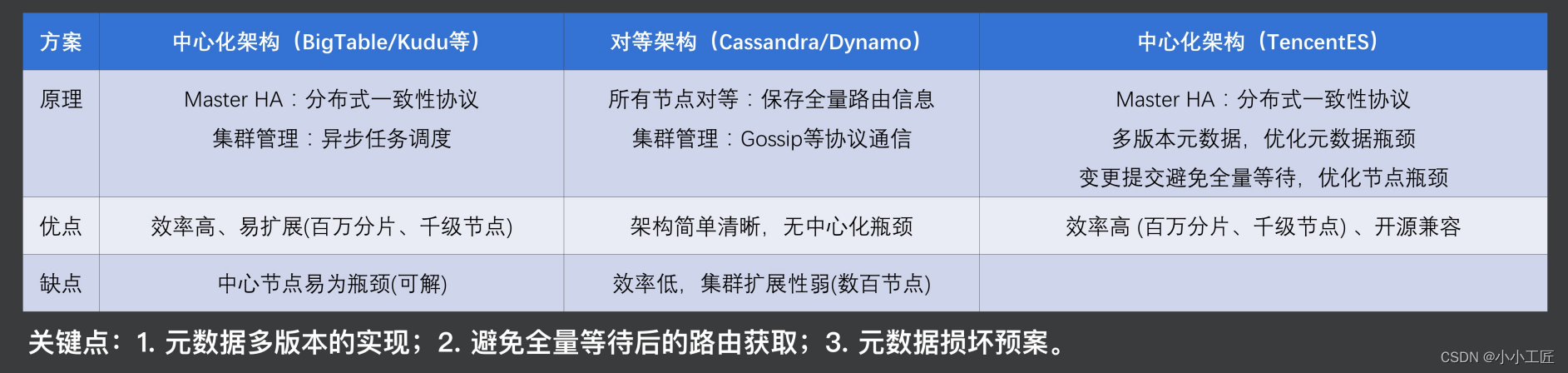
次に、クラスターの管理プロセス全体がタスクを通じて実行されます。マスターにはメタデータの変更に注意を払うための非同期タスクがあります。メタデータが変更されると、生成されたタスクは実行のために指定されたデータ ノードに送信されますこのようにして、効率が高く、拡張性も優れています。この設計方法では、セントラル ノードのマスターに比較的高いボトルネックがあるのではないかと心配されるかもしれませんが、実際には、マスターの多くのタスクをデータ ノードにオフロードして、マスター全体の負荷を軽減することができます。
2 番目の典型的なソリューションは、Cassandra や Dynamo に代表されるピアツーピア アーキテクチャで、クラスタ全体のすべてのノードが同等であり、各ノードが完全な量の情報を保持し、クラスタの変更はメタを通じて行われます。データの同期が完了し、2 つのノードが相互に通信し、最終的にクラスターの状態が一貫した状態になります。このソリューションの利点の 1 つは、アーキテクチャが比較的シンプルで明確であることですが、欠点は、このメタデータ同期の収束に時間がかかるため、このソリューションではクラスターのスケーラビリティが良くないという一般的な状況が見られることです。
ES に基づく実装スキームの 1 つは次のとおりです。ES 自体は分散アーキテクチャであるため、できることは次の 1 つです。
-
マスターは引き続き分散型コンセンサス プロトコルを通じて HA を保証します。その後、メタデータ Diff を使用して従来の集中型アーキテクチャのタスクを置き換え、メタデータ Diff がこの役割を果たします。すべてのメタデータの変更、生成、適用プロセスは Diff に基づいて完了するため、メタデータのスケーラビリティが大幅に向上します。
-
次に、メタデータ送信のプロセスでは、ノードのスケーラビリティを向上させるために、実際にはすべてのノードが応答またはタイムアウトする必要はなく、大部分のみが応答またはタイムアウトする必要があります。このようなソリューションにより、集中型アーキテクチャにおける強力な拡張性と高効率を実現するだけでなく、オープンソース ES のこれらとの互換性も実現しました。
-
ただし、この実装にはいくつかの注意点があります。1つの注意点は、複数のバージョンのメタデータを実装する方法です。実装したソリューションは Copy On Right モードです。2 つ目の注意点は、すべてのノードを待つ必要がないためです。送信、次にメタデータのルーティング情報の制御が必要で、3 つ目はメタデータの全体的な被害計画です。
2.3 堅牢なアーキテクチャ
次に、クラスターの堅牢性の観点からアーキテクチャを見てみましょう。先ほどスケーラビリティについて説明しましたが、今度は堅牢性について見てみましょう。ES は典型的な 2 層クエリ構造で、全体として、ES クエリには大規模クエリ、高同時実行ポイント クエリ、および高同時書き込みの3 つのカテゴリが含まれます。
- 大規模なクエリではメモリ リソースに対する要件が高くなるため、単一ノードのメモリが簡単に過負荷になり、その後、クラスタ内の各ノードが徐々に過負荷になってしまいます。
- 同時実行ポイントが高いクエリでは、コンピューティング リソースや I/O リソースに対する要件が比較的高く、I/O やコンピューティング リソースの競合が容易に発生し、ロングテールや拒否が発生する可能性があります。
- 高度な同時書き込みには、コンピューティングとメモリに対する高い要件があり、拒否や雪崩が発生する可能性があります。もちろん、分散クラスターにおけるハードウェア障害やネットワーク ジッターなどの一般的な問題も、サービス ジッターを引き起こす可能性があります。
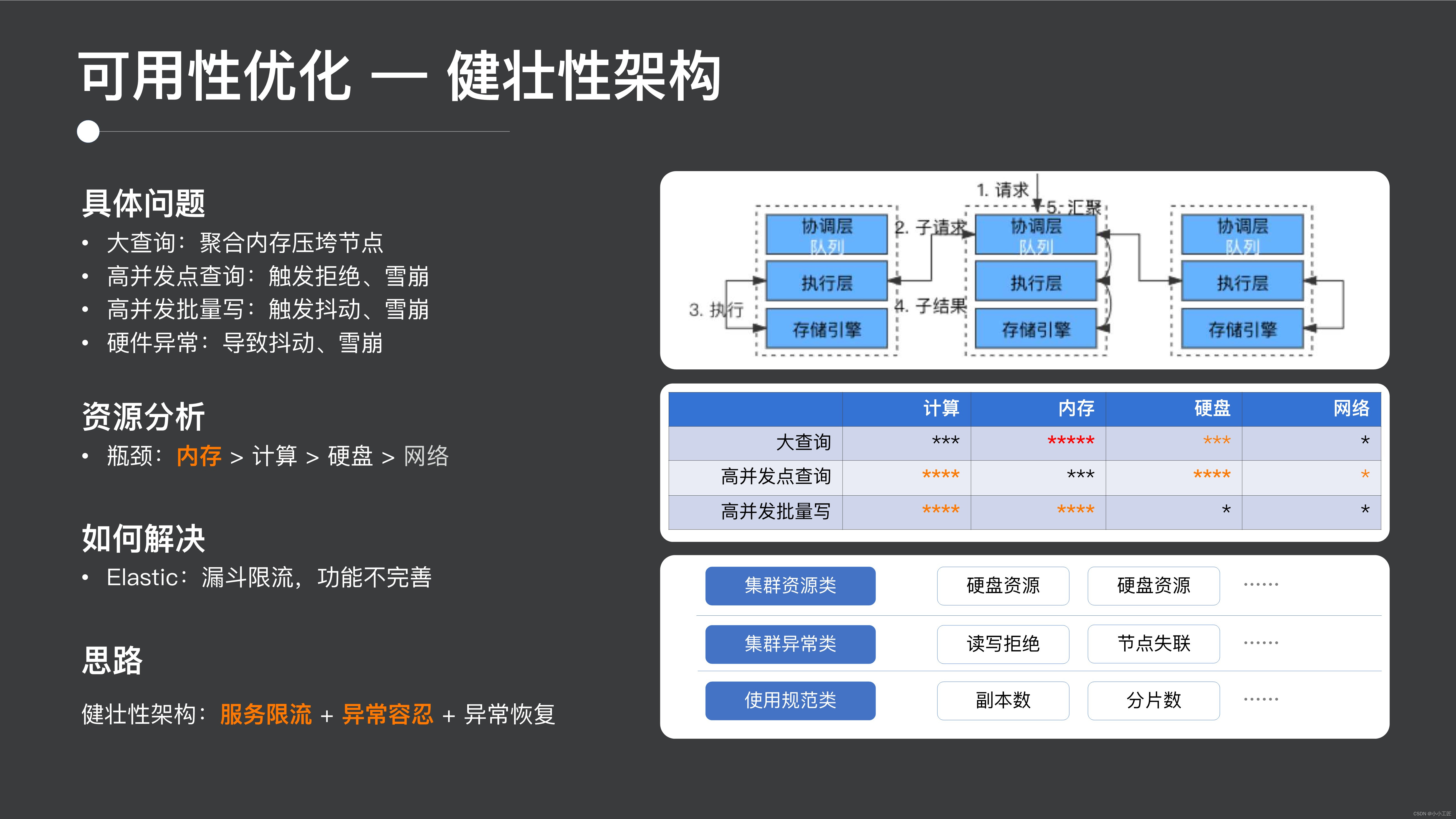
したがって、リソース全体の観点から見ると、主なボトルネックは実際にはメモリのボトルネックが最も明白で、次にコンピューティングとハードディスクのボトルネックが続きます。この問題を解決するにはどうすればよいでしょうか?
Elastic の設計では、実際にはデフォルトでファンネル電流制限のセットが提供されていますが、このファンネル電流制限の実装は比較的初歩的であり、ニーズを満たすことができません。私たちの実装アイデアの 1 つは、まずサービス フローの制限によってクラスター全体の安定性を確保し、次に例外耐性のあるアーキテクチャ設計を通じて安定したサービスを提供することで、応答レベルが比較的安定した状態を維持することです。
2.3.1 サービス電流制限
クラスターの安定性を確保するための堅牢なアーキテクチャの観点から、サービス フローの制限を見てみましょう。
実際、業界にはサービス電流制限に関して 2 種類の一般的な実装ソリューションがあります。
-
1 つはプロキシのような電流制限方法で、ルール エンジンを使用して電流を制限します。この方法は、高同時実行ポイント クエリ モードにより適しており、マイクロサービスなどのシナリオに適していますが、ES などの大規模なクエリ シナリオにも適しています。あまり満足していません。
-
2 番目のタイプはビッグ データ シナリオで、通常よく見られる MapReduce または Hadoop シナリオで表されるタスク コンテナーの現在の制限がYarn によって実装されます。各タスクは実行前にコンテナーを生成します。このタスクをコンテナー内で実行します。このアプローチの利点は、他のリクエストに影響を与えることなく、各タスクのリソース使用量を正確に制御できることです。しかし問題は、コンテナ全体の割り当てに非常に時間がかかり、ES での小規模なクエリには適していないことです。もう 1 つは、このように、通常、コンピューティング リソースの使用率は高くありません。
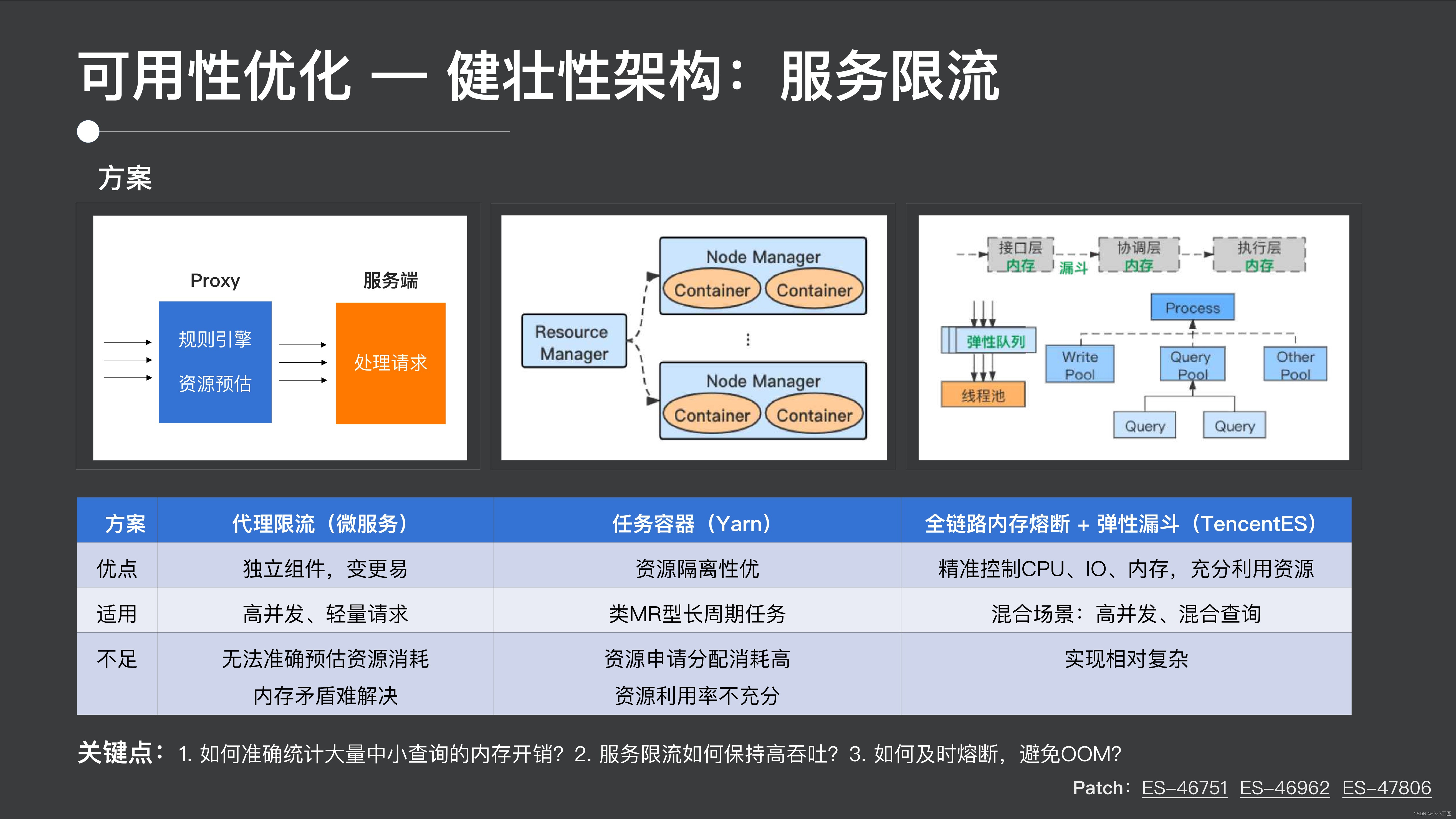
そこで、ES に独自のスキームのセットを実装しました。このスキームの主な設計ロジックは、フル メモリの融合と電流制限、およびエラスティック ファネルです。
- フルメモリ融合と電流制限とは、リクエストエントリ調整層と実行層でメモリ融合を行い、一般に各プロセスの全体メモリと各リクエストレベルのメモリ制限を制限することを意味します。
- さらに、エラスティック キューを導入することで、CPU と I/O のプリエンプションをある程度軽減でき、エラスティック キューのサポートにより、特定の読み取りおよび書き込みの不具合を許容できます。
ただし、この実装にはいくつかの重要なポイントがあります。
- 1 つ目は、多数の中小規模のクエリのメモリを正確にカウントする方法です。まず、Java 言語では、JOM を使用してプロセス全体のメモリを取得でき、一部のクエリについては、クリティカル パス上の大きなブロックのメモリ割り当てをカウントできます。
- 2 つ目はサービス電流制限です。高スループットを確保するにはどうすればよいでしょうか? これを実現する 1 つの方法は、スムーズな電流制限を通じて、無制限の流れの条件下でクラスター全体のスループットが依然として最高レベルに近いことを保証することです。
- 3 番目は、大規模なクエリによって発生する OOM を回避する方法。このプロセス中に、OOM を適時に検出する必要があります。たとえば、私たちの実践の 1 つである集約プロセスでは、集約バケットの生成プロセスを深く掘り下げて、勾配サーキット ブレーカーと電流リミッターを実行します。
2.3.2 例外耐性
クラスターの堅牢性アーキテクチャを導入した後、例外耐性を導入しましょう。クラスターの堅牢なアーキテクチャによりクラスターの安定性と信頼性が保証され、例外耐性により信頼性の低いクラスターでも信頼性の高いサービスを提供できます。
オンライン問題の具体例としては、ログとタイミングのシナリオなどがありますが、この 100 万レベルの TPS シナリオは拒否を引き起こしやすく、クラスターのリソース使用率が高くないという現象が観察されました。もう 1 つは、検索やその他のシナリオ向けの 100,000 レベルの QPS です。ロングテール クエリが非常に明白であり、多くのクエリが第 2 レベル以上の標準に達しており、ユーザー エクスペリエンスに非常に悪影響を及ぼしていることが観察されています。その理由は?
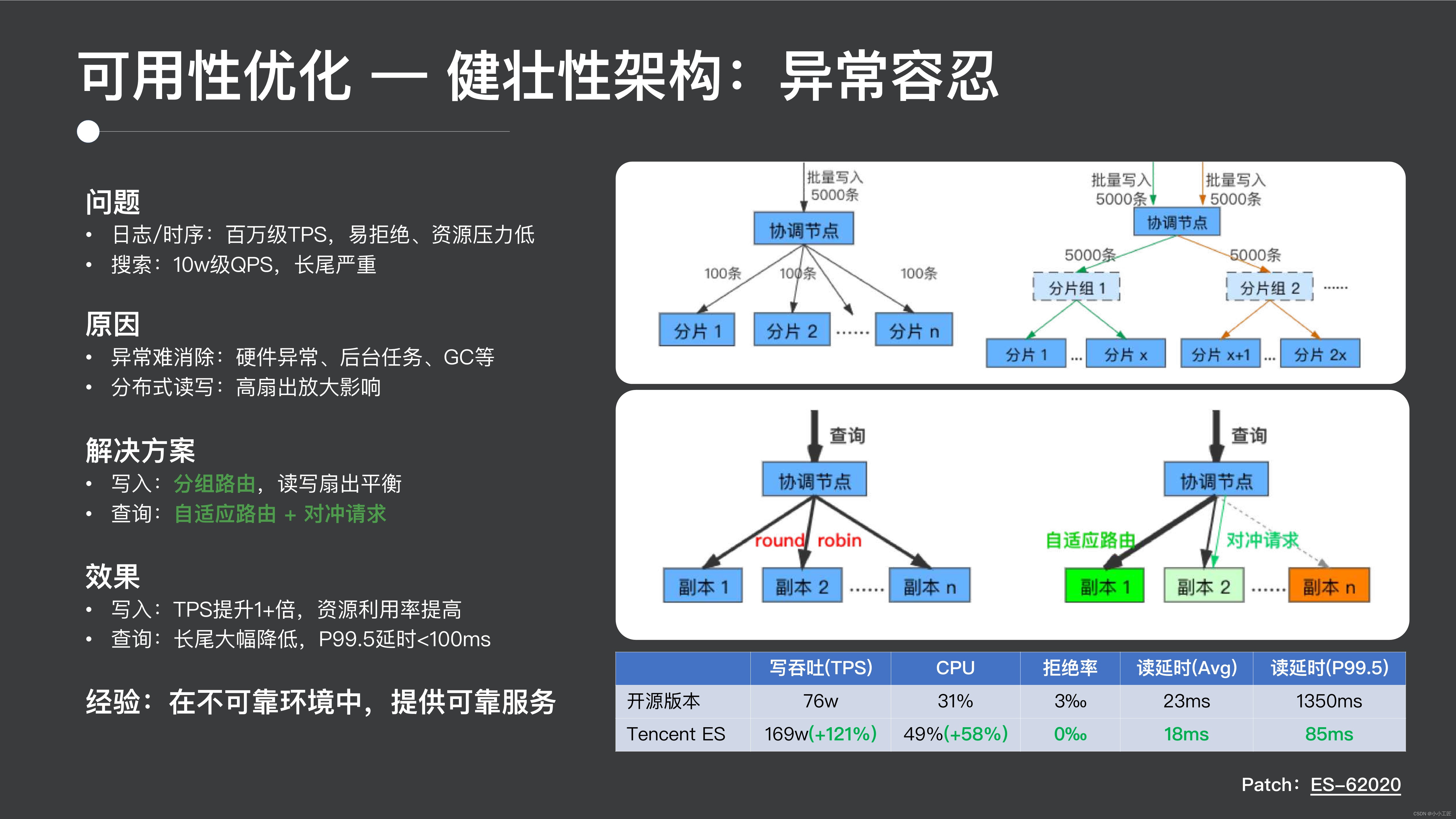
実際、分散シナリオでは、マシンの異常、ネットワークのジッター、GC、リソースのバックグラウンド タスクのプリエンプションなどの異常を排除するのが難しい一方で、実際には分散システムの異常です。これらの異常を徹底的に解決することは困難です. ファンアウトの高い分散システムの場合、分散読み取りおよび書き込みにより異常の影響が増幅されます. たとえば、1 回のリクエストで 100 個のシャードにアクセスする場合、シャードがノードが遅い場合、リクエスト全体がロングテールを待つ必要があり、その結果、サービス エクスペリエンスが低下します。
私たちがここで行っていることの 1 つは、
-
書き込みシナリオでは、グループ ルーティングを実装しました。たとえば、元の書き込みでは、各書き込みリクエストが 100 個のシャードに送信されます。シャードをグループ化し、特定の各シャードをグループに入れます。グループ内にランダムなルートを書き込みます。次に、このグループでは、データ自体の特性に応じてハッシュ ルーティングを実行することで、ファンアウトを大幅に削減し、ロング テールの影響を回避できます。同時に、分散クラスター全体の機能を活用するために、書き込みの異なるバッチが異なるグループに書き込まれます。
-
一方では、クエリについては、この種の適応ルーティングを導入しました。通常、ほとんどの分散システムの実装では、リクエストを送信するデータのコピーがランダムに選択されます。これを行う 1 つの方法は、最近の時間ウィンドウで統計を作成し、それに応じて最も適切な時間ウィンドウにリクエストを送信することです。のコピーにある統計情報に。
-
さらに、ヘッジ リクエストを導入しました。たとえば、リクエストに 100 のフラグメントが必要な場合、個々のフラグメントが遅いリクエストや遅いクエリになることを避けるのは困難です。これを行う 1 つの方法は、最後に少数のコピーにアクセスすることです。ヘッジ リクエストまたはバックアップ リクエストを開始でき、最初に戻った方がレスポンスの結果になります。このようにして、ロング テールの影響は大幅に軽減されます。
この実装の最終的な効果は、書き込みの場合、TPS が 2 倍になり、リソース使用率が着実に増加し、クエリの場合、不具合が 10 分の 1 に減少し、100 ミリ秒未満になったことです。
実際に、信頼性の低い環境で信頼性の高いサービスを構築した経験を次に示します。
2. コストの最適化
ユーザビリティを紹介した後は、コストの最適化について見てみましょう。
2.1 解決策
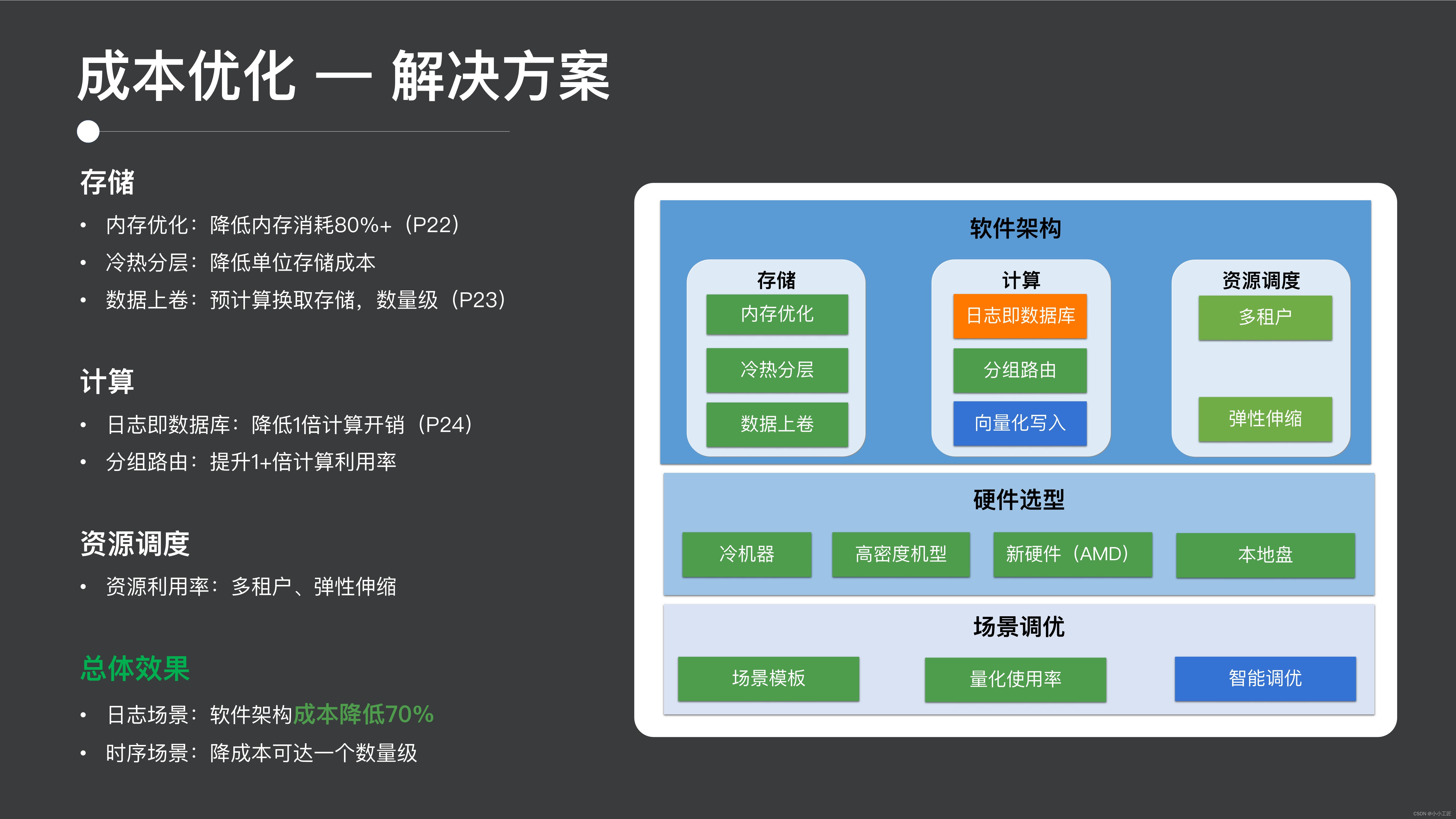
コストの点では、私たちの主なボトルネックはすでに紹介しましたが、一方で、それはメモリ、ストレージ、コンピューティングの次元にあるため、私たちが行っている作業の一部は
- まず、メモリ レベルでメモリを最適化し、メモリの利用効率を向上させます。
- 次に、ハードディスク ストレージについては、ユーザー コストを削減するために、コールド層とホット層、およびデータ ロールアップを作成しました。
- コンピューティングに関しては、データベースとしてのログ ソリューションを通じて書き込みのオーバーヘッドを削減し、同時にパケット ルーティングを通じてリソースの使用率を向上させます。
- もちろん、リソースのスケジューリング、マルチテナント、柔軟なスケーリングを通じて、全体的なリソース使用率も向上します。
最終的な効果は、ログ シナリオのソフトウェア アーキテクチャだけでコストを 70% 削減でき、このハードウェアの選択とリソースの最適化を組み合わせることで、コストを 1 桁削減できます。
2.2 メモリの最適化
次に、コスト最適化作業をいくつか紹介してみましょう。1 つ目はメモリの最適化です。ES のメモリ消費量は非常に高くなります。これは主に、ES が初期の検索シナリオに使用されていたため、パフォーマンスを非常に考慮し、インデックスをメモリに保持するためです。これは、タイミングとログのシナリオでは異なります。履歴データはめったにアクセスされず、一部のフィールドはあまりアクセスされない可能性があります。このような大量のデータを含むすべてのインデックスをメモリに置くと、実際には大量のメモリが消費されます。
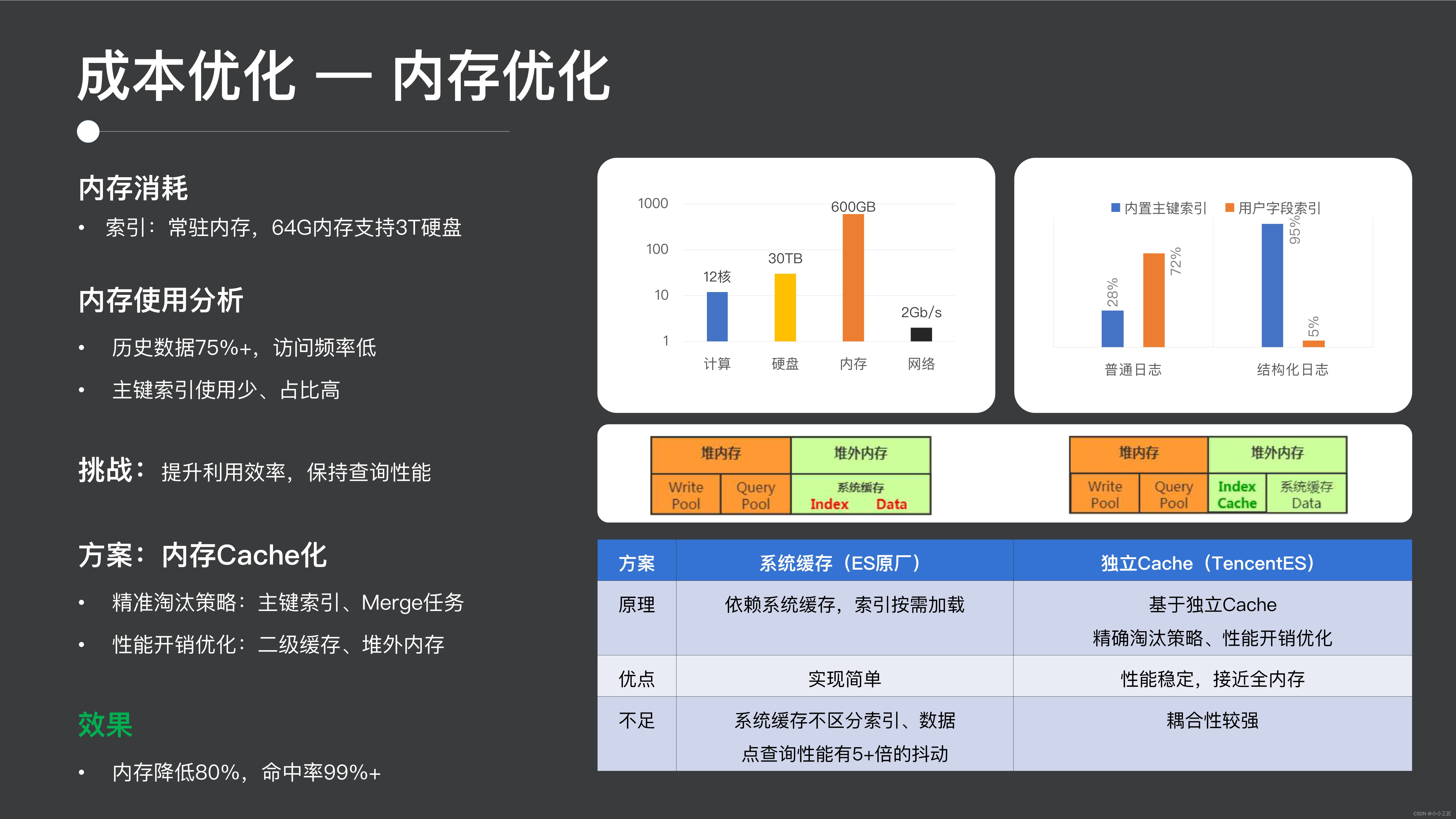
したがって、ここで非常に重要な点は、実際にはメモリ使用効率を向上させることですが、クエリのパフォーマンスを維持することに注意を払うことです。ES コミュニティはこの分野でいくつかの取り組みを行っており、その解決策の 1 つは、クエリの作成プロセス中にインデックスがオンデマンドでロードされ、システム キャッシュに配置されることです。ただし、このソリューションの欠点は、システム キャッシュがインデックスとデータを区別しないため、大規模なクエリによってシステム キャッシュがフラッシュされると、フォローアップ全体でクエリ ジッターが発生することです。
ここでは、独立したキャッシュを使用してこの作業。一方で、正確なキャッシュ ヒット率を最適化しました。たとえば、主キー インデックスがアクセスされない場合、キャッシュに入れることはできません。このプロセスでは、履歴データのインデックスを積極的に削除して、インデックス全体のメモリ使用効率を向上させます。次に、インデックスのパフォーマンスも最適化しました。たとえば、複数のキャッシュ ルックアップを複数のクエリ間で共有できるため、キャッシュの場所をヒープの外に移動しました。Java 言語でキャッシュの場所をヒープの外に配置すると、 Java GC の影響が軽減され、パフォーマンスが向上します。
最終的な効果は、メモリ使用率が 80% 増加したにもかかわらず、パフォーマンスは基本的に変わらず、キャッシュのヒット率は 99% 以上です。主な理由は、ネイティブ ES がメモリ使用率の点で比較的弱いことです。
2.3 データ ロールアップ: コンピューティング代替ストレージ
2 番目の部分はコストの最適化であり、データのロールアップにあります。実際、この監視シナリオでは、この種の需要は当然です。つまり、履歴データと監視シナリオでは半年以上データを保存する必要があり、同時に高いクエリ パフォーマンスが必要です。典型的なアプローチは、事前計算を通じてコストを交換することです。事前に時間またはその他のディメンションごとにデータを集計できます。集計後は、コストが大幅に下がります。
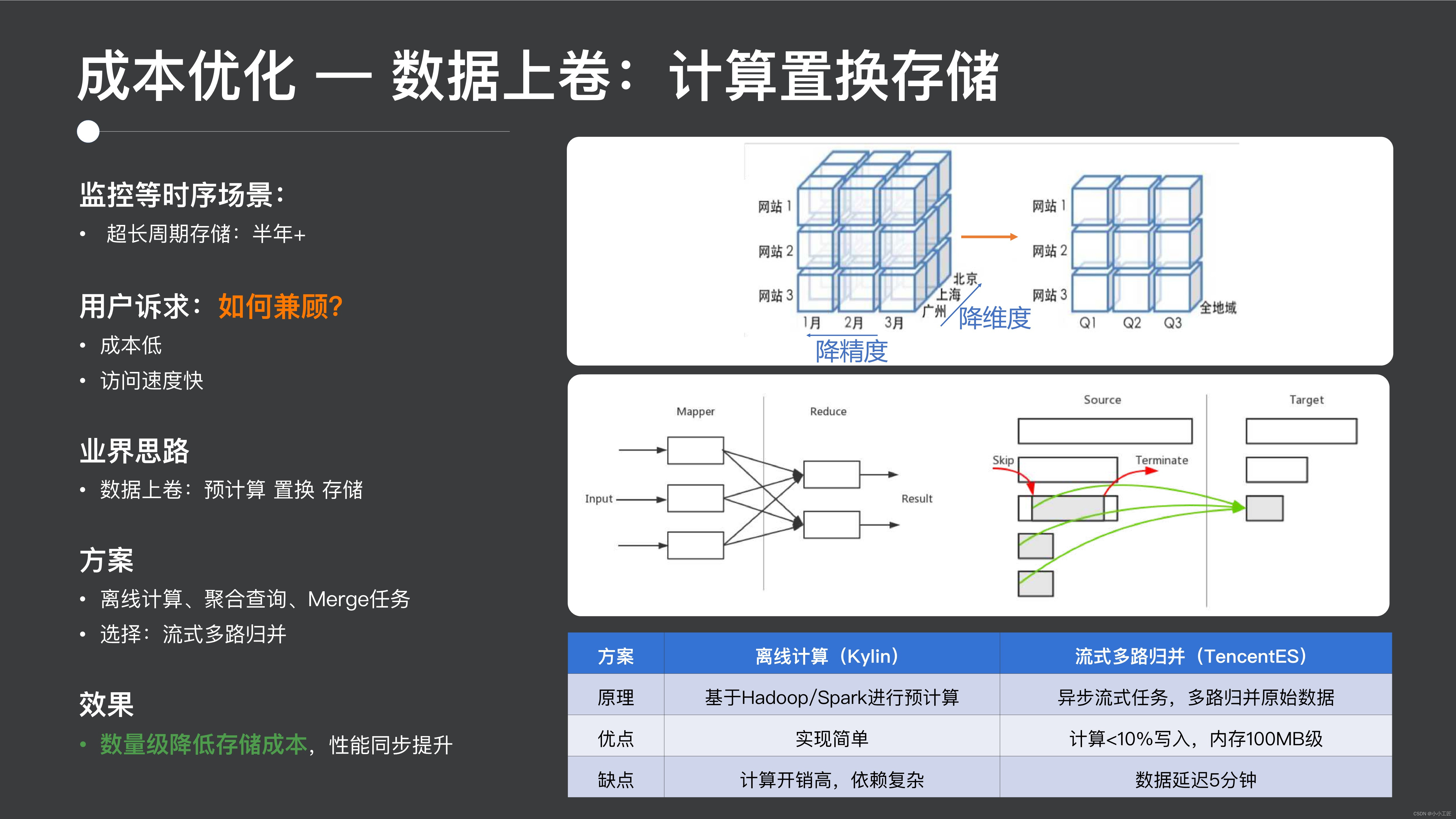
ここでは、いくつかの代表的なスキームの比較を紹介します. いくつかの代表的なスキームは、複雑で計算コストが高い Hadoop のオフライン コンピューティング手法に依存しています; 他の手法 (集計クエリ、集計クエリなど) は、基数の場合メモリバーストを起こしやすいため、Mergeタスクなどの方法もあります。Mergeの処理では、最下層がデータの強さを利用してデータをロールアップする計算処理を完了させますが、この方法は冗長テーブルのストレージ。
私たちが採用する解決策は、ES の基礎となるデータに対してストリーミング タスク スケジューリングを使用して、マルチウェイ マージを実行してこのプロセスを完了することであり、冗長テーブルの書き込みはありません。計算全体で書き込みに使用されるメモリは 10% のみであり、非常に制御しやすく、リアルタイム データのみに基づくとデータ遅延は 5 分の増加に相当し、ユーザー エクスペリエンスにとって非常に優れています。
2.4 ログはデータベースです
ログはデータベースです。Log as Database は実際には非常に革新的な設計であり、ほとんどの分散システムではマスター/スレーブ レプリカの設計が行われており、データの一貫性を確保します。ただし、ログ シナリオと時系列シナリオでは、データの適時性に対する一貫性要件が比較的低いため、実際には一定の違いがあります。
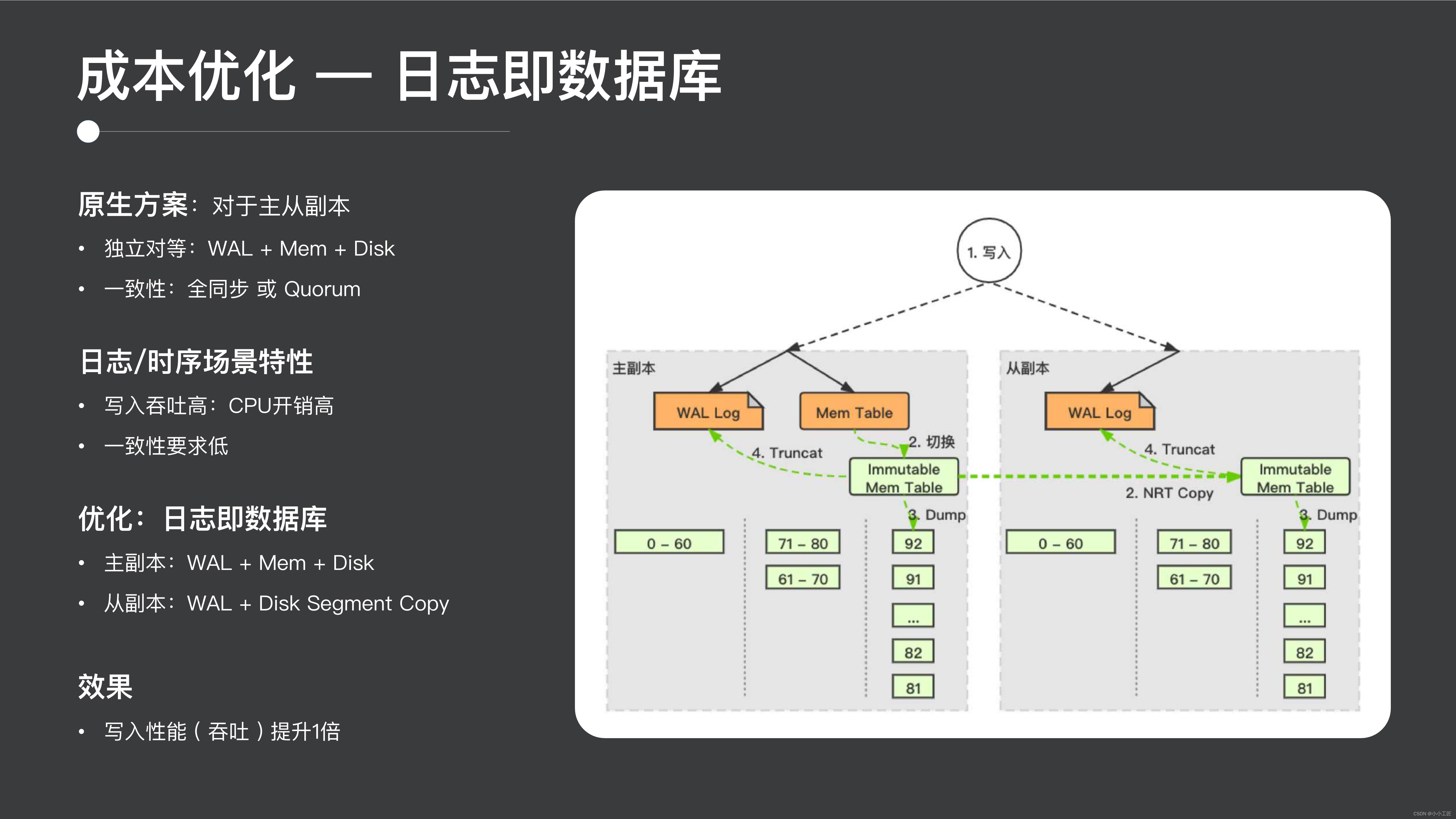
したがって、ここで実行できる非常に優れた最適化は、データベースとしてのログの概念です。プライマリ シャードでは、通常、分散システム設計の一貫性を保ち、セカンダリ シャードでは、プライマリ シャードからデータ ファイルを取得して read を提供するための高い信頼性と周期性を確保するためにログを書き込みます。これにより、書き込み速度が 2 倍になり、書き込み全体のスループットが 2 倍になり、非常に良い効果が得られます。
3. パフォーマンスの最適化
最後に、パフォーマンスの最適化について見てみましょう。パフォーマンスの最適化に関しては、ES 全体のストレージ層からエグゼキューター、オプティマイザーに至るまで、実際に多くの作業を行ってきました。
3.1 解決策
- ストレージ層については、主に時系列マージを実行して、基盤となる小さなファイルを削減し、I/O を最適化します。前述したように、この種のデータ ロールアップ作業によりパフォーマンスが向上します。
- たとえば、前述のヘッジ クエリやファイル クリッピングなどのエグゼキュータに関しては、オープンソース コミュニティにフィードバックしたパッチもいくつかあります。
- オプティマイザーに関しては、たとえば RBO (ルールベースの最適化) の最適化、その後のパーティションのプルーニングなどが挙げられます。
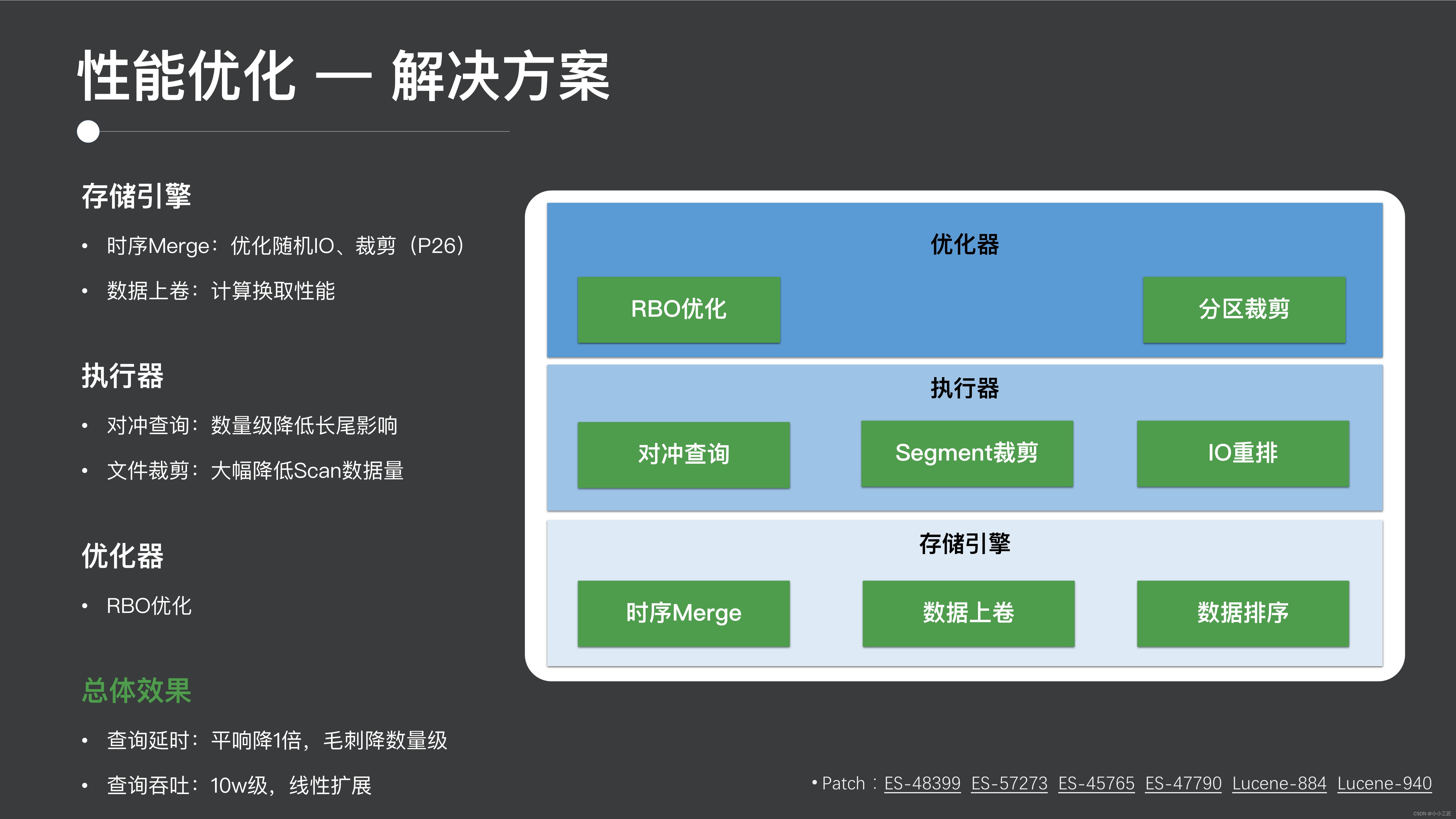
全体的な最終的な効果は、この検索シナリオではパフォーマンスが 2 倍になり、グリッチが 1 桁減少し、クラスター全体の線形拡張が非常に良好になることです。
3.2 タイミングマージ
ここではマージ戦略を紹介します。ここでは、時系列マージと呼ばれる新しい種類のマージを実際のシーンに実際に導入します。ES の従来の Merge は、実際にはサイズと効率を考慮した典型的な Merge であり、同じようなサイズのファイルをまとめて単一ファイルのサイズの上限を制限しようとします。この方法の欠点の 1 つは、基礎となるファイルが 30 個と比較的多く存在するため、分析に多くの I/O が関係することです。
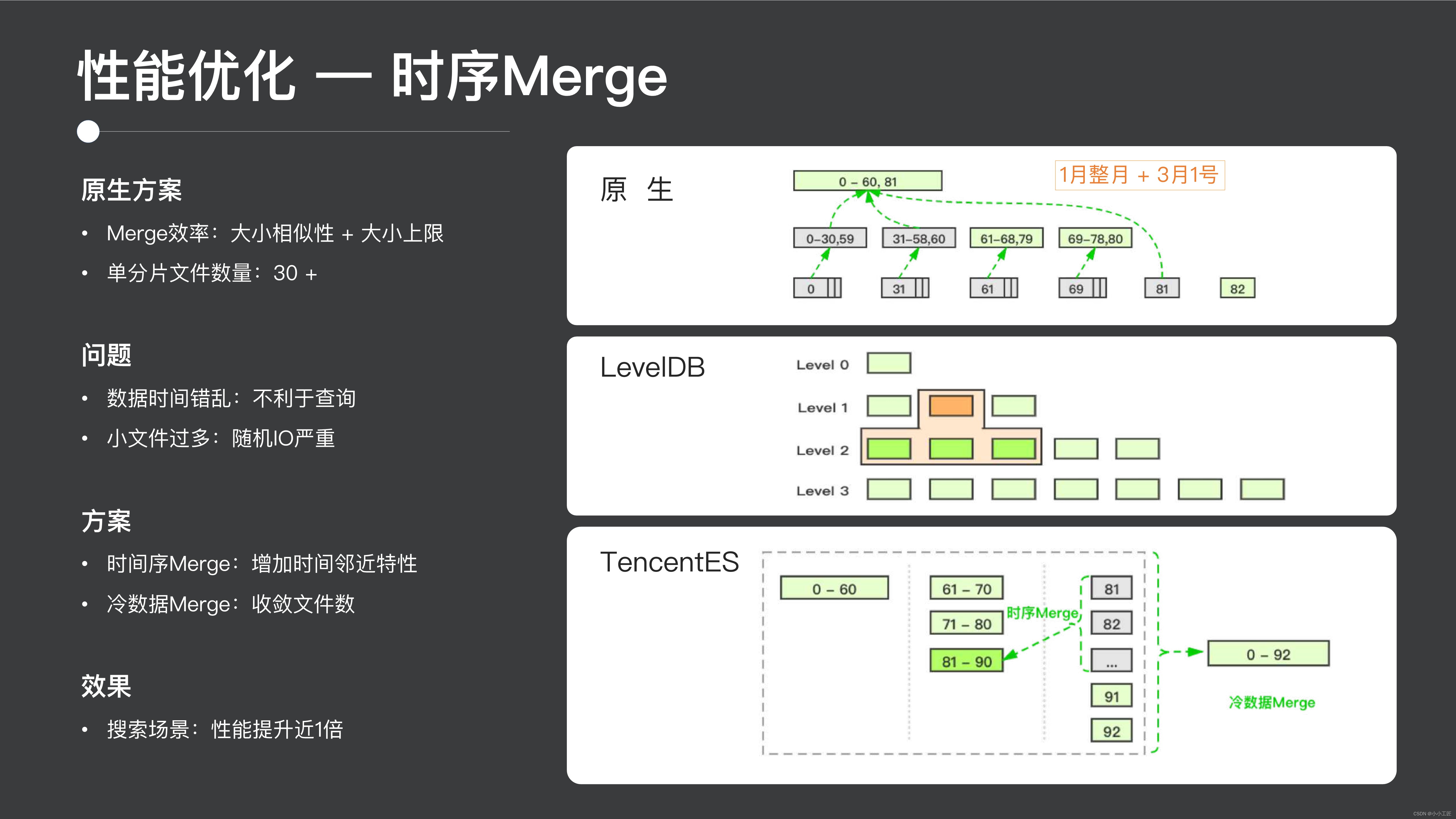
一方、基になるデータ ファイルの時間は連続していないため、1 つのファイルに 1 月全体のデータと 3 月 1 日のデータが含まれる可能性があるため、この時点で 3 月初めのデータをクエリすると、 , 問題の 1 つは、多数の基になるファイルをスキャンする必要があるため、トリミングが困難になることです。オープン ソース コミュニティには、このようなマージ ソリューションが多数あります。その典型的な例は LevelDB です。LevelDB の最下層には、独自のマージ戦略 (コンパクト戦略) も実装されています。データは生成時にレベル0に配置され、レベル0のレベルまたは下位レベルのファイル数に応じて上位レベルから下位レベルにデータがマージされ、最終的にデータ全体の管理が実現されます。 。
このモードは、この種のポイント クエリまたは QV システムに非常に適しています。これらのファイルの特定のインデックス情報がメモリに保存されるため、ポイント クエリを実行するときに、インデックス情報に従って迅速にカットできます。スキャンする必要がある 結果を返せるファイルが少なくなります。しかし、これは実際には ES には適していません。ES は通常、より多くのデータを読み取る必要があるため、最下層で非常に多くのファイルをスキャンする必要があり、小さなファイルが多すぎるため、時系列マージ ソリューションを導入しました。
大まかな考え方としては、まず同一ファイル内のデータに相当するESの階層的なMergeに基づいた時系列の概念を導入し、全員が切り取れる限り連続した時間が必要となる。もう 1 つの側面は、コールド データのマージ、ログ、時系列データを実行することです。何日も前のデータは実際にはアクセスしにくいため、ファイル数を統合してパフォーマンスを向上させることができます。**最終的に、タイミング マージの効果は、製品のパフォーマンスが基本的に 2 倍になるということです。
4. まとめと今後の予定
先ほどたくさんの内容を紹介しましたが、簡単にまとめてみましょう。
1. 現状の概要
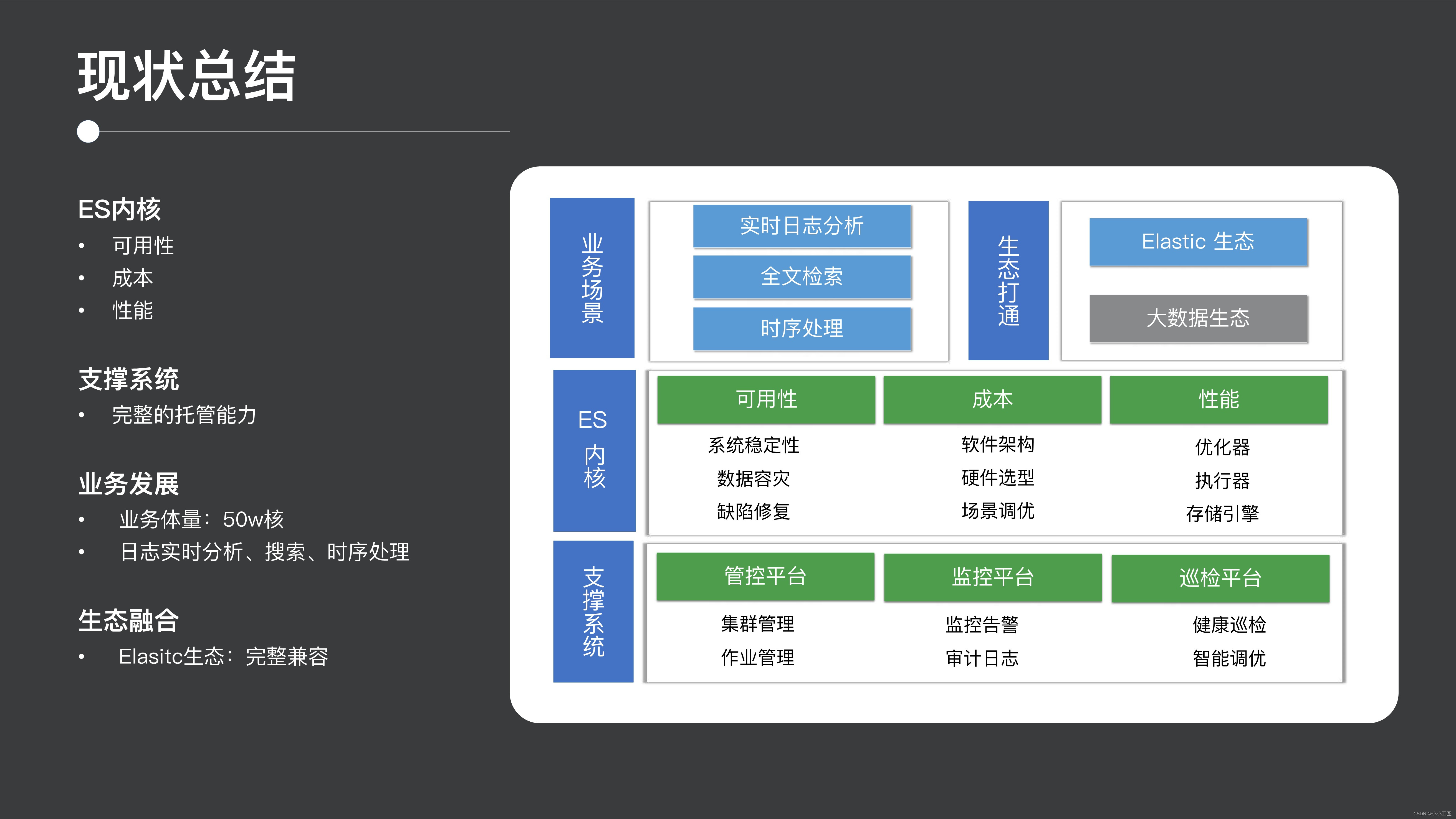
現状から判断すると、私たちは ES の可用性、コスト、パフォーマンス全体について多くの最適化を行っており、コミュニティ全体でも主導的な立場にあります。次に、クラスターの管理、制御、ホスティングの観点から、クラスターの管理と制御の操作、監視、検査のための豊富なプラットフォームを含む、成熟したホスティング プラットフォームも提供します。
また、現在のビジネス開発も非常に早い段階に達しており、ログのリアルタイム分析、全文検索、時系列処理などのプロセスをサポートしており、公式の Elastic エコシステムとの互換性も良好です。
2. 今後の展開
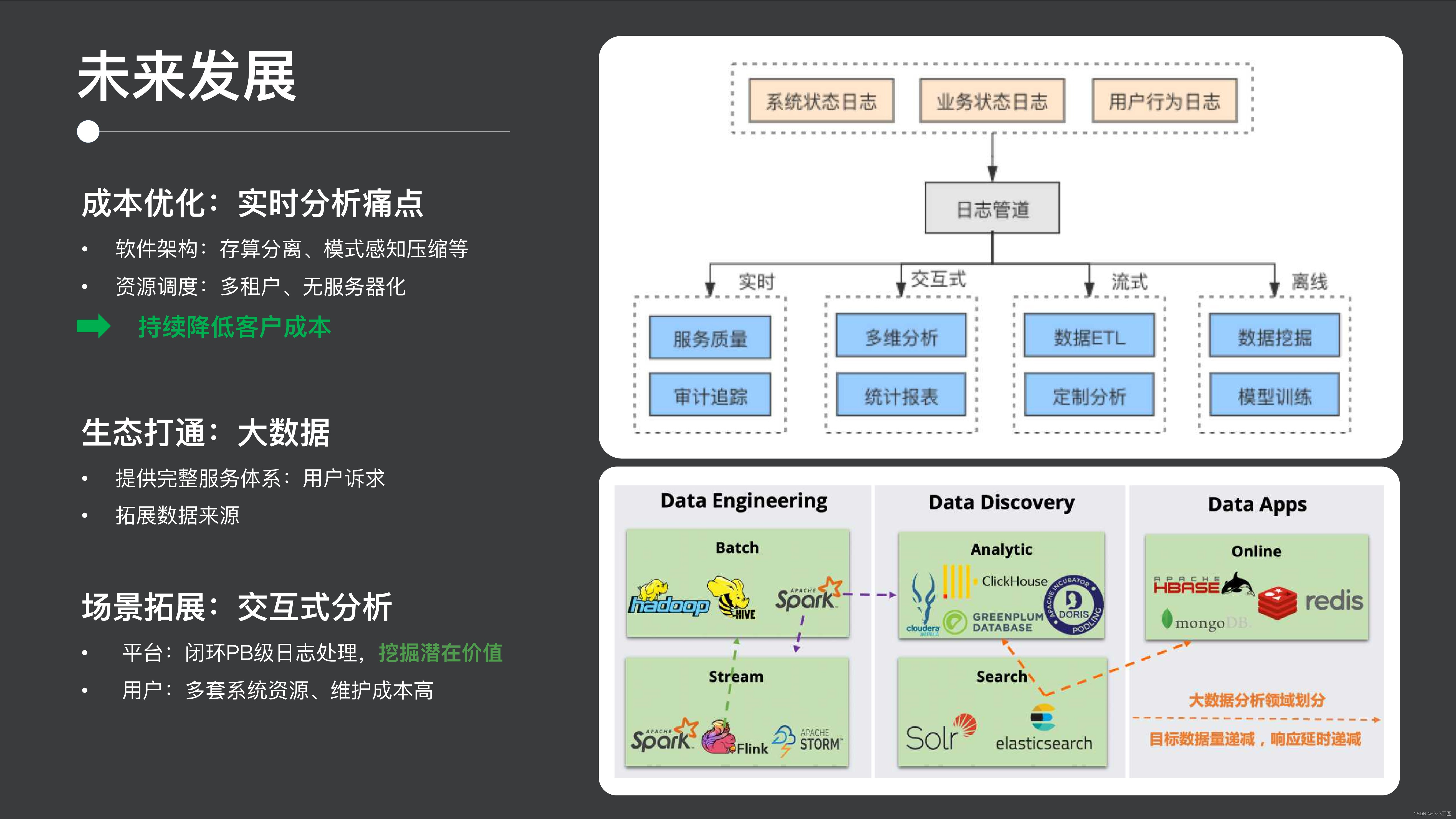
次に将来計画ですが、実は先ほども述べたように、ログシナリオや時系列シナリオではコストとデータ価値は常に相反するものなので、この2つの側面から解決していきます。コストの観点から、リソースのスケジュールとシステム アーキテクチャの最適化を継続していきます。ビジネス価値の観点から言えば、私たちが採用する対策は、一方ではビッグデータ エコロジーを開放し、誰もがビッグ データ エコロジーのデータを利用できるようにすることですが、他方では実際には、誰もが行うデータの使用の典型的な区分は、データとして理解できます。 ストリーム バッチ処理、データの検索と分析 (たとえば、検索分析、対話型の操作分析など) などのエンジニアリング タイプの使用。
3番目のカテゴリーはオンラインアプリで、検索・分析分野には、検索分野ではES Solr、分析分野ではClickHouse、Dorisなどのシステムやソフトウェアがたくさんありますので、今後も期待しています。 ES に基づくインタラクティブ分析の分野を拡大し、システム内の PB レベルのログに対する閉ループ ソリューションを提供し、ユーザーがデータの価値をさらに掘り出すのを支援し、そのようなメンテナンス システムの数を減らし、メンテナンス コストを削減します。
3. オープンソースのコラボレーション

最後の部分では、オープンソース コラボレーションの部分を見てみましょう。オープンソース コラボレーションの分野では、ソース コード パッチへの貢献を含め、コミュニティに多くの貢献を行っており、アジア太平洋地域全体で ES に最も貢献しているチームです。コミュニティ活動としては、この技術に関するコミュニティサミットMeetupにも積極的に参加し、技術原稿も継続的に出力しています。
もちろん、オープンソース コミュニティへの貢献は、一方ではコミュニティの発展に役立ちますが、他方では、私たち個人やチームにとっても非常に有益です。技術レベルでは、まずバージョン維持コストを削減でき、オープンソースコミュニティに比べてブランチの機能や特徴が綿密にフォローされ、オープンソースコミュニティの動きを常に把握できるようになります。 ; 一方、人材育成の面では、オープンソース コミュニティがこのオープンで透明性があり、効率的な開発モデルであるため、誰もが良い開発習慣を身につけることができます; 影響力という点では、当社は CEO からも認められていますこれは、Elastic の開発者やコミュニティ組織にとっても有益であり、人材を惹きつけ、製品開発を支援します。最後に、オープンソース コミュニティからのフィードバックのプロセスに全員が参加し、最終的にはオープンソース コミュニティ、企業、個人にとって Win-Win のプロセスを達成することをお勧めします。
症例レビュー
注意すべき落とし穴は、ES にはユーザビリティの問題があることです。クラスターのスケーラビリティなど、いくつかの一般的な落とし穴があります。オープンソース ES を使用する場合は、比較的安定した状態を確保するために、クラスター内のテーブルの数が 10,000 を超えないようにし、クラスター内のノードの数が 100 を超えないようにすることをお勧めします。手術。もちろん、より高い要件がある場合は、チューニングのためにコミュニティを参照し、いくつかのベスト プラクティスを参照する必要がありますが、これはこの側面における罠です。
一方で、いくつかの落とし穴もあり、ESの使用上の問題やリソース不足の幻想に遭遇した場合には、マシンリソースの観点から根本原因を詳細に分析し、問題を発見し、むやみに拡張しないようにしてください。問題を解決する能力。
