目次

序文
このプロジェクトは、音声ファイルと方言注釈ファイルを使用して音声のメル ケプストラム係数の特徴を抽出し、これらの特徴を正規化します。注釈ファイルに基づいて、データを管理するための辞書が構築されます。次に、トレーニング用の WaveNet 機械学習モデルを選択し、モデルの出力に対してソフトマックス処理を実行します。最後に、トレーニングされたモデルは後で使用できるように保存されます。
このプロジェクトでは、まず音声ファイルと注釈ファイルを取得し、対応する手法を使用してメル ケプストラム係数の特徴を抽出します。これらの機能は、音声信号のスペクトル情報をキャプチャし、後続のモデル トレーニングへの入力を提供できます。
音声ファイルを注釈に正確に関連付けるために、注釈ファイルに基づいて辞書を構築し、各音声ファイルを対応する注釈情報に関連付けることができます。
効果的な音声認識モデルをトレーニングするために、WaveNet 機械学習モデルを選択しました。WaveNet は、音声の生成および認識タスクに広く使用されている深層学習ベースのモデルです。トレーニング データを使用して WaveNet モデルをトレーニングし、音声ファイルと対応する注釈の間の関連性を学習できるようにします。
最後に、トレーニングが完了した後、ソフトマックスを通じてモデルの出力を処理して、最終的な予測結果を取得します。このような処理により、出力を確率分布に変換できるため、モデルが音声を正確に認識しやすくなります。
この一連の手順を経て、プロジェクトは音声ファイルを認識し、注釈情報に基づいて方言を分類できるようになります。トレーニングされたモデルは、実際のアプリケーションで後で使用できるように保存されます。このプロジェクトは、音声認識分野におけるさらなる研究と応用のための強固な基盤を提供します。
全体的なデザイン
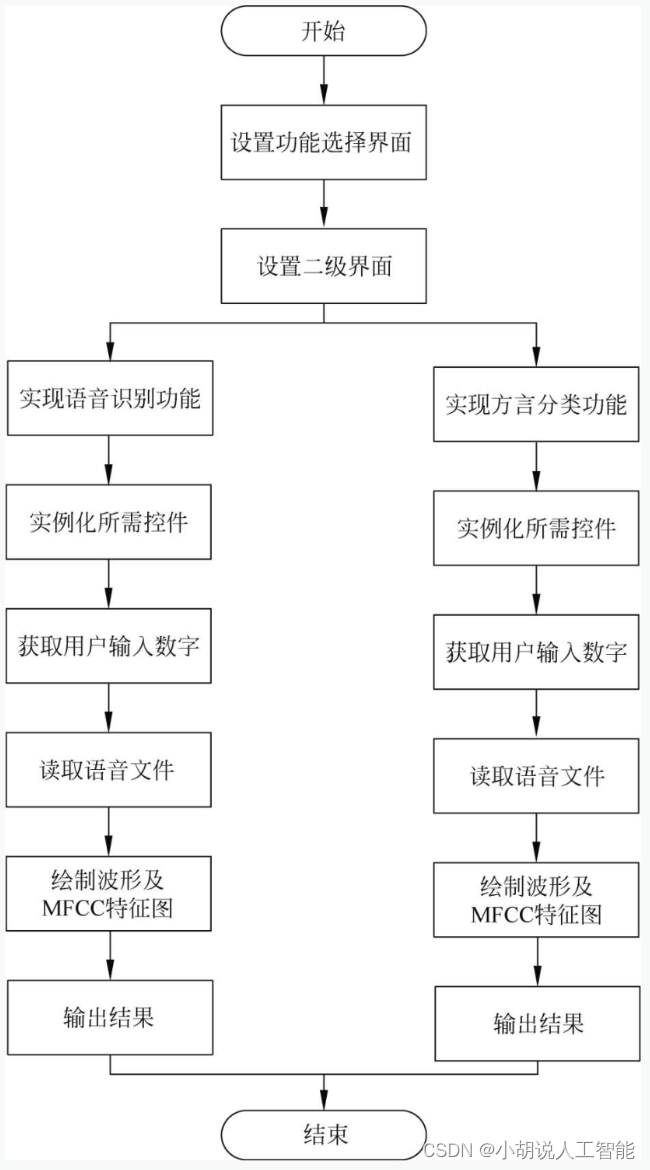
システムの全体構成図とシステムフローチャートを記載します。
システム全体構成図
システムの全体構成を図に示します。

システムフローチャート
音声認識と方言分類のプロセスを図 1 に、ページ設計のプロセスを図 2 に示します。

動作環境
このセクションには、Python 環境と Tensorflow 環境が含まれます。
Python環境
Python 3.6 以降の構成が必要です。Windows 環境では、Python に必要な構成を完了するために Anaconda をダウンロードすることをお勧めします。ダウンロード アドレスはhttps://www.anaconda.com/です。仮想マシンをダウンロードして、Linux 環境でコードを実行することもできます。
Tensorflow 環境
Anaconda プロンプトを開き、清華倉庫のイメージを入力します。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config -set show_channel_urls yes
TensorFlow という名前の Python 3.6.5 環境を作成します。現時点では、Python のバージョンと TensorFlow のそれ以降のバージョンとの間に一致の問題があるため、このステップでは Python3.x を選択します。
conda create -n tensorflow python==3.6.5
確認する必要がある場合は、Yキーを押してください。
Anaconda プロンプトで TensorFlow 環境をアクティブ化します。
conda activate tensorflow
python3.6.5 と一致する TensorFlow の CPU バージョンをインストールします。
pip install tensorflow==1.9
Python と TensorFlow に一致する Keras バージョンをインストールします。ここでは Keras2.2.0 です。
pip install Keras==2.2.0
3 つのバージョンが一致しない場合、Keras をインポートするときにカーネルで問題が発生します。
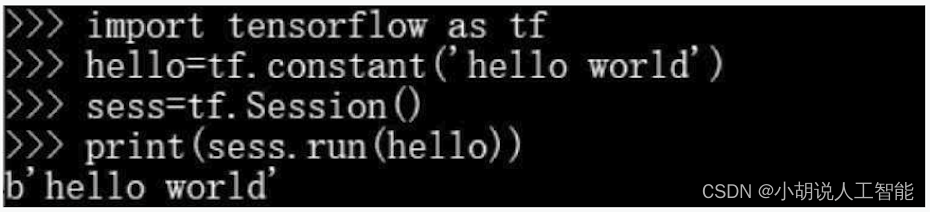
インストールが完了したら確認し、 cmd に入力後Python、図のように入力し、出力されればインストール成功です。
モジュールの実装
このプロジェクトには、方言分類、音声認識、モデルテストの 3 つのモジュールが含まれており、各モジュールの機能紹介と関連コードは以下のとおりです。
1. 方言の分類
この部分には、データのダウンロードと前処理、モデルの構築、モデルのトレーニングと保存が含まれます。
データのダウンロードと前処理
データ セットは HKUST Xunfei によって提供されています。長沙方言、上海方言、南昌方言の 3 つの方言が含まれています。50 ~ 300 KB の 19,489 個の音声データ セットが含まれています。そのうち 17,989 個の学習データと 1,500 個の検証データが含まれています。ダウンロード アドレスは http: // /challenge.xfyun.cn/2019/。データセットをダウンロードしてインポートします。トレーニング セットと検証セットのデータには、それぞれtrain_flesとという名前が付けられますdev_fles。関数を使用してglob ()データをインポートするコードは次のとおりです。
#加载pcm文件,其中17989条训练数据,1500条验证数据
#定义训练集
train_files = glob.glob(r'D:\homework\dialect\data\*\train\*\*.pcm')
#定义验证集
dev_files = glob.glob(r'D:\homework\dialect\data\*\dev\*\*\*.pcm')
print(len(train_files), len(dev_files),train_files[0])
#打印语音数据集的数量与训练集第一条数据
ダウンロードした音声データ セットを並べ替えて分類し、トレーニング セットと検証セットの各データにラベルを付けます。関連するコードは次のとおりです。
labels = {
'train': [], 'dev': []}
#对于train_files中的每一条数据
for i in tqdm(range(len(train_files))):
path = train_files[i] #取出路径
label = path.split('\\')[1] #以'\\'划分路径,取出其中对应地区分类的标签
labels['train'].append(label)#以字典进行存储
#对于dev_files中的每一条数据进行如上操作
for i in tqdm(range(len(dev_files))):
path = dev_files[i]
label = path.split('\\')[1]
labels['dev'].append(label)
print(len(labels['train']), len(labels['dev']))
#整理每条语音数据对应的分类标签图
データセットはダウンロード後に前処理されます。音声データの処理、pcm 形式から wav 形式への変換、および音声データ セットの視覚化のための 3 つの関数を定義します。音声クリップの長さはさまざまであるため、1 秒未満の短いクリップは削除され、長いクリップは 3 秒以下のセグメントに分割されます。
a. 音声データの処理
関連するコードは次のとおりです。
def load_and_trim(path, sr=16000):
audio = np.memmap(path, dtype='h', mode='r') #对大文件分段读取
audio = audio[2000:-2000]
audio = audio.astype(np.float32)
energy = librosa.feature.rms(audio) #计算能量
frames = np.nonzero(energy >= np.max(energy) / 5) #最大能量的1/5视为静音
indices = librosa.core.frames_to_samples(frames)[1]#去除静音
audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0]
slices = []#存储划分为小于3s大于1s的切片
for i in range(0, audio.shape[0], slice_length):
s = audio[i: i + slice_length]#切分为3s片段
if s.shape[0] >= min_length:
slices.append(s) #去除小于1s的片段
return audio, slices
b. pcm から wav への関数
関連するコードコードは次のとおりです。
def pcm2wav(pcm_path, wav_path, channels=1, bits=16, sample_rate=sr):
data = open(pcm_path, 'rb').read() #读取文件
fw = wave.open(wav_path, 'wb') #存储wav路径
fw.setnchannels(channels) #设置通道数:单声道
fw.setsampwidth(bits // 8) #将样本宽度设置为bits/8个字节
fw.setframerate(sample_rate) #设置采样率
fw.writeframes(data) #写入data个长度的音频
fw.close()
c. 音声データセットの視覚化関数
関連するコードは次のとおりです。
def visualize(index, source='train'):
if source == 'train':
path = train_files[index] #训练集路径
else:
path = dev_files[index] #验证集路径
print(path)
audio, slices = load_and_trim(path) #去除两端静音,并切分为片段
print('Duration: %.2f s' % (audio.shape[0] / sr)) #打印处理后的长度
plt.figure(figsize=(12, 3)) #图像大小
plt.plot(np.arange(len(audio)), audio) #绘制波形
plt.title('Raw Audio Signal') #设置标题
plt.xlabel('Time') #设置横坐标
plt.ylabel('Audio Amplitude') #设置纵坐标
plt.show() #绘图展示
feature = mfcc(audio, sr, numcep=mfcc_dim) #提取mfcc特征
print('Shape of MFCC:', feature.shape) #打印mfcc特征
fig = plt.figure(figsize=(12, 5)) #图像大小
ax = fig.add_subplot(111)
im = ax.imshow(feature, cmap=plt.cm.jet, aspect='auto') #绘制mfcc
plt.title('Normalized MFCC') #图像标题
plt.ylabel('Time') #设置纵坐标
plt.xlabel('MFCC Coefficient') #设置横坐标
plt.colorbar(im, cax=make_axes_locatable(ax).append_axes('right', size='5%', pad=0.05))
ax.set_xticks(np.arange(0, 13, 2), minor=False); #设置横坐标间隔
plt.show() #绘图展示
wav_path = r'D:/homework/dialect/example.wav'#wav文件存储路径
pcm2wav(path, wav_path) #pcm文件转化为wav文件
return wav_path
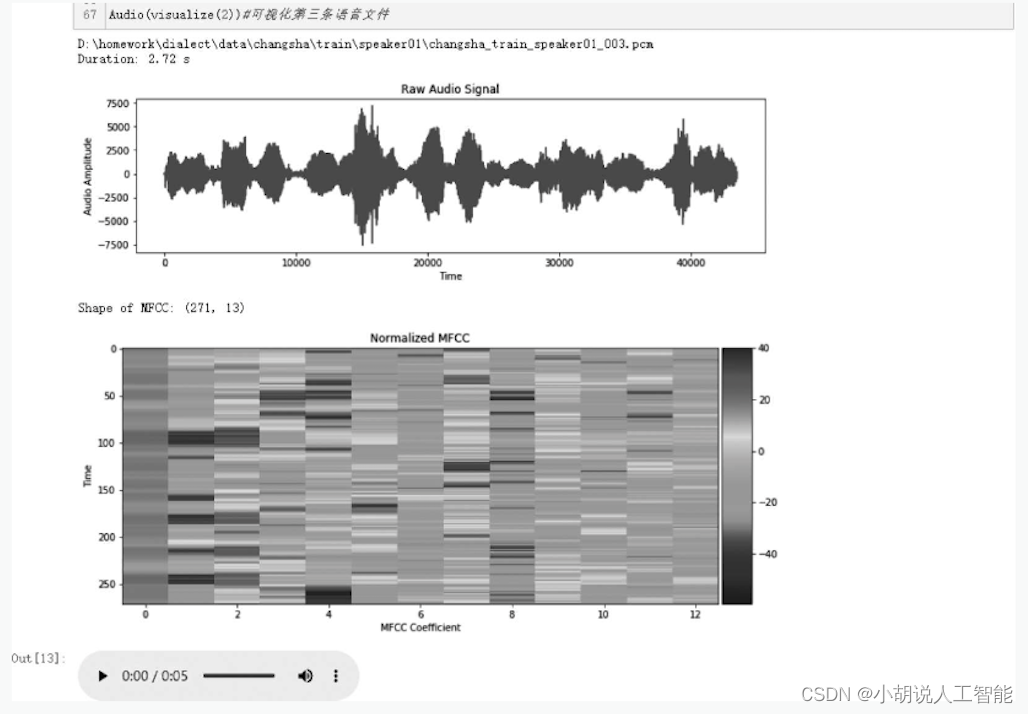
3 番目の音声データの視覚化を例として、結果を図 3 に示します。トレーニング セットと検証セットの MFCC 特徴をそれぞれ正規化します。関連するコードは次のとおりです。
#对训练集MFCC特征归一化
X_train = [(x - mfcc_mean) / (mfcc_std + 1e-14) for x in X_train]
#对验证集MFCC特征归一化
X_dev = [(x - mfcc_mean) / (mfcc_std + 1e-14) for x in X_dev]
LabelEncoder()処理対象のラベルを整数として使用しto_categorical()、トレーニングセットと検証セットを関数を通じてベクトルに変換し、反復関数を定義します。関連するコードは次のとおりです。
le = LabelEncoder()
Y_train = le.fit_transform(Y_train) #处理训练集标签
Y_dev = le.transform(Y_dev) #处理验证集标签
num_class = len(le.classes_) #3个类别
Y_train = to_categorical(Y_train, num_class) #将训练集转化为向量
Y_dev = to_categorical(Y_dev, num_class) #将验证集转化为向量
モデル構築
データをモデルにロードした後、モデル構造を定義し、損失関数を最適化する必要があります。
(1) モデル構造の定義
このモデルは、多層因果拡張畳み込みを使用してデータを処理します。まず、1 次元畳み込み層を構築して使用します。次に、BN (BatchNormalization) アルゴリズムを導入し、batchnorm ()モデルの過学習問題を解消するための正則化関数を定義しますactivation ()。最後に、ニューラル ネットワークのトレーニングをアクティブにする関数を定義します。 ,res_block ()関数を定義し、基本ブロックでは修復の目的を達成するために Conv+BN+Relu+Conv+BN 側枝のモデルを使用することがよくあります。GlobalMaxPooling1D ()シーケンス出力全体に対して次元削減を実行して、ソフトマックス ロジスティック回帰モデルを定義します。畳み込みの最終層の特徴マップの数は辞書のサイズと同じであり、softmax 関数で処理すると、各小セグメントに対応する MFCC について辞書全体の確率分布が得られます。関連するコードは次のとおりです。
#定义多层因果空洞卷积MFCC一维,使用conv1d
def conv1d(inputs, filters, kernel_size, dilation_rate):
return Conv1D(filters=filters, kernel_size=kernel_size, strides=1, padding='causal', activation=None, dilation_rate=dilation_rate)(inputs)
#加速神经网络训练BN算法
def batchnorm(inputs):
return BatchNormalization()(inputs)
#定义神经网络激活函数
def activation(inputs, activation):
return Activation(activation)(inputs)
def res_block(inputs, filters, kernel_size, dilation_rate):
hf = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'tanh')
hg = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'sigmoid')
h0 = Multiply()([hf, hg])
#tanh激活函数
ha = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')
hs = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')
return Add()([ha, inputs]), hs
#tanh激活函数
h0 = activation(batchnorm(conv1d(X, filters, 1, 1)), 'tanh')
shortcut = []
for i in range(num_blocks):
for r in [1, 2, 4, 8, 16]:
h0, s = res_block(h0, filters, 7, r)
shortcut.append(s)
#Relu激活函数
h1 = activation(Add()(shortcut), 'relu')
h1 = activation(batchnorm(conv1d(h1, filters, 1, 1)), 'relu')
h1 = batchnorm(conv1d(h1, num_class, 1, 1))
h1 = GlobalMaxPooling1D()(h1) #通过GlobalMaxPooling1D对整个序列输出进行降维
Y = activation(h1, 'softmax') #softmax逻辑回归模型
(2) 損失関数の最適化
モデルのアーキテクチャを決定し、コンパイルします。これはマルチカテゴリ分類問題であるため、損失関数の計算には CTC (Connectionist 時間分類) アルゴリズムが使用されます。すべてのラベルには同様の重みがあるため、精度がパフォーマンスの指標として使用されます。関連するコードは次のとおりです。
#Adam优化算法
optimizer = Adam(lr=0.01, clipnorm=5)
#模型输入/输出
model = Model(inputs=X, outputs=Y)
#模型损失和准确率
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
#模型保存路径
checkpointer = ModelCheckpoint(filepath='D:/homework/dialect/fangyan.h5', verbose=0)
lr_decay = ReduceLROnPlateau(monitor='loss', factor=0.2, patience=1, min_lr=0.000)
モデルのトレーニングと保存
モデル アーキテクチャを定義してコンパイルした後、トレーニング セットを通じてモデルをトレーニングし、モデルに方言分類を実行させます。ここでは、トレーニング セットと検証セットを使用してモデルを適合させ、保存します。
(1) モデルのトレーニング
関連するコードは次のとおりです。
#分批读取数据
history = model.fit_generator(
#训练集批处理器
generator=batch_generator(X_train, Y_train),
#每轮训练的数据量
steps_per_epoch=len(X_train),
epochs=epochs,
#测试集批处理器
validation_data=batch_generator(X_dev, Y_dev),
validation_steps=len(X_dev)
callbacks=[checkpointer, lr_decay])
このうち、バッチ(batch)とは、順方向/逆方向伝播処理で使用される学習サンプルの数であり、一度に1180個の音声データが学習に使用され、合計11800個の音声データが学習されます。図に示すように。

トレーニング セットとテスト セットの損失関数と精度を観察することで、モデルのトレーニングの程度を評価し、モデルのトレーニングに関するさらなる決定を下します。トレーニング セットとテスト セットの損失関数 (または精度率) は変化せず、基本的にモデル トレーニングの最良の状態と同じです。トレーニングプロセス中に保存された正解率と損失関数は、簡単に観察できるように画像の形式で表示されます。
train_loss = history.history['loss']#训练集损失函数
valid_loss = history.history['val_loss']#验证集损失函数
#画图
plt.plot(train_loss, label='训练')
plt.plot(valid_loss, label='验证')
plt.legend(loc='upper right')
plt.xlabel('训练次数')
plt.ylabel('损失')
plt.show()
train_acc = history.history['acc']#训练集精确度
valid_acc = history.history['val_acc']#验证集精确度
#画图
mpl.rcParams['font.sans-serif'] = ['SimHei']
plt.plot(train_acc, label='训练')
plt.plot(valid_acc, label='验证')
plt.legend(loc='upper right')
plt.xlabel('训练次数')
plt.ylabel('精确度')
plt.legend()
plt.show()
(2) モデルの保存
関連するコードは次のとおりです。
#保存模型
model.save('fangyan.h5') #HDF5文件
モデルを保存した後、再利用したり、他の環境に移植したりできます。カテゴリ予測の場合、辞書を .pkl ファイルとして保存します。関連するコードは次のとおりです。
#保存字典
with open('resources.pkl', 'wb') as fw:
pickle.dump([class2id, id2class, mfcc_mean, mfcc_std], fw)
2. 音声認識
このセクションには、データの前処理、モデルの構築、モデルのトレーニング、およびモデルの保存が含まれます。
データの前処理
データ セットのソース アドレスはwww.openslr.org/18/で、これには 100 ~ 400 KB の 13388 個の音声データ セットが含まれています。データセットをダウンロードし、glob ()関数を使用してインポートします。関連するコードは次のとおりです。
#加载trn,读取语音对应的文本文件
text_paths = glob.glob(r'D:/homework/language/language/data/*.trn')
#导入数据集
total = len(text_paths) #统计文本个数
print(total) #打印数据集总数
with open(text_paths[0], 'r', encoding='utf8') as fr:
lines = fr.readlines()
print(lines) #打印第一条数据中内容
音声認識データ セットには、音声を表す .wav ファイルと文字起こしを表す .trn ファイルがあります。最初のデータを印刷すると、出力は図のようになります。

ダウンロードした音声データセットを整理し、テキスト内の中国語をテキストリストに保存し、各音声のパスをパスリストに保存します。関連するコードは次のとおりです。
#提取文本内容和语音文件路径,去掉空白格
texts = [] #放置文本
paths = [] #防止每个语音文件的路径
for path in text_paths:
with open(path, 'r', encoding='utf8') as fr:
lines = fr.readlines()
line = lines[0].strip('\n').replace(' ', '')
#用逗号替换空白格,去掉拼音
texts.append(line) #更新文本,添加整理好的内容
paths.append(path.rstrip('.trn'))#除去.trn的文件就是.wav音频文件
print(paths[0], texts[0])#打印语音文件所在路径以及对应的文本内容
音声データセットをダウンロードして前処理します。音声データの処理と音声データセットの視覚化のための 2 つの関数を定義します。音声データの加工機能では、音声ファイルの両端の無音部分を削除します。音声データを処理する関数コードの一部は次のとおりです。
def load_and_trim(path):
audio, sr = librosa.load(path) #读取音频
energy = librosa.feature.rms(audio) #计算能量
frames = np.nonzero(energy >= np.max(energy) / 5) #最大能量的1/5视为静音
indices = librosa.core.frames_to_samples(frames)[1] #去除静音
audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0]
return audio, sr
#可视化语音数据集部分函数代码
def visualize(index):
path = paths[index] #获取某个音频
text = texts[index] #获取音频对应的文本
print('Audio Text:', text)
audio, sr = load_and_trim(path) #调用函数去除两端静音
plt.figure(figsize=(12, 3))
plt.plot(np.arange(len(audio)), audio)
plt.title('Raw Audio Signal')
plt.xlabel('Time')#x轴为时间
plt.ylabel('Audio Amplitude') #y轴为音频高度
plt.show()
feature = mfcc(audio, sr, numcep=mfcc_dim, nfft=551) #计算MFCC特征
print('Shape of MFCC:', feature.shape)
fig = plt.figure(figsize=(12, 5))
ax = fig.add_subplot(111)
im = ax.imshow(feature, cmap=plt.cm.jet, aspect='auto')
plt.title('Normalized MFCC')
plt.ylabel('Time')
plt.xlabel('MFCC Coefficient')
plt.colorbar(im, cax=make_axes_locatable(ax).append_axes('right', size='5%', pad=0.05))
ax.set_xticks(np.arange(0, 13, 2), minor=False);
plt.show()
return path
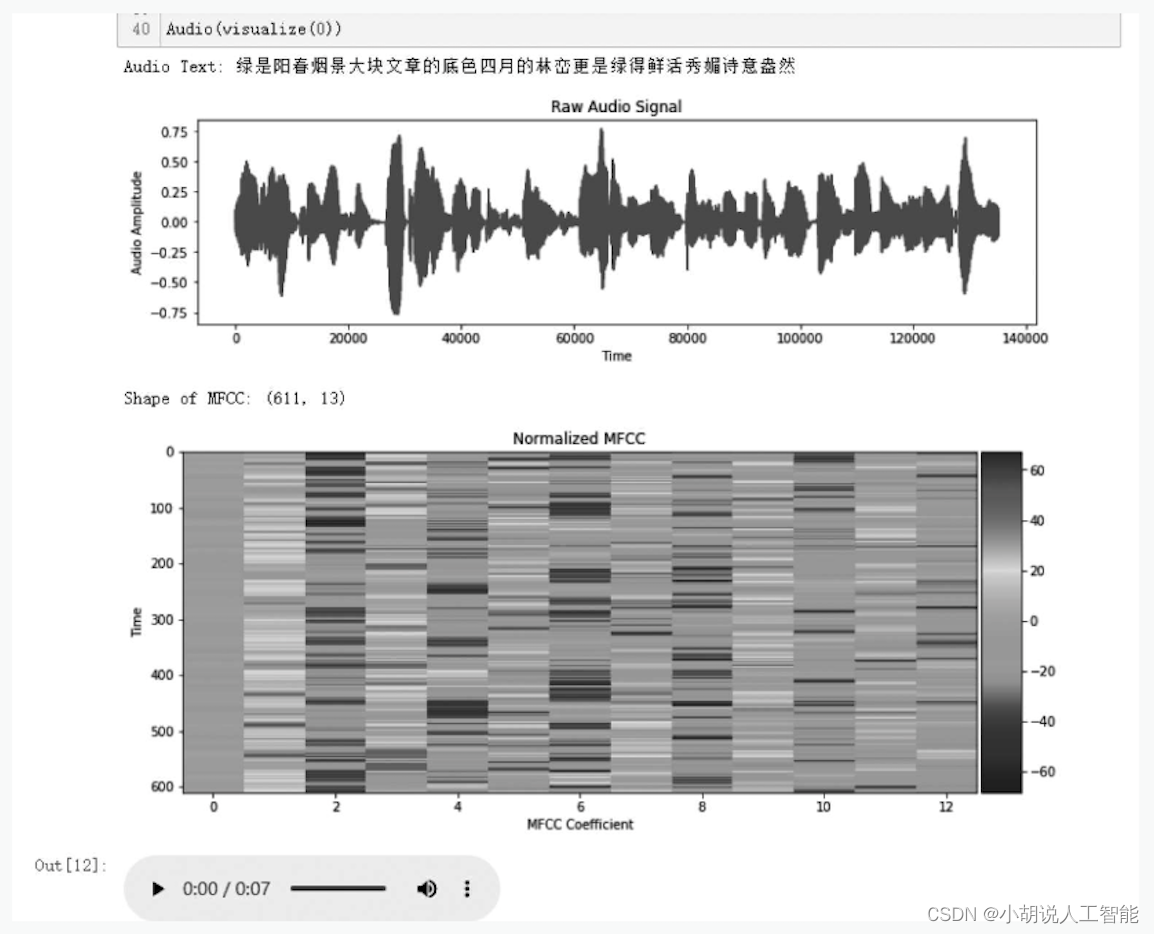
最初の音声データの視覚化を例として、結果を図に示します。
オーディオ ファイルの MFCC 特徴を正規化し、辞書を作成します。関連するコードは次のとおりです。
features=[(feature-mfcc_mean)/(mfcc_std + 1e-14) for feature in features]
#建立字典
chars = {
}
for text in texts:
for c in text:
chars[c] = chars.get(c, 0) + 1
chars = sorted(chars.items(), key=lambda x: x[1], reverse=True)
chars = [char[0] for char in chars]
print(len(chars), chars[:100]) #打印随机100段音频中汉字数量
char2id = {
c: i for i, c in enumerate(chars)}
id2char = {
i: c for i, c in enumerate(chars)}
データは分割され、全体のデータの 90% がトレーニング セットとして使用されます。バッチデータを生成する関数batch_generator()を定義します。関連するコードは次のとおりです。
data_index = np.arange(total)
np.random.shuffle(data_index) #将索引打乱
train_size = int(0.9 * total) #训练数据占90%
test_size = total - train_size
train_index = data_index[:train_size] #切分出来训练数据的索引
test_index = data_index[train_size:] #切分出来测试数据的索引
X_train = [features[i] for i in train_index] #取出训练音频的MFCC特征
Y_train = [texts[i] for i in train_index] #取出训练的标签
X_test = [features[i] for i in test_index] #取出测试音频的MFCC特征
Y_test = [texts[i] for i in test_index] #取出测试的标签
モデル構築
データをモデルにロードした後、モデル構造を定義し、損失関数を最適化する必要があります。
(1) モデル構造の定義
WaveNet ネットワークを定義します。多層因果的アトラス畳み込みを使用してデータを処理するモデル構造の使用方法は、方言分類部分とほぼ同じです。
(2) 損失関数とモデルの最適化 モデルのアーキテクチャ
を決定した後、コンパイルします。これはマルチカテゴリ分類問題であるため、損失関数の計算には CTC (Connectionist 時間分類) アルゴリズムが使用されます。関連するコードは次のとおりです。
def calc_ctc_loss(args): #CTC损失函数
y, yp, ypl, yl = args
return K.ctc_batch_cost(y, yp, ypl, yl)
ctc_loss = Lambda(calc_ctc_loss, output_shape=(1,), name='ctc')([Y, Y_pred, X_length, Y_length]) #调用函数
model = Model(inputs=[X, Y, X_length, Y_length], outputs=ctc_loss)
optimizer = SGD(lr=0.02, momentum=0.9, nesterov=True, clipnorm=5)
model.compile(loss={
'ctc': lambda ctc_true, ctc_pred: ctc_pred}, optimizer=optimizer) #定义模型
checkpointer = ModelCheckpoint(filepath='asr.h5', verbose=0)
lr_decay = ReduceLROnPlateau(monitor='loss', factor=0.2, patience=1, min_lr=0.000)
モデルのトレーニングと保存
モデル アーキテクチャを定義してコンパイルした後、トレーニング セットを使用してモデルをトレーニングし、モデルに音声を認識させます。ここでは、トレーニング セットと検証セットを使用してモデルを適合させ、保存します。
1) モデルのトレーニング
関連するコードは次のとおりです。
#分批读取数据
history = model.fit_generator(
#训练集批处理器
generator=batch_generator(X_train, Y_train),
#每轮训练的数据量
steps_per_epoch=len(X_train),
epochs=epochs,
#测试集批处理器
validation_data=batch_generator(X_dev, Y_dev),
validation_steps=len(X_dev)
callbacks=[checkpointer, lr_decay])
図に示すように、データのバッチは 753 を超えません。

関連するコードは次のとおりです。
#训练集损失
train_loss = history.history['loss']
#验证集损失
valid_loss = history.history['val_loss']
#绘制损失函数图像
mpl.rcParams['font.sans-serif'] = ['SimHei'] #默认字体黑体
plt.plot(np.linspace(1, epochs, epochs), train_loss, label='训练')
plt.plot(np.linspace(1, epochs, epochs), valid_loss, label='验证')
plt.legend(loc='upper right')
plt.xlabel('训练次数')
plt.ylabel('损失')
plt.legend()
plt.show()
2) モデルの保存
後続の GUI デザインのインポートのために、モデルを .h5 形式のファイルとして保存します。
関連するコードは次のとおりです。
#模型保存
sub_model.save('asr.h5')
辞書を pkl 形式ファイルとして保存します。関連するコードは次のとおりです。
#字典保存
with open('dictionary.pkl', 'wb') as fw:
pickle.dump([char2id, id2char], fw)
モデルとディクショナリを保存した後、再利用したり、他の環境に移植したりできます。
3. モデルのテスト
設計された GUI にモデルをインポートし、音声ファイルを選択して、元の波形と MFCC 機能マップを表示します。音声認識と方言分類の2つの機能が選択可能です。グラフィカルユーザーには主に、機能選択インターフェース、言語認識機能実現インターフェース、方言認識機能実現インターフェースの3つのインターフェースが含まれます。
機能選択インターフェース
関連する操作は次のとおりです
(1) 関数選択インターフェースをルートフォームとして設定します。関数選択インターフェイスの各属性を初期化します。関連する操作は次のとおりです。
#设置功能选择界面的大小及标题
root = Tk()
root.geometry('300x450')
root.title('语音识别及方言分类')
#界面展示
mainloop()
ルート ウィンドウはグラフィカル アプリケーションのルート コントローラーであり、Tkinter の基礎となるコントロールのインスタンスです。Tkinter モジュールをインポートした後、Tk()関数を呼び出してルート ウィンドウ インスタンスを初期化し、title()関数を使用してタイトル テキストを設定し、geometry()関数を使用してウィンドウ サイズ (ピクセル単位) を設定します。ルート フォームをメイン ループに置くと、ユーザーが閉じない限りプログラムは実行され続けます。メイン ループのルート形式では、他のビジュアル コントロール インスタンスを継続的に表示でき、イベントの発生が監視され、対応するハンドラーが実行されます。
(2) インターフェースに表示するコントロールとそれに対応するプロパティ、レイアウトを設定します。関連する操作は次のとおりです。
#设置文本标签,提示用户欢迎信息
lb = Label(root, text='欢迎使用!',font=('华文新魏',22))
lb.pack()
#设置文本标签位置
lb.place(relx=0.15, rely=0.2, relwidth=0.75, relheight=0.3)
#设置两个提示按钮及文本字体大小
btn = Button(root, text='语音识别',font=('华文新魏',12),command=asr)
btn.pack()
#设置第一个按钮位置
btn.place(relx=0.3, rely=0.5, relwidth=0.4, relheight=0.1)
btn_btn = Button(root, text='方言分类',font=('华文新魏',12),command = dialect)
btn_btn.pack()
#设置第二个按钮位置
btn_btn.place(relx=0.3, rely=0.65, relwidth=0.4, relheight=0.1)
ラベル インスタンス lb、ボタン インスタンス btn および btn_ btn は親コンテナのルートでインスタンス化され、テキスト (text)、フォント (font)、およびコマンド属性が設定されます。コントロールがインスタンス化されると、インスタンス属性は「属性 = 属性値」の形式で列挙します。順不同です。属性値は通常、テキスト形式で表現されます。
ボタンは主に、マウス クリック イベントに応答して実行中のプログラムをトリガーするように設定されており、コントロールの共通プロパティを除けば、コマンド (コマンド) が最も重要なプロパティです。通常、実行のきっかけとなるプログラムはあらかじめ関数の形式で定義されており、その関数を直接呼び出します。パラメータの式は「コマンド=関数名」で、関数名の後に括弧はなく、パラメータも指定されません。合格した。したがって、インターフェイスを実現するには、ボタンテキストに対応する機能をトリガーするコマンド属性を設定します。
place ()relx、rely、relheight を使用したメソッドを使用すると、relwidth パラメータによって取得されるインターフェイスをルート ウィンドウのサイズに適応させることができます。
言語認識機能実現インターフェース
関連する操作は次のとおりです。
(1) Toplevel()関数を呼び出して、音声認識機能を実現するためのセカンダリインターフェースを設定します。
(2) 必要なテキスト ラベル、イメージ ラベル、テキスト、およびボタン コントロールをインスタンス化します。
(3) ユーザーが入力した番号を取得する関数を定義し、その後の認識のために音声ファイルを選択します。
(4) 音声ファイルを読み込む関数を定義し、一連の処理の後、元の波形と MFCC 特徴量画像を描画し、ローカルに保存します。
#语音文件初始处理,去除两端静音
audio, sr = librosa.load(wavs[int(x)]) #读取语音文件
energy = librosa.feature.rms(audio) #计算语音文件能量
#判定能量小于最大能量1/5为静音
frames = np.nonzero(energy >= np.max(energy) / 5)
indices = librosa.core.frames_to_samples(frames)[1]
audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0] #去除两端静音
plt.figure(figsize=(12, 3)) #图像大小
plt.plot(np.arange(len(audio)), audio) #绘制原始波形
plt.title('Raw Audio Signal') #图像标题
plt.xlabel('Time') #图像横坐标
plt.ylabel('Audio Amplitude') #图像纵坐标
#保存原始波形图像
plt.savefig('E:/北邮学习/2020课件/信息系统设计/语音识别/原始波形.png')
#feature.shape二维数组(切片数量,维度)
#指定音频文件、采样率、mfcc维度,获取MFCC特征
feature = mfcc(audio, sr, numcep=mfcc_dim, nfft=551)
#绘制MFCC特征图
fig = plt.figure(figsize=(12, 5))#图像大小
ax = fig.add_subplot(111) #分块绘图
#绘制mfcc特征
im = ax.imshow(feature, cmap=plt.cm.jet, aspect='auto')
plt.title('Normalized MFCC') #图像标题
plt.ylabel('Time') #图像纵坐标
plt.xlabel('MFCC Coefficient') #图像横坐标
#右侧colorbar绘制
plt.colorbar(im, cax=make_axes_locatable(ax).append_axes('right', size='5%', pad=0.05))
ax.set_xticks(np.arange(0, 13, 2), minor=False); #图像横坐标值设置
#保存MFCC特征图像
plt.savefig('E:/北邮学习/2020课件/信息系统设计/语音识别/mfcc.png')
(5) インターフェイスに MFCC 機能マップと元の波形マップをそれぞれ表示するために使用される 2 つの関数を定義します。
(6) 音声ファイルのマークされたテキストを取り出してインターフェース上に表示する関数を定義します。
(7) 関数を定義し、音声認識用の学習済みモデルを読み込み、認識結果を出力・表示します。
audio, sr = librosa.load(wavs[int(x)]) #读取语音文件
energy = librosa.feature.rms(audio) #计算语音文件能量
#判定能量小于最大能量1/5为静音
frames = np.nonzero(energy >= np.max(energy) / 5)
indices = librosa.core.frames_to_samples(frames)[1]
audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0] #去除两端静音
X_data = mfcc(audio, sr, numcep=mfcc_dim, nfft=551) #获取mfcc特征
X_data = (X_data - mfcc_mean) / (mfcc_std + 1e-14) #mfcc归一化处理
#加载模型进行语音识别
pred = model.predict(np.expand_dims(X_data, axis=0))
#加载预测结果
pred_ids = K.eval(K.ctc_decode(pred, [X_data.shape[0]], greedy=False,beam_width=10, top_paths=1)[0][0])
pred_ids = pred_ids.flatten().tolist()
#实例化lb标签,在界面中展示识别文本结果
lb3 = Label(top, text='识别结果:'+''.join([id2char[i] for i in pred_ids]))
lb3.place(relx=0.1, rely=0.96, relwidth=0.75, relheight=0.03)
(8) ボタン コントロールのコマンド属性を設定し、上で定義した機能とリンクして、ボタンに対応する実現可能な機能が正しくトリガーされるようにします。
方言分類機能実現インターフェース
関連する操作は次のとおりです。
(1) Toplevel () 関数を呼び出して、方言分類関数を実現するための第 2 レベルのインターフェイスを設定します。
(2) 必要なテキスト ラベル、イメージ ラベル、テキスト、およびボタン コントロールをインスタンス化します。
(3) その後の方言分類のために音声ファイルをランダムに選択する関数を定義します。
(4) 関数を定義し、音声ファイルを読み込み、一連の処理を行った後、元の波形と MFCC 特徴量画像を描画し、ローカルに保存します。
#定义函数,加载语音文件,去除两端静音,对长语音进行片段切片
def load_and_trim(path, sr=16000):
audio = np.memmap(path, dtype='h', mode='r') #对大文件分段读取
audio = audio[2000:-2000]
audio = audio.astype(np.float32)
energy = librosa.feature.rms(audio) #计算能量
#最大能量的1/5视为静音
frames = np.nonzero(energy >= np.max(energy) / 5)
indices = librosa.core.frames_to_samples(frames)[1] #去除静音
audio = audio[indices[0]:indices[-1]] if indices.size else audio[0:0] #去除静音后的语音文件
slices = [] #存储划分为小于3s大于1s的切片
for i in range(0, audio.shape[0], slice_length):
s = audio[i: i + slice_length] #切分为3s片段
if s.shape[0] >= min_length:
slices.append(s) #去除小于1s的片段
return audio, slices
#定义函数以读取语音文件,绘制原始波形及MFCC特征两个图像,并保存到本地
def run2():
#从文本框中提取随机选取的语音文件路径
path = txt1.get("0.0","end")
path = path.strip("\n").split(" ")[0]
audio, slices = load_and_trim(path) #去除两端静音,并切分为片段
#绘制原始波形图像
plt.figure(figsize=(12, 3))#图像大小
plt.plot(np.arange(len(audio)), audio) #绘制波形
plt.title('Raw Audio Signal')#设置标题
plt.xlabel('Time') #设置横坐标
plt.ylabel('Audio Amplitude')#设置纵坐标
#保存原始波形图像
plt.savefig('E:/北邮学习/2020课件/信息系统设计/原始波形.png')
#绘制MFCC特征图像
feature = mfcc(audio, sr, numcep=mfcc_dim) #提取MFCC特征
fig = plt.figure(figsize=(12, 5))#图像大小
ax = fig.add_subplot(111)
im = ax.imshow(feature, cmap=plt.cm.jet, aspect='auto') #绘制MFCC
plt.title('Normalized MFCC')#图像标题
plt.ylabel('Time')#设置纵坐标
plt.xlabel('MFCC Coefficient')#设置横坐标
plt.colorbar(im, cax=make_axes_locatable(ax).append_axes('right', size='5%', pad=0.05))
ax.set_xticks(np.arange(0, 13, 2), minor=False);#设置横坐标间隔
#保存mfcc特征图像
plt.savefig('E:/北邮学习/2020课件/信息系统设计/mfcc.png')
(5) インターフェイスに MFCC 機能マップと元の波形マップをそれぞれ表示するために使用される 2 つの関数を定義します。
(6) 音声ファイルのカテゴリを抽出してインターフェース上に表示する関数を定義します。
(7) 関数を定義し、学習済みモデルを読み込んで方言を分類し、認識結果を出力・表示します。
path = txt1.get("0.0","end")
path = path.strip("\n").split(" ")[0]
#去除两端静音,并切分为片段
audio, slices = load_and_trim(path)
#获取mfcc特征
X_data = [mfcc(s, sr, numcep=mfcc_dim) for s in slices]
#MFCC归一化处理
X_data = [(x - mfcc_mean) / (mfcc_std + 1e-14) for x in X_data]
maxlen = np.max([x.shape[0] for x in X_data])
X_data = pad_sequences(X_data, maxlen, 'float32', padding='post', value=0.0)
#加载模型进行方言分类
prob = model.predict(X_data)
prob = np.mean(prob, axis=0)
pred = np.argmax(prob)
prob = prob[pred]
pred = id2class[pred]
#实例化lb标签,在界面中展示识别预测类别
lb3 = Label(top1, text='预测类别:'+ pred + ' Confidence:'+ str(prob))
lb3.place(relx=0.1, rely=0.96, relwidth=0.75, relheight=0.03)
(8) ボタン コントロールのコマンド プロパティを設定し、上で定義した関数に接続して、ボタンに対応する実現可能な関数が正しくトリガーされるようにします。
システムテスト
このセクションには、トレーニングの精度、テスト結果、モデルのアプリケーションが含まれます。
1. トレーニングの精度
音声認識タスク、予測モデルのトレーニングは比較的成功しています。図に示すように、学習回数が増加するにつれて、学習データとテスト データ上のモデルの損失は徐々に収束し、最終的には安定する傾向にあります。
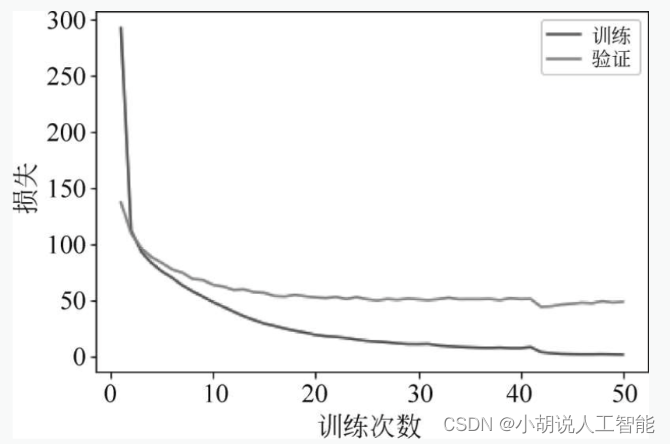
方言分類では、トレーニング セットのテスト精度率が 98% を超えており、予測モデルのトレーニングが比較的成功していることを意味します。訓練回数が増加するにつれて、訓練データ上のモデルの損失と精度は徐々に収束し、最終的には安定しますが、テストデータ上の損失と精度は十分に安定せず、図 4 に示すようにある程度変動します。および図5。
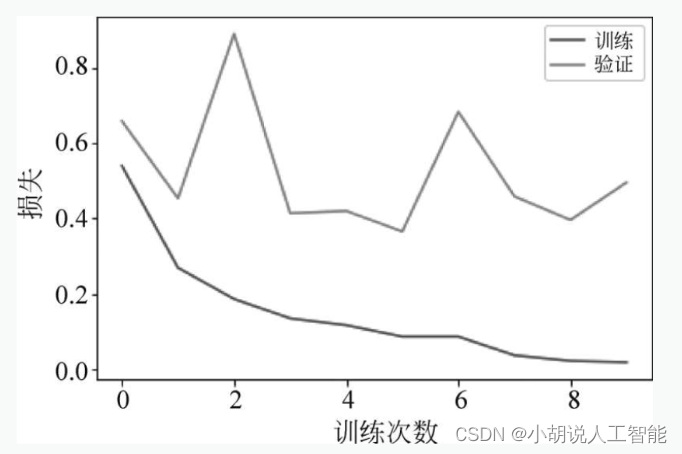
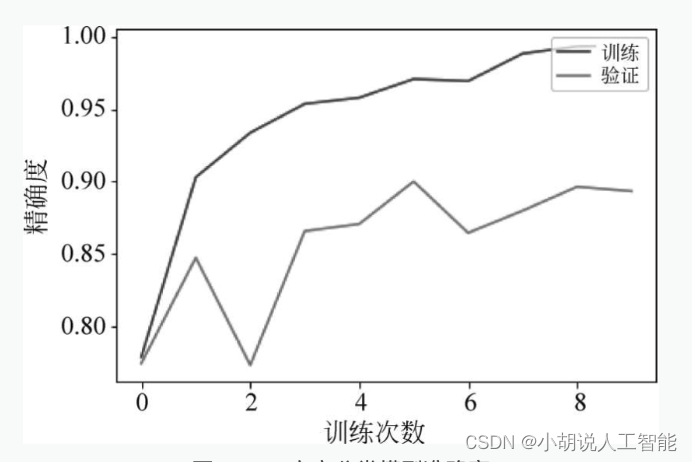
2. テスト効果
次の図に示すように、テスト セットをテストし、認識されたテキストと分類ラベルを表示して元のデータと比較します。

この結果から、このモデルは音声認識と方言分類を実現できることがわかります。
3. モデルの適用
このセクションには、グラフィカル ユーザー インターフェイスの使用方法とテスト結果が含まれています。
1. グラフィカル ユーザー インターフェイスの説明
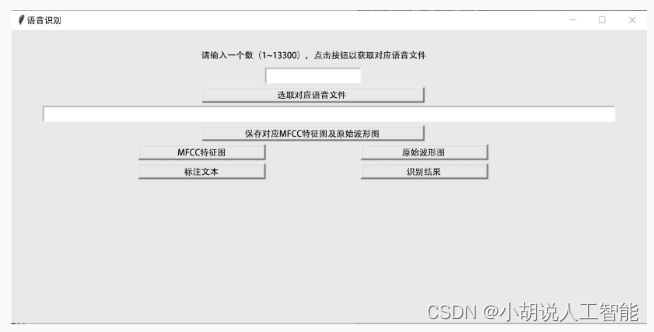
.py ファイルをコンパイルして実行すると、図に示すように初期インターフェイスが表示されます。

インターフェイスは、上から下にテキスト プロンプトと 2 つのボタンで構成されます。[音声認識]ボタンをクリックすると、図6に示すように、音声認識機能を実現するための二次インターフェイスが表示され、[方言分類]ボタンをクリックすると、方言分類を実現するための二次インターフェイスが表示されます。図 6.7 に示すように、
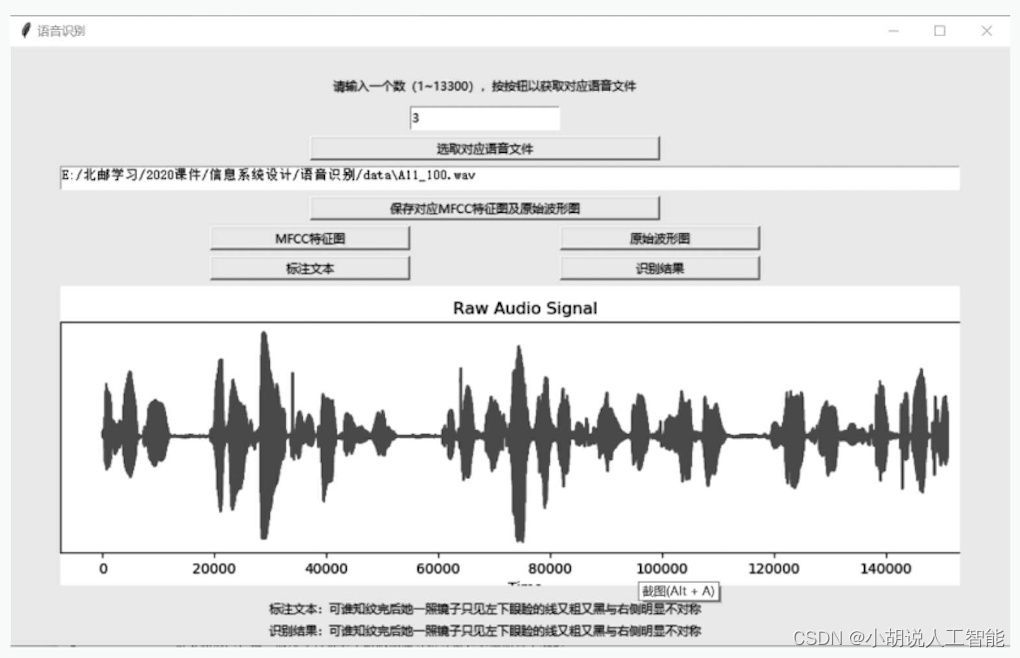
インターフェイスは上から下に、テキスト プロンプト、入力ボックス、ボタン、テキスト ボックスで構成されます。入力ボックスに番号を入力し、[対応する音声ファイルを選択]ボタンをクリックし、今回音声認識するファイルを選択し、テキストボックスにファイルパスを出力し、[対応するMFCC機能マップと元の波形チャートを保存]をクリックします。ローカルに保存するボタンをクリックすると、ローカルに保存された画像が表示されます。[MFCC 機能マップ] ボタンと [オリジナル波形] ボタンをクリックすると、ローカルに保存された画像が表示されます。[注釈テキスト] ボタンをクリックすると、対応する注釈ファイルのテキストが表示されます。 [認識結果]ボタン をクリックして予測を行い、文字予測結果を表示します。
インターフェースは上から下まで、テキスト プロンプト、ボタン、テキスト ボックスで構成されます。テキストプロンプトに従って、[音声ファイルを選択]ボタンをクリックして、今回音声認識するファイルをランダムに選択し、ファイルパスをテキストボックスに出力し、[対応するMFCC機能マップと元の波形マップを保存]ボタンをクリックして、対応する画像をローカリゼーション後に保存します; [MFCC 機能マップ] および [元の波形図] ボタンをクリックしてローカルに保存された画像を表示します; [マーク カテゴリ] ボタンをクリックしてファイルの対応するカテゴリを表示します; 予測予測されたカテゴリの結果。

2. テスト効果
GUIの音声認識テスト結果を図に示します。
GUIの方言分類テスト結果を図に示します。

プロジェクトのソースコードのダウンロード
詳細については、ブログ リソースのダウンロード ページをご覧ください。
その他の情報ダウンロード
人工知能関連の学習ルートと知識システムについて学び続けたい場合は、私の他のブログ「重い| 完全な人工知能 AI 学習 - 基本知識学習ルート」を読んでください。すべての資料は、料金を支払わずにネットワーク ディスクから直接ダウンロードできます。このブログでは、
Github の有名なオープン ソース プラットフォーム、AI テクノロジー プラットフォーム、および関連分野の専門家 (Datawhale、ApacheCN、AI Youdao、Huang Haiguang 博士など) について言及しています。関連資料は約 100G あります。友達全員を助けてください。