
本文约1200字,建议阅读5分钟本文重点介绍了平常容易忽视的三类问题:线性回归的理论依据是什么、过拟合意味着什么和模型优化的方向。序文
線形回帰は、比較的単純な機械学習アルゴリズムです。多くの書籍で最初に紹介されている機械学習アルゴリズムは、線形回帰アルゴリズムです。私が参照した中国の書籍はすべて、線形回帰の式を示し、パラメータの最適化方法を説明しています。学生はいくつかの問題を無視しますが、少なくとも著者はそれらを無視しています。したがって、この記事では、通常見落とされがちな 3 つのタイプの問題、(1) 線形回帰の理論的基礎は何か、(2) 過学習の意味、(3) モデル最適化の方向に焦点を当てます。
目次
1. 線形回帰の理論的基礎は何ですか?
2. 過学習とは何を意味しますか
3. モデル最適化の方向性
4. まとめ
線形回帰の理論的根拠
テイラー式
関数 f(x) が x0 を含む閉区間 [a,b] 上に n 次微分を持ち、開区間 (a,b) 上に (n+1) 次微分がある場合、閉区間 [ a ,b] 任意の点 x において、次の式が成立します。
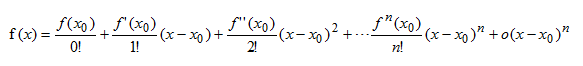
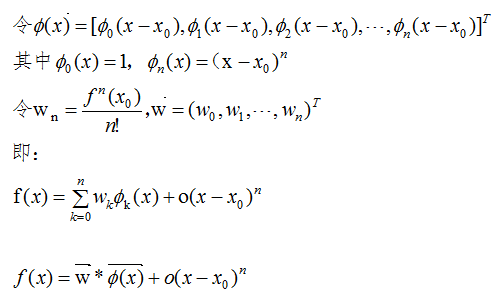
結論: 区間 [a,b] 上の任意の点について、関数値は 2 つのベクトルの内積の式によって近似できます。
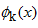 は基底関数であり、 は
は基底関数であり、 は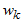 対応する係数です。
対応する係数です。
高次の式は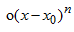 両方の値の誤差を表します (学習した線形回帰式を思い出してください)。
両方の値の誤差を表します (学習した線形回帰式を思い出してください)。
フーリエ級数

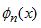 周期関数 f(x) は、基底関数を表し、
周期関数 f(x) は、基底関数を表し、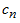 対応する係数を表し、
対応する係数を表し、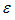 誤差を表すベクトル内積によって近似できます。
誤差を表すベクトル内積によって近似できます。
線形回帰
テイラーの公式とフーリエ級数から、基底関数の数が十分に大きい場合、ベクトル内積は関数値に限りなく近づくことがわかります。線形回帰のベクトル内積式は次のとおりです。
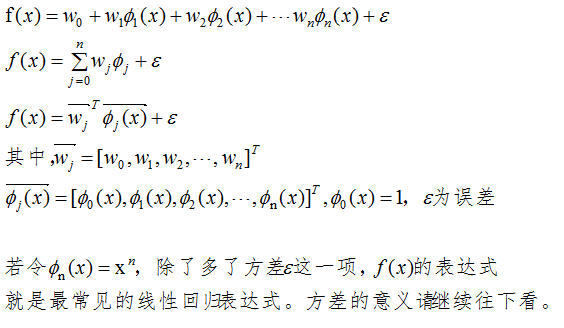
過学習問題
過学習の定義
モデル構築時の学習誤差が非常に小さいか 0 であるのに、テスト誤差が非常に大きくなるこの現象は、過学習と呼ばれます。
ガウスノイズデータモデル
ノイズのガウス ノイズ モデルを仮定すると、収集したサンプル データには実際にはノイズが含まれており、平均は 0、分散は です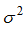 。
。
サンプル データのラベルが y1、理論上のラベルが y、ノイズが η の場合、次のようになります。
y1 = y + η、(η はガウス分布からのサンプル)
前節の線形回帰式の分散表現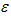 の意味は、ノイズ ガウス分布のランダム サンプリングであり、本書の線形回帰式に
の意味は、ノイズ ガウス分布のランダム サンプリングであり、本書の線形回帰式に は分散も含まれています。
は分散も含まれています。
過学習の理由
数学用語: 基底関数の数が十分に大きい場合、線形回帰式の方程式は同一になります。
以下に示すように:

機械学習の用語: モデルは非常に複雑であるため、無関係なノイズを学習します。
線形回帰の係数ベクトル間の差が比較的大きい場合、高い確率で設計されたモデルは過学習になります。数学的な観点から考えると、特定の係数が非常に大きい場合、非常に近い x 値に対して結果に大きな差が生じ、これはより明らかな過学習現象となります。
過学習に対する解決策は、複雑さを軽減することです。後ほど、対応するパブリック アカウントの記事が公開される予定です。引き続き注目してください。
モデルの最適化の方向
モデル間の違いは主にパラメータの数、パラメータのサイズ、正則化パラメータ λ に反映されます。モデルを最適化する方法は、上記の 3 つのパラメータ (カーネル関数など、これに限定されません) を調整することです。最適なモデルを見つけることです。
要約する
この記事では、テイラーの公式とフーリエ級数の例を通じて線形回帰の合理性を説明します。線形回帰式には、ガウス ノイズ モデルのランダム サンプリングである分散項目が含まれています。線形回帰式内のトレーニング データが同一の場合、次に、過学習の問題を考慮する必要がありますが、回帰係数の差が大きいことも過学習の判断材料となります。モデルの最適化にはさまざまな方法がありますが、より一般的な方法は、パラメーターの数、パラメーターのサイズ、正則化パラメーター λ を調整することです。
参考:
Christopher M.Bishop <<パターン認識と機械学習>>
編集者: 王晶
