
作者:Skanda VIvek翻译:陈之炎
校对:zrx
本文约3100字,建议阅读7分钟
对开源的大语言模型进行微调的确令人兴奋不已,相比之下,又如何微调非开源的大语言模型呢?タグ: 大規模な言語モデル
LinkedIn アカウントのフォークで、LLaMA のようなオープンソース モデルを微調整する方法を尋ねられました。企業は、AI と LLM を特定の製品に適用して、LLM がホストおよびデプロイしたソリューションを販売するビジネス ケースを探しています。なぜ ChatGPT のような非オープンソース モデルを使用しないのかと尋ねたところ、正しい答えは得られませんでした。そこで、LLM を使用して日常のビジネス上の問題を解決する方法に答えるためにこの記事を書くことにしました。
非オープンソース API の場合
ChatGPT の API を使用して特定のケースを実装しようとしたことがありますか? テキストの要約を実装したり、質問に答えたりしたい場合、または単に Web サイトでチャットボットを見つけたい場合は、通常、ChatGPT がこれらの言語タスクを適切に実行します。
一般に、非オープンソース モデルは高価すぎると考えられています。1000 トークンのコストは 0.002 ドルです。100 個のサンプルで試して、特定のアプリケーションにとって大規模な言語モデルが最良の選択であるかどうかを評価してみてはいかがでしょうか。実際、この範囲では 1 日あたり少なくとも数千回の API 呼び出しがあるため、ChatGPT API はブログで言及されているオープン ソース モデルよりもはるかに安価です。
ポイントの 1 つは、何千ものドキュメントの質問に答える必要があると仮定すると、現時点では、このデータに基づいてオープン ソース モデルをトレーニングまたは微調整する方が簡単であり、このデータを使用して微調整するのが簡単かどうかを検討することです。モデルを調整しますか?これは思ったほど単純ではないことがわかります (さまざまな理由により、ラベル付きデータの微調整に関するセクションで後述します)。
しかし、ChatGPT には、何千ものドキュメントのコンテキストに基づいて質問に答えるシンプルなソリューションがあります。すべてのドキュメントを小さなテキストの塊としてデータベースに保存します。

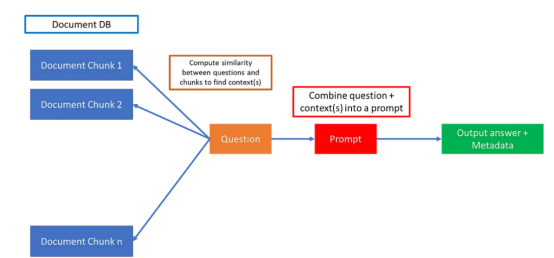
スケーリングされた LLM クエリ用のデータベースへのドキュメントのダウンロード | Skanda Vivek
データは、モデル スキーマから、質問に答えるために必要な情報をモデルに提供するドキュメント ブロックを含むデータベースにオフロードされます。
質問と文書ブロックの類似度を計算することで、文書ブロックと質問を単語埋め込みベクトルに変換し、文書ブロックと質問のコサイン類似度を計算し、最終的に該当する文書のみを選択することで、関連する文書を見つけることができます。コサイン類似度を超える特定のドキュメント ブロックは、関連するコンテキストとして扱われます。
最後に、質問とコンテキストを次のようなプロンプトに結合し、ChatGPT などの大規模な言語モデル API に組み込むことができます。


文書全体と質問をプロンプトに入力するだけではなく、小さな文書の塊に分割するのはなぜではないのかと疑問に思うかもしれません。すべてのドキュメントを 1 つのプロンプトに結合するのではなく、ドキュメントをチャンクに分割する理由は、大規模な言語モデルには最大入力長と出力長に一定の制限があるためです。ChatGPT の場合、入出力の最大長は 4096 トークンで、これはテキストの約 6 ~ 7 ページに相当します。
ドキュメント内に答えが明確に存在する場合、ドキュメントをデータベースにダウンロードし、非オープン ソース LLM API を使用してクエリを実行すると、うまく機能する可能性があります。しかし、多くの場合、ChatGPT にトピックに関する専門家の視点を提供してもらいたい場合など、次善の結果が生じる可能性があります。たとえば、米国経済の財政見通しについての推測などです。
専門分野LLM
ChatGPT や BARD を試してみて気に入らない場合は、答えは確かに少し外れています。たとえば、ChatGPT に質問する場合:
「米国経済のインフレはいつまで続くのでしょうか?」
次の答えが返されます。
AI 言語モデルとしては、特に複雑な経済システムに関して、将来を確実に予測することはできません。ただし、現在の状況を理解するのに役立つ情報と視点をいくつか提供できます。
インフレは、需要の増加や供給の制約など、さまざまな要因によって引き起こされる複雑な現象です。
残念ながら、上記の答えは十分ではありません。そしてもちろん、ジェローム・パウエルFRB議長の発言に関するニュースをChatGPTに知らせてください。しかし、それではその分野で多くの経験が得られるわけではありません。そして、話し続けると、「ジェローム・パウエル、他には誰だ!」という結論に達するかもしれません。あるいは別の専門家。
ある分野の専門家になるにはどうすればよいかを考えてみましょう。その分野に関する本を読むだけでなく、その分野の専門家と交流して経験から学ぶこともできます。ChatGPT は多数の金融書籍に基づいてトレーニングされていますが、トップの金融専門家やその他の分野固有の専門家によってトレーニングされていない可能性があります。では、LLMを金融分野の「専門家」にするにはどうすればよいでしょうか? ここで微調整が必要になります。
LLM の微調整
大規模な言語モデルの微調整について説明する前に、まず、大規模な言語モデルが登場する前に一般的であった BERT のような小規模な言語モデルの微調整について説明します。BERT や RoBERTa などのモデルの場合、微調整はコンテキストとラベルを渡すことになります。コンテキストから回答を抽出したり、電子メールをスパムとスパム以外に分類したりするなど、明確に定義されたタスク。これらについていくつかのブログ投稿を書きました。言語モデルの微調整に興味がある場合に役立つかもしれません。

大規模言語モデル (LLM) が非常に人気がある理由は、キューを変更することで複数のタスクをシームレスに実行でき、相手側で人間と会話しているのと同様のエクスペリエンスが得られるためです。次に、LLM を、ある主題の専門家になり、「人間」のように会話に参加できるように適応させる必要があります。これは、特定のタスクで BERT モデルを微調整することとはまったく異なります。
最初のオープンソースのブレークスルーの 1 つは、スタンフォード大学の研究者グループで、7B LLaMa モデル (今年初めに Meta によって公開された) を微調整し、52,000 命令で 600 ドル未満で達成し、Alpaca の使用を呼びかけました。その直後、Vicuna チームは、ChatGPT の品質の 90% を達成した 130 億パラメータ モデルをリリースしました。
最近、MPT-7B トランスフォーマーがリリースされました。これは、ChatGPT の入力サイズの 16 倍である 65,000 トークンを取り込むことができます。20万ドルの費用で9.5日間のゼロからのトレーニング。専門分野における LLM の例として、ブルームバーグは、金融分野向けに構築され、やはりゼロからトレーニングされた gpt に似たモデル、BloombergGPT をリリースしました。
オープンソース モデルのトレーニングと微調整における最近の進歩により、中小企業はカスタム LLM を使用して自社の製品を充実させています。では、専門分野で LLM を調整またはトレーニングする時期をどのように決定すればよいでしょうか?
まず、専門分野におけるクローズドソースの LLM API の制限を明確にし、クライアントが低コストでその分野の専門家とチャットできるようにする必要があります。100K 程度の命令の場合、モデルの微調整はそれほど高価ではありませんが、命令を正しく行うには慎重な検討が必要です。これは大胆なことですが、どの特殊な領域でも ChatGPT よりも大幅に優れたパフォーマンスを発揮する微調整されたモデルは思いつきませんが、ここに変曲点があり、これを行う企業は必ず報われると私は信じています。
これをきっかけに、LLM をゼロから完全にトレーニングする場合について考えてみました。これには、簡単に数十万ドル以上の費用がかかる可能性がありますが、そうするやむを得ない理由があれば、投資家は喜んで諦めるでしょう。IBM との最近のインタビューで、Hugging Face の CEO である Clem DeLancourt 氏は、近い将来、カスタムの大規模言語モデルが独自のコードベースと同じくらい一般的になるだろうし、業界の競争力を高めるのと同じくらい重要になるだろうとコメントしました。
主なポイント
特定のドメインに適用される LLM は業界で非常に価値があり、追加コストとカスタマイズ性の観点から 3 つの層に分かれています。
1.非オープンソース API + ドキュメント埋め込みデータベース: ChatGPT API の高品質を考慮すると、最初のソリューションはおそらく実装が最も簡単で、(最高ではないにしても) 十分なパフォーマンスを提供する可能性もあります。そして、それは高価でもありません!
2. LLM の微調整: LLaMA モデルの微調整による最近の進歩により、一部のドメインで ChatGPT のようなベースライン パフォーマンスを達成するには約 500 ドルかかることがわかりました。ベースライン モデルを微調整するために、約 50 ~ 100,000 の命令や会話のデータベースがある場合にも、試してみる価値があります。
3.ゼロからトレーニングする: LLaMA と最新の MPT-7B モデルで示されているように、費用は約 100 ~ 200,000 で、1 ~ 2 週間かかります。
上記を理解したら、カスタム独自ドメイン LLM アプリケーションの構築を開始してください。
原題:
LLM をいつ微調整する必要があるか?
元のリンク:
https://medium.com/towards-data-science/when-Should-you-fine-tune-llms-2dddc09a404a?source=explore---------8-58------- -------------bbc182a3_471b_4f78_ad66_68a6b5de2c39--------15
編集者: ユウ・テンカイ
校正:リン・イーリン
翻訳者プロフィール

Chen Zhiyan 氏は、北京交通大学で通信制御工学を専攻し、工学修士号を取得し、長城コンピューター ソフトウェアおよびシステム会社と大唐マイクロエレクトロニクス会社でエンジニアとして勤務し、現在は北京市のテクニカル サポーターを務めています。武威超群技術有限公司 現在、知的翻訳教育システムの運用保守に従事し、人工知能ディープラーニングや自然言語処理(NLP)について一定の経験を積んでおります。趣味は翻訳と創作が好きで、主な翻訳作品にはIEC-ISO 7816、イラク石油エンジニアリングプロジェクト、新財政主義宣言などがある。グローバルタイムズに掲載されました。空いた時間を利用して、THU Data Pie プラットフォームの翻訳ボランティア グループに参加できます。皆さんとコミュニケーションを取り、共有し、一緒に進歩していきたいと思っています。
翻訳チーム採用情報
仕事内容:厳選された外国語記事を流暢な中国語に翻訳する細心の注意が必要です。データサイエンス/統計/コンピュータを学ぶ留学生、海外で関連する仕事に従事している方、または外国語の運用能力に自信のある友人がいる方は、翻訳チームへの参加を歓迎します。
ボランティアの翻訳レベルを向上させるための定期的な翻訳トレーニング、データサイエンスの最前線に対する意識の向上、海外の友人と国内技術応用の開発について連絡を取り合うことができる、THUのデータベースの産学連携の背景などが得られます。 -調査研究はボランティアに多大な利益をもたらします開発の機会。
その他のメリット:有名企業のデータ サイエンス担当者、北京大学、清華大学、海外の有名学校の学生がすべて翻訳チームのパートナーになります。
記事末尾の「原文を読む」をクリックしてDatapaiチームに参加してください~
重版のお知らせ
転載する場合は、記事冒頭の目立つ位置に著者と出典を明記し(出典:Datapi ID:DatapiTHU)、記事末尾に目を引くQRコードを設置してください。オリジナルロゴ記事をお持ちの場合は、連絡先メールアドレスに[記事名 - 承認する公式アカウント名とID]を送信し、ホワイトリスト承認申請を行い、必要に応じて編集を行ってください。
公開後、リンクを連絡先メールアドレスに返送してください (下記を参照)。無断転載・翻案につきましては、法律に基づき法的責任を追及させていただきます。

「原文を読む」をクリックして組織を受け入れてください