フロントコンテンツ
画像本来の情報をできるだけ残す場合、画像内のノイズを取り除く処理が画像の平滑化処理(フィルタリング処理とも呼ばれます)となり、得られる画像は滑らかな画像になります(画像内のノイズをフィルタリングして除去し、比較的滑らかな画像を生成します)。
栗を取ります:
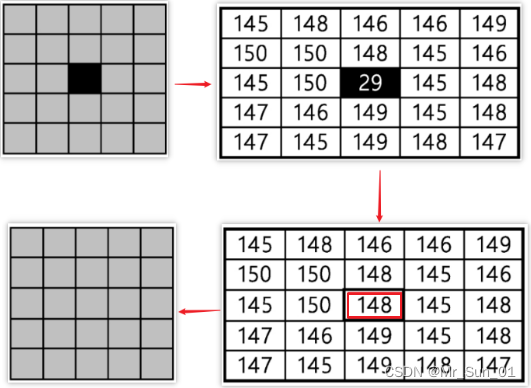
画像にノイズ点が存在します。読み込み後、ある点のピクセル値が周囲のピクセル値と大きく異なることがわかりました。周囲のピクセル点を使用して平均値を新しい値を生成し、再表示します。ノイズは消え、ページはスムーズです。
画像平滑化処理の基本原理は、ノイズが存在する画素の画素値を、その周囲に隣接する画素の近似値に一定の方法で加工することであり、本書では平均値フィルタリング、ガウスフィルタリング、メディアンフィルタリングなどの手法が紹介されています。フィルタリング。
さらに、画像の平滑化には通常、画像のぼかしが伴うため、平滑化は画像のぼかしと呼ばれることもあります。
平均フィルタリング
基本原理: 平均値フィルタリングとは、現在のピクセル値を、現在のピクセル点の周囲の N*N ピクセル値の平均値に置き換えることを指します。画像内のすべてのピクセルを走査して処理する必要があります。
ピクセルを中心とした場合、3×3の範囲の9ピクセルの平均を計算できます。また、5×5の範囲の25ピクセルの平均も計算できます。画像の境界点は、画像内に存在する周囲の点の画素平均値をとるしかありません。
5x5 の範囲の場合、計算は次のようになります。

つまり、各画素のフィルタリングを、内部値が1/25である5×5のマトリクスを乗じて平均フィルタリングの計算結果を得ることが考えられる。
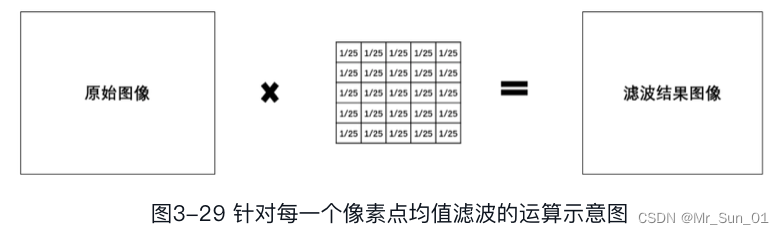
単純化すると、次のような結果になります。

OpenCV では、上図の右側の行列をコンボリューション カーネルと呼びます (画像を 1 つずつ解析する限り、このコンボリューション カーネルは非常に重要です)。一般的な形式は次のとおりです。
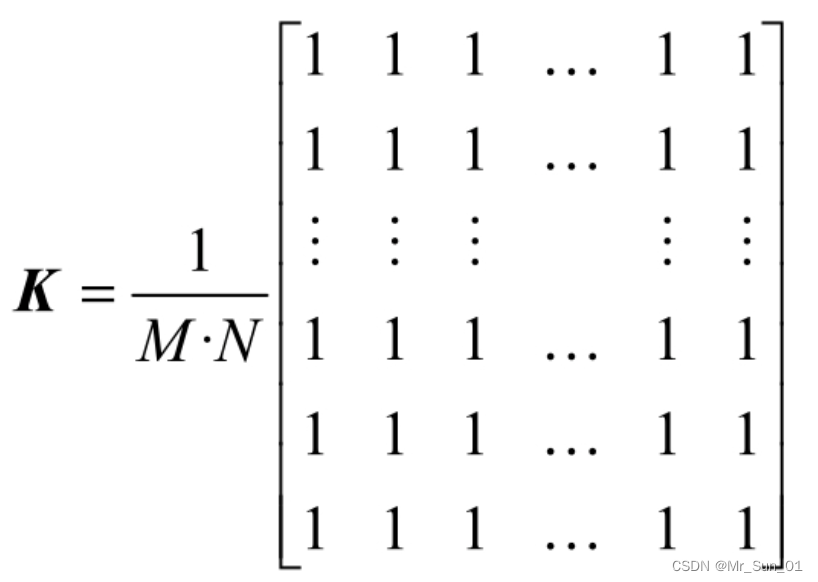
このうち、M と N はそれぞれ行列の高さと幅に対応し、一般に M と N は等しいです。M と N の値が大きいほど、より多くのピクセルが演算に関与し、現在のピクセルの計算結果はより多くの周囲の点の影響を受けます。
関数構文: dst = cv2.blur( src , ksize ,アンカー , borderType )
- dst : 平均値フィルタリング後の処理結果
- src : 元の画像
- ksize: フィルター カーネルのサイズ。上記の M と N の値です。
- アンカー : アンカー ポイント。デフォルト値は (-1,-1) です。これは、平均値を計算するためのピクセル ポイントがフィルター カーネルの中心に位置することを意味し、デフォルト値で問題ありません。
- borderType : 境界線の処理方法を決定する境界線のスタイルです。境界線のスタイルはパディング値によって異なります。パディング値は 0/255/エッジ値/特定の値で、デフォルトをそのまま使用できます。
したがって、平均フィルター関数はdst = cv2.blur( src ,ksize )のように簡略化できます。
栗の説明:
import cv2 as cv
lena_noise = cv.imread("lenaNoise.png")
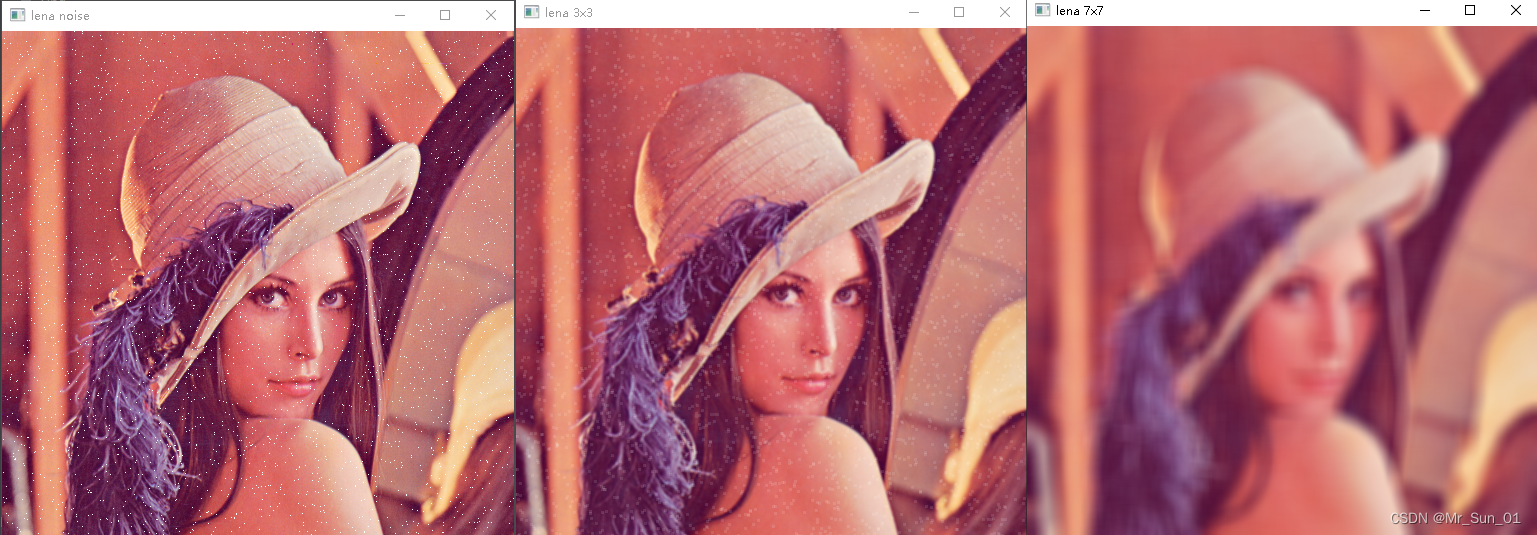
lena_3x3 = cv.blur(lena_noise, (3, 3)) # 滤波核越小,图像噪点越清晰,但图片越清晰
lena_7x7 = cv.blur(lena_noise, (17, 17)) # 滤波核越大,图像越模糊
cv.imshow("lena noise", lena_noise)
cv.imshow("lena 3x3", lena_3x3)
cv.imshow("lena 7x7", lena_7x7)
cv.waitKey()
cv.destroyAllWindows()効果は次のとおりです (元の画像、3x3、7x7 の順):
ガウスフィルター
原理: 平均値フィルタリングでは、計算行列内の各ピクセルの重みは等しくなりますが、ガウス フィルタリングでは、隣接するピクセルの重みが増加し、中心から遠く離れたピクセルの重みが減少します。
フィルターカーネルのサイズに応じて、通常は 3x3、5x5、7x7 があり、重量配分は次のとおりです。

ここでは 3x3 コンボリューション カーネルを例として取り上げます。
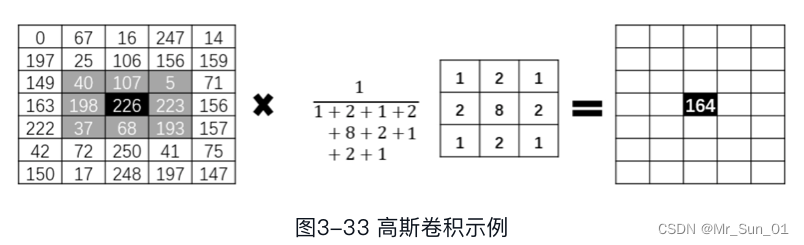
実際の計算は次のとおりです。

行列の範囲内の各点の合計に各点の重み比を乗算したものが、ガウス フィルター後の新しい値になります。
さらに、同じサイズのフィルター カーネル内の同じ位置の比率は、フィルター カーネルの重みが整数であるか小数であるかに関係なく、異なる場合があり、その比率が反映されます。
関数構文: dst = cv2.GaussianBlur( src , ksize , sigmaX , sigmaY , borderType )
- dst と src はそれぞれ出力イメージと元の入力イメージです
- ksize : フィルターカーネルのサイズ、幅、高さは奇数でなければなりません
- sigmaX : 重み比を制御する水平方向のフィルター カーネルの標準偏差。このパラメータは必須です。
- sigmaY : 垂直方向のフィルター カーネルの標準偏差。値が 0 の場合、sigmaX のみが使用されます。
- borderType : 境界線のスタイル、境界線の処理方法、デフォルト値で問題ありません
シグマが大きいほど、重み値の分布が滑らかになります。出力値に対する近傍点の影響が大きくなるほど、画像はよりぼやけます。シグマが小さいほど、重み値の分布はより急峻になります。出力値に対する近傍点の影響が小さいほど、画像の変化は小さくなります。
公式ドキュメントでは、ksize、sigmaX、および sigmaY を指定することを推奨しています。sigmaX と sigmaY をデフォルト値 0 として指定できるため、一般的な形式は次のようになります。
dst = cv2.GaussianBlur( src , ksize ,0 , 0 )
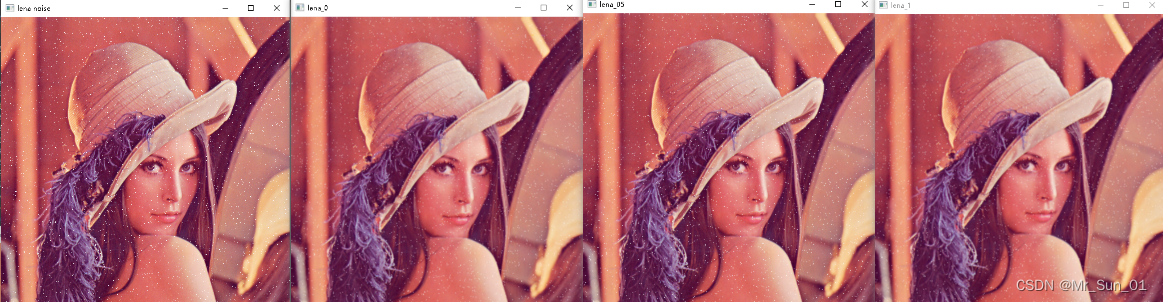
栗の説明:
import cv2 as cv
lena_noise = cv.imread("lenaNoise.png")
ksize = 3 #滤波核长宽
lena_0 = cv.GaussianBlur(lena_noise, (ksize, ksize), 0, 0) # sigmaY=sigmaY=0
lena_05 = cv.GaussianBlur(lena_noise, (ksize, ksize), 0.5, 0.5) # sigmaY=sigmaY=0.5
lena_1 = cv.GaussianBlur(lena_noise, (ksize, ksize), 1, 1) # sigmaY=sigmaY=1
cv.imshow("lena noise", lena_noise)
cv.imshow("lena_0", lena_0)
cv.imshow("lena_05", lena_05)
cv.imshow("lena_1", lena_1)
cv.waitKey()
cv.destroyAllWindows()
メディアンフィルター
基本原理: メディアン フィルターは、現在のピクセルと周囲のピクセルのピクセル値を取得して並べ替え、その中央値をピクセルのピクセル値として取得します。
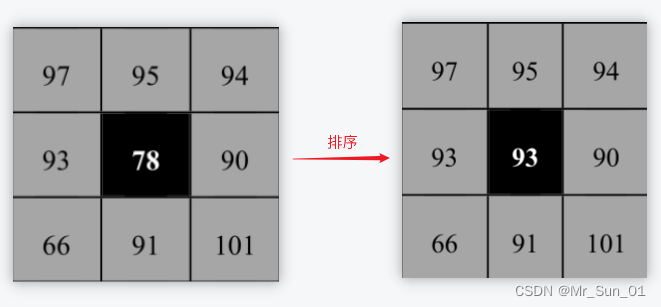
ピクセルと周囲のピクセルを並べ替えると、[66、78、90、91、93、94、95、97、101] となり、中央の値 93 を現在のピクセルの 78 に置き換えます。
関数の構文: dst = cv2.medianBlur( src , ksize)
ksize: フィルター カーネルの幅と高さは 1 より大きい基数でなければなりません
栗の説明:
import cv2 as cv
lena_noise = cv.imread("lenaNoise.png")
lena_0 = cv.medianBlur(lena_noise, 3) # 滤波核的长宽为3
cv.imshow("lena noise", lena_noise)
cv.imshow("lena_medianBlur", lena_0)
cv.waitKey()
cv.destroyAllWindows()
概要: 計算アルゴリズムとさまざまな平滑化操作の実際の効果を組み合わせると、メディアン フィルターの効果はより優れていますが、より多くの並べ替え操作が必要になります。