Demonstração da fonte: GitHub - ddiu8081/chatgpt-demo: Um repositório de demonstração baseado na API OpenAI.
Treino torcido:
 A interface de bate-papo (https://api.openai.com/v1/chat/completions) fornecida pela openai possui um modelo grande (175 bilhões de parâmetros ou algo assim) e é difícil concluir uma única solicitação http. usa o método de retorno de fluxo, saltando palavra por palavra e renderizando pouco a pouco, como o código na demonstração:
A interface de bate-papo (https://api.openai.com/v1/chat/completions) fornecida pela openai possui um modelo grande (175 bilhões de parâmetros ou algo assim) e é difícil concluir uma única solicitação http. usa o método de retorno de fluxo, saltando palavra por palavra e renderizando pouco a pouco, como o código na demonstração:
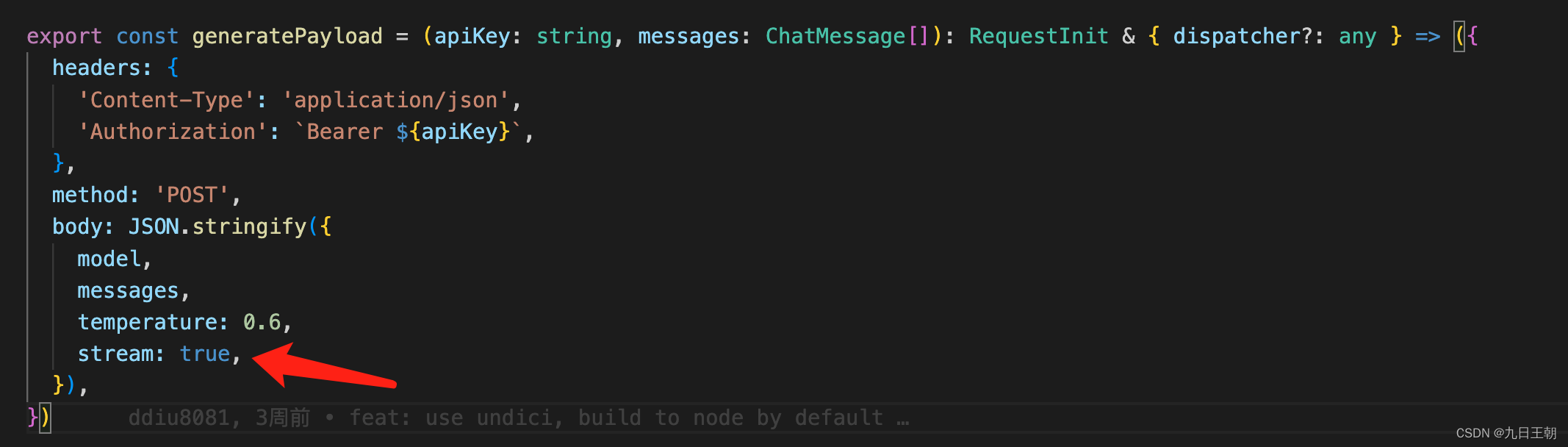
export const parseOpenAIStream = (rawResponse: Response) => {
const encoder = new TextEncoder()
const decoder = new TextDecoder()
if (!rawResponse.ok) {
return new Response(rawResponse.body, {
status: rawResponse.status,
statusText: rawResponse.statusText,
})
}
const stream = new ReadableStream({
async start(controller) {
const streamParser = (event: ParsedEvent | ReconnectInterval) => {
if (event.type === 'event') {
const data = event.data
if (data === '[DONE]') {
controller.close()
return
}
try {
// response = {
// id: 'chatcmpl-6pULPSegWhFgi0XQ1DtgA3zTa1WR6',
// object: 'chat.completion.chunk',
// created: 1677729391,
// model: 'gpt-3.5-turbo-0301',
// choices: [
// { delta: { content: '你' }, index: 0, finish_reason: null }
// ],
// }
const json = JSON.parse(data)
const text = json.choices[0].delta?.content || ''
const queue = encoder.encode(text)
controller.enqueue(queue)
} catch (e) {
controller.error(e)
}
}
}
const parser = createParser(streamParser)
for await (const chunk of rawResponse.body as any)
parser.feed(decoder.decode(chunk))
},
})
return new Response(stream)
}Semelhante a este método de processamento.
No entanto, a transmissão de fluxo não é necessariamente aplicável a todos os serviços.Se o fluxo for alterado para falso, a resposta da interface provavelmente atingirá o tempo limite.
Portanto, algumas estratégias de otimização são necessárias:
1. Reduza a inteligência
Escolha um modelo com energia mais baixa, mas tentei o modelo gpt3 e ele não fala palavras humanas

Na interface de /v1/completions, apenas text-davinci-003 é aceitável
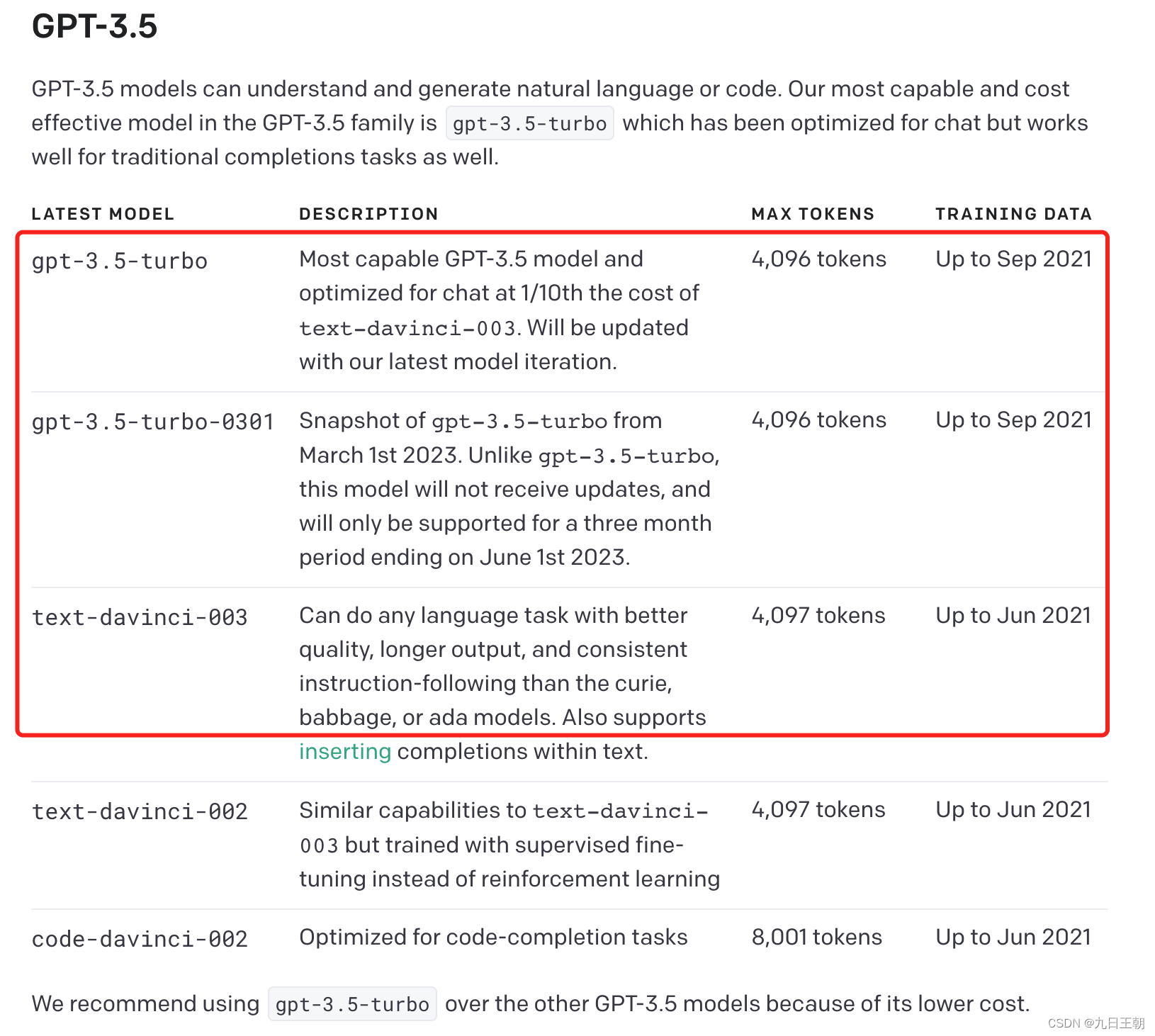
Explique a diferença entre /v1/completions e v1/chat/completions, /v1/chat/completions passa uma matriz de mensagens para concluir a associação de contexto, enquanto /v1/completions passa um parâmetro de prompt de string, mas ainda pode ser adicionado em de forma que suas respostas sejam sensíveis ao contexto.
mas! ! text-davinci-003 O custo é 10 vezes maior que o do turbo! ! ! ! ! ! !
Isso é absolutamente inaceitável! ! !

2. Reduza o parâmetro de temperatura

Isso terá um efeito de luz. Se você não precisar responder a diferentes respostas para a mesma pergunta todas as vezes, poderá reduzir esse valor ou até mesmo reduzi-lo para 0
3. Otimize o comprimento de retorno
Isso terá o maior impacto, e o teste pessoal é o mais eficaz. Adicione uma configuração de resposta antes da pergunta. Por exemplo, a resposta não deve exceder 100 palavras. Responda às perguntas a seguir de forma concisa. Isso minimizará o tempo de retorno, pois a interface é cobrada de acordo com o número de palavras chamadas e o número de palavras retornadas (ChatGPT (GPT3.5) nome do modelo oficial da API é "gpt-3.5-turbo" e "gpt-3.5- turbo-0301 ". O preço da chamada API é 10 vezes mais barato do que o modelo GPT text-davinci-003. A taxa de chamada é de $ 0,002/1000tokens, o que equivale a quase 0,1 yuan para 4000 ~ 5000 palavras. Este número inclui o número de palavras na pergunta e o resultado retornado.), então chatgpt mantém o princípio de tantos bb quanto possível, e menos para deixá-lo mais bb pode economizar dinheiro.


Observe que não há necessidade de definir max_tokens no parâmetro, pois ele apenas cortará sem pensar.Se a configuração for menor que a resposta de saída original, a resposta ficará incompleta.