アルゴリズム学習メモ(C++) - 文字列処理
文字列の基本
- 文字列標準テンプレートを使用するには、ヘッダー ファイル #include を追加する必要があります
- 初期化に関しては、文字列を直接使用して変数に値を割り当てることができます
string str = "hello world";
// or
string str = str + " !!!";
- 長さに関しては、size() と length() の 2 つのメソッドが使用できます。
- アクセス方法としては、添字アクセスとイテレータアクセスの2通りがあります。
(1) 添字アクセス:
string str = "hello world";
for (int i=0; i<str.size(); ++i){
printf("%c", str[i]);
}
(2) イテレータアクセス
string str = "hello world";
for (string::iterator it = str.begin(); it !=str.end(); ++it){
printf("%c", *it);
}
- 文字列内の要素の操作については、
(1) 指定位置にinsert()を挿入
str.insert(index, str);
最初のパラメータは挿入された位置のインデックス
、2 番目のパラメータは挿入された文字列です
(2) 指定位置の消去 Erase()
str.erase(first_char, length_of_erase);
第一引数は削除インデックスの開始位置
、第二引数は削除文字列の長さで、デフォルトでは削除します。文字列の終わり
(3) 文字列clear()を
パラメータなしで空にする
-
文字列を含む演算
文字列の加算とは文字列を連結すること
文字列の「==」「<=」「">」などの演算は辞書順に基づいて大小を比較する -
その他よく使われる関数について
(1) find()
文字列内の特定の文字または文字列を検索し、見つかった場合は対応する添字を返し、見つからない場合は string::npos を返します (int 型受信の場合は -1) )
string渗透入= "hello world";
int found = str.find("world");
if(found != string::npos){
cout << found << endl;
}
found = str.find('.');
(2) substr()
str.substr(begin_index, length)
第一引数は開始位置
、第二引数は文字列の全長です。
string str1 = "we think in generalities";
string str2 = str1.substr(3, 5);
文字列の応用例
注: 文字列適用のプロセスでは、境界の問題が頻繁に発生します
。文字列の読み取りプロセスでは、文字列にスペースが含まれている場合、cout と scanf を使用して読み取ることはできなくなり、文字列のロードは次の時点で終了します。 getline を使用すると、読み取りの中断を回避できます。
テーマ:
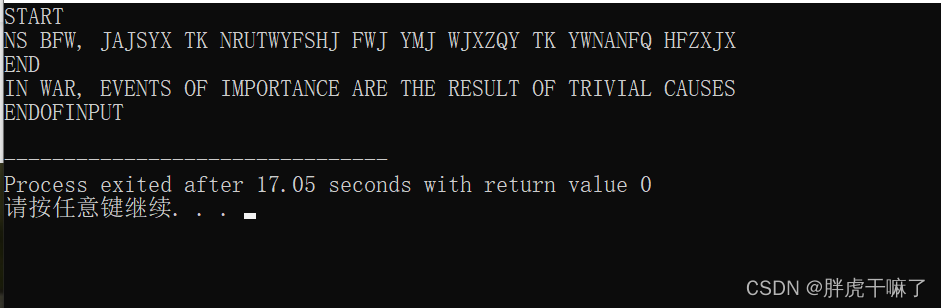
パスワード暗号化問題:
平文のA~Zの各文字をアルファベットの下5桁に相当する文字に置き換えると、V~ZはA→Fのように暗号文が得られます。平文の「 」(最後の 5 文字)は、暗号文の A ~ Z に対応します。
次に、暗号文を平文に変換する必要があります
入力形式:
暗号文の各行の最初の行は START、次の行は END で、最終的に ENDOFINPUT が読み取られるとプログラムは終了します。
出力形式は複数行で、各行にはプレーンテキストが含まれます。
# include <string>
# include <cstdio>
# include <iostream>
using namespace std;
int main(){
string str;
// the first line, deciding a new case of the end of code
while(getline(cin, str)){
if (str == "ENDOFINPUT"){
break;
}
// text which is encoded
getline(cin, str);
for (int i=0; i<str.size(); ++i){
if ( 'A' <= str[i] && str[i] <= 'Z'){
str[i] = (str[i] - 5 + 26 - 'A') % 26 + 'A';
}
}
string str1;
// eat the string "END"
getline(cin, str1);
cout << str << endl;
}
return 0;
}
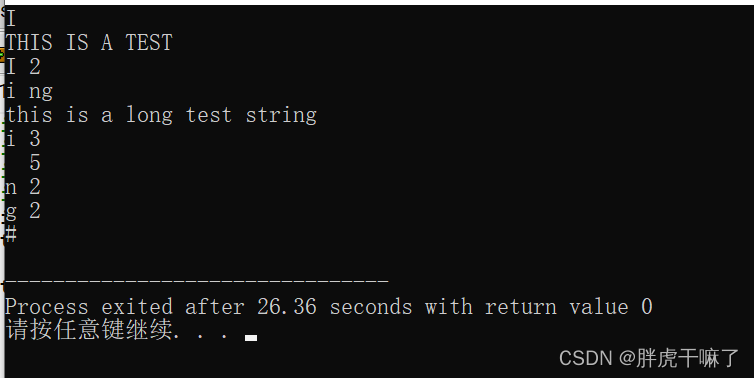
指定された文字列内の指定された文字の出現数をカウントします。
入力形式:
各テスト サンプルは 2 行で構成され、最初の行は 5 文字以下の文字列、2 行目は 80 文字以下の文字列です (スペースを含む、つまり、スペースも必要な文字です)読み取り時 '#'に到達すると入力終了
出力形式:
テストサンプルごとに、1行目の文字列と2行目の文字列の各文字の出現回数をカウントし、以下の形式で出力します。
c0 n0
c1 n1
c2 n2
# include <cstdio>
# include <iostream>
# include <string>
# include <cstring>
using namespace std;
int number[128];
int main(){
// record appearing times for every char
string str1;
string str2;
while (getline(cin, str1)){
if (str1=="#"){
break;
}
// initial the array
memset(number, 0, sizeof(number));// sizeof() returns how many bytes the array has
getline(cin, str2);
// count appearing times
for (int i=0; i<str2.size(); ++i){
number[str2[i]] += 1;
}
for (int i=0; i<str1.size(); ++i){
printf("%c %d \n", str1[i], number[str1[i]]);
// cout << str1[i] << " " << str2[str1[i]] << endl;
}
}
return 0;
}
文字列マッチング問題 - KMP アルゴリズム
テキスト文字列とパターン文字列のマッチング問題には、効率的な KMP アルゴリズムがあります。
その核心は、パターン文字列が一致しない場合、次の文字列から開始して最初から再一致させるのではなく、既存の文字列を使用することです。情報を取得すると、パターン文字列とビーズ文字列のマッチング時間を最小限に抑え、マッチング作業を迅速に完了するために、正常にマッチングできない一部の位置をスキップします。
KMP アルゴリズムの時間計算量について:
次のテーブルを取得するためにパターン文字列を 1 回走査するだけでよく、テキスト文字列が文字列の一致を取得できるように次のテーブルを走査する必要があるため、KMP アルゴリズムの時間計算量はアルゴリズムは O(m+n)
例:
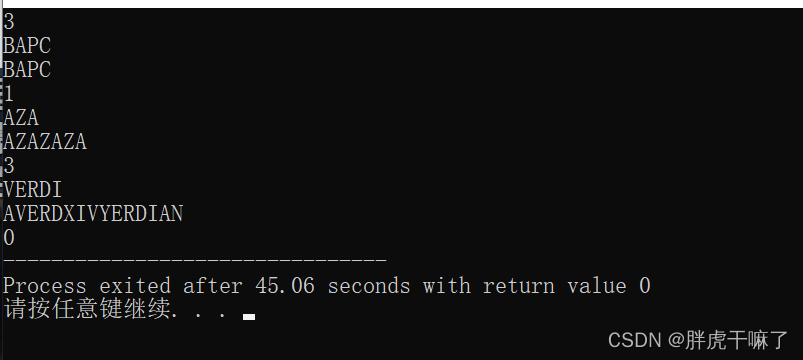
テキスト文字列内でパターンが正常に一致した回数をカウントします。
# include <cstdio>
# include <string>
# include <iostream>
using namespace std;
const int MAXN = 100;
int nextTable[MAXN];
void GetNextTable(string pattern){
int m = pattern.size();
// initial
memset(nextTable, 0, sizeof(nextTable));
int j = 0;
nextTable[j] = -1;
int i = nextTable[j];
while (j<m){
if(i==-1 || pattern[i]==pattern[j]){
++i;
++j;
nextTable[j] = i;
}
else{
i = nextTable[i];
}
}
return ;
}
int KMP(string pattern, string text){
// the number of pattern appears
int number = 0;
int m = pattern.size();
int n = text.size();
int j = 0; // match with pattern
int i = 0; // match with text
while (i < n){
if (j==-1 || text[i]==pattern[j]){
// no error just now
++i;
++j;
}
else{
// error in match
j = nextTable[j];
}
if (j == m){
// successfully matched
++number;
j = nextTable[j];
}
}
return number;
}
int main(){
int casenumber;
cin >> casenumber;
while (casenumber--){
string pattern;
string text;
cin >> pattern >> text;
// get the next table
GetNextTable(pattern);
// KMP algorithm
cout << KMP(pattern, text);
}
return 0;
}