私流
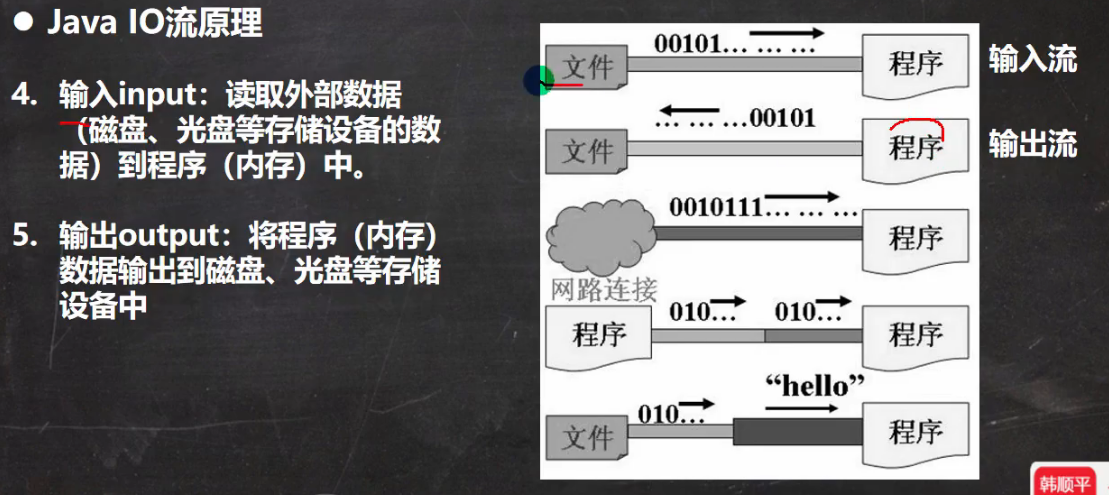
原理
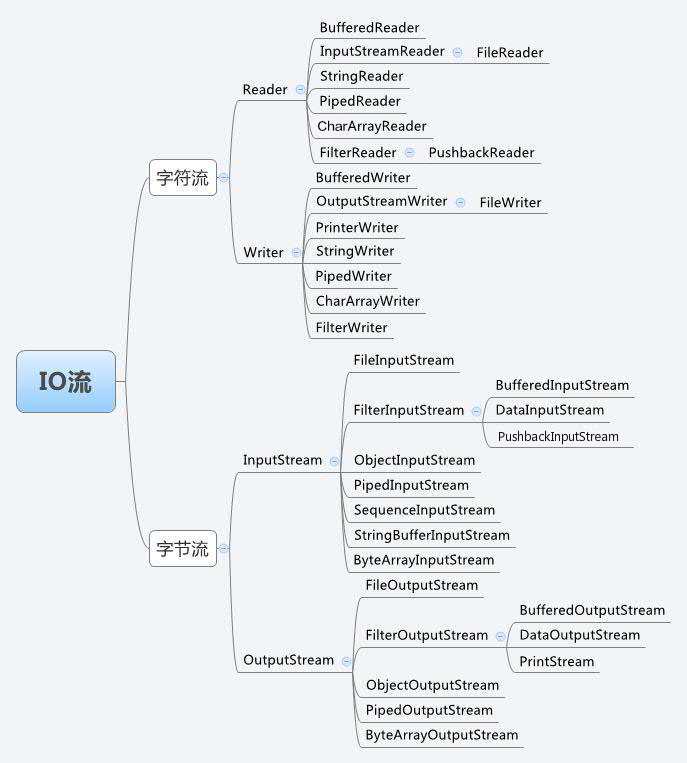
分類
バイトストリームと文字ストリーム

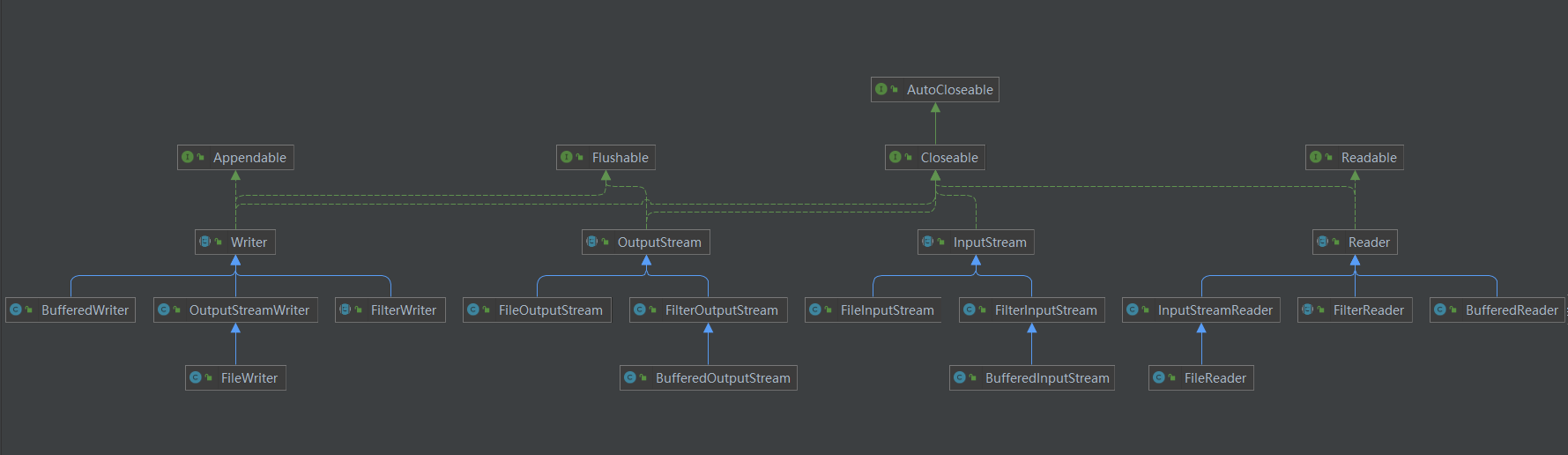
ノードストリームとラッパーストリーム
- Java IO詳細解説(5)-----パッケージングの流れ- YSOcean - Blog Garden (cnblogs.com)
- JAVA I/Oストリーム キャラクタストリームとバイトストリーム、ノードストリームと処理ストリーム(ラッパーストリーム、フィルタストリーム)、バッファストリーム_フィルタストリームとバッファストリーム、バイトストリーム間の関係_X-Dragon Misty Rain Ren Pingshengのブログ - CSDNブログ
文字ストリーム
import org.junit.jupiter.api.Test;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class CopyBytes {
public static void main(String[] args) throws IOException {
}
//单个字节的读取
@Test
public void test1() throws IOException{
FileInputStream in = null;
FileOutputStream out = null;
String path="src\\single\\in.txt";
String dpath="src\\single\\out.txt";
try {
in = new FileInputStream(path);
//String,boolean true追加;false覆盖,默认
out = new FileOutputStream(dpath,true);
int datacode;
//read()一次读取一个字节,返回读取字节的ASCII码,返回-1,表示读取完毕
while ((datacode = in.read()) != -1) {
System.out.println(datacode);//输出ASCII码 例如 a 是97 ;一个汉字是3个字节
System.out.println((char)datacode);
out.write(datacode);
}
} finally {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
}
}
}
@Test
public void test2() throws IOException{
FileInputStream in = null;
FileOutputStream out = null;
String path="src\\single\\in.txt";
String dpath="src\\single\\out.txt";
try {
in = new FileInputStream(path);
out = new FileOutputStream(dpath);
//一次读取多个字节,返回读取字节的长度
byte[] buf=new byte[3];
int datalen=0;//实际读取的长度,读取完毕返回-1
while((datalen=in.read(buf))!=-1){
System.out.println(datalen);
System.out.println(new String(buf,0,datalen));
//System.out.println(new String(buf));//这样会导致读取异常,因为当最后一次读取不够时,上一次的读取并没有清空
out.write(buf,0,datalen);
}
} finally {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
}
}
}
}
バイトストリーム
package file;
import org.junit.jupiter.api.Test;
import java.io.*;
public class FileReader_ {
public static void main(String[] args) {
}
//单个字符
@Test
public void readFile01() {
String filePath = "src\\file\\in.txt";
String dPath="src\\file\\out.txt";
FileReader fileReader = null;
FileWriter fileWriter=null;
int datacode = 0;
//1. 创建 FileReader 对象
try {
fileReader = new FileReader(filePath);
fileWriter=new FileWriter(dPath);
//循环读取 使用 read, 单个字符读取
while ((datacode = fileReader.read()) != -1) {
System.out.print(datacode);
System.out.println((char) datacode);
fileWriter.write(datacode);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fileReader != null) {
fileReader.close();
}
if(fileWriter!=null){
//这里一定要关闭,才会写入 或者flush
//close 等价于 flush + close
//底层还是字节流
fileWriter.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Test
public void readFile02() {
String filePath = "src\\file\\in.txt";
String dPath="src\\file\\out.txt";
FileReader fileReader = null;
FileWriter fileWriter=null;
int readLen = 0;
char[] buf = new char[8];
//1. 创建 FileReader 对象
try {
fileReader = new FileReader(filePath);
fileWriter=new FileWriter(dPath,true);
//循环读取 使用 read(buf), 返回的是实际读取到的字符数
//如果返回-1, 说明到文件结束
while ((readLen = fileReader.read(buf)) != -1) {
System.out.print(new String(buf, 0, readLen));
fileWriter.write(buf,0,readLen);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fileReader != null) {
fileReader.close();
}
if(fileWriter!=null){
fileWriter.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
バッファリングされたストリーム

package file;
import java.io.*;
/**
* @author 韩顺平
* @version 1.0
* 演示 bufferedReader 使用
*/
public class BufferedReader_ {
public static void main(String[] args) {
String filePath = "src\\file\\in.txt";
String dPath="src\\file\\out.txt";
//创建 bufferedReader
BufferedReader bufferedReader =null;
BufferedWriter bufferedWriter=null;
try {
bufferedReader=new BufferedReader(new FileReader(filePath));//也可以传入其他的Reader
bufferedWriter=new BufferedWriter(new FileWriter(dPath));
//读取
String line; //按行读取, 效率高
//说明
//1. bufferedReader.readLine() 是按行读取文件
//2. 当返回 null 时,表示文件读取完毕
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
bufferedWriter.write(line);
bufferedWriter.newLine();
}
} catch (Exception e) {
e.printStackTrace();
}finally {
//关闭流, 这里注意,只需要关闭 BufferedReader ,因为底层会自动的去关闭 节点流
try {
if(bufferedReader!=null) {
bufferedReader.close();
}
if(bufferedWriter!=null){
bufferedWriter.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
利点
- より使いやすくなり、基礎となる詳細が保護されます。
- バッファリングされた読み取りを使用すると、より効率的になります
- より強力な
大きなファイル
- フロントエンドがファイルをアップロードする前に、まずデータをクエリして md5 値を比較します。存在する場合は、2 回目の送信を促します。
- フラグメントが存在しない場合、フロントエンドはフラグメントでアップロードします。アップロードする前に、まずフラグメントが存在するかどうかを確認します。フラグメントが存在する場合、ブレークポイント再開を実現するためにアップロードする必要はありません
- バックエンドストレージのシャーディング
- ファイルがアップロードされたら、フラグメントを結合して完全なファイルにし、ファイル レコードをデータベースに保存します。
分散ファイルシステム
1 つのコンピュータに大量のファイルを保存することはできません。多数のファイルを保存し、多数のユーザーからの要求を受信するために、複数のコンピュータがネットワークを通じて組織され、これらの組織されたコンピュータはネットワークを通じて通信します。
利点:
1. 1 台のコンピュータのファイル システム処理能力を複数のコンピュータに拡張して、同時に処理できます。
2. 1 台のコンピュータがダウンした場合、別のコピー コンピュータがデータを提供します。
3. 各コンピュータを異なるリージョンに配置できるため、ユーザーは近くにアクセスしてアクセス速度を向上させることができます。
小さい
公式サイト:https://min.io
中国語: https://www.minio.org.cn/、http://docs.minio.org.cn/docs/
- 軽量、シンプル、強力
- 写真、ビデオ、ログファイル、バックアップデータ、コンテナ/仮想マシンイメージなどの大容量の非構造化データの保存に適しています。数kから5Tまでのサイズに対応
- 優れた読み取りおよび書き込みパフォーマンス
- MinIO クラスターは分散共有アーキテクチャを採用しており、各ノードはピアツーピア関係にあり、負荷分散され、Nginx 経由でアクセスできます。
- 冗長ストレージ、高セキュリティ
- 分散化の利点は何ですか?
ビッグデータの分野では、通常の設計概念は中心がなく分散されています。Minio 分散モードは、可用性の高いオブジェクト ストレージ サービスの構築に役立ち、これらのストレージ デバイスを実際の物理的な場所に関係なく使用できます。
異なるサーバーに分散された複数のハードディスクを組み合わせて、オブジェクト ストレージ サービスを作成します。ハードディスクは異なるノードに分散されているため、分散 Minio は単一障害点を回避します。以下に示すように:
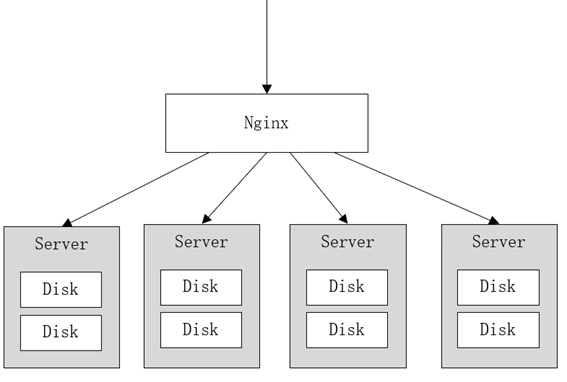
Minio は、消去コード技術を使用してデータを保護します。これは、失われたデータや破損したデータを回復するための数学的アルゴリズムです。各ノードのディスクにデータ ブロックを冗長的に保存します。使用可能なすべてのディスクがセットを形成します。この図は 8 台のハード ドライブで構成されます。ファイルがアップロードされると、ファイルは消去コードアルゴリズムの計算によりブロックに保存されます。ファイル自体が4つのデータブロックに分割されることに加えて、4つのチェックブロックが生成されます。データブロックとチェックブロックは、これらに分散して保存されます。ハードディスクは8台。
消去コードを使用する利点は、ハード ドライブの半分 (N/2) が失われた場合でもデータを回復できることです。たとえば、上記の収集で破損したハードディスクが 4 台未満の場合は、アップロードとダウンロードに影響を与えることなくデータの復旧が保証されますが、半分以上のハードディスクが破損した場合は復旧できません。