1. 同時実行性と並列性
スレッドとはプログラムを実行する最小単位であり、プロセスは 1 つまたは複数のスレッドで構成され、各スレッドも横断的に実行されます。
-
单核CPU同時実行、 、と同等宏观同时执行,微观高速切换 交替执行。マルチスレッドや高い同時実行性などの言葉は、サーバー プログラムでよく使われます。 -
Parallel は、 に相当し
多核CPU、微观同时执行パフォーマンスの上限を向上させることに重点を置いています。マルチプロセッシングは、ハイパフォーマンス コンピューティングや分散コンピューティングとより関連しています。 -
マルチプロセス: 複数の独立したプロセスを同時に実行します。各プロセスは、互いに独立した独自の独立したメモリ空間と実行コンテキストを持ちます。
-
マルチスレッド: 同じプロセス内で複数のスレッドが同時に実行されます。スレッドはプロセスの一部であり、同じプロセスのメモリ空間と実行コンテキストを共有します。
マルチエントリ/スレッドと逐次シリアル実行の違い:どちらも効果を
多进程和多线程達成でき、効率も向上しますが、逐次シリアル実行と比較すると、并行和并发减少任务间的等待时间进程/线程的切换也会引起时间损耗
マルチプロセスとマルチスレッドの違い:
- スイッチング速度: 複数のスレッドが同じプロセスのメモリ空間と実行コンテキストを共有し、
线程之间的切换比进程切换更快速オーバーヘッドが比較的小さい。 - セキュリティ: プロセスは互いに独立しているため、
多进程编程更安全マルチスレッド プログラミングでは、スレッド間の同期と相互排他をより慎重に管理し、共有データを慎重に処理し、競合状態などの同時実行の問題を防止する必要があります。
現在、コンピュータの構成は4コア8スレッドが主流であり、実際の作業タスク数は4つ以上のものがほとんどであるため、并发执行特定のタスクを交互に実行する必要があります。
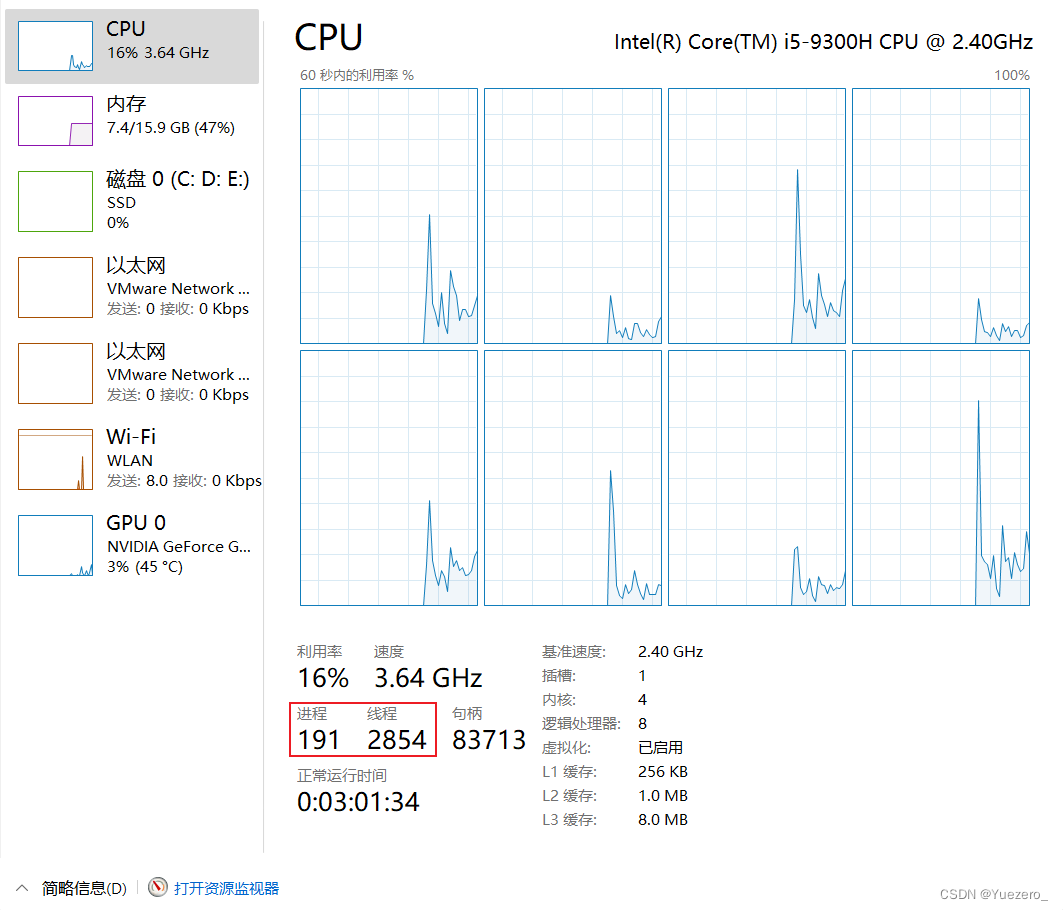
言うことはあまりありませんが、ここに例を示します (3 つの異なるデジタル シーケンスのオイラー数を同時に計算します)。 、顺序串行执行、を使用して3 つのタスクをそれぞれ計算し、タイミングと速度の測定を実行します多线程调用。多进程调用
import threading as th
import multiprocessing as mp
import time
from functools import wraps
def timer(func): # 函数的通用计时器,使用时在函数前面声明@timer即可
@wraps(func)
def inner_func():
t = time.time()
rts = func()
print(f"timer: using {
time.time() - t :.5f} s")
return rts
return inner_func
def euler_func(n: int) -> int:
res = n
i = 2
while i <= n // i:
if n % i == 0:
res = res // i * (i - 1)
while (n % i == 0): n = n // i
i += 1
if n > 1:
res = res // n * (n - 1)
return res
task1 = list(range(2, 50000, 3)) # 2, 5, ...
task2 = list(range(3, 50000, 3)) # 3, 6, ...
task3 = list(range(4, 50000, 3)) # 4, 7, ...
def job(task: list):
for t in task:
euler_func(t)
@timer
def normal(): # 顺序串行执行
job(task1)
job(task2)
job(task3)
@timer # @timer 是上面写的修饰器
def mutlthread(): # 多线程调用
th1 = th.Thread(target=job, args=(task1, ))
th2 = th.Thread(target=job, args=(task2, ))
th3 = th.Thread(target=job, args=(task3, ))
# start() ,告诉线程/进程:你可以开始干活了,程序主逻辑还得继续往下运行
th1.start()
th2.start()
th3.start()
# 到 join() 这里,咱们是指让线程/进程阻塞住咱的主逻辑,比如p1.join()是指:p1不干完活,我主逻辑不往下进行(属于是「阻塞」)
th1.join()
th2.join()
th3.join()
@timer
def multcore(): # 多进程调用
p1 = mp.Process(target=job, args=(task1, ))
p2 = mp.Process(target=job, args=(task2, ))
p3 = mp.Process(target=job, args=(task3, ))
# start() ,告诉线程/进程:你可以开始干活了,程序主逻辑还得继续往下运行
p1.start()
p2.start()
p3.start()
# 到 join() 这里,咱们是指让线程/进程阻塞住咱的主逻辑,比如p1.join()是指:p1不干完活,我主逻辑不往下进行(属于是「阻塞」)
p1.join()
p2.join()
p3.join()
if __name__ == '__main__':
print("同步串行:"); normal()
print("多线程并发:"); mutlthread()
print("多进程并行:"); multcore()
結果分析:多线程并发この方法のパフォーマンスが向上しました。
- マルチスレッドの同時実行により、コンピューターのマルチコアの利点を活用して複数のサブタスクを同時に実行でき、タスクをより効率的に完了できます。
- ただし、同期シリアル方式では、各サブタスクの完了を待ってから次のタスクに進む必要があるため、一定の時間遅延が発生します。
- マルチプロセス並列方式でも複数のサブタスクを同時に実行できますが、プロセス間の切り替えやデータ通信のオーバーヘッドが大きいため、マルチスレッド並列方式に比べて実行時間は若干長くなります。
タスクやコンピューティング環境が異なると、結果も異なる場合があることに注意してください。
同步串行:
timer: using 0.44006 s
多线程并发:
timer: using 0.30993 s
多进程并行:
timer: using 0.41000 s
2. マルチタスクモード
マルチタスクを実現するには、主に 2 つの方法があります。
1. マルチプロセッシング モード マルチプロセッシング
2. マルチスレッド モード スレッド化
複数のタスクを同時に実行することは、通常は無関係ではありませんが、相互に通信して調整する必要があります。場合によっては、タスク 1 は実行を続行する前に、一時停止してタスク 2 が完了するまで待つ必要があります。場合によっては、タスク 3 とタスク 4 を同時に実行できないこともあります。したがって、マルチプロセスおよびマルチスレッド プログラムの複雑さは、前に作成した単一プロセスおよびシングルスレッド プログラムの複雑さよりもはるかに高くなります。
たとえば、アルゴリズム C/S アーキテクチャが導入されている場合、サーバーが rtmp ビデオ ストリームをプルして、ビデオ フレーム分析、アルゴリズム推論、結果プッシュなどの複数の相互依存タスクを実行するときに、マルチスレッドおよびマルチプロセス方式を使用できます。
2.1 マルチプロセッシングモード マルチプロセッシング
プロセスはオペレーティング システムの実行エンティティであり、各プロセスは独自のメモリ空間を持ち、相互に影響を及ぼしません。一般に、プロセス数のデフォルトはコンピュータの CPU コアの数です。コンピュータにクアッドコアが搭載されている場合、コンピュータのプロセスのデフォルトは 4 です。
Python では、マルチプロセス パッケージを使用してmultiprocessingマルチプロセス タスク処理を実行します。multiprocessingこのモジュールは、Processプロセス オブジェクトを表すクラスを提供します。
# Process参数解析
multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={
}, *, daemon=None)
#group分组
#target表示调用对象!即此进程调用的函数名
#name表示进程的别名
#args表示调用对象的位置参数元组,即函数的参数
#kwargs表示调用对象的字典
# Process类的常用方法
close() 关闭进程
is_alive() 进程是否在运行
join() 等待join语句之前的所有程序执行完毕以后再继续往下运行,通常用于进程间的同步
start() 进程准备就绪,等待CPU调度
run() strat()调用run方法,如果实例化进程时没有传入target参数,这star执行默认run()方法
# Process类的常用属性
pid 进程ID
name 进程名字
次の例は、開始一个子进程(即单进程)と終了の待機を示しています。子プロセスは実際には、通常呼び出す単一の関数と同じです。
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())#用来获取 主进程 的进程ID
p = Process(target=run_proc, args=('test',))#实例化进程p,调用run_proc函数,传入参数对象args
print('Child process will start.')
p.start()#p进程准备就绪
p.join()#调用p进程,主进程等待p进程执行
print('Child process end.')
実際多个子进程(即多进程)、複数のプロセスを確立するには 2 つの方法があります。1 つは複数のプロセス オブジェクトを直接インスタンス化する多个函数随机同步运行方法、もう 1 つはプロセス プール (Pool)です。
- これを直接使用して
multiprocessing.Process()、複数のサブプロセスをインスタンス化し、さまざまな関数を呼び出すことができます。しかし、タスク(呼び出す関数)の数が多い場合、p.start()以下のように複数のプロセスオブジェクトをインスタンス化する必要があり、準備のために複数行記述するのが面倒です。
from multiprocessing import Process
import random,time
def do_task(task):
print('我正在做{}'.format(task))
time.sleep(random.randint(1,3))
def write_task(task):
print('我正在写{}'.format(task))
time.sleep(random.randint(1,3))
if __name__ == "__main__":
p1 = Process(target=do_task,args=('PPT',))
p2 = Process(target=write_task,args=('Sql',))
p1.start()
p2.start()
multiprocessing.Pool(processing_number)process_number のプロセスを含むプロセス プールをインスタンス化するために使用し、apply_async()このメソッドを使用して、処理のためにタスクをプロセス プールに非同期的に送信します。
multiprocessing.Pool = Pool(processes_number: int)#process为进程数
上記の例をプロセスプール Pool で表現すると、次のようになります。
import multiprocessing
import random
import time
from multiprocessing import Process, Queue
def do_task(q, task):
print('我正在做{}'.format(task))
q.put(task) # 将消息入队尾
time.sleep(random.randint(1, 3))
def listen_task(q, xxx):
if (not q.empty()):
print('我收到了,你做完了{}'.format(q.get())) # 从队头取出消息
else:
print('queue empty')
time.sleep(random.randint(1, 3))
if __name__ == "__main__":
q = Queue() # 注意进程通信要用multiprocessing.Queue
p1 = Process(target=do_task,args=(q, ['PPT',]))
p2 = Process(target=listen_task,args=(q, ['Sql',]))
p1.start()
p2.start()
p1.join()
p2.join()
print('All subprocesses done.')
出力は次のとおりです。
Waiting for all subprocesses done...
我正在做PPT
我正在写Sql
All subprocesses done.
プロセス通信进程不共享内存:このため、 、など进程间通信(IPC)の特定のメカニズムを使用する必要があります。標準ライブラリの Queue はスレッド間の通信しか実現できず、その get メソッドと put メソッドはブロックされています。!Queue.Queue はインプロセスのノンブロッキング キューであり、multiprocess.Queue はクロスプロセス通信キューです。マルチプロセスの前者は相互にプライベートであり、後者は各サブプロセスで共有されます。管道(Pipe)队列(Queue)
from multiprocessing import Process, Queue
def worker(q):
q.put('Hello from process') # 字符串消息入队q.put()
if __name__ == '__main__':
q = Queue() # 实例化队列q
process = Process(target=worker, args=(q,))
process.start()
process.join()
print(q.get()) # 从队头中取出消息q.get()
特記事項: MultiProcessing.Process によって作成されたプロセスには共通の親プロセスがありますが、MultiProcess.Pool によって作成されたプロセスには共通の親プロセスがありません。
MultiProcessing.Processで作成したプロセスはMultiProcessingのQueue通信を利用できますが、プロセスプールで作成したプロセスを利用する場合はManagerクラスでカプセル化されたデータ構造を利用する必要があります。
Queue.qsize() 返回队列的大小
Queue.empty() 如果队列为空,返回True,反之False
Queue.full() 如果队列满了,返回True,反之False
Queue.get([block[, timeout]]) 获取队列,timeout等待时间
Queue.get_nowait() 相当Queue.get(False)
非阻塞 Queue.put(item) 写入队列,timeout等待时间
Queue.put_nowait(item) 相当Queue.put(item, False)
2.2 マルチスレッドモードのスレッド化
threadingマルチスレッド モードでは、一度に 1 つのプロセスのみを開始しますが、このプロセスでは複数のスレッドを開始して、複数のスレッドが複数のタスクを同時に実行できるようにします。Python では、モジュール内のクラスの助けを借りてマルチスレッドを開始する必要があります。構築中に使用されるパラメーターとメソッドは、基本的にProcessと同じですThread。
# Thread参数解析
Thread(group=None, target=None, name=None, args=(), kwargs={
})
#方法
isAlive()
get/setName(name) 获取/设置线程名
start()
join()
作成するとは一个线程、関数を呼び出すことです。
import time, threading
def do_chioce(task):
print('我正在{}'.format(task))
time.sleep(random.randint(1,3))
if __name__ == "__main__":
t = threading.Thread(target=do_chioce,args=('选PPT模板',)) # 实例化线程t
t.start() # 调用t线程
作成とは多个线程、複数の関数を呼び出すことです。 do_chioce() 関数と do_content() 関数は、互いに干渉することなく、それぞれのスレッド t1 と t2 で実行されます。
import time, threading
def do_chioce(task):
print('我正在{}'.format(task))
time.sleep(random.randint(1,3))
def do_content(task):
print('我正在{}'.format(task))
time.sleep(random.randint(1,3))
if __name__ == "__main__":
t1 = threading.Thread(target=do_chioce,args=('选PPT模板',))
t2 = threading.Thread(target=do_content,args=('列PPT大纲',))
t1.start()
t2.start()
スレッド通信:スレッドはメモリを共有するため、スレッド間のデータは相互にアクセスできます。しかし、いつ多个线程同时修改数据时就会出现问题。この問題を解決するには、ロック (Lock) や条件 (Condition) などのスレッド同期ツールを使用する必要があります。
import threading
class BankAccount:
def __init__(self):
self.balance = 100 # 共享数据
self.lock = threading.Lock()
def deposit(self, amount):
with self.lock: # 使用锁进行线程同步
balance = self.balance
balance += amount
self.balance = balance
def withdraw(self, amount):
with self.lock: # 使用锁进行线程同步
balance = self.balance
balance -= amount
self.balance = balance
def deposit_money(account, amount):
for _ in range(100000):
account.deposit(amount)
def withdraw_money(account, amount):
for _ in range(100000):
account.withdraw(amount)
account = BankAccount()
# 创建两个线程,一个存款,一个取款
deposit_thread = threading.Thread(target=deposit_money, args=(account, 10))
withdraw_thread = threading.Thread(target=withdraw_money, args=(account, 5))
# 启动线程
deposit_thread.start()
withdraw_thread.start()
# 等待线程结束
deposit_thread.join()
withdraw_thread.join()
print(f"最终余额: {
account.balance}")
この例では、初期残高 100 の銀行口座オブジェクト アカウントを作成します。次に、入金用と出金用の 2 つのスレッドを作成します。各スレッドは、アカウントに対して特定の数の操作 (入金または出金) を実行します。スレッド ロックを使用することで、入金または出金操作中に残高変数へのアクセスが確実に同期され、データの競合や不一致が回避されます。
特記事項: Python スレッドは Global Interpreter Lock (GIL) によって制限されていますが、IO 集約型タスク (ネットワーク IO やディスク IO など) の場合、マルチスレッドを使用するとプログラムの実行効率が大幅に向上します。
3. OpenCVビデオストリーミングへのマルチスレッドアプローチ
スレッドはプロセス内の実行単位です。マルチスレッドとは、スレッド間で CPU の制御を迅速に切り替える (コンテキスト スイッチと呼ばれます) ことによって、複数のスレッドを同時に実行することを指します。この例では、マルチスレッドにより FPS (フレーム/秒) が増加し、より高速なリアルタイム ビデオ処理が可能になることがわかります。
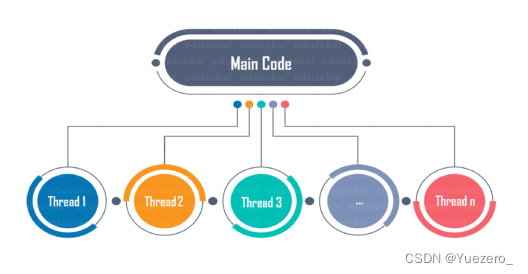
マルチスレッドによって処理が高速化される理由:
ビデオ処理コードは 2 つの部分に分かれています。カメラから次に利用可能なフレームを読み取り、顔認識のための深層学習モデルの実行など、フレーム上でビデオ処理を実行します。
次のフレームが読み取られ、マルチスレッドなしのプログラムで順次処理されます。プログラムは、次のフレームが利用可能になるまで待機してから、そのフレームに対して必要な処理を実行します。フレームの読み取りに必要な時間は、次のビデオ フレームを要求し、待機し、カメラからメモリに転送するのに必要な時間にほとんど関係します。CPU であれ GPU であれ、ビデオ フレームの計算に費やされる時間は、ビデオ処理に費やされる時間のほとんどを占めます。
複数のスレッドを備えたプログラムでは、次のフレームの読み取りと処理が連続している必要はありません。1 つのスレッドが実行されている間读取下一帧的任务、メインスレッドも実行できます使用 CPU 或 GPU 来处理最后读取的帧。このように、2 つのタスクをオーバーラップさせることで、フレームの読み取りと処理にかかる合計時間を短縮できます。
マルチスレッドを使用しないコード:
# importing required libraries
import cv2
import time
# opening video capture stream
vcap = cv2.VideoCapture(0)
if vcap.isOpened() is False :
print("[Exiting]: Error accessing webcam stream.")
exit(0)
fps_input_stream = int(vcap.get(5))
print("FPS of webcam hardware/input stream: {}".format(fps_input_stream))
grabbed, frame = vcap.read() # reading single frame for initialization/ hardware warm-up
# processing frames in input stream
num_frames_processed = 0
start = time.time()
while True :
grabbed, frame = vcap.read()
if grabbed is False :
print('[Exiting] No more frames to read')
break
# adding a delay for simulating time taken for processing a frame
delay = 0.03 # delay value in seconds. so, delay=1 is equivalent to 1 second
time.sleep(delay)
num_frames_processed += 1
cv2.imshow('frame' , frame)
key = cv2.waitKey(1)
if key == ord('q'):
break
end = time.time()
# printing time elapsed and fps
elapsed = end-start
fps = num_frames_processed/elapsed
print("FPS: {} , Elapsed Time: {} , Frames Processed: {}".format(fps, elapsed, num_frames_processed))
# releasing input stream , closing all windows
vcap.release()
cv2.destroyAllWindows()
マルチスレッドコード:
# importing required libraries
import cv2
import time
from threading import Thread # library for implementing multi-threaded processing
# defining a helper class for implementing multi-threaded processing
class WebcamStream:
def __init__(self, stream_id=0):
self.stream_id = stream_id # default is 0 for primary camera
# opening video capture stream
self.vcap = cv2.VideoCapture(self.stream_id)
if self.vcap.isOpened() is False:
print("[Exiting]: Error accessing webcam stream.")
exit(0)
fps_input_stream = int(self.vcap.get(5))
print("FPS of webcam hardware/input stream: {}".format(fps_input_stream))
# reading a single frame from vcap stream for initializing
self.grabbed, self.frame = self.vcap.read()
if self.grabbed is False:
print('[Exiting] No more frames to read')
exit(0)
# self.stopped is set to False when frames are being read from self.vcap stream
self.stopped = True
# reference to the thread for reading next available frame from input stream
self.t = Thread(target=self.update, args=())
self.t.daemon = True # daemon threads keep running in the background while the program is executing
# method for starting the thread for grabbing next available frame in input stream
def start(self):
self.stopped = False
self.t.start()
# method for reading next frame
def update(self):
while True:
if self.stopped is True:
break
self.grabbed, self.frame = self.vcap.read()
if self.grabbed is False:
print('[Exiting] No more frames to read')
self.stopped = True
break
self.vcap.release()
# method for returning latest read frame
def read(self):
return self.frame
# method called to stop reading frames
def stop(self):
self.stopped = True
# initializing and starting multi-threaded webcam capture input stream
webcam_stream = WebcamStream(stream_id=0) # stream_id = 0 is for primary camera
webcam_stream.start()
frame = []
# processing frames in input stream
num_frames_processed = 0
start = time.time()
while True:
if webcam_stream.stopped is True:
break
else:
frame = webcam_stream.read()
# adding a delay for simulating time taken for processing a frame
delay = 0.03 # delay value in seconds. so, delay=1 is equivalent to 1 second
time.sleep(delay)
num_frames_processed += 1 # count the number of frames
cv2.imshow('frame', frame)
key = cv2.waitKey(1)
if key == ord('q'):
break
end = time.time()
webcam_stream.stop() # stop the webcam stream
# printing time elapsed and fps
elapsed = end - start
fps = num_frames_processed / elapsed
print("FPS: {} , Elapsed Time: {} , Frames Processed: {}".format(fps, elapsed, num_frames_processed))
# closing all windows
cv2.destroyAllWindows()
同様に、rtsp/rtmp ストリーミングと Flask およびその他のアーキテクチャのストリーミングを実装する場合、マルチスレッドも使用できます拉流线程(读取帧)。处理线程(跑算法)推流线程(发送帧)