序文
グローバル化と多文化主義の今日、音声翻訳テクノロジーは言語の壁を乗り越える右腕となりつつあります。音声翻訳(Speech Translation、ST) は、ソース言語の音声をターゲット言語のテキストに翻訳することを目的としており、会議音声翻訳、ビデオ字幕翻訳、AR 拡張翻訳などのさまざまなシナリオで広く使用されています。音声翻訳はコミュニケーションの効率と利便性を向上させます。ビジネス会議や旅行中の日常的なコミュニケーションでも、辞書を調べたりボディランゲージでコミュニケーションしたりする必要がなくなり、母国語で話すだけでリアルタイムに翻訳され、障壁なく世界中の人々とコミュニケーションできるようになります。

01. 音声翻訳への挑戦
近年、ニューラル機械翻訳技術はますます成熟しており、2 つ以上の言語間の高品質で大規模な並列コーパスを持つことが、今日の機械翻訳モデルが良好なパフォーマンスを達成するための前提条件となっています。しかし、音声翻訳のニーズを満たす「音声文字起こし・翻訳」データは比較的少ない。英語からドイツ語への翻訳を例にとると、機械翻訳で一般的に使用される WMT16 データセット [1] には 460 万個のトレーニング データがあるのに対し、音声翻訳で最も一般的に使用される MuST-C データセット [2] にはわずか 23 万個のトレーニング データしかなく、その差は数十倍です。データの欠如により音声翻訳モデルのパフォーマンスが制限されます。これは、機械翻訳における低リソース言語の機械翻訳シナリオと非常によく似ています。低リソース言語の機械翻訳では、逆翻訳や事前トレーニングなどの技術が非常に効果的です [3][4]。では、低リソースの機械翻訳技術は音声翻訳に役立つのでしょうか?
しかし、機械翻訳技術をそのまま音声翻訳に適用するのは現実的ではありません。これは、音声とテキストの間に表現の違いがあるためです。音声データは通常、連続波形信号またはメル スペクトルとして表現されますが、テキストは離散シンボルで表現されます。この表現の違いが技術移行の困難さを高めています。したがって、音声を表すために離散記号も使用できる場合、音声翻訳の問題を解決するために機械翻訳技術を自然に使用でき、音声翻訳と機械翻訳が統合されます。
音声信号の表現とテキスト
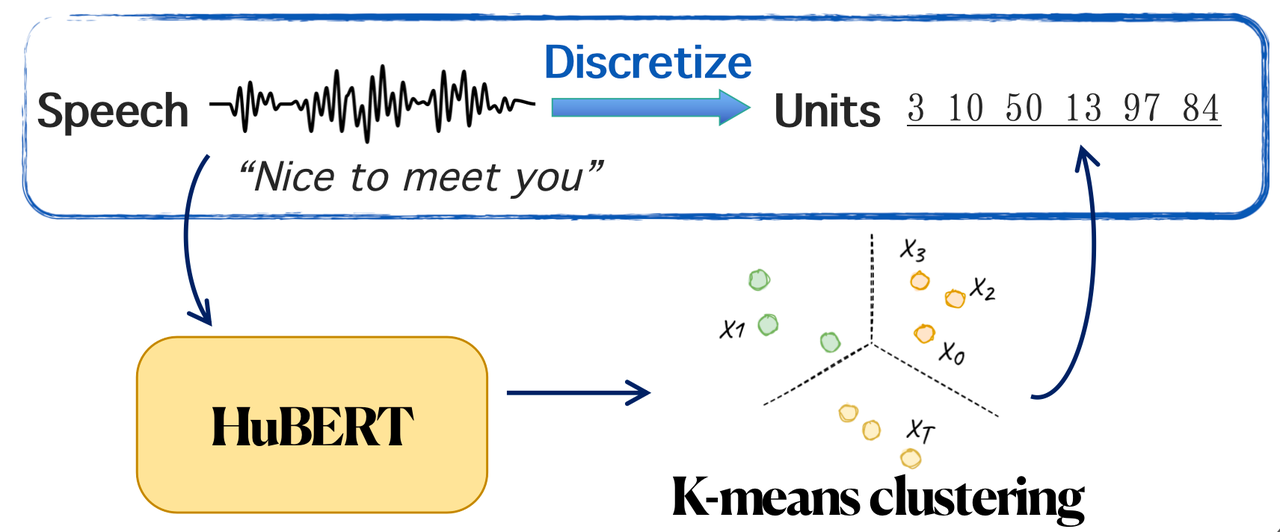
最近の研究では、教師なしの離散化された音声表現に焦点を当てた研究が増えています [5][6]。以下の図に示すように、より一般的に使用される音声離散化表現は HuBERT 離散単位 [7] です。これは、HuBERT によって抽出された連続表現に対して K-means クラスタリングを実行することによって得られます。研究によれば、この離散化表現はある程度の情報フィルタリングの役割を果たすことができ、つまり、コンテンツ情報を保持し、話者などの無関係な情報を削除することができます [6]。HuBERT によって得られた音声離散表現と低リソースの機械翻訳技術を組み合わせて音声翻訳タスクを解決する実現可能な方法です。HuBERT の研究を参照して、復旦大学と ByteDance AI Lab は共同で DUB : Discrete Unit Back - translation for Speech Translation [8] を提案し、これはACL 2023 の調査結果に含まれています。

論文リンク:
https://aclanthology.org/2023.findings-acl.447.pdf
コードリンク:
https://github.com/0nutation/DUB
ハグフェイススペース:
栄養/DUB · ハグフェイス
この記事では、音声翻訳を新しい観点から考察します。音声を離散化されたシンボルとして表すことにより、音声翻訳タスクは特別な低リソースの機械翻訳タスクと同等になり、それによって逆翻訳と事前トレーニング技術を組み合わせて音声翻訳を支援します。
これに基づいて、この文書では次の 2 つの質問と回答を行います。
-
音声の離散表現と連続表現のどちらが、音声翻訳タスクに適した入力特徴ですか?
-
機械翻訳テクノロジーを離散表現と組み合わせることで、音声翻訳に改善をもたらすことができるでしょうか?
さらに、この論文は、資源の少ない絶滅危惧言語や書かれていない言語の音声翻訳における音声離散化表現の可能性を実証します。
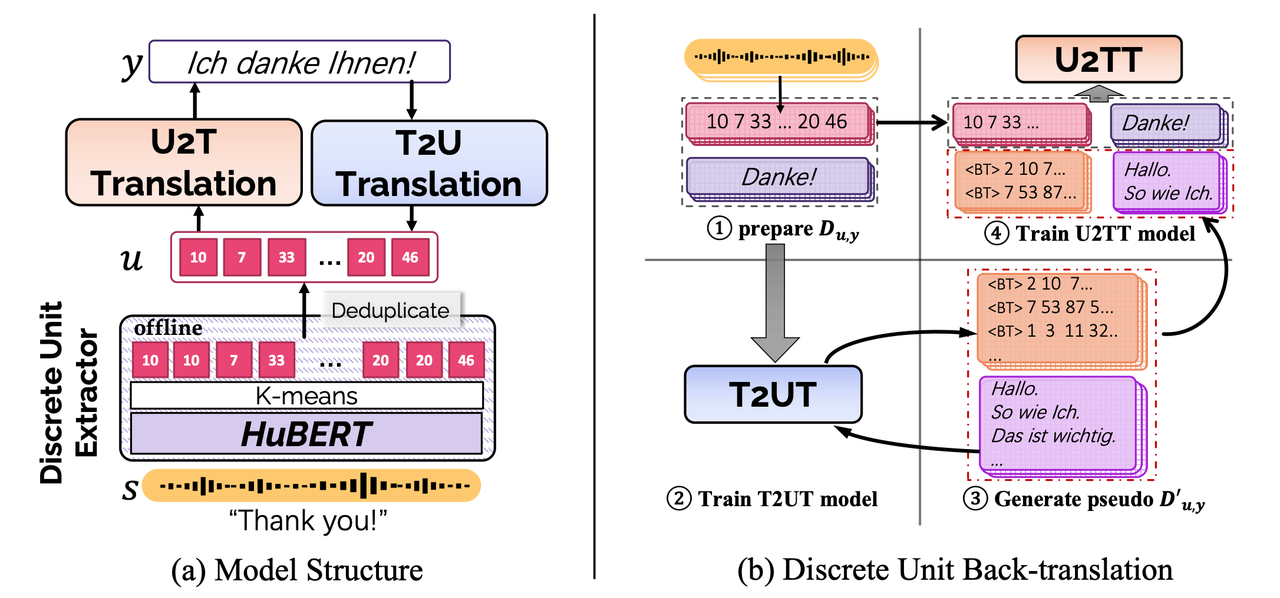
02. DUBモデルの構造とアルゴリズムの流れ
2.1 モデルの構造
DUB は、離散単位抽出器を使用して連続音声を離散化し (論文では HuBERT が使用されています)、その結果、一連の離散単位が得られます。その後、2 つの変換モデルを使用して、それぞれ単位からテキストへの翻訳 (U2TT) とテキストから単位への翻訳 (T2UT) の順方向および逆方向の翻訳プロセスを完了します。
2.2 アルゴリズム処理
上記の U2TT モデルと T2UT モデルに基づく、DUB のアルゴリズム フローは次のとおりです。
-
ステップ 1: 各音声入力に対して、対応する離散表現を抽出し、離散単位翻訳ペアを取得します。
-
ステップ 2: 上記の離散単位翻訳ペアに基づいて T2UT モデルをトレーニングします。
-
ステップ 3: ターゲット言語の大量のテキスト データ y' を導入し、それをトレーニング済み T2UT モデルに送信して、多数の擬似離散単位を作成し、それによって擬似離散単位と翻訳のペアを取得します。デコード プロセスには、ビーム サーチ、top-k サンプリング、サンプリングなどが含まれます。
-
ステップ 4: 実際の離散単位翻訳ペアと擬似離散単位翻訳ペアを混合して、最終的な U2TT モデルをトレーニングします。
03. 音声翻訳タスクにおけるDUBのパフォーマンスと分析
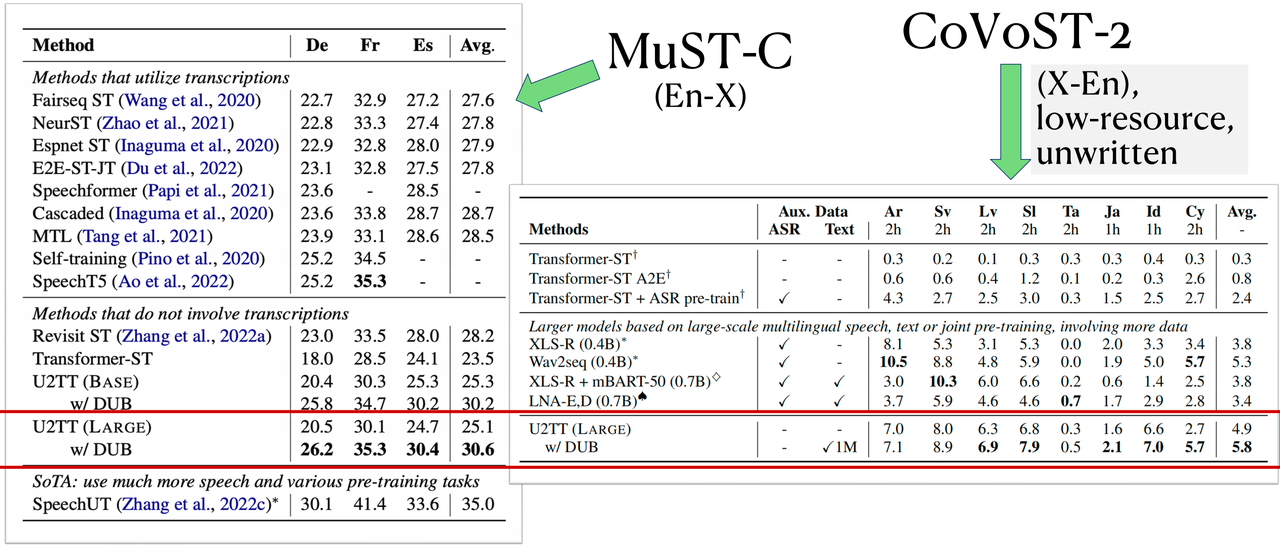
3.1 En-X 言語と X-En 言語の両方が大きな翻訳効果を達成
この論文では、下表に示すように、MuST-C データセットの En-De/Es/Fr 言語方向と CoVoST2 データセットの 21 個の X-En 言語方向について実験を行っており、ベースライン モデル U2TT と比較して、DUB は翻訳品質の大幅な向上をもたらしました。低リソースのX-En言語では、DUBのパフォーマンスは、大量の音声データとテキストデータを使用する共同事前トレーニングシステムよりもさらに優れており、低リソースの絶滅危惧言語や文字なし言語の音声翻訳におけるDUBの可能性を示しています。
3.2 音声の離散表現は、元の連続表現よりも優れた入力表現ですが、ある程度の情報の損失があります。
上で挙げた最初の質問については、音声翻訳タスクの場合、音声の離散表現と連続表現のどちらが入力特徴として優れていますか? 音声の離散表現を入力として使用する U2TT は、元の連続表現 fbank を入力として使用する Transformer-ST よりも優れていることがわかりますが、入力として Hubert 連続表現を使用する HuBERT-Transformer と比較すると、一定の情報損失があります。これは、音声の離散表現が元の連続表現よりも優れた入力表現であることを示していますが、ある程度の情報が失われています。しかし、100 万のターゲット テキスト コーパスを導入することによってのみ、この損失部分を補うことができます。

3.3 逆翻訳や事前トレーニングなどの機械翻訳テクノロジーは、音声翻訳のパフォーマンスを大幅に向上させることができます
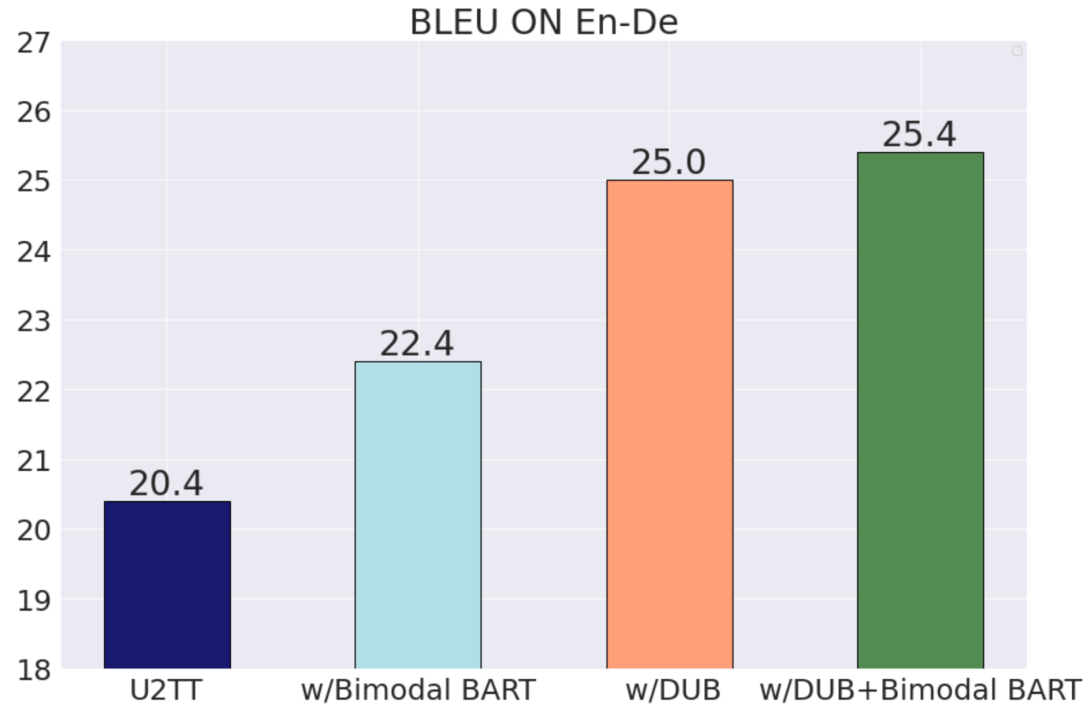
前回の記事の 2 番目の質問については、機械翻訳テクノロジーを離散表現と組み合わせることで音声翻訳に改善をもたらすことができますか? 下の図から、DUB が U2TT に対して 5 BLEU 近くの大幅な改善をもたらすことがわかり、逆変換テクノロジが非常に効果的であることがわかります。逆翻訳テクノロジーに加えて、事前トレーニングも低リソース言語の機械翻訳を改善するための一般的なテクノロジーです。また、著者は、多数のテキストおよび音声の離散ユニットに対して mBART トレーニング方法を使用してバイモーダル BART をトレーニングし、それを U2TT の事前トレーニング モデルとして使用しました。バイモーダル BART は BLEU の 2 つの改善ももたらす可能性があり、mBART 事前トレーニング方法が音声翻訳にも効果的であることを示しています。さらに、DUB とバイモーダル BART を組み合わせると、さらなるパフォーマンスの向上がもたらされます。
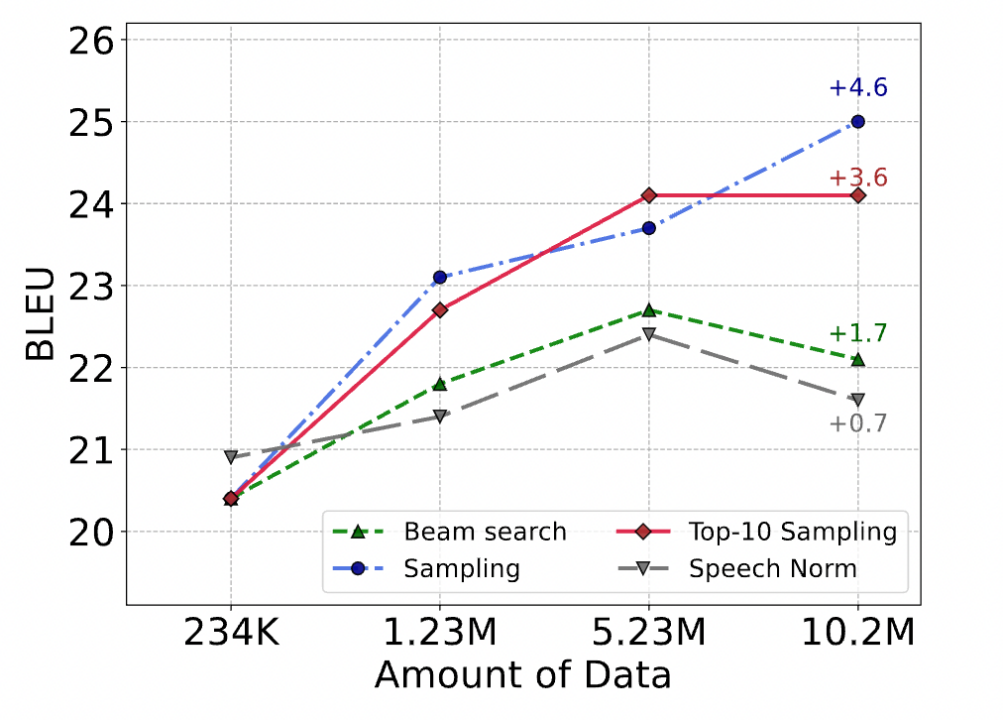
3.4 離散表現に基づく音声翻訳は機械翻訳と同様の現象を示す
T2UT モデルを使用して DUB のステップ 3 で擬似離散ユニットを生成する場合、ビーム検索、top-k サンプリング、サンプリングなどを含むさまざまなデコード戦略の使用を選択できます。以下の図に示すように、BLEU インデックスから、サンプリング > トップ 10 サンプリング > ビーム サーチの順であり、これは機械翻訳における逆変換と同じ結論、つまり、生成された疑似データのノイズが多いほど改善が大きいことがわかります。これは、離散的な音声単位がテキストと同様の構造を持つ可能性があることを示しています。
3.5 擬似離散単位には正しい意味情報がある
下図のように、T2UTとボコーダモデルを接続し、T2UTで生成した擬似離散ユニットをボコーダに送信すると、原文と同じ意味の音声が復元され、テキスト音声翻訳機能が実現されます。これは、擬似離散単位が正しい意味情報を持っていることを示しています。以下のドイツ語から英語への翻訳の例を聞いてください。

日文:そして確かに、私たちは常に消火栓を掘り出していたかもしれませんし、多くの人がそうしています。
日本語参考:そして確かに、私たちは最初からこれらの消火栓をかき集めていたかもしれませんし、多くの人がそうしています。
逆翻訳によって作成された英語のスピーチ: そして確かに、いつでも消火栓を解除することもできましたし、多くの人がそうしています。
04. 概要
この記事では、ACL 2023 の音声翻訳作業 DUB を主に紹介します。その中心的なアイデアは、音声を離散化することで音声翻訳と機械翻訳のタスクを統合し、音声翻訳を支援するために低リソースの機械翻訳テクノロジを使用することです。音声翻訳タスクの入力として音声の離散表現を提案したのは初めてです。実験結果は、入力としての離散表現の有効性と、このフレームワークの下で逆翻訳や事前トレーニングなどの機械翻訳技術を適用すると、音声翻訳のパフォーマンスが大幅に向上する可能性があることを証明しています。この論文は、音声理解タスクへの新しいアプローチを提供し、資源の少ない絶滅の危機に瀕した未文言語の可能性を実証します。
参考文献
[1] オンドジェ・ボジャール、ラジェン・チャタジー、クリスチャン・フェダーマン、イベット・グラハム、バリー・ハドー、マティアス・ハック、アントニオ・ヒメノ・イエペス、フィリップ・コーン、ヴァルバラ・ロガチェヴァ、クリストフ・モンツ、マッテオ・ネグリ、オーレリー・ネヴェオル、マリアナ・ネヴェス、マルティン・ポペル、マット・ポスト、ラファエル・ルビノ、カロリーナ・スカートン、ルシア・スペシア、マールco Turchi 他… 2016. 2016 年機械翻訳会議の調査 結果。第 1 回機械翻訳会議議事録: 第 2 巻、共有タスク ペーパー、131 ~ 198 ページ、ドイツ、ベルリン。計算言語学協会。
[2] マッティア・A・ディ・ガンジ、ロルダーノ・カットーニ、ルイーザ・ベンティヴォーリ、マッテオ・ネグリ、マルコ・トゥルキ。2019. MuST-C: 多言語音声翻訳コーパス。計算言語学協会北米支部の 2019 年会議議事録: 人間の言語技術、第 1 巻 (長文および短文)、2012 ~ 2017 ページ、ミネソタ州ミネアポリス。計算言語学協会。
[3] セルゲイ・エドゥノフ、マイル・オット、マイケル・アウリ、デヴィッド・グランジェ。2018. 逆翻訳を大規模に理解する。プロセスで。EMNLP、489 ~ 500 ページ、ベルギー、ブリュッセル。計算言語学協会。
[4] インハン・リウ、ジアタオ・グー、ナマン・ゴヤル、シアン・リー、セルゲイ・エドゥノフ、マルジャン・ガズヴィニネジャド、マイク・ルイス、ルーク・ゼトルモイヤー。2020. ニューラル機械翻訳の多言語ノイズ除去事前トレーニング。計算言語学協会のトランザクション、8:726–742。
[5] アレクセイ・バエフスキー、周裕豪、アブデルラフマン・モハメド、マイケル・アウリ。2020. wav2vec 2.0: 音声表現の自己教師あり学習のためのフレームワーク。神経情報処理システムの進歩、33:12449–12460。
[6] クシャル・ラホティア、ユージン・ハリトーノフ、ウェイニン・スー、ヨッシ・アディ、アダム・ポリアク、ベンジャミン・ボルト、トゥアン・グエン、ジェイド・コペット、アレクセイ・バエフスキー、アブデルラフマン・モハメド、他。2021. 生の音声からの生成音声言語モデリングについて。計算言語学協会のトランザクション、9:1336–1354。
[7] スー・ウェイニン、ベンジャミン・ボルト、ヤオ・フン・ヒューバート・ツァイ、クシャル・ラコティア、ルスラン・サラハトディノフ、アブデルラフマン・モハメド。2021. Hubert: 隠れユニットのマスクされた予測による自己教師あり音声表現学習。音声、音声、および言語処理に関する IEEE/ACM トランザクション、29:3451–3460。
[8] Dong Zhang、Rong Ye、Tom Ko、Wang Mingxuan、および Zhou Yaqian. 吹き替え: 音声翻訳のための離散ユニット逆翻訳. ACL 2023 の調査結果より。
TechBeat 人工知能コミュニティについて
▼
TechBeat (www.techbeat.net) は、江門ベンチャー キャピタルに属しており、中国の世界的な AI エリートが集まる成長コミュニティであり、AI 人材のためにより専門的なサービスと体験を作成し、彼らの学習と成長を加速し、伴走することを目指しています。これが、皆さんがアルの最先端の知識を学び、最新の作品を共有し、AI の進歩に向かう途中でアップグレードしてモンスターと戦うための高台となることを楽しみにしています! 詳細 >> TechBeat、世界中から中国の AI エリートが集まる学習と成長のコミュニティ