この記事は、Huawei クラウド コミュニティ「REST クライアント インターフェイスを通じて RESTful インターフェイス データを読み取り、Hive-SQL を通じて保存する DataArts Studio の機能」(著者: Zhang Haoqi) から共有されたものです。
Rest クライアントは、RESTful インターフェイス データを読み取る機能を提供します。Rest クライアントは、RESTful アドレスからデータを取得し、それをデータ統合によってサポートされるデータ型に変換し、それをストレージのためにダウンストリームの hive-sql ノードに渡します。この記事では、POST インターフェイスの一般的なシナリオを例として使用し、Rest クライアントを使用して RESTful アドレスからデータを読み取り、それをハイブ テーブルに同期する方法を示します。
この記事では、RESTful アドレスからデータを読み取り、それを MRS-Hive テーブルに同期する方法を説明します。大まかに言うと、DataArtStudio は構成収集タスクを管理し、CDM サービス経由で送信してサードパーティ API サーバーに接続し、応答メッセージは分析と保存のためにノード間パラメーターを通じて MSR-Hive-SQL に渡されます。
統合プロセスは次のとおりです。
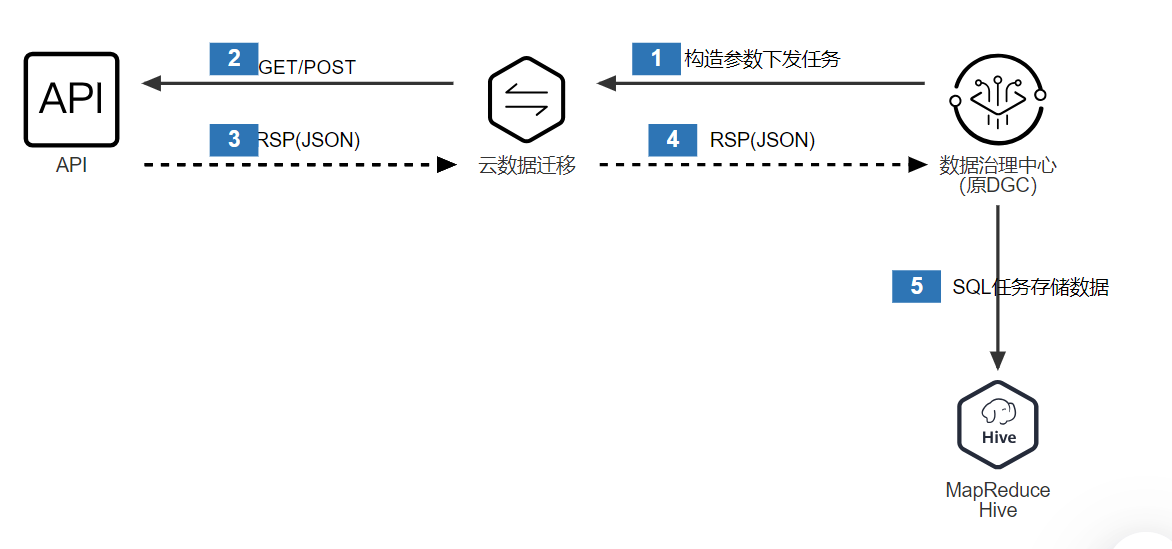
プログラムの開発プロセスは次のとおりです。
ステップ 1: DataArtsStudio で REST クライアント タスクを作成する
データ開発モジュール、Rest Client ノードの作成、認証方法、ヘッダー フィールド、リクエスト パラメーター/メッセージ本文を含む GET/POST パラメーターの入力
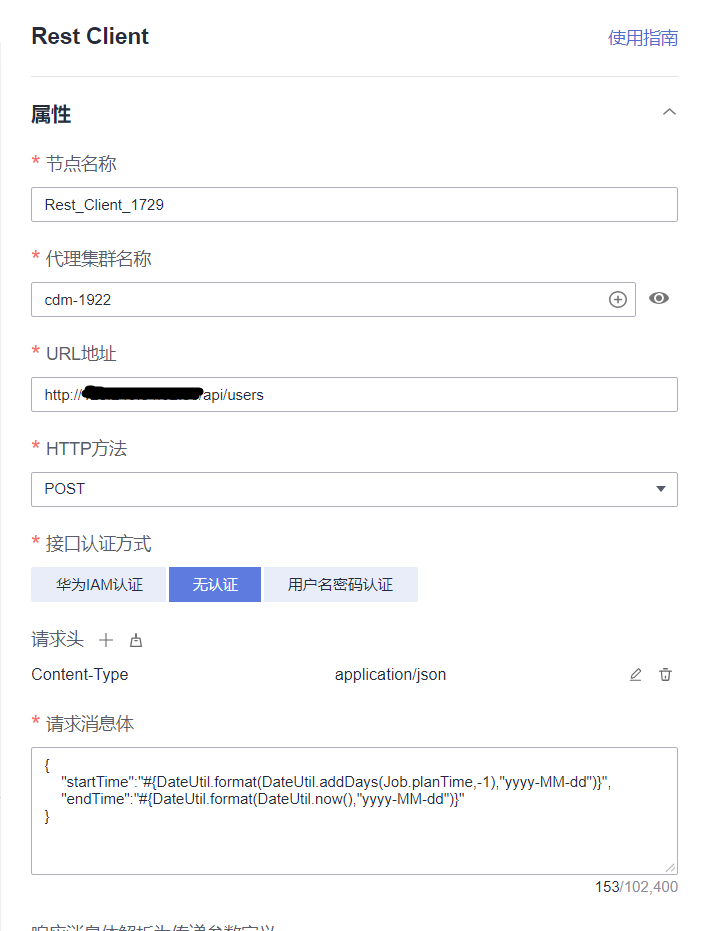
リクエストメッセージ本文の json では、時間フィルタリングパラメータの伝達などの EL 式を使用できます。
JSON Body体
{
"startTime":"#{DateUtil.format(DateUtil.addDays(Job.planTime,-1),"yyyy-MM-dd")}", "endTime":"#{DateUtil.format(DateUtil.now(),"yyyy-
MM-dd")}"
}
システム変換後のパラメータは以下のとおりです。
{
"startTime":"2023-07-11",
"endTime":"2023-07-12"
}
EL 式の詳細なリファレンスは次のとおりです。
https://support.huaweicloud.com/usermanual-dataartsstudio/dataartsstudio_01_0494.html
応答メッセージの JSON で返されるメッセージは、次の配列形式です。
応答本文:
{"data":
[
{
"
id":99467,
"proportionProjectId":"0405",
"proportionProjectName":"現場手当",
"
positionAfterTax
":40800,
"proportionDepartmentId":289
, "proportionDepartmentName":"
本社税務部",
"
vocationStatusTime
"
:
16007 29 6,"
proportionDepartmentName
":"本社メーカー部門",
"voucherStatusTime":1606209149000,
"billsNumber":"2020112402000" }
]
}
ステップ 2: MSR-Hive テーブルの作成
存在しない場合はテーブルを作成します mrs_hive_rest ( `billsNumber` STRING ,`proportionDepartmentId` BIGINT ,`voucherStatusTime` BIGINT ,`proportionProjectId` STRING ,`proportionAfterTax` BIGINT ,`id` BIGINT ,`proportionProjectName` BIGINT ,`proportionDepartmentName` STRING );
ステップ 3: DataArtsStudio は、POST インターフェイスの応答メッセージを保存するための hive-sql スクリプトを作成します。
データ開発モジュールは、次のような hive-sql スクリプトを作成します。
-- HIVE SQL
-- ********************************************************************* --
著者: zhanghaoqi
-- 作成時刻: 2023/07/12 15:50:41 GMT+08:00
-- ****** *************************************************************** --
SELECT * FROM mrs_hive_rest;
INSERT INTO mrs_hive_rest SELECT json_tuple(json, 'billsNumber', 'proportionDepartmentId', 'voucherStatusTime', 'proportionProjectId', 'proportionAfterTax', 'id', 'proportionProjectName', 'proportionDepartmentName') FROM ( SELECTexplode(split(regexp_replace(regexp_replace('${json) Str}', '\\[|\\]',''),'\\}\\,\\{','\\}\\;\\{'),'\\;')) as json)
t
;
SELECT * FROM mrs_hive_rest;
SQLスクリプトのポイントを説明します スクリプト内では、応答メッセージのJSON文字列として **${jsonStr}** を引用して解析しています(手順4でパラメータの内容を定義・変更)
応答メッセージは JSON 配列であるため、組み込みの json メソッドと string メソッドが解析に使用されます。
ステップ 4: DataArtsStudio は、スクリプトを実行するための hive-sql ノードを作成します。
hive-sql ノードを作成し、ステップ 3 のスクリプトを実行します。
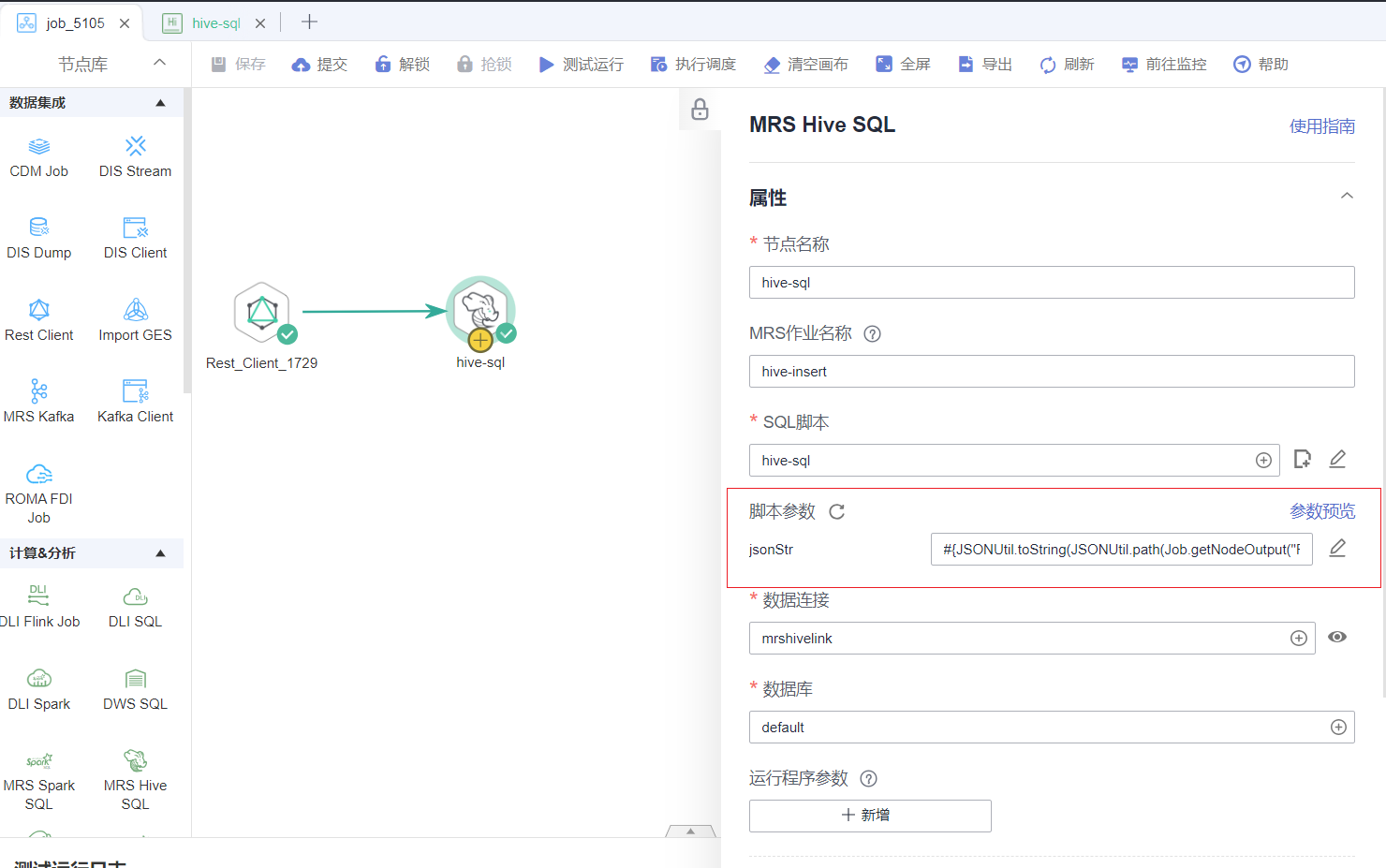
パラメータの重要なポイント: スクリプト パラメータは、SQL スクリプトで参照されるパラメータを自動的に抽出します。ここで、パラメータの内容を設定する必要があります。パラメータは EL 式を使用して、前の Rest_Client ノードの戻り値を取得します#{JSONUtil.toString(JSONUtil.path(Job.getNodeOutput("Rest_Client_1729"),"data"))} ここで、Rest_Client_1729 は前のノードのタスク名、データは前のノードのデータパス。
ステップ 5: 構成が完了したら、テスト実行検証スクリプトを実行します。
構成が完了したら、スクリプトをテストして実行し、ログをチェックして、コンテンツが期待を満たしているかどうか、および SQL ストレージが成功したかどうかを確認します。
[2023/07/12 20:13:24 GMT+0800] [情報] サーバーに正常に接続しました
[2023/07/12 20:13:24 GMT+0800] [情報] SQL:SELECT * FROM mrs_hive_rest; を実行しています。
[2023/07/12 20:13:24 GMT+0800] [情報] SQL が正常に実行されました
[2023/07/12 20:13:24 GMT+0800] [情報] SQL 実行結果の読み取り
[2023/07/12 20:13:24 GMT+0800] [情報] 最初の 0 行:
[2023/07/12 20:13:24 GMT+0800] [情報] SQL 実行結果の読み取りに成功しました
[2023/07/12 20:13:24 GMT+0800] [情報]
[2023/07/12 20:13:24 GMT+0800] [情報] SQL:INSERT INTO mrs_hive_rest SELECT json_tuple(json, 'billsNumber', 'proportionDepartmentId', 'voucherStatusTime', 'proportionProjectId', 'proportionAfterTax', 'id', 'proportionProjectName', '割合部門名') FROM (
SELECTexplode(split(regexp_replace(regexp_replace('[{"billsNumber":"2020092299467","proportionDepartmentId":289,"voucherStatusTime":1600758794000,"proportionProjectId":"0405","proportionAfterTax" :40800, "id": 9946 7、"proportionProjectName": "現場手当", "proportionDepartmentName": "本社税務部"}, {"billsNumber": "2020112402000", "proportionDepartmentId": 296, "voucherStatusTime": 1606209149000, "proportionProject Id": "040102", "proportionAfterTax" : 20000, "id": 102000, "proportionProjectName": "040102 _機能部門の従業員の年収", "proportionDepartmentName": "本社メーカー部門"}]', '\[|\]',''),'\}\,\{','\}\;\{'),'\; '))
json として)t;
[2023/07/12 20:13:38 GMT+0800] [情報] SQL が正常に実行されました
[2023/07/12 20:13:38 GMT+0800] [情報] SQL 実行結果の読み取り
[2023/07/12 20:13:38 GMT+0800] [情報] SQL 実行結果の読み取りに成功しました
[2023/07/12 20:13:38 GMT+0800] [情報]
[2023/07/12 20:13:38 GMT+0800] [情報] SQL:SELECT * FROM mrs_hive_rest; を実行しています。
[2023/07/12 20:13:38 GMT+0800] [情報] SQL が正常に実行されました
[2023/07/12 20:13:38 GMT+0800] [情報] SQL 実行結果の読み取り
[2023/07/12 20:13:38 GMT+0800] [情報]最初の 2 行:
2020092299467,289,1600758794000,0405,40800,99467,null,本社税務部
2020112402000,296,1606209149000,040102,20000,102000,null,メーカー本社部門
[2023/07/12 20:13:38 GMT+0800] [情報] SQL 実行結果の読み取りに成功しました
[2023/07/12 20:13:38 GMT+0800] [情報]
スクリプトが正常に実行され、保存が成功したことを確認します。
[クラウドカフェQ&A] HUAWEI CLOUDのビッグコーヒーアーキテクトが戦場に座り、アプリケーションの革新について話し、質問し、開発者向けのカスタムギフトを獲得するために交流する第2号〜https://bbs.huaweicloud.com/forum/thread-0234124103999807029-1-1.html
クリックしてフォローして、Huawei Cloudの最新テクノロジーについて初めて学びましょう~
2023 年に最も需要の高い 8 つのプログラミング言語: PHP は好調、C/C++ の需要は鈍化 Programmer's Notes CherryTree 1.0.0.0 リリース CentOS プロジェクトは「誰にでもオープン」と宣言 MySQL 8.1 と MySQL 8.0.34 正式リリース GPT-4 はますますバカになっている?精度率は 97.6% から 2.4% に低下しました Microsoft: Windows 11 で Rust Meta を使用するための取り組みを強化 拡大: オープンソースの大規模言語モデル Llama 2 をリリースし、商用利用は無料です C# と TypeScript の父が最新の オープンソース プロジェクトを発表しました: TypeChat は レンガを移動したくないが、要件も満たしたいと考えていますか? おそらく、この 5,000 スター GitHub オープン ソース プロジェクトが役立つかもしれません - MetaGPT Wireshark の 25 周年記念、最も強力なオープン ソース ネットワーク パケット アナライザー