下のカードをクリックして「CVer」公式アカウントをフォローしてください
AI/CV 重量物乾物、初めて納品
クリックして入力 —>【Transformer】WeChat交流グループ
魚と羊はアウフェイ寺院から送られ
、Qubit (QbitAI) から複製されました。
Microsoft の大型モデルの新しいアーキテクチャがTransformer に正式に挑戦します!
論文のタイトルは明るく次のように書かれています。
Retentive Network (RetNet): 大規模モデルの分野における Transformer の後継。

Retentive Network: 大規模言語モデル用の Transformer の後継
コード: https://github.com/microsoft/unilm
論文: https://arxiv.org/abs/2307.08621
この論文では、アテンションに代わる新しいリテンション メカニズムを提案しています。マイクロソフト アジア研究所と清華大学の研究者は、彼らの「野心」を否定せず、大胆にこう言いました。
RetNet は、優れたスケーリング結果、並列トレーニング、低コストの導入、効率的な推論を実現します。
これらの特性により、このインフラストラクチャは、大規模言語モデルにおける Transformer の強力な後継者になります。
実験データは、言語モデリング タスクに関して次のことも示しています。
RetNet は Transformer に匹敵する複雑さを実現できます
8.4 倍高速な推論
メモリ使用量を 70% 削減
優れた拡張性を備えています
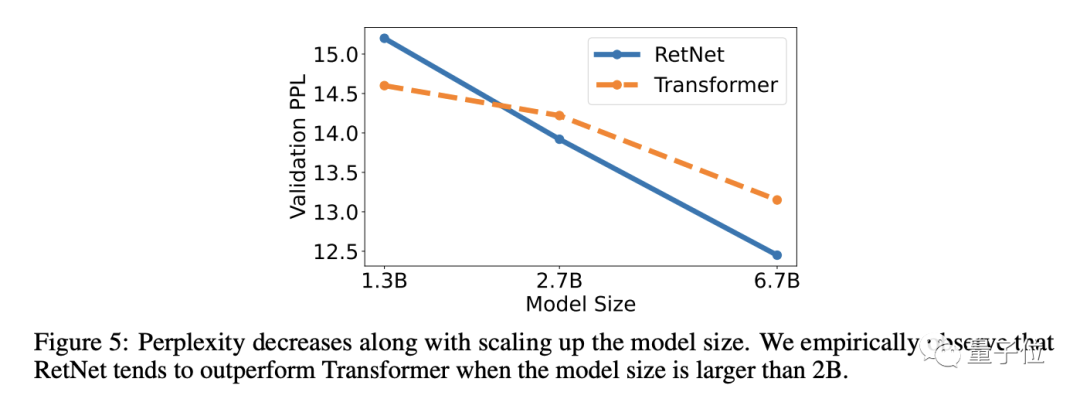
また、モデルのサイズが一定のスケールより大きい場合、RetNet は Transformer よりも優れたパフォーマンスを発揮します。
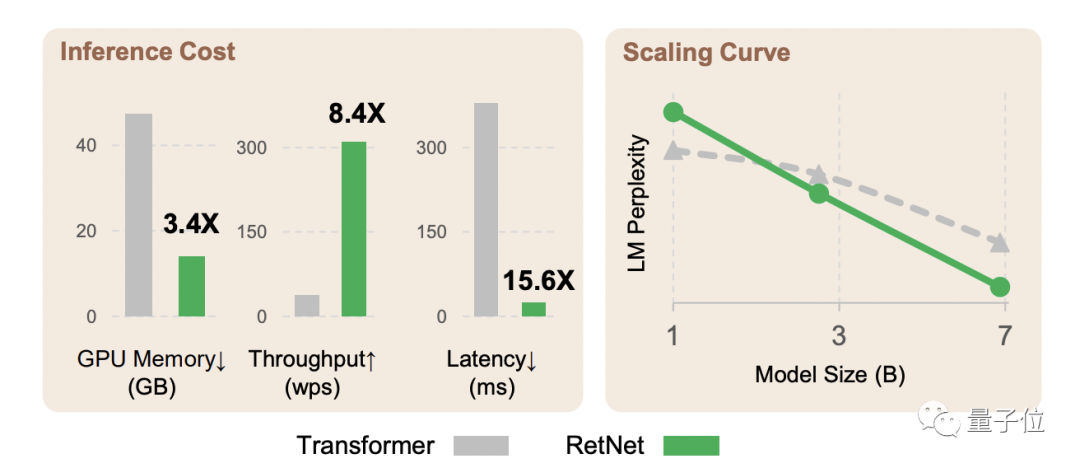
トランスフォーマーは本当に「後継モデルあり」?詳しくは一緒に見ていきましょう。
「不可能な三角形」を解く
大規模な言語モデルにおける Transformer の重要性は疑いの余地がありません。OpenAI の GPT シリーズ、Google の PaLM、Meta の LLaMA などはすべて Transformer をベースにしています。
しかし、Transformer は完璧ではありません。その並列処理メカニズムは非効率的な推論を犠牲にしており、各ステップの複雑さは O(N) です。Transformer はメモリ集約型のモデルであり、シーケンスが長ければ長いほど、より多くのメモリを消費します。 。
それまでは、誰もが Transformer を改善し続けることを考えていなかったわけではありません。ただし、主な研究の方向性はやや無視されています。
直線的な注意は推論のコストを削減できますが、パフォーマンスは低くなります。
リカレント ニューラル ネットワークは並行してトレーニングできません。
言い換えれば、これらのニューラル ネットワーク アーキテクチャの前には「不可能な三角形」があり、その 3 つの角は、並列トレーニング、低コストの推論、優れたスケーラビリティを表しています。
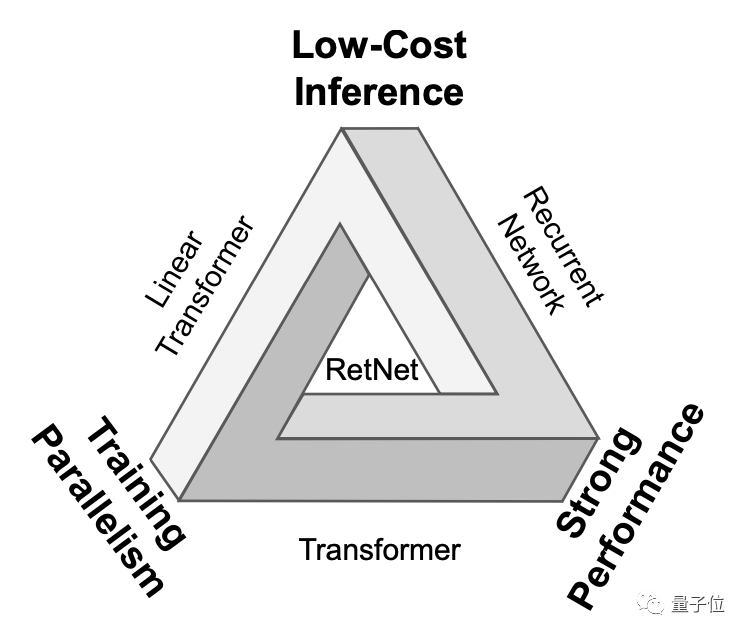
RetNet の研究者がやりたいことは、不可能を可能にすることです。
具体的には、Transformer に基づいて、RetNet はマルチスケール保持メカニズムを使用して、標準のセルフ アテンション メカニズムを置き換えます。
標準の自己注意メカニズムと比較して、保持メカニズムにはいくつかの特徴があります。
位置依存の指数関数的減衰項がソフトマックスの代わりに導入され、計算が簡素化され、前のステップの情報が減衰の形で保存されます。
複素数空間を導入して位置情報を表現し、絶対または相対位置コーディングを置き換え、再帰形式に簡単に変換します。
さらに、保持メカニズムではマルチスケール減衰率を使用することでモデルの表現力が向上し、GroupNorm のスケーリング不変性を利用して保持層の数値精度が向上します。
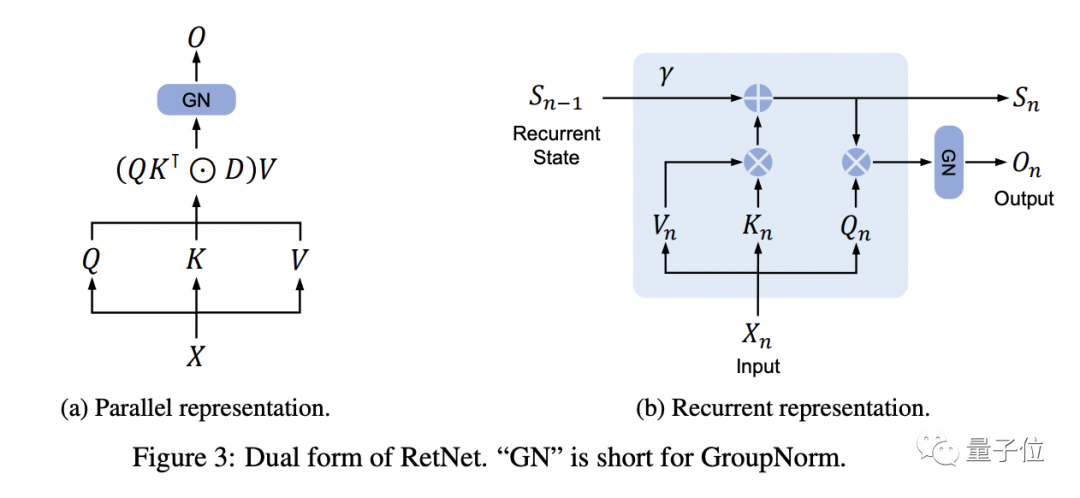
△ RetNetの二重表現
各 RetNet ブロックには、マルチスケール保存 (MSR) モジュールとフィードフォワード ネットワーク (FFN) モジュールの 2 つのモジュールが含まれています。
ホールド メカニズムは、次の 3 つの形式でのシーケンスの表現をサポートします。
平行
再帰
ブロック再帰、つまり並列表現と再帰表現のハイブリッド形式では、入力シーケンスをブロックに分割し、ブロック内で並列表現に従って計算を実行し、ブロック間で再帰表現に従います。
その中で、並列表現により、RetNet は Transformer と同様に GPU を効率的に並列トレーニングに利用することができます。
再帰的表現により O(1) の推論複雑さが達成され、メモリ使用量と待ち時間が削減されます。
チャンク再帰により、長いシーケンスをより効率的に処理できます。
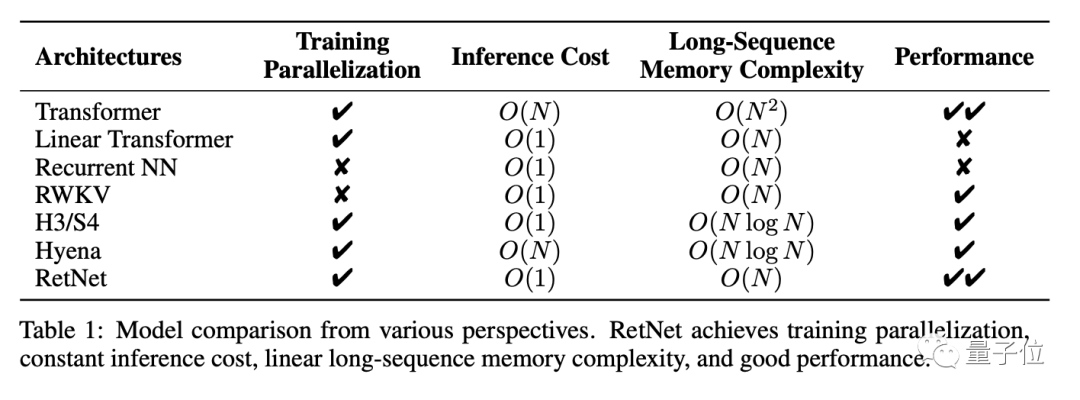
このように、RetNet は「不可能な三角形」を可能にします。以下は、RetNet と他のインフラストラクチャの比較結果です。
言語モデリング タスクに関する実験結果は、RetNet の有効性をさらに証明しています。
結果は、RetNet が Transformer (PPL、言語モデルの品質を評価する指標、小さいほど優れている) と同様のパープレキシティを達成できることを示しています。
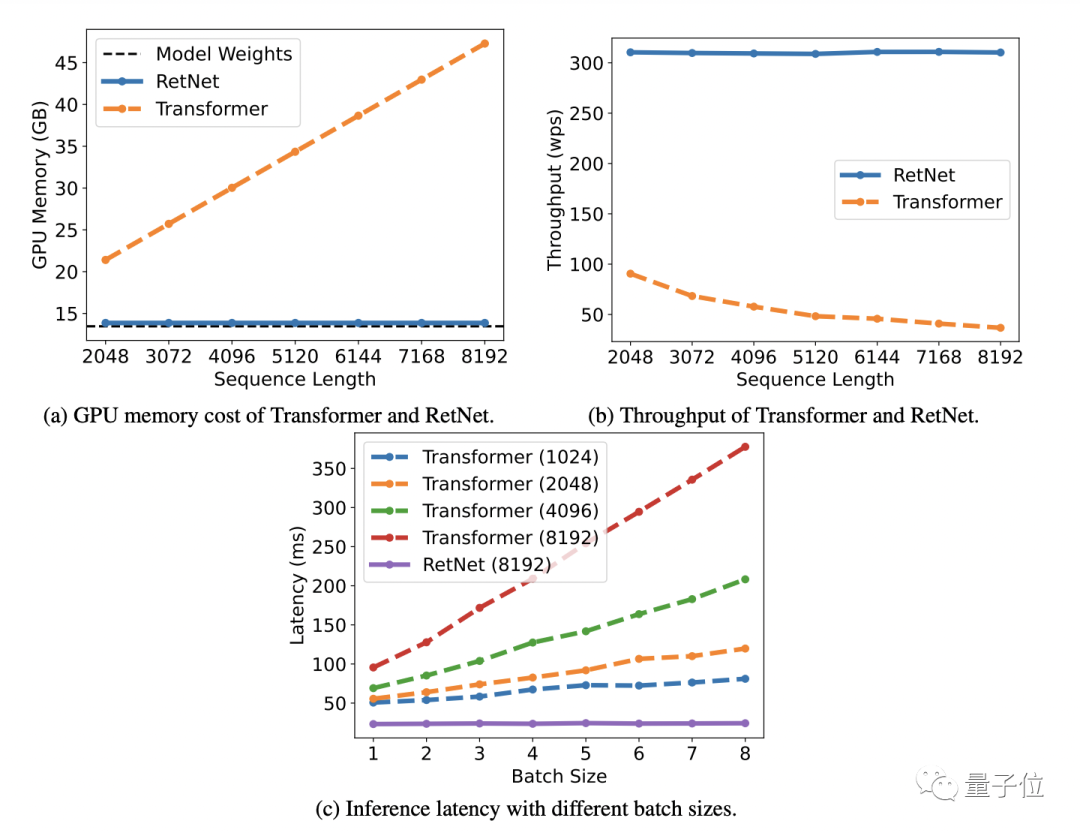
同時に、モデルパラメータが 70 億、入力シーケンス長が 8k の場合、RetNet の推論速度はTransformer の推論速度の8.4 倍に達し、メモリ使用量は70% 削減されます。
トレーニング プロセス中、RetNet はメモリ節約効果と加速効果の点で標準の Transformer+FlashAttend よりも優れたパフォーマンスを発揮し、それぞれ25 ~ 50%と7 倍に達します。
RetNet の推論コストはシーケンスの長さに依存せず、推論のレイテンシはバッチ サイズの影響を受けないため、高いスループットが可能になることに言及する価値があります。
さらに、モデル パラメーターのサイズが 20 億を超える場合、RetNet は Transformer よりも優れたパフォーマンスを発揮します。
研究チーム
RetNet の研究チームはマイクロソフト アジア研究所と清華大学から構成されています。
孫宇濤と東李として一緒に。
Sun Yutao 氏は清華大学コンピュータ サイエンス学部の学部生で、現在マイクロソフト アジア研究所でインターンをしています。
Dong Li は、マイクロソフト アジア研究所の研究者です。注目を集めた論文「10億個のトークンを記憶できるトランスフォーマー」の著者の一人でもある。
RetNet 論文の責任著者は Wei Fruit です。彼は Microsoft Asia Research Institute のグローバル研究パートナーであり、10 億トークンの Transformer も彼の研究チームからのものです。
論文アドレス:
https://arxiv.org/abs/2307.08621
クリックして入力 —>【コンピュータビジョン】WeChat交換グループ
ICCV/CVPR 2023 ペーパーとコードのダウンロード
バックグラウンド返信: CVPR2023、 CVPR 2023 論文のコレクションとオープンソース論文のコードをダウンロードできます。
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理するのは簡単ではありません、いいねして見てください![]()