
諌めではなく過去を認識し、未来を知ることで追求できる
C++プログラマー、2024年電子情報系大学院生
目次
7. 主キーの問題として自己インクリメント ID を推奨する
8. MySQL の自動インクリメント主キーが連続しない理由
24. クラスター化インデックスと非クラスター化インデックス
30. 通常インデックスと独自インデックスはどのように選択すればよいですか?
1. 3つのパラダイム
1NF (第 1 正規形): 属性 (テーブル内のフィールドに対応) は分割できなくなりました。つまり、このフィールドは 1 つの値のみになり、他の複数のフィールドに分割できません。1NF はすべてのリレーショナル データベースの最も基本的な要件です。つまり、リレーショナル データベースで作成されるテーブルは第一正規形を満たす必要があります。
2NF (第 2 正規形): 2NF では、データベース テーブル内の各インスタンスまたは行が一意に区別できる必要があります。2NF は 1NF に基づいて列を追加します。この列は主キーと呼ばれ、非主属性は主キーに依存します。鍵。
3NF (第 3 正規形): 2NF に基づいて、3NF では、各列が間接的に関連するのではなく、主キー列に直接関連していること、つまり、他のテーブルの非主キー情報が存在しないことが要求されます。
開発プロセスでは、3 つのパラダイムを満たす必要はありませんが、クエリ効率を向上させるために、テーブル内で他のテーブルのフィールドが冗長になる場合があります。
2. DML文とDDL文の違い
-
DML は Data Manipulation Language (Data Manipulation Language) の略で、主にテーブル レコードの挿入、更新、削除、クエリなど、データベース内のテーブル レコードの操作を指し、開発者が日常的に最も頻繁に使用する操作です。 。
-
DDL(Data Definition Language)とは、Data Definition Languageの略で、簡単に言うと、データベース内のオブジェクトを作成、削除、変更するための操作言語です。DML 言語との最大の違いは、DML はテーブルの内部データのみを操作し、テーブルの定義や構造の変更、その他のオブジェクトを含まないことです。DDL ステートメントはデータベース管理者 (DBA) によってよく使用され、一般の開発者によって使用されることはほとんどありません。
3. 主キーと外部キーの違い
-
主キー: データ行を一意に識別するために使用されます。繰り返しはできません。空のスペースは許可されません。また、テーブルには主キーを 1 つだけ持つことができます。
-
外部キー: 他のテーブルとの関係を確立するために使用されます。外部キーは、別のテーブルの主キーです。外部キーは重複することも、null にすることもできます。テーブルには複数の外部キーを持つことができます。
4. ドロップ、削除、切り捨ての違い
(1) 使い方の違い
-
drop(データの破棄):drop table 表名、テーブルを削除するときに使用される、テーブル構造を直接削除します。 -
truncate(データのクリア):truncate table 表名、テーブル内のデータのみを削除し、データを挿入するときに、テーブル内のデータをクリアするときに使用される自動インクリメント ID が再び 1 から始まります。 -
delete(delete data):delete from 表名 where 列名=值行のデータを削除するには、where句を追加しない場合、truncate table 表名効果は同様です。
(2) 異なるデータベース言語に属している
-
truncateおよび がdropDDL (データ定義言語) ステートメントである場合、操作はすぐに有効になり、元のデータはロールバック セグメントに配置されず、ロールバックできず、操作によってトリガーはトリガーされません。 -
deleteこのステートメントは DML (データベース操作言語) ステートメントであり、この操作はロールバック セグメントに配置され、トランザクションがコミットされた後に有効になります。
(3) 実行速度が異なる
-
deleteコマンドを実行するとデータベースbinlogログが生成され、ログ記録に時間がかかりますが、データのロールバックやリカバリが容易になるメリットもあります。 -
truncateコマンド実行時にはデータベースログが生成されないため、deleteコマンドよりも高速です。さらに、テーブルの自己インクリメント値がリセットされ、インデックスが元のサイズに戻ります。 -
dropこのコマンドは、テーブルによって占有されているすべてのスペースを解放します。
一般的に: drop> truncate>delete
5. インフラストラクチャー
以下の図は MySQL の簡単なアーキテクチャ図であり、クライアントの SQL ステートメントが MySQL 内でどのように実行されるかがよくわかります。
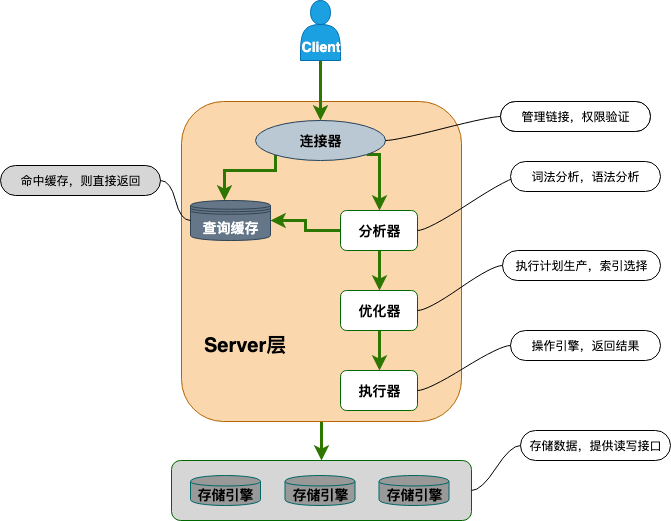
画像
-
コネクタ: ID 認証と権限に関連します (MySQL へのログイン時)。
-
クエリ キャッシュ:クエリ ステートメントを実行すると、最初にキャッシュにクエリが実行されます (この機能はあまり実用的ではないため、MySQL 8.0 以降では削除されました)。
-
アナライザー:キャッシュがヒットしない場合、SQL ステートメントはアナライザーを通過します。率直に言うと、アナライザーは、まず SQL ステートメントの動作を確認し、次に SQL ステートメントの構文が正しいかどうかをチェックします。
-
オプティマイザー: MySQL が考慮した最適解に従って実行します。
-
Executor:ステートメントを実行し、ストレージ エンジンからデータを返します。ステートメントを実行する前に権限があるかどうかを判断し、権限がない場合はエラーを報告します。
-
プラグイン ストレージ エンジン: 主にデータの保存と読み取りを担当し、プラグイン アーキテクチャを採用し、InnoDB、MyISAM、Memory などのストレージ エンジンをサポートします。
6. MyISAM と InnoDB の違いは何ですか?
MySQL 5.5 より前は、MyISAM エンジンが MySQL のデフォルトのストレージ エンジンであり、MySQL 5.5 以降は、InnoDB が MySQL のデフォルトのストレージ エンジンでした。
(1) 行レベルのロックをサポートするかどうか
MyISAM にはテーブル レベルのロックのみがありますが、InnoDB は行レベルのロックとテーブル レベルのロックをサポートしており、デフォルトは行レベルのロックです。
(2) 取引対応の有無
MyISAM はトランザクション サポートを提供しませんが、InnoDB はトランザクション サポートを提供し、SQL 標準で定義されている 4 つの分離レベルを実装し、トランザクションをコミットおよびロールバックする機能を備えています。
InnoDB によってデフォルトで使用される REPEATABLE-READ (再読み取り可能) 分離レベルは、(MVCC および Next-Key Lock に基づく) ファントム読み取りの問題を解決できます。
(3) 外部キーのサポートの有無
MyISAM はこれをサポートしていませんが、InnoDB はサポートしています。
(4) データベース異常クラッシュ後の安全なリカバリをサポートするかどうか
MyISAM はこれをサポートしていませんが、InnoDB はサポートしています。InnoDB を使用するデータベースが異常クラッシュした後、データベースが再起動されると、データベースはクラッシュ前の状態に確実に復元されます。回復プロセスは によって異なりますredo log。
(5) MVCCをサポートするかどうか
MyISAM はこれをサポートしていませんが、InnoDB はサポートしています。
(6) インデックスの実装
MyISAM エンジンと InnoDB エンジンはどちらもインデックス構造として B+Tree を使用しますが、この 2 つの実装方法は異なります。
-
InnoDB エンジンでは、そのデータ ファイル自体がインデックス ファイルです。テーブル データ ファイル自体は B+Tree によって編成されたインデックス構造であり、ツリーのリーフ ノードのデータ フィールドには完全なデータ レコードが格納されます。
-
MyISAM インデックス ファイルとデータ ファイルは分離されており、インデックスにはデータ ファイルへのポインタが格納されます。
(7) 性能の違い
InnoDB のパフォーマンスは MyISAM よりも優れており、読み取り/書き込み混合モードでも読み取り専用モードでも、CPU コアの数が増加するにつれて、InnoDB の読み取りおよび書き込み能力は直線的に増加します。MyISAM は同時に読み書きできないため、その処理能力はコアの数とは関係ありません。
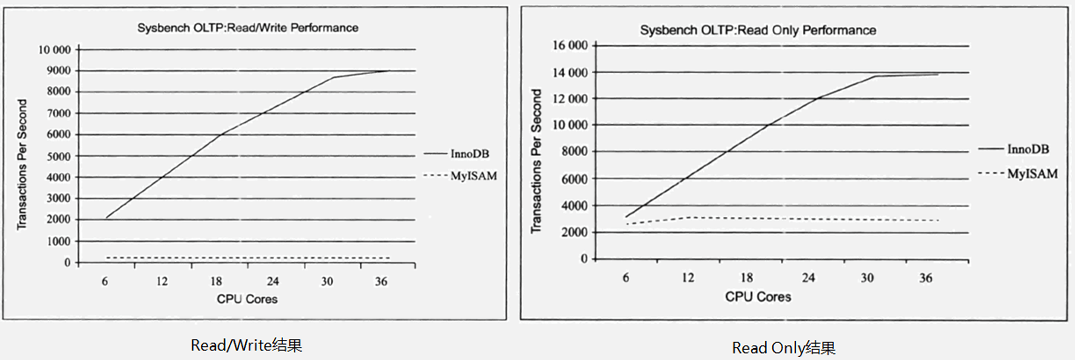
InnoDB と MyISAM のパフォーマンスの比較
7. 主キーの問題として自己インクリメント ID を推奨する
-
通常インデックスのB+ツリーには主キーインデックスの値が格納されており、値が大きいと「通常インデックスの格納領域が大きくなる」
-
自己インクリメント ID を主キー インデックスとして使用し、新しいデータがページの最後に配置されている限り、意図的にメンテナンスすることなく直接「順番に挿入」します。
-
ページ分割はメンテナンスが簡単です。データが挿入されている現在のページがほぼいっぱいになると、ページ分割が発生します。主キー インデックスが自己増加 ID でない場合、データはページの途中から挿入される可能性があります。ページ上のデータは頻繁に変更されます。「ページ分割によるメンテナンスコストの増加につながります。」
8. MySQL の自動インクリメント主キーが連続しない理由
-
MySQL 5.7 以前のバージョンでは、自己インクリメント値はメモリに保存され、永続化されません。
-
一意キーの競合: データを挿入するときに、最初に自動インクリメント主キーを +1 増やしてから、データを挿入するときに一意キーが競合し、データの挿入は失敗しますが、自動インクリメント主キーは元に戻されません。
-
トランザクションのロールバック: 一意のキーの競合と同様に、ロールバック操作中に自己インクリメント値はロールバックされません。実際、これを行う主な理由はパフォーマンスを向上させることです。
9. REDO ログは何をしますか?
redo log(REDO ログ) はInnoDBストレージ エンジンに固有のものであり、MySQLクラッシュからの回復を可能にします。
たとえば、MySQLインスタンスがハングアップまたはダウンした場合、再起動時にInnoDBストレージ エンジンはredo log復元されたデータを使用して、データの永続性と整合性を確保します。
Buffer Poolテーブルデータを更新する際、に更新対象のデータがあることが判明した場合は、Buffer Poolに直接更新されます。次に、「特定のデータ ページにどのような変更が加えられたか」を REDO ログ キャッシュ ( ) に記録しredo log buffer、redo logファイルにフラッシュします。
10. REDOログのフラッシュタイミング
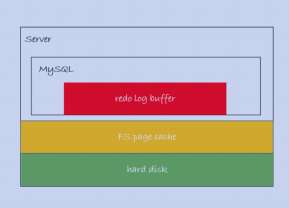
-
赤い部分はメモリに属するREDOログバッファです。
-
黄色の部分はページ キャッシュで、この時点でディスクに書き込まれていますが、永続化されていません。
-
緑色の部分は永続化されたハードディスクです。
InnoDB ストレージ エンジンは、REDO ログのフラッシュ戦略に innodb_flush_log_at_trx_commit パラメータを提供し、3 つの戦略をサポートします。
-
0 に設定すると、トランザクションがコミットされるたびにディスク操作が実行されるのではなく、REDO ログ バッファーにのみ保持され、mysql クラッシュにより 1 秒のデータが失われることを意味します。
-
1 に設定すると、トランザクションがコミットされるたびにディスク操作が実行され(デフォルト値)、ディスクに永続化されます。
-
2 に設定すると、トランザクションがコミットされるたびにREDO ログ バッファの内容のみがページ キャッシュに書き込まれ、永続化されないため OS のダウンタイムにより 1 秒のデータが失われます。
innodb_flush_log_at_trx_commit パラメータのデフォルトは 1 です。これは、トランザクションがコミットされると、fsync (同期操作) が呼び出されて REDO ログがフラッシュされることを意味します。
さらに、InnoDB ストレージ エンジンには、REDO ログ バッファの内容を 1 秒ごとにファイル システム キャッシュ (ページ キャッシュ) に書き込み、その後 fsync を呼び出してディスクをフラッシュするバックグラウンドスレッドがあります。
REDO ログ バッファが占めるスペースが innodb_log_buffer_size の半分に達しようとすると、バックグラウンド スレッドがディスクをアクティブにフラッシュします。
11. REDO ログはどのようにログを記録しますか?
ハードディスク上に保存されるredo logログ ファイルは 1 つだけではなく、ログ ファイル グループの形式で保存され、各redoログ ファイルのサイズは同じです。
たとえば、ファイルのグループとして構成でき4、各ファイルのサイズがログ ファイル グループ1GB全体でredo log記録できる内容になります4G。
以下の図に示すように、リング配列の形式を採用し、最初から書き込み、最後まで書き込み、最初に戻るというループで書き込みます。
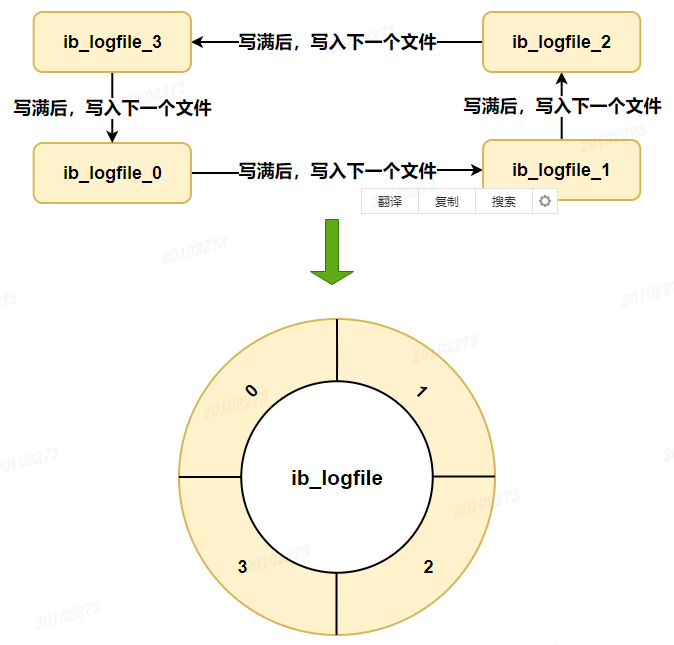
したがって、データがいっぱいであっても実際にデータをディスクにフラッシュする時間がなかった場合、「メモリ ジッター」現象が発生します。肉眼で見ると、mysql が一定時間ダウンしていることがわかります。しばらくすると、この時点でディスクがフラッシュされます。
12. ビンログとは何ですか
binlog は、サーバー層ログに属するアーカイブ ログです。バイナリ形式のファイルです。レコードの内容は、ステートメントの元のロジックであり、「ID=2 行の c フィールドに 1 を追加する」と似ています。 」。
使用されているストレージ エンジンに関係なく、テーブル データの更新が発生する限り、binlogログが生成されます。その主な機能は、データのバックアップとマスター/スレーブ レプリケーションです。
binlogデータの更新を伴うすべての論理操作が記録され、論理ログに属し、順次書き込まれます。
13. バイナリログレコード形式
binlogログには 3 つの形式があり、binlog_formatパラメータで指定できます。
-
ステートメント: レコードの内容は
SQLステートメントの原文であり、データの整合性に問題があります。 -
row : レコードには操作の特定のデータが含まれており、これにより同期データの一貫性が保証されます。
-
混合: レコードの内容が前者 2 つの混合物であり、データの不整合が発生する可能性があるかどうかが判断され、発生する場合は
MySQLその形式が使用され、そうでない場合はその形式が使用されます。SQLrowstatement
14. バイナリログ書き込みメカニズム
トランザクションの実行中、最初にログが書き込まれbinlog cache、トランザクションがコミットされるとファイルにbinlog cache書き込まれます。binlog
トランザクションはbinlog逆アセンブルできないため、トランザクションがどれほど大きくても一度に書き込む必要があり、システムは各スレッドにメモリ ブロックを割り当てますbinlog cache。
単一スレッドのバイナリ キャッシュ サイズはパラメータを介して制御できます。ストレージ コンテンツがこのパラメータを超える場合は、一時的にディスク ( )binlog_cache_sizeに保存する必要があります。Swap
binlog は、ページ キャッシュとディスクへの書き込みタイミングを制御する sync_binlog パラメーターも提供します。
-
0: トランザクションが送信されるたびに、トランザクションはファイル システムのページ キャッシュにのみ書き込まれます。いつ実行するかはシステムが決定します。
fsyncマシンがダウンすると、page cache内部のバイナリログが失われます。 -
1: トランザクションがコミットされるたびに、 REDO ログのログ フラッシュ プロセス
fsyncと同様に実行されます。 -
N(N>1): トランザクションがコミットされるたびに、トランザクションはファイル システムのページ キャッシュに書き込まれますが、それは
Nトランザクションが蓄積された後でのみですfsync。マシンがダウンすると、N最新のトランザクションのログが失われますbinlog。
15. redolog と binlog の違いは何ですか
-
RedologはInnodb の一意のログですが、binlog はサーバー層にあり、すべてのストレージ エンジンが使用されます。
-
Redolog は、特定の値、特定のページにどのような変更が加えられたか、binlogによって記録される操作内容を記録します。
-
binlogサイズが上限に達するか、フラッシュ ログによって新しいファイルが生成される場合、redolog のサイズは固定されており、リサイクルのみが可能です。
-
binlog ログにはクラッシュ セーフ機能がなく、アーカイブにのみ使用できますが、REDO ログにはクラッシュ セーフ機能があります。
-
REDO ログは、トランザクションの実行中に継続的に書き込むことができます (フラッシュが 1 に設定され、バックグラウンド スレッドが 1 秒ごとに実行されるか、REDO ログ バッファが占有するスペースが innodb_log_buffer_size の半分に達しようとしています)。トランザクションがシステムにコミットされたときにのみファイル キャッシュに書き込まれます。
16. 2フェーズコミット
SQL実行の過程でREDOログが書き込まれた後、binlogログの書き込み中に例外が発生した場合はどうなるでしょうか?
バイナリログは完了する前に異常であるため、現時点ではバイナリログに対応する変更レコードはありません。したがって、後で binlog ログを使用してデータを復元する場合、この更新は省略され、最終的なデータは不整合になります。
2 つのログ間の論理的一貫性の問題を解決するために、InnoDB ストレージ エンジンは2 フェーズ コミットスキームを使用します。
REDO ログの書き込みは、準備とコミットの 2 つのステップに分割され、これは 2 フェーズのコミットです。2 フェーズ コミットを使用した後は、バイナリ ログへの書き込み時の例外には影響しません。これは、MySQL が REDO ログ ログに基づいてデータを復元するときに、REDO ログがまだ準備段階にあり、対応するバイナリ ログが存在しないことが判明するためです。 , そのため、トランザクションはロールバックされます。
別のシナリオを見てみましょう。REDO ログ設定のコミットフェーズで例外が発生しました。トランザクションはロールバックされますか?
トランザクションはロールバックされません。REDO ログは準備段階にありますが、対応する binlog ログはトランザクション ID を通じて見つけることができるため、MySQL はトランザクションが完了したと見なし、トランザクションを送信してデータを復元します。
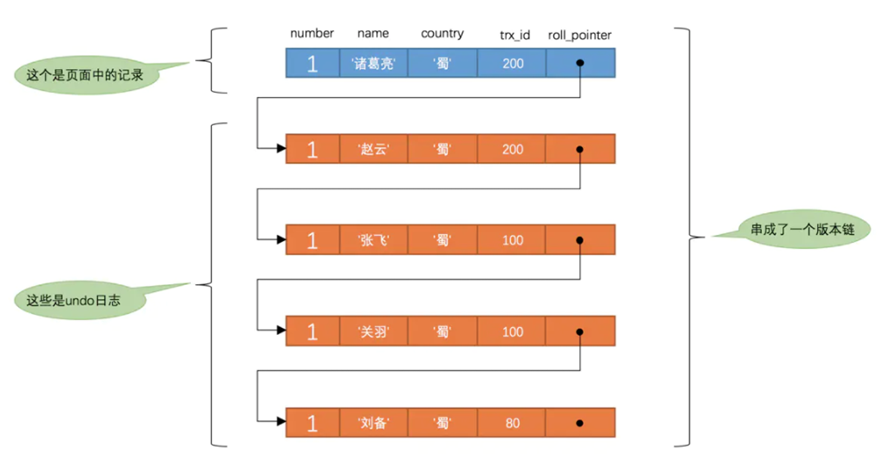
17. アンドゥログとは何ですか。
トランザクションの原子性を確保したい場合は、例外が発生したときに実行された操作 (INSERT、DELETE、UPDATE) をロールバックする必要があることがわかっています。MySQL では、ログ (UNDO ログ) をロールバックすることで回復メカニズムが実装されています 。はい、トランザクションによって行われたすべての変更は、まずこのロールバック ログに記録され、その後、関連する操作が実行されます。
レコードが変更されるたびにアンドゥ ログが記録され、各アンドゥ ログには属性もあり、DB_ROLL_PTRこれらのアンドゥ ログを連結してリンク リストを形成し、バージョン チェーンを形成できます。
バージョン チェーンのヘッド ノードは、現在のレコードの最新の値です。
18. リレーログとは
Relaylog は、マスターとスレーブの同期中に使用されるリレー ログであり、マスター ノードから同期された binlog ログの内容を保存するために使用される中間の一時ログ ファイルです。
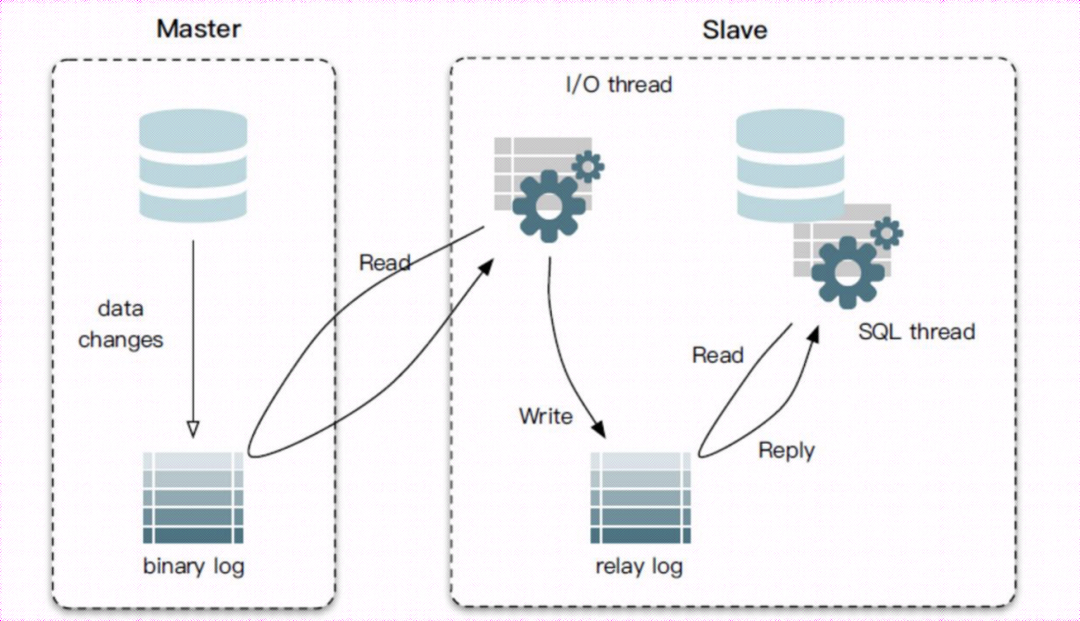
マスターマスターノードのビンログがスレーブノードに送信された後、リレーログに書き込まれ、スレーブノードのスレーブSQLスレッドがリレーログからログを読み取り、それをスレーブノードにローカルに適用します。
スレーブ サーバーの I/O スレッドはマスター サーバーのバイナリ ログを読み取り、スレーブ サーバーのローカル ファイルに記録します。次に、SQL スレッドがリレー ログ ログの内容を読み取り、それをスレーブ サーバーに適用します。スレーブ サーバーとマスター サーバーのデータが一致したままであること。
19. インデックス
インデックスは実際には、データベース内のデータを迅速に取得するのに役立つデータ構造です。
索引の機能は本の目次に相当します。たとえば、辞書を引くとき、ディレクトリがなければ、ページごとに調べる必要がある単語しか見つけることができず、速度が非常に遅くなります。目次がある場合は、目次に移動して単語の位置を見つけて、そのページに直接移動するだけで済みます。
20. ハッシュインデックス
ハッシュ テーブルはキーと値のペアの集合であり、キー (キー) を介して対応する値 (値) をすばやく取得できるため、ハッシュ テーブルはデータを高速に取得できます (O(1) に近い)。
しかし!ハッシュ アルゴリズムにはハッシュ競合の問題があり、複数の異なるキーが最終的に同じインデックスを取得することになります。通常、私たちの一般的な解決策はチェーンアドレス法です。
チェーンアドレス方式は、ハッシュ衝突データをリンクリストに格納する方式です。たとえば、JDK1.8 より前では、HashMap はハッシュの競合を解決するためにチェーン アドレス方式を使用していました。しかし、JDK1.8以降、HashMapはリンクリストが長すぎる場合の検索時間を短縮するために赤黒ツリーを導入しました。
ハッシュ衝突の発生を減らすために、優れたハッシュ関数は、可能なハッシュ値のセット全体にデータを「均一に」分散する必要があります。
ハッシュ テーブルは非常に高速なので、MySQL はなぜハッシュ テーブルをインデックス データ構造として使用しないのでしょうか? 主な理由は、ハッシュ インデックスがシーケンシャル クエリと範囲クエリをサポートしていないためです。テーブル内のデータを並べ替えたり、範囲クエリを実行したりする場合、ハッシュ インデックスは機能せず、毎回 1 つの IO しか取得できません。
21. B ツリーと B+ ツリー
-
B ツリーのすべてのノードはキーとデータの両方を保存しますが、B+ ツリーのリーフ ノードのみがキーとデータを保存し、他の内部ノードはキーのみを保存します。
-
B ツリーのリーフ ノードはすべて独立しており、B+ ツリーのリーフ ノードには、隣接するリーフ ノードを指す参照チェーンがあります。
-
B ツリーの検索プロセスは、範囲内の各ノードのキーワードに対して二分検索を実行することと等価であり、葉ノードに到達する前に検索が終了する可能性があります。B+木の検索効率は非常に安定しており、どの検索も根ノードから葉ノードまでの過程であり、葉ノードが順次検索されることは明らかである。
22. 主キーインデックス
データテーブルの主キー列は、特別な一意のインデックスである主キーインデックスを使用します。
MySQL の InnoDB テーブルでは、指定されたテーブルの主キーが表示されていない場合、InnoDB はテーブル内に一意のインデックスがあるかどうかを自動的にチェックし、null 値を持つフィールドを許可しません。そうである場合は、このフィールドをデフォルトの主キーとして選択しますそれ以外の場合、InnoDB は 6Byte の自動インクリメント主キーを自動的に作成します。
23. 二次インデックス
セカンダリ インデックスのリーフ ノードに格納されているデータが主キーであるため、セカンダリ インデックスは補助インデックスとも呼ばれます。つまり、セカンダリ インデックスを通じて、主キーの位置を特定できます。
一意インデックス、通常インデックス、プレフィックスインデックスなどのインデックスはセカンダリインデックスです。
-
一意のインデックス (一意のキー): 一意のインデックスも制約です。インデックス列の値は一意である必要がありますが、NULL 値も許可されます。複合インデックスの場合、列値の組み合わせは一意である必要があります。テーブルでは複数の一意のインデックスを作成できます。ほとんどの場合、一意のインデックスを確立する目的は、クエリの効率性ではなく、属性列内のデータの一意性のためです。
-
通常のインデックス (インデックス): 通常のインデックスの唯一の機能は、データを迅速にクエリすることです。テーブルには複数の通常のインデックスを作成でき、データの重複と NULL が許可されます。
-
プレフィックス インデックス (Prefix): プレフィックス インデックスは文字列型データにのみ適用されます。接頭辞インデックスは、テキストの最初の数文字のインデックスを作成するもので、最初の数文字のみが取得されるため、通常のインデックスによって作成されるデータは小さくなります。
-
複合インデックス: 複数のフィールドに対して作成されるインデックスを指します。インデックスは、インデックス作成時の最初のフィールドがクエリ条件で使用される場合にのみ使用されます。複合インデックスを使用する場合は、左端のプレフィックス セット(後述) に従います。
-
フルテキスト インデックス (フル テキスト): フルテキスト インデックスは主に大きなテキスト データからキーワード情報を取得するためのもので、現在検索エンジンのデータベースで使用されている技術です。Mysql5.6 より前は、MYISAM エンジンのみがフルテキスト インデックス作成をサポートしていましたが、5.6 以降は、InnoDB もフルテキスト インデックス作成をサポートします。
MySQL のフルテキスト インデックスには、最小検索長と最大検索長の2 つの変数があります。長さが最小検索長より短く、最大検索長より長い単語にはインデックスが作成されません。
24. クラスター化インデックスと非クラスター化インデックス
クラスター化インデックスは、個別のインデックス タイプではなく、インデックス構造とデータが一緒に格納されるインデックスです。InnoDB の主キー インデックスのリーフ ノードにはデータ行が格納されるため、クラスター化インデックスに属します。
MySQL では、InnoDB エンジン テーブルの .ibd ファイルにはテーブルのインデックスとデータが含まれています。InnoDB エンジン テーブルの場合、テーブルのインデックス (B+ ツリー) の各非リーフ ノードにインデックスが格納され、リーフ ノードにはインデックスが格納されます。インデックスに対応するデータを格納します。
非クラスター化インデックスは、インデックス構造とデータが個別に格納されるインデックスであり、別個のインデックス タイプではありません。セカンダリ インデックス (補助インデックス) は非クラスター化インデックスです。MySQL の MyISAM エンジンは、主キーか非主キーに関係なく、非クラスター化インデックスを使用します。
補助インデックスは私たちが作成したインデックスです。そのリーフ ノードには主キーが格納されます。補助インデックスを通じて主キーを見つけた後、テーブルに戻って、見つかった 主キーを通じて主キー インデックスを見つけることができます。
25. テーブルに戻る
テーブルに戻ると、データベース インデックスを介してインデックス ツリー内のデータの行をスキャンし、主キー ID を取得してから、主キー ID を介して主キー インデックス番号のデータを取得します。つまり、クエリです。非主キー インデックスに基づいて、追加のインデックス ツリーをスキャンする必要があります。
26. カバーインデックスとジョイントインデックス
インデックスにクエリが必要なすべてのフィールドの値が含まれている (またはカバーされている) 場合、それを「カバー インデックス」と呼びます。これは、インデックスに従ってデータ テーブル内のデータをクエリする (テーブルに戻る) 必要がなく、インデックスを介して必要なデータをクエリできることを意味します。これにより、データベースの IO 操作が削減され、クエリ効率が向上します。
テーブル内の複数のフィールドを使用してインデックスを作成することは、結合インデックスであり、複合インデックスまたは複合インデックスとも呼ばれます。
27. 一番左のプレフィックスマッチング原則
左端のプレフィックス マッチングの原則は、ジョイント インデックスを使用する場合、MySQL はジョイント インデックス内のフィールドの順序に従って左から右にクエリ条件を照合します。一致するフィールドがある場合は、このフィールドを使用してフィルタリングします。ジョイント インデックス内のすべてのフィールドが一致するまでデータのバッチを実行するか、実行中に範囲クエリ (>、<、between、% で始まる類似のクエリなど) が検出されると、一致が停止されます。
したがって、結合インデックスを使用する場合、識別性の高いフィールドを左端に配置することができ、より多くのデータをフィルタリングすることもできます。
28. インデックスのプッシュダウン
インデックス条件プッシュダウン (インデックス条件プッシュダウン) は、MySQL バージョン 5.6 で提供されるインデックス最適化機能です。非クラスター化インデックスの走査プロセス中に、最初にインデックスに含まれるフィールドを判断し、修飾されていないレコードを除外し、戻り時間を短縮できます。
29. 暗黙的な変換
演算子が異なる型のオペランドで使用される場合、オペランドの互換性を保つために型変換が行われます。一部の変換は暗黙的に行われます。たとえば、MySQL は必要に応じて文字列を数値に、またはその逆に自動的に変換します。次のルールは、比較演算がどのように変換されるかを説明します。
-
2 つのパラメータのうち少なくとも 1 つが NULL の場合、比較結果も NULL になります。特殊な場合、<=> を使用して 2 つの NULL を比較すると、1 が返されます。どちらの場合も、型変換は必要ありません。
-
どちらのパラメータも文字列であり、型変換なしで文字列に従って比較されます。
-
どちらのパラメーターも整数であり、型変換なしで整数に従って比較されます。
-
16 進値を数値以外と比較する場合、それらはバイナリ文字列として扱われます。
-
1 つのパラメータは TIMESTAMP または DATETIME で、もう 1 つのパラメータはタイムスタンプに変換される定数です。
-
1 つのパラメータが 10 進数タイプです。もう 1 つのパラメータが 10 進数または整数の場合、整数は比較のために 10 進数に変換されます。もう 1 つのパラメータが浮動小数点の場合は、比較のために 10 進数が浮動小数点に変換されます。
-
それ以外の場合は、両方の引数が浮動小数点数に変換されて比較されます。
30. 通常インデックスと独自インデックスはどのように選択すればよいですか?
-
お問い合わせ
-
-
通常のインデックスが条件の場合、テーブル全体がスキャンされるまで、クエリされたデータがスキャンされます。
-
一意のインデックスがクエリ条件である場合、テーブルのスキャンを続行せずに、見つかったデータが直接返されます。
-
-
更新する
-
-
通常のインデックスは、操作を変更バッファに直接更新して終了します。
-
データが競合するかどうかを判断するには、一意のインデックスが必要です
-
したがって、一意のインデックスはクエリ シナリオに適しており、通常のインデックスは挿入シナリオに適しています。
31. インデックスの失敗を回避する
インデックスの失敗も、クエリが遅い主な理由の 1 つです。インデックスの失敗につながる一般的な状況は次のとおりです。
-
SELECT *; を使用してクエリを実行します。
-
複合インデックスが作成されますが、クエリ条件が左端の一致原則に準拠していません。
-
インデックス付き列に対して計算、関数、型変換などの操作を実行します。
-
'%abc' など、% で始まる LIKE クエリ。
-
クエリ条件で or が使用されており、or の前条件と後条件の列にインデックスがない場合、関連するインデックスは使用されません。
-
match() 関数で指定された列は、フルテキスト インデックスで指定された列とまったく同じである必要があります。そうでない場合は、エラーが報告され、フルテキスト インデックスは使用できません。
-
全文インデックス作成によりインデックスが失敗する場合は、検索の長さに注意してください
32. インデックス作成のルール
-
NULL ではないフィールド: データが NULL であるフィールドに対してデータベースを最適化するのは難しいため、インデックス フィールドのデータはできる限り NULL にならないようにしてください。フィールドが頻繁にクエリされるが NULL になることが避けられない場合は、代わりに 0、1、true、false などの明確なセマンティクスを持つ短い値または短い文字を使用することをお勧めします。
-
頻繁にクエリされるフィールド: インデックスを作成するフィールドは、頻繁にクエリされるフィールドである必要があります。
-
条件としてクエリされるフィールド: WHERE 条件としてクエリされるフィールドは、インデックス付けの対象として考慮される必要があります。
-
頻繁に並べ替えが必要なフィールド: インデックスは並べ替えられているため、クエリでインデックスの並べ替えを使用して並べ替えクエリの時間を短縮できます。
-
接続によく使用されるフィールド: 接続によく使用されるフィールドは、外部キー列である可能性があります。外部キー列の場合、テーブル間の関係に関係する列であれば、外部キーを確立する必要はありません。結合によって頻繁にクエリが実行されるフィールドの場合、複数テーブルの結合クエリの効率を向上させるためにインデックス付けを検討できます。
-
頻繁に更新されるフィールドには慎重にインデックスを作成する必要があります。
-
可能な限り、単一列インデックスの代わりに結合インデックスを構築することを検討してください。
-
文字列型のフィールドでは、通常のインデックスの代わりにプレフィックス インデックスを使用することを検討してください。
-
長期間使用されていないインデックスを削除します。
33. トランザクションの極端な特性
Thing は n 個のユニットで構成されており、これらの n 個のユニットは実行中に同時に成功するか失敗するため、n 個のユニットがトランザクションに含まれます。簡単な例を挙げますと、テスト問題の正誤を考慮せず、複数の問題からなるテスト用紙を個別に教師に渡し、テスト用紙はここでは取引として理解することができます。
トランザクションの特徴:
-
A: アトミック性 (
Atomicity)、アトミック性とは、トランザクションが分割できない作業単位であり、トランザクション内の操作がすべて発生するか、まったく発生しないことを意味します。 -
C: 整合性 (
Consistency) は、トランザクションにおいて、トランザクションの前後でデータの整合性が一貫している必要があります。 -
I:
Isolation複数のトランザクションに存在する分離 ( )。トランザクションの分離とは、複数のユーザーがデータベースに同時にアクセスするときに、あるユーザーのトランザクションが他のユーザーのトランザクションによって干渉されることがなく、複数の同時トランザクション間のデータが分離されている必要があることを意味します。相互に孤立します。 -
D: 永続性 (
Durability)、永続性とは、トランザクションがコミットされると、データベース内のデータへの変更が永続的となり、データベースに障害が発生した場合でも影響を与えないことを意味します。
34. 同時トランザクションによって引き起こされる問題
-
ダーティ リード: トランザクション B は、トランザクション A によってコミットされていないデータを読み取ります。
-
変更の喪失 (変更の喪失): トランザクションがデータを読み取ると、別のトランザクションもデータにアクセスし、最初のトランザクションでデータが変更された後、2 番目のトランザクションもデータを変更します。このように、最初のトランザクションでの変更結果が失われるため、変更のロストと呼ばれます。
-
反復不可能な読み取り: トランザクション B は、トランザクション A によって送信されたデータを読み取ります。つまり、トランザクション A がコミットされる前後でトランザクション B によって読み取られたデータは矛盾しています (トランザクション A と B は同じデータに対して動作します)
内容。 -
ファントム読み取り/仮想読み取り: トランザクション B はトランザクション A によって送信されたデータを読み取ります。つまり、トランザクション A が挿入操作を実行しますが、トランザクション A の前後でトランザクション B によって読み取られたデータは不整合です
数量。
35. トランザクション分離レベル
上記の分離によって引き起こされる同時実行性の問題を解決するために、データベースはトランザクション分離メカニズムを提供します。
-
read uncommitted (read uncommitted): トランザクションがコミットされていない場合、トランザクションが行った変更は、コミットされていないデータを読み取っている他のトランザクションから参照できますが、この問題は解決できません。
-
コミットされた読み取り (コミットされた読み取り): トランザクションがコミットされた後、その変更は他のトランザクションによって表示されます。コミットされたデータを読み取ることでダーティ リードを解決できます - Oracle のデフォルト。
-
反復可能読み取り (反復可能読み取り): トランザクションの実行中に表示されるデータは、トランザクションの開始時に表示されるデータと常に一致しているため、ダーティ リードと非反復可能読み取りを解決できます。
-
Serializable (シリアル化): 名前が示すように、レコードの同じ行に対して、「write」は「書き込みロック」を追加し、「read」は「読み取りロック」を追加します。読み取り/書き込みロックの競合が発生した場合、後からアクセスされたトランザクションは、前のトランザクションが完了するまで待機してから実行を続行する必要があります。ダーティ リード、非反復読み取り、ファントム リードを解決できます。これはテーブルをロックするのと同じです。
シリアル化可能レベルではデータベースの同時実行性の問題をすべて解決できますが、読み取られたデータのすべての行がロックされるため、大量のタイムアウトやロック競合の問題が発生し、効率が低下する可能性があります。したがって、実際のアプリケーションではシリアライザブルを使用することはほとんどなく、データの一貫性を確保する必要があり、同時実行性を許容できない場合にのみ、このレベルの採用を検討する必要があります。
36、MVCC
ロックの粒度が大きすぎるとパフォーマンスが低下しますが、MySQL の InnoDB エンジンではよりパフォーマンスの良い MVCC メソッドがあります。
MVCC はMulti-Version Concurremt ControlMVCC の略称で、バージョン番号によって異なるトランザクション間での同じデータの競合を回避するマルチバージョン同時実行制御プロトコルを意味します。これは主に、データベースの同時読み取りおよび書き込みのパフォーマンスを向上させ、複数のトランザクションがロックせずに同時に読み取りおよび書き込みできるようにすることを目的としています。
MVCC の実装は、非表示の列、Undo ログ、Read Viewに依存しています。
SQL 標準で定義されている 4 つの分離レベルについての上記の説明から、標準 SQL 分離レベル定義では、REPEATABLE-READ (反復読み取り) ではファントム読み取りを防ぐことができないことが わかります。
ただし、InnoDB によって実装された REPEATABLE-READ 分離レベルは、主に次の 2 つの状況でファントム読み取りの問題を実際に解決できます。
-
スナップショット読み取り: MVCC メカニズムにより、ファントム読み取りが発生しないことが保証されます。
-
現在の読み取り: ファントム読み取りが発生しないように、ネクスト キー ロック (近接キー ロック) を使用してロックします。ネクスト キー ロックは、行ロック (レコード ロック) とギャップ ロック (ギャップ ロック) の組み合わせです。行ロックは、行ロックのみを実行できます。 lock 新しい行の挿入を避けるために、既存の行はギャップ ロックに依存する必要があります。
InnoDB ストレージ エンジンは通常、分散トランザクションの場合に SERIALIZABLE 分離レベルを使用します。
37. Mysqlのロック
ロックは操作の種類で分けると読み取りロックと書き込みロックに分けられますが、ここで言う読み取り/書き込みロックの概念は Java の概念に似ており、共有ロックと排他ロックとして理解できます。粒度の観点から、行ロック、ページ ロック、テーブル ロックに分けることができます。通常、最もよく使用されるのは行ロックとテーブル ロックです。ここで説明するのは主にロックのスコープのサイズを指します。ロックのスコープのサイズ。また、同時実行の程度にも直接影響します。行ロックの同時実行度は最も高くなりますが、そのロック コストは Innodb エンジンで非常に一般的です。テーブル ロックのロック コストは低いですが、ロック範囲も広く、同時実行性は最も低くなります。 「機能 - 共有」を読んだところによると、MySIAM は偏ったクエリ シナリオに適しています。
ロックとトランザクション レベルが同時実行シナリオを解決するために実際に使用されていることはわかっています。トランザクション レベルは、REDO ログと UNDO ログを利用することで理解できます。では、それらとロックの間にはどのような関係があるのでしょうか? ロック メカニズムは主に粒度の粗い制御であることは理解されていますが、ストレージ構造の存在により、データの読み取りと書き込みが一度に成功するわけではなく、その結果、ダーティ読み取り、ダーティ書き込み、および反復不能が発生します。読み取りとファントム読み取りの問題、およびこれらの問題の解決策は、MVVC メカニズムによって実現されます。
38. クエリ文実行処理
select * from tb_student s where s.age='18' and s.name=' 张三 ';-
まず、ステートメントにパーミッションがあるかどうかを確認します。パーミッションがない場合は、エラー メッセージが直接返されます。パーミッションがある場合、MySQL8.0 バージョンより前では、最初にキャッシュにクエリを実行し、この SQL ステートメントをキーとして使用して、メモリに結果があるかどうかをクエリし、ある場合は直接キャッシュし、ない場合は次のステップに進みます。
-
アナライザーを介して字句解析を実行して、SQL ステートメントの主要な要素を抽出します。たとえば、上記のステートメントはクエリ選択として抽出され、クエリ対象のテーブルの名前は tb_student で、すべての列をクエリする必要があります。クエリ条件はこのテーブルの id='1' です。次に、SQL文に文法上の誤りがないか、キーワードが正しいかなどを判断します。チェックに問題がなければ次のステップに進みます。
-
次のステップは、オプティマイザが実行計画を決定することです。上記の SQL ステートメントには 2 つの実行計画を含めることができます。
-
a. まず、学生テーブル内の名前が「Zhang San」である学生をクエリし、次に年齢が 18 歳かどうかを判断します。
-
b. まず生徒の中から 18 歳の生徒を見つけて、次に名前が「Zhang San」という生徒をクエリします。次に、オプティマイザは、独自の最適化アルゴリズムに従って、最高の実行効率を持つソリューションを選択します (オプティマイザは、それが必ずしも最高であるとは限らないと考えます)。そして、実行計画を確認したら、実行を開始する準備が整います。
-
-
権限検証を行い、権限がなければエラーメッセージを返し、権限があればデータベースエンジンインターフェースを呼び出し、エンジンの実行結果を返します。
クエリ ステートメントの実行プロセスは次のとおりです。 パーミッションの検証 (キャッシュにヒットした場合) ---> クエリ キャッシュ ---> アナライザー ---> オプティマイザー ---> パーミッションの検証 ---> エグゼキューター ---> > エンジン
39. Update文実行処理
update tb_student A set A.age='19' where A.name=' 张三 ';このステートメントは基本的に前のクエリのフローに従いますが、更新の実行時にログを記録する必要がある点が異なり、ログ モジュールが導入されます。MySQL に付属するログ モジュールは binlog (アーカイブ ログ) であり、すべてのストレージは All一般的に使用される InnoDB エンジンには、ログ モジュール REDO ログ (REDO ログ) も付属しています。InnoDB モードでのこのステートメントの実行プロセスについて説明します。
まず、Zhang San のデータをクエリします。キャッシュがある場合は、そのキャッシュも使用します。
次に、クエリ ステートメントを取得し、年齢を 19 に変更し、エンジン API インターフェイスを呼び出してこのデータ行を書き込みます。InnoDB エンジンはデータをメモリに保存し、同時に REDO ログを記録します。このとき、REDO はログは準備状態に入り、いつでも送信できるように実行を完了するように実行者に指示します。
Executor は通知を受信すると、binlog を記録し、エンジン インターフェイスを呼び出して、送信ステータスとして REDO ログを送信します。
アップデートが完了しました。
update ステートメントの実行フローは次のとおりです。 アナライザー ---> 権限の検証 ---> エグゼキューター ---> エンジン --- REDO ログ (準備ステータス) ---> binlog ---> REDO ログ(コミット状態)
40. SQLの最適化
テーブル全体のスキャンは可能な限り回避する必要があり、まず where および order by に関係する列でインデックスを考慮する必要があります。
where 句で次のステートメントを使用しないようにしてください。使用しないと、エンジンはインデックスの使用を断念し、テーブル全体のスキャンを実行します。
フィールドのnull値を判定するには、
!= または <> を使用してください
または条件を接続します (代わりに Union all を使用します)
in と not in も注意して使用する必要があります
ファジークエリを使用しないでください(全文インデックス作成が可能です)
式の操作を減らす
関数操作
select * from t をどこにも使用せず、「*」を特定のフィールド リストに置き換え、使用されていないフィールドを返さないでください。
1 つのテーブルに 6 つを超えるインデックスを持たないことが最善ですが、多すぎる場合は、頻繁に使用されない一部の列にインデックスを構築する必要があるかどうかを検討する必要があります。
多くの場合、in の代わりに存在するを使用することをお勧めします。
複数テーブルの結合クエリを最小限に抑えます。
ページネーションの最適化。
インデックスを正しく使用してください。
41. マスタスレーブ同期データ
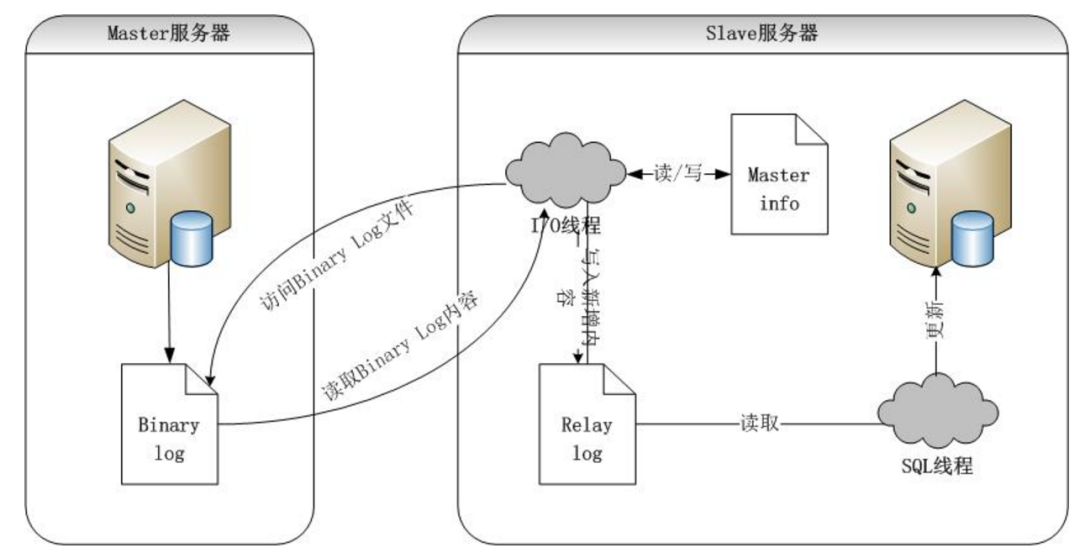
master メイン ライブラリは、この更新のイベント タイプをメイン ライブラリの binlog ファイルに書き込みます。
マスターはログ ダンプ スレッドを作成して、データを更新する必要があることをスレーブに通知します。
スレーブはマスター ノードにリクエストを送信し、binlog ファイルの内容をローカルのリレーログに保存します。
スレーブは SQL スレッドを開始してリレーログの内容を読み取り、その内容をローカルで再実行してマスターとスレーブのデータ同期を完了します。
同期戦略:
完全同期レプリケーション: マスター ライブラリはログをスレーブ ライブラリに強制的に同期し、すべてのスレーブ ライブラリが実行された後にクライアントに戻りますが、パフォーマンスが低下します。
準同期レプリケーション: マスター ライブラリは、スレーブ ライブラリから少なくとも 1 つの確認を受信した場合に操作が成功したとみなし、スレーブ ライブラリはログへの書き込みに成功して ack 確認を返します。
42. マスタースレーブ遅延の解決方法
MySQL 5.6 以降では、SQL スレッドを複数のワーカー スレッドに変換して再生する並列レプリケーション方式が提供されています。
マシン構成を改善する(王道)
ビジネスの開始時に適切なサブデータベースとサブテーブル戦略を選択して、大規模な単一形式のデータベースによって引き起こされるコピーの余分なプレッシャーを回避します。
長時間の取引を避ける
データベースにさまざまな大規模な操作を実行させないようにする
遅延に敏感な一部の企業の場合は、メイン ライブラリを直接使用して読み取ります。
43. ロングトランザクションを使用しない理由
同時実行の場合、データベース接続プールがバーストしやすくなります
大量のブロッキングやロック タイムアウトが発生しやすく、長いトランザクションもロック リソースを占有し、ライブラリ全体をダウンさせる可能性もあります。
実行時間が長く、マスタースレーブ遅延が発生しやすい
ロールバックに必要な時間は比較的長く、トランザクションが長ければ長いほど、期間全体でのトランザクション数が多くなります。
アンドゥログ ログはますます大きくなり、トランザクションが長いと、システム内に非常に古いトランザクション ビューが存在することになります。これらのトランザクションはいつでもデータベース内の任意のデータにアクセスできるため、トランザクションがコミットされる前に、データベース内で使用される可能性のあるロールバック レコードを保持する必要があり、その結果、大量のストレージ スペースが占有されます。