さまざまなネットワーク サービスを数百万、数千万、さらには 1 億を超えるユーザーに提供する必要があるため、第一線のインターネット企業でバックエンド開発の学生を面接し昇進させるための重要な要件の 1 つは、高度なサービスをサポートできることです。同時実行性とパフォーマンスのオーバーヘッドを理解すると、パフォーマンスが最適化されます。また、多くの場合、基盤となる Linux を深く理解していないと、オンライン パフォーマンスのボトルネックが多数発生したときに、何も始めることができないと感じるでしょう。
現在、私たちはグラフィカルな方法を使用して、Linux でのネットワーク パケットの受信プロセスを深く理解しています。または、慣例に従い、最も単純なコードを借用して考え始めます。わかりやすくするために、次のように udp を例として使用します。
int main(){
int serverSocketFd = socket(AF_INET, SOCK_DGRAM, 0);
bind(serverSocketFd, ...);
char buff[BUFFSIZE];
int readCount = recvfrom(serverSocketFd, buff, BUFFSIZE, 0, ...);
buff[readCount] = '\0'; printf("Receive from client:%s\n", buff);
}上記のコードは、udp サーバーが受信確認を受信するためのロジックの一部です。開発の観点から見ると、クライアントが対応するデータを送信する限り、サーバーはそれを受信し、実行recv_from後に出力できます。ここで知りたいのは、ネットワーク パケットがネットワーク カードに到達してから、recvfromデータを受信するまでの途中で何が起こったのかということです。
この記事を通じて、Linux ネットワーク システムが内部でどのように実装され、各部分がどのように相互作用するかを深く理解できるようになります。これはあなたの仕事に大いに役立つと思います。この記事は Linux 3.10 に基づいています。ソース コードについては https://mirrors.edge.kernel.org/pub/linux/kernel/v3.x/ を参照してください。ネットワーク カード ドライバーは例として Intel の igb ネットワーク カードを使用します。
この記事は少し長いので、最初にマークを付けてから読んでください。
Linuxネットワークパケット受信の概要
TCP/IP ネットワーク階層モデルでは、プロトコル スタック全体が物理層、リンク層、ネットワーク層、トランスポート層、アプリケーション層に分割されます。物理層はネットワーク カードとケーブルに対応し、アプリケーション層は一般的な Nginx、FTP、その他のアプリケーションに対応します。Linux は、リンク層、ネットワーク層、トランスポート層の 3 つの層を実装します。
Linux カーネルの実装では、リンク層プロトコルはネットワーク カード ドライバーによって実装され、カーネル プロトコル スタックはネットワーク層とトランスポート層を実装します。カーネルは、ユーザー プロセスがアクセスできるように、上位アプリケーション層にソケット インターフェイスを提供します。Linux の観点から見た TCP/IP ネットワーク階層化モデルは次のようになります。

図 1 Linux から見たネットワーク プロトコル スタック
Linux のソースコードには、ネットワークデバイスドライバに相当するロジックがありdriver/net/ethernet、そのディレクトリに intel シリーズのネットワークカードのドライバが存在しますdriver/net/ethernet/intel。プロトコル スタック モジュールのコードは、ディレクトリにありkernelますnet。
カーネルおよびネットワーク デバイス ドライバーは割り込みによって処理されます。データがデバイスに到着すると、CPU の関連ピンの電圧変化がトリガーされ、CPU にデータを処理するように通知されます。ネットワークモジュールの場合、処理が複雑で時間がかかるため、割り込み関数内ですべての処理を完了してしまうと、(優先度が高すぎる)割り込み処理関数がCPUを過剰に占有し、CPUが処理できなくなります。他のデバイス (マウスやキーボードのメッセージなど) に応答します。したがって、Linux の割り込み処理機能は上半分と下半分に分かれています。上部は最も単純な作業を実行し、迅速に処理して CPU を解放します。その後、CPU は他の割り込みを許可できるようになります。残りの作業のほとんどは下半分に配置されており、ゆっくりと落ち着いて処理できます。2.4 以降のカーネル バージョンで採用されている実装方法の下半分はソフト割り込みであり、ksoftirqd カーネル スレッドによって完全に処理されます。ハード割り込みとは異なり、ハード割り込みは CPU の物理ピンに電圧変化を適用しますが、ソフト割り込みはメモリ内の変数にバイナリ値を与えることによってソフト割り込みハンドラーに通知します。
ネットワーク カード ドライバー、ハード割り込み、ソフト割り込み、および ksoftirqd スレッドについて一般的に理解した後、次の概念に基づいてカーネルがパケットを受信するパスの概略図を示します。

図2 パケットを受信するLinuxカーネルネットワークの概要
データがネットワーク カードで受信されると、Linux で最初に動作するモジュールはネットワーク ドライバーです。ネットワーク ドライバーは、ネットワーク カードで受信したフレームを DMA によってメモリに書き込みます。次に、CPU への割り込みを開始して、データが到着したことを CPU に通知します。次に、CPU が割り込み要求を受信すると、ネットワーク ドライバーによって登録された割り込みハンドラーを呼び出します。ネットワークカードの割り込み処理機能は、あまり負荷をかけずにソフト割り込み要求を送り、すぐにCPUを解放します。ksoftirqd は、ソフト割り込み要求の到着を検出すると、poll を呼び出してパケットのポーリングと受信を開始し、受信後、処理のためにすべてのレベルのプロトコル スタックに渡します。UDP パケットの場合、パケットはユーザー ソケットの受信キューに配置されます。
上の図から、データパケットに対する Linux の処理過程が全体として把握できました。しかし、ネットワーク モジュールの動作についてさらに詳しく理解したい場合は、下に目を向ける必要があります。
2 つの Linux ブート
Linux ドライバー、カーネル プロトコル スタック、およびその他のモジュールは、ネットワーク カード データ パケットを受信できるようになる前に、多くの準備作業を行う必要があります。例えば、ksoftirqdカーネルスレッドを事前に作成し、各プロトコルに対応した処理関数を登録し、ネットワークデバイスサブシステムを初期化し、ネットワークカードを起動する必要があります。これらが準備完了になって初めて、実際にパケットの受信を開始できます。それでは、これらの準備がどのように行われるかを見てみましょう。
2.1 ksoftirqd カーネルスレッドの作成
Linux のソフト割り込みはすべて専用のカーネル スレッド (ksoftirqd) で実行されるため、後でパケット受信プロセスをより正確に理解できるように、これらのプロセスがどのように初期化されるかを確認することが非常に必要です。プロセスの数は 1 ではなく N です。N はマシンのコアの数と同じです。
システムが初期化されると、kernel/smpboot.c で smpboot_register_percpu_thread が呼び出され、この関数がさらに spawn_ksoftirqd (kernel/softirq.c にある) に対して実行されて、softirqd プロセスが作成されます。

図 3 ksoftirqd カーネル スレッドの作成
関連するコードは次のとおりです。
//file: kernel/softirq.c
static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run = ksoftirqd_should_run,
.thread_fn = run_ksoftirqd,
.thread_comm = "ksoftirqd/%u",};static __init int spawn_ksoftirqd(void){
register_cpu_notifier(&cpu_nfb);
BUG_ON(smpboot_register_percpu_thread(&softirq_threads)); return 0;
}
early_initcall(spawn_ksoftirqd);ksoftirqd が作成されると、独自のスレッド ループ関数 ksoftirqd_Should_run および run_ksoftirqd に入ります。処理が必要なソフト割り込みがあるかどうかを常に判断します。ここで注意すべき点は、ソフト割り込みにはネットワーク ソフト割り込みだけでなく、他の種類のソフト割り込みも含まれるということです。
//file: include/linux/interrupt.henum{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ,
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ,
};2.2 ネットワークサブシステムの初期化

図 4 ネットワーク サブシステムの初期化
Linux カーネルはsubsys_initcall呼び出しを通じてさまざまなサブシステムを初期化し、ソース コード ディレクトリでこの関数への多くの呼び出しを grep アウトできます。net_dev_initここで話しているのは、関数を実行するネットワーク サブシステムの初期化です。
//file: net/core/dev.c
static int __init net_dev_init(void){
......
for_each_possible_cpu(i) {
struct softnet_data *sd = &per_cpu(softnet_data, i);
memset(sd, 0, sizeof(*sd));
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
sd->completion_queue = NULL;
INIT_LIST_HEAD(&sd->poll_list);
......
}
......
open_softirq(NET_TX_SOFTIRQ, net_tx_action); open_softirq(NET_RX_SOFTIRQ, net_rx_action);
}
subsys_initcall(net_dev_init);この関数では、softnet_dataデータ構造が各 CPU に適用されます。このデータ構造では、poll_listドライバーがポーリング関数を登録するのを待機しています。このプロセスは、後でネットワーク カード ドライバーが初期化されるときに確認できます。
また、open_softirq はソフト割り込みごとに処理関数を登録します。NET_TX_SOFTIRQ の処理関数は net_tx_action、NET_RX_SOFTIRQ の処理関数は net_rx_action です。追跡を続けたところ、変数open_softirqに登録方法が記録されていることが分かりました。softirq_vecksoftirqd スレッドが後でソフト割り込みを受信したときも、この変数を使用して各ソフト割り込みに対応する処理関数を見つけます。
//file: kernel/softirq.c
void open_softirq(int nr, void (*action)(struct softirq_action *)){
softirq_vec[nr].action = action;
}2.3 プロトコルスタックの登録
カーネルは、ネットワーク層で ip プロトコルを実装し、トランスポート層で tcp プロトコルと udp プロトコルを実装します。これらのプロトコルに対応する実装関数はそれぞれ ip_rcv()、tcp_v4_rcv()、udp_rcv() です。私たちが通常コードを記述する方法とは異なり、カーネルは登録を通じて実装されます。Linux カーネルおよびfs_initcallと同様にsubsys_initcall、これは初期化モジュールのエントリ ポイントでもあります。fs_initcallを呼び出したinet_init後、ネットワーク プロトコル スタックの登録を開始します。渡されるとinet_init、これらの関数は inet_protos および ptype_base データ構造に登録されます。以下に示すように:

図5 AF_INETプロトコルスタックの登録
関連するコードは次のとおりです
//file: net/ipv4/af_inet.c
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,};static const struct net_protocol udp_protocol = {
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
.netns_ok = 1,};static const struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1, .netns_ok = 1,
};
static int __init inet_init(void){
......
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
...... dev_add_pack(&ip_packet_type);
}上記のコードでは、udp_protocol 構造体のハンドラーが udp_rcv であり、tcp_protocol 構造体のハンドラーが tcp_v4_rcv であり、inet_add_protocol によって初期化されることがわかります。
int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol){
if (!prot->netns_ok) {
pr_err("Protocol %u is not namespace aware, cannot register.\n",
protocol);
return -EINVAL;
}
return !cmpxchg((const struct net_protocol **)&inet_protos[protocol], NULL, prot) ? 0 : -1;
}inet_add_protocolこの関数は、tcpとudpに対応する処理関数をinet_protos配列に登録します。この行をもう一度見てみるとdev_add_pack(&ip_packet_type);、ip_packet_type構造体のtypeはプロトコル名、funcはip_rcv関数で、dev_add_packのptype_baseハッシュテーブルに登録されます。
//file: net/core/dev.c
void dev_add_pack(struct packet_type *pt){
struct list_head *head = ptype_head(pt); ......
}
static inline struct list_head *ptype_head(const struct packet_type *pt){
if (pt->type == htons(ETH_P_ALL))
return &ptype_all;
else return &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}ここで、inet_protos は udp および tcp 処理関数のアドレスを記録し、ptype_base は ip_rcv() 関数の処理アドレスを格納することを覚えておく必要があります。後で、softirq が ptype_base を通じて ip_rcv 関数のアドレスを見つけ、実行のために ip パケットを ip_rcv() に正しく送信することがわかります。ip_rcv では、inet_protos を通じて tcp または udp 処理関数が検出され、パケットは udp_rcv() 関数または tcp_v4_rcv() 関数に転送されます。
さらに拡張して、ip_rcv や udp_rcv などの関数のコードを見ると、多くのプロトコルの処理がわかります。たとえば、ip_rcv は netfilter および iptable のフィルタリングを処理しますが、多くのまたは非常に複雑な netfilter または iptables ルールがある場合、これらのルールはソフト割り込みのコンテキストで実行されるため、ネットワーク遅延が増加します。別の例として、udp_rcv はソケットの受信キューがいっぱいかどうかを判断します。対応する関連カーネル パラメータは net.core.rmem_max および net.core.rmem_default です。興味がある場合は、inet_initこの関数のコードを注意深く読むことをお勧めします。
2.4 ネットワークカードドライバーの初期化
すべてのドライバー (ネットワーク カード ドライバーだけでなく) は module_init を使用して初期化関数をカーネルに登録し、カーネルはドライバーのロード時にこの関数を呼び出します。たとえば、igb ネットワーク カード ドライバーのコードは次の場所にあります。drivers/net/ethernet/intel/igb/igb_main.c
//file: drivers/net/ethernet/intel/igb/igb_main.c
static struct pci_driver igb_driver = {
.name = igb_driver_name,
.id_table = igb_pci_tbl,
.probe = igb_probe,
.remove = igb_remove, ......
};
static int __init igb_init_module(void){
......
ret = pci_register_driver(&igb_driver); return ret;
}ドライバー呼び出しが完了すると、Linux カーネルは、igb ネットワーク カード ドライバーや関数アドレスなどpci_register_driverのドライバーの関連情報を認識します。ネットワーク カード デバイスが認識されると、カーネルはそのドライバーのプローブ メソッドを呼び出します (igb_driver のプローブ メソッドは igb_probe)。プローブ メソッドの実行を駆動する目的は、デバイスを準備することです。igb ネットワーク カードの場合、これはdrivers/net/ethernet/intel/igb/igb_main.c にあります。実行される主な操作は次のとおりです。igb_driver_nameigb_probeigb_probe

図 6 ネットワーク カード ドライバーの初期化
ステップ 5 では、ネットワーク カード ドライバーが ethtool に必要なインターフェイスを実装し、ここで登録して関数アドレスの登録を完了していることがわかります。ethtool がシステム コールを開始すると、カーネルは対応する操作のコールバック関数を見つけます。igb ネットワーク カードの場合、その実装関数はすべて drivers/net/ethernet/intel/igb/igb_ethtool.c にあります。今回でethtoolの動作原理は十分理解できたのではないでしょうか?このコマンドがネットワーク カードのパケット送受信統計を表示し、ネットワーク カードの適応モードを変更し、RX キューの数とサイズを調整できる理由は、ethtool コマンドが最終的にネットワークの対応するメソッドを呼び出すためです。 ethtool 自体がこの強力な機能を備えているのではなく、カード ドライバーです。
手順 6 で登録した igb_netdev_ops には、ネットワーク カードの起動時に呼び出される igb_open などの関数が含まれています。
//file: drivers/net/ethernet/intel/igb/igb_main.c
static const struct net_device_ops igb_netdev_ops = {
.ndo_open = igb_open,
.ndo_stop = igb_close,
.ndo_start_xmit = igb_xmit_frame,
.ndo_get_stats64 = igb_get_stats64,
.ndo_set_rx_mode = igb_set_rx_mode,
.ndo_set_mac_address = igb_set_mac,
.ndo_change_mtu = igb_change_mtu, .ndo_do_ioctl = igb_ioctl,
......ステップ 7 では、igb_probe の初期化プロセス中に、これも と呼ばれますigb_alloc_q_vector。NAPI メカニズムに必要なポーリング関数を登録しました。igb ネットワーク カード ドライバーの場合、この関数は次のコードに示すように igb_poll です。
static int igb_alloc_q_vector(struct igb_adapter *adapter,
int v_count, int v_idx,
int txr_count, int txr_idx,
int rxr_count, int rxr_idx){
......
/* initialize NAPI */
netif_napi_add(adapter->netdev, &q_vector->napi, igb_poll, 64);
}2.5 ネットワークカードの起動
上記の初期化が完了すると、ネットワークカードを起動できるようになります。前のネットワーク カード ドライバーの初期化を思い出して、ドライバーが構造体 net_device_ops 変数をカーネルに登録したことを説明しました。この変数には、ネットワーク カードのアクティブ化、パケット送信、MAC アドレス設定などのコールバック関数 (関数ポインター) が含まれています。ネットワーク カードが有効になると (たとえば、ifconfig eth0 up 経由で)、net_device_ops の igb_open メソッドが呼び出されます。通常は次のことを行います。

図 7 ネットワークカードの起動
//file: drivers/net/ethernet/intel/igb/igb_main.c
static int __igb_open(struct net_device *netdev, bool resuming){
/* allocate transmit descriptors */
err = igb_setup_all_tx_resources(adapter);
/* allocate receive descriptors */
err = igb_setup_all_rx_resources(adapter);
/* 注册中断处理函数 */
err = igb_request_irq(adapter);
if (err)
goto err_req_irq;
/* 启用NAPI */
for (i = 0; i < adapter->num_q_vectors; i++)
napi_enable(&(adapter->q_vector[i]->napi)); ......
}上記の__igb_open関数は、igb_setup_all_tx_resources および igb_setup_all_rx_resources を呼び出します。このステップではigb_setup_all_rx_resources、RingBuffer が割り当てられ、メモリと Rx キューの間のマッピング関係が確立されます。(Rx Tx キューの数とサイズは ethtool を通じて設定できます)。割り込み関数の登録をもう一度見てみましょうigb_request_irq。
static int igb_request_irq(struct igb_adapter *adapter){
if (adapter->msix_entries) {
err = igb_request_msix(adapter);
if (!err)
goto request_done;
...... }
}
static int igb_request_msix(struct igb_adapter *adapter){
......
for (i = 0; i < adapter->num_q_vectors; i++) {
...
err = request_irq(adapter->msix_entries[vector].vector,
igb_msix_ring, 0, q_vector->name,
}上記のコード__igb_open=> igb_request_irq=>の関数呼び出しを追跡するとigb_request_msix、igb_request_msixマルチキュー ネットワーク カードの場合、割り込みが各キューに登録されており、対応する割り込み処理関数が igb_msix_ring であることがわかります (この関数は drivers/ net/ にもあります)。イーサネット/インテル/igb/igb_main.c)。また、msix モードでは、各 RX キューに独立した MSI-X 割り込みがあり、ネットワーク カードのハードウェア割り込みのレベルから、受信パケットが異なる CPU で処理されるように設定できます。(irqbalance を使用して CPU とのバインド動作を変更するか、/proc/irq/IRQ_NUMBER/smp_affinity を変更できます)。
以上の準備が完了したら、ゲスト(データパケット)をお迎えするためのドアを開けることができます!
3 人はデータの到着を歓迎します
3.1 ハード割り込み処理
まず、データ フレームがネットワーク ケーブルからネットワーク カードに到着すると、最初に停止するのはネットワーク カードの受信キューです。ネットワーク カードは、自身に割り当てられた RingBuffer 内で利用可能なメモリの場所を探します。それが見つかった後、DMA エンジンは、ネットワーク カードに関連付けられたメモリにデータを DMA します。このとき、CPU は影響を受けません。DMA 操作が完了すると、ネットワーク カードは CPU と同様にハード割り込みを開始し、データが到着したことを CPU に通知します。

図8 NICデータハード割り込み処理プロセス
注: RingBuffer がいっぱいになると、新しいデータ パケットは破棄されます。ifconfig がネットワーク カードをチェックすると、オーバーランが発生する可能性があります。これは、リング キューがいっぱいだったためにパケットが破棄されたことを示しています。パケット損失が見つかった場合は、ethtool コマンドを使用してリング キューの長さを増やすことが必要になる場合があります。
ネットワーク カードの起動に関するセクションで、ネットワーク カードのハード割り込み登録の処理関数が igb_msix_ring であると述べました。
//file: drivers/net/ethernet/intel/igb/igb_main.c
static irqreturn_t igb_msix_ring(int irq, void *data){
struct igb_q_vector *q_vector = data;
/* Write the ITR value calculated from the previous interrupt. */
igb_write_itr(q_vector);
napi_schedule(&q_vector->napi); return IRQ_HANDLED;
}igb_write_itrハードウェアの割り込み頻度を記録するだけです(CPUの割り込み頻度を減らすのが目的と言われています)。napi_schedule 呼び出しを最後までたどります。__napi_schedule=>____napi_schedule
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi){
list_add_tail(&napi->poll_list, &sd->poll_list); __raise_softirq_irqoff(NET_RX_SOFTIRQ);
}list_add_tailここでは、CPU 変数 Softnet_data の Paul_list が変更され、ドライバー napi_struct によって渡された Paul_list が追加されていることがわかります。Softnet_data の Paul_list は、デバイスが処理を待機している入力フレームを持っている双方向リストです。その直後、__raise_softirq_irqoffソフト割り込み NET_RX_SOFTIRQ がトリガーされますが、このいわゆるトリガー プロセスは変数の OR 演算のみを実行します。
void __raise_softirq_irqoff(unsigned int nr){
trace_softirq_raise(nr); or_softirq_pending(1UL << nr);
}
//file: include/linux/irq_cpustat.h
#define or_softirq_pending(x) (local_softirq_pending() |= (x))Linux はハード割り込みで単純で必要な作業のみを完了し、残りの処理のほとんどはソフト割り込みに引き継がれると述べました。上記のコードからわかるように、ハード割り込み処理プロセスは実際には非常に短いです。レジスタを記録し、CPU の poll_list を変更して、ソフト割り込みを発行しただけです。たとえ困難な中断作業が完了したとしても、それはとても簡単です。
3.2 ksoftirqd カーネル スレッドはソフト割り込みを処理します

図 9 ksoftirqd カーネル スレッド
カーネル スレッドが初期化されるとき、 ksoftirqd に 2 つのスレッド関数を導入しましksoftirqd_should_runたrun_ksoftirqd。コードは次のとおりですksoftirqd_should_run。
static int ksoftirqd_should_run(unsigned int cpu){ return local_softirq_pending();
}
#define local_softirq_pending() \ __IRQ_STAT(smp_processor_id(), __softirq_pending)ここでは、同じ関数がハード割り込みで呼び出されていることがわかりますlocal_softirq_pending。使用上の違いは、ハード割り込み位置はマークの書き込み用であるのに対し、ここでは読み取り専用であることです。ハード割り込みに設定されていればNET_RX_SOFTIRQ、当然ここで読み出すことができます。次に、実際に処理のためにスレッド関数に入りますrun_ksoftirqd。
static void run_ksoftirqd(unsigned int cpu){
local_irq_disable();
if (local_softirq_pending()) {
__do_softirq();
rcu_note_context_switch(cpu);
local_irq_enable();
cond_resched();
return;
} local_irq_enable();
}では__do_softirq、現在のCPUのソフト割り込みタイプに応じて判断し、登録されているアクションメソッドを呼び出します。
asmlinkage void __do_softirq(void){
do {
if (pending & 1) {
unsigned int vec_nr = h - softirq_vec;
int prev_count = preempt_count();
...
trace_softirq_entry(vec_nr);
h->action(h);
trace_softirq_exit(vec_nr);
...
}
h++;
pending >>= 1; } while (pending);
}ネットワーク サブシステムの初期化セクションでは、NET_RX_SOFTIRQ のハンドラー関数 net_rx_action を登録したことがわかりました。したがって、net_rx_action関数が実行されます。
ここで細かい点に注意が必要ですが、ハード割り込みにはソフト割り込みフラグがセットされており、ksoftirq によるソフト割り込みの有無の判断は smp_processor_id() によって行われます。これは、どの CPU でハード割り込みが応答される限り、ソフト割り込みもその CPU で処理されることを意味します。したがって、Linux のソフト割り込みの CPU 消費が 1 つのコアに集中していることがわかった場合は、ハード割り込みの CPU アフィニティを調整して、ハード割り込みを別の CPU コアに分散させる方法があります。
このコア機能にもう一度注目してみましょうnet_rx_action。
static void net_rx_action(struct softirq_action *h){
struct softnet_data *sd = &__get_cpu_var(softnet_data);
unsigned long time_limit = jiffies + 2;
int budget = netdev_budget;
void *have;
local_irq_disable();
while (!list_empty(&sd->poll_list)) {
......
n = list_first_entry(&sd->poll_list, struct napi_struct, poll_list);
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
trace_napi_poll(n);
}
budget -= work; }
}関数の先頭の time_limit と Budget は、net_rx_action 関数のアクティブな終了を制御するために使用されます。その目的は、ネットワーク パケットの受信によって CPU が占有されないようにすることです。次回ネットワーク カードにハード割り込みが発生するまで待ってから、残りの受信データ パケットを処理します。バジェットはカーネルパラメータを通じて調整できます。この関数の残りのコア ロジックは、現在の CPU 変数 Softnet_data を取得し、その poll_list を走査し、ネットワーク カード ドライバーに登録されているポーリング関数を実行することです。igb ネットワーク カードの場合、これはigb_polligb 駆動力の機能です。
static int igb_poll(struct napi_struct *napi, int budget){
...
if (q_vector->tx.ring)
clean_complete = igb_clean_tx_irq(q_vector);
if (q_vector->rx.ring)
clean_complete &= igb_clean_rx_irq(q_vector, budget); ...
}読み取り操作でのigb_poll重要な作業は、igb_clean_rx_irqの呼び出しです。
static bool igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget){
...
do {
/* retrieve a buffer from the ring */
skb = igb_fetch_rx_buffer(rx_ring, rx_desc, skb);
/* fetch next buffer in frame if non-eop */
if (igb_is_non_eop(rx_ring, rx_desc))
continue;
}
/* verify the packet layout is correct */
if (igb_cleanup_headers(rx_ring, rx_desc, skb)) {
skb = NULL;
continue;
}
/* populate checksum, timestamp, VLAN, and protocol */
igb_process_skb_fields(rx_ring, rx_desc, skb);
napi_gro_receive(&q_vector->napi, skb);
}
}igb_fetch_rx_buffersumの機能はigb_is_non_eop、RingBuffer からデータ フレームを削除することです。なぜ 2 つの関数が必要なのでしょうか? フレームが複数の RingBuffer を占有する可能性があるため、フレームの終わりまでループで取得されます。取得されたデータフレームはsk_buffで表される。データを受信したら、いくつかのチェックを実行し、タイムスタンプ、VLAN ID、プロトコル、および sbk 変数のその他のフィールドの設定を開始します。次に、napi_gro_receive を入力します。
//file: net/core/dev.c
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb){
skb_gro_reset_offset(skb); return napi_skb_finish(dev_gro_receive(napi, skb), skb);
}dev_gro_receiveこの機能は、ネットワーク カードの GRO 機能を表します。単純に、関連する小さなパケットを 1 つの大きなパケットに結合するものとして理解できます。目的は、ネットワーク スタックに送信されるパケットの数を減らし、CPU 使用率の削減に役立ちます。今は無視して、napi_skb_finishこの関数が主に呼び出されているものを直接見てみましょうnetif_receive_skb。
//file: net/core/dev.c
static gro_result_t napi_skb_finish(gro_result_t ret, struct sk_buff *skb){
switch (ret) {
case GRO_NORMAL:
if (netif_receive_skb(skb))
ret = GRO_DROP;
break; ......
}ではnetif_receive_skb、データ パケットがプロトコル スタックに送信されます。ステートメント、以下の 3.3、3.4、3.5 もソフト割り込みの処理過程に属しますが、長すぎるため分割して取り出します。
3.3 ネットワークプロトコルスタック処理
netif_receive_skbパケットのプロトコルに従って、それが udp パケットの場合、この関数はパケットを ip_rcv()、udp_rcv() プロトコル処理関数に送信して処理します。

図10 ネットワークプロトコルスタック処理
//file: net/core/dev.c
int netif_receive_skb(struct sk_buff *skb){
//RPS处理逻辑,先忽略 ...... return __netif_receive_skb(skb);
}
static int __netif_receive_skb(struct sk_buff *skb){
......
ret = __netif_receive_skb_core(skb, false);}static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc){
......
//pcap逻辑,这里会将数据送入抓包点。tcpdump就是从这个入口获取包的 list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (!ptype->dev || ptype->dev == skb->dev) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
......
list_for_each_entry_rcu(ptype,
&ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
if (ptype->type == type &&
(ptype->dev == null_or_dev || ptype->dev == skb->dev ||
ptype->dev == orig_dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
} }
}で__netif_receive_skb_core、よく使っていた tcpdump のパケットキャプチャポイントを眺めてみたら、ソースコードを読む時間も実に無駄ではなかったと感激しました。次に__netif_receive_skb_coreプロトコルを取り出し、データ パケットからプロトコル情報を取り出し、このプロトコルに登録されているコールバック関数のリストを調べます。ptype_baseこれは、プロトコル登録セクションで説明したハッシュ テーブルです。ip_rcv 関数のアドレスはこのハッシュ テーブルに格納されます。
//file: net/core/dev.c
static inline int deliver_skb(struct sk_buff *skb,
struct packet_type *pt_prev,
struct net_device *orig_dev){
...... return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}pt_prev->funcこの行は、プロトコル層によって登録されたハンドラー関数を呼び出します。ipパケットの場合は入りますip_rcv(arpパケットの場合はarp_rcvが入ります)。
3.4 IPプロトコル層の処理
Linux が IP プロトコル層で何を行うのか、そしてパケットがどのように udp または tcp プロトコル処理機能にさらに送信されるのかを概観してみましょう。
//file: net/ipv4/ip_input.c
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev){
......
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL, ip_rcv_finish);
}ここにNF_HOOKフック関数があり、登録されたフックが実行されると、最後のパラメータが指す関数が実行されますip_rcv_finish。
static int ip_rcv_finish(struct sk_buff *skb){
......
if (!skb_dst(skb)) {
int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
iph->tos, skb->dev);
...
}
...... return dst_input(skb);
}トレースした後、ip_route_input_noref再度呼び出されたことがわかりましたip_route_input_mc。ではip_route_input_mc、関数は次のようにip_local_deliverに割り当てられますdst.input。
//file: net/ipv4/route.c
static int ip_route_input_mc(struct sk_buff *skb, __be32 daddr, __be32 saddr,u8 tos, struct net_device *dev, int our){
if (our) {
rth->dst.input= ip_local_deliver;
rth->rt_flags |= RTCF_LOCAL; }
}ip_rcv_finishそれで話は戻りますreturn dst_input(skb);。
/* Input packet from network to transport. */
static inline int dst_input(struct sk_buff *skb){
return skb_dst(skb)->input(skb);
}skb_dst(skb)->input呼び出される入力メソッドは、ルーティング サブシステムによって割り当てられた ip_local_deliver です。
//file: net/ipv4/ip_input.c
int ip_local_deliver(struct sk_buff *skb){
/* * Reassemble IP fragments. */
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL, ip_local_deliver_finish);
}
static int ip_local_deliver_finish(struct sk_buff *skb){
......
int protocol = ip_hdr(skb)->protocol;
const struct net_protocol *ipprot;
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot != NULL) {
ret = ipprot->handler(skb); }
}プロトコル登録セクションで示したように、tcp_rcv() と udp_rcv() の関数アドレスは inet_protos に保存されます。ここでは、パッケージ内のプロトコルの種類に応じてディストリビューションを選択し、skb パッケージをさらに上位層のプロトコルである udp と tcp にディスパッチします。
3.5 UDPプロトコル層の処理
プロトコル登録セクションで、udp プロトコルの処理機能は であると述べましたudp_rcv。
//file: net/ipv4/udp.c
int udp_rcv(struct sk_buff *skb){
return __udp4_lib_rcv(skb, &udp_table, IPPROTO_UDP);
}
int __udp4_lib_rcv(struct sk_buff *skb, struct udp_table *udptable,
int proto){
sk = __udp4_lib_lookup_skb(skb, uh->source, uh->dest, udptable);
if (sk != NULL) {
int ret = udp_queue_rcv_skb(sk, skb
} icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0);
}__udp4_lib_lookup_skbこれは、skb に従って対応するソケットを見つけ、見つかった場合はデータ パケットをソケットのバッファ キューに入れることです。見つからない場合は、宛先が到達不能な icmp パケットが送信されます。
//file: net/ipv4/udp.c
int udp_queue_rcv_skb(struct sock *sk, struct sk_buff *skb){
......
if (sk_rcvqueues_full(sk, skb, sk->sk_rcvbuf))
goto drop;
rc = 0;
ipv4_pktinfo_prepare(skb);
bh_lock_sock(sk);
if (!sock_owned_by_user(sk))
rc = __udp_queue_rcv_skb(sk, skb);
else if (sk_add_backlog(sk, skb, sk->sk_rcvbuf)) {
bh_unlock_sock(sk);
goto drop;
}
bh_unlock_sock(sk); return rc;
}sock_owned_by_user は、ユーザーがこのソケット上でシステムコールを行っているかどうか (ソケットが占有されているか) を判断し、そうでない場合は、ソケットの受信キューに直接入れることができます。存在する場合は、sk_add_backlogパケットをバックログ キューに追加します。ユーザーがソケットを解放すると、カーネルはバックログ キューをチェックし、データがある場合は受信キューに移動します。
sk_rcvqueues_full受信キューがいっぱいの場合、パケットは直接破棄されます。受信キューのサイズは、カーネル パラメータ net.core.rmem_max および net.core.rmem_default の影響を受けます。
4 つのrecvfrom システムコール
2 つの花が咲き、それぞれが枝を表します。以上で、Linux カーネル全体によるデータ パケットの受信と処理のプロセスが完了し、最後にデータ パケットをソケットの受信キューに入れます。recvfrom次に、ユーザー プロセスの呼び出し後に何が起こったかを振り返ってみましょう。コード内で呼び出しているのはrecvfromglibc ライブラリ関数であり、この関数が実行されると、ユーザーはカーネル状態になり、Linux によって実装されたシステム コールに入りますsys_recvfrom。Linux ペアを理解する前にsys_revvfrom、このコア データ構造を簡単に見てみましょうsocket。このデータ構造は大きすぎるため、今日のトピックに関連するコンテンツのみを次のように描画します。

図 11 ソケットカーネルのデータ構造
socketデータ構造内でconst struct proto_ops対応するのは、プロトコルのメソッドのセットです。各プロトコルは異なるメソッドのセットを実装しており、IPv4 インターネット プロトコル ファミリの場合、各プロトコルには次のように対応する処理メソッドがあります。UDP の場合、inet_dgram_opsメソッドが登録される によって定義されますinet_recvmsg。
//file: net/ipv4/af_inet.c
const struct proto_ops inet_stream_ops = {
......
.recvmsg = inet_recvmsg,
.mmap = sock_no_mmap, ......
}
const struct proto_ops inet_dgram_ops = {
......
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg, ......
}socketデータ構造内のもう 1 つのデータ構造は、struct sock *sk非常に大きく、非常に重要な下部構造です。このうち、sk_prot二次処理機能が定義されています。UDP プロトコルの場合は、UDP プロトコルによって実装されたメソッド セットに設定されますudp_prot。
//file: net/ipv4/udp.c
struct proto udp_prot = {
.name = "UDP",
.owner = THIS_MODULE,
.close = udp_lib_close,
.connect = ip4_datagram_connect,
......
.sendmsg = udp_sendmsg,
.recvmsg = udp_recvmsg,
.sendpage = udp_sendpage, ......
}socket変数を読んだ後、sys_revvfrom実装プロセスを見てみましょう。
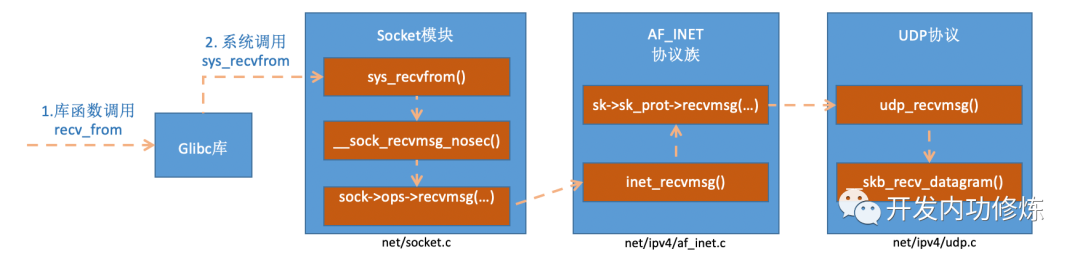
図 12 recvfrom 関数の内部実装プロセス
がinet_recvmsg呼んでいますsk->sk_prot->recvmsg。
//file: net/ipv4/af_inet.c
int inet_recvmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg,size_t size, int flags){
......
err = sk->sk_prot->recvmsg(iocb, sk, msg, size, flags & MSG_DONTWAIT,
flags & ~MSG_DONTWAIT, &addr_len);
if (err >= 0)
msg->msg_namelen = addr_len; return err;
}上で、これが udp プロトコルのソケットに当てはまるとsk_prot述べました。ここから私たちは方法を見つけました。net/ipv4/udp.cstruct proto udp_protudp_recvmsg
//file:net/core/datagram.c:EXPORT_SYMBOL(__skb_recv_datagram);
struct sk_buff *__skb_recv_datagram(struct sock *sk, unsigned int flags,int *peeked, int *off, int *err){
......
do {
struct sk_buff_head *queue = &sk->sk_receive_queue;
skb_queue_walk(queue, skb) {
......
}
/* User doesn't want to wait */
error = -EAGAIN;
if (!timeo)
goto no_packet; } while (!wait_for_more_packets(sk, err, &timeo, last));
}最後に、確認したいポイントを見つけました。上記では、アクセスといういわゆる読み取りプロセスを見てきましたsk->sk_receive_queue。データがなく、ユーザーが待機を許可した場合、wait_for_more_packets() が呼び出されて待機操作が実行され、ユーザー プロセスがスリープ状態になります。
5つのまとめ
ネットワーク モジュールは Linux カーネルの中で最も複雑なモジュールであり、単純なパケット受信プロセスには、ネットワーク カード ドライバー、プロトコル スタック、カーネル ksoftirqd スレッドなど、多くのカーネル コンポーネント間の相互作用が含まれているようです。とても複雑そうに見えますが、この記事ではカーネルのパケット受信処理を図解を使って分かりやすく説明したいと思います。次に、パケット収集プロセス全体をまとめてみましょう。
ユーザーがrecvfrom呼び出しを実行すると、ユーザープロセスはシステムコールを通じてカーネルモードに移行します。受信キューにデータがない場合、プロセスはスリープ状態になり、オペレーティング システムによって一時停止されます。この部分は比較的単純で、残りのシーンのほとんどは Linux カーネルの他のモジュールによって実行されます。
まず、パケットの受信を開始する前に、Linux は多くの準備作業を行う必要があります。
- 1. ksoftirqd スレッドを作成し、それに独自のスレッド関数を設定して、ソフト割り込みの処理を期待します。
- 2. プロトコル スタックの登録。Linux は arp、icmp、ip、udp、tcp などの多くのプロトコルを実装する必要があります。各プロトコルは独自の処理関数を登録するため、パッケージが到着したときに対応する処理関数をすぐに見つけることができて便利です。
- 3. ネットワーク カード ドライバーの初期化。各ドライバーには初期化機能があり、カーネルによってドライバーが初期化されます。この初期化プロセスでは、独自の DMA を用意し、NAPI のポーリング関数のアドレスをカーネルに伝えます。
- 4. ネットワークカードを起動し、受信キューと送信キューを割り当て、割り込みに対応する処理関数を登録します。
上記は、カーネルがパケットを受信する準備ができるまでの重要な作業であり、上記の準備が完了したら、ハード割り込みを開いてデータ パケットの到着を待つことができます。
データが到着すると、最初にそれを迎えるのはネットワーク カードです (行きます、これはナンセンスではありませんか)。
- 1. ネットワーク カードはデータ フレームをメモリの RingBuffer に DMA し、CPU への割り込み通知を開始します。
- 2. CPUは割り込み要求に応答し、ネットワークカード起動時に登録された割り込み処理関数を呼び出します。
- 3. 割り込み処理関数はほとんど何もせず、ソフト割り込み要求を開始します。
- 4. カーネル スレッド ksoftirqd スレッドは、ソフト割り込み要求があることを検出し、最初にハード割り込みを閉じます。
- 5. ksoftirqd スレッドは、パケットを受信するためにドライバーのポーリング関数の呼び出しを開始します。
- 6. ポーリング関数は受信したパケットをプロトコルスタックに登録されているip_rcv関数に送信します。
- 7. ip_rcv 関数は、パケットを udp_rcv 関数に送信します (tcp パケットの場合、パケットは tcp_rcv に送信されます)。
ここで、最初の質問に戻ることができます。ユーザー層で見た単純な行ですrecvfrom。データをスムーズに受信できるように、Linux カーネルは非常に多くの作業を行う必要があります。これはまだ単純な UDP ですが、これが TCP である場合、カーネルはさらに多くの作業を行う必要があり、カーネルの開発者は本当に善意で開発しているとため息がつきます。
パケット受信プロセス全体を理解すると、パケットを受信する Linux の CPU オーバーヘッドを明確に知ることができます。まず最初のブロックは、システムコールを呼び出してカーネル状態に陥るユーザープロセスのオーバーヘッドです。2 番目のブロックは、CPU 応答パケットのハード割り込みの CPU オーバーヘッドです。3 番目のブロックは、ksoftirqd カーネル スレッドのソフト割り込みコンテキストによって消費されます。後ほど、これらの費用を実際に観察するための専用記事を投稿します。
さらに、NAPI、GRO、RPS がないなど、ネットワークの送受信には拡張されていない詳細が多数あります。私の言ったことは正しすぎると、プロセス全体の全員の理解に影響を与えると思うので、メインフレームのみを維持するようにしてください。少ないほど良いです。