Guide: It is necessary to collect common architectural technical points as a project manager to understand these knowledge points and solve specific scenarios. Technology needs to serve the business, and the combination of technology and business can bring out the value of technology.
Table of contents
1. Microservices
Microservice architecture is an architectural pattern, which advocates dividing a single application into a group of small services, and the services coordinate and cooperate with each other to provide users with ultimate value. Each service runs in its own process, and services communicate with each other using a lightweight communication mechanism (usually an HTTP-based Restful API). Each service is built around a specific business and can be Independent deployment to production environment, production-like environment, etc.
- Monolithic application: simple, fragile (if a module fails, the whole system is unavailable), weak combat effectiveness, and low maintenance cost
- Microservice architecture: complex and robust (a problem with a certain module will not affect the overall availability of the system), strong combat effectiveness, and high maintenance costs
Features of microservice architecture:
- Published for a specific service, with little impact, low risk, and low cost
- Frequent version releases, fast delivery requirements
- Low-cost expansion, elastic scaling, adapting to the cloud environment
Why is Spring Cloud the most popular microservice framework in China, and what out-of-the-box components does it provide? An overview is as follows:
- Spring Boot service application
- Spring Cloud Config configuration center
- Spring Cloud Eureka Service Discovery
- Spring Cloud Hystrix fuse protection
- Spring Cloud Zuul Service Gateway
- Spring Cloud OAuth 2 Service Protection
- Spring Cloud Stream message-driven
- Distributed Full Link Tracking
- Deploy microservices
Extended reference: This article takes you to understand microservice architecture and design (multiple pictures) - Small Twenty Seven - Blog Garden (cnblogs.com)
2. Service Discovery
Service discovery refers to using a registration center to record the information of all services in the distributed system, so that other services can quickly find these registered services. Service discovery is the core module supporting large-scale SOA and microservice architecture, and it should be as high available as possible.
In addition to providing the three key features of service registration, directory, and search, service discovery also needs to be able to provide health monitoring, multiple queries, real-time updates, and high availability.
Service discovery has three roles, service provider, service consumer and service intermediary . Service intermediary is a bridge connecting service providers and service consumers. The service provider registers the address of the service it provides with the service intermediary, and the service consumer finds the address of the service he wants from the service intermediary, and then enjoys the service. The service intermediary provides multiple services, and each service corresponds to multiple service providers.
There are three typical service discovery components, namely ZooKeeper, Eureka and Nacos
3. Flow peak clipping
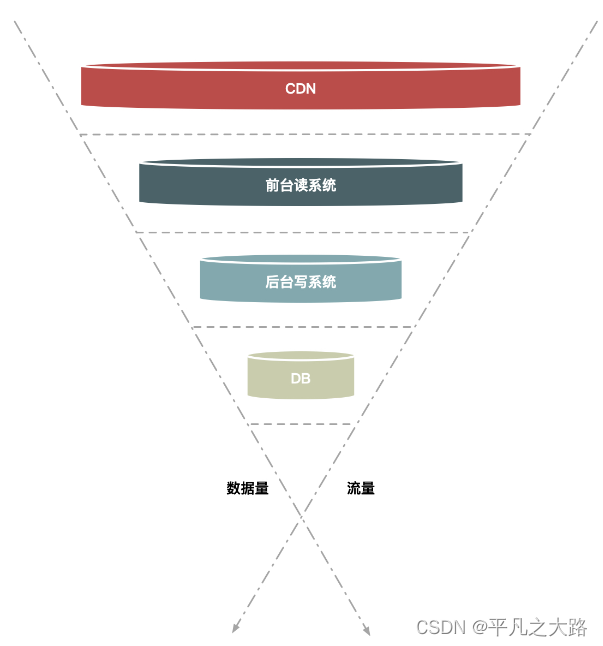
If you look at the request monitoring curve of the lottery or seckill system, you will find that this kind of system will have a peak during the time period when the event is open, but when the event is not open, the request volume and machine load of the system are generally relatively stable . In order to save machine resources, we cannot always provide the maximum resource capacity to support short-term peak requests. Therefore, it is necessary to use some technical means to weaken the instantaneous request peak and keep the system throughput controllable under the peak request. Peak clipping can also be used to eliminate glitches, making server resource utilization more balanced and sufficient. Common peak-shaving strategies include queuing, frequency limiting, hierarchical filtering, and multi-level caching.
Traffic peak shaving is like a solution to peak shifting and traffic restriction because of the problems of morning peak and evening peak.
Generally, the following methods are used:
- Queuing: The first thing that comes to mind in traffic peak shaving is the queue, which converts synchronous requests into asynchronous requests, and pushes traffic peaks smoothly through the message queue.
- Answer: The requests after answering the questions have a sequence, so that the subsequent business logic can be easily controlled
- Hierarchical filtering: filtering invalid requests, hierarchal filtering uses the funnel method for request processing.
4. Version compatible
In the process of upgrading the version, it is necessary to consider whether the new data structure can understand and parse the old data after the version is upgraded, and whether the newly modified protocol can understand the old protocol and make appropriate processing as expected. This requires version compatibility during the service design process.
For continuous iterative products, version configuration management needs to be done well, and some special cases of lower versions should be considered in version compatibility.
5. Overload protection
Overload means that the current load has exceeded the maximum processing capacity of the system. The occurrence of overload will cause some services to be unavailable. The unavailability of the service caller leads to the unavailability of the service caller, and the process of gradually amplifying the unavailability) . Overload protection is just a measure for this abnormal situation to prevent the service from being completely unavailable.
This pattern should be used to: Prevent applications from directly calling remote services or shared resources that are likely to fail.
Unsuitable scenarios: For direct access to local private resources in applications, such as data structures in memory, using the fuse mode will only increase system overhead. Not suitable as a replacement for exception handling for business logic in your application.
6. Service circuit breaker
The function of the service fuse is similar to the fuse in our home. When a service is unavailable or the response times out, in order to prevent the entire system from avalanche, the call to the service is temporarily stopped.
Scenario: An exception occurs in a certain service, dragging down the entire service link, consuming the entire thread queue, causing the service to be unavailable and resources to be exhausted:
1) The service provider is unavailable
- Hardware failure: server host downtime caused by hardware damage, inaccessibility of service providers caused by network hardware failure
- Program Bugs:
- Cache breakdown: Cache breakdown generally occurs when the cache application is restarted, when all caches are cleared, and when a large number of caches fail in a short period of time. A large number of cache misses cause requests to hit the backend directly, causing service providers to overload and cause service is not available
- A large number of requests from users: Before the seckill and the big promotion start, if the preparation is not sufficient, a large number of requests from users will also cause the service provider to be unavailable
2) Retry to increase traffic
- User retries: After the service provider is unavailable, the user can't stand the long wait on the interface, and keeps refreshing the page or even submitting the form
- Code logic retry: There will be retry logic after a large number of service exceptions at the service caller
3) The service caller is unavailable: Resource exhaustion caused by synchronous waiting: When the service caller uses synchronous calls, a large number of waiting threads will occupy system resources. Once the thread resources are exhausted, the services provided by the service caller will also be exhausted. It is in an unavailable state, so the service avalanche effect occurs.
7. Service downgrade
Service downgrade means that when the pressure on the server increases sharply, some services and pages are strategically downgraded according to the current business situation and traffic, so as to release server resources and ensure the normal operation of core tasks. Degradation often specifies different levels, and performs different processing in the face of different exception levels.
According to the service method: the service can be refused, the service can be delayed, and sometimes the service can be random.
According to the scope of service: a certain function can be cut off, and some modules can also be cut off.
In short, service degradation needs to adopt different degradation strategies according to different business needs. The main purpose is that although the service is damaged, it is better than nothing.
8. Fusing VS Degradation
The same point: the goal is the same, starting from usability and reliability, in order to prevent the system from crashing; the user experience is similar, and what the user experiences in the end is that some functions are temporarily unavailable;
Differences: The triggering reasons are different. Service fusing is generally caused by a service (downstream service) failure, while service degradation is generally considered from the overall load;
9. Service current limit
Current limiting can be regarded as a kind of service degradation. Current limiting is to limit the input and output traffic of the system to achieve the purpose of protecting the system. Generally speaking, the throughput of the system can be measured. In order to ensure the stable operation of the system, once the threshold that needs to be limited is reached, it is necessary to limit the flow and take some measures to complete the purpose of limiting the flow. For example: delayed processing, rejected processing, or partial rejected processing, etc.
10. Fault masking
The faulty machine is removed from the cluster to ensure that new requests are not distributed to the faulty machine.