1 はじめに
データベース、オペレーティングシステム、コンパイラを総称して三大システムと呼び、コンピュータソフトウェア全体の根幹とも言えます。その中でもデータベースはアプリケーション層に近く、多くの企業を支えています。この分野の開発は数十年を経て、常に新たな進歩が見られます。
多くの人がデータベースを使用したことがありますが、データベース、特に分散データベースを実装した人はほとんどいません。データベース実装の原理と詳細を理解することは、一方では個人のスキルを向上させ、他のシステムの構築に役立ちますが、他方では、データベースを有効に活用することにも役立ちます。
テクノロジーを研究する最良の方法は、オープンソース プロジェクトの 1 つを研究することです。データベースも例外ではありません。スタンドアロン データベースの分野には優れたオープンソース プロジェクトが数多くありますが、その中でも MySQL と PostgreSQL の 2 つは最も有名であり、多くの学生がこれら 2 つのプロジェクトのコードを見たことがあるでしょう。しかし、分散データベースに関しては、優れたオープンソース プロジェクトはそれほど多くありません。TiDB は広く注目を集めており、特に一部のテクノロジー愛好家はこのプロジェクトへの参加を望んでいます。分散データベース自体が複雑なため、多くの人がプロジェクト全体をよく理解していません。そのため、ユーザー目に見えるテクノロジーと、ユーザーには見えない多くの技術的なポイントが SQL インターフェイスの背後に隠されています。
2 セーブデータ
データベースの最も基本的な機能はデータを保存することなので、ここから始めます。
データを保存するにはさまざまな方法がありますが、最も簡単な方法は、メモリ内にデータ構造を直接構築して、ユーザーが送信したデータを保存することです。たとえば、配列の場合、データを受信するたびに、レコードが配列に追加されます。このソリューションは非常にシンプルで、最も基本的なニーズを満たし、パフォーマンスは間違いなく良好ですが、抜け穴がたくさんあります。最大の問題は、データが完全にメモリ内にあることです。サービスが停止されるか、サービスが停止されると、再起動すると、データは完全に失われます。
データ損失の問題を解決するには、データを不揮発性記憶媒体 (ハードディスクなど) に保存します。改善された解決策は、ディスク上にファイルを作成し、データを受信したときにファイルに行を追加するだけです。OK、これでデータを永続的に保存するためのソリューションが完成しました。しかし、それだけでは十分ではありません。このディスクに不良トラックがあった場合はどうなるでしょうか? RAID (独立ディスクの冗長アレイ) を実行して、スタンドアロンの冗長ストレージを提供できます。マシン全体がダウンしたらどうなるでしょうか? たとえば、火災が発生した場合、RAID はデータを保持できません。ストレージの代わりにネットワーク ストレージを使用したり、ハードウェアまたはソフトウェアを通じてストレージ レプリケーションを実行したりすることもできます。この時点で、データセキュリティの問題は解決したようで、安堵のため息をつくことができます。しかし、コピー処理中にコピー間の整合性は保証できるでしょうか? つまり、データが失われないことを前提として、データが良好であることも保証する必要があります。データが失われないようにすることは基本的な要件にすぎませんが、解決を待っている問題はさらに多くあります。
- データセンター全体の災害復旧をサポートできますか?
- 書き込み速度は十分に速いですか?
- データ保存後は読みやすいですか?
- セーブデータを改造するにはどうすればいいですか?同時変更をサポートするにはどうすればよいですか?
- 複数のレコードをアトミックに変更するにはどうすればよいですか?
これらの問題はそれぞれ非常に困難ですが、優れたデータストレージシステムを構築するには、上記のそれぞれの問題を解決する必要があります。データストレージの問題を解決するために、私たちは TiKV プロジェクトを開発しました。次に、TiKV の設計思想と基本概念をいくつか紹介します。
3 キーと値
データ ストレージ システムとして最初に決定することは、データ ストレージ モデル、つまりデータをどのような形式で保存するかです。TiKV が選択したのは Key-Value モデルであり、順序付けられた走査方法を提供します。TiKV は、簡単に言うと Key と Value を元の Byte 配列とした巨大な Map とみなすことができ、この Map では Byte 配列の元のバイナリビットを比較する順に Key が並べられています。ここにいる人は全員、TiKV について次の 2 つの点を覚えておく必要があります。
- これは巨大なマップです。つまり、キーと値のペアが保存されます。
- このマップ内のキーと値のペアは、キーのバイナリ順序に従って順序付けされます。つまり、特定のキーの位置をシークし、Next メソッドを継続的に呼び出して、このキーよりも大きいキーと値を取得できます。注文
ここまで話した後、ここで述べたストレージ モデルと SQL のテーブルの間にはどのような関係があるのかと尋ねる人もいるかもしれません。ここで 4 回言っておきたい重要なことが 1 つあります。
ここでのストレージ モデルは SQL のテーブルとは何の関係もありません。ここでのストレージ モデルは SQL のテーブルとは何の関係もありません。ここでのストレージ モデルは SQL のテーブルとは何の関係もありません。ここでのストレージ モデルは SQL のテーブルとは何の関係もありません。
ここで SQL の概念を忘れて、TiKV のような高性能で信頼性の高い巨大な (分散) マップを実装する方法に焦点を当てましょう。
4 ロックスDB
どの永続ストレージ エンジンでも、結局のところデータはディスクに保存される必要があり、TiKV も例外ではありません。ただし、TiKV はデータをディスクに直接書き込むのではなく、RocksDB にデータを保存することを選択し、RocksDB が特定のデータのランディングを担当します。この選択の理由は、スタンドアロン ストレージ エンジンの開発には多くの作業が必要であり、特に高性能スタンドアロン エンジンの場合、さまざまな細心の最適化が必要となるためです。RocksDB は、優れたオープンソースのスタンドアロン ストレージ エンジンです。スタンドアロン エンジンにはさまざまな要件がありますが、Facebook チームは継続的な最適化を行っているため、非常に強力で継続的に改良されているスタンドアロン エンジンをほとんど労力をかけずに利用できるようになります。もちろん、私たちはこのプロジェクトがより良いものになることを願って、RocksDB にもいくつかのコードを提供しました。ここでは、RocksDB はスタンドアロンの Key-Value マップであると単純に考えることができます。
基盤となる LSM ツリーは、データへの増分変更をメモリに保存し、指定されたサイズ制限に達した後、データをバッチでディスクにフラッシュします。ディスク内のツリーを定期的にマージして大きなツリーを形成し、パフォーマンスを最適化できます。
5 いかだ
さて、長征の最初の一歩が踏み出され、データ用の効率的で信頼性の高いローカル ストレージ ソリューションが見つかりました。ことわざにあるように、何事も初めは難しく、途中も難しく、最後も難しいものです。次に、より困難な課題に直面します。それは、スタンドアロン障害が発生した場合に、データが失われず、エラーが発生しないことをどのように保証するかです。簡単に言うと、データを複数のマシンにレプリケートする方法を見つけて、1 つのマシンがハングアップしても他のマシンにコピーを保持できるようにする必要があります。複雑な観点から言えば、このレプリケーション ソリューションが信頼性が高く、効率的で、信頼性が高く、効率的である必要もあります。レプリカの無効化を処理できる。難しそうに思えますが、幸いなことにRaftプロトコルがあります。Raft はコンセンサス アルゴリズムで、Paxos と同等ですが、理解しやすいです。Raft の論文、興味のある方はぜひご覧ください。この記事では Raft について簡単に説明します。詳細については論文を参照してください。もう 1 つ言及すべき点は、Raft 論文は単なる基本的な解決策にすぎず、論文に従って厳密に実装するとパフォーマンスが低下するため、Raft プロトコルの実装に多くの最適化を行っています。
Raft は、いくつかの重要な機能を提供するコンセンサス プロトコルです。
- リーダー選挙
- メンバーチェンジ
- ログのレプリケーション
TiKVではデータレプリケーションにRaftを使用しており、各データ変更はRaftログとして実装され、Raftのログレプリケーション機能により、データはグループ内のほとんどのノードに安全かつ確実に同期されます。

ここで、単一マシンの RocksDB を使用すると、データをディスクに迅速に保存でき、Raft を使用すると、複数のマシンにデータをレプリケートして、単一マシンの障害を防ぐことができるということを要約しましょう。データは、RocksDB に直接書き込むのではなく、Raft レイヤー インターフェイスを通じて書き込まれます。Raft を実装することで、KV が分散され、特定のマシンがハングアップすることを心配する必要がなくなりました。
6 地域
これに関して言えば、非常に重要な概念である「地域」について言及することができます。この概念は、その後の一連のメカニズムを理解するための基礎となりますので、このセクションをよく読んでください。
前述したように、TiKV は巨大で秩序のある KV マップとして認識されているため、ストレージの水平拡張を実現するには、データを複数のマシンに分散する必要があります。ここで述べたデータは複数のマシンに分散しており、Raft のデータ レプリケーションは概念ではありませんが、このセクションでは Raft のことは忘れて、理解しやすいようにすべてのデータのコピーが 1 つだけあると仮定します。
KV システムの場合、複数のマシンにデータを分散するための一般的なソリューションは 2 つあります: 1 つはキーに従ってハッシュを実行し、ハッシュ値に従って対応するストレージ ノードを選択する方法、もう 1 つは範囲を分割し、特定の連続したストレージ ノードを選択する方法です。キーは 1 つのストレージ ノードに保存されます。TiKV は 2 番目の方法を選択し、キーと値の空間全体を多くのセグメントに分割します。各セグメントは一連の連続したキーであり、各セグメントをリージョンと呼び、各リージョンに保存されるデータが一定の値を超えないようにすることを試みます。サイズ (このサイズは構成可能です。現在のデフォルトは 64MB です)。各領域は、StartKey から EndKey までの左から閉じて右から開く間隔で記述することができます。

ここでのリージョンは SQL のテーブルとは関係がないことに注意してください。SQL のことは忘れて、KV についてだけ話してください。データをリージョンに分割した後、次の 2 つの重要な作業を行います。
- リージョンの単位で、クラスター内のすべてのノードにデータを分散し、各ノードで提供されるリージョンの数がほぼ同じになるようにします。
- Raftのレプリケーションとリージョン単位のメンバー管理
この 2 つの点は非常に重要ですので、1 つずつ説明しましょう。
まず最初の点を見てください。データはキーに従って多数のリージョンに分割され、各リージョンのデータは 1 つのノードにのみ保存されます。私たちのシステムには、クラスター内のすべてのノードにリージョンをできるだけ均等に分散するコンポーネントが含まれているため、一方ではストレージ容量の水平方向の拡張を実現できます (新しいノードを追加すると、他のノードのリージョンは一方、負荷分散も実現します (あるノードに大量のデータがあり、他のノードにデータがないということは起こりません)。同時に、上位レベルのクライアントが必要なデータに確実にアクセスできるようにするために、ノード上のリージョンの分布を記録するコンポーネントもシステム内に存在します。つまり、任意のキーを通じて、キーがどのリージョンにあるか、およびそのリージョンが現在どのノードにあるかをクエリします。
2 番目の点については、TiKV はリージョン単位でデータをレプリケートします。つまり、リージョン内のデータの複数のコピーが保存され、各コピーをレプリカと呼びます。Raft を介してレプリカ間でデータの一貫性が維持され、リージョンの複数のレプリカが異なるノードに保存されて Raft グループを形成します。レプリカの 1 つがグループのリーダーになり、他のレプリカがフォロワーになります。すべての読み取りと書き込みはリーダーによって実行され、リーダーによってフォロワーにコピーされます。
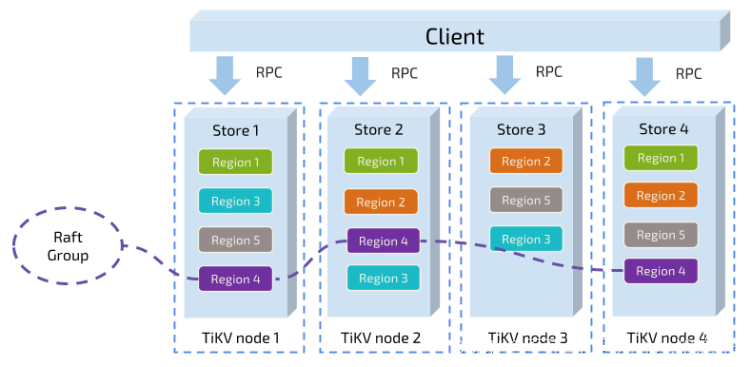
データを分散および複製するための単位としてリージョンを使用しており、特定の災害復旧機能を備えた分散 KeyValue システムを備えているため、データ ストレージやディスク障害、データ損失を心配する必要がありません。これは素晴らしいですが、完璧ではないため、さらに多くの機能が必要です。
7 MVCC
多くのデータベースはマルチバージョン管理 (MVCC) を実装しており、TiKV も例外ではありません。2 つのクライアントがキーの値を同時に変更するシナリオを想像してください。MVCC がない場合、データをロックする必要があります。分散シナリオでは、パフォーマンスとデッドロックの問題が発生する可能性があります。TiKV の MVCC 実装は、Key の後に Version を追加することで実現されます。簡単に言うと、MVCC の前の TiKV は次のようになります。
Key1 -> 値
Key2 -> 値
……
KeyN -> 値
MVCC を使用した場合、TiKV のキー配列は次のようになります。
Key1-バージョン3 -> 値
Key1-バージョン2 -
> 値 Key1-バージョン1 -> 値
……
Key2-バージョン4 -> 値
Key2-バージョン3 -> 値
Key2-バージョン2 -> 値
Key2-バージョン1 -> 値
……
KeyN-バージョン2 - > 値
KeyN-Version1 -> 値
……
同じキーの複数のバージョンについては、大きいバージョン番号を前に、小さいバージョン番号を後ろに配置することに注意してください (キーと値のセクションで紹介したキーが規則正しく配置されていることを思い出してください)。ユーザーはキー + バージョンを通じて値を取得します。キーとバージョンを使用して、キー バージョンである MVCC キーを構築できます。次に、直接 Seek(Key-Version) を実行して、この Key-Version 以上の最初の位置を見つけることができます。
8件
TiKVのトランザクションはPercolatorモデルを採用しており、多くの最適化が行われています。TiKV のトランザクションはオプティミスティック ロックを使用します。トランザクションの実行中、書き込みと書き込みの競合は検出されません。競合の検出は送信プロセス中にのみ行われます。競合する当事者のうち、先に送信を完了した者のうち、書き込みは成功し、相手はトランザクション全体を再実行しようとします。ビジネスの書き込み競合が深刻ではない場合、テーブル内の特定の行のデータをランダムに更新するなど、テーブルが非常に大きい場合、このモデルのパフォーマンスは非常に優れています。ただし、ビジネス書き込み競合が深刻な場合、パフォーマンスは低下します。極端な例はカウンタです。複数のクライアントが同時に少数の行を変更すると、深刻な競合が発生し、多数の無効な再試行が発生します。
その他9
これまでのところ、TiKV の基本概念と詳細を学び、トランザクションを備えたこの分散 KV エンジンの階層構造とマルチコピー フォールト トレランスを実現する方法を理解しました。次のセクションでは、KV ストレージ モデル上に SQL レイヤーを構築する方法を紹介します。