
努力は凡庸ではないよ〜
学ぶ最大の理由は平凡を取り除くことであり、1日早ければ人生はより素晴らしくなり、1日遅ければさらに平凡になります。
目次
7. 現在の状態が親の状態と一致しているかどうかを確認します。
1. 入力状況によっては、無限ループや過剰なメモリー消費が発生する場合がありますが、これらの状況に適切に対処するために、制限や最適化措置を追加することができます。
2. 研究の結果、川を渡る未開人や宣教師の問題では、次の 2 つの最適化戦略の方が優れていることがわかりました。
3. ここでは検索の深さを制限する例を取り上げます。次の手順に従うことができます。
1. 問題の説明
N 人の宣教師と N 人の未開人が川を渡るためにやって来ます。川岸には一度に最大 k 人が乗れるボートがあります。質問: 安全のため、宣教師は、いつでも川の両側とボートに乗っている野蛮人の数が宣教師の数を超えないよう、フェリーの計画をどのように立てるべきですか(そうしないと安全ではありません。そして宣教師たちは野蛮人に食べられるかもしれない)。それは、左岸から右岸まで宣教師と野生人を運ぶ過程の任意の時点で、M(宣教師の数)≧C野生人の数)、M+C≦kを満たすフェリー計画を解くことである。
2. 問題の説明
1. アルゴリズム解析
宣教師の数を M、未開人の数を C とすると、この問題を状態空間で解くプロセスは次のようになります。
M、C = N、ボート = k、M>=C および M+C <= K が必要
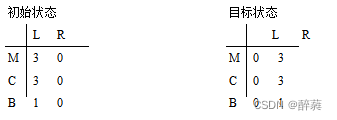
トリプル (ML 、 CL 、 BL) で表されます。
ここで、 0<=ML 、 CL <= 3 、 BL ∈ { 0 , 1}
初期状態: 川の左岸に未開人 3 人、宣教師 3 人、川の右岸に未開人 0 人、宣教師 0 人、船は左岸に止まり、乗員は 0 人です。初期状態(3、3、1)
目標状態: 川の左岸に未開人 0 名と宣教師 0 名、川の右岸に未開人 3 名と宣教師 3 名、ボートは右岸に停止し、乗員は 0 名です。ターゲット状態 (0, 0, 0)
全体の問題は、初期状態から一連の中間状態を経て、どのようにして目標状態に到達するかという問題として抽象化されており、状態変化はボートを漕いで川を渡ることによって引き起こされる。
川の左岸を基点として考えてください。
Pij: 左岸から右岸までボートを漕ぎます。最初の下付き文字 i は船に乗っている宣教師の数を示し、2 番目の下付き文字 j は船に乗っている人食い人種の数を示します。
Qij: ボートを右岸から左岸に漕ぎ戻します。添え字は前と同じように定義されます。
合計 10 個の演算があり、演算セットは F={P01, P10, P11, P02, P20, Q01, Q10, Q11, Q02, Q20} です。
ルールセット
P10 if ( ML ,CL , BL=1 ) then ( ML–1 , CL , BL –1 )
P01 if ( ML ,CL , BL=1 ) then ( ML , CL–1 , BL –1 )
P11 if ( ML ,CL , BL=1 ) then ( ML–1 , CL–1 , BL –1 )
P20 if ( ML ,CL , BL=1 ) then ( ML–2 , CL , BL –1 )
P02 if ( ML ,CL , BL=1 ) then ( ML , CL–2 , BL –1 )
Q10 if ( ML ,CL , BL=0 ) then ( ML+1 , CL , BL+1 )
Q01 if ( ML ,CL , BL=0 ) then ( ML , CL+1 , BL +1 )
Q11 if ( ML ,CL , BL=0 ) then ( ML+1 , CL +1 , BL +1 )
Q20 if ( ML ,CL , BL=0 ) then ( ML+2 , CL +2 , BL +1 )
Q02 if ( ML ,CL , BL=0 ) then ( ML , CL +2, BL +1 )
要件に従って、次の 5 つの可能な河川横断スキームが得られます。
(1) 宣教師2名との交配
(2) フェリー 2 サベージ
(3) クロッシング 1 サベージ 1 宣教師
(4) 交差 1 宣教師
(5) クロッシング1 サベージ
ルールの選択をガイドするヒューリスティック関数を見つける

このプログラムは、状態ノードを定義し、コレクションを使用して状態ノードを保存し、再帰的思考を使用してターゲット状態を見つける必要があります。
2. プログラムの実行プロセス
上記の原則は完全に宣教師と未開人の数が 3 名、船の最大乗客定員が 2 名であるという前提に基づいています。上記の分析を組み合わせると、宣教師と未開人の具体的な数と船の最大乗客定員が規定されていない場合、前の分析との違いは人数に応じて、どのようにするかだけであることがわかります。川の端から端までたくさんの乗客がいますか? 方法、その他の原理的なプロセスはすべて、宣教師と野蛮人の数が 3 人で、船の最大乗客定員が 2 人の場合と同じです。
表 1 に示すように、合計 32 の可能な状態が存在します。
表 1 宣教師と人食い問題の考えられるすべての状態
| 州 |
m、c、b |
州 |
m、c、b |
州 |
m、c、b |
州 |
m、c、b |
| S0 |
3,3,1 |
S8 |
1,3,1 |
S16 |
3,3,0 |
S24 |
1,3,0 |
| S1 |
3,2,1 |
S9 |
1、2、1 |
S17 |
3,2,0 |
S25 |
1、2、0 |
| S2 |
3,1,1 |
S10 |
1、1、1 |
S18 |
3,1,0 |
S26 |
1,1,0 |
| S3 |
3,0,1 |
S11 |
1,0,1 |
S19 |
3,0,0 |
S27 |
1,0,0 |
| S4 |
2,3,1 |
S12 |
0、3、1 |
S20 |
2,3,0 |
S28 |
0,3,0 |
| S5 |
2,2,1 |
S13 |
0、2、1 |
S21 |
2,2,0 |
S29 |
0,2,0 |
| S6 |
2,1,1 |
S14 |
0、1、1 |
S22 |
2,1,0 |
S30 |
0、1、0 |
| S7 |
2,0,1 |
S15 |
0,0,1 |
S23 |
2,0,0 |
S31 |
0,0,0 |
タイトルで指定された条件に従って、違法な状態を取り消す必要があることに注意してください。これにより、検索と解決の効率が向上します。たとえば、第一に、岸にいる人食い人種の数は宣教師の数を上回っており、S4、S8、S9、S20、S24、およびS25の6つの州は違法である、第二に、右岸の人食い人種は、数値が僧侶を超える状況、つまり S6、S7、S11、S22、S23、S27 など; 残りの 20 の法的状態のうち、不可能な状態が 4 つあります; S15 と S16 は、船が存在するため出現できません。無人の海岸に停泊している可能性がある; 数で優勢な人食い人種の目の前で宣教師が安全にボートを漕いで戻ることは不可能であるため、S3 は出現できない; S28 も漕ぐ必要がある。ボートは支配的な人喰いの鼻の下を通って対岸まで安全に漕ぎ進んだ。状態空間には、トピックで指定された条件を実際に満たす妥当な状態が 16 個しかないことがわかります。
3. 問題を解決するプログラムを書く
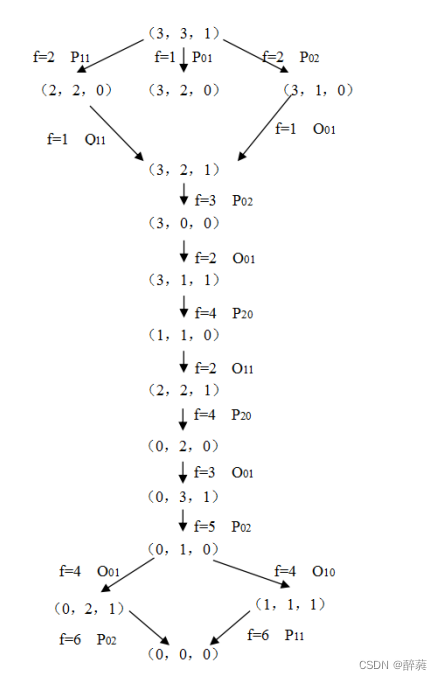
3. 問題思考
1. アルゴリズム分析:
宣教師と未開人が川を渡る問題で、宣教師の数をM、未開人の数をC、船の乗客定員をKとする。問題の状態空間は次のとおりです。
左岸:M、C
右岸:0、0
開始位置:左岸
初期状態:左岸に宣教師がM名、野蛮人がC名、右岸には誰もおらず、ボートは左岸に止まっています。
目標状態: 左岸には誰もおらず、右岸には M 人の宣教師と C 人の野蛮人がおり、ボートは右岸に止まります。
この問題を解決するには、状態空間検索とヒューリスティック関数を使用できます。船が左岸から右岸に移動する際、乗船する乗客は次のルールに従って選択できます。
①宣教師2人をクロスさせる
②野蛮人2体をクロスさせる
③野蛮人1人と宣教師1人のクロス
④クロス1 宣教師
⑤ 交差 1 野蛮人
プログラムの実行フローは次のとおりです。
①法的国家の集合を定義し、条件を満たさない国家を除外する。
②状態空間探索と再帰的手法を用いて、一連の状態遷移を通じて目的の状態を見つけます。
③ ヒューリスティック関数に従って、状態遷移をガイドする適切なルールを選択します。
④ 目標の状態が見つかるか、解決策が見つからないまで、考えられる各状態をたどって判断します。
⑤ 問題を解くプログラムを書き、結果を出力します。
2. 実験実行プロセス:
①宣教師と川を渡る野蛮人の状態を表現するために使用される状態空間クラスを作成します。
② 初期状態と目標状態を初期化します。
③法的国家の集合を定義し、条件を満たさない国家を除外する。
④ 深さ優先検索アルゴリズムと再帰的方法を使用して、法的状態セット内の有効なパスを検索します。
⑤ ヒューリスティック機能を実現し、ルールに従って適切な状態遷移を選択します。
⑥目的の状態が見つかるか、解が見つからないまで、考えられる各状態をたどって判断します。
⑦ 問題を解決し、結果を出力するプログラムを作成します。
4. コードの各ステップの方法、目的、重要性
1. ライブラリをインポートします。
![]()
pandas はデータ処理と結果の出力に使用されます。
numpy は配列操作を処理するために使用されます。
2. 入力を取得します。

ユーザーは宣教師の数、野人の数、船の最大収容人数を入力します。
3. データ構造を定義します。
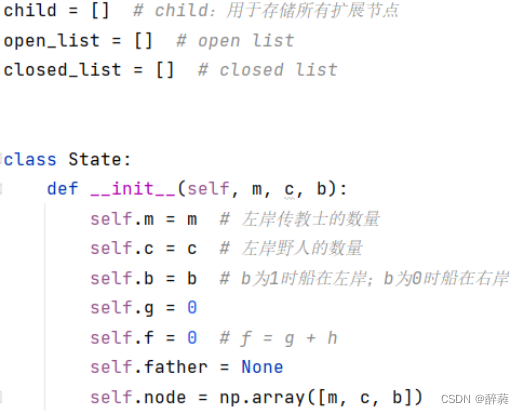
![]()
子リストは、展開されたすべてのノードを保存するために使用されます。
open_list は、展開されるノードを格納するために使用されます。
Closed_list は、展開されたノードを格納するために使用されます。
State クラスは、宣教師の数、未開人の数、船の位置などの情報を含む州ノードを表します。
4. 州が合法かどうかを判断します。

セーフ関数は、状態ノードが正当であるかどうかを判定し、ある条件に従って制約条件が満たされるかどうかを判定するために使用される。
5. ヒューリスティック関数:
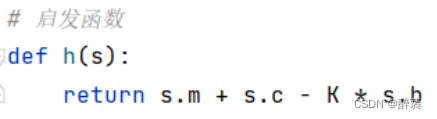
h 関数は、ノードのヒューリスティック値を評価するために使用されるヒューリスティック関数です。ここでは、宣教師の数と未開人の数から船の位置と船の最大容量を引いた積が使用されます。
6. 2 つの状態が同じかどうかを判断します。

等しい関数は、2 つの状態ノードが同じかどうかを判断するために使用され、ノードの属性値が等しいかどうかを比較することによって、それらが同じかどうかを判断します。
7. 現在の状態が親の状態と一致しているかどうかを確認します。

back 関数は、現在の状態ノードがその祖先ノードと一致しているかどうかを判断するために使用され、ノードの属性値を段階的に遡って比較することで一致しているかどうかを判断します。
8. 開いたリストを f 値で並べ替えます。
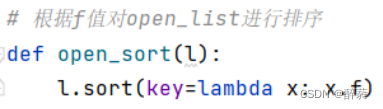
open_sort 関数は、f 値に従ってオープンリスト内のノードをソートするために使用されます。
9. リストでノードを見つけます。
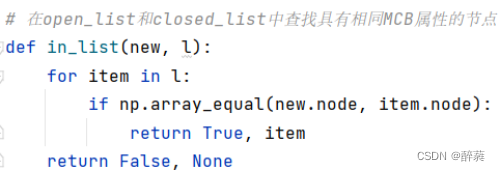
in_list 関数は、リスト内に指定されたノードと同一のノードがあるかどうかを確認するために使用されます。
10. A* アルゴリズムの本体:

open_list を使用して展開するノードを保存し、closed_list を使用して展開されたノードを保存します。
ループ内では、まずターゲット ノードが存在するかどうかを確認し、存在する場合は A リストに追加し、open_list から削除します。
open_list が空の場合は、ループを終了します。
open_list から最初のノードを取得し、closed_list に追加し、船の位置に応じて左側と右側に新しい子ノードを生成します。
子ノードの正当性と親ノードとの整合性を確認し、条件を満たさない場合は子ノードを削除します。
それ以外の場合は、子ノードの親ノードを設定し、g 値と f 値を更新し、子ノードを open_list に追加してから、open_list を並べ替えます。
最終的なターゲット ノード セット A を返します。
11. パスを再帰的に出力します。

printPath 関数は、ターゲット ノードから最初のノードまで遡ってパスを再帰的に出力し、各ノードの属性値を出力するために使用されます。
12.メインプログラム:

メインプログラムはまず宣教師の数、未開人の数、船の最大収容人数を出力します。
A_star 関数を呼び出して、最終的なターゲット ノード セットを取得します。
解の数を出力します。
解決策が存在する場合は、各解決策へのパスが 1 つずつ出力されます。
解決策が見つからない場合は、適切なプロンプト メッセージが出力されます。
5.綿密な調査とコードの最適化
1. 入力状況によっては、無限ループや過剰なメモリー消費が発生する場合がありますが、これらの状況に適切に対処するために、制限や最適化措置を追加することができます。
① 検索の深さを制限する: プログラムが無限に検索するのを防ぐために、検索の深さの制限を追加します。最大検索深さを設定し、検索中に確認できます。最大深度に達しても解が見つからない場合は、解がないと判断するか、探索を終了することができる。
②状態の繰り返しを制限する: 繰り返しの訪問を避けるために、訪問した状態ノードをclosed_listに記録します。ノードを展開するときは、新しく生成されたノードが Closed_list に既に存在するかどうかを最初に確認し、存在する場合はそのノードをスキップできます。
③ヒューリスティック関数の最適化:ヒューリスティック関数の計算方法を調整することで、より正確かつ効率的になります。ヒューリスティック関数の選択は、検索アルゴリズムの効率と結果の品質に影響します。さまざまなヒューリスティック関数を試して、アルゴリズムのパフォーマンスを最適化できます。
④ 枝刈り戦略: 新しいノードを生成する際、いくつかの条件判断を使用して無効な枝を枝刈りします。たとえば、宣教師よりも野人の方が多い場合、この状態は無効になり、スキップできます。
⑤ 反復深化検索を使用する: 反復深化検索は、反復ごとに検索の深さを段階的に増加させる深さ優先検索の変形です。このアプローチでは、限られた検索深さ内でソリューションを見つけることができ、完全な深さ優先検索よりもスペースを必要としません。
2. 研究の結果、川を渡る未開人や宣教師の問題では、次の 2 つの最適化戦略の方が優れていることがわかりました。
① 検索深さを制限する: 最大検索深さを設定することで、プログラムが無限に検索することを防ぎます。これは、アルゴリズムの実行時間とリソース消費を制御するのに役立ちます。問題のサイズと複雑さに基づいて、最大検索深度を決定できます。探索が最大深さを超えて解が見つからない場合には、解がないと判断したり、探索を終了したりすることができる。
②状態の繰り返しを制限する: 繰り返しの訪問を避けるために、訪問した状態ノードをclosed_listに記録します。これにより、アルゴリズムが無効な状態を繰り返し循環するのを防ぎます。ノードを展開するときは、まず新しく生成されたノードがclosed_listに含まれているかどうかを確認します。含まれている場合は、そのノードをスキップできます。
もちろん、どの制限措置を使用するかは、ニーズと実際の状況によって異なります。アルゴリズムの実行時間に関してより厳しい要件がある場合は、検索の深さを制限する方が適切な場合があります。アルゴリズムのメモリ消費がより重要な場合は、状態の重複を制限することがより重要になる可能性があります。
3. ここでは検索の深さを制限する例を取り上げます。次の手順に従うことができます。
①コードに変数を追加して、最大の検索深さを指定します(max_ Depth など)。
② A_star 関数を変更して、検索処理中に現在の検索深さが最大深さを超えているかどうかを確認します。再帰の次のレベルに入る前に深さをチェックでき、最大深さを超えると検索が終了します。必要に応じて、次のコード スニペットを追加できます。
get.g > max_ Depth の場合:
# 最大深さを超えたので、検索を終了します
壊す
③main関数に最大検索深さの値を設定します(例:max_ Depth = 10)。
最大検索深さを設定することにより、アルゴリズムの実行時間とリソース消費を制御できます。問題の規模と複雑さに応じて、必要に応じて最大深さの値を適切に調整できます。
検索深さの変更は、アルゴリズムの実行時間を制御するのに役立つ単なる制限措置であることに注意してください。ただし、最適な解決策を検索するのに十分な深さが存在しない可能性があるため、場合によっては解決策が見つからない可能性もあります。したがって、ソリューションを使用する際の所要時間とソリューションの品質の間にはトレードオフの関係があります。
6、完全なコード
川を渡る宣教師と野蛮人 (numpy、パンダ) は、完全なコード A* アルゴリズムを使用してカスタマイズおよび入力できます。リソース - CSDN ライブラリ