Python 爬虫類の就学前の準備
インターネット時代では、ネットワークを通じて大量の情報データを取得できますが、これらのデータを分析してマイニングするには、まずデータをクロールする必要があります。強力なプログラミング言語である Python は、非常に強力なクローリング機能も備えているため、Python クローラー技術は大きな注目を集め、多くの業界で広く使用されています。では、Python クローラーを学ぶ前にどのような準備をする必要があるのでしょうか?
Web クローリングを学ぶ理由
学ぶべきことは
网络爬虫たくさんあります好处。

まず、クローラを利用することで、インターネット上から大量のデータを自動的に取得し、効果的に保存・分析することができるため、ビッグデータ時代のデータ分析に非常に役立ちます。次に、クローラーを学習すると、検索エンジンがどのように機能するかをより深く理解できるようになり、検索エンジンの最適化に使用できます。また、クローラエンジニアは現在不足している人材の一つであり、雇用のチャンスと展望も期待できます。
学習目的とニーズ
爬虫類を学ぶ目的は人によって若干異なりますが、一般的には次のように要約できます。
- 検索エンジンを個人的にカスタマイズします。
- ビッグデータ分析を容易にするために、より多くのデータソースを取得します。
- 検索エンジンの最適化を行います。
- 就職・転職してクローラーエンジニアになりましょう。
したがって、上記の目的とニーズを達成するには、Python クローラーの基本的な知識と技術を習得する必要があります。
観客
このチュートリアルは主に、Python スクレイピングに興味のある初心者および上級学習者を対象としています。HTML、CSS、JavaScript、Python プログラミングの知識がある場合は、このチュートリアルを読むのがより簡単で楽しいでしょう。
Python Web クローラーを学習するための前提条件
Python Web クローラーを学習する前に、次の基本的な知識が必要です。
- HTML、CSS、および JavaScript の基礎知識: HTML は Web ページのマークアップ言語であり、CSS は Web ページを美しくするために使用され、JavaScript は Web ページのインタラクションと動的効果に使用されます。Python クローラーを学習する場合、Web ページのソース コードに基づいて Web ページの構造とコンテンツ情報を解析する必要があるため、HTML、CSS、および JavaScript に精通している必要があります。
- Python プログラミングの基本知識: Python はクローラーで最も一般的に使用されるプログラミング言語の 1 つであるため、Python の基本的な構文とプログラミングの考え方を学ぶ必要があります。
- ネットワーク テクノロジの基本知識: Python クローラーを学習するには、HTTP プロトコル、TCP/IP プロトコルなど、いくつかの基本的なネットワーク テクノロジとプロトコルを理解する必要があります。
もちろん、これらの基礎知識は Python クローラーを学習するための前提条件にすぎません。これらの知識を習得したら、Python クローラーについて学習を開始できます。
つまり、Python クローラーの学習にはある程度の予備知識が必要ですが、段階的に学習して練習していけば、近い将来、Python クローラー エンジニアの資格を取得できると思います。
爬虫類とは何ですか
用語: Web クローラー(Web スパイダー、Web ロボットとも呼ばれます)

Web クローラーとは、インターネットの情報を一定のルールに従って自動的に取得するプログラムまたはスクリプトのことで、Web スパイダー、Web ロボット、Web ページ チェイサーなどとも呼ばれます。ビッグデータ時代の到来に伴い、インターネットではクローラの役割がますます重要になり、私たちが知りたい情報を効率よく入手することができます。
Web クローラーのコンポーネント
Web クローラーの構成はさまざまな角度から分類でき、いくつかの違いがある場合があります。
从更宏观的角度看Web クローラーは主に、クローリング、解析、ストレージの 3 つの部分で構成されます。これら 3 つの部分は互いに独立していますが、密接に接続されて完全な Web クローラー システムを形成します。
クロールとは対象の Web サイト上のデータを取得すること、解析とはデータをコンピューターが読み取り可能な形式に変換し、必要なデータのクリーニングや処理を行うこと、ストレージとはデータをデータベースまたはファイルに特定の形式で保存することです。
从更微观的角度看Web クローラーの構成は、コントロール ノード、クローラー ノード、リソース ライブラリに分けることができます。
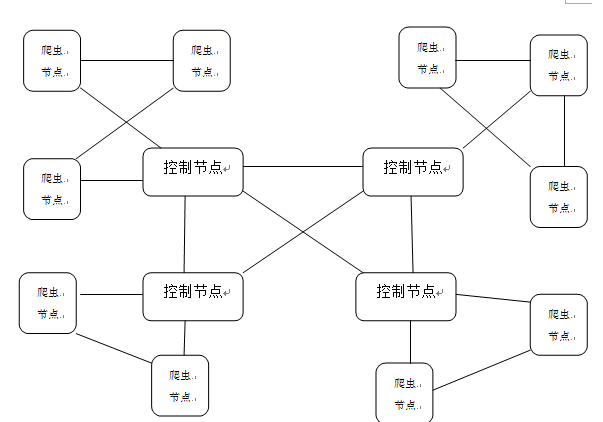
この構成方法は、Web クローラーの実際の動作プロセスに重点を置いています。
| マクロの視点 | 説明 |
|---|---|
| 這う | クローラー ノードは、ネットワーク リソース ライブラリにアクセスして、指定された戦略に従って Web ページをクロールし、キャプチャされたデータをストレージ モジュールに送信します。 |
| 分析する | Web クローリングによって取得されたデータを、後で使用できるようにクリーニング、フィルタリング、フォーマットなどを行う |
| 保管所 | クローラーが取得したデータは保存する必要があり、具体的な方法としてはデータベース、テキストファイル、バイナリファイル、メモリキャッシュなどが挙げられます。 |
| マイクロアングル | 説明 |
|---|---|
| 制御ノード | Web クローラー システム全体の中心であり、クローラー ノードの作業の指揮、計画、監視を担当します。 |
| クローラーノード | クロール タスクを実行し、指定されたクロール戦略に従って Web ページをクロールし、データをストレージ モジュールに送信する本体 |
| リソースライブラリ | Web クローラーが情報を取得するターゲット サイト、およびクローラー ノードの主なクローリング オブジェクト |
したがって、両方のステートメントには、Web クローラーの理解とアプリケーション シナリオのニーズに応じて適用可能性があります。
Web クローラーの種類
データをクローリングする目的と方法に応じて、Web クローラーはさまざまな種類に分類できます。一般に、Web クローラーは次のカテゴリに分類できます。
-
**通用网络爬虫**: 深さ優先または幅優先の方法でインターネット上のすべてのページを走査し、ネットワーク全体のデータを収集します。一般的な Web クローラーは、ロボット プロトコルに従う必要があります。このプロトコルを通じて、Web サイトはどのページがクロール可能でどのページがクロールできないかを検索エンジンに伝えます。
ロボット協定: 法的効力を持たない一種の「協定兼通称」協定であり、インターネット民の「契約精神」を体現したものです。業界の実務者は意識的にこの協定を遵守するため、「紳士協定」とも呼ばれます。
| コンセプト | クロール対象リソース インターネット全体には、膨大な数のクロール対象が存在します。 |
|---|---|
| 性能要件 | すごく高い。 |
| アプリケーションシナリオ | 非常に高い応用価値を持つ大規模な検索エンジン。 |
| 構成 | これは、初期 URL 収集、URL キュー、ページ クローリング モジュール、ページ分析モジュール、ページ データベース、リンク フィルタリング モジュールなどで構成されます。 |
| 這う戦略 | 主に、深さ優先のクローリング戦略と幅優先のクローリング戦略があります。 |
-
聚焦网络爬虫: 特定の Web サイトまたはトピックのみをクロールし、Web サイトまたはトピックに関連するデータのみを収集します。
聚焦爬虫运行流程图
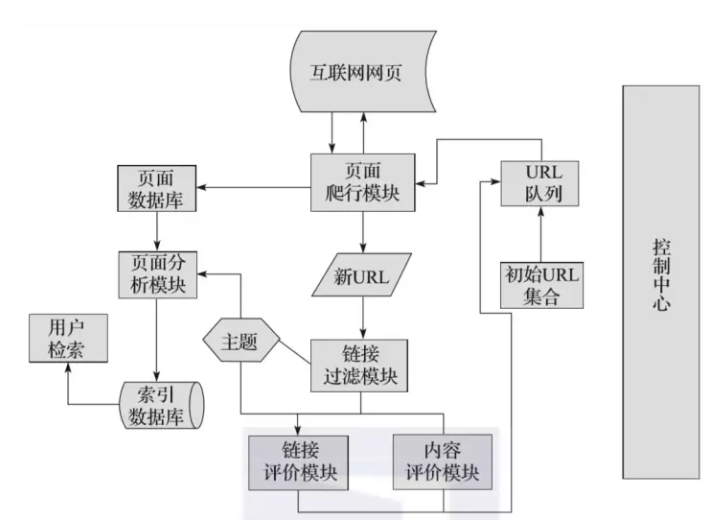
| コンセプト | トピックに関連するページでクロール対象を見つけ、特定の情報をクロールします。 |
|---|---|
| 性能要件 | - |
| アプリケーションシナリオ | これは主に、特定のグループにサービスを提供するための特定の情報のクローリングに使用されます。 |
| 構成 | 初期 URL、URL キュー、ページ クローリング モジュール、ページ分析モジュール、ページ データベース、リンク フィルタリング モジュール、コンテンツ評価モジュール、リンク評価モジュール。 |
| 這う戦略 | コンテンツ評価に基づくクローリング戦略、リンク評価に基づくクローリング戦略、強化学習に基づくクローリング戦略、およびコンテキスト グラフに基づくクローリング戦略。 |
增量式网络爬虫: リソースと時間を節約するために、ターゲット Web サイト内の新しいデータと変更されたデータのみをクロールします。
| コンセプト | ダウンロードした Web ページを段階的に更新し、新しく生成または変更された Web ディスク クローラーのみをクロールします。これにより、クロールされたページが可能な限り新しいものであることがある程度保証されます。 |
|---|---|
| 性能要件 | - |
| 特徴 | 新しく生成または更新されたページはクロールする必要があり、変更されていないページは再ダウンロードされません。これにより、データのダウンロード量が効果的に削減され、クロールされた Web ページが適時に更新され、時間とスペースの消費が削減されますが、クロール アルゴリズムの複雑さと実装の難易度は高まります。 |
| アプリケーションシナリオ | 最初のクロールが完了したら、タイムリーにページを更新し続けます。 |
| 構成 | クロールモジュール、ソートモジュール、更新モジュール、ローカルページセット、クロール対象のURLセット、ローカルURLセット。 |
| 這う戦略 | - |
| 一般的な方法 | 統一更新方法、個別更新方法、分類別更新方法。 |
-
均一な更新方法: クローラーは、Web ページの変更頻度に関係なく、同じ頻度ですべての Web ページにアクセスします。
-
個別更新方法: クローラーは、個々の Web ページが変更される頻度に基づいて個々のページを再訪問します。
-
分類ベースの更新方法: クローラーは、Web ページの変更頻度に応じて Web ページを 2 つのタイプ (更新の速い Web ページのサブセットと更新の遅い Web ページのサブセット) に分類し、これら 2 つのタイプの Web ページを異なる頻度で範囲指定します。
-
**深层网络爬虫**: 一般的な Web クローラーや集中型 Web クローラーと比較して、ディープ Web クローラーは 1 つの Web ページから他の関連する Web ページを再帰的にクロールします。より複雑なデータ情報を取得できますが、多くのリソースと時間コストを消費する必要もあります。
| コンセプト | インターネットの深いページをクロールできます。(最も重要な部分はフォーム部分に記入することです) |
|---|---|
| 性能要件 | - |
| アプリケーションシナリオ | ほとんどのページ |
| 構成 | URL リスト、LVS リスト (LVS はラベル/値のコレクション、つまりフォームに入力するデータ ソースを指します)、クローラー コントローラー、パーサー、LVS コントローラー、フォーム アナライザー、フォーム プロセッサー、応答アナライザー。 |
| 這う戦略 | - |
| フォーム記入タイプ | フィールド知識フォーム入力、Web ページ構造分析フォーム入力 |
Web ページがインターネット上に存在する仕組み
インターネットでは、Web ページはその存在の仕方によって分類され、表層ページと深層ページに分けることができます。
- サーフェス ページ: フォームを送信せずに静的リンクを使用してアクセスできる静的ページ。
- ディープ ページ: フォームの背後に隠されており、静的リンクから直接取得することはできず、特定のキーワードを指定した後にのみページを取得できます。
インターネットでは、ディープ ページの数がサーフェイス ページの数よりもはるかに多いことがよくあります。
ディープ Web クローラーのフォーム入力タイプ
ディープ Web クローラーのフォーム入力には 2 つのタイプがあります。
- ドメイン知識に基づいたフォーム入力。簡単に言えば、フォームに入力するためのキーワード ライブラリであり、入力が必要な場合には、意味分析に基づいて対応するキーワード ライブラリが選択されて入力されます。
- Web ページ構造に基づいたフォーム入力。簡単に言えば、この入力方法は一般的に限られた分野の知識がある場合に使用され、Web ページの構造を分析してフォームに自動的に入力します。
検索エンジンのコア
検索エンジンは、Web クローラー テクノロジーに基づいたコア アプリケーションであり、Web クローラーを通じてインターネット上の情報を収集し、インデックスを構築し、ユーザーのクエリに応じて対応する検索結果を返します。
搜索引擎的核心工作流程图
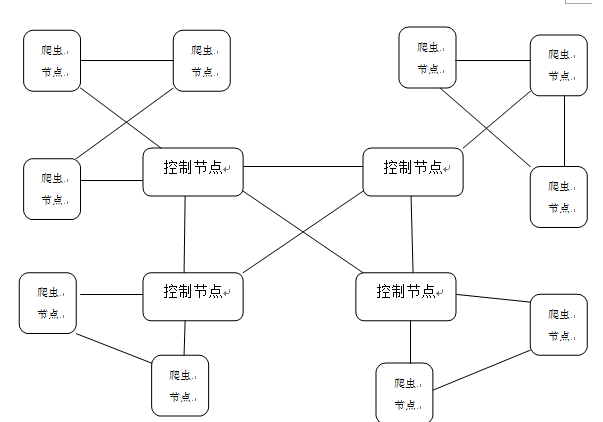
検索エンジンのコア技術とは、インターネット上の情報を取得、加工、提供するための一連の技術を指します。主に次のモジュールが含まれています。
| モジュール | 関数 |
|---|---|
| クローラーモジュール | インターネットからページを取得し、生のデータベースに保存します |
| インデクサ | 元のデータベースのデータにインデックスを付けて、インデックス データベースに保存します。 |
| レトリーバー | ユーザーが入力したキーワードに応じて、索引データベースからデータが取得され、対応する検索処理が行われます。 |
| ユーザーインターフェース | 検索エンジンの入力ボックスにキーワードを入力すると、関連情報が得られます。 |
| ユーザーデータストレージ | ユーザーの IP アドレス、入力したキーワードなどのユーザーの行動を保存するために使用されます。 |
| ログアナライザー | 主に、大量のユーザーデータに応じて元のデータベースやインデックスデータベースを調整したり、ランキング結果を変更したりするその他の操作を担当します。 |
ユーザーの爬虫類に関するあれこれ
ユーザー クローラーは Web クローラーの一種で、主にインターネット上のユーザー データをクロールするために使用されます。これらのデータを分析することで、ユーザーの好みや行動を分析することができ、商品のポジショニングやコンテンツのレコメンデーションに非常に役立ちます。
ユーザー クローラーが取得できる情報とデータの例を次に示します。
| クロールオブジェクト | クロールデータ |
|---|---|
| ほぼ知っている | 登録ユーザーの男女比、地理的分布、従事業種 |
| Qゾーン | ユーザーの発言の時間帯、年齢分布、性別分布など |
ユーザー クローラーを使用する場合は、合法的な使用とユーザーのプライバシーの保護に注意する必要があります。ユーザークローラを利用する場合には、ユーザーのプライバシーを保護し、無用なトラブルを防止するために、関連する法律や倫理を遵守する必要があります。
Webスクレイピングとは
Web クローリングとは、Web クローラー技術を通じて対象の Web サイトから必要なデータをクローリングし、必要なデータのクリーニングと処理を実行することを指します。Web クローリングを使用すると、必要なデータをより効率的に取得できるため、作業効率が向上します。
Web クローリングと Web クローラー
Web クローリングは Web クローリングとよく似ており、Web クローリングはインターネット上の閲覧や情報取得を指しますが、Web クローラーは Web クローリングを実現するための自動プログラムです。したがって、日常生活ではこの 2 つを同義語として使用することもできます。
WebクローラーとWebスクレイピングの違い
| ウェブ クローラー | ウェブスクレイピング | |
|---|---|---|
| 意味 | Webサイトへのアクセスを自動化し、ソフトウェアプログラムを通じてデータを取得する技術 | Web サイトから特定のデータを取得するためのプラクティス |
| 物体 | インターネット全体の(ほぼ)すべての Web ページ | 特定の Web サイトまたはページのデータを抽出する |
| 省略 | 一部のサイトではクロールが制限されています | フェッチする前にフェッチする必要はありません |
| 目的 | コンテンツのインデックス付けと検索 | 新しいデータを分析または生成する |
| キーメソッド | Web ページ上の内部リンクをたどってインターネットをクロールする | 特定の情報を見つける |
WebクローラーとWebスクレイピングの特徴
| ウェブ クローラー | ウェブスクレイピング | |
|---|---|---|
| スピード | データをより速く、より深く取得 | クロールされるデータの量とターゲット サイトによって異なります。 |
| 影響 | サイトの速度に影響を与える可能性があります | Web クローラーのように大規模なサイトにはアクセスしません |
| 应用 | 大多数搜索引擎使用网络爬虫,例如 Google、Bing 等 | 抓取市场数据、业务线索和供应商产品等 |
| 可能限制 | 某些网站采用的程序可能会限制网络爬虫免费获取数据的访问 | 没有特别限制 |
| 数据类型 | 通常用于收集大量数据,例如网站上的文本、图片和链接等 | 只抓取特定数据,例如股票市场数据、业务线索和供应商产品等 |
总之,了解网络爬虫与网页爬取的基本概念、组成、类型、应用以及注意事项等方面,对于进行相关工作的人员来说都是很有必要的。
爬虫是一把双刃剑
爬虫技术是指通过编写程序自动获取互联网上的信息资源的技术。

它能为我们带来很大的便利,提高我们的工作效率和数据获取能力,但同时也给互联网带来了一些负面影响,如隐私泄露、恶意攻击等。
爬虫的优点
- 提高效率:爬虫技术能够自动化获取大量的数据信息,极大地提高了我们的工作效率。
- 方便快捷:使用爬虫可以从海量互联网资源中快速获取有用信息。
- 信息全面:使用爬虫可以获取到平时无法轻易获取到的、隐藏在深层次的信息资源。
- 数据分析:使用爬虫可以获取到数据资源后进行深入分析,从而得出更为准确的结论。
爬虫的缺点
- 网络安全问题:恶意爬虫可能会对网站进行攻击,影响网站的正常运转。
- 隐私泄露:爬虫也可能获取用户的隐私信息,威胁用户的个人安全。
- 无序爬取:一部分爬虫会不考虑目标网站的负荷承受能力,对网站造成过大的负荷压力。
- 法律问题:有些网站可能对被爬取的数据资源拥有知识产权,未经授权的爬取可能会导致侵权问题。
如何使用爬虫技术
为了充分利用爬虫技术的优点,我们应该注意以下几个方面:
- 合法使用:使用爬虫技术要遵循相关法律和规定,不要进行违法、非法活动。
- 尊重 robots.txt 协议:爬虫应遵守网络协议,不要访问被禁止的页面,避免对网站造成冲击。
- 设置合理的访问频率:避免对目标网站造成过大负荷,设置合理的间隔时间和访问频率。
- データ処理の整合性: データの整合性と正確性を確保するために、データの削除や改ざんを避けます。
- データのプライバシーを保護する: ユーザーのプライバシー データなどの機密情報については、セキュリティ保護を十分に行い、ユーザー情報を開示しないでください。
要約する
側面:
- 合法的な使用:クローラーテクノロジーの使用は、関連する法律および規制に従う必要があり、違法または違法な行為に従事してはなりません。
- robots.txt プロトコルを尊重する: クローラーはネットワーク プロトコルを遵守し、禁止されたページにアクセスせず、Web サイトへの影響を避ける必要があります。
- 適切な訪問頻度を設定する: ターゲット Web サイトへの過度の負荷を避けるために、適切な間隔と訪問頻度を設定します。
- データ処理の整合性: データの整合性と正確性を確保するために、データの削除や改ざんを避けます。
- データのプライバシーを保護する: ユーザーのプライバシー データなどの機密情報については、セキュリティ保護を十分に行い、ユーザー情報を開示しないでください。
要約する
つまり、クローラ技術は実用化において非常に幅広い応用の可能性を秘めていますが、同時に一定のリスクや危険性ももたらします。クローラー開発に従事するエンジニアは、常に倫理および社会法規を遵守し、合法的かつ安全かつ責任ある方法でクローラー技術を開発および適用する必要があります。