関数の基本を復習する
C++ 関数を使用するには、次の作業を行う必要があります。
- 関数定義を提供する
- 関数プロトタイプを提供する
- 関数の呼び出し
ライブラリ関数は定義およびコンパイルされた関数であり、標準ライブラリ ヘッダー ファイルを使用してそのプロトタイプを提供できるため、この関数を正しく呼び出すだけで済みます。ただし、独自の関数を作成する場合は、上記の 3 つの側面を自分で処理する必要があります。例えば
#include<iostream>
using namespace std;
void hello(); //函数的声明
int main()
{
cout << "主函数将调用自己编写的hello这个函数:" << endl;
hello(); //函数的调用
cout << "调用自编函数hello结束" << endl;
return 0;
}
//函数的声明
void hello()
{
cout << "我向大家问好!"<<endl;
}
プログラムは行順に実行されます。関数 hello() が実行されると、main() 内のコードは一時停止され、関数 hello() が実行された後、main() 内のコードは引き続き実行されます。
関数を定義する
関数は、値を返さない関数と値を返す関数の 2 つのカテゴリに分類できます。
値を返さない関数は void 関数と呼ばれ、一般的な形式は次のとおりです。
void functionName(parameterList)
{
statement(s)
return;
}このうち、parameterList は関数に渡すパラメータの種類と数を指定します。
値を返す関数は値を生成し、それを呼び出し元の関数に返します。このような関数の戻り値の型は、戻り値の型として宣言されます。一般的な形式は次のとおりです。
typeName functionName(parameterList)
{
statement(s)
return value;
}値を返す関数の場合、呼び出し元の関数に値を返すには return ステートメントを使用する必要があります。戻り値の型は配列にすることはできませんが、他の型 (整数、浮動小数点数、ポインタ、構造体、オブジェクト) にすることができることに注意してください。

関数は return ステートメントの実行後に終了します。関数に複数の return ステートメントが含まれている場合、関数は最初に見つかった return ステートメントを実行した後に終了します。例えば
int bigger(int a,int b)
{
if(a > b)
return a;
else
return b;
}関数プロトタイプと関数呼び出し
以下の例を参照してください
#include<iostream>
using namespace std;
void cheers(int); //prototype, no return value
double cube(double x); //prototype, return a double
int main()
{
cheers(5); //function call
cout << "Give me a number: ";
double side;
cin >> side;
double volume = cube(side); //function call
cout << "A " << side << "-foot cube has a volume of ";
cout << volume << " cubic feet" << endl;
cheers(cube(2));
return 0;
}
void cheers(int n)
{
for (int i = 0; i < n; i++)
{
cout << "Cheers! ";
}
cout << endl;
}
double cube(double x)
{
return x * x * x;
}
1. なぜプロトタイプが必要なのでしょうか?
プロトタイプは、コンパイラに対する関数のインターフェイスを記述します。つまり、関数の戻り値 (存在する場合) の型とパラメータの型と数をコンパイラに伝えます。
関数プロトタイプは次のステートメントにどのような影響を与えますか?
double volume = cube(side);上記のステートメントの場合、関数プロトタイプは、cube() に double パラメーターがあることをコンパイラーに伝えます。プログラムがそのようなパラメーターを提供しない場合、プロトタイプはコンパイラーがそのようなエラーをキャッチできるようにします。次に、cube() 関数が計算を完了した後、戻り値を指定された位置に置き、関数を呼び出します (ここではは main() 関数です) 戻り値は、この指定された場所からフェッチされます。プロトタイプでは cube() の戻り値の型が double であると記述されているため、コンパイラーは取得するバイト数とその解釈方法を認識します。この情報がないと、コンパイラは推測することしかできませんが、コンパイラは推測しません。
2. プロトタイプの構文
関数のプロトタイプはステートメントであるため、セミコロンで終わる必要があります。これを行う最も簡単な方法は、関数定義内の関数ヘッダーをコピーし、セミコロンを追加することです。(関数プロトタイプには変数名は必要なく、型のリストだけが必要です。次の両方が正しいです)
void hell(int);
void hell(int x);3. プロトタイプの機能
プロトタイプでは次のことが保証されます。
- コンパイラは関数の戻り値を正しく処理します。
- コンパイラは、正しい数の引数が使用されているかどうかをチェックします。
- コンパイラは、使用されているパラメータの型が正しいかどうかをチェックし、そうでない場合は、その機能の範囲内で正しい型に変換します。
関数パラメータと値渡し
C++ では通常、パラメーターを値で渡します。これは、数値パラメーターを関数に渡し、関数がそれを新しい変数に割り当てることを意味します。
渡された値を受け取るために使用される変数は仮パラメータと呼ばれ、関数に渡される値は実パラメータと呼ばれます。

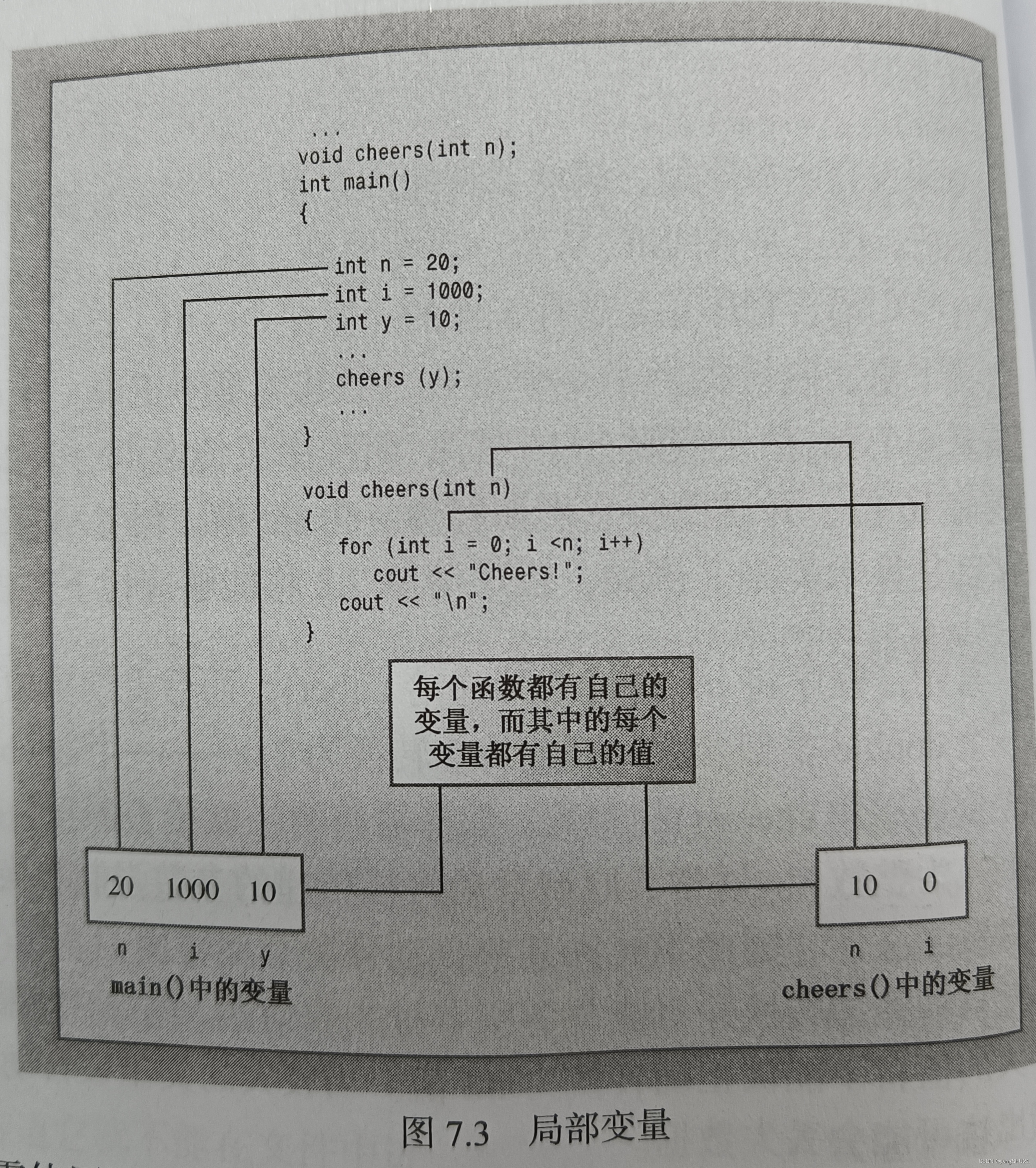
関数内で宣言された変数 (パラメーターを含む) は、その関数に対してプライベートです。関数が呼び出されると、コンピュータはこれらの変数にメモリを割り当て、関数が終了すると、コンピュータはこれらの変数によって使用されていたメモリを解放します。このような変数はローカル変数と呼ばれます。
main() で x という名前の変数を宣言し、別の関数で x という名前の変数を宣言すると、それらはまったく異なる 2 つの無関係な変数になります。
複数のパラメータ
関数には複数のパラメータを含めることができます。関数を呼び出すときにパラメータをカンマで区切るだけです。
n_chars('R',50);上記の関数呼び出しは、2 つの引数を関数 n_chars() に渡します。
同様に、関数を定義するときは、関数ヘッダーでパラメータ宣言のカンマ区切りリストを使用します。
void n_chars(char c,int n) //two arguments関数ヘッダーは、関数 n_chars() が char パラメーターと int パラメーターを受け入れ、各パラメーターの型を個別に指定する必要があり、通常の変数のように宣言を組み合わせることができないことを示しています。
関数と配列
関数は複雑な型 (配列、構造体など) を扱うための鍵です。配列と関数を組み合わせる方法を学びましょう
ここで、配列内のすべての要素の合計を計算したいと仮定すると、for ループを使用して 1 つずつトラバースして追加できるため、すべての数値をそれに応じて変更する必要があります。ここでは、毎回新しいループを作成することなく、さまざまな配列に対する変更をできるだけ少なくするための統合インターフェイスを作成します。
#include<iostream>
using namespace std;
const int ArSize = 8;
int sum_arr(int arr[], int n);
int main()
{
int cookies[ArSize] = { 1,2,4,8,16,32,64,128 };
int sum = sum_arr(cookies, ArSize);
cout << "Total cookies: " << sum << endl;
return 0;
}
int sum_arr(int arr[], int n)
{
int total = 0;
for (int i = 0; i < n; i++)
{
total = total + arr[i];
}
return total;
}
関数ヘッダーを見てみましょう
int sum_arr(int arr[], int n)角括弧は arr が配列であることを示し、空の角括弧は任意の長さの配列を関数に渡すことができることを示します。しかし、これは当てはまりません。arr は実際には配列ではなく、ポインタです。(関数の残りの部分を記述するときは、arr を配列として考えることができます)
関数がポインタを使用して配列を処理する方法
前述したように、C++ は配列名をその最初の要素のアドレスとして解釈します。
cookies == &cookies[0]配列宣言では、配列名を使用して格納場所をマークします。配列名に sizeof を使用すると、配列全体の長さ (バイト単位) が取得されます。アドレス演算子 & が配列名に使用されると、次のアドレスが返されます。配列全体
関数呼び出しでは次のようになります。
int sum = sum_arr(cookies, ArSize);このうち、cookie は配列の名前であり、C++ の規則によれば、cookie はその最初の要素のアドレスであるため、関数はそのアドレスを渡します。配列の要素の型は int であるため、Cookie の型は int ポインター、つまり int* である必要があります。これは、正しい関数ヘッダーが次のようになるべきであることを示唆しています。
int sum_arr(int *arr,int n)これは、関数ヘッダー int *arr と int arr[] の両方が正しいことを証明します。C++ では、関数ヘッダーまたは関数プロトタイプで使用される場合に限り、両方とも同じ意味を持ち、両方とも arr が int ポインターであることを意味します。他のコンテキストでは、int * arr と int arr[ ] は異なる意味を持ちます。
上記のプログラムでは、配列の内容を関数に渡すのではなく、配列の位置(アドレス)、要素の種類(type)、要素の数(変数n)を関数に渡していることがわかります。この情報を使用すると、関数は元の配列を使用できるようになります。
通常の変数を渡す場合、関数は変数のコピーを使用しますが、配列を渡す場合、関数は元の配列を使用します。
配列アドレスを引数として受け取ると、配列全体をコピーするのに必要な時間とメモリが節約されます。
ポインタと定数
const キーワードは、2 つの異なる方法でポインターとともに使用できます。
1 つ目の方法は、ポインターが定数オブジェクトを指すようにすることで、ポインターが指す値を変更するために使用されるのを防ぎます。
int age = 39;
const int* pt = &age;このステートメントでは、pt が const int (39) を指しているため、pt を使用してこの値を変更することはできません。
*pt += 1; //INVALID
cin >> *pt; //INVALIDpt の宣言は、それが指す値が実際に定数であることを意味するのではなく、値が pt に対して定数であることを意味するだけです。(たとえば、pt は age を指しますが、age は const ではありません。age 変数を使用して age の値を直接変更できますが、pt ポインターを使用して変更することはできません。)
*pt = 20; //INVALID
age = 20;ここでは、さらに 2 つのケースがあることに注意してください。以前は、常に通常の変数のアドレスを通常のポインタに割り当てていましたが、ここでは通常の変数のアドレスを const へのポインタに割り当てます (したがって、さらに 2 つのケースがあります: const変数のアドレスをconst へのポインタに代入する場合、const 変数のアドレスを通常のポインタに代入します。実際には、最初のものだけが実行可能で、2 番目は実行可能ではありません)
const float g_earth = 9.8;
const float *pe = &g_earth; //VALIDこの場合、g_earth を使用して値 9.8 を変更することも、ポインタ pe を使用して値を変更することもできません。
可能な限り const を使用してください
ポインター パラメーターを定数データへのポインターとして宣言する理由は 2 つあります。
1) これにより、データの意図しない変更によるプログラミング エラーが回避されます。
2) const を使用して、関数が const 引数と非 const 引数を処理できるようにします。それ以外の場合、関数は非 const パラメータのみを受け入れることができます。
2 番目の方法は、ポインター自体を定数として宣言することです。これにより、ポインターが指すものを変更することができなくなります。
int sloth = 3;
int *const finger = &sloth;この宣言構造により、finger は、sloth のみを指すことができますが、finger を使用して、sloth の値を変更できるようになります。
再帰
C++ 関数には興味深い機能があります。関数は自分自身を呼び出すことができます (C 言語とは異なり、C++ では main() が自分自身を呼び出すことはできません)。この機能は再帰と呼ばれます。
再帰関数がそれ自体を呼び出すと、呼び出された関数も自分自身を呼び出すことになり、コード内に呼び出しのチェーンを終了させるものが存在しない限り、無限ループが継続します。通常のアプローチは、次の再帰関数のように、if ステートメント内に再帰呼び出しを配置することです。
void recurs(argumentlist)
{
statements1
if(test)
recurs(arguments2)
statements2
}