目次
この記事へのリンク: https://blog.csdn.net/weixin_47058355/article/details/130400400?spm=1001.2014.3001.5501
序文
特徴構築が十分な幅を獲得した後、これらの特徴がスクリーニングされます。
特徴の選択には 2 つの主な機能があります。
特徴の数を減らす、次元を減らす、モデルの一般化能力を強化する、および過学習を減らすです。
特徴と特徴値の間の理解を強化します。一般に、機能は次の 2 つの考慮事項から選択されます。
特徴が発散するかどうか: たとえば、特徴が発散しない場合、分散は 0 に近くなります。つまり、サンプルは基本的にこの特徴に差がなく、この特徴はサンプルを区別するのには役に立ちません。
特徴量とターゲット間の相関関係: これは比較的明らかであり、ターゲットとの相関性が高い特徴量を優先的に選択する必要があります。
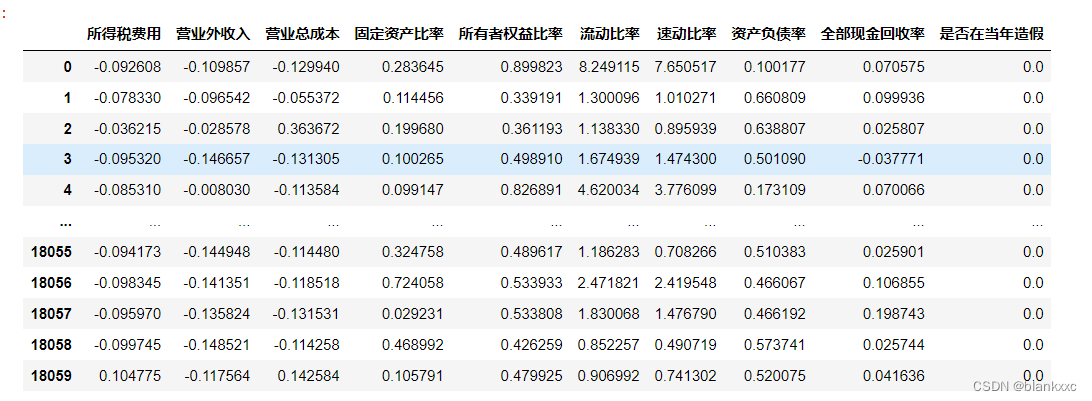
データ表示:
1.ろ過方法
私の理解では、フィルタリングの方法は、統計的手法によってデータを判断して処理することです。
1.1 分散ベース
分散を利用してデータが発散しているかどうかを判断し、最終的には発散結果に応じてデータを削除するかどうかを判断します
# 对方差的大小排序
data.std().sort_values() # select_data是final_data去掉了独热的那些特征
#去掉变化小的特征 比如一个特征如果全是1或者0 那么这数据是没有意义的

ソートされたデータに応じて、結果が0のデータを選択して削除、または一定の閾値未満の列を削除して特徴選択を行います。
1.2 相関係数
相関係数は、2 つの変数間の線形関係の近さを測定するために使用される統計です。その値の範囲は -1 ~ 1 で、1 は完全な正の相関を示し、-1 は完全な負の相関を示し、0 は線形関係がないことを示します。記号 r は通常、相関係数を表すために使用されます。
一般的に使用されるのはピアソン係数とスピアマン係数です
import matplotlib.pyplot as plt
corr = data.corr('pearson') # .corr('spearman')
#corr得到特征与特征之间的相关性 然后corr['target']就是目标特征与所有特征之间的相关性
#利用corr方法得出特征的pearson或spearman系数值
plt.rcParams['font.family']=['Microsoft YaHei']
plt.figure(figsize=(5,5)) #将结果画图表示
corr['是否在当年造假'].sort_values(ascending=False)[1:].plot(kind='bar')#一般是使用标签作为相关性计算的列
plt.tight_layout()
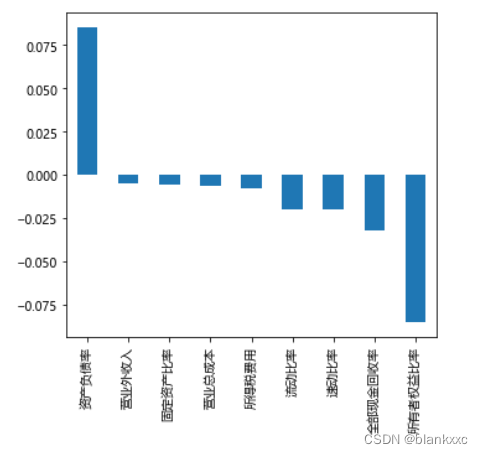
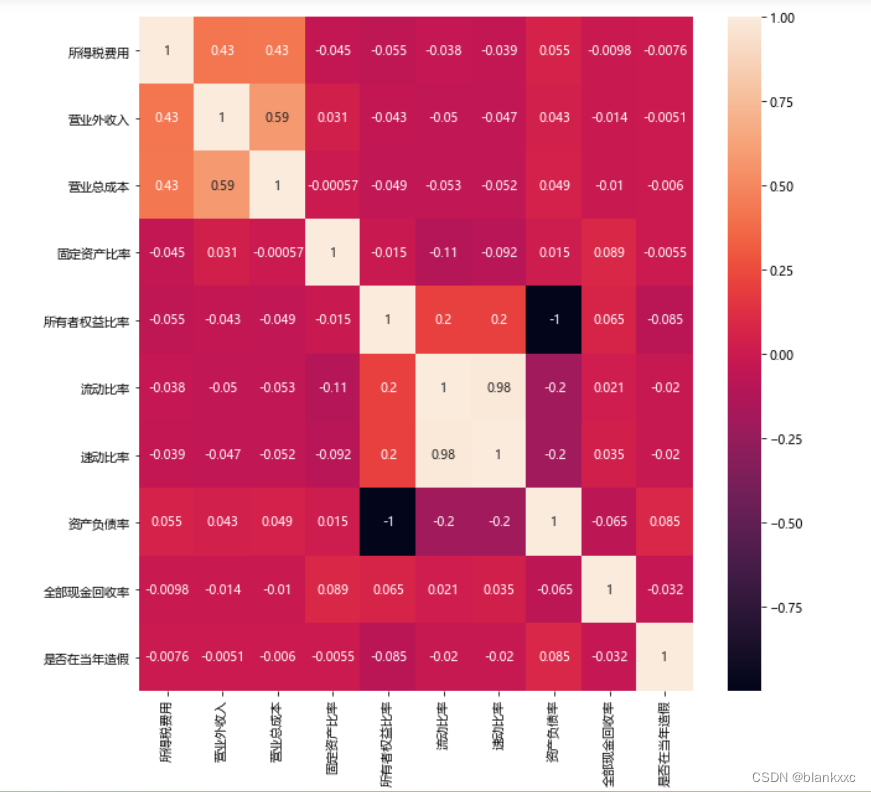
またはヒートマップで視覚化する
import seaborn as sns
# 用热力图看一下互相之间的关系
f, ax = plt.subplots(figsize=(10, 10))#设置大小
sns.heatmap(corr, annot=True)# annot表示是否在方块上出现数字
一般的に使用される相関係数の概要は次のとおりです
。統計学でよく使用される相関係数は次のとおりです。ピアソン相関係数: 2 つの連続変数間の線形関係を測定するために使用される最も一般的に使用される相関係数です。通常、データがほぼ正規分布している場合、これが最良の選択です。
スピアマン
相関係数: 2 つの変数間の単調な関係を測定するために使用されるノンパラメトリックな方法であり、変数が線形である必要はありません。これは、生データをランク (順序) データに変換し、
ランク データ間のピアソン相関係数を計算することによって計算されます。Kendall 相関係数: 2 つの変数間の単調な関係を測定するためのノンパラメトリックな方法でもあり、場合によっては
Spearman 相関係数よりも適用可能です。これは、2 つの変数間のランク協調性の対数を計算することによって計算されます。チェビシェフ相関係数: 2 つの変数間の距離または差を測定するために使用され、2 つの変数間の最大差の絶対値です。
イータ相関係数: 2 つのカテゴリ変数間の関係を測定するために使用され、ピアソンの相関係数の変形として見ることができます。
相互情報量: 特に多変量関係とノイズ干渉が存在する場合に、2 つの変数間の非線形関係を測定するために使用されます。
実際のアプリケーションでは、特定のデータタイプや研究目的に応じて、異なる相関係数を計算用に選択できます。
相関係数が異なれば計算方法や適用シーンも異なりますが、それぞれの違いと利点は次のとおりです。
ピアソン: 相関係数: 2 つの連続変数間の線形関係を測定するために使用されます。単純な計算、便利な解釈、強力な比較可能性という利点がありますが、欠点は外れ値に敏感であり、非線形関係に鈍感であることです。
スピアマン: 相関係数: 2 つの変数間の単調な関係を測定するために使用されます。外れ値の影響を受けず、データが正規分布する必要がないという利点があり、非線形の単調関係に適していますが、データ間の差異情報が無視される可能性があります。Kendall 相関係数: 2 つの変数間の単調な関係を測定するためにも使用されます。スピアマン
相関係数と比較すると、より堅牢で小さなサンプルの問題に効果的に対処できますが、計算の複雑さは高くなります。チェビシェフ相関: 2 つの変数間の距離または差を測定するために使用されます。データの分散やスケーリングに依存しないという利点がありますが、極端な外れ値に対して堅牢ではない可能性があります。
イータ相関係数: 2 つのカテゴリ変数間の関係を測定するために使用されます。カイ二乗検定の効果量に基づいているため、有意水準の情報は得られますが、扱うことができるのは 2 つの変数間の関係のみです。
相互情報量: 2 つの変数間の非線形関係を測定するために使用されます。ピアソン
相関係数よりも柔軟で、多変量関係やノイズ干渉を処理できますが、計算の複雑さが高く、大量のサンプル データのサポートが必要です。要約すると、データの種類や研究目的によって適した相関係数は異なり、適切な方法を選択することでより正確な結果を得ることができます。
2つ、包まれた状態
ラップされたメソッドは、最適なサブセットが選択されるまで、初期特徴セットから特徴サブセットを継続的に選択し、学習者をトレーニングし、学習者のパフォーマンスに応じてサブセットを評価します。ラップされた特徴選択により、特定の学習者に合わせて直接最適化されます。
(簡単に言うと、特徴量を一つずつ分解して学習し、モデルスコアによって特徴量の関連性を判断することです)
2.1 ランダムフォレスト
ランダム フォレストをモデルとして使用してデータをフィルタリングする
#正常的处理 将单个特征挨个进行评分
from sklearn.model_selection import cross_val_score, ShuffleSplit
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import KFold
import numpy as np
X = data.iloc[:,:-1]
Y = data['是否在当年造假']
names = X.columns
rf = RandomForestRegressor(n_estimators=20, max_depth=4)
kfold = KFold(n_splits=5, shuffle=True, random_state=7)
scores = []
for column in X.columns:
print(column)
tempx = X[column].values.reshape(-1, 1)
score = cross_val_score(rf, tempx, Y, scoring="r2",error_score='raise',
cv=kfold)
scores.append((round(np.mean(score), 3), column))
print(sorted(scores, reverse=True))

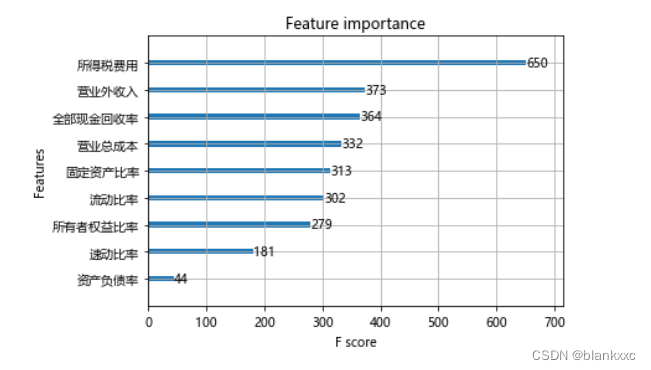
2.2 XGBoostの重要性分析
XGBoost の勾配ブースティング ツリーを使用して、各決定木の重要な手順の後に、一定の重みに従って判定特徴が追加されます。
# 下面再用xgboost跑一下 xgboost有专门的一个特征评测体系
from xgboost import XGBRegressor
from xgboost import plot_importance
xgb = XGBRegressor()
xgb.fit(X, Y)
plt.figure(figsize=(20, 10))
plot_importance(xgb)
plt.show()
2.3 SFS シーケンス前方選択アルゴリズム (Sequential Forward Selection)
ランダム フォレスト リグレッサー (RandomForestRegressor) に基づく逐次前方選択アルゴリズム (逐次前方選択)
#利用SFS进行特征的排序
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
# sfs = SFS(LinearRegression(), k_features=20, forward=True, floating=False, scoring='r2', cv=0)
sfs = SFS(RandomForestRegressor(n_estimators=10, max_depth=4), k_features=5, forward=True, floating=False, scoring='r2', cv=0)
# RandomForestRegressor(n_estimators=10, max_depth=4):使用10个决策树,每棵决策树最大深度为4的随机森林回归器。
# k_features=5:最终选择出来的特征数量。
# forward=True:使用序列前向选择算法进行特征选择。
# floating=False:不使用悬浮搜索算法。
# scoring='r2':评估指标为R方(coefficient of determination)。
# cv=0:交叉验证的折数。由于该参数值为0,因此没有使用交叉验证,而是直接使用默认的训练集和测试集进行模型训练和评估。
X = data.iloc[:,:-1]
Y = data['是否在当年造假']
sfs.fit(X, Y)
sfs.k_feature_names_

#画出sfs的特征的前几项的边际效应
from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs
fig1 = plot_sfs(sfs.get_metric_dict(), kind='std_dev')
plt.grid()
plt.show()
3. 埋め込み型
埋め込み特徴スクリーニングは、機械学習で一般的に使用される特徴選択手法であり、モデルのトレーニング中に特徴の重要性を直接考慮し、モデルのトレーニングに特徴の重みを埋め込むことで特徴の選択を実行します。
具体的には、埋め込み特徴スクリーニングでは、アルゴリズムはターゲット変数に最も関連する特徴を自動的に選択すると同時に、モデルへの寄与が少ない特徴にペナルティを与えます。これにより、過剰適合の問題を効果的に防止し、モデルの解釈能力をある程度向上させることができます。
実際のアプリケーションでは、埋め込み特徴スクリーニングは、線形回帰、ロジスティック回帰、サポート ベクター マシンなどのさまざまな機械学習アルゴリズムと併用されることがよくあります。
3.1 SVC
SVC の例は次のとおりです。
from sklearn.svm import LinearSVC
from sklearn.feature_selection import SelectFromModel
X = data.iloc[:,:-1]
Y = data['是否在当年造假']
# 注意:dual 设置为 False,否则会报错
model_lsvc = LinearSVC(penalty='l1', C=0.2, dual=False)#设置模型
model_lsvc.fit(X,Y)
#penalty:惩罚项,指定正则化策略。'l1'表示使用L1正则化,'l2'表示使用L2正则化。
#C:正则化系数,控制模型的复杂度和拟合程度,值越小表示正则化强度越高,模型越简单。
#dual:对偶或原始问题的求解方法,当样本数量大于特征数量时,通常dual=False可以更快地求解。
#下面是将特征筛选的结果用特征名表示
df_0=pd.DataFrame(X.columns)
df=pd.DataFrame(list(model_lsvc.coef_))
df2 = pd.DataFrame(df.values.T, index=df.columns, columns=df.index)#转置
df3=pd.concat([df_0,df2],axis=1)
df3.columns=['特征','权重']
list(df3[df3['权重']!=0]['特征'])

要約する
特徴の選択とは、元のデータから最も代表的で重要な特徴を選択し、これらの特徴を保持し、無駄な特徴や冗長な特徴を削除することを指します。その主な目的は次のとおりです。
モデルの精度と精度の向上: 最も重要な特徴をフィルタリングして保持することで、ノイズや無関係な特徴の干渉を排除し、モデルの予測精度と精度を向上させることができます。
過学習のリスクを軽減する: 特徴の数が多い場合、モデルは過学習の問題を引き起こす傾向があります。つまり、トレーニング セットでは良好なパフォーマンスが得られますが、テスト セットではパフォーマンスが低下します。特徴を選択すると、特徴の数が減り、モデルの複雑さが軽減されるため、過剰適合のリスクが軽減されます。
トレーニング時間を短縮し、コンピューティング リソースを節約する: 特徴を選択すると、処理する必要があるデータの量が削減されるため、トレーニング時間が短縮され、コンピューティング リソースが節約されます。
解釈性と視覚化の向上: 特徴を選択すると、モデルの特徴がより直観的で解釈しやすくなり、その後の視覚的な分析と解釈が容易になります。
要約すると、高品質で効率的で解釈可能な機械学習モデルを構築するには、特徴の選択が非常に重要です。
特徴選択に加えて、特徴スクリーニングには次元削減という別の方法があります。これについては、別のブログで説明します。
このブログがお役に立ちましたら、いいね、コレクション、コメントをお願いします!