「自動運転ハート」公開アカウントに注目するには下のカードをクリックしてください
ADAS ジャンボ乾物、手に入れられます
今日は、Heart of Autopilot が歩行者の軌跡予測における最新の進歩を共有します - 自動運転の安全性について考えます。共有したい関連作業がある場合は、記事の最後にご連絡ください。
>>クリックして入ってください→オートパイロットの核心【軌道予測】技術交流グループ

車両と人間の相互作用が複雑な都市環境で安全な自動運転を確保するには、自動運転車両が歩行者の短期的かつ即時の行動をリアルタイムで予測する機能を備えていることが重要です。近年、自動運転シナリオにおける歩行者の行動の推定を研究するためにさまざまな方法が開発されていますが、歩行者の行動には明確な定義がありません。この研究では、文献のギャップが調査され、歩行者の行動特性の分類が提案されています。さらに、自車両カメラ観測のみを入力として使用して、歩行者の行動と軌道予測のために、新しいマルチタスクのシーケンス間トランスフォーマエンコーダデコーダ(TF-ed)アーキテクチャが提案されています。提案された方法は、アクションおよび軌道予測に関して既存の LSTM エンコーダ/デコーダ (LSTM 版) アーキテクチャと比較されます。2 つのモデルのパフォーマンスは、公開されている Joint Attendance Autonomous Driving (JAAD) データセット、CARLA シミュレーション データ、および大学キャンパスで収集されたリアルタイムの自動運転接続データに基づいて評価されます。評価結果によると、JAAD テスト データでは、行動予測タスクにおけるこの方法の精度は 81% に達し、LSTM アルゴリズムの精度より 7.4% 高く、軌跡予測タスクでは LSTM アルゴリズムの方が優れたパフォーマンスを示しました。予測シーケンスの長さは 25 フレームです。
序章
他の道路利用者との安全なやり取りは、完全自律型インテリジェント車両の開発と実装における重要な課題です。都市部の運転環境では歩行者事故が発生しやすいため、路上での歩行者の行動の予測と推定、およびタイムリーな操縦決定は、都市部の運転シナリオや大学キャンパスなどの混合交通環境で自動運転車を導入するための重要な要件の 1 つです。都市や町などの構造化されていない運転環境でのラストマイル接続用の小型自動運転シャトル。
膨大な文献では、純粋に視覚ベースの歩行者検出と追跡または軌道予測による歩行者モデリングに焦点を当てています。これらの方法は有望な結果を示していますが、歩行者を意識した自動運転には十分ではありません。なぜなら、歩行者の行動パターンは非常に動的(動作計画や向きの突然の変化)であり、影響が小さくても環境の変化に敏感だからです。
より高いレベルの動作モデリングとして、最も重要で頻繁に研究される問題の 1 つは、横断歩行者/非横断車両/道路の動作を予測することです。これは、文献では歩行者の意図と呼ばれることがよくあります。いくつかの研究では、視覚データ、歩行者の動作、人間の姿勢と時空間的手がかり、姿勢データからの軌跡など、測定可能または観察可能なエンティティを使用して意図の予測を調査しています。将来のシーンの予測に基づくアクションの分類と、マルコフ特性を使用した予測された意図 (隠れた状態が歩行者の意図である場合) も調査されます。機械学習手法は、出力が横断する/横断しないという二項分類問題として意図をモデル化するためにも使用されており、これらの手法は最先端の歩行者行動データセットで検証されています。
この研究で著者らは、歩行者の行動の定義に関する文献のギャップについて簡単に議論し、自動運転シナリオに関連するさまざまな行動レベルを説明するための分類法を提案しています。著者らは、歩行者の軌跡と行動予測のためのマルチタスクのシーケンス対シーケンスの Transformer エンコーダ/デコーダ アーキテクチャを提案し、同じ入力とタスクを使用して提案された最先端の PV-LSTM モデルと比較します。シミュレートされた (CARLA)、JAAD、データセットに対する手法の有効性は、グラウンド トゥルース情報を使用して評価されます。最後に、著者らは大学キャンパス内の自動運転シャトルのカメラ データを収集し、視覚ベースの歩行者追跡情報を入力として使用して 2 つのモデルをエンドツーエンドで評価しました。YOLOv5 検出器と DeepSORT はそれぞれ歩行者の検出と追跡に使用されます。
分類
文献には数多くの研究があるにもかかわらず、歩行者の行動には一貫した定義や分類がありません。さらに、既存の研究では、実際の歩行者の意図の代用として、行動認識、軌道推定、ポーズベースの動作予測が使用されています。この目的を達成するために、著者らはこの研究で歩行者の行動特性の分類法を提案し、議論します。以下の図 1 は、この分類法の概要フローチャートを示しています。
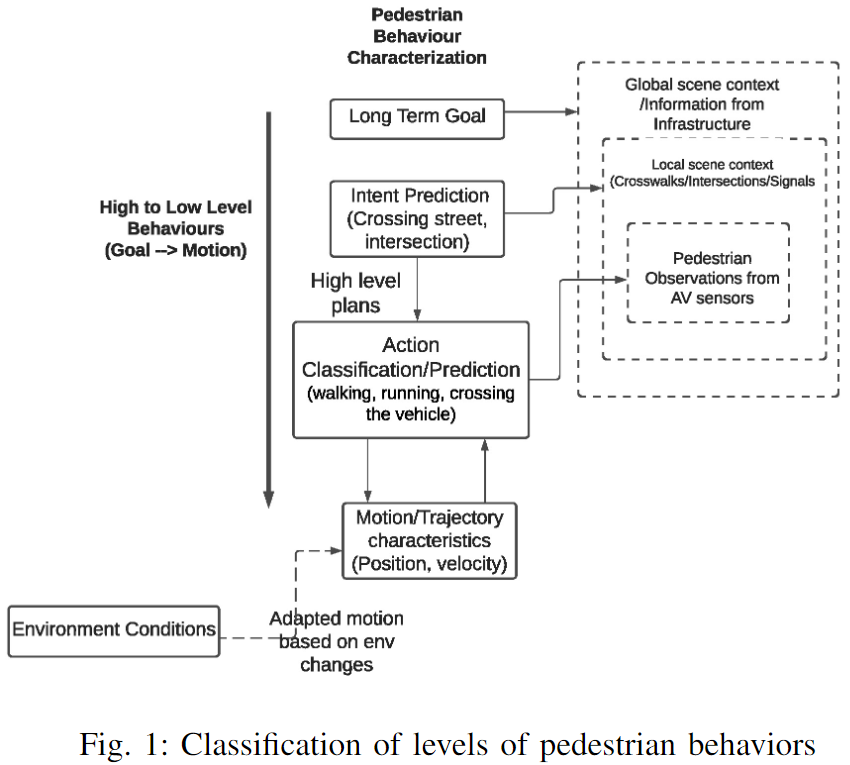
交通シナリオでは、歩行者は長期的な目標や目的地、短期的な目標や行動 (交差点や道路を横断するなど)、即時的な行動 (路上の車両の近くを横断するなど) を持つことができます。通常、行動の特徴には、歩行者が何をしようとしているか、その目標は何か (意図)、歩行者が何をしようとしているか (行動)、および歩行者がどのような軌道をたどるのか (動作) に関する質問への回答が含まれます。これらの間には階層的な因果関係があり、歩行者は上位の計画や意図に従って行動をとり、これらの行動の運動特性は交通/道路状況の変化に応じて変化する可能性があります。環境/交通シーン情報の必要性は、行動推定の必要レベルに比例して増加します。著者の分類によれば、本当の意図の予測(道路を横断する/横断しない)には、ローカルシーンのコンテキストが必要です。この情報がなければ、歩行者の横断意図と車両の前を横断する歩行者の行動を区別することが不明確になります。歩行者の行動は交通、環境、個々の歩行者の特性などの多くの要因に依存するため、著者らは、行動の推定値には、これらの推定値が適用される範囲を明確に記載する必要があると提案しています。たとえば、バス停で待っている歩行者を考えてみます。歩行者がバスを確認するために道路に出た場合、これは、軌道ベースのアプローチに従って接近する自車の横断行動として解釈される可能性がありますが、これは反映されていません。歩行者の全体的な目標または意図。したがって、著者らは、運動特性を持つ行動を自車両に関連する低レベルの行動として定義し、その特徴は歩行者によってのみ観察される範囲で決定でき、安全な経路計画と自動運転車両のナビゲーションにとって重要です。意図は高レベルの行動表現であり、直接観察することはできず、単純に歩行者の軌跡を使用して推定することもできませんが、過去の行動、過去の行動、文脈上のシーン情報などからより深い推論が必要です。この論文では、文脈上のシーン情報や過去の行動からの推論が事前に知られておらず、推定されていないため、著者らは歩行者(横断する/横断しない)と自転車の低レベルの行動表現に焦点を当てています。
方法
問題の定式化
著者らは、歩行者の行動と軌道予測を多目的学習問題として定式化します。時刻 t における歩行者の位置と速度をそれぞれ pt と st とする。時刻 t における歩行者の行動を次のように表すとします。
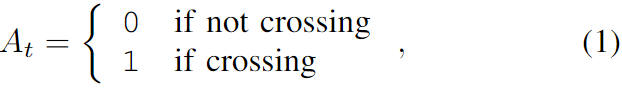
時間 t で、長さ m+1 の履歴位置と速度軌道が与えられると、次のように表されます。
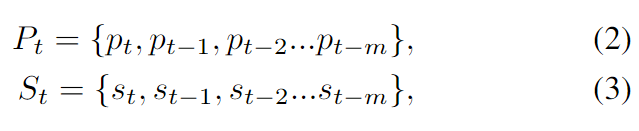
学習された確率分布は次のとおりです。
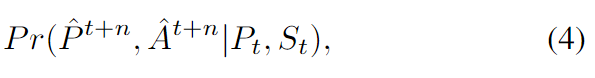
$\hat P^{t+n},\hatA^{t+n}P_t, S_t は、次の n 個の位置とアクションを予測します。
次に著者らは、モデルの入力と出力を含む、提案された TF-ed モデルと PV-LSTM モデルの高レベルのアーキテクチャの詳細について説明し、その後 2 つのアーキテクチャを個別に説明します。
建築
この研究では、著者らはマルチタスクの Transformer エンコーダ/デコーダ (TF 版) アーキテクチャを提案し、そのパフォーマンスを PV-LSTM モデルの LSTM エンコーダ/デコーダ アーキテクチャ (LSTM 版) と比較します。TF 化されたフレームワーク全体の概要図を以下の図 2a に示します。
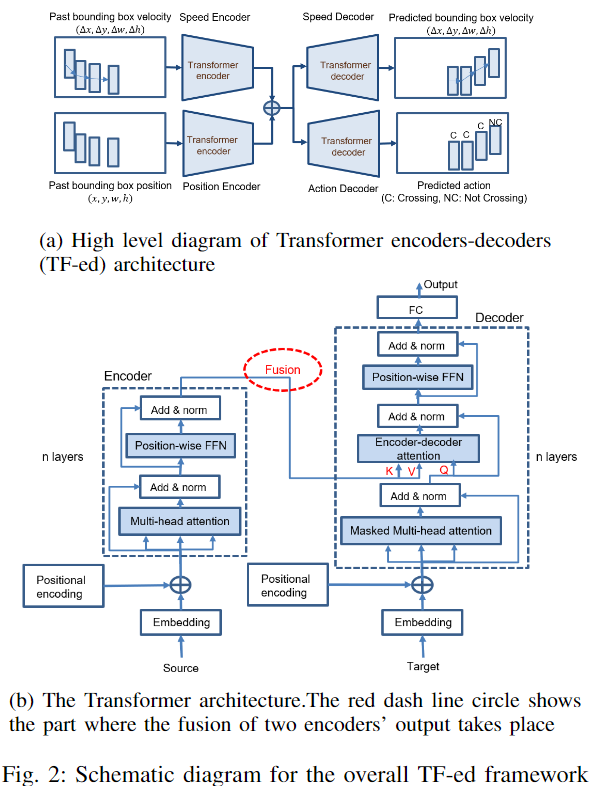
LSTM と TF の場合、観察された歩行者の速度と位置のシーケンスは、対応するエンコーダーによってエンコードされます。高次元の隠れた特徴は 2 つのエンコーダーの出力で連結され、速度デコーダーとモーション デコーダーに渡されます。最後に、デコーダの出力は、それぞれ 4 次元と 2 次元の予測速度とアクションのシーケンスに逆投影されます。
1) モデルの入力と出力:
歩行者の周囲の空間境界ボックス座標は、歩行者の位置をエンコードするために使用されます。bbox 座標は通常、最先端の軌道データセットからのグラウンドトゥルース形式で、またはリアルタイムのマルチオブジェクト追跡アルゴリズムの出力として利用できます。さらに、歩行者の速度ももう 1 つの特徴入力であり、同じ歩行者の 2 つの連続したフレームの bbox 座標を減算することによって取得されます。形式的には、歩行者 i について、一連の履歴位置および速度観測 (式 (2) および (3)) が与えられます。ここで、 は bbox の中心座標 (x、y、幅、高さ)、 は対応する速度です。
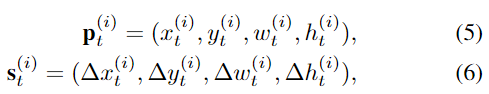
時間インスタンス t+1 から t+n について、著者は歩行者の速度と将来の一連の行動を予測し、予測された速度に基づいて将来の位置を計算できます。
2) トランスフォーマーエンコーダーデコーダー (TF-ed):
TF ネットワークは、自然言語処理のために [23] で最初に提案されました。入力シーケンスを段階的に処理する LSTM とは異なり、TF は埋め込みシーケンス全体を一度に処理するため、並列トレーニングが可能になります (上記の図 2b を参照)。TF はエンコーダとデコーダで構成されます。ソースおよびターゲット シーケンスの埋め込みは、セルフ アテンション スタッキング モジュール ベースのエンコーダおよびデコーダに供給される前に、位置的にエンコードされます。
a) 入力の埋め込み: 速度と位置のソースとターゲットの入力は、最初に完全に接続された層を介して高次の D 次元空間に埋め込まれます。
b) 位置エンコーディング: 位置エンコーディング マスク PE を同時に追加することで、各入力エンベディングにタイムスタンプが付けられ、PE は次のように計算されます。
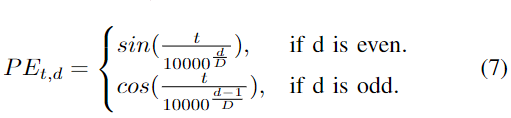
ここで、 d は、d 次元の埋め込み全体の次元を表します。
c) マルチヘッド自己注意: 逐次非線形性を捕捉するネットワークの能力は主に注意モデルにあります。入力はクエリ (Q)、キー (K)、および値 (V) ベクトルに埋め込まれます。Q と K は、スケーリングされたドット積層とソフトマックス層を介して入力シーケンス間の相関を反映するアテンション行列を計算するために使用されます。次に、次のように、出力の各部分がシーケンスの他の部分からの時間情報とマージされるように、アテンション マトリックスを使用して V に重み付けが行われます。
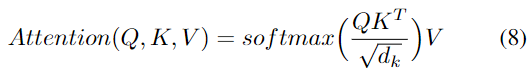
具体的には、エンコーダ/デコーダ アテンション層では、Q は前のデコーダ層の出力から取得され、K と V はエンコーダ出力から取得されます。デコーダ セルフ アテンションでは、Q、K、V はすべて前のデコーダ層の出力から得られます。ただし、デコーダ内の各位置は、その位置までのデコーダ内のすべての位置にのみ焦点を当てることができ、予測がすでに生成された出力予測にのみ依存することが保証されます。評価中は、グラウンド トゥルース データを使用したトレーニングとは異なり、グラウンド トゥルース ターゲットが存在しないため、デコーダーの以前の予測出力が新しいターゲット入力として繰り返し使用されます。
著者が提案した TF-ed の全体的なアーキテクチャを上の図 2a に示します。2 つの TF エンコーダは速度と位置の入力を並行して処理し、2 つのエンコーダの K 出力と V 出力はカスケードによって融合され、速度予測と動作予測のために別のデコーダに渡されます。予測速度出力は、歩行者の将来の軌跡を計算するための出力シーケンスとして拡張されます。
3) LSTM エンコーダ/デコーダ (LSTM 版):
LSTM は、時系列データから長期的な相関関係を学習できます。LSTM にはリカレント ニューラル ネットワークの特性に加えて、入力ゲート、忘却ゲート、出力ゲートで構成される専用のメモリ ユニットも含まれています (以下の図 3 を参照)。
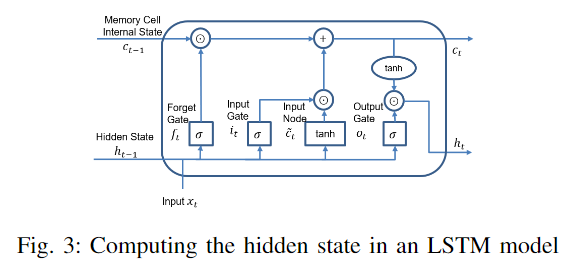
これらのゲートは、各メモリ セル内の情報の流れを制御し、保護します。入力ベクトルが与えられる。
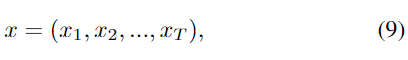
各 LSTM メモリ セルの隠れ層出力 ht は、次の方程式に従って、t = 1 から t = t までの各タイム ステップ t で計算および更新されます。
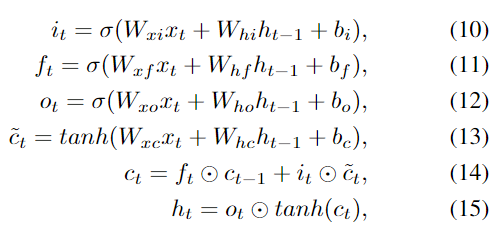
ここで、Wと bは 3 つのゲートとメモリ セルの重み行列とバイアス、σ(x) はシグモイド関数、
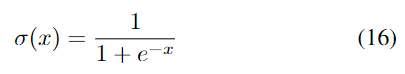
比較に使用される全体的な LSTM アーキテクチャは論文 [12] から引用されています。観測された速度と位置の入力シーケンスが与えられると、速度エンコーダーと位置エンコーダーは、タイム ステップ t で対応する速度とポーズの隠れ状態を生成します。これらは、すべての特徴を含む単一の隠れ状態に連結され、個別に渡されます。デコーダーは軌道に使用されます。および行動予測タスク。
実験による評価
著者らは、セクション III の LSTM 化および TF 化されたアーキテクチャで説明されている方法を評価します。これには、アクションと軌道予測の 3 つのシナリオが含まれます: (1) CARLA シミュレーターでシミュレートされたシナリオ (2) 最先端のシナリオJAAD データセット (3) 大学キャンパスの運転シナリオでシャトル バス上で収集されたデータ。著者らは、CARLA および JAAD データセットを使用して、アクションと軌道予測のパフォーマンスを独立して評価することを目的としており、それによってグラウンド トゥルース (GT) データを両方のモデルへの入力として使用します。
次に著者らは、自動運転シャトルで収集されたデータの評価を実行しました。この場合、視覚ベースの追跡アルゴリズムを通じて取得された歩行者のデータがモデルへの入力として使用されました。エンドツーエンドの評価 (動作および軌道予測への画像入力) は、騒音条件や潜在的な追跡エラー/障害が存在する場合の自動運転車の実世界ナビゲーション ソリューションの方法の有効性を検証するために重要です。
評価設定
a) CARLA : CARLA は自動運転研究用のオープンソース シミュレータです。著者らの作業では、CARLA の都市走行環境 (Town10HD) がシミュレーション環境として使用されます。以下の図 4b は、そのような環境の鳥瞰図を示しています。

解像度 1920x1080、視野 90° の自車両の車載カメラは横断歩道の近くに伸びており (図 4a に示すカメラの視野)、歩行者とそのコントローラーが一緒に右側の歩道に伸びています。歩行者は歩道に沿って走行し、横断歩道の近くでしばらく停止し、道路の反対側に到達するまで横断し始めます。シミュレーション中に、GT ボックスと対応するアクション ラベル (交差する/交差しないなど) が自動的に生成されるようにプログラムされました。シーケンス全体には、GT ボックスと歩行者のアクションで注釈が付けられた 145 フレームが含まれています。
b) 自動運転のための共同注意 (JAAD) データセット: 都市部の運転環境における自動運転の文脈における共同注意に焦点を当てています。このデータセットは、歩行者が横断するとき/横断しないときなど、歩行者とドライバーの行動を研究することを目的としています。JAAD には、さまざまな自然のシーンや照明条件で、フロント カメラによって 30 FPS、解像度 1920x1080 ピクセルでキャプチャされたビデオが含まれています。82032 フレームのビデオが合計 346 個あり、ビデオの長さの範囲は 60 フレームから 930 フレームです。2,793 人の歩行者に bbox として注釈が付けられ、そのうち 686 人には、歩く、立つ、道路を渡る、見る (交通) などの行動を含む行動ラベルが付いています。データセットの歩行行動のアノテーションには、「追い越ししながら歩く」または「歩きながら歩かない」というサブ行動が含まれています。この評価では、著者らは、比較性別の一貫性を保つために [12] と同じデータ処理を維持するために、行動予測に使用される歩行のサブセットである横断行動に関連するラベルのみを使用します。
c) リアルタイム データ: リアルタイム データ収集に使用される車両は、Autonomous Stuff から購入した Polaris GEM e6 です (以下の図 5a を参照)。車両にはGPS、ライダー、ルーフ前部中央にカメラが搭載されています。すべての制御およびセンシング ソフトウェアはロボット オペレーティング システム (ROS) を使用して統合され、データはテキサス A&M 大学のキャンパスで 15 FPS のフレーム レートで収集されました。シャトルは平均時速 16 マイルで手動で運転されます。データは解像度 1296x728 ピクセルの 298 フレームで構成されており、キャンパス内の典型的な横断歩道/横断シーンをカバーしています。データは、現実的なテストのために、理想的とは言えない照明条件の下で夜間に意図的に収集されました。

実装の詳細
1) データ前処理: 行動予測のためのモデル入力は歩行者の bbox ピクセル座標 (x, y, w, h) の形で存在します。JAAD および CARLA の評価では、bbox 座標のグランド トゥルースが使用されます。さらに、歩行者 ID と行動ラベルがデータ アノテーションから抽出されます。すべてのフレーム内の各歩行者に対応する bbox 座標のシーケンス全体と対応するアクション クラスが取得されると、シーケンスはさらにサブシーケンスに分割され、各サブシーケンスには長さ O の観測シーケンスと、長さ T の対応するグラウンド トゥルース データ シーケンスが含まれます。
自動運転シャトルのデータ評価では、以下の図 6 に示すように、ビジョンベースの検出/追跡アルゴリズムがパイプラインに統合され、追跡出力が行動予測モデルの入力として使用されます。
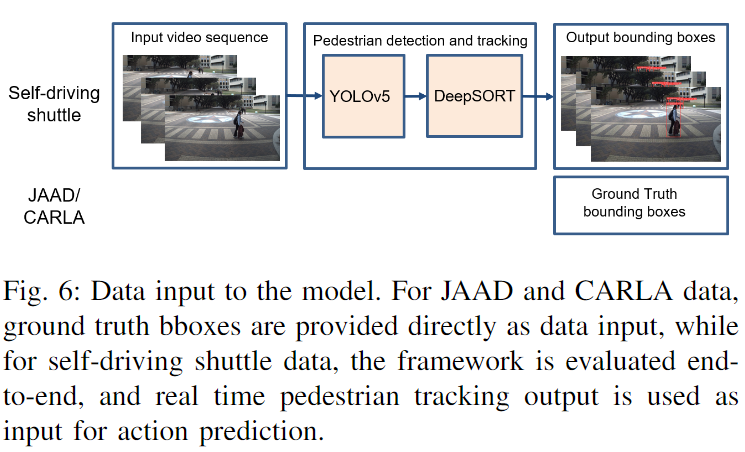
YOLOv5 および DeepSORT アルゴリズムは、ビデオ シーケンス内の複数の歩行者を検出および追跡するために使用されます。この研究では歩行者のメールボックス情報のみが必要であるため、YOLOv5 の MS COCO データセットと DeepSORT の osnet x1 0 で事前トレーニングされた重みクラウドヒューマン yolov5m に基づいて推論を実行する際、検出されるオブジェクト カテゴリは 0 (人間) に設定されます。
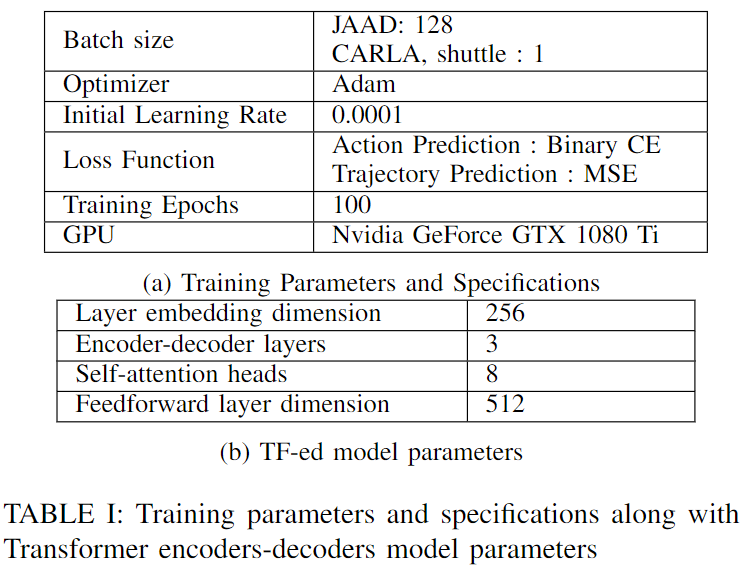
2) トレーニングとテスト: LSTM モデルと TF モデルは両方とも JAAD トレーニング セットと検証セットでトレーニングされ、それぞれ CARLA シミュレーション、JAAD テスト セット、自律シャトル データで評価されます。ただし、自律シャトル データの評価では、グラウンド トゥルースの注釈が欠如しているため、定性的な結果しか得られません。JAAD データセットは、0.7:0.1:0.2 の比率でトレーニング、検証、テストに分割されています。LSTM トレーニングの場合、著者らは [12] のパラメーターを採用し、隠れ状態次元 256 とエンコーダー/デコーダー層 1 を採用しました。TF 化アーキテクチャの追加パラメーターとすべてのデータセットのトレーニング仕様を以下の表 I にまとめます。実装にはPytorchライブラリを使用します。
評価指標
bbox 中心座標の平均変位誤差 (ADE) と最終変位誤差 (FDE) は、軌道予測のバッチを評価するためのモデル パラメーター メトリックとして使用されます (式 (17)、(18))。 (19) )) は行動予測の指標として使用されます。ADE は、各タイム ステップ間の差を平均して、予測のグラウンド トゥルースに対する全体的な適合度を測定します。
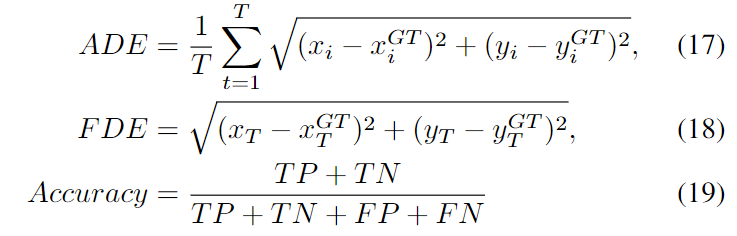
ADE はすべての予測と予測期間中の真の値の平均二乗誤差 (RMSE) であり、FDE は最終予測と予測シーケンスの終了時の対応する真の値の間の RMSE です。この記事の例では、ADE と FDE はどちらもピクセル単位です。
結果と考察
検出と追跡
自動運転給電データの歩行者検出および追跡サンプル出力フレームを上の図 5 に示します。図 5b に示すように、画像フレーム内のすべての歩行者が正常に検出および追跡されています。図 5c は、道路の中央にいる歩行者が検出されない障害シナリオを示しています (挿入図は歩行者の拡大図を示しています)。上記の断続的な検出エラーは、特に両側が木で覆われた道路で特に観察され、すでに最適とは言えない夜間の照明条件にさらに影響を与えました。
行動と軌道の予測
JAAD および CARLA テスト セットでのアクション予測精度の結果と、軌道予測の ADE および FDE の結果を以下の表 II にまとめます。ADE と FDE はバッチ方式で計算されます。
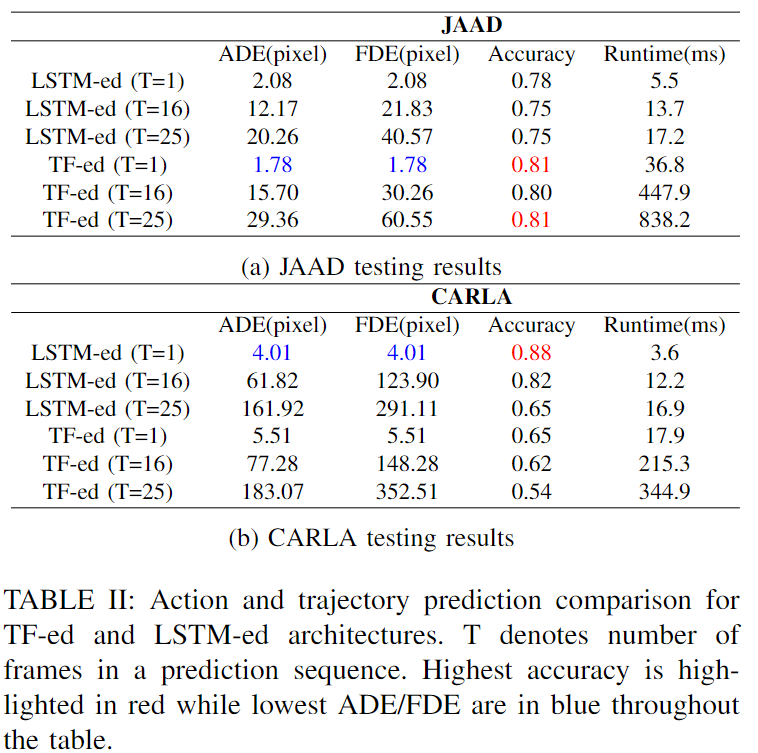
また、アクション定義、使用されるデータ、パイプラインなどが異なるため、他のモデルを直接比較できないため、推論ランタイムには LSTM 化および TF 化のみが評価に含まれると報告されています。長さ O の観測を考慮して、著者らは次の T フレームのアクションと軌跡を予測し、これを長さ T の予測シーケンスと呼びます。O=16、T=1、O=T=16、および O=T=25 の結果が報告されます。特に、TF 化 (T=1) モデルは 1 つのヘッドを持つ 1 つのレイヤーでトレーニングされますが、他のモデルは 8 つのヘッドを持つ 3 つのレイヤーを使用します。JAAD テスト セットの場合、予測が 1 つだけ行われた場合、TF 化モデルは両方のタスクで LSTM 化モデルよりも優れており、ADE と FDE が 14.4% 削減され、精度が 4% 近く向上しました。予測シーケンス長が 16 および 25 に増加するにつれて、LSTM ed の ADE および FDE は低くなりますが、アクション予測では TF ed ほど正確ではありません。特に TF-ed では、T = 25 の場合に行動予測精度が 7.4% 向上しました。CARLA データ評価では、LSTM-ed の方がすべてのケースで優れたパフォーマンスを示します。一般に、LSTM 版の実行時間は TF 版よりもはるかに短くなります。以下の図 8 は、TF 化モデルの 3 つの評価シナリオにおけるアクションと軌跡の予測の 5 つの例を、左から右の時間ステップで示しています。

図 8a では、歩行者が最初に数秒間道路脇で待機し、2 番目のフレームで横断を開始し、同時に車両が接近しています。図 8b は、より離れた横断歩道をシミュレートしていますが、自車両はある程度離れた横断歩道の後ろに駐車しています。この結果から、アクションの予測は正しいものの、ADE と FDE は予測シーケンスのタイム ステップに比例して徐々に増加することがわかります。これは、図8eに示す自動ドライブスプライシングデータの結果でも観察されます。これは、以下の図 7 に示す傾向によって説明できます。この傾向は、予測時間ステップが増加するにつれて累積誤差が増加することを示しています。

言い換えれば、各予測シーケンスの最初と最後の予測フレームは、それぞれ最も低い ADE/FDE と最も高い ADE/FDE を持ちます。誤差シフトは、図8aおよび8dと比較して図8eで最も顕著であることに留意されたい。これは、図8eのみが同じ予測シーケンスからサンプリングされたフレームを含んでおり、徐々に増加する誤差のより顕著な影響を反映しているためであり、他の例の画像フレームは、より長い軌跡を含む4つの異なる予測シーケンスからの最初の予測サンプルであるためです。歩行者の割合が多いため、誤差が徐々に増加することはありません。さらに、著者らは、図 8e では、動きの最初の数秒間は歩行者が検出されず、しっかりと追跡されていないことを観察しています。これが、行動予測の遅れを説明しています。
要約すると、入力として bboxes 座標のみを使用すると、予測シーケンス長が増加すると、LSTM ed モデルは歩行者軌跡予測のタスクでより良いパフォーマンスを発揮するのに対し、TF ed モデルは歩行動作予測のタスクでより良いパフォーマンスを発揮します。さらに、著者らは、安全な自動運転のための歩行者行動予測手法の有効性と限界を調査するために、議論に値するいくつかの興味深いシナリオを観察しました。たとえば、以下の図 9a では、車両の進路ではなく、自車両の右側を横断する 2 人の歩行者がいます。交差点で右折する車両ではよくあることです。図 9b では、車両が近づいているときに歩行者が斜めに渡っています (横断歩道はありません)。どちらの場合も、アルゴリズムは正しいアクションを予測できませんでした。さらに、追跡 ID の切り替えはリアルタイムのエンドツーエンド評価における大きな課題であり、下流の歩行者の行動や軌道予測タスクに悪影響を及ぼします。カメラの視野が限られていると、観察の蓄積に時間がかかるため、歩行者がフレームに入って横断し始める前に車両がタイムリーに反応するためのバッファー時間が限られます。

これらの課題とシナリオは、特に信号交差点の有無にかかわらず大学のキャンパスや住宅地などのエリアで、車両と人間の相互作用についてより徹底的なテストとデータ収集の必要性を強調しています。安全な自動運転のためには、自動シャトルや車両が短期的な行動を確実に予測できるように、歩行者の行動予測方法(例:障害の追跡や行動予測精度への精度の影響など)をエンドツーエンドでリアルタイムに評価することが重要です。歩行者が車両の真正面にいない可能性がある重要な状況であっても、横断歩道で通常観察される軌道プロファイルとはわずかに異なる軌道プロファイルを持つ可能性があります。
結論は
著者らは、安全な自動運転のための都市部の運転シナリオにおける歩行者の軌跡行動予測のための、Transformer エンコーダ/デコーダ マルチタスク モデルを提案しています。このメソッドは LSTM エンコーダ/デコーダ モデルと比較され、グラウンド トゥルース データを使用して、シミュレートされた公開されている JAAD データセットで評価されます。これは、フレームワークがビジョンベースの歩行者検出および追跡アルゴリズムと統合されている、自動運転用のフィーダー データに対するエンドツーエンドのパイプライン評価によって補完されます。歩行者の行動特性の分類も提供され、異なる行動レベル間の階層的因果関係が議論されます。著者らは実験結果を通じて、ラストマイルのコネクテッド走行シナリオを接続する自動運転に関しては、純粋に自車両の観察に依存する短期行動予測手法には限界があると結論付けている。追跡 ID の切り替えは、複数の歩行者の行動を追跡および予測する場合にも課題となり、車両が安全性を判断する時間がほとんどなくなります。この目的を達成するために、将来の研究の興味深い方向性は、集団行動と個々の歩行者の行動を調査し、集団行動の予測と主要な歩行者のみの行動の特定と予測のトレードオフを研究することです。
参考
[1].安全な自動運転を実現するための歩行者行動の学習
(1)動画講座はこちら!
自動運転の心臓部は、ミリ波レーダービジョンフュージョン、高精度地図、BEV知覚、センサーキャリブレーション、センサー展開、自動運転協調知覚、セマンティックセグメンテーション、自動運転シミュレーション、L4知覚、意思決定計画、軌道予測などを統合します。 . 方向学習ビデオ、ご自身で受講してください (コードをスキャンして学習を入力してください)

(コードをスキャンして最新のビデオをご覧ください)
動画公式サイト:www.zdjszx.com
(2) 中国初の自動運転学習コミュニティ
1,000 人近くのコミュニケーション コミュニティと 20 以上の自動運転技術スタックの学習ルートが、自動運転の認識 (分類、検出、セグメンテーション、キー ポイント、車線境界線、3D 物体検出、占有、マルチセンサー フュージョン、物体追跡、オプティカル フロー推定、軌道予測)、自動運転位置決めとマッピング(SLAM、高精度マップ)、自動運転計画と制御、フィールド技術ソリューション、AI モデル展開の実装、業界トレンド、求人リリース、スキャンへようこそ以下の QR コード、自動運転の中心となるナレッジ プラネットに参加してください。ここは本物の乾物がある場所です。この分野の大手の人々と、仕事の開始、勉強、仕事、転職に関するさまざまな問題を交換し、論文 + コードを共有します。毎日+ビデオ、交換を楽しみにしています!

(3) 【自動運転の心臓部】フルスタック技術交流会
The Heart of Autonomous Driving は、物体検出、セマンティック セグメンテーション、パノラマ セグメンテーション、インスタンス セグメンテーション、キー ポイント検出、車線境界線、物体追跡、3D 物体検出、BEV 認識、マルチセンサー フュージョン、 SLAM、光流推定、深さ推定、軌道予測、高精度地図、NeRF、計画制御、モデル展開、自動運転シミュレーションテスト、プロダクトマネージャー、ハードウェア構成、AI求人検索とコミュニケーションなど。

Autobot Assistant Wechat への招待を追加してグループに参加します
備考:学校/会社+方向+ニックネーム