[AI Combat] スクラッチから構築された、オープンソースで商用利用可能な中国語と英語の大規模言語モデル baichuan-7B

baichuan-7B の紹介
baichuan-7B は、Baichuan Intelligence によって開発されたオープンソースで商用利用可能な大規模な事前トレーニング済み言語モデルです。Transformer 構造に基づいて、約 1 兆 2000 億のトークンでトレーニングされた 70 億のパラメーター モデルは中国語と英語の両方をサポートし、コンテキスト ウィンドウの長さは 4096 です。標準的な中国語と英語の権威あるベンチマーク (C-EVAL/MMLU) では、同じサイズで最高の結果が得られます。
baichuan-7B 中国語の評価
-
C-評価
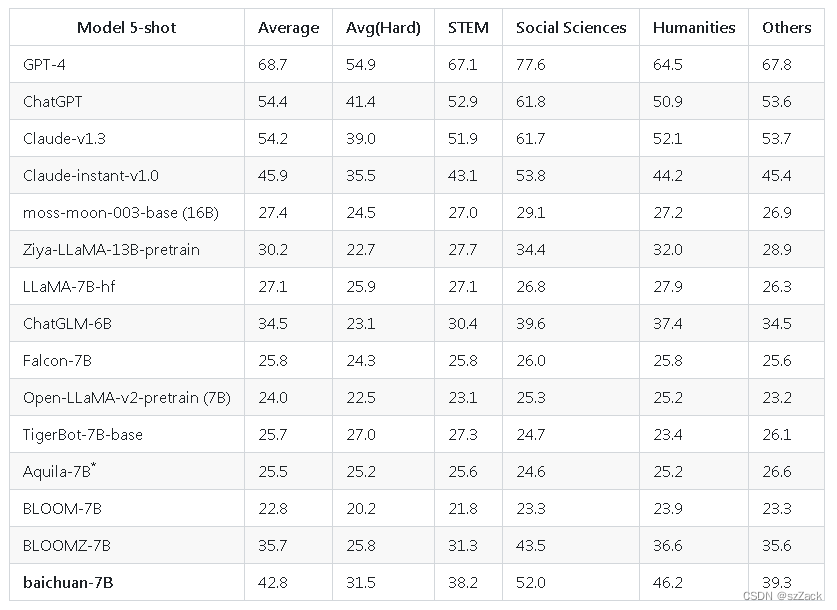
-
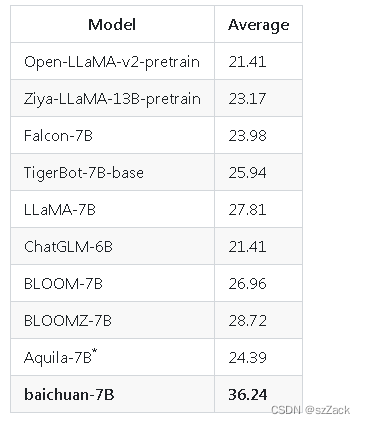
ガオカオ
baichuan-7B ビルド
-
1. Docker イメージをプルします
docker pull nvcr.io/nvidia/pytorch:21.08-py3【】cuda 11.1以降が必要です
-
2.ドッカーを作成する
nvidia-docker run -it -d \ --name baichuan_llm \ -v /llm:/notebooks \ -e TZ='Asia/Shanghai' \ --shm-size 16G \ nvcr.io/nvidia/pytorch:21.08-py3コンテナに:
docker exec -it baichuan_llm env LANG=C.UTF-8 /bin/bash -
3. コードをダウンロードする
cd /notebooks/ git clone https://github.com/baichuan-inc/baichuan-7B.git -
4. モデル重量ファイルをダウンロードする
cd baichuan-7B/ git clone https://huggingface.co/baichuan-inc/baichuan-7B -
5. 依存ライブラリによる
pip install -r requirements.txt -
6. 推論
from transformers import AutoModelForCausalLM, AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("baichuan-7B", trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained("baichuan-7B", device_map="auto", trust_remote_code=True) inputs = tokenizer('登鹳雀楼->王之涣\n夜雨寄北->', return_tensors='pt') inputs = inputs.to('cuda:0') pred = model.generate(**inputs, max_new_tokens=64,repetition_penalty=1.1) print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))-
出力

-
-
7. トレーニング
-
データの準備
ユーザは、学習コーパスを総ランク数の倍数に応じて複数のUTF-8テキストファイルに均等に分割し、コーパスディレクトリ(デフォルトではdata_dir)に配置します。各ランク プロセスは、コーパス ディレクトリ内の異なるファイルを読み取り、それらをすべてメモリにロードし、後続のトレーニング プロセスを開始します。上記は簡略化されたデモンストレーション プロセスであり、ユーザーは正式なトレーニング タスク中にニーズに応じてデータ生成ロジックを調整することをお勧めします。 -
DeepSpeed を構成し
、config/hostfile を変更します。複数のマシンと複数のカードがある場合は、ssh で各ノードの IP 構成を変更する必要があります。 -
訓練
sh scripts/train.sh
-
参考
https://huggingface.co/baichuan-inc/baichuan-7B/tree/main
https://github.com/baichuan-inc/baichuan-7B