Modèle pré-formé BERT et classification de texte
introduire
Si vous prêtez attention au développement de la technologie de traitement du langage naturel, vous devez avoir entendu parler de BERT, dont la naissance est une étape importante dans le domaine du traitement du langage naturel. Cette expérience présentera la structure du modèle de BERT et l'appliquera à la pratique de la classification de texte.
points de connaissance
- Modèles de langage et vecteurs de mots
- Structure détaillée du BERT
- Classification de texte BERT
Le nom complet de BERT est Représentations d'encodeurs bidirectionnels de Transformer, qui est un modèle de représentation de langage publié par Google en octobre 2018. BERT a été pré-formé à travers un énorme corpus composé de Wikipédia et de corpus de livres. Lors de son utilisation, il n'a besoin que de modifier la couche de sortie et de modéliser la formation de réglage fin en fonction des tâches en aval, et il peut obtenir de bons résultats. Au début de la sortie de BERT, il a obtenu des résultats qui ont dépassé les meilleurs résultats de l'époque sur les critères d'évaluation et les ensembles de données tels que GLUE, MultiNLI et SQuAD. Mais avant de se plonger dans la structure de BERT, il est nécessaire de comprendre ce qu'est un modèle de langage et comment les gens vectorisent le texte avant la naissance de BERT.
Modèles de langage et vecteurs de mots
Un modèle de langage est un modèle utilisé pour calculer la probabilité d'une séquence de texte. Dans le développement du traitement du langage naturel, il existe deux modèles de langage largement utilisés : le modèle de langage statistique et le modèle de langage de réseau neuronal. Ensuite, nous les présenterons respectivement.
modèle de langage statistique
Modèle de langage statistique (modèle de langage statistique) est un modèle qui calcule la probabilité d'une chaîne de caractères composée de mots selon la distribution de probabilité, c'est-à-dire la formule (1)(1) : P(ω1,⋯,ωm)(1 )(1) P(ω1,⋯,ωm)
Pour faire simple, le modèle statistique du langage consiste à calculer une phrase non conforme aux règles du langage. Par exemple, l'utilisation d'un modèle de langage pour calculer la probabilité de "j'ai mangé une pomme aujourd'hui" doit être supérieure à la probabilité de "j'ai mangé une pomme aujourd'hui", donc la première est plus probable que la seconde.
Lors de la construction d'un modèle de langage statistique, il est nécessaire d'utiliser des méthodes statistiques pour calculer la formule (1)(1).Pour faciliter le calcul, la formule (1)(1) peut être transformée en formule (2) : P(ω1,ω2 ,…, ωm)=P(ω1)P(ω2|ω1)P(ω3|ω1,ω2)…P(ωi|ω1,ω2,…,ωi−1)…P(ωm|ω1,ω2,…, ωm−1 )
Mais en pratique, la longueur du texte est généralement longue, donc l'estimation de la formule (2)(2) sera très difficile.Par conséquent, les chercheurs ont proposé le modèle N-gramme (N-Gram Model) selon la chaîne de Markov règle . Obtenir alors la formule (3) : P(ωi|ω1,ω2,...,ωi−1)≈P(ωi|ωi−n+1,...,ωi−1)
Dans le modèle N-gramme, la fréquence d'occurrence des mots est généralement utilisée pour estimer la probabilité conditionnelle N-gramme. On peut imaginer que lorsque la valeur de N est très grande, il y aura un problème de données rares lors du calcul de la fréquence, donc la valeur de N est généralement 3. Les modèles de langage statistique peuvent être utilisés dans de nombreuses applications de traitement du langage naturel, telles que la reconnaissance vocale, la traduction automatique, le marquage des parties du discours, l'analyse syntaxique et la recherche d'informations. Cependant, le modèle de langage statistique a également ses limites. IBM a déjà effectué une évaluation de la récupération d'informations et a constaté que le modèle de langage binaire nécessite des centaines de millions de mots pour atteindre des performances optimales, tandis que le modèle de langage trigramme nécessite des milliards de mots. .
Modèle de langage de réseau neuronal
Ces dernières années, avec le développement de l'apprentissage en profondeur, les chercheurs ont conçu un modèle de langage basé sur un réseau de neurones.La structure du modèle de langage de réseau de neurones (Nerual Network Language Model) est illustrée dans la figure ci-dessous :
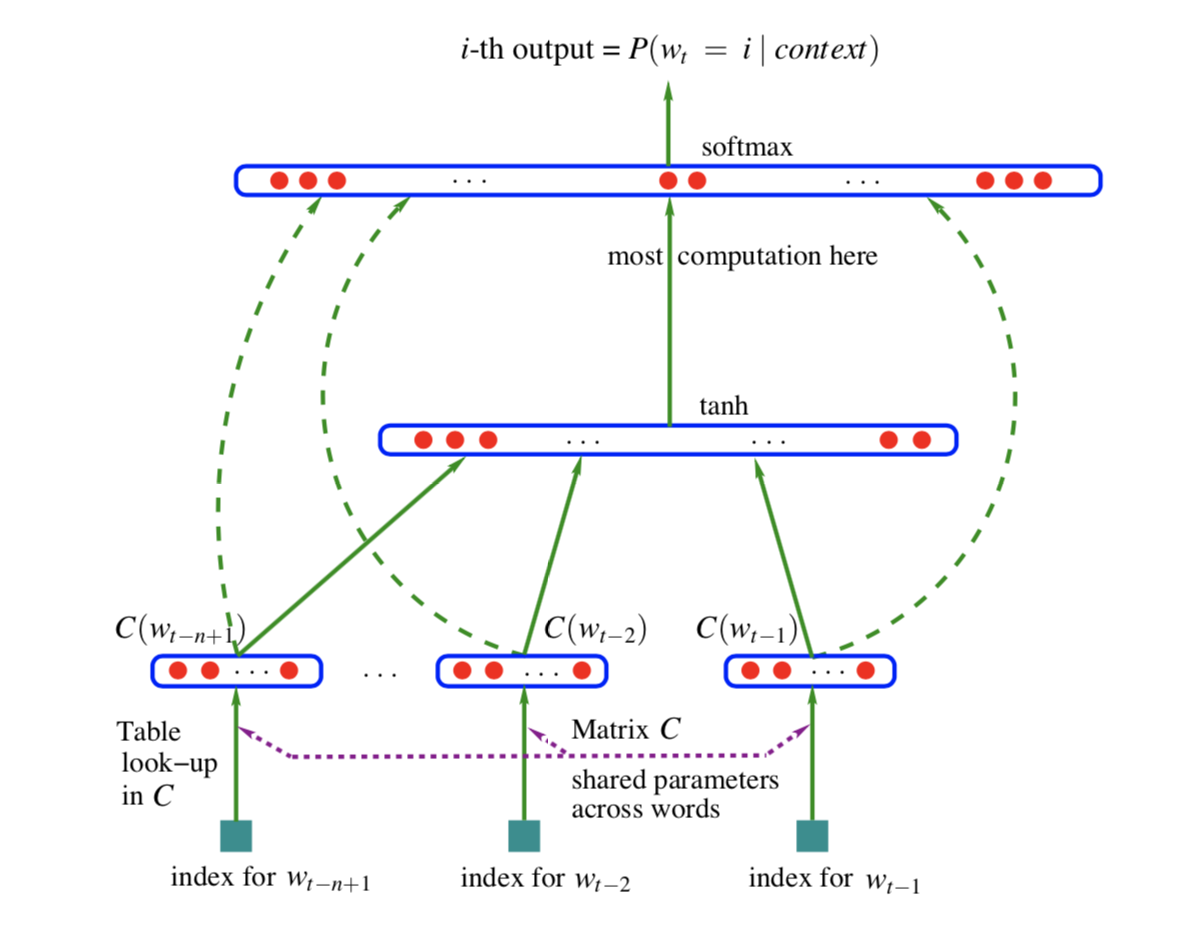
Analysons maintenant la structure du modèle selon la figure ci-dessus. Tout d'abord, la couche inférieure est le nombre dans le vocabulaire correspondant à la phrase entrée dans le modèle, puis le vecteur de mot correspondant est trouvé dans la table de consultation via le nombre. Ensuite, entrez dans la couche entièrement connectée, la fonction d'activation est tanh, et combinez la sortie de cette couche avec le vecteur de mot d'origine et entrez-la dans la couche finale entièrement connectée. Enfin, Softmax est utilisé pour calculer le résultat de la prédiction du mot suivant dans le contexte précédent.
On peut voir que le modèle de langage de réseau neuronal utilise principalement la couche entièrement connectée et la fonction d'activation pour remplacer le calcul de probabilité du modèle de langage statistique. Il existe un sous-produit dans le réseau de neurones : le deuxième paramètre de couche entièrement connecté, qui est le vecteur de mots dont nous parlerons ensuite.
vecteur de mot
Inspirés par le modèle de langage des réseaux de neurones, les chercheurs ont découvert une méthode de représentation distribuée des vecteurs de mots, c'est-à-dire de représenter le sens d'un mot à travers son contexte. De plus, par rapport à la méthode statistique de génération de vecteurs de mots basée sur une représentation clairsemée (Sparse Representation), comme le modèle de sac de mots, le vecteur de mots de représentation distribuée (Distributed Representation) généré par le réseau de neurones a obtenu de meilleurs résultats.
Cependant, cette méthode présente également des inconvénients, c'est-à-dire que les mots polysémiques ne peuvent pas être représentés, et la signification de ce mot polysémique sera affectée par le corpus d'apprentissage. Par exemple, le mot « pomme » a une signification différente dans « J'aime les pommes » que dans « J'aime la pomme ». Cependant, si dans le corpus d'entraînement, une grande quantité de corpus représente la sémantique des pommes, alors la "pomme" dans le vecteur de mots entraîné contiendra la sémantique des fruits, ce qui conduira à comprendre les déviations du modèle.
Afin de résoudre ce problème, un modèle de langage qui génère des vecteurs de mots basés sur une représentation contextualisée (Contextualized Representation) a vu le jour.Lors de l'encodage d'une phrase, ce type de modèle va combiner le contexte de chaque mot de la phrase.Ce mot basé sur le contexte Le vecteur résout avec succès le problème de la distinction des mots polysémiques. BERT est un tel modèle de langage qui génère des vecteurs de mots basés sur le contexte. Examinons la structure spécifique de BERT.
Structure détaillée du BERT
La structure globale de BERT est illustrée dans la figure ci-dessous. Il est construit sur la base de Transformer, utilise la méthode WordPiece pour le prétraitement des données et exécute enfin des modèles de représentation linguistique pré-formés via des tâches MLM et des tâches de prédiction de la phrase suivante. Commençons par la structure de BERT : Transformer, et analysons BERT en détail étape par étape.
Transformateur
Présentez d'abord la base de la structure du modèle BERT: Transformer . Transformer est un module entièrement basé sur le mécanisme d'attention (mécanisme d'attention).Par rapport à RNN (Recurrent Neural Network), lorsque la phrase d'entrée est une longue phrase, RNN peut oublier les mots qui apparaissaient dans la phrase précédente, tandis que le mécanisme d'attention de Transformer le poids des mots importants dans la phrase, afin de s'assurer qu'ils ne seront pas oubliés. Et un autre énorme avantage de Transformer est qu'il peut utiliser des méthodes parallèles pour exécuter des calculs, ce qui accélère la vitesse.
La structure spécifique de Transformer est la suivante :
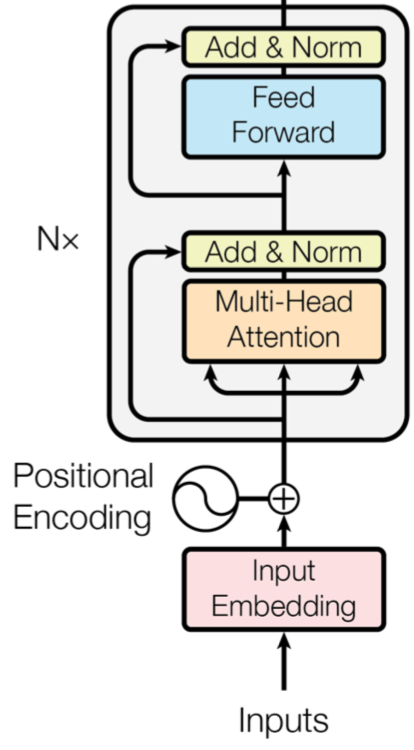
D'après la figure ci-dessus, nous pouvons voir que la structure interne du Transformer est la suivante : les entrées d'entrée sont vectorisées via le module Input Embedding, puis le Positional Encoding y est ajouté, puis les données entrent vers le haut par Multi-Head Attention, Add & Norm, Feed Forward Et parmi les N touts composés d'un autre Add & Norm.
Parmi eux, l'attention multi-têtes est la plus critique.Avant de présenter le mécanisme d'attention multi-têtes de Transformer, parlons brièvement de l'encodage positionnel.
Le codage positionnel, littéralement parlant, est un codage positionnel, qui est utilisé pour représenter la position correspondant à chaque mot dans le vecteur de phrase d'entrée. En raison de la structure différente de Transformer, il est impossible d'obtenir les informations de synchronisation des phrases comme RNN, il est donc nécessaire d'utiliser le codage positionnel pour représenter la séquence de mots dans la phrase. Une méthode de calcul courante consiste à utiliser la fonction sinus et la fonction cosinus pour construire la valeur de chaque position. Des recherches ultérieures ont montré que le même effet peut être obtenu grâce à des paramètres entraînables. Le modèle BERT consiste à atteindre la méthode des paramètres entraînables.
Introduisons maintenant le focus de la structure Transformer : Multi-Head Attention. Le facteur composant de l'attention multi-tête est l'attention à soi. Comme son nom l'indique, l'attention à soi est l'attention à soi, c'est-à-dire que l'énoncé calcule le poids de l'attention pour lui-même. La formule s'exprime comme suit :

Dans la formule (7), prenez un vecteur ligne dans QQ comme exemple (c'est-à-dire le qi correspondant à xi dans chaque échantillon d'entrée), multipliez qiqi par le kiki correspondant à chaque échantillon, puis divisez par la dimension de la tête d'attention pour obtenir la valeur Attention correspondant à chaque échantillon. Ensuite, utilisez la fonction Softmax pour convertir la valeur en une valeur de probabilité (forme vectorielle) dont la somme est 1 et multipliez-la par V pour obtenir la valeur de sortie calculée par le mécanisme d'attention.
Le processus peut également faire référence à la figure suivante :
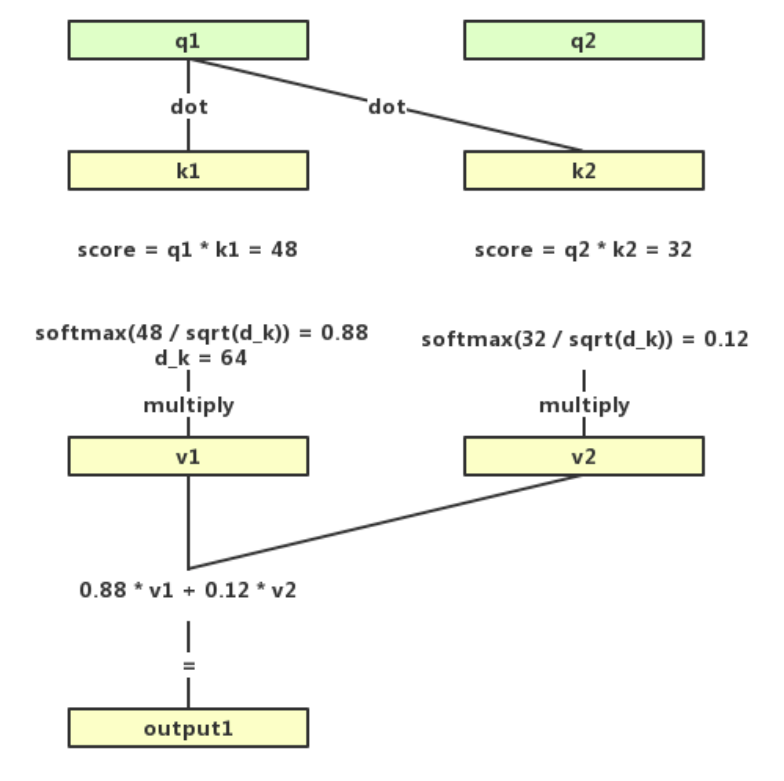
On peut voir que la fonction Bidirection de BERT se reflète dans le mécanisme d'auto-attention, c'est-à-dire lors du calcul de la répartition de l'attention dans une phrase sur un mot, à la fois le mot sur le côté gauche du mot et le mot sur le Le côté gauche du mot est pris en compte Le mot à droite du mot.
Maintenant que nous avons compris l'auto-attention, l'attention multi-Heah est en fait une pile de plusieurs auto-attentions. Comme le montre la figure ci-dessous, l'auto-attention multicouche forme l'attention multi-tête. Cependant, en raison des multiples couches, toute Self-Attention générera finalement plusieurs matrices de la même taille. La méthode de traitement consiste à assembler ces matrices, puis à obtenir le résultat final du calcul en multipliant une matrice de paramètres.
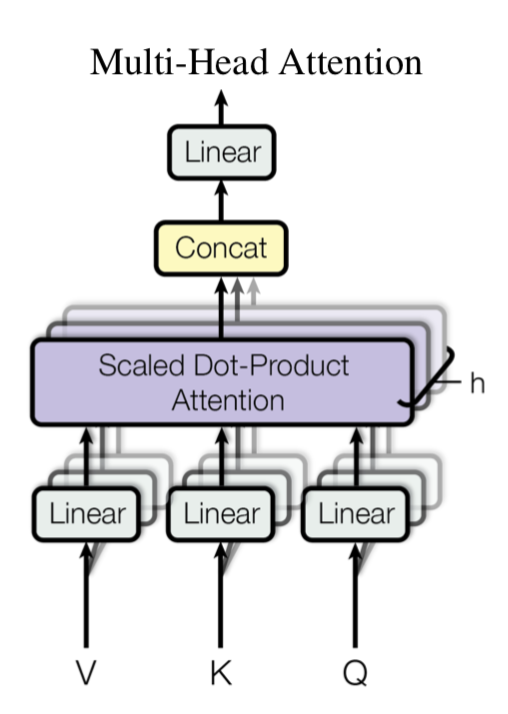
L'attention multi-tête peut mapper la phrase d'entrée sur différents sous-espaces grâce à l'attention sur soi multicouche, afin que les informations contenues dans la phrase puissent être mieux comprises.
Ce qui suit présente un extrait du code d'implémentation du modèle BERT pour l'attention personnelle :
# 取自 hugging face 团队实现的基于 pytorch 的 BERT 模型
class BERTSelfAttention(nn.Module):
# BERT 的 Self-Attention 类
def __init__(self, config):
# 初始化函数
super(BERTSelfAttention, self).__init__()
if config.hidden_size % config.num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (config.hidden_size, config.num_attention_heads))
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
def transpose_for_scores(self, x):
# 调整维度,转换为 (batch_size, num_attention_heads, hidden_size, attention_head_size)
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states):
# 前向传播函数
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# 将"query"和"key"点乘,得到未经处理注意力值
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
# 使用 softmax 函数将注意力值标准化成概率值
attention_probs = nn.Softmax(dim=-1)(attention_scores)
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
return context_layer
En se référant à la structure du transformateur précédent, après que l'attention multi-tête est Add & Norm, qui ajoute et normalise le vecteur calculé par le mécanisme d'attention à l'entrée d'origine, entre dans le réseau de neurones Feed Forward, puis exécute à nouveau l'entrée Add et normaliser.
Méthode de segmentation de mots WordPiece
La structure spécifique de BERT est présentée ci-dessus, et la méthode de prétraitement des données utilisée par BERT est présentée ci-dessous. Le prétraitement des données est très important pour la formation du modèle, qui est liée à l'amélioration de l'efficacité et de la précision de la formation du modèle. BERT utilise la méthode WordPiece lors du prétraitement des données.WordPiece signifie littéralement briser les mots en morceaux.
Par exemple, trois mots tels que regarder, regarder et regarder ont en fait le même sens, mais si nous utilisons des mots comme unités, ils seront considérés comme des mots différents. Cette situation est très courante en anglais, donc pour résoudre ce problème, WordPiece divisera ces trois mots en look, look et ##ed, look et ##ing, cette méthode divise le mot lui-même et la représentation tendue Open, not seul peut réduire efficacement la taille du vocabulaire, améliorer l'efficacité, mais aussi améliorer la distinction des mots.
Cependant, cette méthode n'est pas valable pour le chinois, car chaque caractère est la plus petite unité en chinois, contrairement à l'anglais, qui utilise des espaces pour diviser les mots, et de nombreux mots peuvent être davantage divisés, donc utiliser WordPiece pour le chinois équivaut à diviser par caractères , ce qui est également une limitation du modèle chinois de pré-formation du BERT. Par conséquent, bien que le modèle de pré-formation chinois BERT fonctionne bien, il y a encore place à l'amélioration. Certains chercheurs ont amélioré le BERT chinois de ce point de vue, comme cet article : Couverture complète des mots chinois BERT , les chercheurs ont remplacé la méthode de segmentation des mots de WordPiece dans le BERT original par la segmentation des mots chinois pendant la méthode de traitement des données de pré-formation, puis ajoutent un masque au mot dans son ensemble, et enfin effectuer une pré-formation. Dans le test de l'ensemble de données chinois, les résultats des tests utilisant ce modèle de pré-formation amélioré sont meilleurs que les résultats des tests du modèle de pré-formation chinois utilisant le BERT d'origine.
Modèle pré-formé BERT
La structure de BERT et la méthode WordPiece utilisée par BERT pour le prétraitement des données sont présentées ci-dessus. Ensuite, nous introduirons deux tâches de BERT dans la phase de pré-formation : le modèle de langage masqué et la tâche de prédiction de phrase. Ce sont également ces deux tâches qui permettent au BERT d'apprendre la compréhension du langage naturel.
modèle de langage masqué
Différent de la tâche commune de pré-formation consistant à former le modèle de langage de gauche à droite (modèle de langage de gauche à droite), BERT prend la formation du modèle de langage masqué (modèle de langage masqué) comme objectif de pré-formation, en particulier , l'entrée Les mots de la phrase sont [Mask] recouverts de manière aléatoire d'étiquettes, puis le modèle est formé pour faire des prédictions combinant le contexte gauche et droit des mots couverts. On peut voir que par rapport au modèle de langage de gauche à droite qui ne prédit que le mot suivant dans la phrase de gauche, le modèle de langage masqué peut générer une représentation du langage qui combine les contextes gauche et droit. Cette approche permet à BERT d'apprendre une représentation sémantique plus complète des mots.
L'article de BERT mentionne que la manière spécifique d'augmenter le masque est la suivante : segmentez d'abord la phrase dans WordPiece, puis sélectionnez 15 % des caractères de la phrase après la segmentation, par exemple, sélectionnez le caractère ii, puis :
- Le remplacement est utilisé avec une probabilité de 80 % à 80 %
[Mask]. - Remplacer par un caractère aléatoire avec une probabilité de 10 % 10 %.
- Ne rien faire avec une probabilité de 10% 10%.
Ensuite, nous utilisons les classes encapsulées dans la bibliothèque de modèles PyTorch-Transformers BERTForMaskedLM() pour voir réellement l'effet de prédiction de BERT sur les mots masqués après la pré-formation. Tout d'abord, PyTorch-Transformers doit être installé.
!pip install pytorch-transformers==1.0 # 安装 PyTorch-Transformers
PyTorch-Transformers est une bibliothèque de modèles de pré-formation en traitement du langage naturel construite sur la base du framework d'apprentissage en profondeur PyTorch. Elle s'appelait auparavant pytorch-pretrained-bert, si elle est officiellement devenue un projet indépendant.
À l'aide de la bibliothèque de modèles PyTorch-Transformers, configurez d'abord un exemple à saisir dans le modèle, utilisez l' BertTokenizer() objet de création d'un tokenizer pour segmenter la phrase d'origine, puis convertissez le mot en un numéro de série selon le vocabulaire.
import torch
from pytorch_transformers import BertTokenizer
model_name = 'bert-base-chinese' # 指定需下载的预训练模型参数
# BERT 在预训练中引入了 [CLS] 和 [SEP] 标记句子的开头和结尾
samples = ['[CLS] 中国的首都是哪里? [SEP] 北京是 [MASK] 国的首都。 [SEP]'] # 准备输入模型的语句
tokenizer = BertTokenizer.from_pretrained(model_name)
tokenized_text = [tokenizer.tokenize(i) for i in samples]
input_ids = [tokenizer.convert_tokens_to_ids(i) for i in tokenized_text]
input_ids = torch.LongTensor(input_ids)
input_ids
Utilisez ensuite BertForMaskedLM() le modèle de construction et définissez le modèle sur le mode de validation. Étant donné que le modèle BERT est très volumineux et hébergé sur le réseau externe, cette fois, téléchargez d'abord le lien depuis le disque réseau : disque réseau Baidu, veuillez saisir le
code d'extraction Code d'extraction : qkuc
from pytorch_transformers import BertForMaskedLM
# 读取预训练模型
model = BertForMaskedLM.from_pretrained(model_name, cache_dir="./")
model.eval()
À ce stade, nous avons préparé les phrases à saisir et le modèle pré-formé, et la prochaine chose que nous devons faire est de laisser le modèle prédire le numéro de séquence des mots couverts.
outputs = model(input_ids)
prediction_scores = outputs[0]
prediction_scores.shape
Enfin, trouvez le numéro de série correspondant à la valeur maximale dans la valeur prédite, puis tokenizer.convert_ids_to_tokens() convertissez-le dans le mot correspondant en le recherchant dans le vocabulaire.
import numpy as np
sample = prediction_scores[0].detach().numpy()
pred = np.argmax(sample, axis=1)
tokenizer.convert_ids_to_tokens(pred)[14]
La sortie doit être :
中
On peut voir que le résultat final de la prédiction est correct, indiquant que BERT comprend vraiment la langue.
Tâche de prédiction de phrases
En plus de la stratégie de pré-formation MLM lors de la pré-formation BERT, il est également nécessaire de prédire la phrase suivante. La tâche de prédiction de phrase est basée sur la compréhension de la relation entre deux phrases, qui ne peut pas être directement capturée par le modèle de langage masqué. La composition des données d'apprentissage est composée de phrases dans le corpus pour former des paires de phrases. En détail, lorsque deux phrases adjacentes A et B sont sélectionnées pour former des échantillons de pré-apprentissage, il y a 50 % de chances que la phrase A soit avant la phrase B , et 50% des Chances font que la phrase B précède la phrase A. Bien que cette méthode ne soit pas compliquée, cette pré-formation est très utile pour les tâches en aval telles que les tâches de réponse aux questions et les tâches d'inférence en langage naturel.
Ensuite, nous utilisons le modèle de prédiction de phrase dans la bibliothèque PyTorch-Transformers pour observer les résultats de sortie.
Construisez d'abord l'échantillon d'entrée, puis effectuez la segmentation des mots et la conversion mot-nombre.
samples = ["[CLS]今天天气怎么样?[SEP]今天天气很好。[SEP]", "[CLS]小明今年几岁了?[SEP]小明爱吃西瓜。[SEP]"]
tokenizer = BertTokenizer.from_pretrained(model_name)
tokenized_text = [tokenizer.tokenize(i) for i in samples]
input_ids = [tokenizer.convert_tokens_to_ids(i) for i in tokenized_text]
input_ids = torch.LongTensor(input_ids)
input_ids
0 L'identifiant de segment de la phrase construite est marqué comme et respectivement selon les phrases supérieures et inférieures 1.
segments_ids = [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1]]
segments_tensors = torch.tensor(segments_ids)
segments_tensors
Ensuite, utilisez BertForNextSentencePrediction() le modèle d'initialisation, puis chargez les paramètres de pré-formation de BERT.
from pytorch_transformers import BertForNextSentencePrediction
model = BertForNextSentencePrediction.from_pretrained(
model_name, cache_dir="./")
model.eval()
Enfin, les échantillons sont entrés dans le modèle pour la prédiction, et les résultats de prédiction du modèle sont produits.
outputs = model(input_ids)
seq_relationship_scores = outputs[0]
seq_relationship_scores
sample = seq_relationship_scores.detach().numpy()
pred = np.argmax(sample, axis=1)
pred
Le résultat final devrait être : [0, 1].
0 Cela signifie qu'il s'agit d'une relation contextuelle, 1 et cela signifie que ce n'est pas une relation contextuelle. Par conséquent, on peut voir à partir des résultats ci-dessus que le modèle prédit que la première paire de phrases est la relation de phrase supérieure et inférieure, mais que la deuxième paire de phrases ne l'est pas.La prédiction de ces deux échantillons BERT est correcte.
Regardons l'effet de BERT à travers deux exemples, tous deux très idéaux. En fait, il y a deux raisons principales à la bonne performance du BERT :
- La structure Transformer bidirectionnelle utilisée apprend les contextes gauche et droit.
- En utilisant une formation complète sur le corpus de documents au lieu de phrases brouillées, avec la tâche de prédiction de phrase suivante, il a appris la capacité de capturer les informations dans de très longues phrases continues.
Pratique de classification de texte BERT
Ci-dessus, nous avons complété deux petits exemples en utilisant BERT. Ensuite, essayez d'utiliser BERT pour terminer la tâche de classification de texte. En fait, lorsque vous utilisez BERT pour effectuer une classification de texte, il existe généralement 2 options :
- Extrayez le vecteur de caractéristiques du modèle BERT pré-formé, c'est-à-dire la méthode d'extraction de caractéristiques.
- Ajoutez le modèle de tâche en aval au modèle BERT, puis utilisez l'ensemble d'apprentissage de la tâche en aval pour vous entraîner, c'est-à-dire la méthode de réglage fin.
Habituellement, la méthode de réglage fin est plus couramment utilisée par les personnes, car en affinant l'ensemble de données de la tâche en aval pour ajuster les paramètres du modèle de pré-formation, le modèle peut mieux capturer les caractéristiques des données de la tâche en aval. Ensuite, utilisez la méthode Fine-Tuning pour appliquer le modèle de pré-formation BERT pour les tâches de classification des sentiments.
Tout d'abord, téléchargez un ensemble de données de classification des sentiments , que nous avons téléchargé à l'avance et placé sur le disque réseau.
Après avoir téléchargé le jeu de données, lisez le fichier de données.
with open('./negdata.txt', 'r', encoding='utf-8') as f:
neg_data = f.read()
with open('./posdata.txt', 'r', encoding='utf-8') as f:
pos_data = f.read()
neg_datalist = neg_data.split('\n')
pos_datalist = pos_data.split('\n')
len(neg_datalist), len(pos_datalist)
Après avoir lu les données, nous allons stocker les données dans une liste, et construire une liste de balises, avec 1 des commentaires positifs et 0 des commentaires négatifs.
import numpy as np
dataset = np.array(pos_datalist + neg_datalist)
labels = np.array([1] * len(pos_datalist) + [0] * len(neg_datalist))
len(dataset) # 共 3000 条数据
Randomisez les exemples de données à l'aide de la bibliothèque NumPy.
np.random.seed(10)
mix_index = np.random.choice(3000, 3000)
dataset = dataset[mix_index]
labels = labels[mix_index]
len(dataset), len(labels)
Prenez ensuite 2500 données comme ensemble d'apprentissage et 500 données comme ensemble de vérification.
TRAINSET_SIZE = 2500
EVALSET_SIZE = 500
train_samples = dataset[:TRAINSET_SIZE] # 2500 条数据
train_labels = labels[:TRAINSET_SIZE]
eval_samples = dataset[TRAINSET_SIZE:TRAINSET_SIZE+EVALSET_SIZE] # 500 条数据
eval_labels = labels[TRAINSET_SIZE:TRAINSET_SIZE+EVALSET_SIZE]
len(train_samples), len(eval_samples)
La fonction de construction d'une get_dummies fonction est de convertir l'étiquette en une représentation unique, telle que 1 l'expression en tant que [0, 1], 0 l'expression [1, 0] en tant que.
def get_dummies(l, size=2):
res = list()
for i in l:
tmp = [0] * size
tmp[i] = 1
res.append(tmp)
return res
DataLoader() Ici , la représentation de l'ensemble de données de l'ensemble d'apprentissage fournie par PyTorch est utilisée et TensorDataset() l'itérateur de données de l'ensemble d'apprentissage est utilisé.
from torch.utils.data import DataLoader, TensorDataset
tokenized_text = [tokenizer.tokenize(i) for i in train_samples]
input_ids = [tokenizer.convert_tokens_to_ids(i) for i in tokenized_text]
input_labels = get_dummies(train_labels) # 使用 get_dummies 函数转换标签
for j in range(len(input_ids)):
# 将样本数据填充至长度为 512
i = input_ids[j]
if len(i) != 512:
input_ids[j].extend([0]*(512 - len(i)))
# 构建数据集和数据迭代器,设定 batch_size 大小为 4
train_set = TensorDataset(torch.LongTensor(input_ids),
torch.FloatTensor(input_labels))
train_loader = DataLoader(dataset=train_set,
batch_size=4,
shuffle=True)
train_loader
Similaire à la création de l'itérateur de données de l'ensemble d'apprentissage, créez l'itérateur de données de l'ensemble de validation.
tokenized_text = [tokenizer.tokenize(i) for i in eval_samples]
input_ids = [tokenizer.convert_tokens_to_ids(i) for i in tokenized_text]
input_labels = eval_labels
for j in range(len(input_ids)):
i = input_ids[j]
if len(i) != 512:
input_ids[j].extend([0]*(512 - len(i)))
eval_set = TensorDataset(torch.LongTensor(input_ids),
torch.FloatTensor(input_labels))
eval_loader = DataLoader(dataset=eval_set,
batch_size=1,
shuffle=True)
eval_loader
Vérifiez si la machine dispose d'un GPU, si c'est le cas, exécutez-le sur le GPU, sinon exécutez-le sur le CPU.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
Créez une classe pour la classification, ajoutez un modèle BERT, ajoutez une couche sous le modèle BERT Dropout pour éviter le surajustement et une Linear couche entièrement connectée.
import torch.nn as nn
import torch.nn.functional as F
from pytorch_transformers import BertModel
class fn_cls(nn.Module):
def __init__(self):
super(fn_cls, self).__init__()
self.model = BertModel.from_pretrained(model_name, cache_dir="./")
self.model.to(device)
self.dropout = nn.Dropout(0.1)
self.l1 = nn.Linear(768, 2)
def forward(self, x, attention_mask=None):
outputs = self.model(x, attention_mask=attention_mask)
x = outputs[1] # 取池化后的结果 batch * 768
x = x.view(-1, 768)
x = self.dropout(x)
x = self.l1(x)
return x
Définissez la fonction de perte et créez l'optimiseur.
from torch import optim
cls = fn_cls()
cls.to(device)
cls.train()
criterion = nn.BCELoss()
sigmoid = nn.Sigmoid()
optimizer = optim.Adam(cls.parameters(), lr=1e-5)
Créez une fonction de prédiction pour calculer le résultat de la prédiction.
def predict(logits):
res = torch.argmax(logits, 1)
return res
Créez la fonction d'entraînement et démarrez l'entraînement. Ce qu'il faut dire ici, c'est qu'en raison de la limitation de la mémoire GPU, l'ensemble d'entraînement batch_size est défini sur 4, ce qui est batch_size trop petit, rendant la direction de descente du gradient imprécise, provoquant des oscillations et rendant difficile la convergence. Par conséquent, la méthode d'accumulation de gradient est utilisée pendant la formation, c'est-à-dire que la valeur moyenne des gradients de 8 petits lots est calculée pour mettre à jour le modèle, obtenant ainsi l'effet de 32 petits lots.
from torch.autograd import Variable
import time
pre = time.time()
accumulation_steps = 8
epoch = 3
for i in range(epoch):
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data).to(device), Variable(
target.view(-1, 2)).to(device)
mask = []
for sample in data:
mask.append([1 if i != 0 else 0 for i in sample])
mask = torch.Tensor(mask).to(device)
output = cls(data, attention_mask=mask)
pred = predict(output)
loss = criterion(sigmoid(output).view(-1, 2), target)
# 梯度积累
loss = loss/accumulation_steps
loss.backward()
if((batch_idx+1) % accumulation_steps) == 0:
# 每 8 次更新一下网络中的参数
optimizer.step()
optimizer.zero_grad()
if ((batch_idx+1) % accumulation_steps) == 1:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss:{:.6f}'.format(
i+1, batch_idx, len(train_loader), 100. *
batch_idx/len(train_loader), loss.item()
))
if batch_idx == len(train_loader)-1:
# 在每个 Epoch 的最后输出一下结果
print('labels:', target)
print('pred:', pred)
print('训练时间:', time.time()-pre)
Après l'entraînement, vous pouvez utiliser l'ensemble de validation pour observer l'effet d'entraînement du modèle.
from tqdm import tqdm_notebook as tqdm
cls.eval()
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(tqdm(eval_loader)):
data = data.to(device)
target = target.long().to(device)
mask = []
for sample in data:
mask.append([1 if i != 0 else 0 for i in sample])
mask = torch.Tensor(mask).to(device)
output = cls(data, attention_mask=mask)
pred = predict(output)
correct += (pred == target).sum().item()
total += len(data)
# 准确率应该达到百分之 90 以上
print('正确分类的样本数:{},样本总数:{},准确率:{:.2f}%'.format(
correct, total, 100.*correct/total))
Une fois la formation terminée, vous pouvez également saisir des données à volonté pour observer directement les résultats de prédiction du modèle.
test_samples = ['东西很好,好评!', '东西不好,差评!']
cls.eval()
tokenized_text = [tokenizer.tokenize(i) for i in test_samples]
input_ids = [tokenizer.convert_tokens_to_ids(i) for i in tokenized_text]
input_ids = torch.LongTensor(input_ids).cuda()
mask = torch.ones_like(input_ids).to(device)
output = cls(input_ids, attention_mask=mask)
pred = predict(output)
pred
Résumer
Cette fois, nous avons d'abord appris le modèle de langage statistique et le modèle de langage de réseau de neurones, puis introduit des vecteurs de mots à partir du modèle de langage de réseau de neurones, et enfin appris le modèle de représentation du langage BERT qui peut générer des vecteurs de mots basés sur le contexte. Ensuite, la structure du BERT et ses deux tâches de phase de pré-formation sont introduites, et les résultats de la pré-formation sont observés. Enfin, BERT est appliqué à l'aide de la méthode Fine-Tuning pour une tâche complète de classification des sentiments.