pache 社のソフトウェア パッケージの公式ダウンロード アドレス: archive.apache.org/dist/
注: Kafka はバージョン 3.0 以降、Zookeeper に依存しなくなりました。
動物園飼育員の概要
公式ダウンロードアドレス: https://archive.apache.org/dist/zookeeper/
動物園飼育員の定義
Zookeeper は、分散フレームワークの調整サービスを提供するオープンソースの分散 Apache プロジェクトです。
飼育員の動作メカニズム
Zookeeper をデザイン パターンの観点から理解すると、オブザーバー パターンに基づいて設計された分散サービス管理フレームワークであり、誰もが関心を持つデータの保存と管理を担当し、オブザーバーの登録を受け付けます。これらのデータ変更があった場合、Zookeeper は、Zookeeper に登録されているオブザーバーに、それに応じて対応するよう通知する責任があります。
つまり、Zookeeper = ファイル システム + 通知メカニズム
動物園飼育員の特徴
(1) 飼育員: リーダー (Leader)、複数のフォロワーのクラスター (Follower)。
(2) Zookeeper クラスター内のノードの半分以上が存続している限り、Zookeeper クラスターは正常に機能します。したがって、Zookeeper は奇数のサーバーをインストールするのに適しています。
(3) グローバル データの一貫性: 各サーバーは同じデータのコピーを保存し、クライアントがどのサーバーに接続してもデータは一貫しています。
(4) 更新要求は順次実行され、同一クライアントからの更新要求は送信順、すなわち先入れ先出しで順次実行されます。
(5) データ更新のアトミック性。データ更新は成功するか失敗します。
(6) リアルタイムで、一定の時間範囲内で、クライアントは最新のデータを読み取ることができます

Zookeeper のデータ構造
ZooKeeper データ モデルの構造は Linux ファイル システムに非常に似ており、全体としてツリーとみなすことができ、各ノードは ZNode と呼ばれます。各 ZNode はデフォルトで 1MB のデータを保存でき、各 ZNode はパスによって一意に識別できます。
Zookeeper のアプリケーション シナリオ
提供されるサービスには、統合ネーミング サービス、統合構成管理、統合クラスター管理、サーバー ノードの動的なアップ/ダウン、ソフト ロード バランシングなどが含まれます。
ユニファイドネーミングサービス
分散環境では、多くの場合、簡単に識別できるようにアプリケーション/サービスに統一した名前を付ける必要があります。例: IP は覚えにくいですが、ドメイン名は覚えやすいです
統合構成管理
(1) 分散環境では、構成ファイルの同期が非常に一般的です。一般に、Kafka クラスターなどのクラスターでは、すべてのノードの構成情報が一貫していることが必要です。構成ファイルが変更された後は、各ノードと迅速に同期できることが期待されます。
(2) ZooKeeperによる構成管理が可能です。構成情報は、ZooKeeper 上の Znode に書き込むことができます。各クライアント サーバーはこの Znode をリッスンします。Znode 内のデータが変更されると、ZooKeeper は各クライアント サーバーに通知します。
統合クラスター管理
(1) 分散環境では各ノードの状態をリアルタイムに把握する必要があります。ノードのリアルタイムのステータスに応じて、いくつかの調整を行うことができます。
(2) ZooKeeper はノード状態変化のリアルタイム監視を実現します。ZooKeeper 上の ZNode にノード情報を書き込むことができます。この ZNode をリッスンして、リアルタイムのステータス変化を取得します
サーバーは動的にオンラインとオフラインになります
クライアントは、オンラインおよびオフラインになるサーバーの変化をリアルタイムで把握できます。
ソフトロードバランシング
Zookeeper の各サーバーの訪問数を記録し、訪問数が最も少ないサーバーに最新のクライアント要求を処理させます。
動物園飼育員の選出メカニズム
選挙メカニズムの最初の立ち上げ
5 つのサーバーがあると仮定します。
(1) サーバー 1 が起動し、選挙が開始されます。サーバー 1 は自分自身に投票します。この時点で、サーバー 1 の投票権は 1 つで、半分 (3 票) に満たないため、選挙を完了できず、サーバー 1 のステータスは LOOKING のままです。
(2) サーバー 2 が起動され、別の選出が開始されます。サーバー 1 と 2 はそれぞれ投票し、投票情報を交換します。このとき、サーバー 1 は、サーバー 2 の myid が現在投票されているもの (サーバー 1) より大きいことを発見し、投票をサーバー 2 を推奨するように変更します。このとき、サーバー 1 は 0 票、サーバー 2 は 2 票となっており、半数以上の結果が得られない場合は選挙を完了できず、サーバー 1 とサーバー 2 のステータスは LOOKING のままになります。
(3) サーバー 3 が起動し、選挙が開始されます。この時点で、サーバー 1 と 2 の両方が投票をサーバー 3 に変更します。この投票の結果: サーバー 1 は 0 票、サーバー 2 は 0 票、サーバー 3 は 3 票です。この時点でサーバー 3 が過半数の票を獲得しており、サーバー 3 がリーダーに選出されます。サーバー 1 と 2 はステータスを FOLLOWING に変更し、サーバー 3 はステータスを LEADING に変更します。
(4) サーバー 4 が起動され、選挙が開始されます。この時点で、サーバー 1、2、および 3 は LOOKING 状態ではなくなり、投票情報は変更されません。投票情報を交換した結果: サーバー 3 は 3 票、サーバー 4 は 1 票です。このとき、サーバー 4 は多数決に従い、投票情報をサーバー 3 に変更し、状態を FOLLOWING に変更します。
(5) サーバー 4 と同様に弟としてサーバー 5 が起動されます。
選挙メカニズムを開始するのは初めてではない
ZooKeeper クラスター内のサーバーが次の 2 つの状況のいずれかに該当すると、リーダーの選出が開始されます。
(1) サーバが初期化され、起動されます。
(2) サーバー稼働中はリーダーへの接続を維持できません。
2. マシンがリーダー選出プロセスに入ると、現在のクラスターは次の 2 つの状態になる場合もあります。
(1) クラスター内にすでにリーダーが存在します。
- すでにリーダーが存在する場合、マシンがリーダーを選出しようとすると、現在のサーバーのリーダー情報が通知されます。このマシンの場合、リーダー マシンとの接続を確立し、状態の同期を実行するだけで済みます。 。
(2) 確かにクラスター内にリーダーは存在しません。
-
ZooKeeper が 5 台のサーバーで構成されており、SID が 1、2、3、4、および 5、ZXID が 8、8、8、7、および 7 であり、SID 3 のサーバーがリーダーであるとします。ある時点でサーバー 3 と 5 に障害が発生し、リーダーの選挙が始まります。
-
選挙リーダーのルール:
- ビッグエポックが直接勝利
- EPOCH は同じで、トランザクション ID が大きい方が勝ちです
- トランザクション ID は同じで、サーバー ID が大きい方が優先されます。
チップ:
- SID: サーバーID。これは、ZooKeeper クラスター内のマシンを一意に識別するために使用されます。各マシンを繰り返すことはできず、myid と一貫性があります。
- ZXID: トランザクション ID。ZXID は、サーバーの状態変化を識別するために使用されるトランザクション ID です。ある時点では、クラスター内の各マシンの ZXID 値がまったく同じにならない場合があります。これは、クライアントの「更新リクエスト」に対する ZooKeeper サーバーの処理ロジック速度に関係しています。
- エポック: 各リーダー用語のコード名。リーダーが存在しない場合、同じラウンドの投票プロセスにおける論理クロック値は同じです。この数字は投票するたびに増加します
2. Zookeeper クラスターを展開する
Zookeeper クラスター用に 3 台のサーバーを準備する
192.168.137.10
192.168.137.15
192.168.137.20
ファイアウォールをオフにする
#所有节点执行
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
JDKのインストール
#非最小化安装一般自带
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
java -version
インストールパッケージをダウンロードする
公式ダウンロード アドレス: /dist/zookeeper のインデックス
cd /opt
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
構成ファイルの変更 (すべてのノード)
cd /usr/local/zookeeper-3.6.3/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
tickTime=2000 #通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10 #Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5 #Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.6.3/data ●修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.6.3/logs ●添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连接端口
#添加集群信息
server.1=192.168.52.140:3188:3288
server.2=192.168.52.110:3188:3288
server.3=192.168.52.100:3188:3288
#集群节点通信时使用端口3188,选举leader时使用的端口3288
-------------------------------------------------------------------------------------
server.A=B:C:D
●A是一个数字,表示这个是第几号服务器。集群模式下需要在zoo.cfg中dataDir指定的目录下创建一个文件myid,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
●B是这个服务器的地址。
●C是这个服务器Follower与集群中的Leader服务器交换信息的端口。
●D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。scp zoo.cfg 192.168.137.15:`pwd`
scp zoo.cfg 192.168.137.20:`pwd`各ノードにデータ ディレクトリとログ ディレクトリを作成する
mkdir /usr/local/zookeeper-3.6.3/data
mkdir /usr/local/zookeeper-3.6.3/logs
各ノードのdataDirで指定したディレクトリにmyidファイルを作成します。
echo 1 > /usr/local/zookeeper-3.6.3/data/myid
echo 2 > /usr/local/zookeeper-3.6.3/data/myid
echo 3 > /usr/local/zookeeper-3.6.3/data/myidZookeeper 起動スクリプトを構成する
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.6.3'
case $1 in
start)
echo "---------- zookeeper 启动 ------------"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "---------- zookeeper 停止 ------------"
$ZK_HOME/bin/zkServer.sh stop
;;
restart)
echo "---------- zookeeper 重启 ------------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "---------- zookeeper 状态 ------------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
#将服务控制脚本传输到其他节点
scp /etc/init.d/zookeeper 192.168.137.10:/etc/init.d/
scp /etc/init.d/zookeeper 192.168.137.20:/etc/init.d/
#设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper
#分别启动 Zookeeper
service zookeeper start
#查看当前状态
service zookeeper statusvim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.6.3'
case $1 in
start)
echo "---------- zookeeper 启动 ------------"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "---------- zookeeper 停止 ------------"
$ZK_HOME/bin/zkServer.sh stop
;;
restart)
echo "---------- zookeeper 重启 ------------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "---------- zookeeper 状态 ------------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
#将服务控制脚本传输到其他节点
scp /etc/init.d/zookeeper 192.168.137.10:/etc/init.d/
scp /etc/init.d/zookeeper 192.168.137.20:/etc/init.d/
#设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper
#分别启动 Zookeeper
service zookeeper start
#查看当前状态
service zookeeper statusカフカの概要
メッセージ キュー (MQ) が必要な理由
主な理由は、同時実行性の高い環境では、同期リクエストの処理が遅すぎて、リクエストがブロックされることが多いためです。たとえば、多数のリクエストが同時にデータベースにアクセスすると、行ロックやテーブル ロックが発生し、最終的にはリクエスト スレッドが多すぎて蓄積され、接続エラーが多すぎて雪崩現象が発生します。
メッセージ キューを使用して、リクエストを非同期に処理することでシステムへの負荷を軽減します。メッセージ キューは、非同期処理、トラフィックのピークカット、アプリケーションの切り離し、メッセージ通信などのシナリオでよく使用されます。
現在、
Web アプリケーション用の一般的なミドルウェア: nginx、tomcat、apache、haproxy、squid、varnish。
MQ メッセージ キュー ミドルウェア: ActiveMQ、RabbitMQ、RocketMQ、Kafka、redis などの
メッセージ キューを使用する利点。
- デカップリング
同じインターフェイスの制約に従っている限り、両側の処理を独立して拡張または変更できます。
- 回復性
システムの一部に障害が発生しても、システム全体には影響しません。メッセージ キューによりプロセス間の結合が軽減されるため、メッセージを処理するプロセスがハングアップした場合でも、キューに追加されたメッセージはシステムの回復後に引き続き処理できます。
- バッファ
これは、システム内のデータ フローの速度を制御および最適化し、生成メッセージと消費メッセージの処理速度が一致しない状況を解決するのに役立ちます。
- 柔軟性とピーク対応能力
トラフィックが急増した場合でも、アプリケーションは機能し続ける必要がありますが、このようなトラフィックの急増はまれです。このようなピークアクセスに対処するためにリソースを常にスタンバイ状態に投資するのは、間違いなく多大な無駄です。メッセージ キューを使用すると、主要コンポーネントが突然の過負荷要求によって完全にクラッシュすることなく、突然のアクセス圧力に耐えることができます。
- 非同期通信
多くの場合、ユーザーはメッセージをすぐに処理したくないし、その必要もありません。メッセージ キューは、ユーザーがメッセージをすぐに処理せずにキューに入れることができる非同期処理メカニズムを提供します。必要なだけメッセージをキューに入れ、必要に応じて処理します。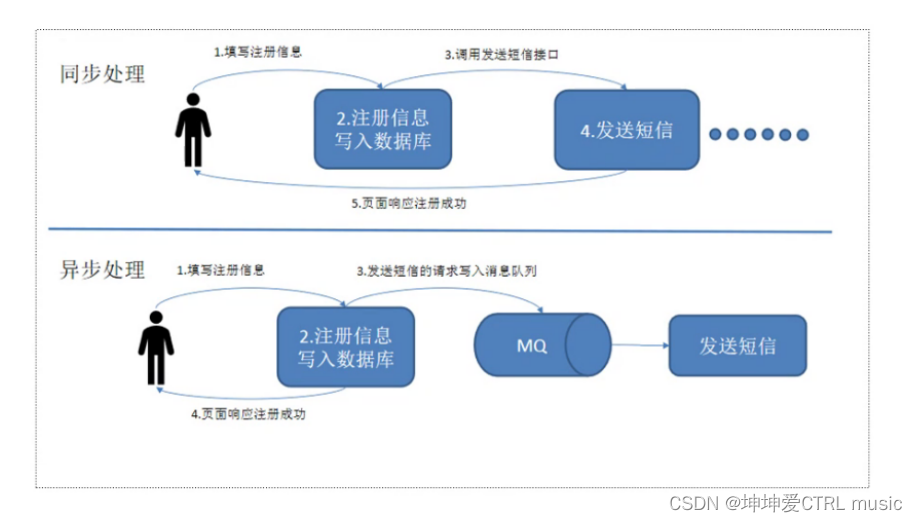
メッセージキューの 2 つのモード
- ポイントツーポイント モード (1 対 1、コンシューマーが積極的にデータをプルし、メッセージは受信後にクリアされます)
- メッセージ プロデューサはメッセージを作成してメッセージ キューに送信し、メッセージ コンシューマはメッセージ キューからメッセージを取り出して消費します。メッセージが消費されると、メッセージ キューにはそれ以上のストレージがなくなるため、メッセージ コンシューマは、すでに消費されたメッセージを消費することはできません。メッセージ キューは複数のコンシューマをサポートしますが、メッセージの場合、それを消費できるのは 1 つのコンシューマのみです。
- パブリッシュ/サブスクライブ モード (1 対多、オブザーバー モードとも呼ばれ、コンシューマーはデータを消費した後にメッセージをクリアしません)
- メッセージ プロデューサー (パブリッシャー) はメッセージをトピックにパブリッシュし、複数のメッセージ コンシューマー (サブスクライバー) が同時にメッセージを消費します。ピアツーピア方式とは異なり、トピックにパブリッシュされたメッセージはすべてのサブスクライバーによって消費されます。パブリッシュ/サブスクライブ モードでは、オブジェクト間の 1 対多の依存関係を定義します。これにより、オブジェクト (ターゲット オブジェクト) の状態が変化するたびに、それに依存するすべてのオブジェクト (オブザーバー オブジェクト) が通知され、自動的に更新されます。
カフカの定義
- Kafka は分散パブリッシュ/サブスクライブ ベースのメッセージ キュー (MQ、メッセージ キュー) であり、主にビッグ データのリアルタイム処理の分野で使用されます。
カフカの紹介
Kafka はもともと Linkedin によって開発され、Zookeeper によって調整された、分散、パーティションサポート、レプリカベースの分散メッセージ ミドルウェア システムです。その最大の特徴は、大量のデータをリアルタイムに処理できることです。さまざまな需要シナリオに対応するために、 Hadoop ベースのバッチ処理システム、低遅延リアルタイム システム、Spark/Flink ストリーミング処理エンジン、nginx アクセス ログ、メッセージ サービスなど、scala 言語で書かれたシステムに、Linkedin が 2010 年に貢献し、Apache Foundation となりました。トップのオープンソースプロジェクト
カフカの特徴
高スループット、低遅延
Kafka は 1 秒あたり数十万のメッセージを処理でき、待ち時間はわずか数ミリ秒です。各トピックは複数のパーティションに分割でき、コンシューマ グループは pPartition 上で消費操作を実行して、ロード バランシングと消費機能を向上させます。
スケーラビリティ
Kafka クラスターは熱膨張の
持続性と信頼性をサポートします
メッセージはローカル ディスクに保存され、データ損失と
フォールト トレランスを防ぐためにデータ バックアップがサポートされています。
クラスター内のノードの障害を許可します (複数のコピーの場合、コピーの数が n の場合、n-1 ノードの障害が許可されます)
高い同時実行性
数千のクライアントの同時読み取りと書き込みをサポート
Kafka システム アーキテクチャ
ブローカ
Kafka サーバーはブローカーです。クラスターは複数のブローカーで構成されます。ブローカーは複数のトピックを保持できます。
トピック
これはキューとして理解でき、プロデューサーとコンシューマーの両方がトピックに直面しています。
データベースのテーブル名やESのインデックスに似ています
物理的に異なるトピックメッセージは個別に保存されます
パーティション
スケーラビリティを実現するために、非常に大きなトピックを複数のブローカー (つまりサーバー) に分散でき、トピックを 1 つ以上のパーティションに分割し、各パーティションを順序付きキューにすることができます。Kafka は、パーティション内のレコードが順序どおりであることのみを保証しますが、トピック内の異なるパーティションの順序は保証しません。
パーティションデータルーティングルール
- パーティションが指定されている場合は、それを直接使用します。
- パーティションが指定されていないが、キーが指定されている場合 (メッセージ内の属性に相当)、キーの値に対してハッシュ モジュロを実行することによってパーティションが選択されます。
- パーティションとキーの両方が指定されておらず、パーティションはポーリングによって選択されます。
- 各メッセージには、メッセージのオフセットを識別するために使用される自己増加する番号があり、識別シーケンスは 0 から始まります。
- 各パーティションのデータは、複数のセグメント ファイルを使用して保存されます。
- トピックに複数のパーティションがある場合、データを使用するときにデータの順序は保証されません。メッセージの消費順序が厳密に保証されているシナリオ (商品のフラッシュセールや赤い封筒の入手など) では、パーティションの数を 1 に設定する必要があります。
- ブローカーはトピック データを保存します。トピックに N 個のパーティションがあり、クラスターに N 個のブローカーがある場合、各ブローカーはトピックのパーティションを保存します。
- トピックに N 個のパーティションがあり、クラスターに (N+M) 個のブローカーがある場合、N 個のブローカーはトピックのパーティションを保存し、残りの M 個のブローカーはトピックのパーティション データを保存しません。
- トピックに N 個のパーティションがあり、クラスター内のブローカーの数が N 未満の場合、1 つのブローカーがトピックの 1 つ以上のパーティションを保存します。実際の運用環境では、Kafka クラスター内のデータの不均衡を容易に引き起こす可能性があるこの状況を回避するようにしてください。
分割の理由
- クラスター内で拡張すると便利です。各パーティションは、それが配置されているマシンに適応するように調整でき、トピックは複数のパーティションで構成できるため、クラスター全体があらゆるサイズのデータに適応できます。
- パーティション単位で読み書きできるため、同時実行性が向上します。
レプリカ
- クラスター内のノードに障害が発生した場合に、ノード上のパーティション データが失われず、Kafka が引き続き動作できるようにするために、コピーします。Kafka はコピー メカニズムを提供します。トピックの各パーティションには複数のコピーがあり、リーダーと数人のフォロワー
リーダー
- 各パーティションには複数のコピーがあり、そのうちの 1 つだけがリーダーであり、リーダーが現在データの読み取りと書き込みを担当するパーティションになります。
フォロワー
- フォロワーはリーダーに従い、すべての書き込みリクエストはリーダーを通じてルーティングされ、データの変更はすべてのフォロワーにブロードキャストされ、フォロワーとリーダーはデータの同期を維持します。Follower はバックアップのみを担当し、データの読み取りと書き込みは担当しません。
- リーダーが失敗した場合は、フォロワーの中から新しいリーダーが選出されます。
- フォロワーがハングしたり、スタックしたり、同期が遅すぎたりすると、リーダーは ISR (リーダーによって管理され、リーダーと同期された一連のフォロワー) リストからフォロワーを削除し、新しいフォロワーを作成します。
プロデューサー
- プロデューサーはデータの発行者であり、この役割はメッセージ プッシュを Kafka のトピックに発行します。
- ブローカーは、プロデューサによって送信されたメッセージを受信した後、データの追加に現在使用されているセグメント ファイルにメッセージを追加します。
- プロデューサーによって送信されたメッセージはパーティションに保存され、プロデューサーはデータ ストレージのパーティションを指定することもできます。
消費者
- 消費者はブローカーからデータを取得できます。コンシューマは複数のトピックからのデータを利用できます。
消費者グループ(CG)
- コンシューマ グループは複数のコンシューマで構成されます。
- すべてのコンシューマはコンシューマ グループに属します。つまり、コンシューマ グループは論理サブスクライバです。コンシューマごとにグループ名を指定できます。グループ名が指定されていない場合は、デフォルトのグループに属します。
- 複数のコンシューマーを集めて特定のトピックのデータを処理すると、データの消費容量をより速く向上させることができます。
- コンシューマ グループ内の各コンシューマは、異なるパーティションからのデータを消費する責任があります。データが繰り返し読み取られるのを防ぐため、パーティションはグループ内の 1 人のコンシューマによってのみ消費されます。
- 消費者団体は相互に影響を与えない
オフセット オフセット
- メッセージは一意に識別できます。
- オフセットによって読み取られるデータの位置が決まり、スレッドの安全性の問題は発生しません。コンシューマーはオフセットを使用して、次回読み取るメッセージ (つまり、消費場所) を決定します。
- メッセージは消費された後、すぐには削除されないため、複数の企業が Kafka メッセージを再利用できます。
- 特定のサービスでは、ユーザーが制御するオフセットを変更することで、メッセージを再読み取りするという目的を達成することもできます。
- メッセージは最終的に削除され、デフォルトのライフサイクルは 1 週間 (7*24 時間) です。
動物園の飼育員
- Kafka は、Zookeeper を使用してクラスターのメタ情報を保存します。消費者は消費過程で停電やダウンタイムなどの障害が発生する可能性があるため、回復後は障害発生前の場所から消費を継続する必要があるため、消費者はどのオフセットを消費したかをリアルタイムで記録する必要があります。障害が回復した後も消費を継続できるようにします。Kafka バージョン 0.9 より前では、コンシューマはデフォルトでオフセットを Zookeeper に保存していましたが、バージョン 0.9 以降では、コンシューマはデフォルトでオフセットを組み込みの Kafka トピック (__consumer_offsets) に保存しました。つまり、Zookeeper の役割は、プロデューサーがデータを Kafka クラスターにプッシュするときに、Kafka クラスターのノードがどこにあるかを見つける必要があることです。これらはすべて Zookeeper を通じて見つけられます。消費者がどのデータを消費するかについても、Zookeeper のサポートが必要です。オフセットは Zookeeper から取得され、最後に消費されたデータがどこで消費されたかを記録するため、次のデータを次に消費できるようになります。
Kafka クラスターをデプロイする
インストールパッケージをダウンロードする
公式ダウンロード アドレス: Apache Kafka
cd /opt
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgzKafka をインストールする
cd /opt/
tar zxvf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka設定ファイルを変更する
cd /usr/local/kafka/config/
cp server.properties{,.bak}
vim server.properties
broker.id=0
#21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.137.10:9092
#31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3 #42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1 #69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168 #103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824 #110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
zookeeper.connect=192.168.239.40:2181,192.168.137.10:2181,192.168.137.20:2181
#123行,配置连接Zookeeper集群地址
mkdir /usr/local/kafka/logsKafkaを他のノードに転送する
cd /usr/local
scp -r kafka/ 192.168.137.15:`pwd`
scp -r kafka/ 192.168.137.20:`pwd他のノード構成ファイルを変更する
#50节点
cd /usr/local/kafka/config/
vim server.properties
#修改21行broker的全局唯一编号
broker.id=1
#修改31行监听地址
listeners=PLAINTEXT://192.168.137.15:9092
#60节点
cd /usr/local/kafka/config/
#修改21行broker的全局唯一编号
broker.id=2
#修改31行监听地址
listeners=PLAINTEXT://192.168.137.20:9092環境変数を変更する (すべてのノード)
cd /usr/local/kafka/bin
ls
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profileZookeeper サービス制御スクリプトを作成する
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)
echo "---------- Kafka 启动 ------------"
${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)
echo "---------- Kafka 停止 ------------"
${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)
$0 stop
$0 start
;;
status)
echo "---------- Kafka 状态 ------------"
count=$(ps -ef | grep kafka | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
echo "kafka is not running"
else
echo "kafka is running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esacサービス制御スクリプトを他のノードに転送する
scp /etc/init.d/kafka 192.168.137.20:/etc/init.d/
scp /etc/init.d/kafka 192.168.137.15:/etc/init.d/ブートアップを設定し、Kafka を開始します (すべてのノード)
chmod +x /etc/init.d/kafka
chkconfig --add kafka
service kafka start
ps -ef | grep kafka #查看服务是否启动Kafka コマンドライン操作
トピックを作成する
kafka-topics.sh --create --zookeeper 192.168.137.10:2181,192.168.137.15:2181,192.168.137.20:2181 --replication-factor 2 --partitions 3 --topic ky18
#--zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
#--replication-factor:定义分区副本数,1 代表单副本,建议为 2
#--partitions:定义分区数
#--topic:定义 topic 名称現在のサーバー内のすべてのトピックを表示する
kafka-topics.sh --list --zookeeper 192.168.137.10:2181,192.168.137.20:2181,192.168.137.15:2181
トピックの詳細を表示する
kafka-topics.sh --describe --zookeeper 192.168.137.10:2181,192.168.137.20:2181,192.168.137.15:2181
発表をする
kafka-console-producer.sh --broker-list 192.168.137.10:9092,192.168.137.20:9092,192.168.137.15:9092 --topic ky18
消費ニュース
kafka-console-consumer.sh --bootstrap-server 192.168.137.10:9092,192.168.137.20:9092,192.168.137.15:9092 --topic ky18 --from-beginning
#--from-beginning:会把主题中以往所有的数据都读取出来パーティションの数を変更する
kafka-topics.sh --zookeeper 192.168.137.10:2181,192.168.137.20:2181,192.168.137.15:2181 --alter --topic ky18 --partitions 6
トピックを削除する
kafka-topics.sh --delete --zookeeper 192.168.137.10:2181,192.168.137.20:2181,192.168.137.15:2181 --topic ky18
要約する
カフカのアーキテクチャ
ブローカー: kafka サーバー kafka は複数のブローカーで構成されます
トピック: メッセージ キューのプロデューサーとコンシューマーは両方ともトピック指向です
プロデューサー: プロデューサー プッシュは、メッセージ データをブローカーのトピックにプッシュします。
Consumer: コンシューマ プルはブローカーのトピックからメッセージ データをプルします。
パーティション: パーティション トピックは、メッセージ送信 (読み取りと書き込み) を高速化するために 1 つ以上のパーティションに分割できます。コピーはパーティションをバックアップします。リーダーは読み取りと書き込みを担当し、フォロワーはバックアップを担当します。
パーティション内のメッセージ データは順序付けされています。パーティションには順序がありません。セクキル赤封筒など、順序が必要なシーンでは 1 つのパーティションのみを使用できます。
offset: オフセットはコンシューマの消費メッセージの場所を記録し、コンシューマが最後に消費したデータがどこにあるかを記録します。これにより、次のデータが引き続き消費されるようになります。
Zookeeper: Kafka クラスターのソース情報を保存し、オフセットを保存します
Zookeeper と Kafka の組み合わせ: プロデューサーがデータを Kafka クラスターにプッシュするとき、zk を介して kafka の場所にアドレス指定する必要があり、オフセットは zk から取得できるため、コンシューマーが消費するデータにも zk のサポートが必要です。