1. MySQL テーブルの追加、削除、確認、変更の概要
• CRUD の略: 作成 (追加)、取得 (検索)、更新 (変更)、削除 (削除)。
• CRUD の操作対象はテーブル内のデータであり、代表的なデータ操作言語である DML (Data Manipulation Language) です。
2.新規データの作成
2.1. 挿入コマンド
新しいデータを追加するための挿入コマンドは次のとおりです。
INSERT [INTO] table_name [(column1 [, column2] ...)] VALUES (value_list1) [, (value_list2)] ...;説明:
• SQL では、大文字はキーワードを表し、[ ] 内はオプションの項目を表します。
• SQL の各 value_list は挿入されるレコードを表し、各 value_list は挿入される複数の列値で構成されます。
• SQL の列リスト。各 value_list の各列値をテーブル内のどの列に挿入するかを指定するために使用されます。
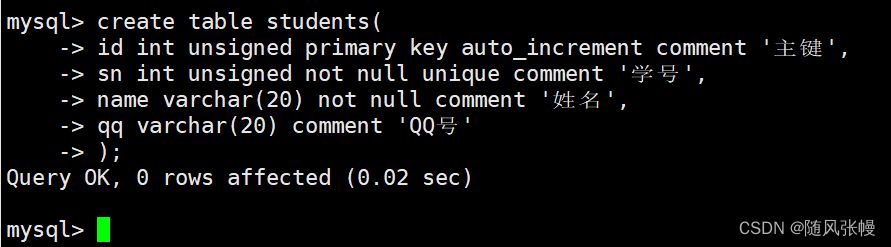
デモのために、自己増加する主キー ID、学生番号、名前、QQ 番号を含む学生テーブルを以下に作成します。次のように:
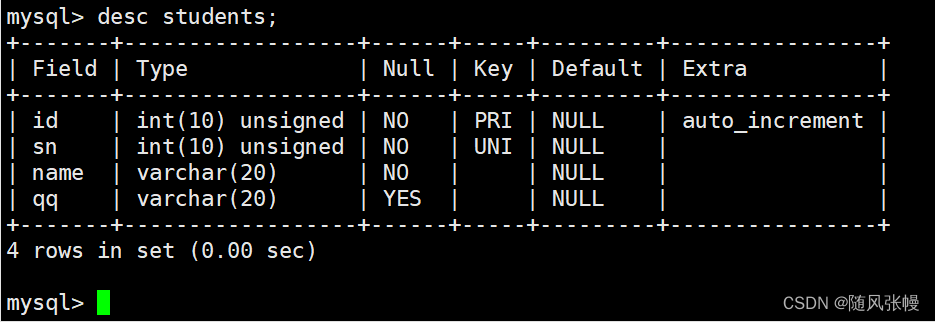
テーブルを作成した後にテーブル構造を確認すると、テーブル構造が次のようになっていることがわかります。
2.2. 単一行データ + 全列挿入
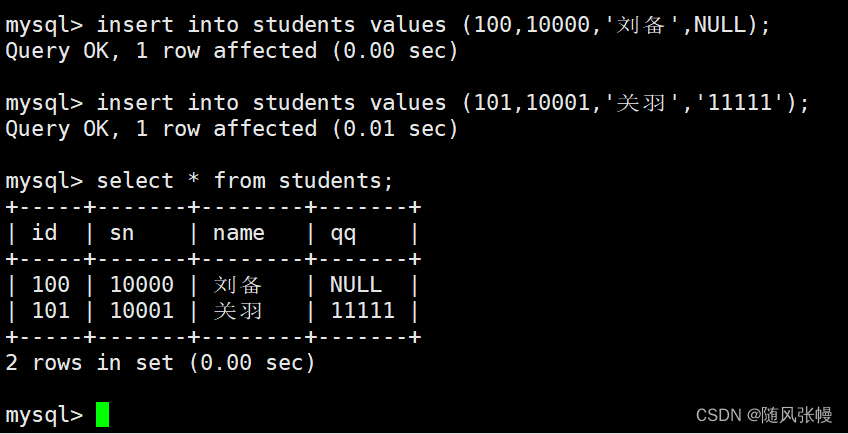
単一行データ + 全列挿入:
次の例では、insert ステートメントを使用して、学生テーブルにレコードを挿入します。レコードがテーブルに挿入されるたびに、レコードの挿入時に列リストが指定されていない場合、すべての列がデフォルトの列順序に従って挿入されることを意味します。したがって、挿入された各レコードでは、列の値がテーブルの順序で連続してリストされる必要があります。次のように:
2.3. 複数行データ+指定列挿入
複数行データ + 指定した列の挿入:
また、insert ステートメントを使用すると、テーブルに複数のレコードを一度に挿入できます。挿入される複数のレコードはカンマで区切られ、レコードの挿入時に特定の列のみを指定して挿入できます。次のように:
注: レコードを挿入する場合、値を指定せずに挿入できるのは、空であることが許可されている列または自己拡張フィールドのみです。空であることが許可されていない列は、値を指定して挿入する必要があります。そうでない場合は、エラーが報告されます。 。
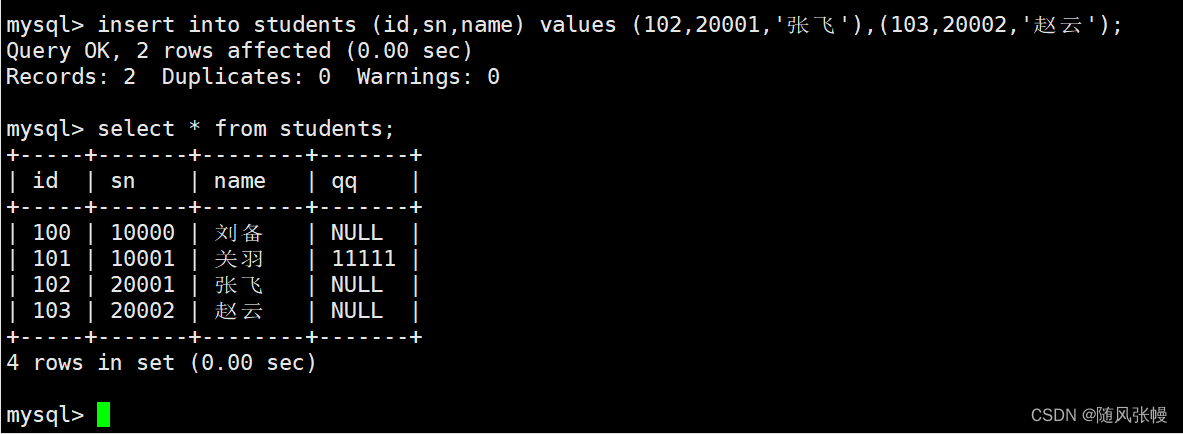
2.4. 他に更新を挿入
更新された使用シナリオを挿入します。
テーブルにレコードを挿入する際、挿入するレコードの主キーまたは一意キーがすでに存在する場合、主キーの競合または一意キーの競合により挿入は失敗します。次のように:
現時点では、オプションで同期更新操作を実行できます。
• テーブル内に競合するデータがない場合、データは直接挿入されます。
• テーブル内に競合するデータがある場合、テーブル内のデータは更新されます。
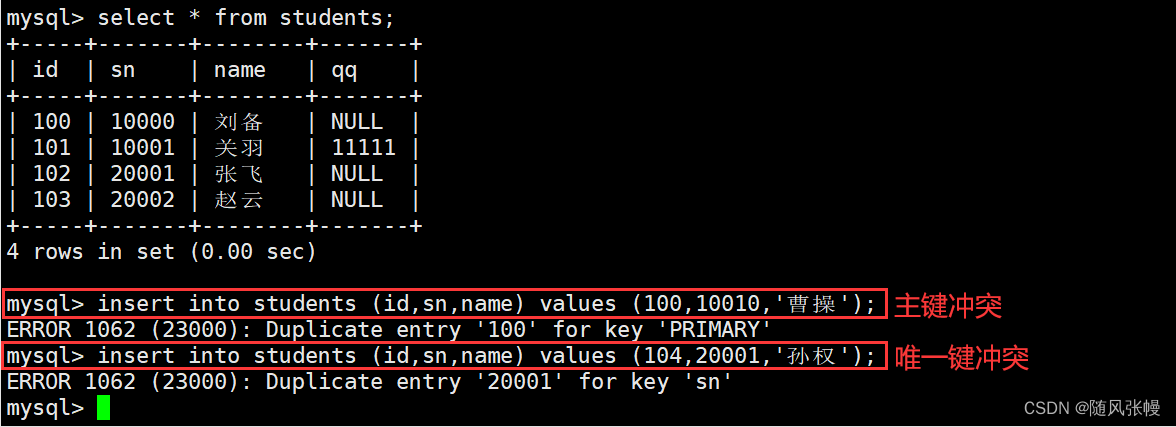
挿入、そうでない場合の更新の SQL は次のとおりです。
INSERT ... ON DUPLICATE UPDATE column1=value1 [, column2=value2] ...;説明:
• SQL では、大文字はキーワードを表し、[ ] 内はオプションの項目を表します。
• SQL の INSERT 後の構文は、前の INSERT ステートメントと同じです。
• UPDATE の後の column=value は、挿入されたレコードに競合がある場合に更新する必要がある列の値を示します。
他に更新を挿入:
たとえば、学生テーブルにレコードを挿入する場合、主キーの競合がない場合、レコードは直接挿入されますが、主キーの競合がある場合、テーブル内の競合するレコードの学生番号と名前が更新されます。 。次のように:
挿入または更新の SQL を実行した後、影響を受けるデータ行の数によってこのデータの挿入ステータスを判断できます。
• 影響を受ける行が 0 行:表内に競合するデータがありますが、競合するデータの値が指定された更新値と同じです(更新されるデータは元のデータと同じです)。
• 1 行が影響を受けます: テーブル内に競合するデータはなく、データは直接挿入されます。
• 2 行が影響を受けます: テーブル内に競合するデータがあり、データは更新されています。
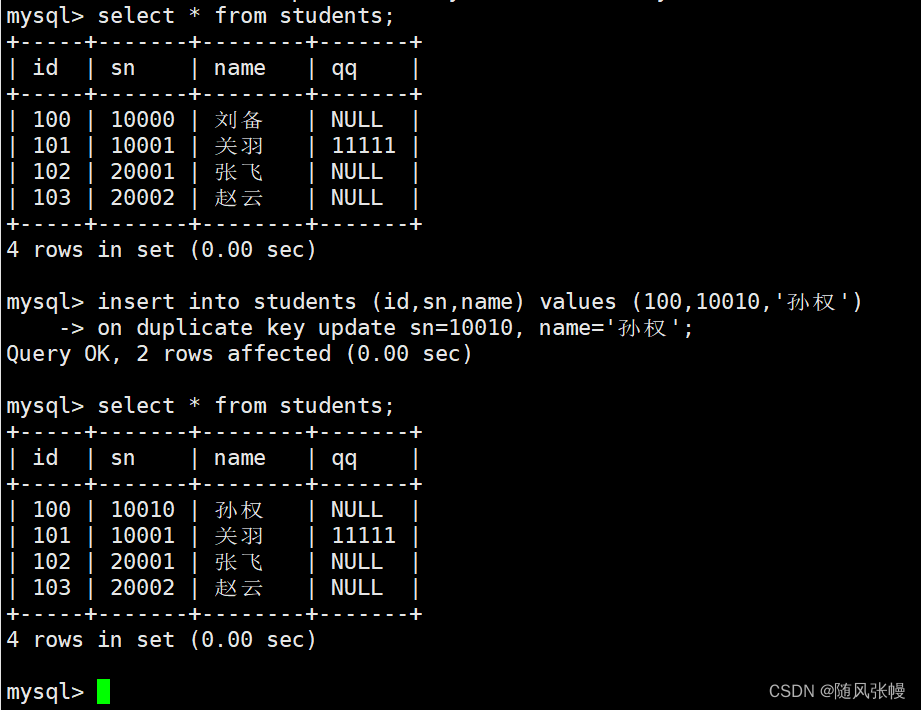
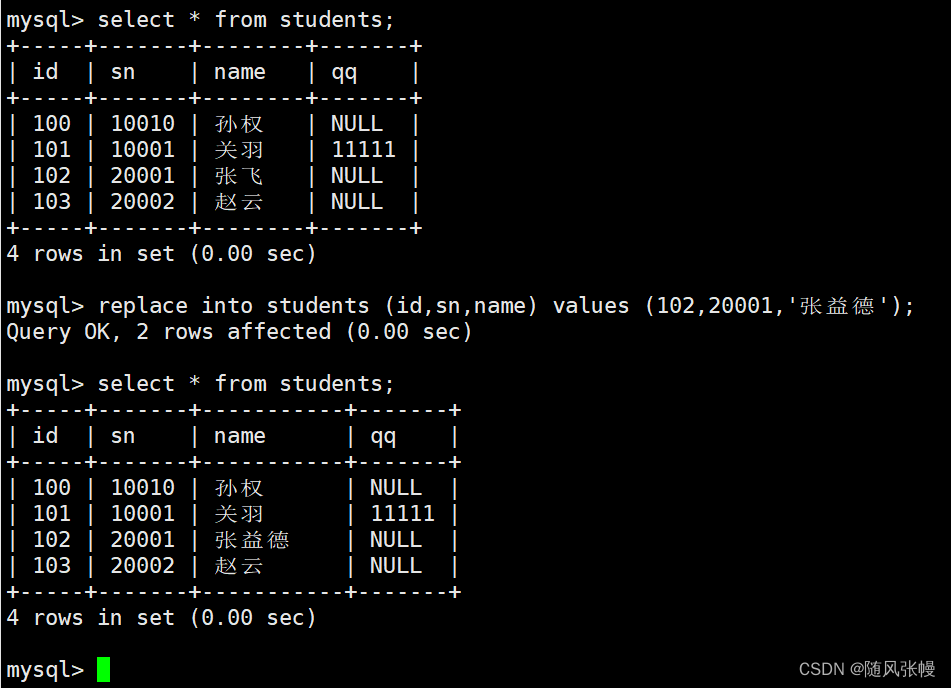
2.5. データの置き換え
置換データ:
• テーブル内に競合するデータがない場合、データは直接挿入されます。
• テーブル内に競合するデータがある場合は、まずテーブル内の競合するデータを削除してから、データを挿入します。
上記の効果を実現するには、データを挿入するときに SQL ステートメントの INSERT を REPLACE に変更するだけです。例えば:
データ置換用の SQL を実行した後、影響を受けるデータ行の数によってこのデータの挿入ステータスを判断することもできます。
• 1 行が影響を受けます: テーブル内に競合するデータはなく、データは直接挿入されます。
• 2 行が影響を受けます: テーブル内に競合するデータがあり、競合するデータは削除され、再挿入されます。
3. 検索データの取得
3.1. 選択コマンド
データを検索する SQL は次のとおりです。
SELECT [DISTINCT] {* | {column1 [, column2] ...}} FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...];説明:
• SQL では、大文字はキーワードを表し、[ ] 内はオプションの項目を表します。
• { } 内の | は、左側のステートメントまたは右側のステートメントが選択できることを意味します。
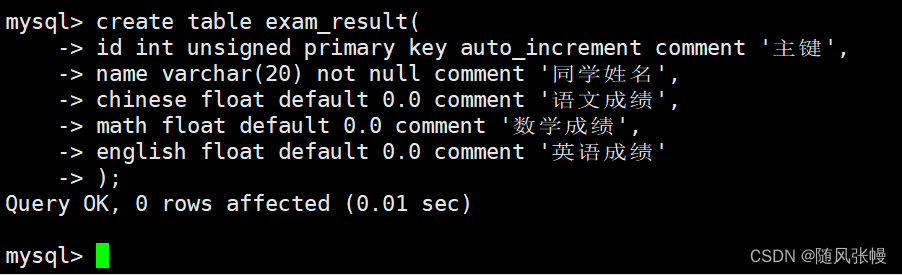
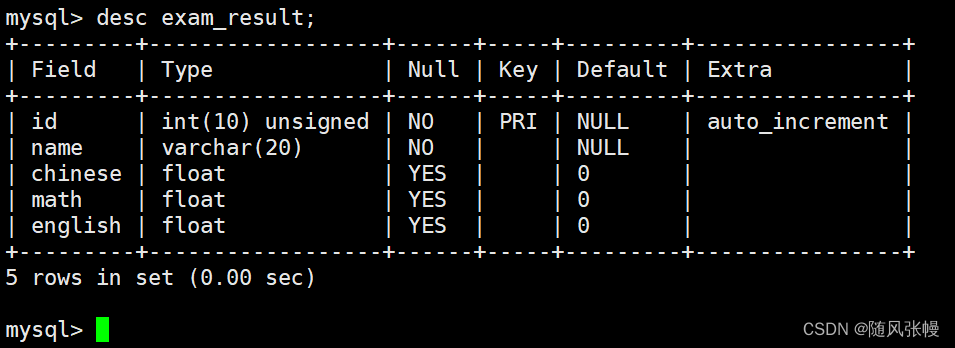
デモのために、自己増加する主キー ID、名前、生徒の中国語スコア、数学スコア、英語スコアを含むスコア テーブルを以下に作成します。次のように:
テーブルを作成した後にテーブル構造を確認すると、テーブル構造が次のようになっていることがわかります。
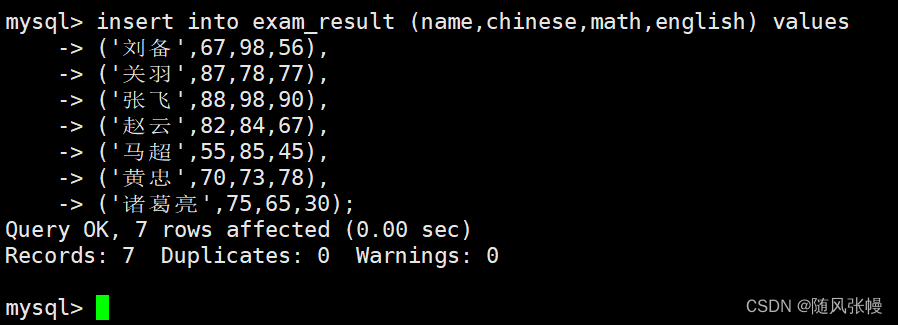
次に、検索できるようにいくつかのテスト レコードをテーブルに挿入します。次のように:
3.2. SELECT カラム
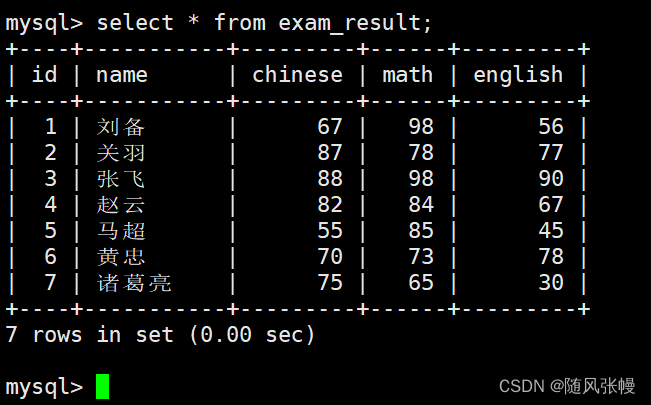
全列クエリ:
データをクエリする場合、* を直接使用して列リストを置き換えます。これは、全列クエリを実行することを意味し、フィルタリングされたレコードのすべての列情報が表示されます。次のように:
注: 一般に、クエリされたデータはネットワークを介して MySQL サーバーからホストに送信される必要があるため、フルカラム クエリに * を使用することは推奨されません。クエリされるカラムが増えるほど、送信されるデータの量が増加します。さらに、全列クエリを実行すると、インデックスの使用に影響を与える可能性があります。
指定された列クエリ:
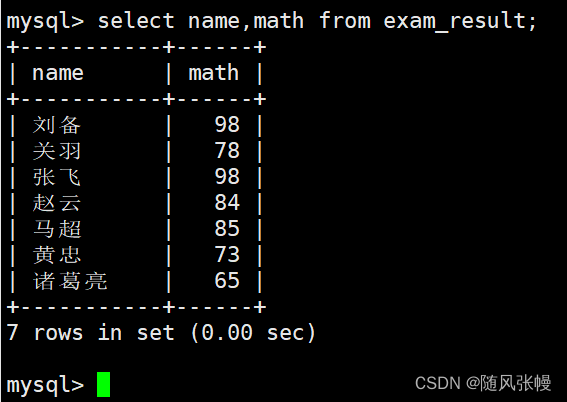
データをクエリするときは、指定した列のみをクエリすることもできます。このとき、クエリが必要な列を列リストにリストすることもできます。次のように:
クエリ フィールドは次の式です。
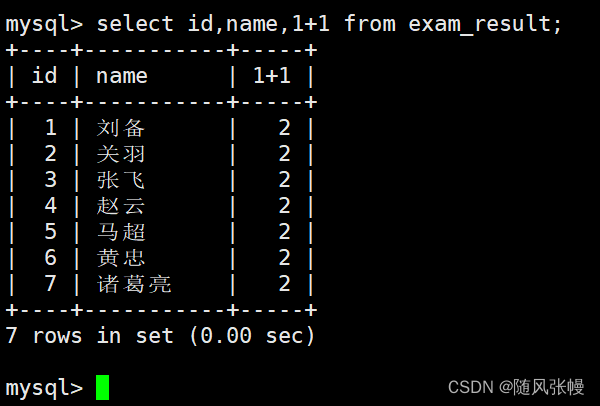
データをクエリする場合、列リストにリストできる列名に加えて、列リストに式をリストすることもできます。次のように:
なぜなら、select はデータのクエリだけでなく、特定の式を計算したり、特定の関数を実行したりするためにも使用できるからです。次のように:
列リストに式を列挙すると、レコードが除外されるたびに式が実行され、式の計算結果がレコードの列の値として表示されます。
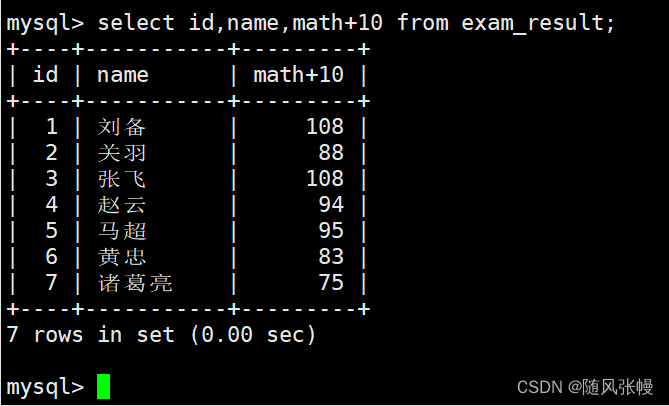
列リストの式には、テーブル内の既存のフィールドを含めることができます。このとき、レコードがフィルターで除外されるたびに、レコード内の対応する列の値が計算用の式に提供されます。次のように:
列リストの式には、複数のテーブルの既存のフィールドを含めることもでき、式を通じてより意味のあるデータを計算できます。次のように:
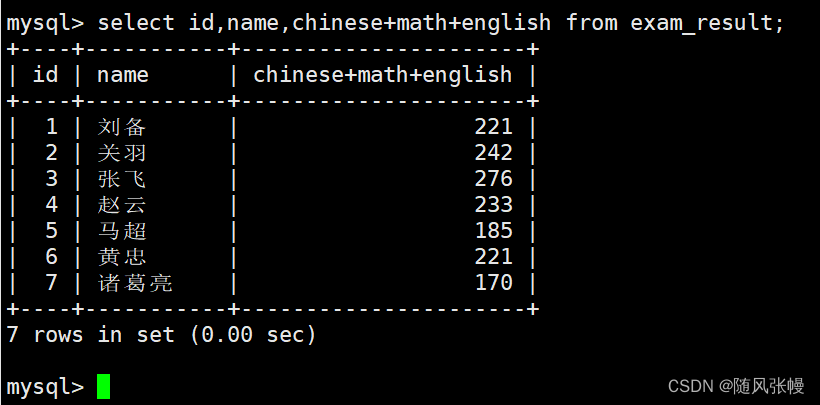
クエリ結果のエイリアスを指定します。
クエリ結果の別名を指定する SQL は次のとおりです。
SELECT column [AS] alias_name [...] FROM table_name;説明:
• SQL では、大文字はキーワードを表し、[ ] 内はオプションの項目を表します。
たとえば、成績表のデータをクエリする場合、各レコードの 3 つの科目を追加し、計算結果に対応する列の別名を「合計点」に割り当てます。次のように:
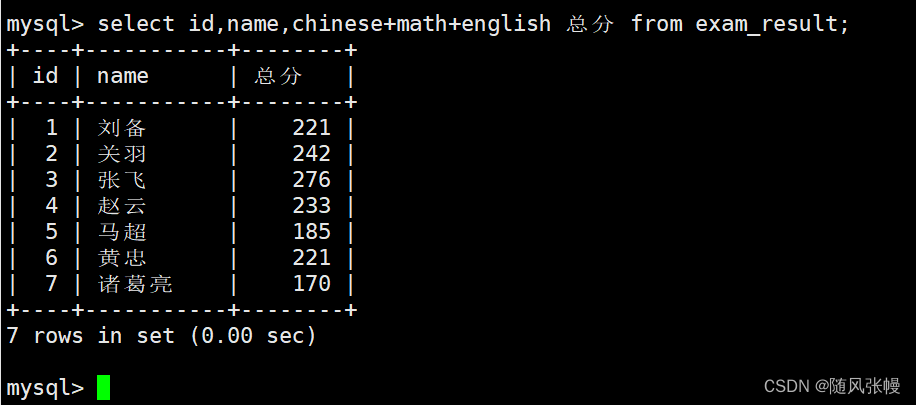
重複排除の結果:
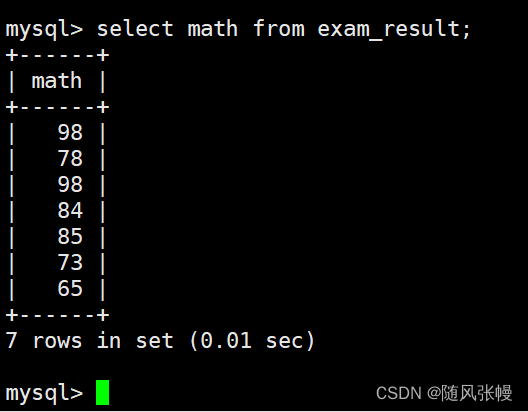
スコア テーブルをクエリするときに、クエリの数学スコアに対応する列を指定すると、数学スコアに繰り返しスコアがあることがわかります。次のように:
クエリ結果の重複を排除する場合は、SQL で select の後に unique を追加できます。次のように:

3.3.WHERE 条件
WHERE 条件:
where 句を追加する場合の違い:
• データのクエリ時に where 句が指定されていない場合は、テーブル内のすべてのレコードがデータ ソースとして直接使用され、select ステートメントが順番に実行されます。
• データクエリ時に where 句を指定した場合、データクエリ時に where 句に従って条件に合致するレコードが絞り込まれ、条件に合致したレコードをデータソースとして順次 select 文が実行されます。 。
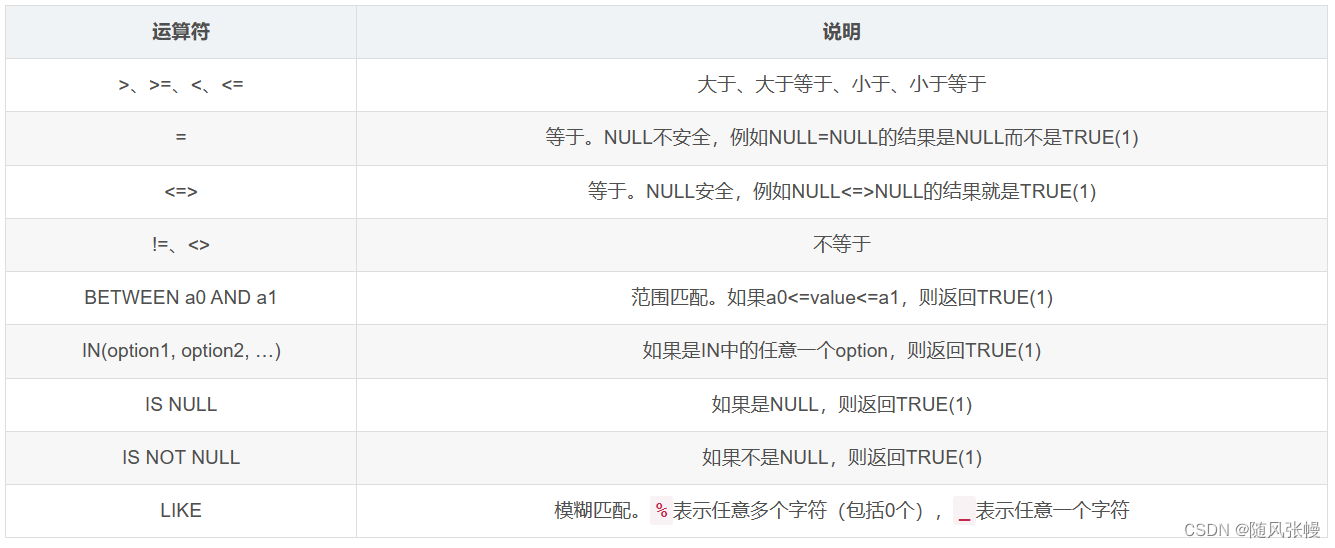
where 句には 1 つ以上のフィルタ条件を指定でき、各フィルタ条件を論理演算子 AND または OR で関連付けることができます。where 句でよく使用される比較演算子および論理演算子は次のとおりです。比較演算子:
論理演算子:

英語で不合格だった生徒とその英語のスコアを質問します。
where句でフィルタ条件が英語スコアが60未満であることを示し、selectの列リストでクエリ対象の列が名前と英語スコアであることを指定します。次のように:
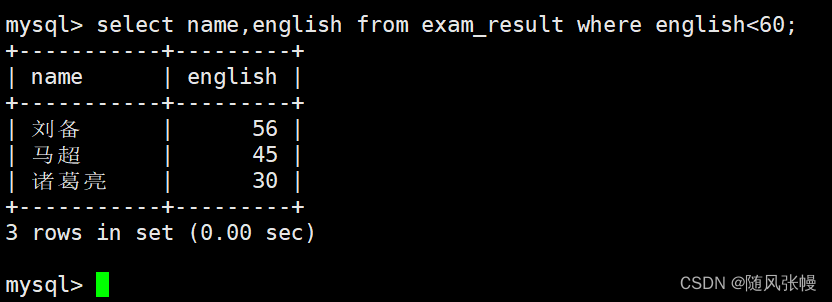
中国語のスコアが 80 ~ 90 の学生とその中国語のスコアをクエリします。
where句でフィルタ条件が中国語スコアが80以上90以下であることを指定し、selectの列リストでクエリ対象の列が名前と中国語スコアであることを指定します。 。次のように:
さらに、ここでは BETWEEN a0 AND a1 を使用して言語スコアの範囲を示すこともできます。次のように:
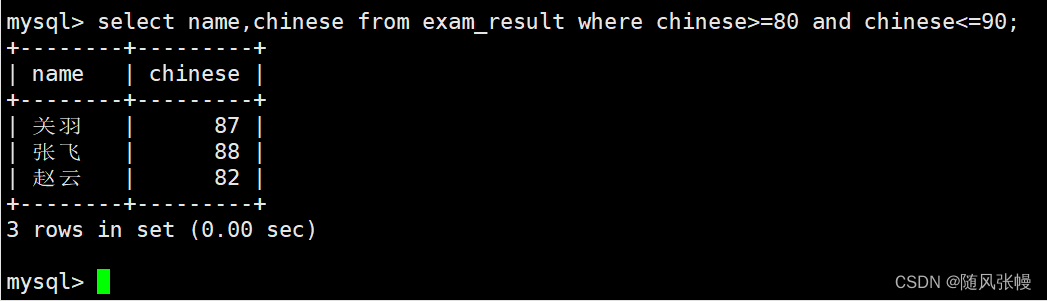

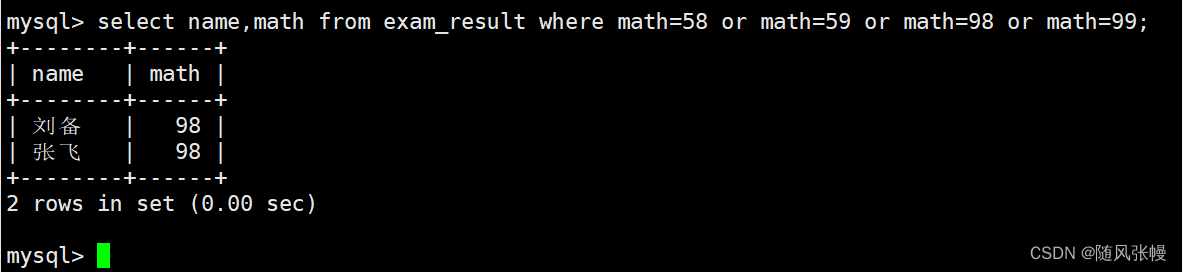
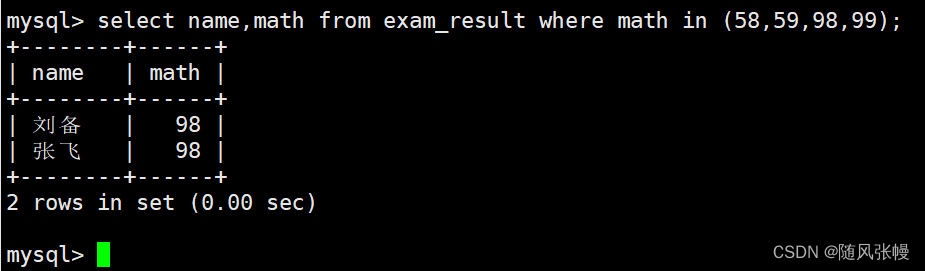
数学のスコアが 58 または 59 または 98 または 99 の生徒とその数学のスコアをクエリします。
where 句で、フィルター条件が数学スコアが 58 または 59 または 98 または 99 に等しいことであることを示し、select の列リストで、クエリ対象の列が名前と数学スコアであることを指定します。次のように:
さらに、ここでは IN(58,59,98,99) の方法を使用して、数学のスコアがスクリーニング要件を満たしているかどうかを判断することもできます。次のように:
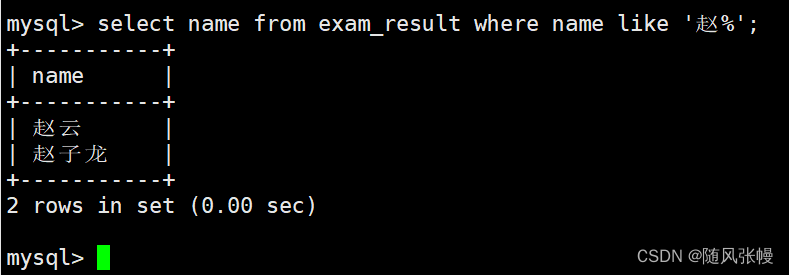
Zhao という姓のクラスメートと Zhao のクラスメートをそれぞれクエリします。
姓が趙である生徒に質問します。
where 句では、あいまい一致を使用して現在のクラスメートの姓が Zhao であるかどうかを判断し (複数の文字に一致するには % を使用する必要があります)、クエリする列を select の列リストの name として指定します。次のように:
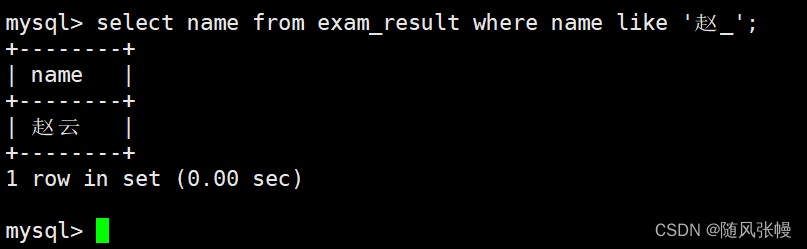
Zhao という名前のクラスメートについて尋ねます。
where句では、現在のクラスメートがZhaoであるかどうかをあいまい一致(単一の文字と厳密に一致させるには_を使用する必要があります)によって判断し、クエリする列をselectの列リストのnameとして指定します。次のように:
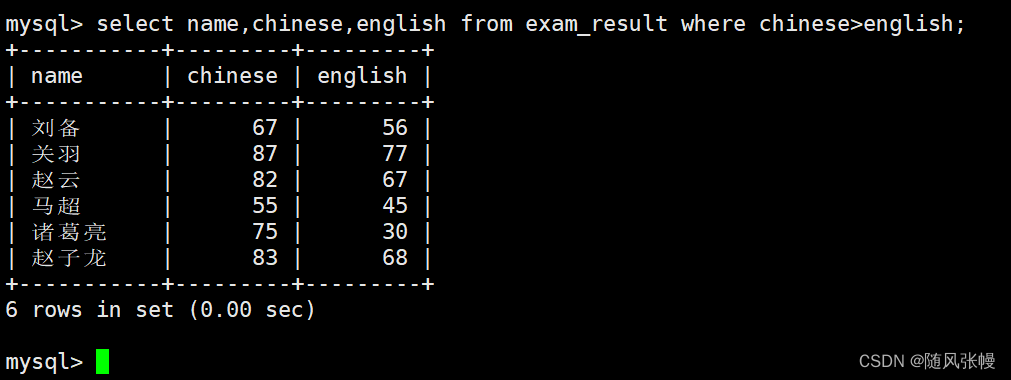
中国語のスコアが英語のスコアよりも優れている学生にクエリを実行します。
where 句で、フィルター条件が中国語のスコアが英語のスコアより大きいことであることを示し、select の列リストで、クエリする列が名前、中国語のスコア、および英語のスコアであることを指定します。次のように:
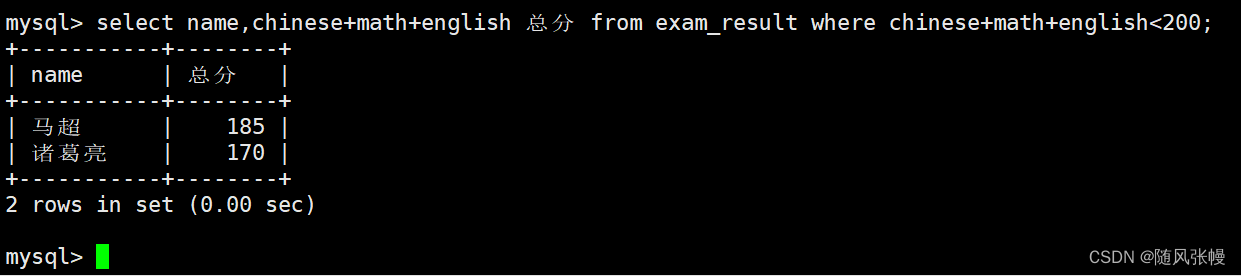
合計スコアが 200 ポイント未満の生徒にクエリを実行します。
select の列リストに式クエリを追加します。クエリの式は、中国語、数学、英語のスコアの合計です。観察しやすいように、式に対応する列の別名を「合計スコア」として指定できます。を指定し、where 句でフィルターを指定します。条件は、3 つのサブジェクトの合計が 200 未満であることです。次のように:
select で指定されたエイリアスは where 句では使用できないことに注意してください。
• データをクエリするときは、最初に where 句に従って修飾されたレコードを除外します。
• 次に、条件を満たすレコードをデータソースとして使用して、select ステートメントを順番に実行します。
つまり、where 句は select ステートメントの前に実行されるため、where 句でエイリアスを使用することはできません。where 句でエイリアスを使用すると、データのクエリ時にエラーが報告されます。次のように:

中国語のスコアが 80 を超え、姓が Zhao ではない学生に対するクエリ:
where 句で、フィルタ条件が中国語スコアが 80 より大きいことであることを示し、あいまい一致を使用し、学生の姓が Zhao ではないことを確認せず、クエリする列を名前と中国語スコアとして指定します。選択の列リスト。次のように:

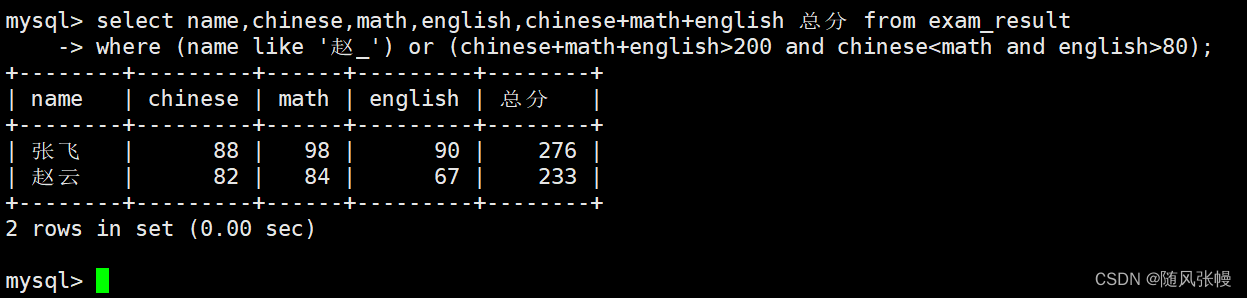
Zhao にクエリを実行します。そうでない場合、合計スコアは 200 点を超え、中国語のスコアは数学のスコアより低く、英語のスコアは 80 点を超えています。
このトピックの要件は、結果を確認することです。質問されている人物は Zhao であるか、合計スコアが 200 点を超え、中国語のスコアが数学のスコア未満で、英語のスコアが 80 点を超えています。ファジー マッチング、クエリには式クエリと論理演算が必要です。次のように:
NULL クエリ:
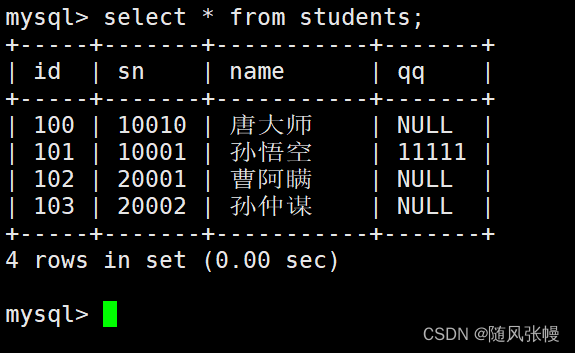
テストフォームを準備します。
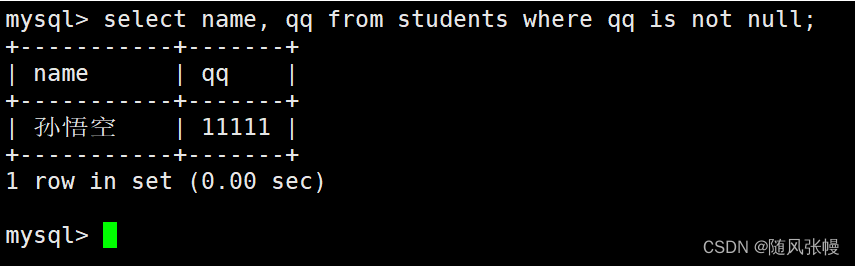
既知の QQ 番号を使用して学生に質問します。
where 句では、フィルター条件が QQ 番号が NULL ではないことであることを示し、select の列リストで、クエリする列が名前と QQ 番号であることを示します。次のように:
不明な QQ 番号を持つ生徒に質問します。
where句でフィルター条件がQQ番号がNULLであることを示し、selectの列リストでクエリする列を名前とQQ番号として指定します。次のように:
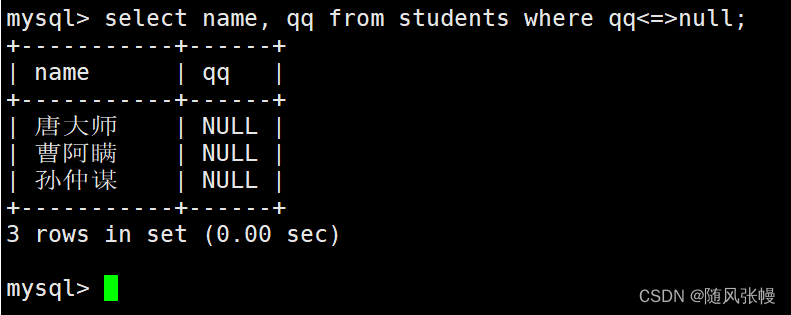
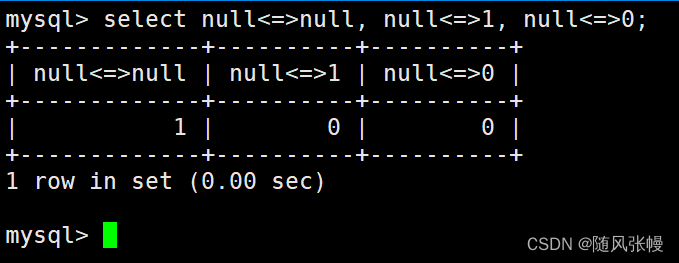
NULL 値と比較する場合は <=> 演算子を使用する必要があり、= 演算子では正しいクエリ結果が得られないことに注意してください。次のように:
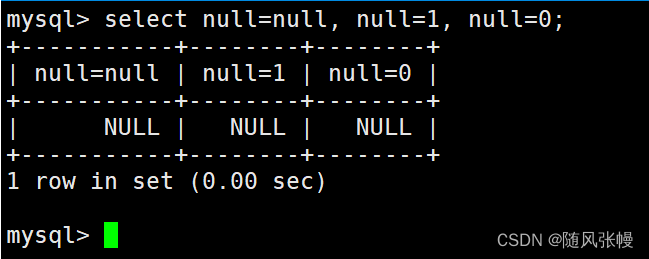
= 演算子は NULL に対して安全ではないため、
=この演算子を使用して任意の値を NULL と比較すると、NULL が返されます。次のように:
ただし、<=> 演算子は NULL セーフです。<=> 演算子を使用して NULL と NULL を比較すると TRUE (1) が返され、NULL 以外の値と NULL を比較すると FALSE (0) が返されます。次のように: