コラムディレクトリ: pytorch (画像分割UNet) クイック入門と実戦 - ゼロ、まえがき
pytorch クイック入門と実戦 - 1、知識の準備(要素の紹介)
pytorch クイック入門と実戦 - 2、深層学習の古典的なネットワーク開発
pytorch クイック導入と実際の戦闘 - 3、Unet による
pytorch の迅速な導入と実際の戦闘 - 4、ネットワークのトレーニングとテスト
上記pytorch クイックスタートと実戦の続き - 1. 知識の準備(要素の紹介) 2.4 章
ネットワークをモジュールに分割すると、4 層構造が大きすぎ、長さ自体も長すぎるため、書き込みや読み取りに不便になるからです。
チュートリアル モジュールは独立性が高く、異なる記事間や記事の異なるモジュール間であっても、どこからでも読むことができます。
幸せになる方法。とにかく、「なんだこれ?」から「ふふふ」までです。この部分
は、わからなくても読み飛ばせるので詳しくは記載しません。
ResNet と Unet を見るだけで済みます。
あるいは、Unet を見てください。
ディープラーニングクラシックネットワーク開発
参考: Xiaoqiang DL コラム記事の概要
機械学習をスキップしてコンピューター ビジョンを理解するには、次の参考資料を使用してください (画像処理を行うときは CV だけに注目する必要があります!) より重要な論文のいくつかを以下に説明します:
AlexNet、VGG、GoogLe-1 : Going Deeper with Convolutions、GoogLe-2: Batch Normalization、GoogLeNet-3、ResNet、FCN、UNet
(まずネットワークについて始めてから、これらを読むのに戻ってくることをお勧めします。たとえば、 ResNet を直接 kill して、UNet の構造を直接再現するだけです。実行してから、この開発プロセスを確認するために戻ってきます。 ) とにかく、画像の特徴を抽出するのはコンボリューション (隣接するピクセル値の分布) です。
1 アレックスネット
1.1 意義
マイルストーン。引き離す畳み込みニューラル ネットワークコンピューター ビジョンを支配するための序曲は、コンピューター ビジョンの応用も加速します。
1.2 構造
5 つの畳み込み層 + 3 つの全結合層
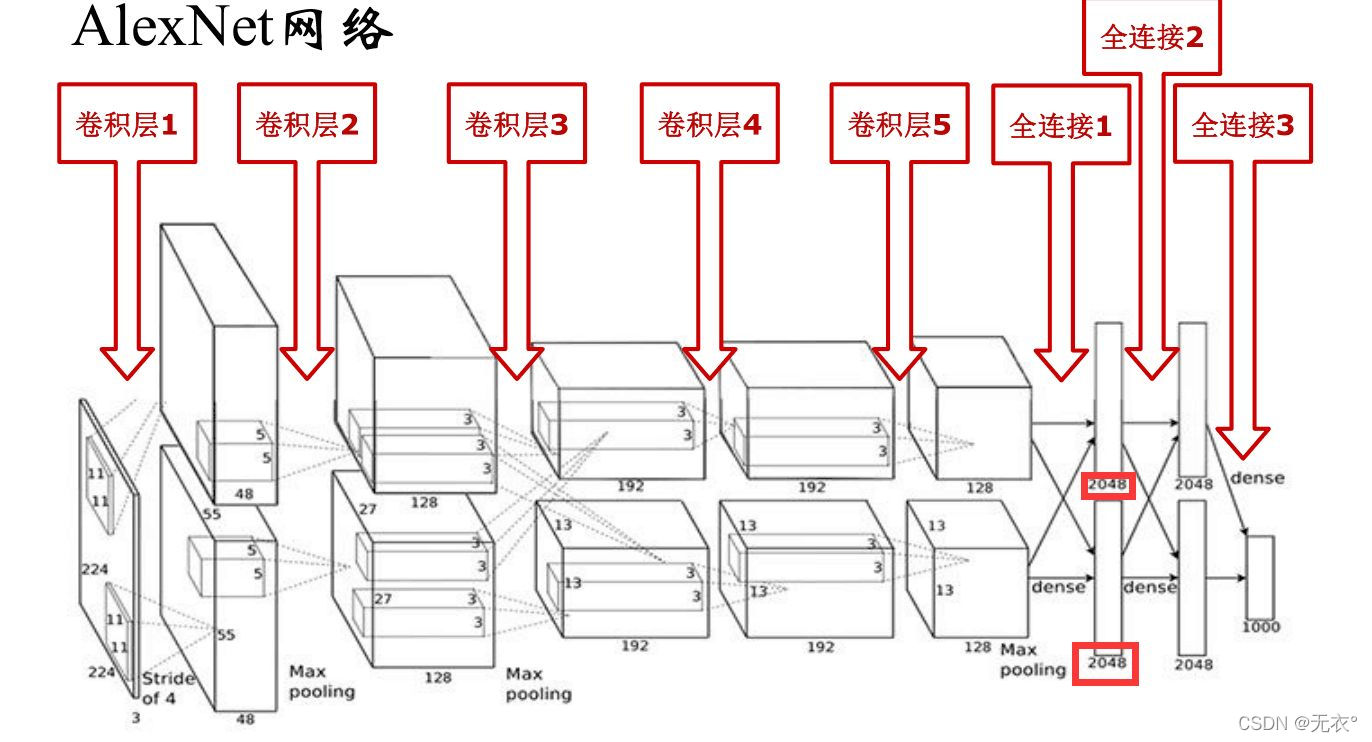
実装が簡単なネットワーク図は VGG の章に示されています。
参考:必読論文 AlexNet
2 VGG
2.1 意義
小さな畳み込みカーネルの時代を開きます。3*3 コンボリューション カーネルが主流のモデルになりました。さまざまな画像タスクのバックボーン ネットワーク構造として。
2.2 構造:
5*5 畳み込み層を 3*3 畳み込み層に置き換えます
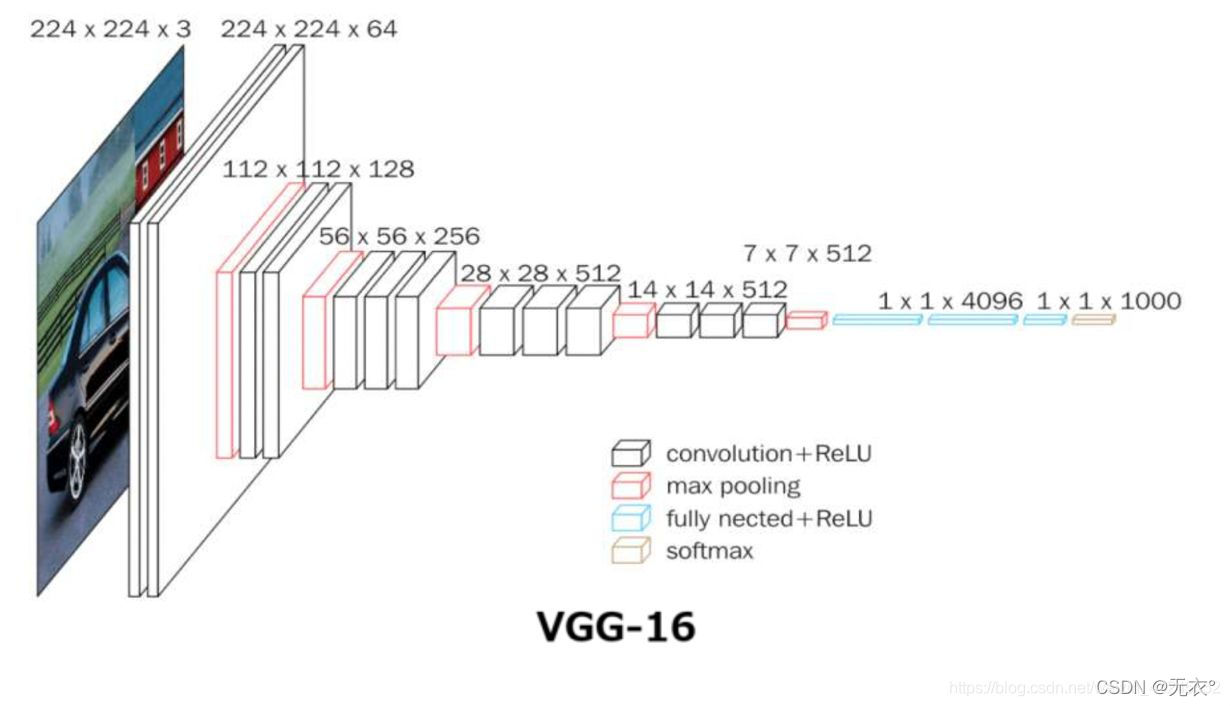
2.3 進化の過程:
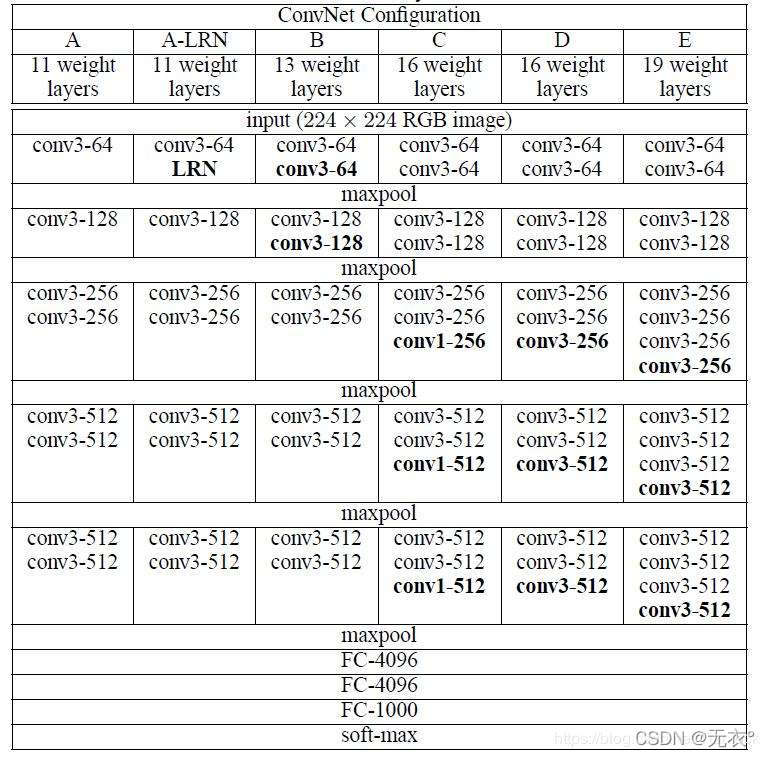
A: 11 層コンボリューション
A-LRN: A に基づいて LRN を追加 B
: コンボリューションを追加 1 番目と 2 番目のブロックに 3*3 コンボリューション
C: 3 番目、4 番目、5 番目のブロックにそれぞれ 1* を追加 1 コンボリューション、非線形性の追加がインデックスの向上に有益であることを示します。
D: 3 番目、4 番目、および 5 番目のブロックの 1*1 畳み込みが
3*3 に置き換えられます。 E: 3 番目、4 番目、および 5 番目のブロックにそれぞれ 3 *3 が追加されます。畳み込み
その中で、AlexNet と VGG16 および 19 の実現ネットワーク図 (下から上):
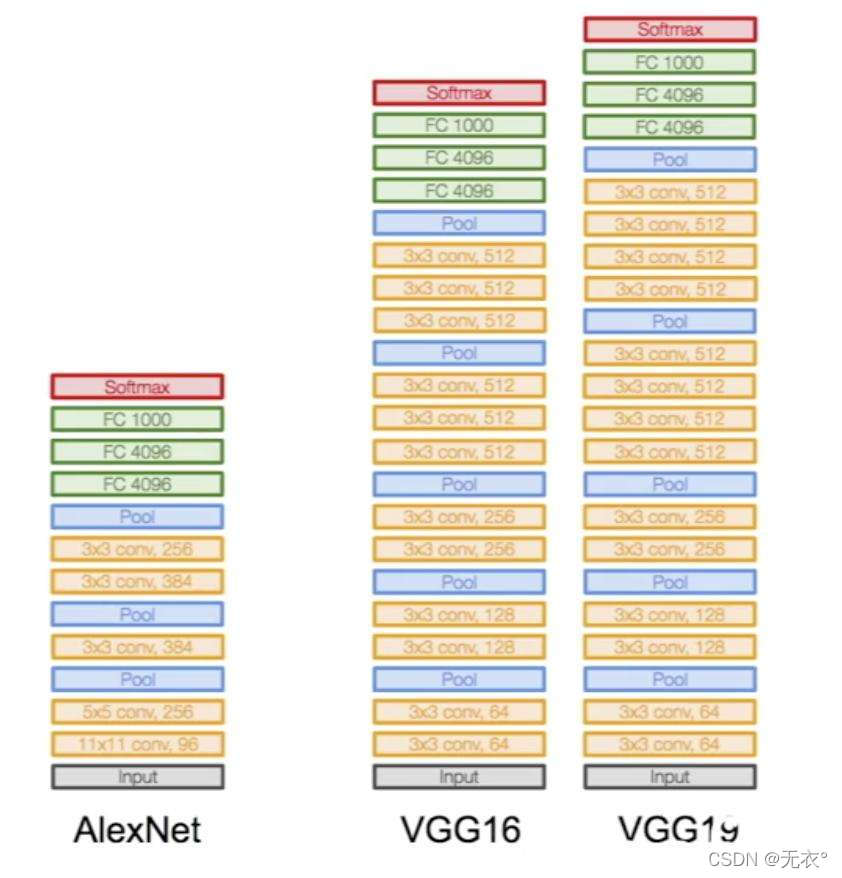
2.4 特徴
受容野を高めるには、2 つの 3*3 スタックは 1 つの 5*5 に相当し、3 つの 3*3 スタックは 1 つの 7*7 に相当します。
等価性の理由は自分で導き出すか、上記の記事を参照して導き出します。
参考:必読論文VGG
3 グーグルネット
2014年にもVGGとタッグを組んでチャンピオンシップを獲得した。
- 1x1 畳み込みを使用して次元を削減します。1
*1 畳み込みを使用する最初の畳み込みニューラル ネットワークでは、完全に接続された層が破棄され、ネットワーク パラメーターが大幅に削減されます。これは、1*1 畳み込みの広範な応用への序章を開きました。- 複数のスケールで同時に畳み込み再集計。マルチスケール畳み込みの時代を開きます。
参考:
Going Deeper with Convolutions
GoogLeNet 構造の深い理解
4 GoogLe Net 2 (BN ネットワーク層)
前回の記事で触れたBN層です。
4.1 重要性
- ディープラーニングの開発を加速
- ニューラル ネットワーク設計の新時代を切り開き、正規化層がディープ ニューラル ネットワークの標準構成になりました
4.2 利点
- より大きな学習率を使用して、モデルの収束を高速化できます。
- 重みの初期化を慎重に設計する必要はありません
- ドロップアウトなし、またはドロップアウトが小さい場合も可能
- L2以下のウェイトディケイは使用できません
- LRN(ローカル応答正規化)を使用できます
また、バッチ正規化の研究ノートには次のように書かれています。
(1) 比較的大きな初期学習率を選択して、トレーニング速度を急上昇させることができます。以前は、学習率をゆっくりと調整する必要があり、ネットワークの学習が途中であっても、学習率をさらにどの程度下げるかを検討する必要がありましたが、現在は初期学習率を大きく設定し、その後学習率を下げることができます。このアルゴリズムは非常に早く収束するため、学習速度も優れています。
もちろん、より小さい学習率を選択した場合でも、このアルゴリズムは高速トレーニング収束の特性を備えているため、以前のアルゴリズムよりも速く収束します (2)ドロップアウトと L2 正則化のパラメーターを心配する必要がなくなりました過学習における選択問題では、BN アルゴリズムを使用した後、これら 2 つのパラメータを削除するか、BN にはネットワークの汎化能力を向上させる特性があるため、より小さい L2 通常制約パラメータを選択することができます (3) 必要がなくなりました。 BN 自体が正規化されたネットワーク層であるため
、部分応答正規化層が使用されます (部分応答正規化は、視覚的推定によく知られている Alexnet ネットワークで使用される方法です)、(4) トレーニング データは完全に処理でき
ますカオス (トレーニングの各バッチ中に特定のサンプルが頻繁に選択されるのを防ぐため、文献にはこれにより精度が 1% 向上すると書かれていますが、私もこの文には困惑しています)。
参考:
バッチ正規化: 内部共変量シフトを低減することでディープ ネットワーク トレーニングを加速する
5 GoogleNet-V3
よく見ずに、ただここに持ってきただけです
コンピューター ビジョンのインセプション アーキテクチャを再考する
5.1 VGG と Google V1 および V2 の概要
VGG ネットワーク モデルは大規模で、多くのパラメーターと大量の計算が必要なため、実際のシナリオには適していません。
GoogLeNet-V1 は、マルチスケール コンボリューション カーネル、1*1 コンボリューション演算を使用します。
GoogLeNet-V2 に基づいて、BN 層が追加され、5*5 畳み込みが 2 つの 3*3 畳み込みスタックに完全に置き換えられて、モデルのパフォーマンスがさらに向上しました。
5.2 V2との比較
- RMSProp 最適化メソッドの使用
- ラベル スムージング正則化メソッドの使用
- 非対称畳み込みを使用して 17*17 特徴マップを抽出する
- BN での補助分類の使用
5.3 革新のポイント
キーポイントとイノベーションポイント
• 非対称畳み込み分解: パラメータの計算量を削減し、畳み込み構造設計に新しいアイデアを提供します。
• 効率的な特徴マップ降下戦略: stride=2 の畳み込みとプーリングを使用して、情報表現のボトルネックを回避します。
• ラベル スムージング: ネットワークの過信を回避し、過剰適合を軽減します。
6レスネット
ようやく ResNet にたどり着きましたが、実はこれまで ResNet と UNet しか読んでいませんでした。以前のネットワークは記事を書くときにしか読んでいませんでした。
6.1 重要性
現代の畳み込みニューラル ネットワークの開発史における新たなマイルストーンマイルストーン、千層ネットワークを突破し、層ホッピング接続が標準構成になりました。
個人的な理解:松葉杖!
すべてのネットワークと同じサポートをサポートできるため、ディープ ラーニングはその名にふさわしいものになります。BN
レイヤーと同様に、他のネットワークの効果を強化できます。個人的には、BN レイヤーは物事を正しく設定する方法であると理解しています。何ができるのかトレーニング中に分布が歪んでいる場合は、標準化によって修正されます。
6.2 背景
CNN ネットワークでは、入力されるのは画像の行列であり、これが最も基本的な特徴でもあり、CNN ネットワーク全体が情報抽出のプロセスであり、基礎的な特徴から高度に抽象化された特徴まで段階的に抽出されます。ネットワークが深くなるほど、抽出できるさまざまなレベルの抽象的な特徴がより豊富になり、ネットワークが深くなるほど、抽出された特徴はより抽象的になり、より多くの意味情報が得られます。
したがって、一般に、より高いレベルの機能を取得するために、より深いネットワーク構造を使用する傾向があります。
6.3 問題と分析
しかし、より深いネットワークが常に良い結果につながるとは限りません。
ネットワークの深さが増すにつれて、ネットワークの精度は飽和するか、低下することさえあります。56 層のネットワークは 20 層のネットワークよりもさらに劣ります。トレーニング誤差は 56 層ネットワークでも同様に高いため、これは過学習の問題ではありません。
また、過学習に対する解決策は数多くあります。たとえば、データ拡張、ドロップアウト (枝刈り)、正則化などです。
ディープネットワークは過学習に加えて、勾配消失や勾配爆発の問題も引き起こしますが、この問題もBN層で解決できます。また、一般的に使用される活性化関数 ReLu を使用すると、微分部分は常に正の数で 1 に等しく、つまり勾配は変化しないため、勾配が消滅したり爆発したりすることはありません。
BN層が追加されたとしても、非線形活性化関数Reluの存在により、各入力から出力までのプロセスはほぼ不可逆的であり、これにより多くの不可逆的な情報損失が発生し、ディープネットワークには依然として劣化の問題が発生します。 (劣化の問題)。
この理由としては、確率的勾配降下法では大域的な最適解ではなく、局所的な最適解が得られることが多いことも考えられますが、深層ネットワークの構造はより複雑であるため、勾配降下法アルゴリズムは局所的な最適解を得る可能性があります。より大きくなります。
6.4 解決策
劣化の問題を解決するには、ネットワークを深くする際に、深いネットワークのパフォーマンスが浅いネットワークのパフォーマンスと少なくとも同等であることを保証する必要があります。つまり、恒等マップは次のようになります。
浅いネットワークがあり、新しい層を上に積み重ねて深いネットワークを構築したいのですが、極端な例では、追加された層は何も学習せず、浅いネットワークの特性をコピーするだけです。 ID マッピング。この場合、深いネットワークは少なくとも浅いネットワークと同等のパフォーマンスを発揮し、劣化は見られないはずです。
6.5 解決策
これに基づいて、He 博士は残差学習のアイデアを提案しました。
深いネットワークの最後の数層が恒等マップ h(x)=x に学習されると、モデルは浅いネットワークに縮退します。しかし、このアイデンティティ マッピングを直接学習することは非常に難しいため、別の方法でネットワークは次のように設計されます: H
(x)=F(x)+x => F(x)=H(x)-x
F(x)=0 は恒等マップ H(x) = x を構成します。ここで、F(x) は残差です。
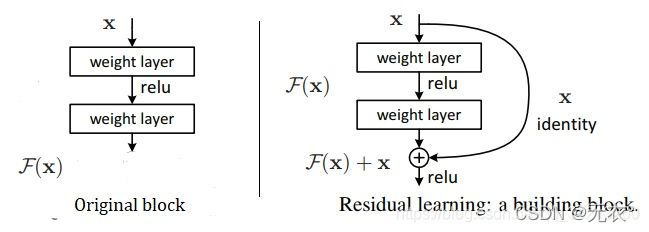
Resnet は、劣化問題を解決する 2 つの方法、アイデンティティ マッピングと残差マッピングを提供します。恒等マッピングは図の「曲線」部分を指し、残差マッピングは曲線以外の残りの部分を指します。F(x) は加算前のネットワーク マップ、H(x) は入力から加算までのネットワーク マップです。
実際、元の画像と比較すると、アイデンティティ マップが追加されています。
著者はブログでそのような例を示しました: g(x) と h(x) というネットワーク パラメータ マッピングがあるとします。ここでは 5 を 5.1 にマッピングし、g(5)=5.1 にして、残差マッピングを導入します。 H(5 )=5.1 = F(5)+5 => F(5)=0.1 。残差を導入するマッピングは、出力の変化に対してより敏感です。たとえば、出力が 5.1 から 5.2 に変更されると、マッピング g(x) の出力は 1/51=2% 増加します。残差構造の出力では、マッピング F(x) が 0.1 から 0.2 に 100% 増加しました。当然、後者の出力変化の方がウェイト調整に与える影響が大きいため、効果はより優れています。
この残差学習構造は、フォワード ニューラル ネットワーク + ショートカット リンクを通じて実装されます。ショートカット リンクは、追加のパラメーターを生成せず、計算の複雑さを増加させることなく、同じマッピングを単に実行することと同等です。ネットワーク全体は、エンドツーエンドのバックプロパゲーションを通じて引き続きトレーニングできます。
ショートカット接続の導入により、ネットワーク情報が効果的に拡散し、勾配逆伝播がスムーズになるため、数千層の畳み込みニューラル ネットワークが収束できます。

図に示すように: 残差ネットワークは H(x)=F(x)+x として表現できます。これは、入力 x に対する出力 H(x) の逆数 (勾配)、つまりバックプロパゲーション中のことを示しています。 、H'(x)=F'(x)+1、残差構造の定数 1 により、勾配の計算時に勾配が消失しないことも保証できます。
6.6 ネットワーク構造:
残差は入力と出力を組み換えたもので、出力が入力から大きく外れないようになっていると思います。実際、この考えを理解するのは問題ありません。
6.7 実装の詳細
ResNet の一部のジャンパー ラインは実線であり、一部のジャンパー ラインは破線です。
点線は、これらのモジュールの前後の次元が一致していないことを表しています。これは、残留構造が除去されたプレーン ネットワークは依然として VGG と同じであるためです。つまり、ダウンサンプリングは n 層ごとに実行されますが、深さは 2 倍になります (VGG は ResNet をダウンサンプリングします)。畳み込みによるプーリング層)。
深さが一致しない場合、1×1畳み込み層を追加してジャンプ処理の際に次元を増やす方法と、直接ゼロを埋めて(最初にダウンサンプリング)深さを深くする方法の2つの解決策があります
。の場合、ニューラル ネットワークはまず 1×1 畳み込みを使用して入力 256 次元を 64 次元に削減し、次に 1×1 を通じてそれを復元します。この目的は、パラメータと計算の量を減らすことです。
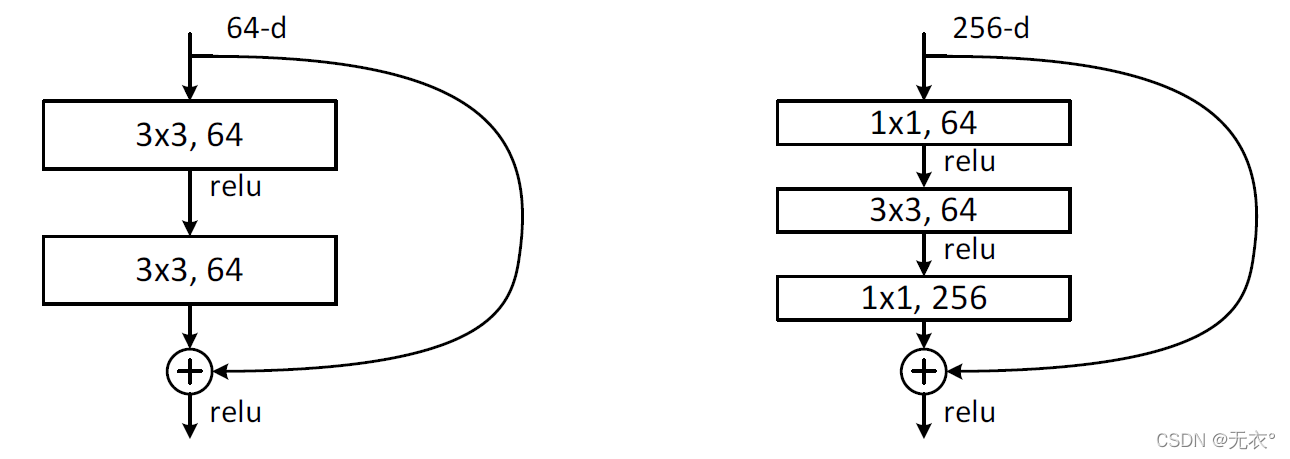
2 つの構造はそれぞれ ResNet34 (左の図) と ResNet50/101/152 (右の図) を対象としており、その主な目的はパラメータの数を減らすことです。
左の図は 2 つの 3x3x256 畳み込み、パラメータ数: 3x3x256x256x2 = 1179648、
右の図は 256 次元のチャネルを 64 次元に削減するための最初の 1x1 畳み込みで、最後に 1x1 畳み込みを通じて復元します。パラメータは使用されています。全体の数値: 1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632.
右の図のパラメータの数は、左の図の 16.94 分の 1 です。したがって、右の図の主な目的は、パラメータの数を削減することです。計算量の削減。
左の画像のパラメータを計算するとき、チャネル数が 256 であると想定されているため、64 ではなく 256 が乗算されることに注意してください。これは、左チャネルが低チャネルに使用され、右チャネルが低チャネルに使用されるためです。ハイチャンネル。
CNN モデルを知っておく必要があります: ResNet
画像処理必読の論文 6 ResNet
深層学習 16 - 残差ネットワーク (ResNet)
CVPR2016: ResNet は深層ネットワークの劣化の問題を根本的に解決します
7 FCN
(なぜネットワーク構造図を載せないのかは聞かないでください。これは UNet への道を開くだけではないでしょうか) Unet を見てください。
CNN は画像レベルの認識、つまり画像から結果までの認識です。
FCN はピクセル レベルの認識であり、入力画像上の各ピクセルがどのカテゴリに属する可能性が最も高いかをマークします。
7.1 背景
画像の AlexNet から始まる CNN 畳み込みネットワーク分類と位置基本的に、2010 年に Li Feifei らによって設立された ImageNet Large Scale Visual Recognition Challenge (ILSVRC: Large-Scale Image Recognition Challenge) の背景の下で、タスクでは良い結果が得られています。
コンペティション項目には、画像分類 (分類)、オブジェクト位置特定 (オブジェクト位置特定)、オブジェクト検出 (オブジェクト検出)、ビデオオブジェクト検出 (ビデオからのオブジェクト検出)、シーン分類 (シーン分類)、シーン分析 (シーン解析) が含まれます
。 NLP (自然言語理解) 分野のセマンティック セグメンテーションや CV (コンピューター ビジョン) 分野の画像セグメンテーションなど、深層学習の応用範囲の拡大は、本来の CNN では解決できません。VGG や Resnet などの一般的な分類 CNN ネットワークの場合、ネットワークの最後にいくつかの全結合層が追加され、ソフトマックスの後にカテゴリ確率情報を取得できます。ただし、この確率情報は 1 次元です。つまり、画像全体のカテゴリのみを識別でき、各ピクセルのカテゴリは識別できないため、この全結合方法は画像セグメンテーションには適していません。
Fully Convolution Network ( Fully Convolution Network、FCN ) は、次のいくつかの完全な接続を畳み込みに置き換えて 2 次元の特徴マップを取得し、続いてソフトマックスを使用して各ピクセルの分類情報を取得できることを提案しています。セグメンテーションの問題を解決します。
7.2 技術的な実現:
この 3 つの点(またはいくつかの概念と理由)については、Unet を読んでよく理解できない場合は、Unet を読んだ後にこの点に戻ることをお勧めします。Unet はこれらを完全に反映しています。ここでの説明が冗長で煩雑だと思われる場合は。
- 完全な畳み込み
全結合層 (fc) を持たない完全畳み込み (full conv) ネットワーク。
従来の CNN の最後の完全接続層を畳み込み層に置き換えます。
- あらゆるサイズの入力と出力に適応可能 (サイズとチャネルは、コンボリューション カーネル、パディング、ストライドを変更することで変更できます)
- デコンボリューション (デコンボリューション)
以前の内挿アップサンプリング (Interpolation) を使用する代わりに、新しいアップサンプリング方法、つまりデコンボリューション (Deconvolution) が提案されています。デコンボリューションは、畳み込み演算の逆演算として理解できます。デコンボリューションは、畳み込み演算によって生じた値の損失を回復することはできません。畳み込みプロセスのステップを 1 回だけ逆にするだけであるため、転置畳み込みとも呼ばれます。
- デコンボリューションを使用すると、優れた結果を出力できます (コンボリューションの重みはすべてバックプロパゲーションに参加できます)。
個人的には、デコンボリューションという名前はあまり良くないと思いますが、転置コンボリューションは非常に適切だと思います。実際、転置畳み込みは依然として畳み込みの一種であり、異なるパラメータを使用した単なる畳み込みです。したがって、pytorch の関数名も transpose2d になります。
この違いをどう説明するかを考えてみましょう。ストライド(デコンボリューションのステップ サイズは常に 1 であり、そのパラメータ stride はステップ サイズを示しません)
一般的なコンボリューションのパラメータ stride =n はステップ サイズが n であることを意味し、
転置コンボリューションのパラメータ stride=n は各ステップ間の補間を意味します。 2 ピクセル n-1 の場合、ステップ サイズはどうでしょうか? は常に 1 です。OK、例を見てください。
パラメータ stride=1 の場合、デコンボリューションはコンボリューションと変わりません。
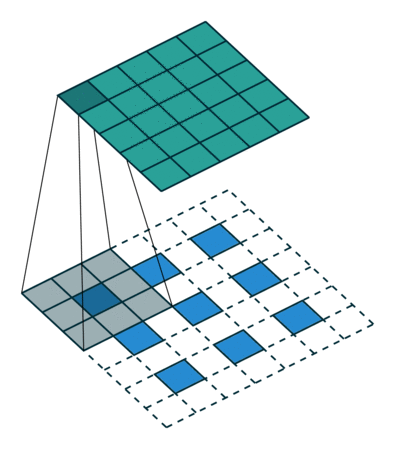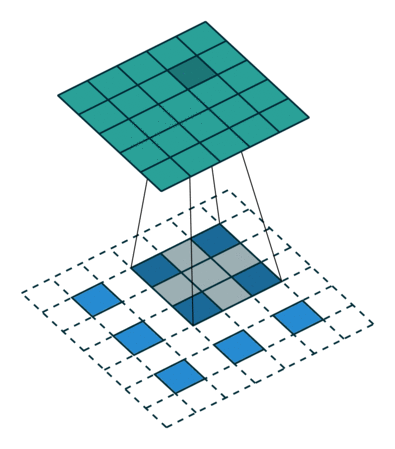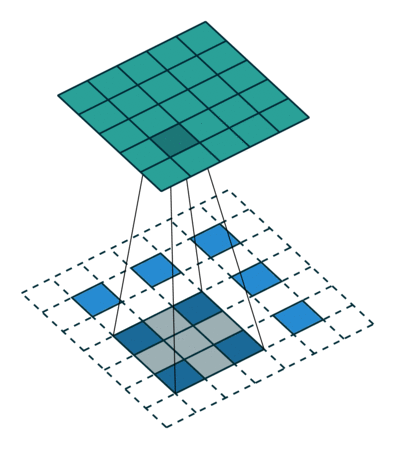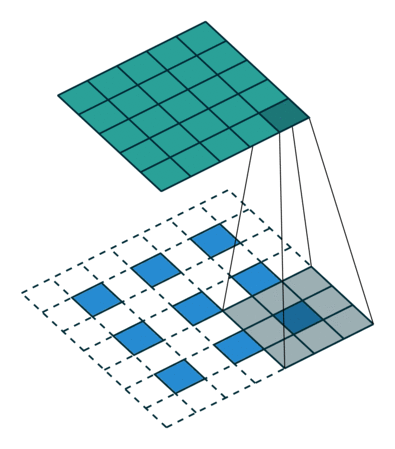
以下に示すようにデコンボリューションします: 青の入力 = 2x2、移動灰色の kernels_size = 3x3、エッジの白のパディング = 2、ストライド = 1、この時点で緑の出力は 4x4 です
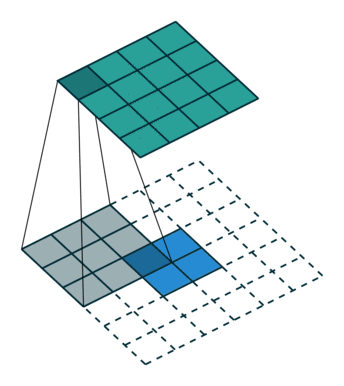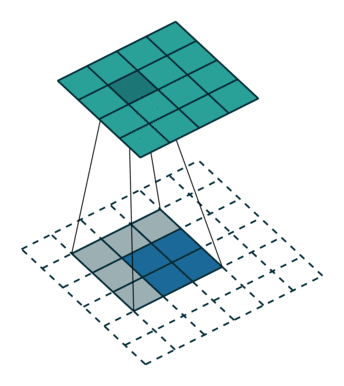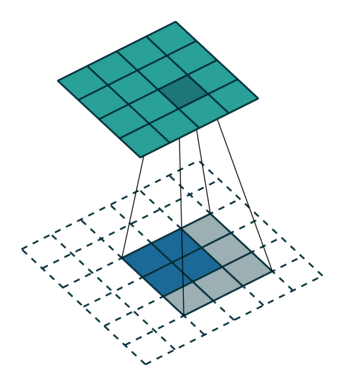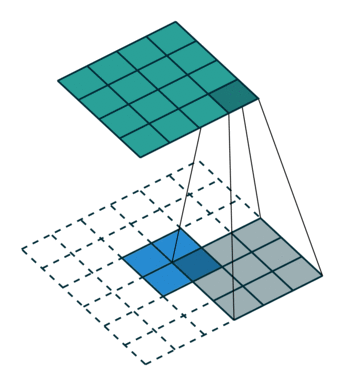
。=1の場合はどうなるでしょうか? 先ほども言いましたが、途中にいくつか入れるということです。
以下に示すようにデコンボリューションします: input=3x3、kernels_size=3x3、padding=1、stride=? 図に示すように、緑の出力 = 5x5の答えは 2 です。青の入力の 2 ピクセルごとに白いピクセルが挿入されるため、パラメーター stride=1+1=2 になります。カーネルの動きの
ステップ サイズは常に次のとおりです。
1.
- ジャンプレイヤー構造(Skip Layer)
異なる深さの特徴の組み合わせが、前部と後部の特徴マップの補正になります。
(私の理解: 現実に近づき、逸脱しないように常にネットワークに思い出させてください) 残差と同様に、この段階ではあまり考えすぎないでください。
- ネットワークの堅牢性と精度を向上させることができます。
参考:
画像のセグメンテーション: セマンティック セグメンテーションにおけるフル畳み込みネットワーク (FCN)
FCN の学習と理解
フル畳み込みネットワーク (FCN) の詳細な説明
7.3 歴史的重要性:
• セマンティック セグメンテーションの分野における先駆的な研究
• エンドツーエンドのトレーニングにより、その後のセマンティック セグメンテーション アルゴリズムの開発への道が開かれた
7.4 その他の関連概念
7.4.1 地域情報
- 抽出場所:浅いネットワークでローカル情報を抽出
- 特徴:物体の幾何学的情報が比較的豊富で、対応する受容野が小さい
- 目的: より小さいサイズのターゲットをセグメント化するのに役立ち、セグメント化の精度を向上させるのに役立ちます。
7.4.2 グローバル情報
- 抽出位置:ディープネットワークでグローバル情報を抽出
- 特徴:物体の空間情報が比較的豊富で、対応する受容野が比較的大きい
- 目的: より大きなターゲットをセグメント化するのに役立ち、セグメント化の精度が向上します。
7.4.3 受容野
畳み込みニューラルネットワークでは、ある層の出力結果の要素に対応する入力層の領域サイズが決まり、これを受容野と呼びます。
一般に、受容野が大きい場合の効果は、受容野が小さい場合よりも優れています。
この式から、歩幅が大きいほど受容野が大きくなることがわかります。ただし、ストライドが大きすぎると、特徴マップに保持される情報が少なくなります。
したがって、歩幅を小さくする場合、いかにして受容野を拡大するか、あるいは受容野を変化させずに維持するかがセグメンテーションにおける大きな問題となる。
7.4.4 エンドツーエンド
コンピュータビジョンの分野では、エンドツーエンドは、入力が元の画像、出力が予測画像で、途中の具体的な処理はアルゴリズム自体の学習能力に依存すると単純に理解できます。
ネットワークの内部構造を通じて、元の画像が次元削減と特徴抽出、その後のプロセスで、より小さいサイズの特徴マップが徐々に作成されます。元の画像と同じサイズの予測画像に戻します。
特徴抽出の品質は最終的な予測結果に直接影響しますが、エンドツーエンドネットワークの最も重要な特徴は、人間の介入なしに設計されたアルゴリズムに従って特徴を学習することです。
次元削減と特徴抽出のプロセスは、ダウンサンプリング、サイズを復元するプロセスは次のとおりです。アップサンプリング。
Unetを見ればすぐにわかります。
8Uネット
8.1 研究結果と意義:
- 高速、512*512 の画像の場合、GPU の使用にかかる時間はわずか 1 秒未満です
- これは、ほとんどの医療画像セマンティック セグメンテーション タスクのベースラインとなっており、また、多くの研究者に U 字型セマンティック セグメンテーション ネットワークについて考えるきっかけを与えました。
- U-Net は、低解像度情報 (オブジェクト カテゴリ認識の基礎を提供) と高解像度情報 (正確なセグメンテーションと位置決めの基礎を提供) を組み合わせており、医療画像のセグメンテーションに最適です。
基本的に、すべてのセグメンテーション問題について、U-Net を使用して最初に基本的な結果を確認し、次に「魔法の変更」を加えることができます。
8.2ネットワーク構造
最初に構造図を載せておきます。Baidu が見つけた図は、公式図よりも香りがよいように感じます。これは主に、分類との比較があり、初心者にとってより優しいためです。
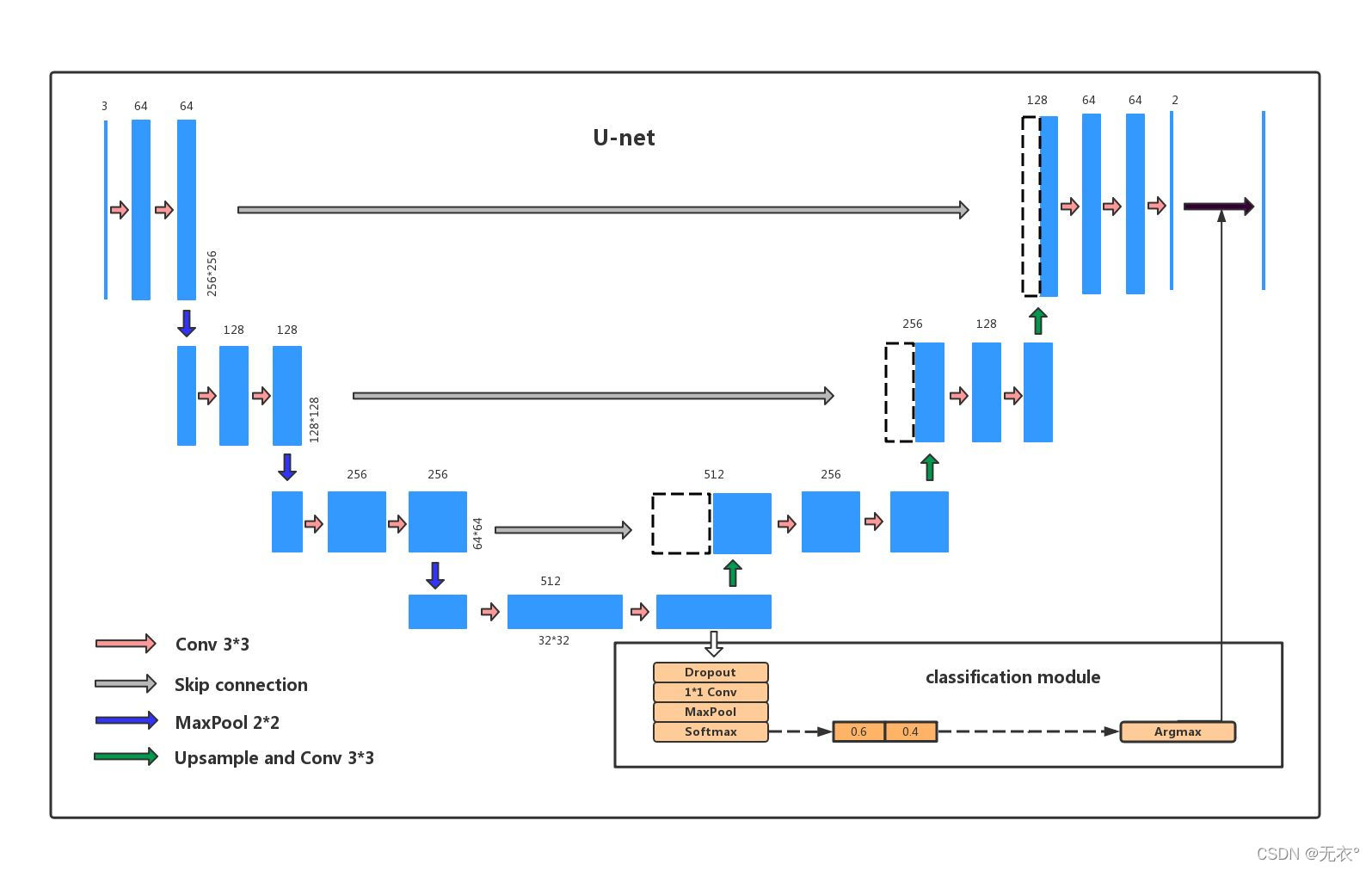
この図についてお話しますと、右下の四角で囲った部分が分類モデルの構造図ですが、U-netにはこの部分は含まれておらず、違いを示すためにのみ公開されています。
Zhihu @陈义新から借りて、この写真を簡単に説明しましょう。
エンコーダの左半分:
2 つの 3x3 畳み込み層 (RELU) と、ダウンサンプリング モジュールを形成する 2x2 最大プーリング層で構成され (背後のコードでわかるように)、デコーダの右半分: アップサンプリング畳み込み層で構成され
ます
。 (デコンボリューション層) + 特徴スプライシング concat + 2 つの 3x3 畳み込み層 (ReLU) が繰り返し形成されます。
OK、解析を開始します。
- まず全体としてはコの字型の対称構造になっています。逆アセンブル後は FCN と同じ構造概念を持ち、
左がダウンサンプリング (エンコード Encoder)、右がアップサンプリング (デコード Decoder) です。
分解して見る前に、3*3畳み込み層 Conv+活性化関数 ReLu+Bn層全体をブロックと呼びます
- 最上層から始めて、左側の青い四角形が入力で、2 ブロック後に出力 (チャネル = 64 の四角形) が取得されます。次に、下に進み、2*2 の最大プーリング maxpool (つまり、Pick out) を確認します。 2*2 の四角形の最大値を 2*2 が 1 つの数字になり、サイズの縦横が半分になるようにして次の層に進みます。ブロック+最大プール。
[上の図は 3 つのダウンサンプリング、合計 4 つのレイヤーです。Unet の原文はダウンサンプリングが 4 回、合計 5 層になっていますが、これは修正されておらず、無害です。】 - 最下層までループした後、ダウンサンプリングが終了し、アップサンプリングの準備が整います。
- 構造に示されているアップサンプリングは、ブロック+デコンボリューション(FCNではデコンボリューション処理といいますが、アップサンプリングは最大プーリングではなくデコンボリューションです)。
3 回アップサンプリングして、元の入力サイズと同じ出力を取得します。 - 終了!
- 注目に値するのは、の左側と右側を灰色の線で結んでいますが、この線はUnetの原文ではコピーとクロップと呼ばれるスキップ接続です。実際、これは残りのアイデアです。左側の出力と下の出力を組み合わせます。ステッチ右側のレイヤーへの入力として入力します。
もう少し詳しく説明します。FCN
のデコーダは比較的単純で、デコンボリューション操作が 1 つだけ使用され、コンボリューション構造に追いつきません。
スキップ接続の場合、FCN は加算を使用し、U-Net は連結を使用します。
この記事を理解するには、追加操作と連結操作については、「ディープ機能融合 - 追加と連結のマルチレイヤー機能融合について」を参照してください。
8.3 モジュール機能
- 畳み込み (Conv) は特徴抽出に使用されます。
- プーリング (maxpool) は次元を削減するために使用されます。
- スプライシング (スキップ接続) は機能の融合に使用されます。[つまり、チャネルが機能です]
- アップサンプリング (Upsample) は次元を復元するために使用されます。
より大きな観点から見ると:
- ダウンサンプリング (エンコーディング エンコーダー): モデルは画像の内容を理解しますが、画像の位置情報を破棄します。
- アップサンプリング (デコーダーのデコード): エンコーダーによる画像コンテンツの理解とモデルを組み合わせて、画像の位置情報を復元します。
次に、さまざまなレイヤーの違いがわかります。
- 浅い層は主に幾何学的な情報であり、画像の内容と、小さな視野 (つまり、猫の目の色など、拡大したときに見えるもの) が表示されます。
- 深い層は主に位置情報であり、画像の位置は何か、表示されているのは大きな視野(つまり、ズームアウトしたときに何が見えるか、写真のどこに猫がいるかなど)です。
8.4 コードの実装
ふふ、ようやくここまでたどり着きましたが……でも、まだまだ細かいことはたくさんあります。単一の記事を開いて、一緒に作業しましょう。
Pytorch のクイック スタートと実際の戦闘 - 3、Unet の実装