前回のブログ投稿では、 Transformer のコア コンポーネントであるMultiHeadAttendant マルチヘッド アテンション メカニズムに焦点を当てましたが、この記事では引き続き Transformer の原理を紹介します。次の図はトランスフォーマーの構造図であり、主に位置エンコーディング、複数セットのエンコーダー、および複数セットのデコーダーで構成されます。以下に 3 つの部分を取り上げます。
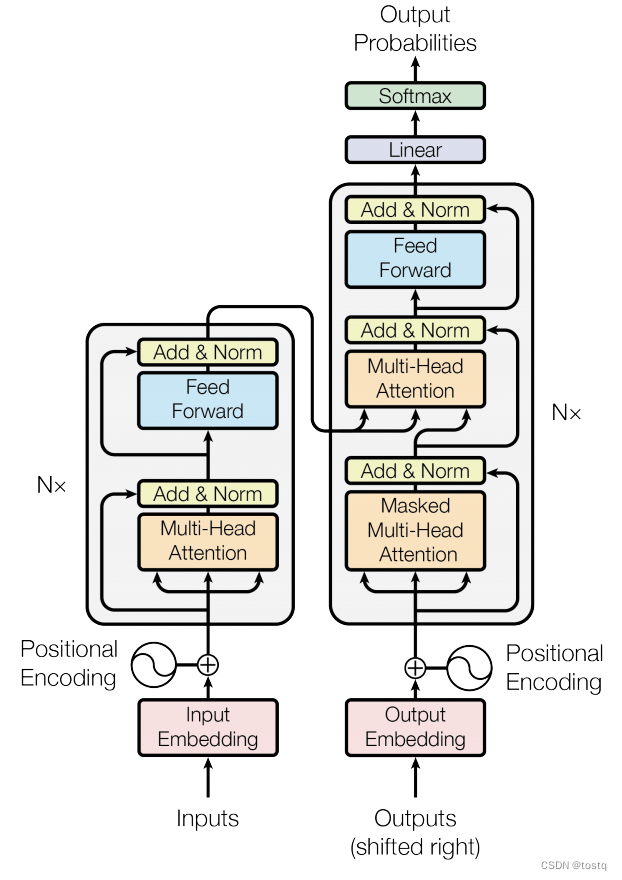
1. 位置エンコーディング
アテンションの問題の 1 つは、シーケンス内の各単語の位置情報が保持されないこと、またはシーケンス内の各単語の順序が交換された後、最終的な出力にほとんど影響を与えないことです。アテンションの入力部分として使用され、Transformer で指定されます。位置エンコード方法は、元の単語ベクトルに位置エンコード ベクトルを重ね合わせるものです。
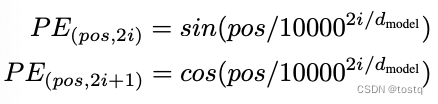
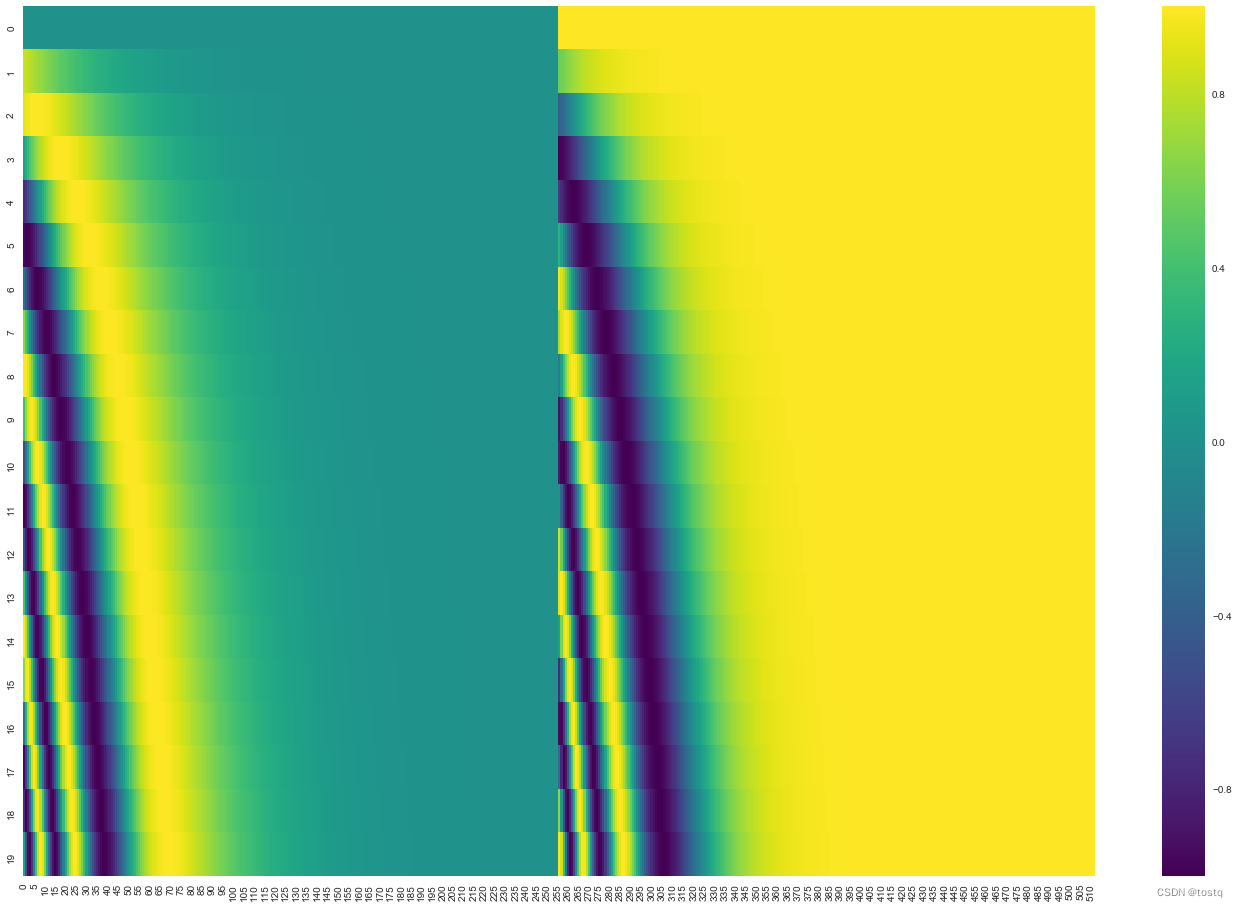
上の式は位置エンコード ベクトルを計算するために使用されます。pos はシーケンス [1,2,3,4...] 内の単語の位置を示します。i は位置エンコード ベクトル内の位置を示し、縦軸は下図は 0 から 19 までの位置を示します。 512 次元の位置エンコード ベクトル。位置エンコード ベクトルは、注目の入力として入力埋め込みベクトルと重畳されます。
2. エンコーダー
エンコーダ コンポーネントでは、マルチヘッド アテンション モジュールの後に、2 つの剰余演算と LayerNorm 演算があります。これら 2 つのモジュールは、モデルの収束を向上させるために使用される一般的な手段です。さらに、アテンションでは、クエリとキーの計算にドット積が使用されます類似性スコアが の場合、要件はゼロ平均と単位分散を満たす必要があるため、LayerNorm は保証の役割も果たします。
もう 1 つのコンポーネントは、フォワード ネットワーク Position-wise Feed-Forward Networks です。これは、実際には 2 層の完全に接続されたネットワークです。
しかし、違いは位置に関するものです。つまり、シーケンス内の各単語ベクトルは完全に接続されたネットワークの 2 つの層を通過するため、シーケンス内の各位置の単語ベクトルは順方向ネットワークを共有するため、FFN ネットワークは基本的に単語を追加します。ベクトル自体の表現は単語ベクトル間の関連情報を学習するものではなく、この部分はアテンションによって行われます。
3. デコーダ
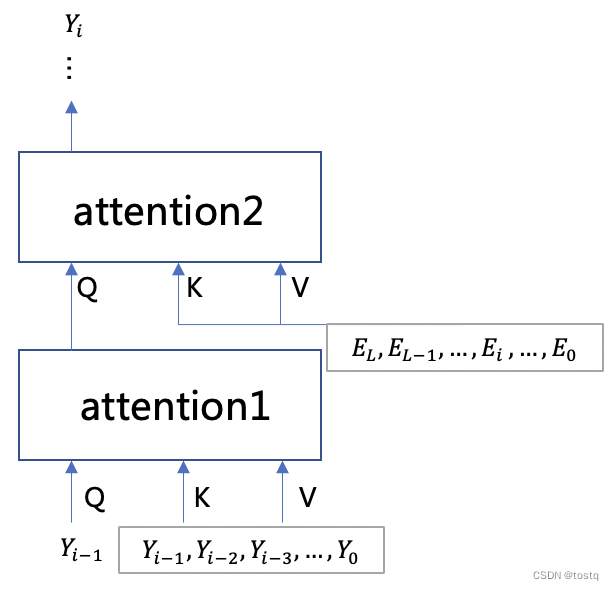
デコーダとエンコーダの唯一の違いは、セルフ アテンション コンポーネントの追加セットがあることです。次の図は、デコーダの 2 セットのセルフ アテンション コンポーネントの入力を示しています。最初のセットのセルフ アテンション コンポーネントのクエリは、注目コンポーネントは前の単語であり、そのキーと値は現在生成されている単語シーケンスであり、主に出力シーケンス自体との関係を確立するために使用され、その出力は注目コンポーネントの 2 番目のグループに含まれます。エンコーダの出力との関係を確立する 全体の構造 RNN と類似点があります。
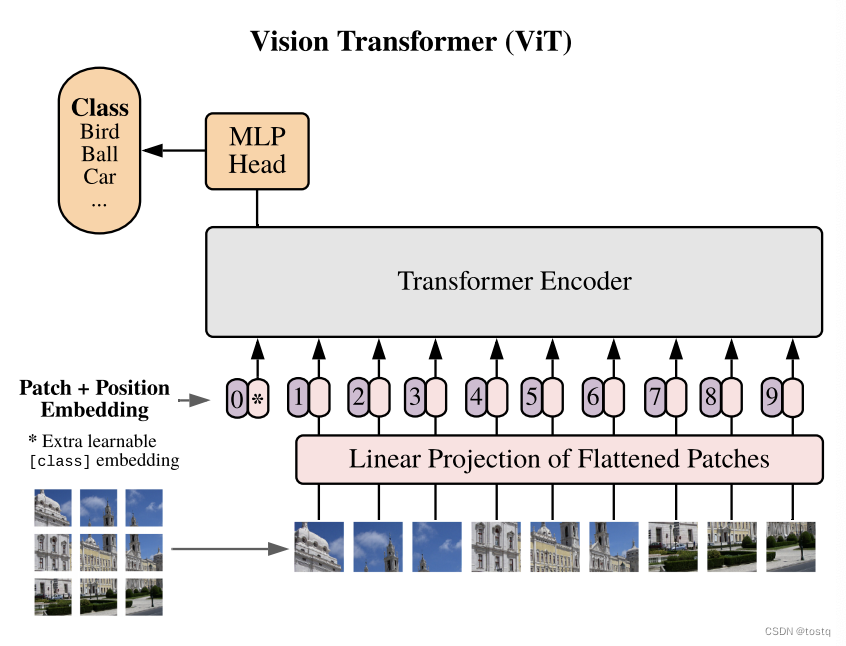
4. アプリケーション
Transformer は主に、機械翻訳、テキスト生成、ダイアログ生成などのシーケンス変換に使用されます。感情分析などのいくつかのシーケンス分類タスクは、Encoder モジュール + 線形レイヤーを適用することで完了できます。また, 近年, 画像処理の分野では Transformer の構造に基づいた研究が多く行われています. たとえば,本稿では Transformer を画像分類に適用します. 原理は画像を 16x16 のパッチに分割することです. 、パッチをベクトルに変換し、上位位置エンコード機能がトランスフォーマーのエンコーダー層に入り、多層エンコーダーの後、最終的に線形層を通じて分類推定値が取得されます。