目次
JVM ガベージ コレクション
ガベージ コレクションの理由: Java は C ステートメントとは異なり、使用するときにコードを通じてスペースを空け、使用後に手動で破棄する必要があります。Java はプログラム用の仮想マシンを提供するため、ビジネス ロジックを重視してコードを記述し、メモリ空間の開発については JVM に解放します。コードは JVM 上で実行され、JVM はアルゴリズムを通じてどれがガベージであるかを識別し、ガベージ コレクション アルゴリズムを通じてプログラム内の未使用領域を自動的に解放します。C言語、C++は手動送信、Javaは自動送信のようなものです。
GC: ガベージ コレクション垃圾收集、若い世代のガベージ コレクションは GC とも呼ばれ、古い世代のガベージ コレクションはフル GC とも呼ばれます。
ガベージとは何ですか
プログラムの実行中、データを保存するためにメモリ内の領域を開く必要があります。ただし、この空間は一度使用されると二度と使用することはできず、この空間を指すアドレスがなければ、プログラムはメモリ内のゴーストのように、このアドレス空間の記憶内容を使用できません。しかし、これらのデータは実際にはメモリ内に存在しており、ゴミです。Java プログラムを作成する場合、スペースを開くだけでスペースは解放されません。そのため、メモリ内の不要なデータによって占有されるメモリスペースが多すぎ、プログラムで実際に使用できるメモリが少し減少し、最終的にはメモリが減少します。メモリオーバーフローを引き起こします。
以下では、例としてノードを削除する単一リンクリストを取り上げます。削除されたノードはゴミです
public class Application {
public static void main(String[] args) {
// 创建三个节点
Node n1 = new Node("张三");
Node n2 = new Node("李四");
Node n3 = new Node("王五");
// 将3个节点连接起来,形成 n1->n2->n3
n1.next=n2;
n2.next=n3;
// 遍历链表
Node node=n1;
while (node!=null){
System.out.println(node.data);
node=node.next;
}
// 删除一个节点 将中间的节点删除
n1.next=n3;
n3.pre=n1;
n2=null;
// 遍历链表
node=n1;
while (node!=null){
System.out.println(node.data);
node=node.next;
}
}
}
@Data
class Node{
Node pre;
Node next;
Object data;
public Node(Object data){
this.data=data;
}
}
考えてみます: n2 ノードは役に立たないのでしょうか? では、まだスペースを占有しているものは何でしょうか?
元のリンクリスト:
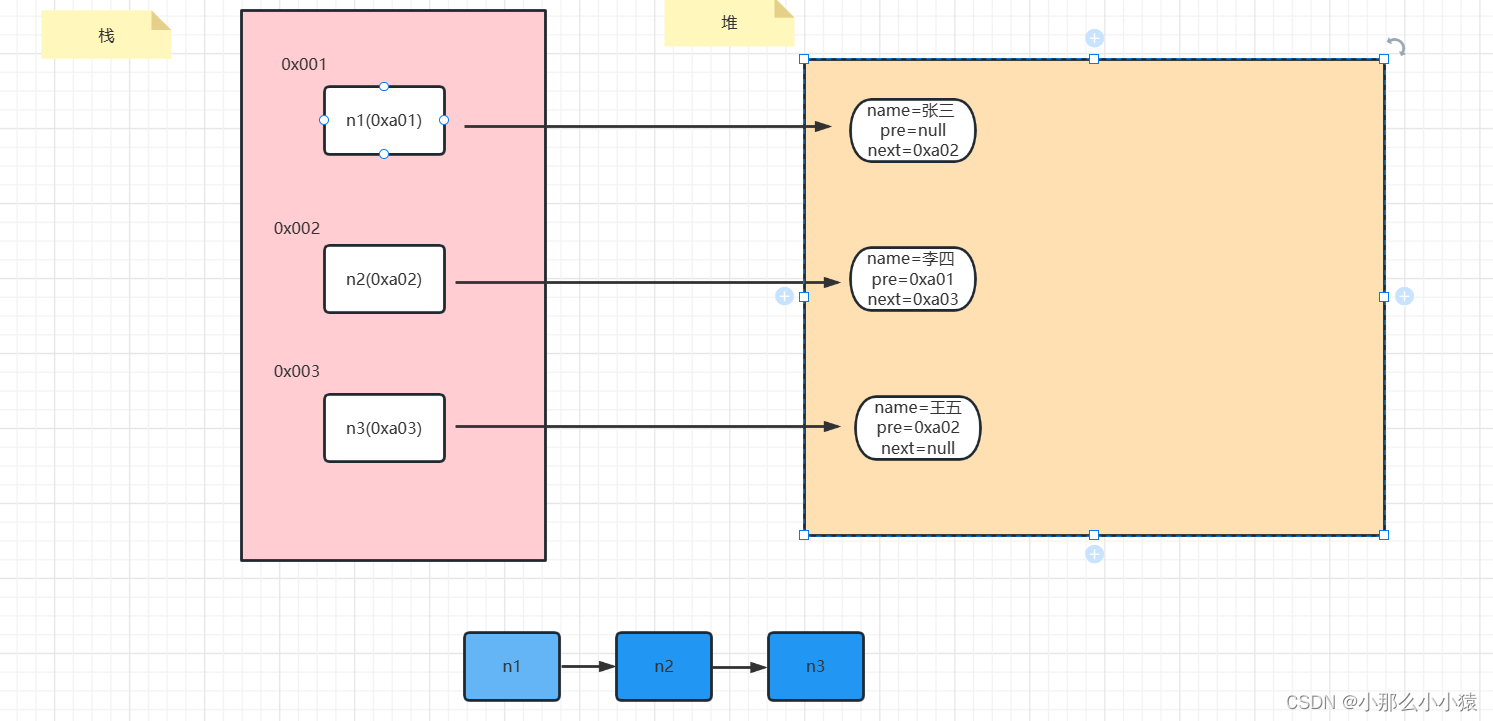
n2 ノードを削除した後: n2 がガベージであることはすでにわかっていますが、C とは異なり、Java はメモリ解放スペースを手動で操作できません。ただし、JVM は自動的にガベージを認識し、解放します。
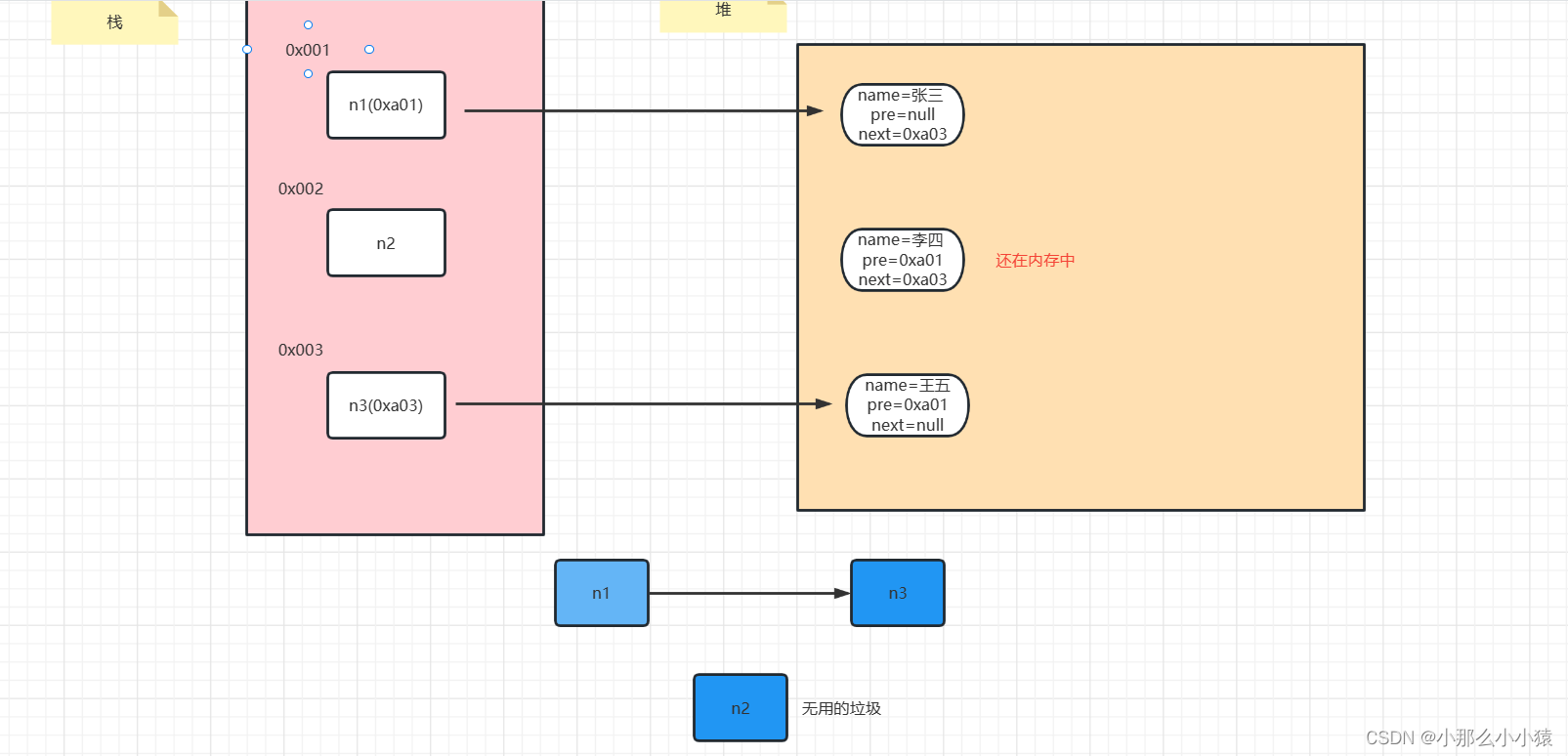
このとき、JVM はアルゴリズム (到達可能性分析) を通じて n2 がガベージであることを認識し、最終的に n2 が配置されているメモリ空間を再利用します。
ゴミ収集のエリアと範囲
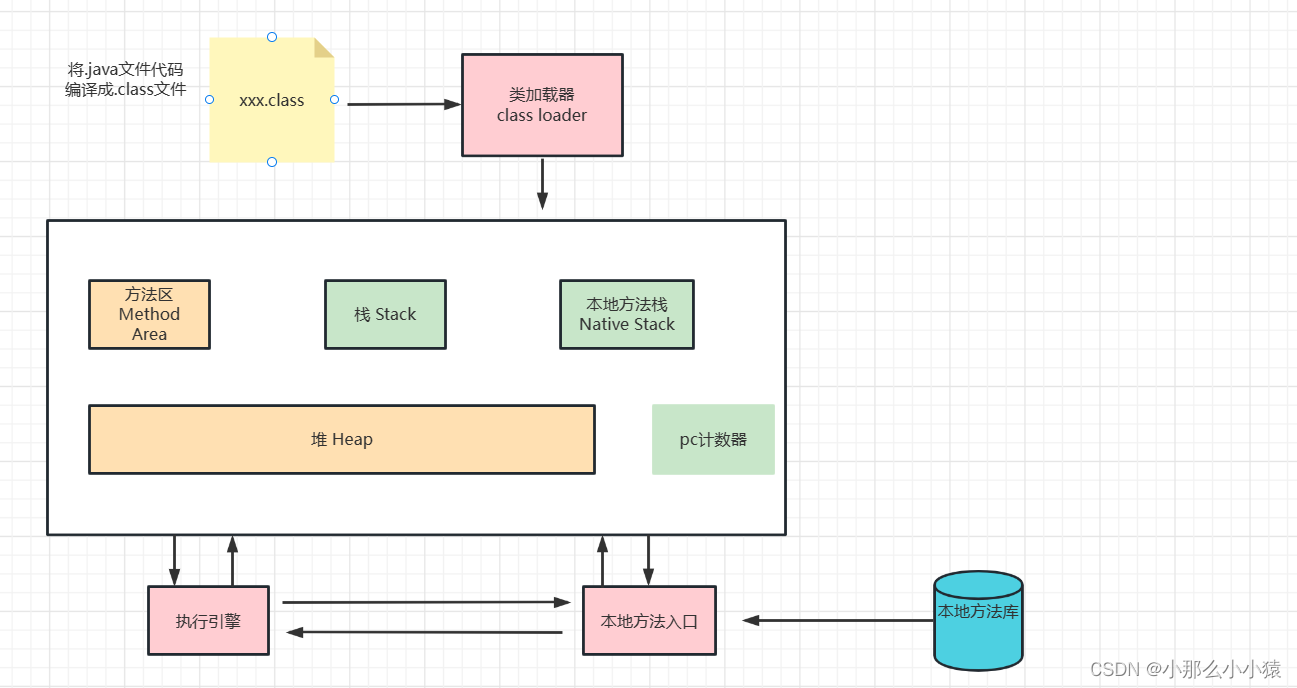
よく言われるように、スタックが実行され、ヒープが保存され、ヒープが最も多くのスペースを占有します。GC はメソッド領域とヒープのガベージ コレクションを担当しますが、主にヒープを担当します。他のエリアは占有スペースが非常に小さく、ゴミも発生しません。
ヒープはガベージ コレクションの主な場所であるため、最初にガベージ コレクションにおける一連の問題を無視してから、ヒープの具体的な論理構造と、ヒープ内でガベージがどのように転送されるかを紹介します。
世代別コレクション
GC ガベージ コレクションは複数回リサイクルされる可能性が高く、同じメモリ領域が最初のガベージ コレクションではガベージにならなくても、2 回目のコレクションではガベージになる可能性があります。ガベージを効率的にスキャンし、効率的にガベージを除去し、JVM の通常の動作にできるだけ影響を与えないようにする方法として、GC はヒープ領域を論理的に 3 つの世代 (メモリ内で物理的に)、つまり新世代、旧世代、および世代に分割します。元のスペース (JDK7 より前の永続世代)。JVM は、これら 3 つの領域の特性に応じて、それらに固有の方法で情報を格納します分代管理。例:若い世代では GC (YoungGC) が実行され、古い世代では FullGC が実行されます。
世代別コレクションには主に 2 つのアイデアがあります。
- ほとんどの被験者は生きて死ぬ
- より多くのガベージ コレクションを経ても生き残るオブジェクトは、ガベージになる可能性が低くなります。
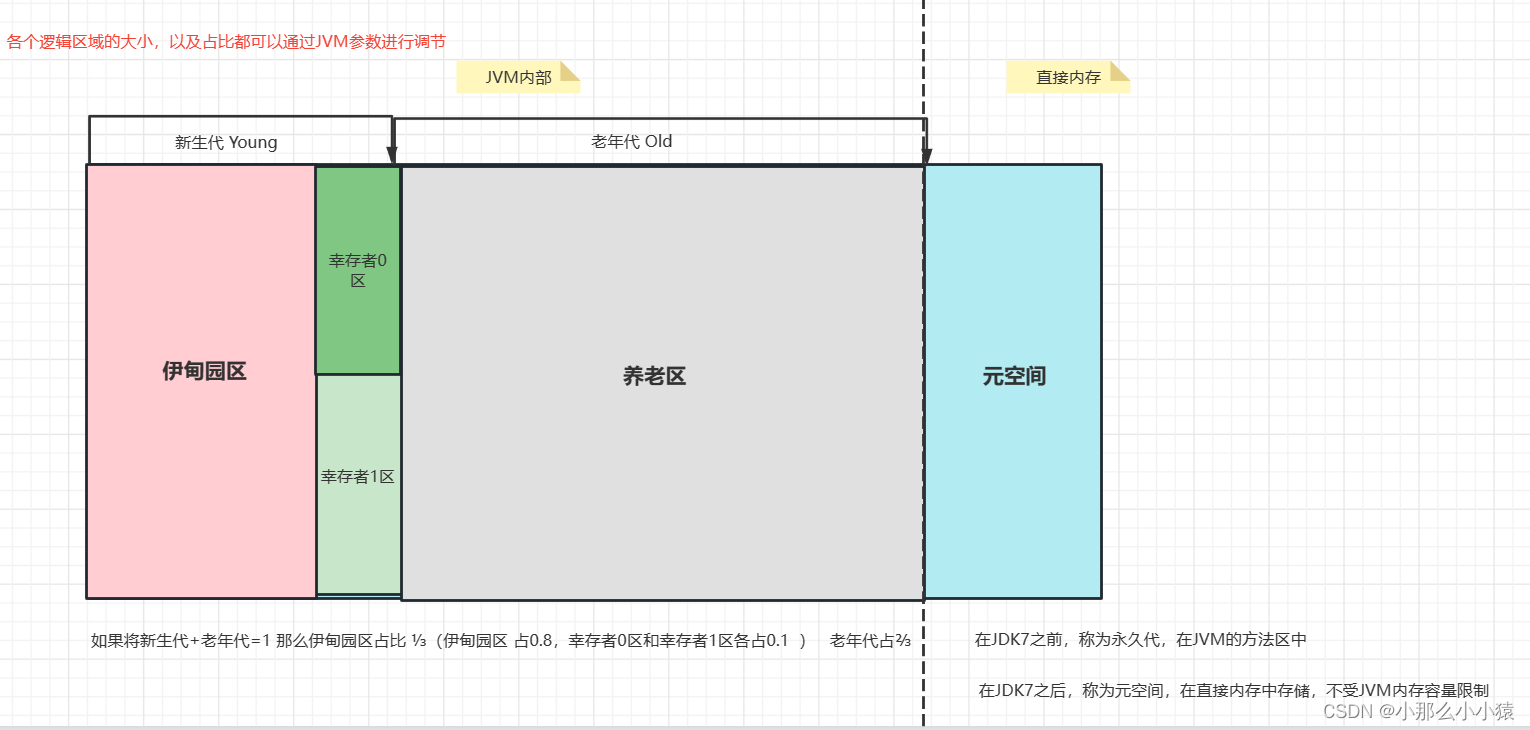
次に、実際のガベージコレクションにおいてこれらの領域がどのように連携して動作するのか、なぜこのように分割するのかを説明します。
最初に作成したクラスオブジェクトは、作成したオブジェクトとして最初はエデン領域(Eden)に配置されます。ますます増えていくにつれて、新しく作成されたオブジェクトを Eden に保存するためのスペースがなくなると、YoungGC がトリガーされます。YongGC が初めてトリガーされます。Eden エリアと生存者の from エリア (現時点では from エリアは空です) 内のすべてのガベージをスキャンし、それをサバイバーの to エリアに転送します不是垃圾。复制Survivor 領域に格納され、清空Eden区Survivor の From 領域内のすべてのデータが同時にエクスペリエンスされます。GC スキャン後、ゴミではないと判断されたコンテンツの Age は +1 されます。
最初の GC 後のヒープ領域の現在の状態: Eden 領域は空、生存者の to 領域には少量の生き残ったデータがあります。これらのデータの年齢は +1 で、to 領域はfrom 領域に変換 to 領域に変換されますが、この時点では to 領域は空です。GC 後にスペースが解放されるため、新しく作成されたオブジェクトは Eden 領域に配置され、プログラムの実行につれてオブジェクトがどんどん作成されます。Eden が再びいっぱいになると、2 回目の GC がトリガーされます。(注:そして今回は Survivor 領域の 1 つ、つまり to 領域が空です) GC は和幸存者from区Eden 領域のガベージではない部分をスキャンして、この部分を別の空の Survivor 領域 to 領域にコピーします。時間は再びガベージのデータ年齢 +1 しません。スペースは GC 後に解放されるため、新しく作成されたオブジェクトは Eden 領域に配置され、サイクルが繰り返されます。
一定の時間(少なくとも 15 GC 後)までは、ガベージとみなされない各データの年齢が +1 されるため、一部のデータの年齢が 15 年に達するまで(JVM パラメータの設定により変更可能)、今回は 15 年経過したデータがすでに存在しています。15 回の GC の後、システムはこれらのデータが将来ゴミになる可能性は低いと判断し、毎回データを前後に移動させるのに時間と労力がかかります。データは古い世代に入れられます。YoungGC がトリガーされるとき、Old Generation は関与しません。
新世代のプロセスはこんな感じ、概要はこんな感じ复制+1->清空->互换。ゴミではないデータを空きのSurvivor領域(エリア0とします。今回はTO領域とします)とそのデータの年齢+1をコピーし、Eden領域と空ではなかったSurvivor領域をクリアします。コピーして (エリア 1 と仮定します。この時点ではエリア 1 が from エリアです)、from エリアと to エリアを交換します。このとき、ゾーン 0 が from ゾーン、ゾーン 1 が to ゾーンになります。次の GC で再度スワップします。
次に、古い領域で年齢が 15 倍に達したデータに移りますが、若い世代で発生するすべての GC はここでは影響を受けませんが、GC の後に新しいデータが追加される可能性があります。頻繁な GC により、新しいデータが常に追加され、システムは古い世代の領域がいっぱいになるかどうか (各新しいデータの平均値 > 古い世代の残りの領域)、およびいつになるかを事前に予測します。次回は古い世代のスペースがいっぱいになる可能性があり、それがトリガーになりますFull GC。古い世代のゴミをスキャンしてクリアし、古い世代のメモリ領域を解放します。
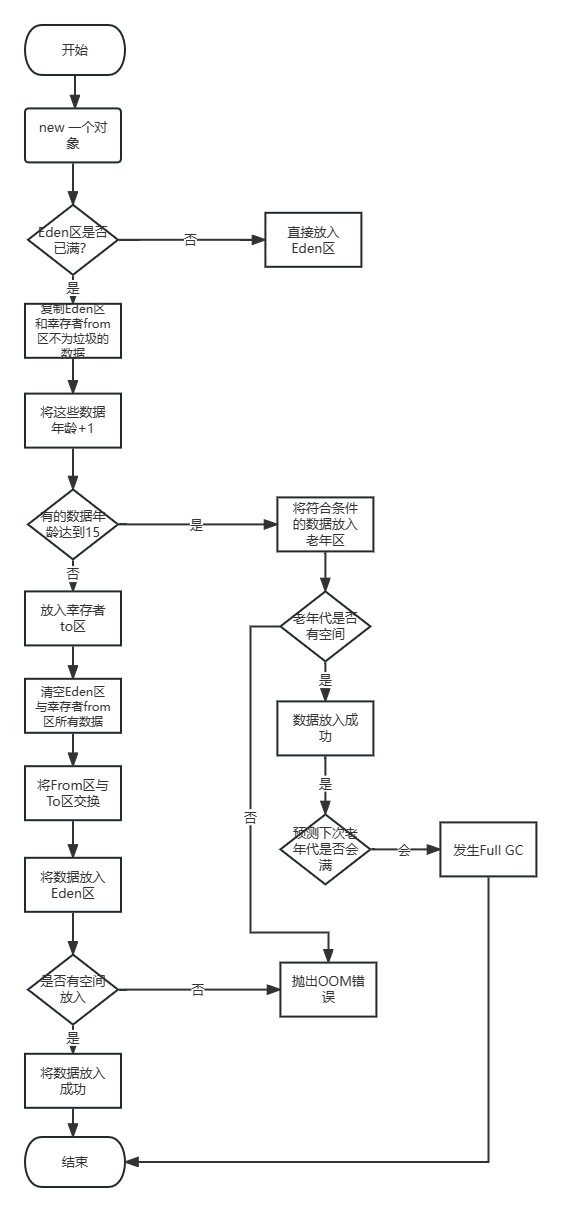
(この図は、細かい部分は無視して大まかな流れを示したものです。)次に、 JDK7以前の
メタスペースについて紹介しますメタスペースは、メソッド領域の実装である永続世代であったため、非メタスペースとも呼ばれます。
ヒープ。ただし、論理的にはヒープの一部であり (ヒープは若い世代、古い世代、永続世代に分割されます)、物理的には同じメモリを使用します。旧世代に縛り付けられており、誰が満員になっても旧世代と永続世代のゴミ撤去のきっかけとなります。この方法では、永続世代に対応するコードを個別に記述する必要がなく、古い世代を直接使用できます。永続世代には主に类信息、普通常量、静态常量などが格納されます编译器编译后的代码。たとえば、作成したオブジェクトはどのクラスに従って作成され、このクラスのテンプレートは永続世代にあり、オブジェクトのヘッダー情報のクラス ニードルは永続世代のインスタンスのクラスを指します。JDK7 以降、文字列定数プールはヒープに移動されました。ただし、永続世代とヒープに格納されるデータが異なるため、永続世代の適切なサイズを決定することが困難であるため、永続世代を中央に移動し、名前を変更しJDK8ます直接内存。 Metaspace (メタスペース)。論理的には Up で、旧世代からは物理的に分離されています。
このようにメタスペースはローカルメモリを使用しますが、デフォルトの最大使用量はローカルメモリのサイズ(上限も設定可能)となっており、実際の状況に応じて自由にクラス情報を読み込むことができます。古い世代に従うことなく、独自のガベージ コレクション頻度を持っています。メタスペースは、旧世代の代わりにメソッド領域の仕様を実装したものです。
永続世代とメタスペースの最大の違いは、メタスペースがダイレクト メモリを使用し、サイズをハードコーディングする必要がないことです
。 注:
新创建的对象都会放入Eden区,但在扫描垃圾时,会将Eden区和不为空的幸存者区放在一起扫描。幸存者from区和幸存者to区大小永远一致- 高齢者エリアに入るために、すべてのオブジェクトが 15 年前である必要があるわけではありません。たとえば、いくつかの大きなオブジェクトや、エデン エリアの生存者スペースのサイズと生存者元エリアのサイズが生存者先エリアのサイズの半分を超えている場合などです。これらは古いエリアに直接配置されます。
- 古い領域でフル GC をトリガーする条件は数多くあります。
- コードで実行されますが
System.gc()、コードではほとんど使用されません - 旧世代ではスペースが不足
- 領域割り当ての保証に失敗します。GC 前に、若い世代から古い世代に昇格した領域の平均サイズを計算し、そのサイズが古い世代の残りの領域を超える場合、FUll GC が実行されます。
- メタスペースがしきい値を超えています。デフォルトでは、メタスペースのサイズはローカル サイズを基準にしています。メタスペースの合計サイズがしきい値を超えると、フル GC が実行されます。
- コードで実行されますが
- Full GC による STW 時間が長すぎる (STW は GC の 10 倍以上) ため、GC のチューニングの考え方は、Full GC の数を減らすか、Full GC の STW 時間を短縮することです。
考え方:既然从Eden区和幸存者区中扫描出不是垃圾的内容要放入另一个幸存者区,那这两个区的功能是固定好的吗?
コピー後、交換が行われ、空いている人が to 領域になります
。最初の GC の後、空いている人が to 領域になります。コピーアルゴリズムは若い世代のゴミ除去に使用されているためです。ジャンクではない部品をスキャンし、別の目的地に転用します。宛先が誰であるかは固定されていません。固定されている場合は、生存者 1 領域が常に from 領域、生存者 0 領域が常に to 領域であるとみなされ、最初の GC で非ガベージ部分がコピーされます。 to 領域と 2 番目のガベージ Recycling は Eden 領域と to 領域をスキャンする必要があり、コピーされる場所は to 領域ではなく、from 領域である必要があります。Survivor 領域もガベージ コレクションする必要があるため、to 領域が必要であり、from 領域と to 領域は論理的な交換が可能である必要があります。
考え方:为什么在新生区清除垃圾时是复制有用的,而不是直接清除无用的?这样不是就不需要幸存者区,会更加节省空间了吗?
統計によると、使用されているオブジェクトの 98% は一時的なオブジェクトであり、これは Eden エリアのほとんどがゴミであることを意味します。ゴミ捨て場から有用なものを 1 つずつ削除するよりも効率的であるため、新しい世代では有用な部分のコピーが使用されます。ただし、この方法でコピーするには余分なスペースが必要です。旧世代のデータは 15 回の GC でゴミになる可能性が低いので、無駄な部分をクリアすれば済みます。
考え方: 什么时候会触发GC?(GC通常指YoungGC)
Eden 領域がいっぱいになると GC がトリガーされます。オブジェクトは作成時に Eden エリアに保存され、生存者の from エリアは新しく作成されたオブジェクトの保存には直接関与しません。
ガベージ コレクションのプロセスについては上で簡単に紹介しましたが、ミクロな観点から見ると、ガベージ コレクターは、若い世代であっても古い世代であっても、どのようにしてどれがゴミであるかを識別するのでしょうか。
ゴミの見分け方
どのようなアルゴリズムであっても、プログラム内で参照関係のないメモリアドレスを見つけることが核心となります。参照関係のないメモリアドレスはプログラム内で使用されることはなく、再利用されます。
参照カウント
ヒープメモリ上のデータの参照回数が+1され、参照回数が1減ります。ヒープメモリ上のデータの参照回数が0の場合は、参照する場所がないことを意味します。このデータを参照するとゴミと判断されます。
例: Node クラスがあり、ノード 1 によって参照され、参照カウントは 1 -> ノード 1、ノード 2 がすべて参照、参照カウントは 2 -> ノード 1 が逆参照、参照カウントが 1 -> ノード 2 がそれを逆参照、参照カウントが 0 の場合、このアドレスのデータはガベージです。
public class Application {
public static void main(String[] args) {
Node node1 = new Node("张三");
Node node2=node1;
System.out.println(node2);
node1=null;
System.out.println(node2);
node2=null;
}
}
しかし、このアプローチには問題があります。循环引用问题
public class Application {
public static void main(String[] args) {
Node node1 = new Node("张三");
Node node2 = new Node("李四");
node1.setData(node2);
node2.setData(node1);
node1=null;
node2=null;
}
}
「Zhang San」という名前のノードを例にとります。 ノード 1 参照、参照カウントは 1 -> ノード 2 データ参照、参照カウントは 2 -> ノード 1 参照は無効、参照カウントは 1 ですが、この時点ではNode2は既にnullなので、このNodeはプログラム内で使用できなくなり、既にゴミとなっていますが、参照数は0ではなく1なのでゴミとして認識できません。これは、参照カウント方法によって引き起こされる循環参照の問題です。
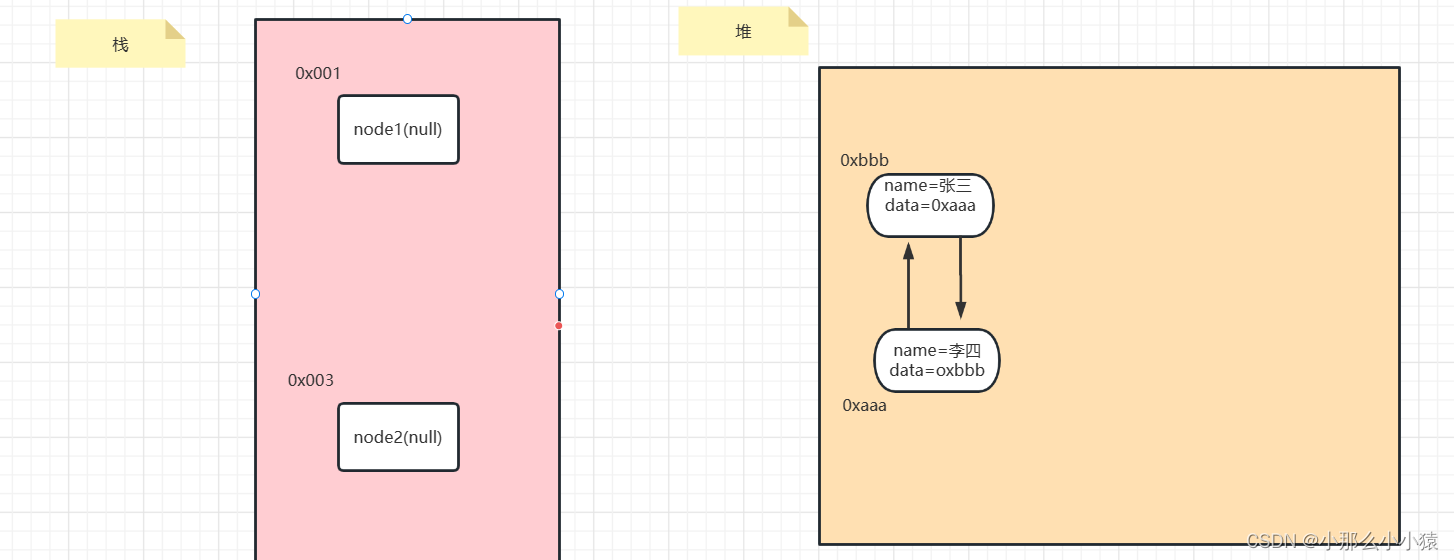
参照カウントの欠点:
- 各オブジェクトは参照カウンターを維持する必要があるため、パフォーマンスが低下します。
- 循環参照に対処するには
参照カウントには顕著な欠点があるため、現在では参照カウント方式は基本的に使用されていませんが、次のようなリーチャビリティ解析方式が使用されています。
アクセシビリティ分析
GC ルートとして使用できるオブジェクトから開始して、その参照関係に従い、その参照チェーンをたどります。トラバースされていないすべての GC ルート オブジェクトはメモリ内でゴミとなり、このアドレスのデータはプログラムで使用されなくなります。ブドウの房と同じように、根元から蔓を下っていきます。見つけられるブドウは房の中にあるはずです。落ちたブドウだけはたどることはできません。これはゴミです。
上記の技術的手法ではまだ解決できない例です。
public class Application {
public static void main(String[] args) {
Node node1 = new Node("张三");
Node node2 = new Node("李四");
Node node3 = new Node("王五");
new Node("赵六");
node1.setData(node2);
node2.setData(node1);
node1=node3;
node2=null;
}
}
上記のコードは次のように表現できます。
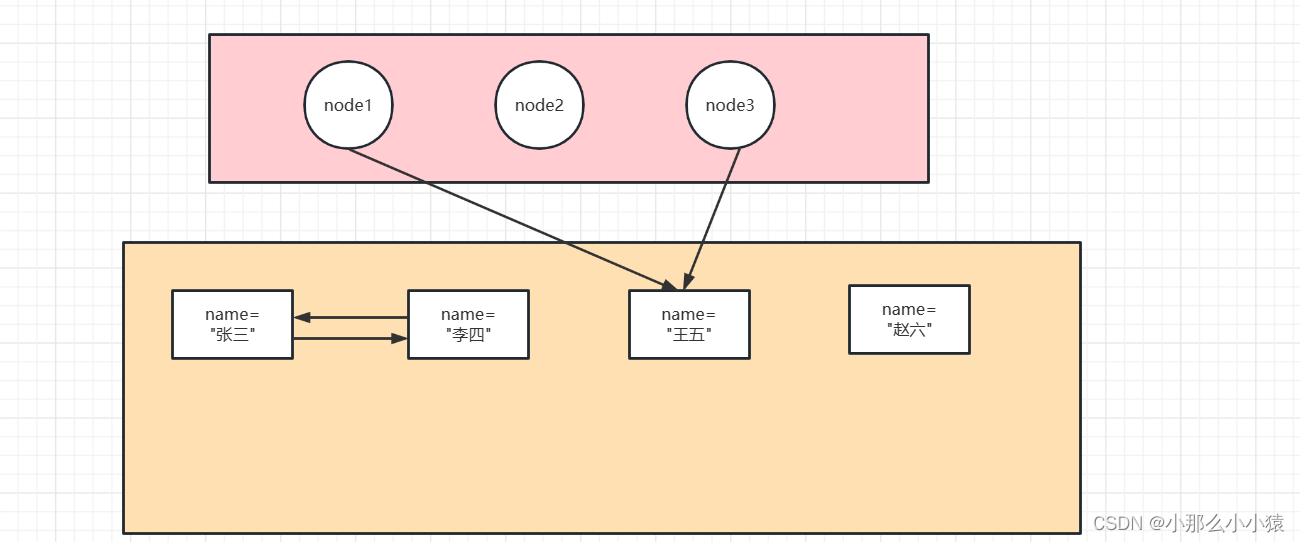
到達可能性分析メソッドを使用する場合、node1、node2、node3 はすべて GC ルートとして使用され、3 番目からその参照関係の追跡を開始できます。最終的に、メモリ内の Zhang San、Li Si、Zhao Liu という名前の 3 つのノードは走査されなかったため、これら 3 つはゴミであり、リサイクルされると判断されました。
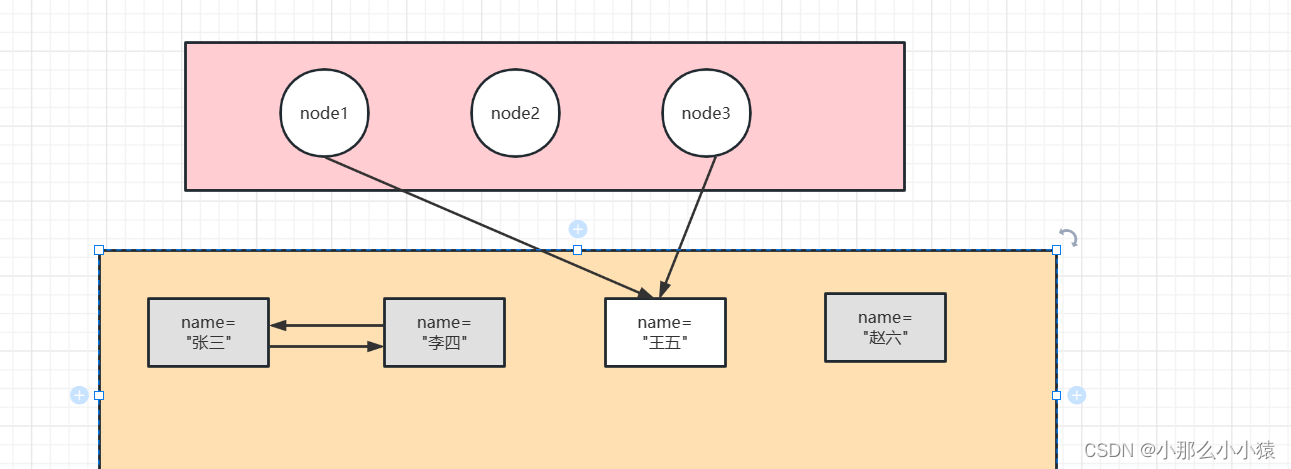
参照関係は GC ルート オブジェクトのコレクションからたどられるため、どのオブジェクトを GC ルートとして使用できるでしょうか? GC ルートは 4 種類のオブジェクトのコレクションです
- スタック上のローカル変数によって参照されるオブジェクト
- メソッド領域の静的プロパティによって参照されるオブジェクト
- メソッド領域の定数によって参照されるオブジェクト
- ネイティブ メソッド スタック JNI によって参照されるオブジェクト
上記の例では、GC ルートであるすべてのオブジェクトはタイプ 1 です。
GC ルートからの参照関係を持つオブジェクトを不是一定不会ガベージとしてトラバースするかどうかは、その時点のメモリ状況と参照関係に依存します。ただし、参照関係がないものは一定会ゴミとして扱われます。
どれがガベージであるかは、GC ルート オブジェクトの参照関係をたどることによって決定されます。これには、参照される関係のタイプも関係します。
4 種類の参照関係: 強い、弱い、弱い、仮想
强引用オブジェクト間の参照関係は、 、软引用、弱引用、の 4 種類に分類できます虚引用。私たちが通常使用する参照関係はすべて強参照であり、残りの 3 つのメソッドは特別な関数で使用されます。

補充:
- JVM は Eden 領域の空き容量が不足している場合や、旧世代の空き容量が不足している場合に GC をトリガーしますが、コード内で手動で GC を呼び出すこともできます。このメソッドを使用すること
System.gc();は一般的ではなく、通常はテストでのみ使用されます。そして: この方法で GC をフル GC として使用します。 - デフォルトでは、ヒープ メモリの最小割り当てがサーバー メモリの合計を占め
六十四分之一、最大メモリがサーバー メモリの合計を四分之一占めます。JVM は最小メモリで開始します。メモリが十分でない場合は、メモリが不足するまで調整されます。最大メモリ。それでも十分でない場合は、OOM エラーが発生します。
検証:
16G のネイティブ メモリは
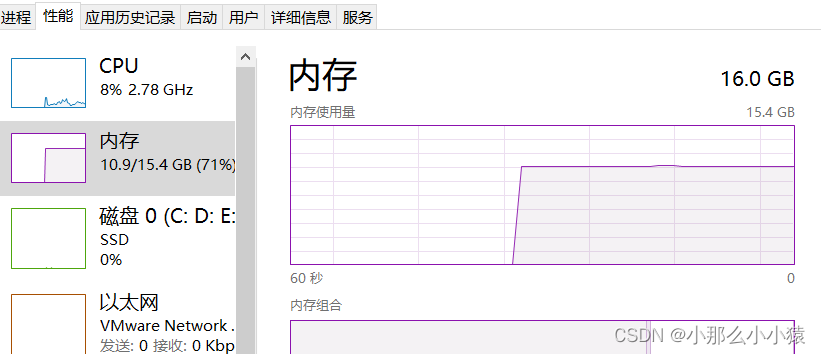
コードからも取得できます。
public class Application {
public static void main(String[] args) {
OperatingSystemMXBean mem = (OperatingSystemMXBean) ManagementFactory.getOperatingSystemMXBean();
// 获取内存总容量
long totalMemorySize = mem.getTotalPhysicalMemorySize();
}
}
JVM の最小ヒープ メモリと最大ヒープ サイズを表示します。
public class Application {
public static void main(String[] args) {
System.out.println(""+Runtime.getRuntime().totalMemory()/1024/1024+"M");
System.out.println(""+Runtime.getRuntime().maxMemory()/1024/1024+"M");
}
}

默认最大ヒープ メモリ サイズ = 合計メモリ サイズ / 4、默认最小ヒープ メモリ サイズ = 合計メモリ サイズ / 64 をほぼ満たします。
これらのデフォルト サイズ パラメータは Idea で調整できます (サーバーは、jar パッケージの起動時にコマンド ラインで調整できます)。通常、メモリの変動を防ぐために、最大ヒープ メモリ領域を最小ヒープ メモリ領域に調整します。
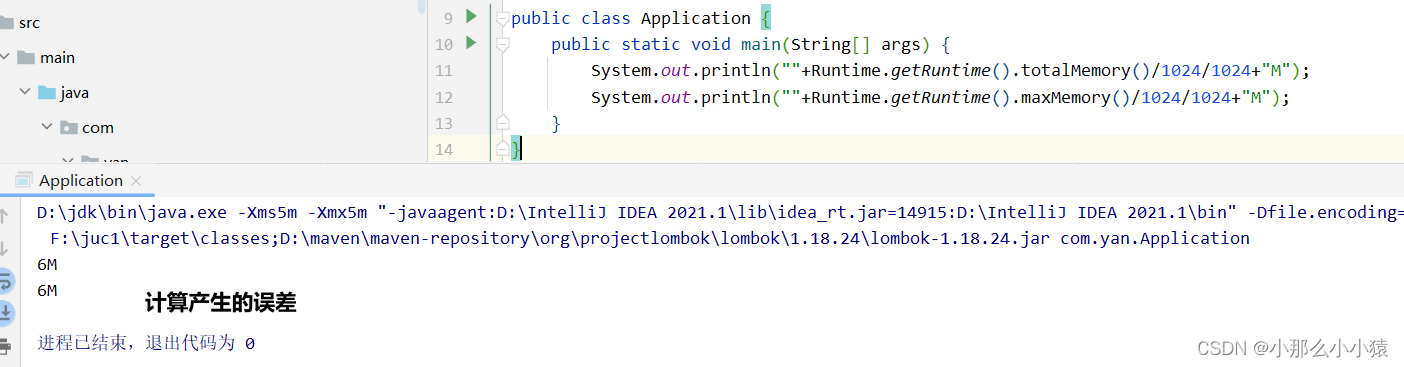
例: -Xms5m:最小ヒープ メモリ スペースを 5M に設定します。 -Xmx5m はヒープ メモリ最大スペースを 5M に設定し、アイデアコードの検証結果
で構成します。
強力な参照
通常使用する参照は強参照であり、その他の参照はコードでマークする必要があります。例えば:
public class Application {
public static void main(String[] args) {
Node node1 = new Node("张三");
Node node2 = new Node("李四");
Node node3=node1;
}
}
Node1 と node3 は Zhang San という名前のノードを参照し、node2 は Li Si という名前のノードを参照します。3 つの参照はすべて強参照です。
強参照の特徴は、GC ルートに到達できる場合、強参照はガベージ コレクションされないことです。メモリが不足している場合、メモリはリサイクルされず、OOM 例外が直接スローされます。
ソフトリファレンス SoftReference
メモリ不足の場合、ソフトリファレンスのヒープ空間アドレスは無効となり、ガベージコレクションも行われます。
コード テストのアイデア: 異なる環境 (十分なメモリと不十分なメモリ) で同じコードをテストし、ソフト参照のみのヒープ領域がガベージ コレクションとして扱われるかどうかをテストします。
public class Application {
public static void main(String[] args) {
User u1 = new User("张三"); //强引用方式
SoftReference<User> softReferenceU1 = new SoftReference<>(u1); // 软引用方式 与强引用都是引用同一块地址
System.out.println(u1); // 以强引用的方式获取引用地址的数据(User (name=“张三”))
System.out.println(softReferenceU1.get()); // 以软引用的方式获取引用地址的数据(User (name=“张三”))
u1=null; //此时 User(“张三”)失去了强引用 ,只有一个软引用
System.gc(); // 经历了一次 Full GC
System.out.println(softReferenceU1.get()); // 测试 User("张三")是否被回收掉
}
}
@Data
@AllArgsConstructor
class User{
private String username;
}
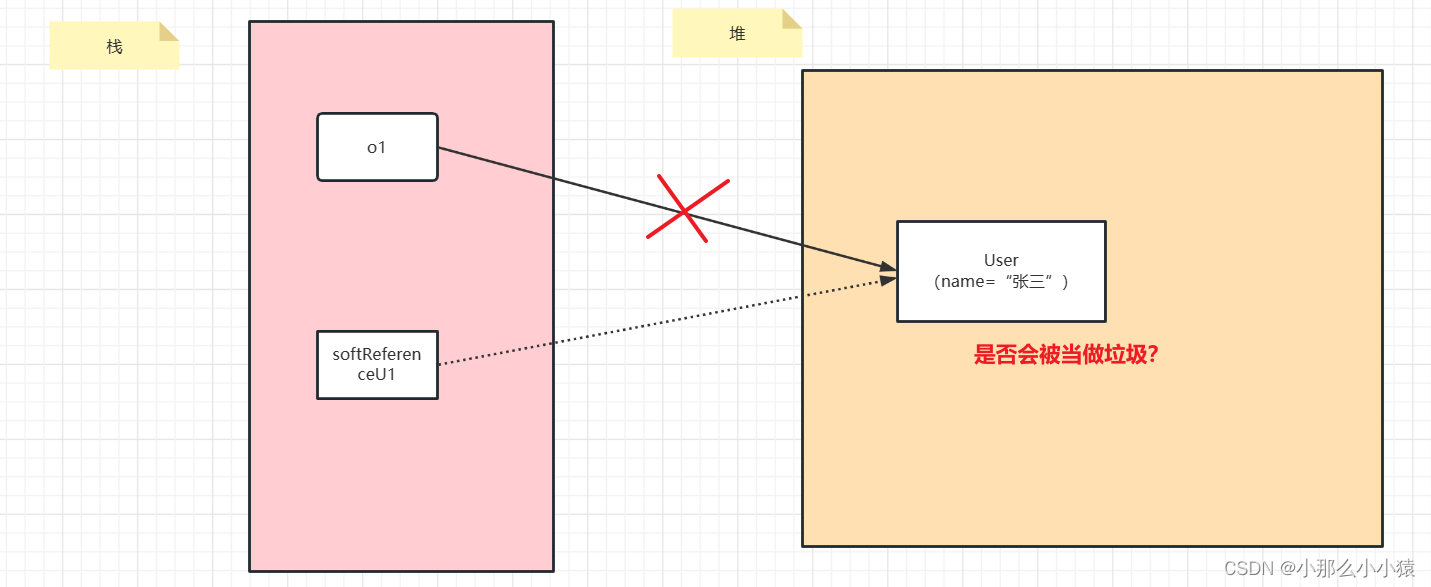
- 十分なメモリがある場合
結果:

これから次のことがわかります。在内存充足时,由于堆内存中User(name=“张三”)仍有一个软引用,使得它没有被当做垃圾回收。
- メモリが不足している場合は、 JVM パラメータを設定し、JVM ヒープの最大メモリと最小メモリを 5MB に設定します。
メモリ不足のため、直接エラーが報告されるため、メモリ不足のステートメントを try でラップして出力するように上記のコードを修正します。
public class Application {
public static void main(String[] args) {
User u1 = new User("张三"); //强引用方式
SoftReference<User> softReferenceU1 = new SoftReference<>(u1); // 软引用方式 与强引用都是引用同一块地址
System.out.println(u1); // 以强引用的方式获取引用地址的数据(User (name=“张三”))
System.out.println(softReferenceU1.get()); // 以软引用的方式获取引用地址的数据(User (name=“张三”))
u1=null; //此时 User(“张三”)失去了强引用 ,只有一个软引用
try {
Byte[] load = new Byte[1024 * 1024 * 10];
// 直接开辟一个10M的内存空间 使得堆内存不足 这是检测是否会只有软引用是否会被当做垃圾回收
}catch (Exception e){
}
finally {
System.out.println(softReferenceU1.get()); // 测试 User("张三")是否被回收掉
}
}
}
結果:

弱い参照 WeakReference
GCがトリガーされている限り、 GCがなければソフト参照は無効になります(ソフト参照のみの空間はゴミとして扱われます)。
public class Application {
public static void main(String[] args) {
User u1 = new User("张三"); //强引用方式
WeakReference<User> weakReferenceU1 = new WeakReference<>(u1); // 弱引用方式 与强引用都是引用同一块地址
System.out.println(u1); // 以强引用的方式获取引用地址的数据(User (name=“张三”))
System.out.println(weakReferenceU1.get()); // 以弱引用的方式获取引用地址的数据(User (name=“张三”))
u1=null; //此时 User(“张三”)失去了强引用 ,只有一个弱引用
System.out.println(weakReferenceU1.get());
}
}
@Data
@AllArgsConstructor
class User{
private String username;
}
結果: GC が存在しない前、参照下のオブジェクトがまだ使用できる場合

GC について
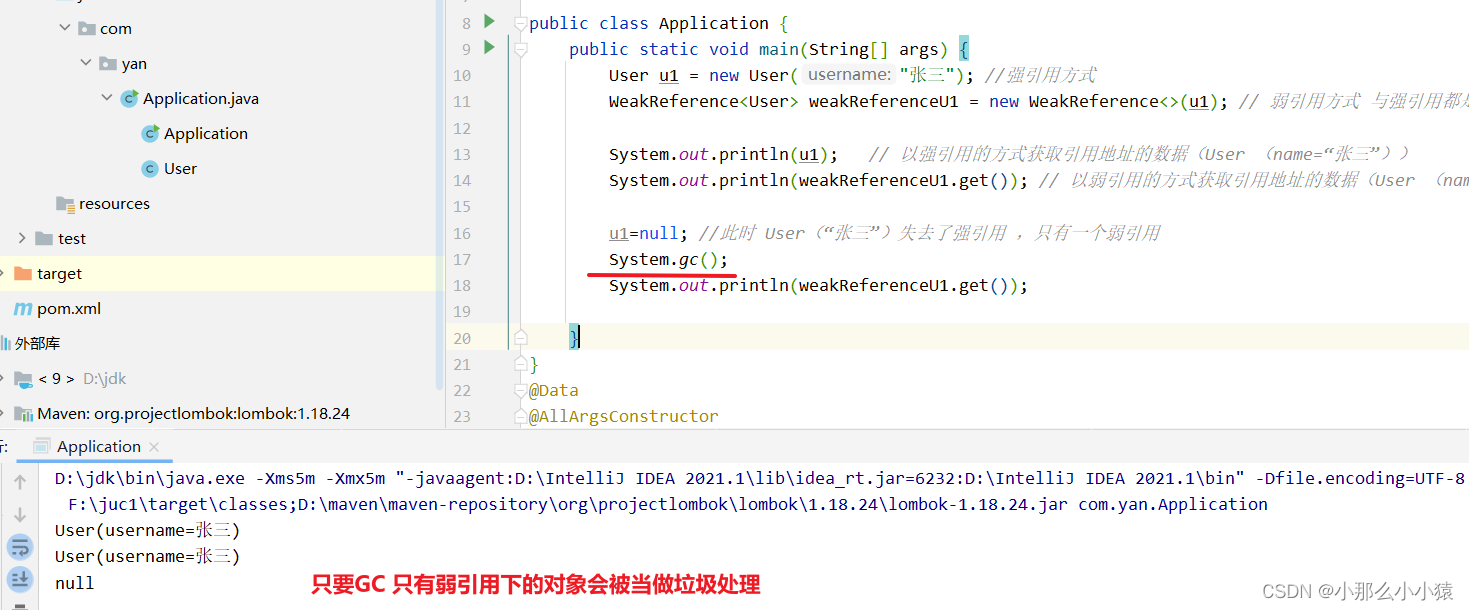
考えてみましょう。なぜコード内で u1 を null に設定する必要があるのでしょうか?
u1 の使用は強参照です。強参照の特徴は、どのような状況でも、強参照が指すオブジェクトがガベージとして扱われないことです。ソフト参照、弱参照、ファントム参照をテストするときに強参照を切断しないと、結果を確認できません。
ウィークハッシュマップ
HashMap を使用する場合、Key は強参照関係になります。例: ユーザー u1=User (name="Zhang San") を作成し、添付値を u1 オブジェクトに追加したいため、u1 をキーとして HashMap に渡しました。u1 オブジェクトが使い果たされたら (添付された値も消えるはずです)、解放したいときは u1=null になりますが、この時点では HashMap はまだ User オブジェクトを指す強い参照を持っています。このオブジェクトはガベージとして解放できません。
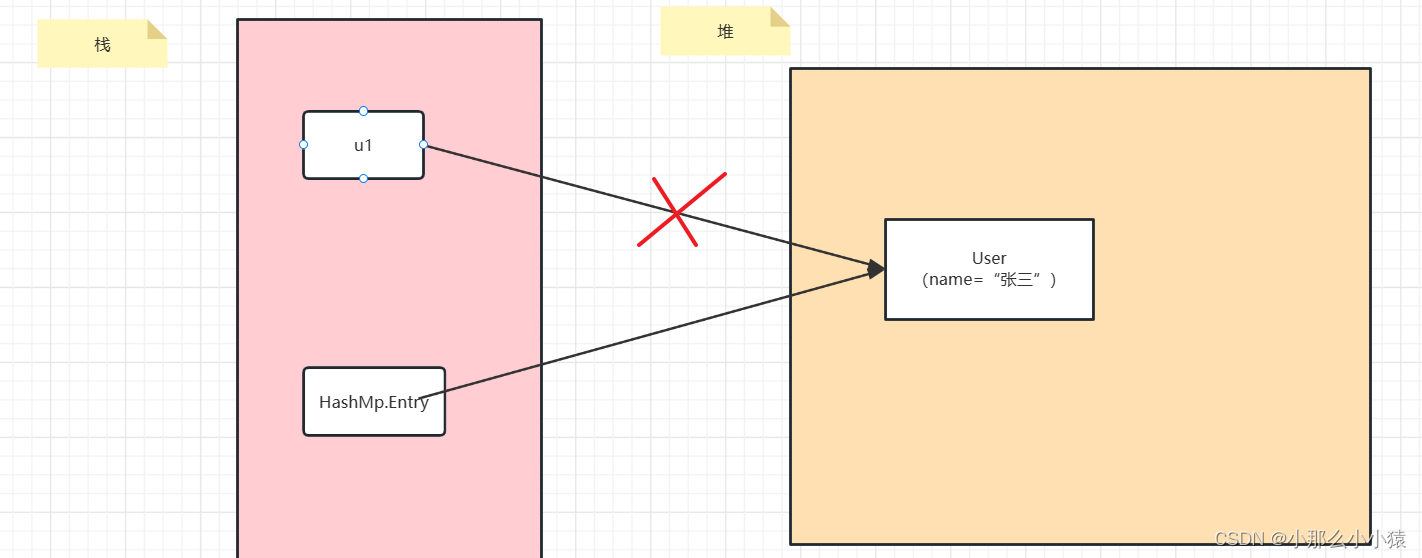
この方法では、ガベージ コレクション中にオブジェクトがまだ存在するため、メモリが無駄になり、OOM の問題が発生します。WeakHashMap を
使用すると、オブジェクトとの弱い参照関係が確立されます。このオブジェクトを使用したい場合は、オブジェクトはゴミではありません。u1 を使い切って強参照が切断されると、GC 時にガベージが収集され、WeakHashMap 内の参照は無視されます。
public class Application {
public static void main(String[] args) {
WeakHashMap<User, String> weakHashMap = new WeakHashMap<>();
User u1 = new User("张三");
User u2 = new User("李四");
weakHashMap.put(u1,"v1");
weakHashMap.put(u2,"v2");
u1=null; // User("张三")由于断开强引用,只有一个弱引用的WeakHashMap与之相连,在发生GC时会被回收
System.out.println(weakHashMap);
System.gc();
System.out.println(weakHashMap); // 判断只有WeakHashMap引用下的对象是否被释放
}
}
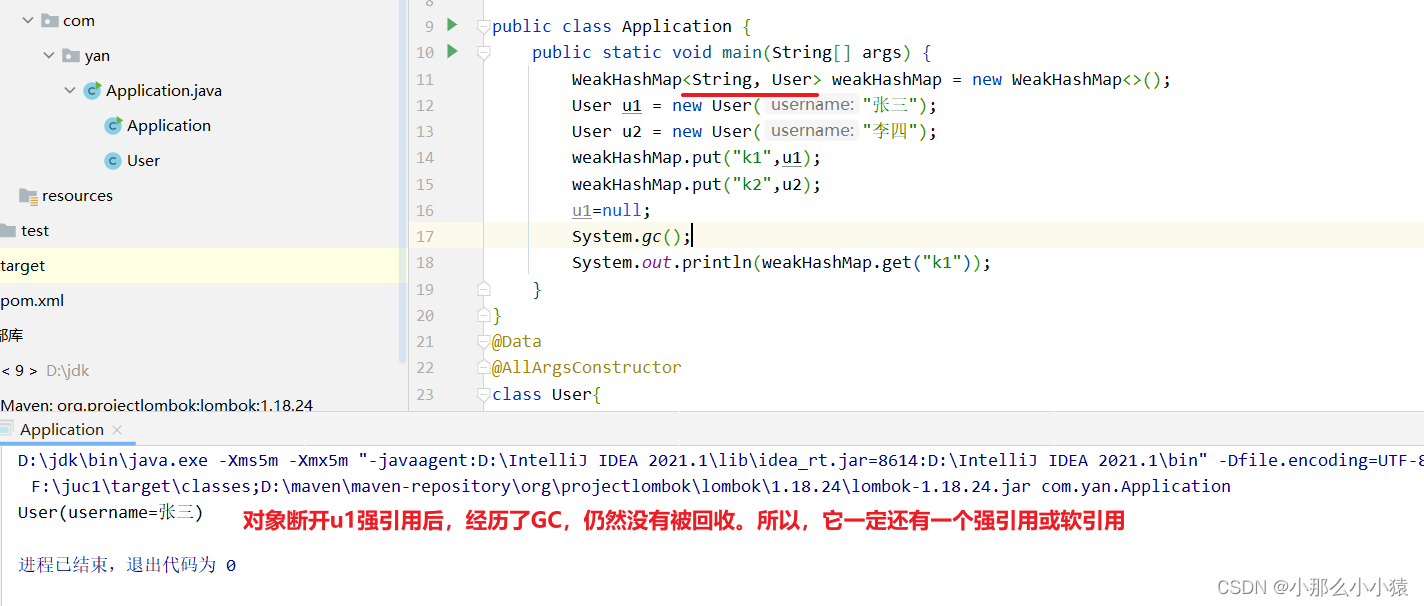
結果:

しかし、オブジェクトが Value としてweakHashMap として使用されると、User オブジェクトは u1 の強参照を解除し、オブジェクトは GC 後もまだ存在するため、WeakHashMap の値の部分は強参照である可能性があります。図に示すように:
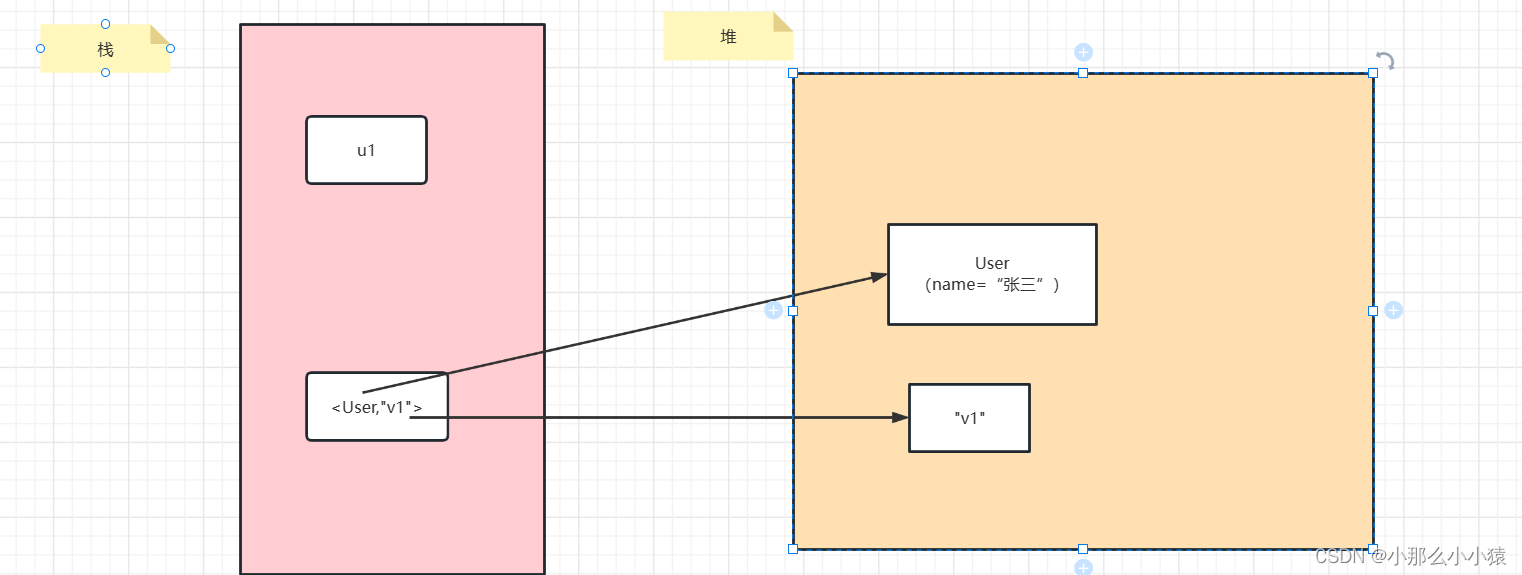
思考: キーが指すオブジェクトがリサイクルされるとき、WeakHashMap のキーを通じて値が取得されると何が返されるでしょうか?
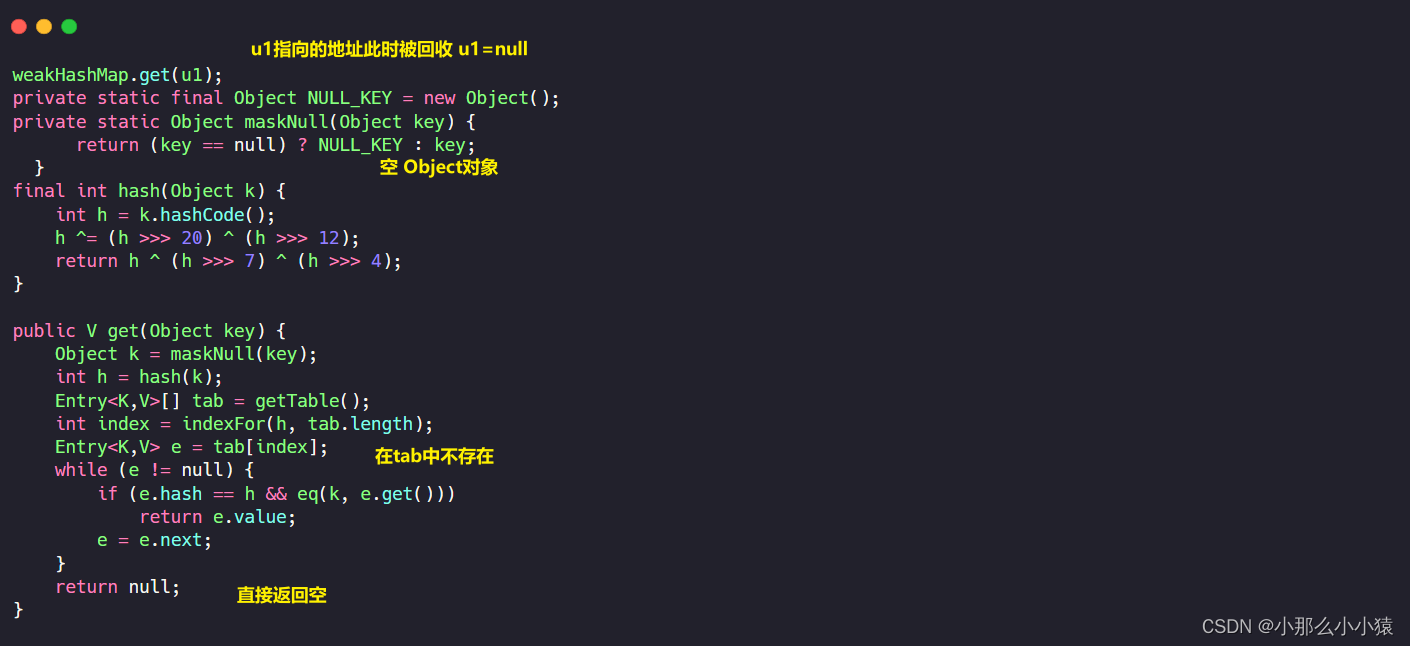
考察: Key が弱参照であるため、WeakHashMap はリサイクルされる可能性がありますが、参照オブジェクトに強参照がない場合、WeakHashMap の値はリサイクル後にどこに行くのでしょうか?

考え中: WeakHashMap<Object,Object>是否类似于HashMap<Reference<Object>,Object>?
補足: ThreadLocalMap のソース コードで、ThreadLocal のメモリ オーバーフローの問題を解決するために弱い参照を使用するというアイデアを見たことがあります。 ThreadLocal をキーとして使用し、ThreadLocal が
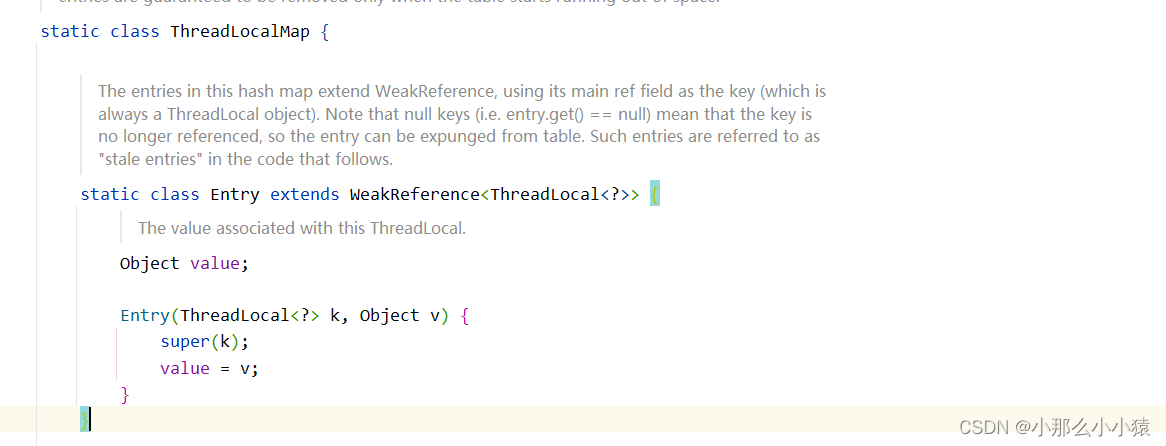
破棄されると、Map 内のこの ThreadLocal に関するデータも削除されます。解放されました。
ソフト参照とファントム参照の使用シナリオ
ソフト参照と弱参照は通常、強参照と組み合わせて使用されます。ソフト参照は、強参照が切断されていても、メモリが許せばアドレス空間を引き続き使用したい場合です。ソフト参照とは、強参照が切れたときにアドレス空間を使う必要がなく、通常はコレクションと組み合わせるのですが、ヒープの解放方法が面倒で、GCに渡して解放します。
例: ソフト参照を使用してキャッシュを生成する
画像を読み込む場合、使用するたびにディスクから読み込むとパフォーマンスに影響し、一度にすべて読み込むとメモリ オーバーフローが発生する可能性があります。メモリオーバーフローを引き起こさずに効率を向上させるにはどうすればよいでしょうか? このとき、メモリ使用率を最大限に高め、メモリ容量が不足してOOMが発生しそうな場合には、メモリにロードされた画像を解放する必要がある。動作時にメモリに余裕があれば、メモリ内の画像を常に使用できます。 HashMap<String, Reference<Byte>> hashMap = new HashMap<>()
ファントム参照と参照キュー
ファントム参照の使用は参照キューと組み合わせて使用する必要があり、参照キューなしでファントム参照を使用しても意味がありません。
参照キュー
参照されたオブジェクトは破棄される前にインポート キューに入れられます。もう一方の端はこのキューをリッスンし、破棄されようとしているオブジェクトに対して何らかの後処理を実行できます。ソフト参照、弱参照、ファントム参照はすべて可能です
。構築中に参照キューを指定します。ファントム参照は、構築時に指定された参照キューを使用する必要があります。
次のファントム参照は、参照キューと組み合わせて使用されます。
public class Application {
public static void main(String[] args) throws InterruptedException {
ReferenceQueue<Object> referenceQueue = new ReferenceQueue<>();
User u1 = new User("张三");
WeakReference<Object> weakReference = new WeakReference<>(u1, referenceQueue);
u1=null;
new Thread(()->{
while (referenceQueue.poll()==null){
}
System.out.println("对象被销毁");
}).start();
System.gc();
TimeUnit.SECONDS.sleep(1);
}
}
ほとんど使われません
仮想リファレンス PhantomReference
ファントム: 幽霊、幻想、ファントム参照は参照オブジェクトを取得できません。その唯一の用途は、参照キューと結合することです。これにより、参照オブジェクトが破棄される前に参照キューに追加され、その後の処理を実行できます。紹介キューのもう一方の端。ファントム参照の使用はクラスに追加の影響を与えず、めったに使用されません。
public class Application {
public static void main(String[] args) throws InterruptedException {
User user = new User("张三");
ReferenceQueue<Object> referenceQueue = new ReferenceQueue<>();
PhantomReference<User> reference = new PhantomReference<>(user, referenceQueue); // 在创虚引用对象时就要指定消息队列
System.out.println(reference.get()); //尝试获取虚引用引用的对象
user=null;
new Thread(()->{
while (referenceQueue.poll()==null){
}
System.out.println("虚引用引用的对象被销毁");
}).start();
System.gc();
TimeUnit.SECONDS.sleep(1);
}
}
結果:

考えてみます: 破棄される前に、他の参照キューを参照キューに追加できますか?
滅多に使えませんが、ファントムリファレンスにしかこの機能がないので特別に紹介します
概要: オブジェクトが再利用されるかどうかは、このオブジェクトへの参照数と参照方法を確認するだけで済みます。
ゴミの見分け方は以上でご紹介しましたが、次はゴミを見つけた後の対処方法です。
ガベージコレクションアルゴリズム
参照カウント
カウントが0の場合はゴミ、参照カウントがあれば+1、参照無効カウントがあれば-1となります。
このアルゴリズムは、ゴミをスキャンする参照カウント方法と組み合わせられますが、この方法には循環参照の問題があり、めったに使用されないため、参照カウントのアルゴリズム方法は使用されません。
コピー コピー
エリア A のジャンク以外の部分をエリア B にコピーし、エリア A をクリアします。この方法は、ヒープの若い世代に適しています。若い世代は少数のゴミではなく、移動量が比較的小さいためです。エデンエリアとサバイバーのfromエリアのゴミではない部分をサバイバーのtoエリアにコピーし、エデンエリアとサバイバーのfromエリアをクリアします。
この方法の方が効率が良く、to領域が全て空になったところからコピーを開始し、クリアはエデン領域とサバイバーのfrom領域を全てクリアするのでメモリの断片化が起こりません。
このアプローチの欠点
- Survivor の to 領域などの追加スペースが必要であり、from 領域と同じサイズである必要があり、Survivor 領域のメモリの半分は常に無駄になります
- エデンエリアの100%がゴミではないといった極端な状況の場合、有用な部分をコピーするのに時間がかかり、生存者がエリアに爆発してしまいます。そのため、生存率の低い場所に適しています(デフォルトでは、エデンエリア:生存者からエリア:生存者へ= 8:1:1)
マーク マークスイープ
マークの削除: 2 つの部分に分かれています。 1. すべての GC ルートを走査して、どの部分がガベージであるかをマークします。 2. ヒープ全体を走査して、ガベージをクリアします。STW (ストップ ザ ワールド) では、ゴミ箱のマークを付けるときとゴミ箱を消去するときの両方でアプリケーション全体を一時停止する必要があります。古い世代のほとんどのオブジェクトは 15 回の GC を経験しており、再びガベージになる可能性は比較的低いため、古い世代で発生します。
これには 2 つの大きな欠点があります。
- 非効率的であり、アプリケーション全体を一時停止する必要がある
- クリアするとメモリが不連続になり、過剰なメモリの断片化が発生します。その後、JVM はメモリの空きリストを維持する必要があり、これもオーバーヘッドとなります。さらに、配列オブジェクトを配置する場合(大きなオブジェクトは古い領域にあります)、大きな連続した領域が必要となり、連続したメモリ領域を見つけるのは容易ではありません。
マークコンパクト
マークの仕上げ: 3 つの部分に分かれています。 1. すべての GC ルートを走査して、どの部分がガベージであるかをマークします。 2. ヒープ全体を走査して、ガベージをクリアします。3. 断片化を減らすためにメモリを整理します。マーキング アルゴリズムと比較すると、ソート ステップが 1 つ多くあり、メモリの断片化の問題は解決されますが、ソートに時間と CPU がかかるという新たな問題も生じます。
旧世代ではマーククリアとマーククリアの両方が発生し、両者を組み合わせて使用することが多く、マーククリアを複数回行った後は1回のクリアが行われます。これにより、時間とパフォーマンスのかかる頻繁なマーキングと並べ替えが回避されるだけでなく、メモリの断片化が妥当な範囲内に抑えられます。
これら 3 つのアルゴリズムにはそれぞれ、独自の長所と短所があります。完璧なアルゴリズムは存在せず、適切な長江に応じて適切なアルゴリズムを選択する必要があります。
上記のどのアルゴリズムがガベージコレクションを解決するためのアイデアであり、具体的な実装ツールは次のガベージコレクタです。
ガベージコレクターの種類
実際には、アルゴリズムに従って実装されたツールと、ガベージ コレクターが一般的にリサイクルする方法に応じて 5 つのカテゴリに分類されます。
シリアルコレクター
収集しているスレッドは 1 つだけであり、ガベージ コレクション時にはすべてのユーザー スレッドが一時停止されます。シングルスレッドのシナリオに適しています。たとえば、授業中に掃除に来る掃除婦は一人だけです。クラスを続けたい場合は、掃除婦が掃除を終えるまで待つしかありません。すべてのユーザー スレッドは、このスレッドが GC を完了するまで一時停止して待つ必要があるため、効率が低くなります。
具体的な実装方法はSerial、(若い世代向け)、Serial Old(古い世代向け)です。
パラレルコレクター
シリアル コレクターと比較すると、リサイクル時にスレッドが 1 つだけ存在するのではなく、複数のスレッドが一緒に参加します。これにより、一人が作業するのを待つ必要がなくなり、タスクの量は変わらないため、一人で作業する場合に比べて、複数人で作業することでユーザースレッドの待ち時間を短縮できます。
具体的な実装はParNew、(若い世代向け)、Parallel Scavenge(若い世代向け)、Parallel Old(古い世代向け)です。
同時コレクター
ユーザースレッドと回復スレッドは連携可能(一時停止はありますが、時間が短い)で、最大の特徴は長時間の一時停止がないことであり、ユーザーのインタラクション要求が強いシナリオに適しています。 。ユーザーは対話中に突然長時間停止することを望まないため、同時ガベージ コレクターを使用すると応答時間を短縮できます。
具体的な実装はCMS(旧世代向け)
G1
ZGC
考え方: 什么是STW?
STW: Stop という言葉は、ガベージ コレクション中にすべてのユーザー スレッドが一時停止され、フリーズ現象が発生することを意味します。
考え方:复制算法也会到导致STW吗?为什么要GC时要STW?
すべてのガベージ コレクターが STW を引き起こすのは時間の問題です。なぜなら、最終的にゴミが確認された時点で整合性を確保しておかないと、プログラムが実行され続け、参照関係が変化し続け、解析結果が不正確になってしまうからです。コピー中に一時停止がない場合、この期間中に作成されたオブジェクトは生存オブジェクトとしてマークされず、生存オブジェクトは生存領域に移動されずに消去され、強参照も消去され、プログラムが誤動作します。 。また、コピーアルゴリズムやマーキングアルゴリズムでは、参照元のオブジェクトのアドレスが変化します。引用の混乱を防ぎます。
一般的なガベージ コレクターの例
新しい世代
シリアル
スレッドのみが一个若い世代のコピー アルゴリズムを使用して、エデンの園内のすべての生存オブジェクトと生存者の From エリアから生存者の To エリアにコピーします。STW は GC 中に必要です。Serial Old ガベージ コレクターと連携できます。
パラレルスカベンジ
スレッドを開始し多个、若い世代のコピー アルゴリズムを使用して、エデンの園内のすべての生存オブジェクトと生存者の From エリアから生存者の To エリアにコピーします。STW は GC 中に必要ですが、複数のスレッドを使用して連携するため、STW の時間が短くなる可能性があります。
スループットは、パラメータ XX:MaxGCPauseMillis とスループットを直接制御するパラメータ -XX:GCTimeRatio によって設定できます。スループット = プログラム実行時間 / (プログラム実行時間 + GC 時間)。スループットを向上させると CPU 使用率が増加する可能性がありますが、応答速度とは関係がなく、必ずしもユーザー エクスペリエンスが向上するとは限りません。
で動作できますCMS垃圾回收器。Parallel Old垃圾回收器
パーニュー
これも複数スレッドによる GC であり、Parallel とは少し異なります (スループットは設定できません)。CMS垃圾回收器と連携できる
古い世代
古いシリアル
ガベージはシングルスレッド方式で収集され、ガベージ コレクション中はすべてのユーザー スレッドが一時停止されます。上記の若い世代のシリアルに似ていますが、古い世代では、メモリの断片化を引き起こさないマークアンドオーガナイズアルゴリズムが使用されます。
パラレルオールド
同時スレッドの回復は若い世代の Parallel と同様ですが、古い世代で採用されているマーキング アルゴリズムはメモリの断片化を引き起こしません。
CMS
CMS の完全名: concurrent mark sweep、翻訳は同時クリアリングです。
CMSの4段階
初始标记: 古い領域内のすべての GC ルート、つまりルート ノードをスキャンします。この間はルートノードの変更が停止されるためSTWとなりますが、GCルートが比較的少ないためSTW時間は比較的短くなります- 同時マーキング: 初期段階ですべてのルート ノードがスキャンされているため、この段階では、ルート ノードに沿って参照できないオブジェクトをスキャンして、それらをガベージとしてマークするだけで済みます。この間、ユーザースレッドと並行して実行されます。通常、ルート ノード以下のノードの数がルート ノードよりも多いため、比較的時間がかかりますが、ユーザー スレッドと並行して実行されるため、STW はありません。欠点は、このノードのパフォーマンスがより多く消費されることです。
重新标记: ユーザースレッドは実行中にガベージをスキャンするため、ガベージが追加される可能性があります。これは、最終的なハウスクリーニングのためにすべてのユーザー スレッドを一時停止するためです。このプロセスで新しく追加されたガベージを再度マークして、クリーニングが完全であることを確認します。また、同時実行によって生成されたガベージが不明になることはありません。このステージはSTWですがゴミの追加が少ないので時間は短めです。- 同時クリア: ここではすべてのガベージがマークされ、残りはクリアされます (クリア アルゴリズムはマーク クリアを使用します)。クリーンアップされたスレッドは、ユーザー スレッドと並行して実行できます。
CMSの最大の特徴はSTWが短く、インタラクション中にシステムが短時間フリーズするため、ユーザーとのインタラクションでの使用に適しています。
ただし、CMS には 2 つの大きな欠点があります。
- 同時クリアの処理では、ユーザースレッドが一時停止されないため、古い世代に新しいデータが追加される可能性があります(古い世代に直接配置された大きなオブジェクトなど)。そのため、データがいっぱいになってもクリアされません。ただし、ある程度のスペースが確保されています。例: 10% ただし、古い世代に入る新しいデータが同時消去プロセス中に予約値の 10% を超えると、その時点では古い世代用のスペースがなくなり、トリガーされます。 CMS は
Concurrent Mode FailureSerial Old ガベージ コレクターに縮退します。すべてのユーザー スレッドを一時停止し、シングル スレッド方式でリサイクルします。深刻な遅れを引き起こします。予約スペースが大きいとフル GC が頻繁に発生し、予約スペースが小さいと CMS リサイクルの失敗が発生します。 - CMS で採用されているアルゴリズムは同時消去アルゴリズムであるため、メモリの断片化が発生します。フラグメントが多すぎる場合、シリアル GC がトリガーされ、シングルスレッドのマーク編成アルゴリズムがクリアとデフラグに使用されます。
考察: なぜ CMS は断片化の問題を解決するためにマークアップ アルゴリズムを使用しないのでしょうか?
照合アルゴリズムが使用されている場合、同時クリーンアップ中にオブジェクトのアドレスが変更される可能性があり、すべてのユーザー スレッドの一時停止が必要になります。
若い世代 + 古い世代
G1
GC ガベージ コレクターの構成と使用法、JVM の一部のパラメーターとコマンド、Linux と組み合わせた JVM のチューニングについては、今後のブログで紹介する予定です。間違いを見つけた場合は、一緒に議論してください。