前回の記事では、相関ルール マイニング アルゴリズム Apriori を通じて実装できるレコメンデーション システム ARL (Association Rule Learning) について紹介しましたが、今日はコンテンツ ベースのフィルタリングを通じてレコメンデーション システムを実装する方法について説明します。
コンテンツベースのフィルタリングは、レコメンダー システムとしてよく使用されるもう 1 つの方法です。コンテンツの類似性は製品メタデータに基づいて計算され、ユーザーが過去に購入した製品に最も類似した推奨事項を作成するオプションを提供します。
メタデータは製品/サービスの特性を表します。たとえば、映画の監督、俳優、脚本家、著者、裏表紙の記事、本の翻訳者、商品のカテゴリ情報などです。(なぜ外部データを使用するのかは聞かないでください)

この画像には、ユーザーが好きな映画の説明が含まれています。ユーザーのお気に入りの映画に基づいて映画を推奨するには、これらの記述を使用して数学的形式を取得する必要があります。つまり、テキストが測定可能である必要があり、その後、他の映画と比較して同様の記述を見つける必要があります。
さまざまな映画とその映画に関するデータがあります。これらのムービー データを比較できるようにするには、データをベクトル化する必要があります。これらの説明をベクトル化する場合、すべての映画説明 (n としましょう) とすべての映画 (m としましょう) にわたって一意の単語のマトリックスを作成する必要があります。列にはすべてのユニークな単語、行にはすべての映画があり、交差点の映画で各単語がどのくらい使用されているかがわかります。このようにして、テキストをベクトル化できます。
コンテンツベースのフィルタリング手順:
- テキストを数学的に表現します (テキストのベクトル化):
- カウントベクトル
- 特別委員会 - IDF
2. 類似度を計算する
1. テキストのベクトル化
テキストのベクトル化は、テキスト処理、テキスト マイニング、自然言語処理に基づく最も重要なステップです。テキストをベクトルに変換し、その類似距離を計算するなどの方法が、データ分析の基礎となります。テキストをベクトルで表現できる場合は、数学的演算を実行できます。
テキストをベクトルとして表す 2 つの一般的な方法は、カウント ベクトルと TF-IDF です。
- カウントベクトル:
- ステップ 1 : すべての一意の用語が列に配置され、すべてのドキュメントが行に配置されます。

- ステップ 2 : 文書内の用語の出現頻度を交点のセルに配置します。

- TF-IDF:
TF-IDF は、テキストとコーパス全体 (対象となるデータ) の両方の単語頻度に対して正規化プロセスを実行します。言い換えれば、文書用語行列、コーパス全体、すべての文書、および用語の頻度を考慮して、作成する単語ベクトルの一般的な正規化を行います。これにより、カウント ベクトルによるバイアスの一部が排除されます。
- ステップ 1 : カウント ベクタライザー (各ドキュメント内の各単語の頻度) を計算します。

- ステップ 2 : TF (期間頻度) を計算する
(関連文書内の用語 t の頻度) / (文書内の用語の総数)

- ステップ 3 : IDF (逆ドキュメント頻度) を計算する
1 + loge((文書数 + 1) / (用語 t を含む文書数 + 1))
サンプルチェックファイル総数:4

単語 t がコーパス全体に頻繁に出現する場合、関連単語がコーパス全体に影響を与えていることを意味します。この場合、正規化はコーパス全体にわたる用語と通過頻度に対して実行されます。
- ステップ 4 : TF * IDF を計算する

- ステップ 5 : L2 正規化
行の平方和の平方根を求め、対応するセルを見つかった値で除算します。
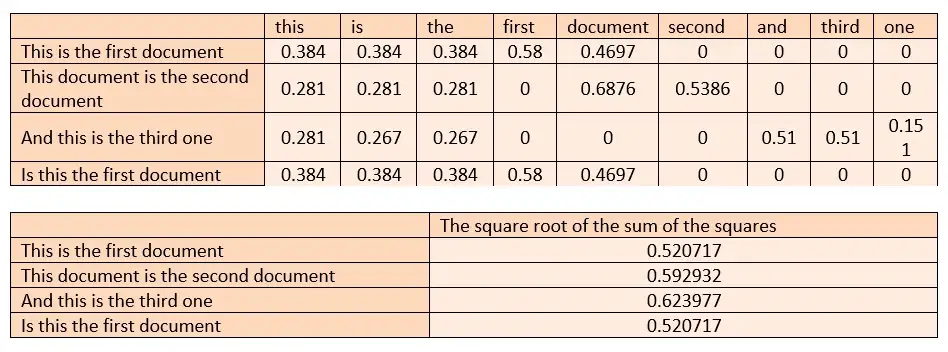
L2正規化は、一部の行に欠損値があり効果を発揮できない単語を再度修正します。
2. 類似度を計算する
説明に n 個の固有の単語が含まれる m 個の映画があるとします。これらの映画とのコンテンツベースの類似点をプログラムで見つける前に、実際にこれを行う方法を見てみましょう。
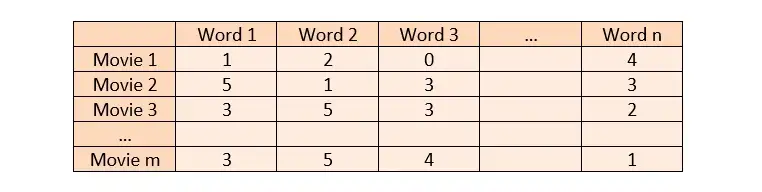
ユークリッド距離またはコサイン類似度を使用して、ベクトル化された映画の類似性を見つけることができます。
- ユークリッド距離:
ユークリッド距離を計算することで、2つの動画間の類似性を表す距離値を求めることができます。距離が近づくにつれて類似性が高まっていることがわかります。このようにして、推薦処理を行うことができる。
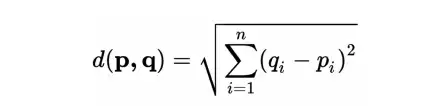
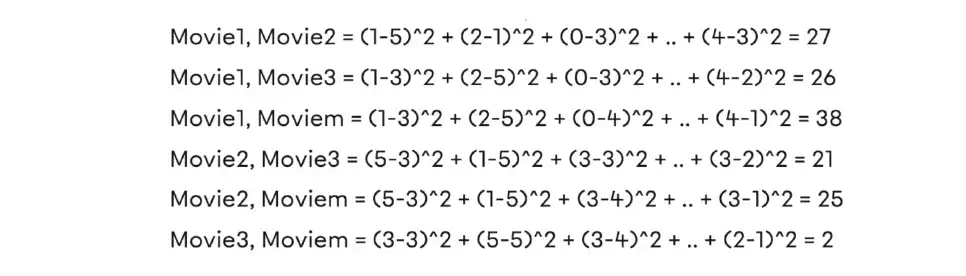
- コサイン類似度:
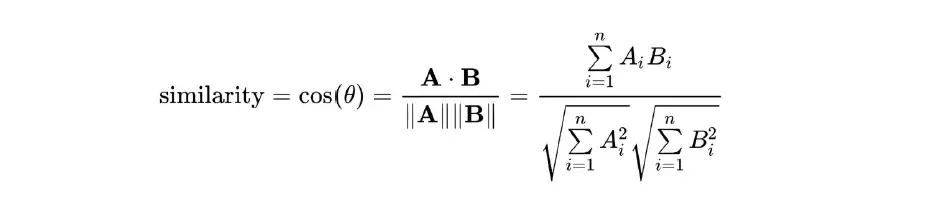
ユークリッドには距離の概念があり、コサイン類似度には類似度の概念があります。ここでは、距離の近接性と類似性の非類似性は同じ概念に対応します。
コンテンツ ベースのフィルタリングのロジックを紹介したので、コンテンツ ベースのフィルタリングの推奨事項を詳しく見てみましょう。
質問:
新しく設立されたオンライン映画プラットフォームは、ユーザーに映画を推奨したいと考えています。ユーザーのログイン率が非常に低いため、ユーザーの習慣が不明です。ただし、ユーザーがどの映画を視聴したかに関する情報には、ブラウザのパンくずリストからアクセスできます。この情報に基づいて、ユーザに映画を推奨することが望ましい。
データセットについて:
メインムービーメタデータファイル。Full MovieLens データセット内の 45,000 本の映画に関する情報が含まれています。特徴には、ポスター、背景、予算、収益、公開日、言語、制作国、会社が含まれます。
TF-ID マトリックスを作成します。
必要なライブラリはプロジェクトの開始時にインポートされ、データセットが読み込まれます。
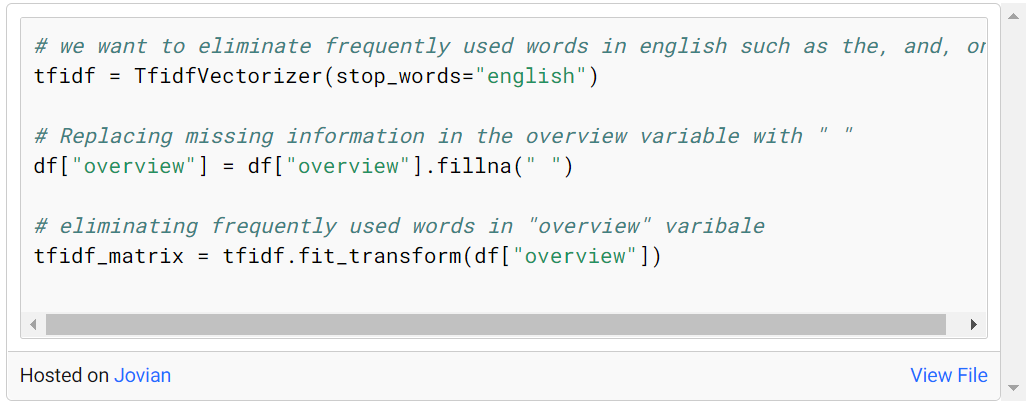
ここで適用される最初の手順は、TF-IDF メソッドを使用することです。このために、プロジェクトの最初にインポートされた TfidfVectorizer のメソッドが呼び出されます。stop_words='english' パラメーターを入力すると、その言語で一般的に使用される単語 (and、the、at、on など) を測定なしで削除できます。この理由は、作成される TF-IDF マトリックスにスパースな値があることに起因する問題を回避するためです。
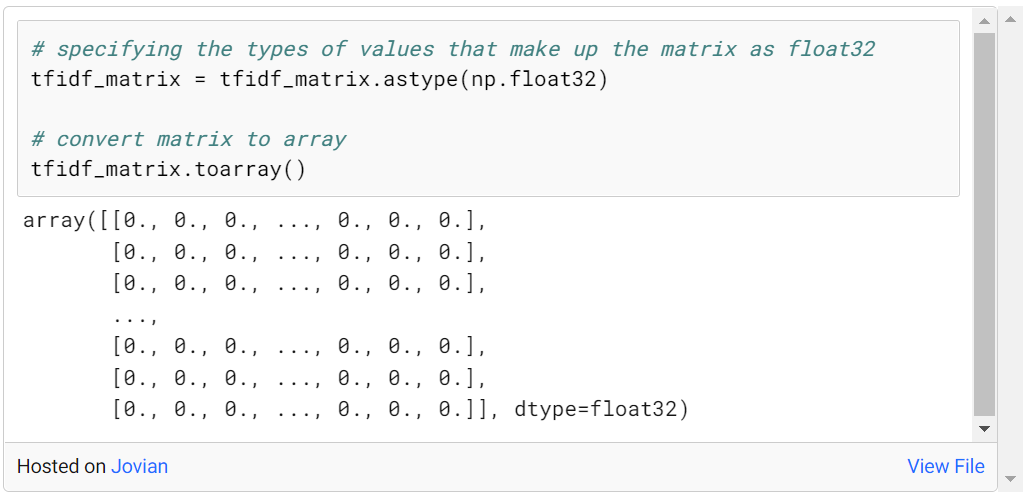
tfidf_matrix の形状は (45466, 75827) です。ここで、45466 はオーバービューの数、75827 は一意のワードの数です。このサイズのデータをより適切に処理できるようにするために、tfidf_matrix の交差部分の値を float32 に型キャストし、それに応じて処理します。
tfidf_matrix の交点のスコアが得られたので、コサイン類似度行列を構築し、映画間の類似性を観察できるようになりました。
コサイン類似度行列を作成します。
プロジェクトの最初にインポートされた cosine_similarity メソッドを使用して、各ムービーと他のムービーの類似性の値を見つけます。

たとえば、次のように、最初のインデックス内の映画と他のすべての映画の類似性スコアを見つけることができます。
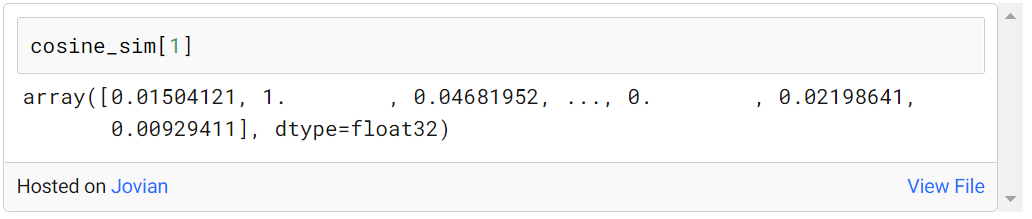
類似性に基づく提案:
類似度はコサイン類似度を使用して計算されますが、これらのスコアを評価するには映画のタイトルが必要です。このため、どの映画がどのインデックスにあるかを含むパンダ シリーズが として作成されますindices = pd.Series(df.index, index=df[‘title’])。
以下に示すように、いくつかの映画で多重化が観察されました。
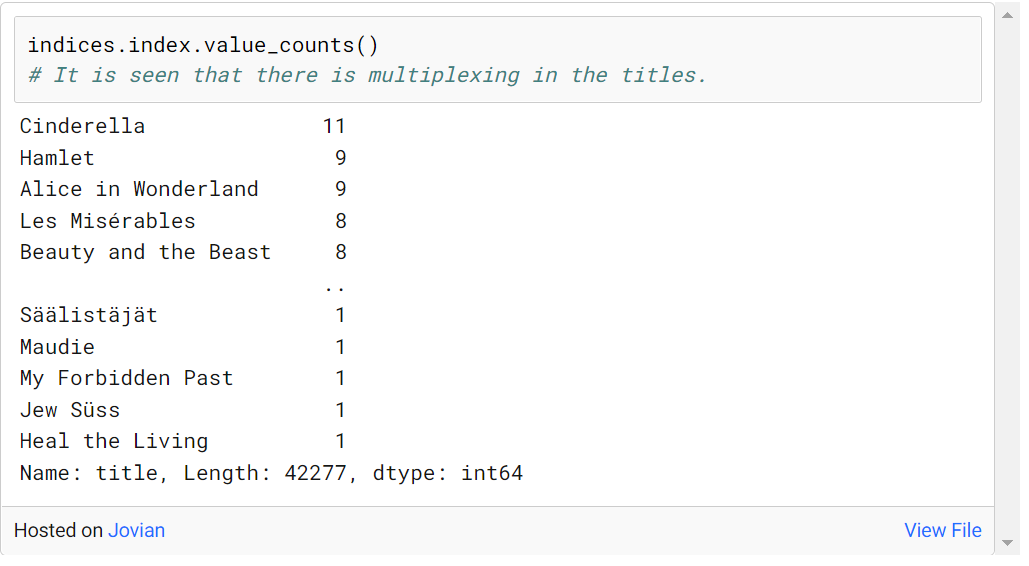
これらの倍数のうちの 1 つを保持し、残りを削除し、これらの倍数のうち最新の日付の最新のものを取得する必要があります。これは次のようにして実行できます。

操作の結果、各タイトルが単一になり、単一のインデックス情報を介してアクセスできることがわかります。
シャーロック ホームズに似た映画を 10 本見つけたいとします。まず、cosine_sim にシャーロック ホームズのインデックス情報を入力してシャーロック ホームズの映画を選択し、この映画と他の映画の類似関係を表すスコアにアクセスします。
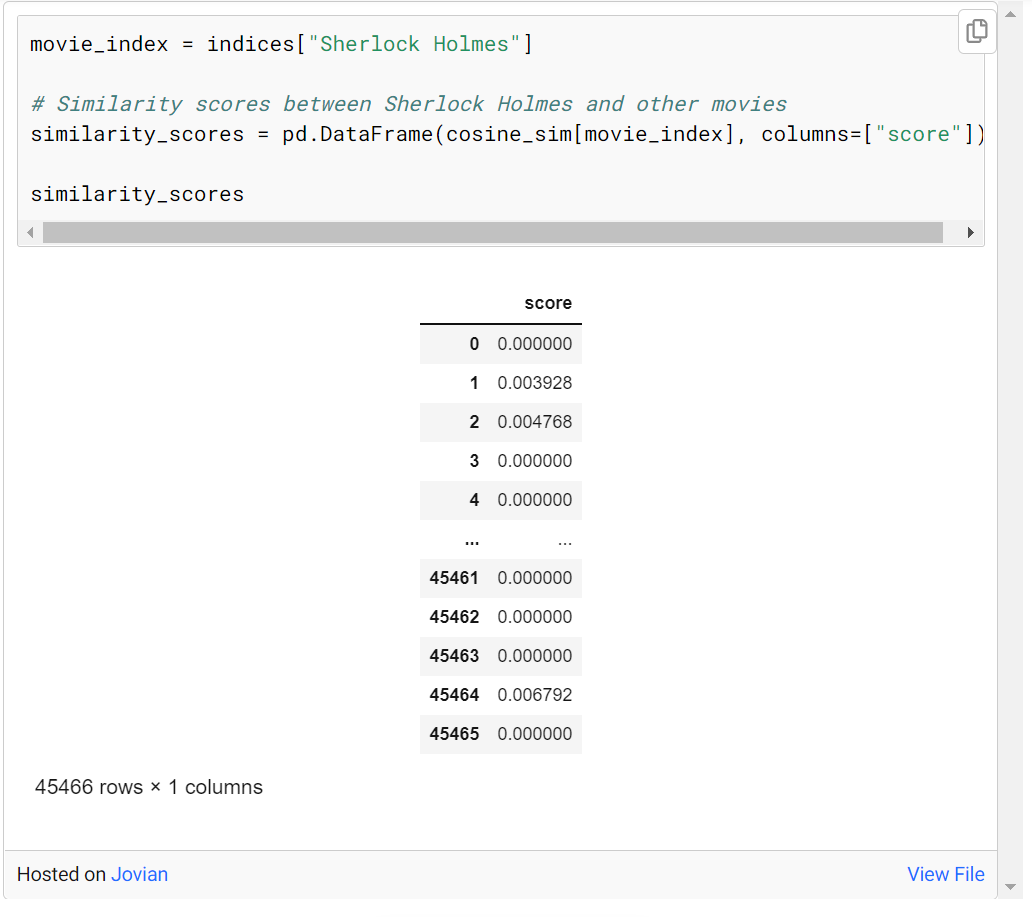
より読みやすい形式で、similarity_scores というデータ フレームが作成されました。cosine_sim[movie_index] に対する選択された類似度は、このデータ フレームの「スコア」変数として保存されます。

シャーロック映画に最も類似した 10 本の映画のインデックスが選択されています。これらのインデックスに対応する映画タイトルには、次のようにアクセスできます。

ここでは、シャーロック・ホームズに最もよく似た映画 10 本を紹介します。これらの映画は、シャーロック ホームズ-シャーロックを見たユーザーに推奨できます。さまざまな映画を試して、推奨結果を観察することもできます。
前回の記事では、相関ルール マイニング アルゴリズム Apriori を通じて実装できるレコメンデーション システム ARL (Association Rule Learning) について紹介しましたが、今日はコンテンツ ベースのフィルタリングを通じてレコメンデーション システムを実装する方法について説明します。
コンテンツベースのフィルタリングは、レコメンダー システムとしてよく使用されるもう 1 つの方法です。コンテンツの類似性は製品メタデータに基づいて計算され、ユーザーが過去に購入した製品に最も類似した推奨事項を作成するオプションを提供します。
メタデータは製品/サービスの特性を表します。たとえば、映画の監督、俳優、脚本家、著者、裏表紙の記事、本の翻訳者、商品のカテゴリ情報などです。(なぜ外部データを使用するのかは聞かないでください)
この画像には、ユーザーが好きな映画の説明が含まれています。ユーザーのお気に入りの映画に基づいて映画を推奨するには、これらの記述を使用して数学的形式を取得する必要があります。つまり、テキストが測定可能である必要があり、その後、他の映画と比較して同様の記述を見つける必要があります。
さまざまな映画とその映画に関するデータがあります。これらのムービー データを比較できるようにするには、データをベクトル化する必要があります。これらの説明をベクトル化する場合、すべての映画説明 (n としましょう) とすべての映画 (m としましょう) にわたって一意の単語のマトリックスを作成する必要があります。列にはすべてのユニークな単語、行にはすべての映画があり、交差点の映画で各単語がどのくらい使用されているかがわかります。このようにして、テキストをベクトル化できます。
コンテンツベースのフィルタリング手順:
- テキストのベクトル化
- カウントベクトル
- 特別委員会 - IDF
2. 類似度を計算する
1. テキストのベクトル化
テキストのベクトル化は、テキスト処理、テキスト マイニング、自然言語処理に基づく最も重要なステップです。テキストをベクトルに変換し、その類似距離を計算するなどの方法が、データ分析の基礎となります。テキストをベクトルで表現できる場合は、数学的演算を実行できます。
テキストをベクトルとして表す 2 つの一般的な方法は、カウント ベクトルと TF-IDF です。
- カウントベクトル:
- ステップ 1 : すべての一意の用語が列に配置され、すべてのドキュメントが行に配置されます。
- ステップ 2 : 文書内の用語の出現頻度を交点のセルに配置します。
- TF-IDF:
TF-IDF は、テキストとコーパス全体 (対象となるデータ) の両方の単語頻度に対して正規化プロセスを実行します。言い換えれば、文書用語行列、コーパス全体、すべての文書、および用語の頻度を考慮して、作成する単語ベクトルの一般的な正規化を行います。これにより、カウント ベクトルによるバイアスの一部が排除されます。
- ステップ 1 : カウント ベクタライザー (各ドキュメント内の各単語の頻度) を計算します。
- ステップ 2 : TF (期間頻度) を計算する
(関連文書内の用語 t の頻度) / (文書内の用語の総数)
- ステップ 3 : IDF (逆ドキュメント頻度) を計算する
1 + loge((文書数 + 1) / (用語 t を含む文書数 + 1))
サンプルチェックファイル総数:4
単語 t がコーパス全体に頻繁に出現する場合、関連単語がコーパス全体に影響を与えていることを意味します。この場合、正規化はコーパス全体にわたる用語と通過頻度に対して実行されます。
- ステップ 4 : TF * IDF を計算する
- ステップ 5 : L2 正規化
行の平方和の平方根を求め、対応するセルを見つかった値で除算します。
L2正規化は、一部の行に欠損値があり効果を発揮できない単語を再度修正します。
2. 類似度を計算する
説明に n 個の固有の単語が含まれる m 個の映画があるとします。これらの映画とのコンテンツベースの類似点をプログラムで見つける前に、実際にこれを行う方法を見てみましょう。
ユークリッド距離またはコサイン類似度を使用して、ベクトル化された映画の類似性を見つけることができます。
- ユークリッド距離:
ユークリッド距離を計算することで、2つの動画間の類似性を表す距離値を求めることができます。距離が近づくにつれて類似性が高まっていることがわかります。このようにして、推薦処理を行うことができる。
- コサイン類似度:
ユークリッドには距離の概念があり、コサイン類似度には類似度の概念があります。ここでは、距離の近接性と類似性の非類似性は同じ概念に対応します。
コンテンツ ベースのフィルタリングのロジックを紹介したので、コンテンツ ベースのフィルタリングの推奨事項を詳しく見てみましょう。
質問:
新しく設立されたオンライン映画プラットフォームは、ユーザーに映画を推奨したいと考えています。ユーザーのログイン率が非常に低いため、ユーザーの習慣が不明です。ただし、ユーザーがどの映画を視聴したかに関する情報には、ブラウザのパンくずリストからアクセスできます。この情報に基づいて、ユーザに映画を推奨することが望ましい。
データセットについて:
メインムービーメタデータファイル。Full MovieLens データセット内の 45,000 本の映画に関する情報が含まれています。特徴には、ポスター、背景、予算、収益、公開日、言語、制作国、会社が含まれます。
TF-ID マトリックスを作成します。
必要なライブラリはプロジェクトの開始時にインポートされ、データセットが読み込まれます。
ここで適用される最初の手順は、TF-IDF メソッドを使用することです。このために、プロジェクトの最初にインポートされた TfidfVectorizer のメソッドが呼び出されます。stop_words='english' パラメーターを入力すると、その言語で一般的に使用される単語 (and、the、at、on など) を測定なしで削除できます。この理由は、作成される TF-IDF マトリックスにスパースな値があることに起因する問題を回避するためです。
tfidf_matrix の形状は (45466, 75827) です。ここで、45466 はオーバービューの数、75827 は一意のワードの数です。このサイズのデータをより適切に処理できるようにするために、tfidf_matrix の交差部分の値を float32 に型キャストし、それに応じて処理します。
tfidf_matrix の交点のスコアが得られたので、コサイン類似度行列を構築し、映画間の類似性を観察できるようになりました。
コサイン類似度行列を作成します。
プロジェクトの最初にインポートされた cosine_similarity メソッドを使用して、各ムービーと他のムービーの類似性の値を見つけます。
たとえば、次のように、最初のインデックス内の映画と他のすべての映画の類似性スコアを見つけることができます。
類似性に基づく提案:
類似度はコサイン類似度を使用して計算されますが、これらのスコアを評価するには映画のタイトルが必要です。このため、どの映画がどのインデックスにあるかを含むパンダ シリーズが として作成されますindices = pd.Series(df.index, index=df[‘title’])。
以下に示すように、いくつかの映画で多重化が観察されました。
これらの倍数のうちの 1 つを保持し、残りを削除し、これらの倍数のうち最新の日付の最新のものを取得する必要があります。これは次のようにして実行できます。
操作の結果、各タイトルが単一になり、単一のインデックス情報を介してアクセスできることがわかります。
シャーロック ホームズに似た映画を 10 本見つけたいとします。まず、cosine_sim にシャーロック ホームズのインデックス情報を入力してシャーロック ホームズの映画を選択し、この映画と他の映画の類似関係を表すスコアにアクセスします。
より読みやすい形式で、similarity_scores というデータ フレームが作成されました。cosine_sim[movie_index] に対する選択された類似度は、このデータ フレームの「スコア」変数として保存されます。
シャーロック映画に最も類似した 10 本の映画のインデックスが選択されています。これらのインデックスに対応する映画タイトルには、次のようにアクセスできます。
ここでは、シャーロック・ホームズに最もよく似た映画 10 本を紹介します。これらの映画は、シャーロック ホームズ-シャーロックを見たユーザーに推奨できます。さまざまな映画を試して、推奨結果を観察することもできます。