基本的な紹介
Java を使用して XML ファイルを解析する実装方法と利点と欠点は、依然として面接の古典的な質問ですが、経験したことがない場合、または認識していない場合は、まだ昔のことです。日常業務で一般的な構成ファイルの種類には、xml、yml、プロパティ、ini、json、その他の形式が含まれます。一部の一般的で単純な構成は、もはや xml の第一の選択肢ではないかもしれませんが、xml 形式は最終的に放棄されることはありません。すべて、他の形式にはない、適切なアプリケーション シナリオと利点が数多くあります。
xml形式ファイルの解析では、dom、jdom、jom4j、sax、JDK6で追加されたJaxbコンポーネントがメモリ内でよく使われており、それぞれの実装の違いは別として、大規模なxmlファイルの解析も主にこれらの理解に依存します。各APIのコントロールでは、ここ数年、xmlファイルの解析にはJaxbが使われており、本当に便利で使いやすいのですが、昨年50Mを超えるxmlファイルに遭遇しました。ファイルが少し大きい場合 この状況では、最初に思い浮かぶのは、ファイルを一度に読み込んで XML 解析を使用することは絶対に不可能であるということです。つまり、上記のすべてのコンポーネントを使用することはできません。また、同僚の推奨に従って、Guava のファイル ツール クラス Files も使用しています。.asCharSource(file, charset).readLines(callback) を使用してファイルをセグメント化し、各セグメントのファイル コンテンツを取得して、それをバッチに結合しますXML コンテンツ セグメントを解析し、最後にすべてのコンテンツ セグメントをループして 1 回限りの読み取りを回避します。このファイルにより、サーバーにメモリ負荷がかかります。したがって、Guava の Files ツール クラスを使用して、キャッシュされたストリームの形式でファイルのコンテンツを 1 行ずつ読み取ることに重点を置きます。Apache Commons IO の FileUtils (同様のツール クラス) も、ファイルを行ごとに読み取る readLines 実装を提供します。最下層は IOUtils を使用します。最後の実装は、BufferedReader を使用してファイルを一度に読み取り、ファイルの内容を行ごとに読み取ります。 List<String> 。このメソッドは大きすぎるファイルには適していません。そうしないとメモリ オーバーフローが発生するため、小さいファイルを使用することをお勧めします。この記事で推奨されている Guava ファイルには readLines 関数もあります (上位バージョンには期限切れとしてマークされています)。asCharSource 関数を使用することをお勧めします。その基礎となる実装は LineProcessor (ライン プロセッサ) をサポートしています。生成と消費を同時に行うことができます適用時に時間を指定するか、バッチ消費後にバッチを生成すると同時に、行を読み取り、消費を待ってから次の行を読み取り、読み取ったデータはキューに格納されます。
この例は 2 つの部分に分かれています: 1. コードを使用して 150M xml ファイルを生成する xml ファイルの内容は規則的であり、内容は特定の行の先頭と特定のキーワードに従ってセグメントに書き込まれます。 line; 2. 特殊行の開始タグと終了タグに従ってファイルをセクション単位で読み込み、読み取った内容をコンソールに出力します(コンソールへの出力はデータの最終処理を模擬しています)。例 1 のファイルは比較的単純ですが、次の図に示すファイル構造の例を見てください。
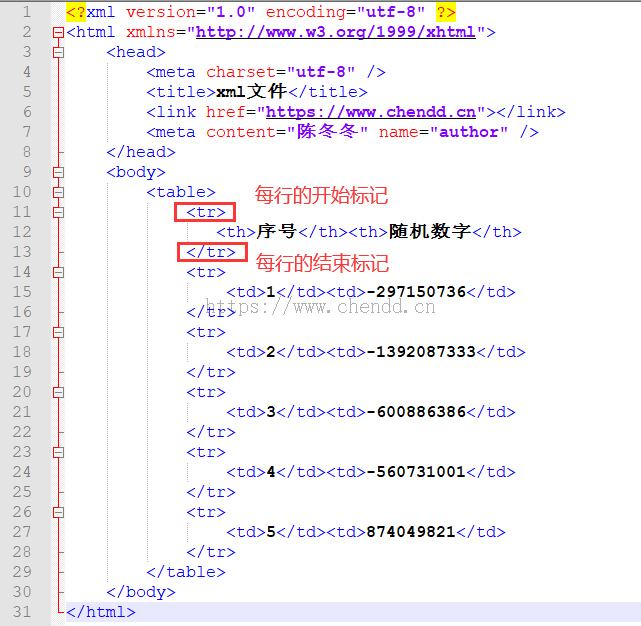
(ファイル形式の例。実際のファイルはヘッダー行 1 行、データ 200 万 2 個で示されています)
参照コード
データコンシューマーの定義
package cn.chendd.xml;
import java.util.List;
/**
* 按行读取文件内容的批量处理
*
* @author chendd
* @date 2023/2/18 8:51
*/
@FunctionalInterface
public interface RowBatchListProcessor {
/**
* 批量处理数据
* @param rows 文本数据
*/
void execute(List<String> rows);
}行ごとにバッチ読み取り
package cn.chendd.xml;
import com.google.common.io.LineProcessor;
import java.util.List;
/**
* 行解析实现
*
* @author chendd
* @date 2023/2/18 8:41
*/
public class RowLineProcessor implements LineProcessor<String> {
/**
* xml文件内容的行节点个数
*/
private static final int BATCH_SIZE = 200;
private List<String> rows;
private String beginMarker;
private String endMarker;
private RowBatchListProcessor processor;
/**
* 构造函数
* @param rows 文件行数据
* @param beginMarker 开始行标记
* @param endMarker 结束行标记
* @param processor 逻辑处理类
*/
public RowLineProcessor(List<String> rows , String beginMarker , String endMarker , RowBatchListProcessor processor) {
this.rows = rows;
this.beginMarker = beginMarker;
this.endMarker = endMarker;
this.processor = processor;
}
/**
* 单次获取的内容
*/
private StringBuilder textBuilder = new StringBuilder();
/**
* 是否开始读取文件
*/
private boolean begin = false;
@Override
public boolean processLine(String line) {
if (line.endsWith(beginMarker)) {
begin = true;
}
if (line.endsWith(endMarker)) {
begin = false;
textBuilder.append(line);
rows.add(textBuilder.toString());
textBuilder.setLength(0);
} else if (begin) {
textBuilder.append(line);
}
if (rows.size() > 0 && rows.size() % BATCH_SIZE == 0) {
processor.execute(rows);
rows.clear();
}
return true;
}
@Override
public String getResult() {
if (rows.isEmpty()) {
return null;
}
this.processor.execute(rows);
return null;
}
}電話の例
package cn.chendd.xml;
import com.google.common.collect.Lists;
import com.google.common.io.Files;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.junit.runners.JUnit4;
import java.io.File;
import java.io.IOException;
import java.net.URLDecoder;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 文件按行读取验证
*
* @author chendd
* @date 2023/2/18 9:59
*/
@RunWith(JUnit4.class)
public class RowLineReaderTest {
@Test
public void reader() throws IOException {
AtomicInteger atomicInteger = new AtomicInteger();
//批量数据解析实现
RowBatchListProcessor execute = rows -> {
System.out.println(String.format("第 %d 批数据处理,数据 %d 行!" , atomicInteger.addAndGet(1) , rows.size()));
};
RowLineProcessor processor = new RowLineProcessor(Lists.newArrayList() , "<tr>" , "</tr>" , execute);
Files.asCharSource(this.getFile(), Charset.defaultCharset()).readLines(processor);
}
private File getFile() throws IOException {
String fileFolder = URLDecoder.decode(getClass().getResource("").getFile() , StandardCharsets.UTF_8.name());
return new File(fileFolder , "data.xml");
}
}サンプル出力
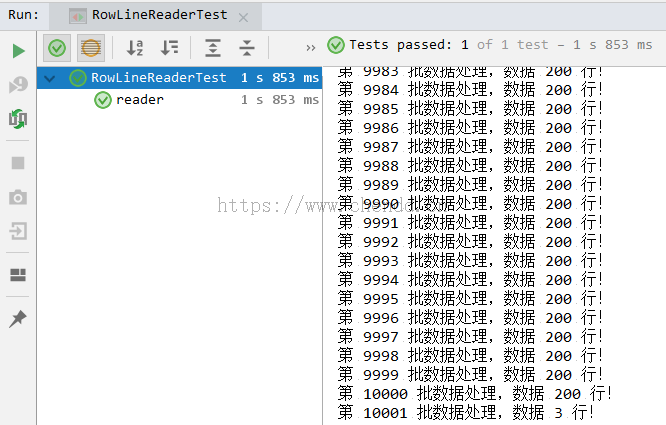
その他の指示
(1) IO バッファを使用してライン ストリームごとにファイルを読み取り、行の特別なマークを開始マークと終了マークとして使用し、ファイルの内容をセグメントで読み取り、読み取ったファイルを照合して、Jaxb マッピングを使用して解析します。 ;
(2) この例のコードの実装は、特殊な形式の開始行と終了行を持つ通常のファイルを解析することです。どの形式のファイルも解析できませんが、同様のルールでファイル解析に適用できます。
(3) この例では、XML の生成と XML 解析の 2 つの例を示します。データ項目の数は 200 万、ファイル サイズは 150M を超えています。
(4) ソース コード プロジェクトのダウンロードは、https: //gitee.com/88911006/chendd-examples/tree/master/xmlで確認できます。
(5) 詳細については、https://www.chendd.cn/blog/article/1626771133537509378.htmlをご覧ください。