記事ディレクトリ
序文
私はバックエンドの開発者ですが、業務上ビッグデータの知識を後々活用する必要があり、以前からHadoop関連の知識を勉強していました。今後も時間があるときにビッグデータの技術スタックを深く理解していきたいと思います。学びながら、まとめながら、途中で挫折しないようにしたいと思います。
スパークの基本
スパークとは
Apache Spark は、オープン ソースの分散コンピューティング フレームワークであり、大規模なデータ処理タスクを処理するように設計されており、大規模なデータ セットに対して高速なバッチ処理、ストリーム処理、機械学習操作を実行できます。
Spark 公式ウェブサイト: http://spark.incubator.apache.org/
スパークとハドゥープの違い
- データ処理モデル: Hadoop はデータ セット全体を一度に処理するバッチ処理モデルを使用しますが、Spark はデータ ストリームをリアルタイムで処理できるバッチ処理モデルとストリーム処理モデルの両方をサポートします。
- 処理速度: Spark は Hadoop よりも高速です。Spark の速度はメモリ コンピューティングとメモリ ベースのデータ共有メカニズムの助けを借りて向上しますが、Hadoop の速度はディスクの読み取りと書き込みの速度によって制限されます。
- プログラミング言語: Hadoop は主に Java でプログラムされていますが、Spark は Java、Scala、Python、R などの複数のプログラミング言語をサポートしています。
- メモリ管理: Spark は、データをメモリにキャッシュできる、より効率的なメモリ管理方法を採用していますが、Hadoop では頻繁なディスクの読み取りおよび書き込み操作が必要です。
- データベースのサポート: Spark は Hive、HBase、Cassandra などのさまざまなデータベースを使用できますが、Hadoop は主に HDFS を使用します。
- エコシステム: Hadoop には、Hive、Pig、MapReduce などのツールを含む巨大なエコシステムがありますが、Spark のエコシステムは比較的小さいですが、常に開発および成長しています。
Spark は、速度、処理モデル、プログラミング言語の点で Hadoop よりも柔軟で効率的であると同時に、Hadoop と互換性があり、Hadoop コンポーネントと併用してビッグ データ処理の選択肢と柔軟性を提供します。
スパークコアモジュール

Spark のコア モジュールには次のものが含まれます。
- Spark Core: Spark の基本モジュール。分散タスク スケジューリング、メモリ管理、フォールト トレランスなどの機能を提供します。Spark Core は、Scala、Java、および Python プログラミング言語をサポートする API セットを提供します。
- Spark SQL: リレーショナル データ処理をサポートする Spark の SQL クエリ モジュールは、SQL ステートメントを通じてデータをクエリでき、Hive などのデータ ウェアハウスと対話することもできます。
- Spark ストリーミング: Spark のストリーム処理モジュールは、リアルタイムのデータ ストリーム処理をサポートします。Spark Streaming は、リアルタイム データ ストリームを処理用のバッチ データに変換できる一連の API を提供します。
- MLlib: Spark の機械学習モジュール。分類、クラスタリング、回帰、協調フィルタリングなどのタスクをサポートする一連の機械学習アルゴリズム ライブラリを提供します。
- GraphX: グラフ データの処理と分析をサポートする Spark のグラフ処理モジュール。
これらのコア モジュールに加えて、Spark は次のような他の多くのモジュールと拡張機能を提供します。
- SparkR: Spark の R 言語インターフェイス。R で Spark を使用したデータ処理と分析をサポートします。
- PySpark: Spark の Python 言語インターフェイス。Python での Spark を使用したデータ処理と分析をサポートします。
- Spark Streaming Kafka: Spark Streaming での Apache Kafka との統合をサポートします。
- Spark Streaming Flume: Spark Streaming での Apache Flume との統合をサポートします。
これらのモジュールと拡張機能は、さまざまなデータ処理と分析のニーズに対応できます。
スパークランニングモード
- ローカル モード: 開発、テスト、デバッグのためにローカル マシン上で Spark アプリケーションを実行します。
- スタンドアロン モード: Spark 独自のクラスター マネージャーを使用して Spark アプリケーションを実行します。複数ノードのクラスターへのアプリケーションのデプロイをサポートします。スタンドアロン モードで高可用性を実現する必要がある場合は、スタンドアロン HA モードを使用できます。
- スタンドアロン HA モード: 高可用性はスタンドアロン モードで実現されます。ZooKeeper を使用してマスター ノードの選択と障害回復を調整することで、マスター ノードに障害が発生したときに Spark アプリケーションが自動的にスタンバイ ノードに切り替わることが保証されます。
- YARN モード: Apache Hadoop YARN クラスター上で Spark アプリケーションを実行します。YARN は、Spark を含むさまざまな分散アプリケーションの操作をサポートする Hadoop クラスター管理システムです。
- Mesos モード: Apache Mesos クラスター上で Spark アプリケーションを実行します。Mesos は、Spark を含むさまざまな分散アプリケーションの運用をサポートする汎用クラスター管理システムです。
- クラウド モード: Spark アプリケーションをデプロイして、Amazon EMR、Google Cloud Dataproc などのクラウド プラットフォーム上で実行します。
将来的には、いくつかの一般的なメソッドを詳細に実装する予定です。
Spark ランニング アーキテクチャ
運営体制

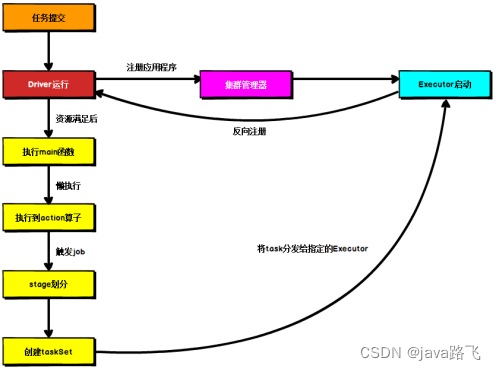
Spark 実行アーキテクチャは主に次の 4 つのコンポーネントで構成されます。
- ドライバー: ドライバー プログラムはマスター ノード上で実行されるプロセスであり、タスクのスケジュール設定、リソースの割り当て、タスクの実行結果の収集と要約など、アプリケーション全体の実行プロセスの制御を担当します。ドライバー プログラムはクラスター マネージャーにリソースを要求し、クラスター内の実行プログラムにタスクを配布して実行します。
- エグゼキュータ: エグゼキュータはワーカー ノード上で実行されるプロセスであり、ドライバー プログラムによって割り当てられたタスクを実行し、タスクの実行結果をドライバー プログラムに返す責任があります。各 Executor には独自の JVM プロセスがあり、タスクの実行中にデータをキャッシュしてタスクの実行を高速化できます。
- クラスター マネージャー: クラスター マネージャーは、クラスター リソースの管理に使用されるコンポーネントです。Spark は、スタンドアロン、Apache Mesos、Hadoop YARN などのさまざまなクラスター マネージャーをサポートします。クラスター マネージャーは、ドライバー プログラムの要求を受信し、ドライバー プログラムに適切なエグゼキューターとリソースを割り当てる責任があります。
- Spark アプリケーション: Spark アプリケーションは、ドライバー プログラムと一連のタスクで構成される分散アプリケーション プログラムです。ドライバー プログラムはアプリケーション プログラム全体の実行プロセスを制御し、タスクは Executor 上で実行されます。Spark アプリケーションは、Spark SQL、Spark Streaming、Spark MLlib などのコンポーネントを作成することで、さまざまなデータ処理および分析タスクを実装できます。
Spark のオペレーティング アーキテクチャでは、ドライバー プログラムとエグゼキューターがネットワーク通信を通じてデータとタスクを渡し、クラスター マネージャーがリソースのスケジュールとクラスターの管理を担当します。Spark はメモリ コンピューティングを使用するため、データの処理と分析の速度と効率を大幅に向上させることができます。
エグゼキューターとコア (コア)
Spark では、エグゼキュータはワーカー ノード上で実行されるプロセスであり、ドライバー プログラムによって割り当てられたタスクを実行し、タスクの実行結果をドライバー プログラムに返す責任があります。各 Executor には独自の JVM プロセスがあり、タスクの実行中にデータをキャッシュしてタスクの実行を高速化できます。
Core(コア)とはExecutor内の計算リソース単位であり、各Executorは複数のCoreから構成されます。コアの数は通常、ハードウェア構成によって決まります。たとえば、ノードに 16 個の CPU コアがある場合、Executor は 8 個のコアを使用するように構成できます。
Spark では、Executor の数と各 Executor が使用するコアの数を構成ファイルを通じて設定できます。Executor の数と各 Executor が使用するコアの数を増やすことにより、Spark アプリケーションの並列性と実行速度を向上させることができます。ただし、エグゼキュータの数が多すぎる場合、または各エグゼキュータが使用するコアの数が多すぎる場合、リソースが無駄になったり不十分になったりして、Spark アプリケーションのパフォーマンスと安定性に影響を与える可能性があります。したがって、エグゼキュータとコアの数を設定するときは、特定のアプリケーション シナリオとハードウェア構成に従って調整する必要があります。
アプリケーション関連の起動パラメータは次のとおりです。
| 名前 | 説明する |
|---|---|
| –num-executors | エグゼキュータの数を構成する |
| –エグゼキュータメモリ | 各 Executor のメモリ サイズを構成する |
| –executor-cores | 各エグゼキュータの仮想 CPU コアの数を構成する |
平行度
並列処理とは、複数のタスクまたはデータを同時に処理できる機能を指します。コンピューターサイエンスでは、アプリケーションまたはシステムが同時に処理できるタスクまたはデータの数を表すためによく使用されます。Spark では、並列処理とは、Spark アプリケーションで複数のタスクまたはデータを同時に処理する能力を指し、通常はエグゼキューターの数と各エグゼキューターで使用されるコアの数で表されます。
Spark アプリケーションでは、並列度を高めるとタスク実行の速度と効率が向上し、データの処理と分析が高速化されます。実際のアプリケーションでは、並列性を向上させるために主に次の方法があります。
- エグゼキュータの数を増やす: エグゼキュータの数を増やすと、Spark アプリケーションの並列処理が増加し、タスクの実行が高速化されます。Executor の数を増やすには、ハードウェア構成とアプリケーションのリソース消費に基づいた適切な設定が必要であることに注意してください。
- 各 Executor が使用するコアの数を増やす:各 Executor が使用するコアの数を増やすことで、各 Executor の計算能力が向上し、タスクの実行が高速化されます。コアの数を増やすには、ハードウェア構成とアプリケーションのリソース消費に基づいた適切な設定も必要になることに注意してください。
- データ パーティショニングを使用する: データ パーティショニングは、並列処理のための特定のルールに従ってデータを複数の部分に分割するテクノロジです。データ パーティションを使用すると、データを異なる Executor に分散して処理できるため、並列性と実行効率が向上します。
- 並列アルゴリズムの使用: 並列アルゴリズムは、複数のプロセッサで同時に実行できるアルゴリズムです。並列アルゴリズムを使用すると、タスクを複数の部分に分解して並列処理できるため、並列性と実行効率が向上します。
有向非巡回グラフ (DAG)
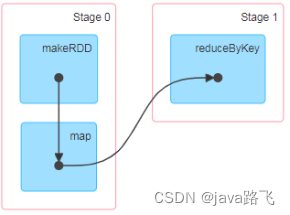
有向非巡回グラフ (略して DAG) は、有向辺で接続されたノードで構成されるグラフ構造です。この構造には循環がなく (つまり、辺で接続されたノードはリングを形成できません)、通常はそれが使用されます。計算プロセスまたはデータ処理プロセスの依存関係を記述するために使用されます。
Spark では、DAG は非常に重要な概念であり、Spark アプリケーションのデータ処理プロセスを記述するために使用されます。Spark アプリケーションでは、DAG は一連の RDD (Resilient Distributed Dataset) と変換操作で構成されます。各 RDD は分散データ セットを表し、変換操作は RDD の変換と計算に使用されます。Spark アプリケーションのすべての操作は新しい RDD を生成し、それを DAG に結合します。DAG 内の各ノードは RDD を表し、各有向エッジは変換演算を表します。
Spark アプリケーションでは、DAG の生成と最適化は Spark のタスク スケジューラの責任です。Spark アプリケーションが実行するためにクラスターに送信されると、Spark はアプリケーション内の各操作を一連のタスクに変換し、依存関係に従ってタスクを DAG に編成します。その後、Spark はタスクの実行効率と並列性を向上させるために、隣接するオペレーションをマージしたり、無駄なオペレーションを削除したりするなど、DAG を最適化します。最後に、Spark は DAG を複数のステージに分割し、各ステージを並行して実行できるため、タスクの実行効率が向上します。
簡単に言うと、DAG はデータ処理プロセスの依存関係を記述するために使用されるグラフ構造です。Spark では、DAG は RDD 間の変換関係や操作シーケンスを記述するために使用されます。DAG を通じて、タスクの実行計画を最適化できます。タスクの並列性と実行効率を向上させます。
スパークの提出方法
クライアント
クライアント モードでは、ドライバー プログラムは Spark アプリケーションを送信するクライアント プロセスで実行され、エグゼキューター プログラムはクラスター内のコンピューティング ノードで実行されます。この送信方法は、アプリケーションの実行ステータスと結果の表示とデバッグが容易になるため、デバッグ環境や開発環境でよく使用されます。
集まる
クラスター モードでは、ドライバー プログラムはクラスター内のノードで実行され、エグゼキューター プログラムもクラスター内の他のノードで実行されます。この送信方法は、クラスター リソースをより有効に活用し、タスクの並列処理と実行効率を向上させることができるため、通常は運用環境で使用されます。
国内の作業では、Spark 参照を Yarn 環境にデプロイする可能性が高いため、このコースの提出プロセスは Yarn 環境に基づいています。
Sparkコアプログラミング
3 つの主要なデータ構造
-
RDD (Resilient Distributed Datasets): RDD は、Spark の最も基本的な分散データ構造の 1 つであり、分散オブジェクトの不変のコレクションです。RDD の各パーティションにはデータの一部が格納され、クラスター内の複数のノードに分散されます。RDD は、RDD を変換および計算できる多数の変換およびアクション操作を提供します。
-
アキュムレータ: アキュムレータは、分散環境で並列操作できる特別な変数です。アキュムレータは加算演算のみを実行でき、ドライバ側からエグゼキュータ側へのデータの蓄積のみが可能であり、その逆はできません。アキュムレータは主に、カウントや合計などの集計操作に使用されます。
-
ブロードキャスト変数: ブロードキャスト変数は、クラスター全体で共有できる読み取り専用変数です。分散コンピューティングのプロセスにおいて、いくつかの変数を複数のノード間で共有する必要がある場合、これらの変数はブロードキャスト変数を使用して送信できます。ブロードキャスト変数は 1 回だけ送信され、その後の使用のために Executor 側にキャッシュされるため、ネットワーク送信とメモリ使用量が削減されます。
RDD
RDDとは
RDD (Resilient Distributed Datasets) は、Spark の最も基本的な分散データ構造の 1 つであり、分散オブジェクトの不変のコレクションです。RDD の各パーティションにはデータの一部が格納され、クラスター内の複数のノードに分散されます。RDD は、RDD を変換および計算できる多数の変換およびアクション操作を提供します。
RDDの特徴は以下の通りです。
- 分散: RDD のデータはクラスターの複数のノードに分散され、並列コンピューティングが可能になります。
- 不変性: RDD は不変であり、一度作成すると変更することはできません。RDD を変換する必要がある場合は、新しい RDD を生成する必要があります。
- 耐障害性:RDDはデータの分割とバックアップにより耐障害性を実現します。ノードに障害が発生した場合は、バックアップからデータを再計算できます。
遅延計算: Spark の変換操作は遅延計算され、データはアクション操作が実行されたときにのみ実際に計算されます。
実行の原則
Yarn 環境では、Spark の RDD は次のように動作します。
- まず、Driver プログラムは ResourceManager にリソースを要求し、ApplicationMaster を開始します。
- ApplicationMasterはResourceManagerからコンテナを申請し、コンテナ内のExecutorを起動します。
- Executor は Driver プログラムに RDD を要求し、データを複数のパーティションに分割してメモリに保存します。
- Driver プログラムは、実行されるタスク (変換操作やアクション操作を含む) を Executor に配布して実行します。
- Executor では、タスクは依存関係の観点から有向非巡回グラフ (DAG) に編成されます。
- Driver プログラムがアクションを実行すると、タスクは実行のために Executor に送信されます。タスクが他のタスクの出力に依存している場合、そのタスクは前のタスクが完了した後に実行されます。
- 実行が完了すると、Executor は結果を Driver プログラムに返します。
RDD API
RDDの作成
- メモリ内のコレクション (並列化されたコレクション) から RDD を作成します。
val rdd = sc.parallelize(1 to 100)
- 外部ストレージ システム (HDFS、ローカル ファイル システムなど) からデータを読み取って RDD を作成する:
SparkContext.textFile() メソッドを使用して、1 つ以上のファイルからテキスト ファイルの RDD を作成します。たとえば、次のコードを使用して HDFS からファイルを読み取り、RDD を作成できます。
val rdd = sc.textFile("hdfs://localhost:9000/data.txt")
- 既存の RDD を変換して新しい RDD を作成する:
既存の RDD に対して一連の変換操作を実行することで、新しい RDD を作成できます。たとえば、次のコードを使用して、各数値が 2 倍になった新しい RDD を作成できます。
val rdd1 = sc.parallelize(1 to 100)
val rdd2 = rdd1.map(_ * 2)
- 既存のデータセットを並列化して RDD を作成する:
SparkContext.newAPIHadoopRDD() メソッドを使用して、既存の Hadoop 入力形式 (TextInputFormat など) から RDD を作成します。たとえば、次のコードを使用して、Hadoop 入力形式のファイルから RDD を作成できます。
val conf = new Configuration()
val file = sc.newAPIHadoopFile("hdfs://localhost:9000/data.txt", classOf[TextInputFormat], classOf[LongWritable], classOf[Text], conf)
val rdd = file.map(pair => pair._2.toString)
RDD変換演算子
| 変換演算子 | 意味 |
|---|---|
| マップ(機能) | func 関数によって変換された各入力要素で構成される新しい RDD を返します。 |
| フィルター(関数) | func 関数による評価後に true を返す入力要素で構成される新しい RDD を返します。 |
| flatMap(関数) | Map と似ていますが、各入力要素は 0 個以上の出力要素にマップできます (したがって、 func は単一の要素ではなくシーケンスを返す必要があります)。 |
| マップパーティション(関数) | Map と似ていますが、RDD の各スライスで独立して動作するため、タイプ T の RDD で動作する場合、func の関数タイプは Iterator[T] => Iterator[U] である必要があります。 |
| MapPartitionsWithIndex(関数) | mapPartitions と似ていますが、func にはパーティションのインデックス値を表す整数パラメータがあるため、タイプ T の RDD で実行する場合、func の関数タイプは (Int, Interator[T]) => Iterator[U] である必要があります。 |
| サンプル(代替品、フラクション、シード付き) | データはfractionで指定された比率に従ってサンプリングされ、置換に乱数を使用するかどうかを選択できます。seedは乱数生成器のシードを指定するために使用されます。 |
| ユニオン(その他のデータセット) | ソース RDD とパラメータ RDD を結合した後の新しい RDD を返します。 |
| 交差点(その他のデータセット) | ソース RDD とパラメータ RDD を交差させた後、新しい RDD を返します。 |
| unique([numTasks])) | ソース RDD を重複排除した後、新しい RDD を返します。 |
| groupByKey([タスク数]) | (K, V) の RDD で呼び出され、(K, Iterator[V]) の RDD を返します。 |
| reduceByKey(func, [numTasks]) | (K, V) RDD で呼び出され、(K, V) RDD を返します。指定された Reduce 関数を使用して同じキーの値を集計します。groupByKey と同様に、Reduce タスクの数は、設定する 2 番目のオプションのパラメータ |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | 集約操作は、PairRDD 内の同じ Key 値に対して実行され、中立の初期値も集約プロセスで使用されます。集計関数と同様に、aggregateByKey の戻り値の型は、RDD の値の型と一致している必要はありません。 |
| sortByKey([昇順], [タスク数]) | (K, V) RDD で呼び出される場合、K は Ordered インターフェイスを実装し、キーでソートされた (K, V) RDD を返す必要があります。 |
| sortBy(func, [昇順], [numTasks]) | sortByKey に似ていますが、より柔軟です |
| join(otherDataset, [numTasks]) | (K, V) および (K, W) 型の RDD で呼び出され、同じキーに対応する要素のすべてのペアの (K, (V, W)) RDD を返します。 |
| cogroup(otherDataset, [numTasks]) | (K,V) および (K,W) 型の RDD で呼び出され、(K,(Iterable,Iterable)) 型の RDD を返します。 |
| デカルト(その他のデータセット) | デカルト積 |
| パイプ(コマンド、[envVars]) | rdd でのパイプライン操作 |
| 合体(パーティション数) | RDDのパーティション数を指定した値まで減らします。大量のデータをフィルタリングした後、次のことができます。 |
| 再パーティション(パーティション数) | RDD の再パーティション化 |
アクションアクション演算子
| アクション演算子 | 意味 |
|---|---|
| リデュース(機能) | func 関数を使用して RDD 内のすべての要素を集約します。この関数は交換可能で並列化可能である必要があります。 |
| 収集() | ドライバー プログラムで、データセットのすべての要素を配列として返します。 |
| カウント() | RDD 内の要素の数を返します。 |
| 初め() | RDD の最初の要素を返します (take(1) と同様) |
| テイク(n) | データセットの最初の n 要素で構成される配列を返します。 |
| takeSample(withReplacement,num, [シード]) | 返回一个数组,该数组由从数据集中随机采样的 num 个元素组成,可以选择是否用随机数替换不足的部分,seed 用于指定随机数生成器种子 |
| takeOrdered(n, [ordering]) | 返回自然顺序或者自定义顺序的前 n 个元素 |
| saveAsTextFile(path) | 将数据集的元素以 textfile 的形式保存到 HDFS 文件系统或者其他支持的文件系统,对于每个元素,Spark 将会调用 toString 方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以 Hadoop sequencefile 的格式保存到指定的目录下,可以使 HDFS 或者其他 Hadoop 支持的文件系统 |
| saveAsObjectFile(path) | 将数据集的元素,以 Java 序列化的方式保存到指定的目录下 |
| countByKey() | 针对(K,V)类型的 RDD,返回一个(K,Int)的 map,表示每一个 key 对应的元素个数 |
| foreach(func) | 在数据集的每一个元素上,运行函数 func 进行更新 |
| foreachPartition(func) | 在数据集的每一个分区上,运行函数 func |
统计操作
| 算子 | 含义 |
|---|---|
| count | 个数 |
| mean | 均值 |
| sum | 求和 |
| max | 最大值 |
| min | 最小值 |
| variance | 方差 |
| sampleVariance | 从采样中计算方差 |
| stdev | 标准差:衡量数据的离散程度 |
| sampleStdev | 采样的标准差 |
| stats | 查看统计结果 |
RDD序列化
RDD序列化是Spark中的一个重要概念,它是指将RDD中的数据对象转换为字节流的过程,以便在不同的节点之间进行网络传输或磁盘存储。在Spark中,需要对RDD进行序列化是因为RDD在分布式计算中需要在多个节点之间传输和存储,而这些节点的操作系统和硬件环境可能不同,因此需要将RDD数据对象进行序列化,以便能够在不同的节点之间传输和存储。
Spark支持两种类型的RDD序列化方式:Java序列化和Kryo序列化。Java序列化是JVM自带的序列化机制,它具有通用性,但是效率较低。Kryo序列化是一个高性能的序列化库,它能够将对象序列化成较小的字节数组,从而提高网络传输和磁盘存储的效率。在使用Kryo序列化时,需要先注册需要序列化的类,以便Kryo能够正确地序列化和反序列化这些对象。
在Spark中,默认情况下使用Java序列化方式,但是可以通过设置SparkConf的“spark.serializer”属性来指定使用Kryo序列化方式,例如:
val conf = new SparkConf()
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sc = new SparkContext(conf)
RDD依赖关系
在Spark中,RDD的依赖关系是指一个RDD与其他RDD之间的关系,包括它们之间的转换操作和依赖类型。根据依赖类型的不同,RDD的依赖关系可以分为两种:宽依赖和窄依赖。
-
窄依赖(Narrow Dependency):指一个RDD的每个分区只依赖于另一个RDD的一个或多个分区。例如,map、filter等转换操作都是窄依赖。
-
宽依赖(Wide Dependency):指一个RDD的每个分区依赖于另一个RDD的多个分区,即一个RDD的每个分区需要与另一个RDD的所有分区进行计算。例如,reduceByKey、groupByKey等转换操作都是宽依赖。
在Spark中,RDD的依赖关系是以有向无环图(DAG)的形式组织起来的。每个RDD都有一组父RDD和一组子RDD,每个父RDD与子RDD之间都有一条有向边来表示依赖关系。在一个DAG中,每个RDD都是通过一系列转换操作从原始数据集导出的,最终得到的RDD被称为输出RDD。
在Spark中,DAG的构建是惰性的,也就是说,只有在需要执行操作时才会计算DAG。这种惰性计算的好处是能够避免不必要的计算,提高计算效率。同时,由于DAG是有向无环图,因此可以通过优化DAG来减少计算的开销,提高计算性能。
RDD持久化
在Spark中,RDD持久化(Persistence)指的是将RDD的数据缓存到内存或磁盘中,以便后续重复使用,可以使用RDD的persist()方法或cache()方法实现。这两个方法的作用是一样的,都可以将RDD的数据缓存到内存或磁盘中。
这两个方法的使用方式非常简单,只需要在RDD上调用persist()方法或cache()方法,并指定缓存的级别即可。例如:
val rdd = sc.parallelize(Seq(1, 2, 3))
rdd.persist(StorageLevel.MEMORY_ONLY)
或者:
val rdd = sc.parallelize(Seq(1, 2, 3))
rdd.cache()
其中,StorageLevel.MEMORY_ONLY指定了缓存级别为内存缓存,表示将RDD的数据存储在内存中。除了MEMORY_ONLY外,Spark还支持其他多种缓存级别,如MEMORY_ONLY_SER、MEMORY_AND_DISK、MEMORY_AND_DISK_SER等,可以根据实际需求进行选择。
需要注意的是,持久化RDD需要消耗内存或磁盘空间,因此需要根据实际情况来选择合适的缓存级别。另外,可以使用unpersist()方法来释放缓存的RDD数据,例如:
rdd.unpersist()
当调用persist()或cache()方法后,Spark会根据缓存级别和当前的可用内存或磁盘空间来决定RDD数据是放在内存中还是磁盘中。如果数据太大无法全部缓存到内存中,Spark会按照缓存级别和LRU算法来淘汰不常用的数据。如果数据在内存中被淘汰,则后续使用该数据时需要重新计算。
RDD分区器
在Spark中,RDD的分区(Partition)是指将一个RDD的数据集划分成若干个小的数据块,每个数据块称为一个分区,每个分区都可以被一个Task并行处理。RDD的分区是Spark实现高效计算的关键,因为它可以将数据并行处理,从而提高计算性能。
而RDD分区器(Partitioner)则是对RDD的分区进行进一步的优化,即对数据进行重新分区,以便更好地利用Spark的并行计算能力。RDD分区器主要用于控制RDD的数据如何被分配到不同的节点上进行计算,从而更好地利用集群的资源。
在Spark中,RDD分区器分为两种类型:哈希分区器和范围分区器。哈希分区器(HashPartitioner)是根据键的哈希值来对RDD进行分区,而范围分区器(RangePartitioner)则是根据键的范围来对RDD进行分区。对于哈希分区器,Spark默认使用的是HashPartitioner,而对于范围分区器,Spark会根据数据的范围和RDD的分区数自动选择使用RangePartitioner。
在使用RDD的groupByKey、reduceByKey等聚合操作时,需要使用到哈希分区器。在使用RDD的sortByKey、join等操作时,需要使用到范围分区器。可以通过对RDD调用partitionBy方法来指定分区器,例如:
val rdd = sc.parallelize(Seq(("a", 1), ("b", 2), ("c", 3)))
val partitioner = new HashPartitioner(2)
val partitionedRDD = rdd.partitionBy(partitioner)
在上面的例子中,我们创建了一个包含三个元素的RDD,并使用HashPartitioner对其进行分区,分为两个分区。其中,HashPartitioner的构造函数需要指定分区数,这里指定为2。然后,我们使用RDD的partitionBy方法将RDD重新分区,并指定使用HashPartitioner进行分区。这样,RDD的数据就会被重新分配到两个节点上,以便更好地利用集群的资源进行计算。
RDD文件读取与保存
在Spark中,可以使用RDD的读取和保存操作,从而将数据加载到RDD中,或将RDD中的数据保存到外部存储系统中。常用的RDD读取和保存方式包括:
从文件中读取数据
可以使用sc.textFile()方法从文件中读取数据,例如:
val rdd = sc.textFile("path/to/file")
其中,path/to/file指定要读取的文件路径,该方法返回一个包含文件中所有行的RDD。
将RDD保存到文件中
可以使用RDD.saveAsTextFile()方法将RDD中的数据保存到文件中,例如:
val rdd = sc.parallelize(Seq("Hello", "World", "Spark"))
rdd.saveAsTextFile("path/to/output")
其中,path/to/output指定要保存的文件路径,该方法将RDD中的数据保存为文本格式。
Hadoop ファイル システムからのデータの読み取り
sc.hadoopFile() メソッドを使用して、Hadoop ファイル システムからデータを読み取ることができます。次に例を示します。
val rdd = sc.hadoopFile("path/to/hdfs/file", classOf[TextInputFormat], classOf[LongWritable], classOf[Text])
このうち、path/to/hdfs/file は読み取る Hadoop ファイルのパスを指定し、TextInputFormat は読み取るファイル形式を指定し、LongWritable と Text はそれぞれキーと値のタイプを指定し、このメソッドは、次のすべての行を含む RDD を返します。 Hadoop ファイル。
RDD を Hadoop ファイル システムに保存する
RDD.saveAsHadoopFile() メソッドを使用して、RDD 内のデータを Hadoop ファイル システムに保存できます。次に例を示します。
val rdd = sc.parallelize(Seq("Hello", "World", "Spark"))
rdd.saveAsHadoopFile("path/to/hdfs/output", classOf[Text], classOf[Text], classOf[TextOutputFormat])
このうち、path/to/hdfs/outputは保存するHadoopファイルのパスを指定し、Textは保存するキーと値の種類を指定し、TextOutputFormatは保存するファイル形式を指定するメソッドです。 Hadoop ファイル形式としての RDD。