この記事は「MOOC」(www.imooc.com)から掲載したものです。IT乾物やプログラマ界の注目ニュースをもっと知りたい方は、「MOOC」またはMOOC公式アカウントをフォローしてください!
著者: Yifan | MOOC講師
Redis は、データベース、キャッシュ、メッセージ キューとして使用されるオープン ソース (BSD ライセンス) のインメモリ データ構造ストレージ システムです。Redis は、文字列、ハッシュ、リスト、セット、範囲クエリを備えた並べ替えられたコレクション、ビットマップ、ハイパーログ、地理空間インデックス、ストリームなどのデータ構造を提供します。Redis には、レプリケーション、Lua スクリプト、LRU エビクション、トランザクション、およびさまざまなレベルのディスク永続性が組み込まれており、Redis Sentinel および Redis Cluster の自動パーティショニングを通じて高可用性を提供します。
1 クラスターの利点
Redis クラスターの明らかな利点をいくつか示します。
1.1 スケーラビリティ、データサイズが増加した場合でも拡張が容易

シングル インスタンス モード: マシン メモリの容量を増やすために垂直方向にのみ拡張できます。
クラスター モード: 垂直方向の拡張をサポートし、水平方向の拡張もサポートし、柔軟性が高く、大容量もサポートできます。
1.2 高可用性、サービス障害時の影響範囲が小さい

シングル インスタンス モード: フェイルオーバー前 (スレーブがマスターに変換される前) は 100% 使用不可。
クラスター モード: フェールオーバー前は部分的に使用できません (クラスター サイズが大きいほど、障害の影響は小さくなります)。
1.3 高いパフォーマンス、クエリおよび書き込みパフォーマンス
シングル インスタンス モード: クエリは複数のスレーブに分散できますが、書き込み用のマスターは 1 つだけです。
クラスター モード: クエリには複数のマスターと複数のスレーブがあり、書き込みには複数のマスターがあります。
2 データシャーディング、一貫したハッシュ
Redis クラスターを実現するための中心点はデータの断片化であり、ここでの一貫したハッシュ アルゴリズムは非常に重要です。
2.1 通常のハッシュアルゴリズム
ノード=ハッシュ(キー)%番号
ノードの数と順序が変更されると、ノードの選択に大きな違いが生じ、その結果、大きなキャッシュ障害が発生します。
2.2 一貫したハッシュ

hash(node) は仮想ノードリングを形成し、hash(key) は仮想ノードリング内に入り、対応するノードを見つけます。
hash(node) の安定性により、ノードの順序とは関係がありません。ノードの変更はデータのごく一部にのみ影響します。
2.3 Redis クラスターのハッシュ スロット アルゴリズム

関係: クラスター > ノード > スロット > キー
Redis Cluster は、その設計で整合性ハッシュを使用しませんが、データの断片化を使用してハッシュ スロットを導入します。
Redis クラスターには 16384 (0 ~ 16383) のハッシュ スロットが含まれており、Redis クラスターに保存されているすべてのキーはこれらのスロットにマッピングされます。
クラスター内の各キーは、16384 のハッシュ スロットの 1 つに属します。クラスターは、slot=CRC16(key)/16384 という式を使用してキーがどのスロットに属するかを計算し、CRC16(key) ステートメントを使用して CRC16 チェックサムを計算します。鍵と。
フラグメンテーションはスロット単位で行われ、各ノードに異なる数のスロットを割り当てることで、各ノードが担当するデータ量やリクエスト数を制御することができます。
3 クラスタメタデータの一貫性
3.1 比較: メタデータの集中ストレージ

Zookeeper、etcd などの外部の集中ストレージ サービスに依存すると、運用とメンテナンスの負担が増大し、システムが複雑になります。
集中化の利点は、メタデータの読み取りと更新の適時性が非常に優れていることです。メタデータが変更されると、すぐに集中ストレージに更新され、読み取り時に他のノードがそれを認識できます。欠点は、すべてのメタデータの更新に圧力がかかることです。が 1 か所に集中しているため、メタデータのストレージに負担がかかる可能性があります。
3.2 ゴシップ プロトコルは、自身の状態とクラスター全体の認識の変化をブロードキャストします。

ノードの生存を確認し、すべてのクラスターのメタデータを同期するための ping/pong メッセージ。
クラスターのメタデータ。マスター/スレーブ ノードのリストとステータス、スロットとノードの関係が含まれます。
各マスター ノードは 1 秒あたり 10 回の ping を実行し、そのたびに、最も長い時間通信していない他の 5 つのノードを選択します。
すべてのノードを定期的にチェックし、特定のノードの通信遅延がcluster_node_timeout / 2に達した場合は、過度のデータ交換遅延を避けるために直ちにpingを送信します。
3.3 新しいノードの追加
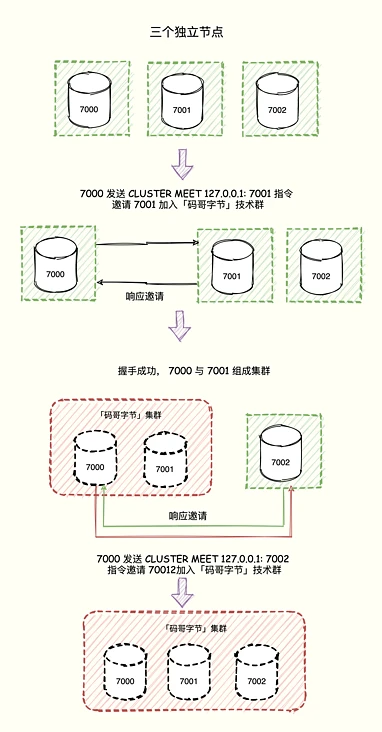
コマンド CLUSTER MEET <ip> <port>
CLUSTER MEET コマンドをノードに送信し、ノードが ip およびポートで指定されたノードとハンドシェイクできるようにします。ハンドシェイクが成功すると、ノード ノードは ip およびポートで指定されたノードを現在の場所に追加します。ノード クラスター内のノード。
ゴシップ プロトコルに従って、Meet メッセージがブロードキャストされ、すべてのノードが新しいノードを受信します。
(ノード) を再ハッシュし、対応するスロットを新しいノードに割り当てて転送します。
4 クライアントの電話のかけ方

4.1 ハッシュスロット情報
クライアントがインスタンスに接続すると、インスタンスはハッシュ スロットとインスタンスの間のマッピング関係をクライアントに応答し、クライアントはハッシュ スロットとインスタンスの間のマッピング情報をローカルにキャッシュします。
4.2 リクエストデータ
クライアントがリクエストを行うと、キーに対応するハッシュ スロットを計算し、ローカルにキャッシュされたハッシュ スロット インスタンス マッピング情報を通じてデータが配置されているインスタンスを特定し、対応するインスタンスにリクエストを送信します。
4.3 リダイレクトメカニズム

クライアントはリクエストをインスタンスに送信します。このインスタンスには対応するデータがありません。Redis インスタンスは、ローカル ハッシュ スロットのキャッシュとマッピング情報を更新し、リクエストを他のインスタンスに送信するようにクライアントに指示します。
5 新しいノードがクラスターに参加します (拡張)
3.3 新しいノードの追加の予約手順と同じです。
再スケーリング中のスロットの移行とデータの詳細については、こちらをご覧ください。
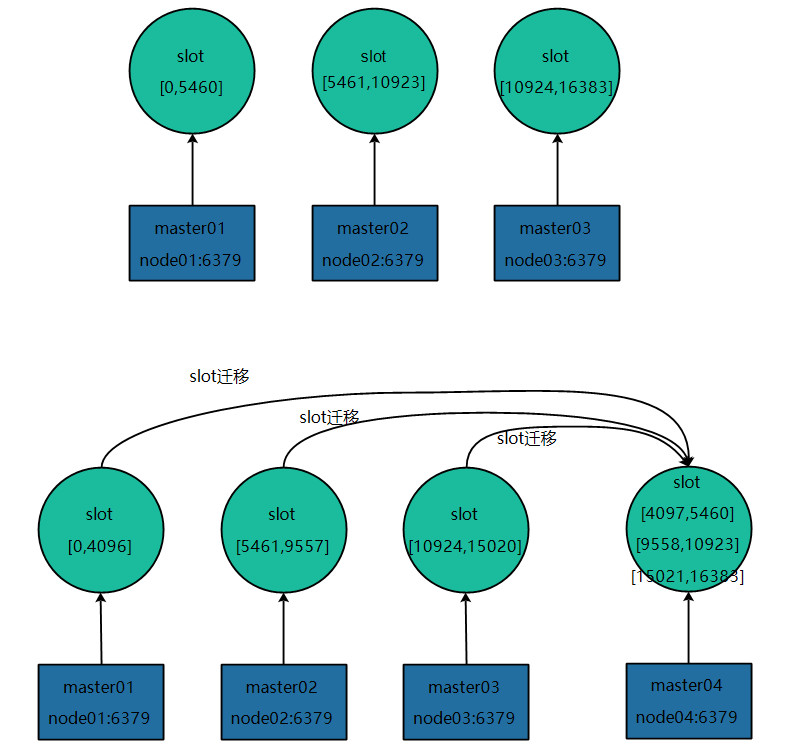
5.1 各スロットの移行プロセスは次のとおりです。
-
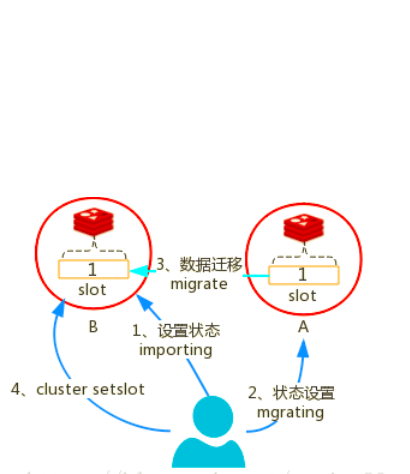
クラスターの setslot {slot_id} importing {sourceNodeId} コマンドをターゲット ノードに送信すると、ターゲット ノードのステータスが「インポート中」としてマークされ、このスロットのデータをインポートする準備が整います。
-
クラスターの setslot {slot_id} 移行 {targetNodeID} コマンドをソース ノードに送信すると、ソース ノードのステータスが「移行中」としてマークされ、スロットのデータを移行する準備が整います。
-
ソースノードは、cluster getkeysinslot {slot_id} {count} コマンドを実行して、このスロットのすべてのキーのリストを取得し (バッチで取得、count は 1 回の取得数を指定します)、キーごとに移行します。
-
ソース ノードで merge {targetIp} {targetPort} "" 0 {timeout}keys {keys} コマンドを実行して、キーのバッチをターゲット ノードに移行します (redis-3.0.6 より前では、一度に 1 つのキーのみを移行できます)。具体的には、ソース ノードは移行されたキーに対して dump コマンドを実行してシリアル化されたコンテンツを取得し、その後、シリアル化されたコンテンツを含む復元コマンドをクライアント経由でターゲット ノードに送信します。ターゲット ノードは受信したコンテンツを逆シリアル化して、そのコンテンツに保存します。自身のメモリがなくなると、ターゲットノードがクライアントに「OK」を返し、ソースノードがキーを削除することで、キーの移行処理が完了します。
-
すべてのキーが移行されると、スロットの移行は終了します。
-
すべてのスロット (移行する必要があるスロット) を移行します。すべてのスロットの移行が完了すると、新しいクラスターのスロットが再分配されます。クラスター内のすべてのマスターにクラスターの setslot {slot_id} ノード {targetNodeId} コマンドを送信して、どのマスターに移行するかを通知します。スロットがどのマスターに移行されたかについては、その情報を更新してください。
5.2 スロット移行に関するその他の手順
-
移行プロセスは同期であり、ターゲット ノードで復元コマンドを実行してから元のノードでキーを削除するまで、キーが正常に削除されるまで、元のノードのメイン スレッドはブロックされます。
-
移行プロセス中にネットワーク障害が突然発生した場合、スロット全体の移行はまだ途中にあります。この時点では、2 つのノードは依然として中間フィルタリング状態、つまり「移行中」と「インポート中」としてマークされます。ツールが接続されている場合は、移行が続行されます。
-
移行プロセス中、各キーの内容が小さい場合、移行プロセスは高速になり、クライアントの通常のアクセスには影響しません。
-
キーの内容が大きい場合、キーの移行プロセスがブロックされるため、元のノードとターゲット ノードが同時にフリーズし、クラスターの安定性に影響を与える可能性があります。 、ビジネス ロジックは可能な限り回避する必要があります。ビッグ キーの生成。
5.3 スロット番号
各マスターが管理するスロット数がバランスしていれば、各マスターのスロット番号が連続している必要はありません。
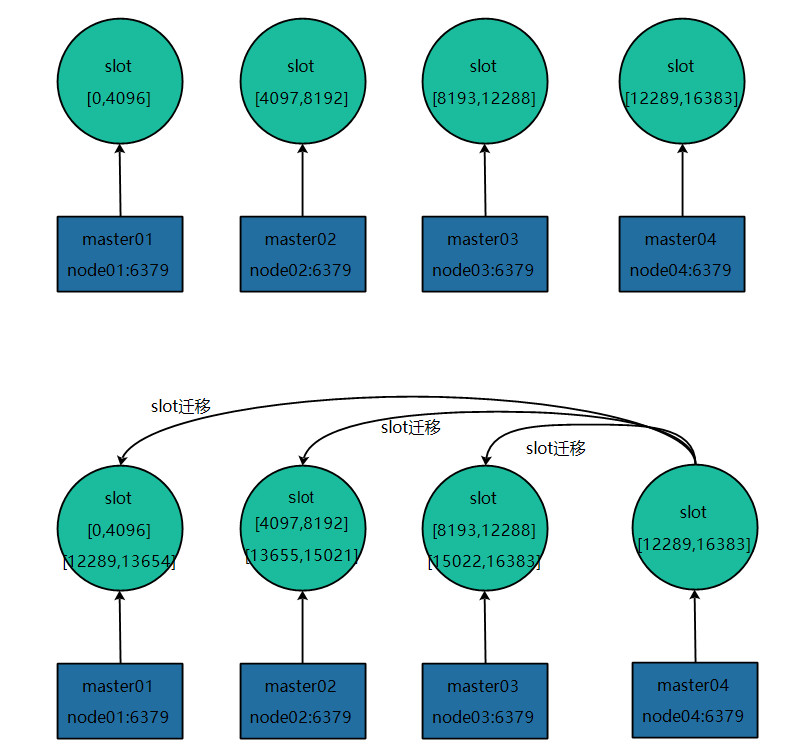
5.4 ノードの削減(縮小)
縮小プロセスはスケーリングと似ていますが、スロットとデータがオフライン ノードから他のノードに転送される点が異なります。
6 クラスタ内のマシンに障害が発生しました
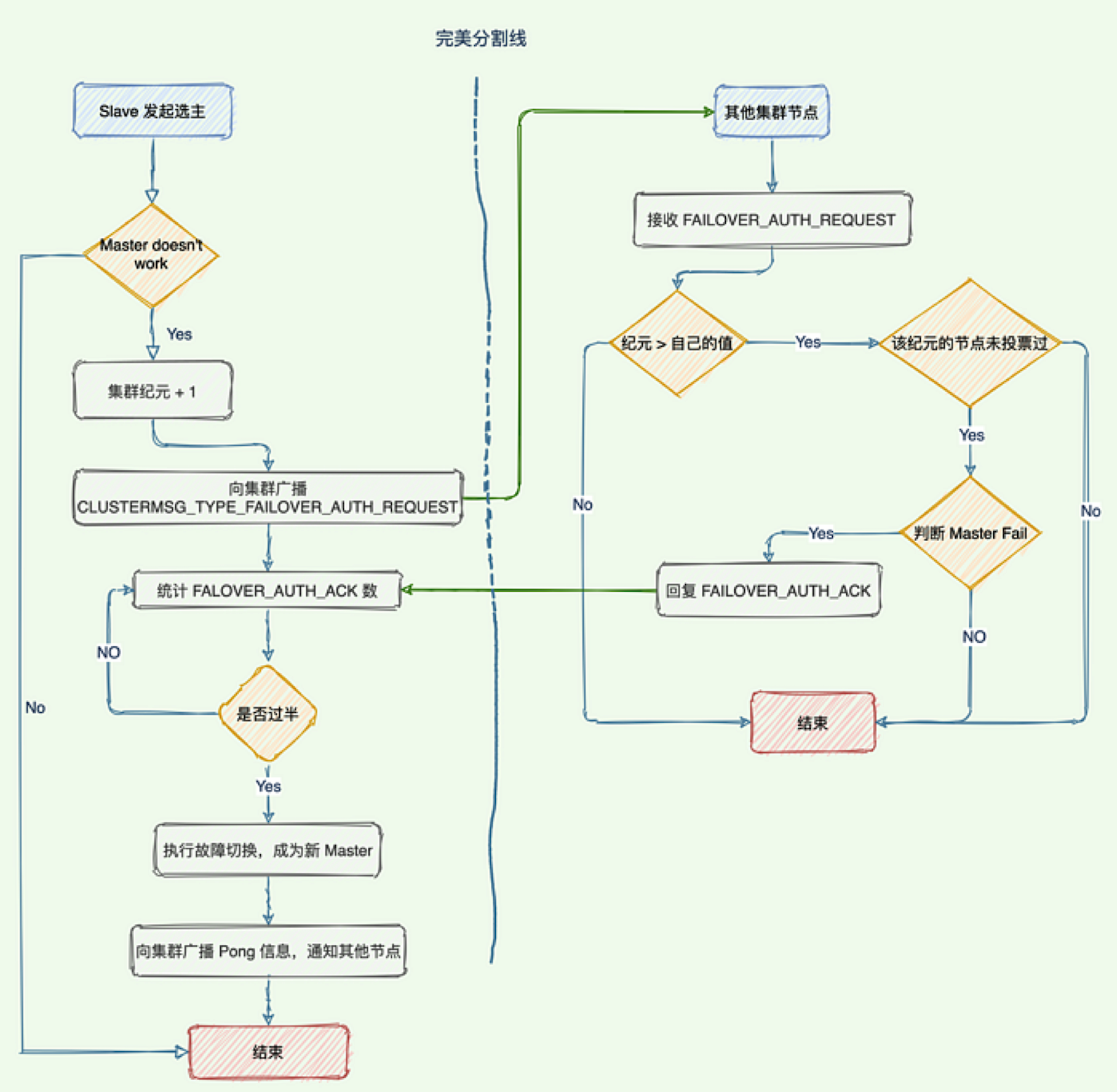
6.1 障害検出、ノード障害
ノードが別のノードがダウンしていると考える場合、それは pfail (主観的なダウンタイム) です。
ノードの半分以上が他のノードがダウンしていると判断した場合、それは失敗し、客観的なダウンタイムとなります。
6.2 フェイルオーバー、ノードの選択
各スレーブ ノードは、マスターによって複製されたデータに対する独自のオフセットに従って選出時間を設定します。オフセットが大きい (複製されるデータが多い) スレーブ ノードほど、選出時間が早くなり、選出の優先順位が高くなります。
すべてのマスターノードがスレーブ選出投票を開始し、選出されるスレーブに投票し、大部分のマスターノード(N/2 + 1)が特定のスレーブノードに投票した場合、選出は通過し、そのスレーブノードを切り替えることができます。マスターに。
スレーブノードがアクティブ/スタンバイ切り替えを実行し、スレーブノードがマスターノードに切り替わります。
7 マスター/スレーブ同期と高可用性
Redis のマスター/スレーブ同期は、クラスター バージョンよりも前から存在していました。これにより、クエリ効率が向上する (複数のスレーブにクエリできる) だけでなく、サービスの可用性も向上します (マスターがハングアップした後、スレーブを有効にすることができます)。マスター)。
7.1 マスタースレーブアーキテクチャを使用する場合

レプリケーションにはマスターが 1 つだけ、スレーブが複数存在します。
すべての書き込みはプライマリ ノードに送られるため、プライマリ ノードの負荷が増加します。
マスターがダウンすると、アーキテクチャ全体が SPOF (単一障害点) になりやすくなります。
MS アーキテクチャは、ユーザー ベースが拡大した場合のスケーリングには役立ちません。
したがって、障害やシャットダウンが発生した場合にマスターを監視するプロセス、つまり Sentinel が必要です。
7.2 Redis セントリー
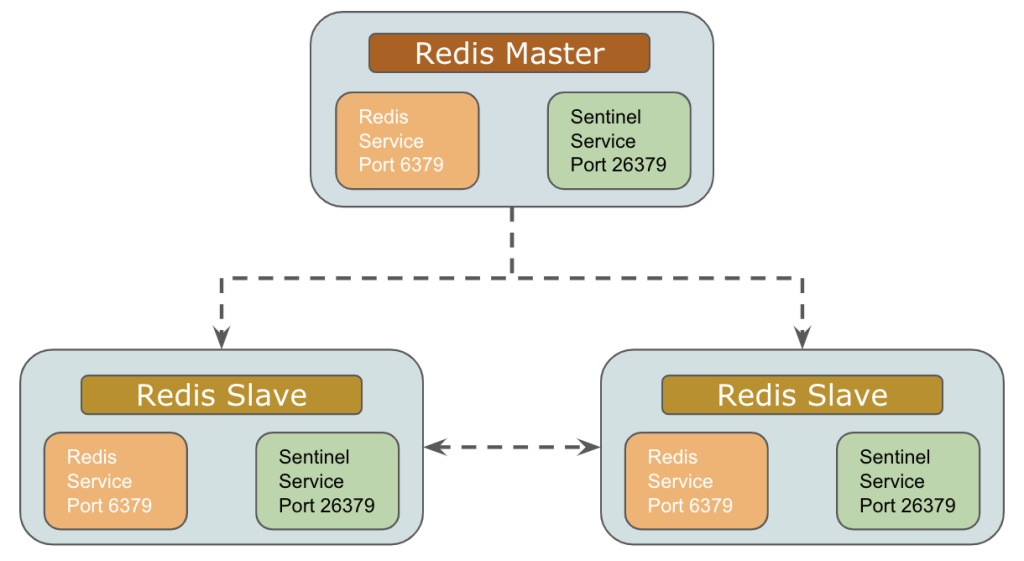
フェイルオーバー処理
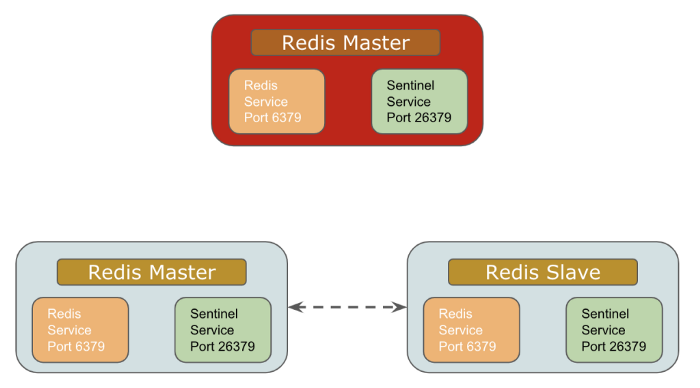
8 マスターとスレーブの同期とデータの一貫性
8.1 マスタ/スレーブ同期の実装プロセス
マスターとスレーブの同期は、同期とコマンドの伝播の 2 つのステップに分かれています。
データの同期にはsyncとpsyncがあります。
sync 完全同期のパフォーマンスは比較的劣りますが、psync 増分同期の速度とリアルタイム パフォーマンスははるかに優れています。
8.2 完全同期同期

サーバーからマスター サービスへの同期操作は、sync コマンドを使用して実現する必要があります。sync コマンドの実行手順は次のとおりです。
-
サーバーからマスターサーバーに同期コマンドを送信します。
-
マスターサーバーはsyncコマンドを受信後、bgsaveコマンドを実行してrdbファイルを生成し、これから実行するwriteコマンドをバッファに記録します。
-
bgsave の実行完了後、生成された rdb ファイルがスレーブ サーバーに送信され、スレーブ サーバーのデータが更新されます。
-
次に、マスターサーバーはバッファに記録された書き込みコマンドをスレーブサーバーに送信し、スレーブサーバーが書き込みコマンドを実行すると、その時点のデータベースの状態はマスターサーバーのデータベースの状態と一致します。
8.3 部分再同期 psync

部分再同期機能は次の 3 つの部分で構成されます。
-
マスターサーバーとスレーブサーバーのレプリケーションオフセット
-
マスターのレプリケーション バックログ バッファ
-
サーバーの実行 ID (実行 ID)
8.4 ハートビートの検出
同期が完了すると、マスター/スレーブ サーバーはコマンド伝播フェーズに入ります。このとき、スレーブ サーバーは 1 秒あたり 1 回の頻度でマスター サーバーにコマンドを送信します: REPLCONF ACK <replication_offset> ここで、replication_offset はスレーブサーバーの現在のレプリケーションオフセット数量
このコマンドの送信には、次の 3 つの主な機能があります。
-
マスターサーバーとスレーブサーバーのネットワーク状態を検出します
-
min-slaves オプションの補助実装
-
コマンド損失の検出 (損失した場合、マスターサーバーは失われた書き込みコマンドをスレーブサーバーに再送信します)
8.5 マスター/スレーブ同期の概要
SLAVEOF コマンドを送信してマスターとスレーブの同期を実行します。例: SLAVEOF 127.0.0.1 6379
マスターとスレーブの同期には、同期とコマンド伝播の 2 つのステップがあります
-
同期: スレーブ サーバーのデータベース ステータスをマスター サーバーの現在のデータベース ステータスに更新します (リソースを消費する操作)
-
コマンド伝播: マスターサーバーのデータベースの状態が変更されると、マスター/スレーブサーバーのデータベースの状態が不整合になります。このとき、マスターとスレーブのデータを一貫したプロセスに同期する必要があります。
マスタとスレーブの同期は、初回コピーと切断後の繰り返しコピーの 2 つのケースに分けられます。
-
バージョン 2.8 以降、切断後に再レプリケーションが発生すると、マスター サーバーは、レプリケーション オフセット、レプリケーション バックログ バッファ、および実行 ID に基づいて、完全な再同期を実行するか部分的な再同期を実行するかを決定します。
-
バージョン 2.8 では、同期操作を実行するために sync コマンドの代わりに psync コマンドを使用します。目的は、同期(syncコマンド)の非効率な動作を解決することです。
質問 1: クラスターの規模を無限に大きくすることはできますか (例: 1 台のマシン)。
答えは「いいえ」です。Redis によって与えられる公式の Redis Cluster スケール制限は 1000 インスタンスです。
制限の理由は、インスタンス間の通信オーバーヘッドにあり、クラスター内の各ノードは、すべてのハッシュ スロットとノード (スロットをノードにマッピングするテーブル) の対応関係と、自身の状態情報を保存します。
3.2 ゴシップ プロトコルのブロードキャスト方法を参照すると、ノードの数が増えるほど、ネットワークとサーバーに対するブロードキャスト ストームの圧力が大きくなります。
ブロードキャストメッセージ同期のタイムアウト時間は設定可能ですが、ノード数が増加しタイムアウト時間が長くなると、データ整合性のためのメッセージ同期遅延も大きくなり、メタデータの不整合が発生する可能性も高くなります。
質問 2: スレーブ ライブラリの使用とトレードオフの方法は?
スレーブ ライブラリの役割は、可用性を向上させることです。メイン ライブラリがダウンしている場合、スレーブ ライブラリはメイン ライブラリとして使用され、すぐにサービスを提供できます。1 つ目は、スケーラビリティを向上させ、データ クエリの同時実行性を向上させることです。サービス リソーススレーブ ライブラリによって提供されるノードが増加し、クエリをサポートするノードが増加します。
マスターとスレーブの同期にはデータの一貫性の問題があるため、スレーブ ライブラリを使用する過程でいくつかの問題が発生します。
たとえば、スレーブ データベースからのデータ同期が遅いため、この時点でマスター データベースがダウンし、不完全なデータを持つスレーブ データベースがマスター データベースとして使用され、データ損失が発生します。スレーブ データベースをクエリに使用する場合も同様の問題があります。リアルタイムで書き込まれる新しいデータは、スレーブ データベースと同期しているときに遅延する可能性があります。データがスレーブ データベースと同期していない場合、スレーブ データベースへのクエリも遅延します。クエリにデータが含まれないようにします。
したがって、スレーブライブラリを使用する場合には、上記の問題を考慮する必要があります。
ダウンタイム、データ損失の問題、インメモリ データベースのリスクに直面して、Redis を使用する場合はこのリスクに直面する必要があります。そうでない場合は、高いパフォーマンスとデータの一貫性を犠牲にする必要があります。Redis データはサービスを提供する前に保持されます。このままでは明らかにパフォーマンスが低下し、インメモリデータベースの利点を満足できなくなります。
データベースからのクエリを有効にすることは、リアルタイムのデータ更新が少なく、ダーティ データの影響をあまり受けない、またはクエリの量が大きすぎて一部のデータ遅延の影響を無視できない一部のビジネスに使用できます。
質問 3: Redis をクラスター化した後、エージェントは必要ですか?
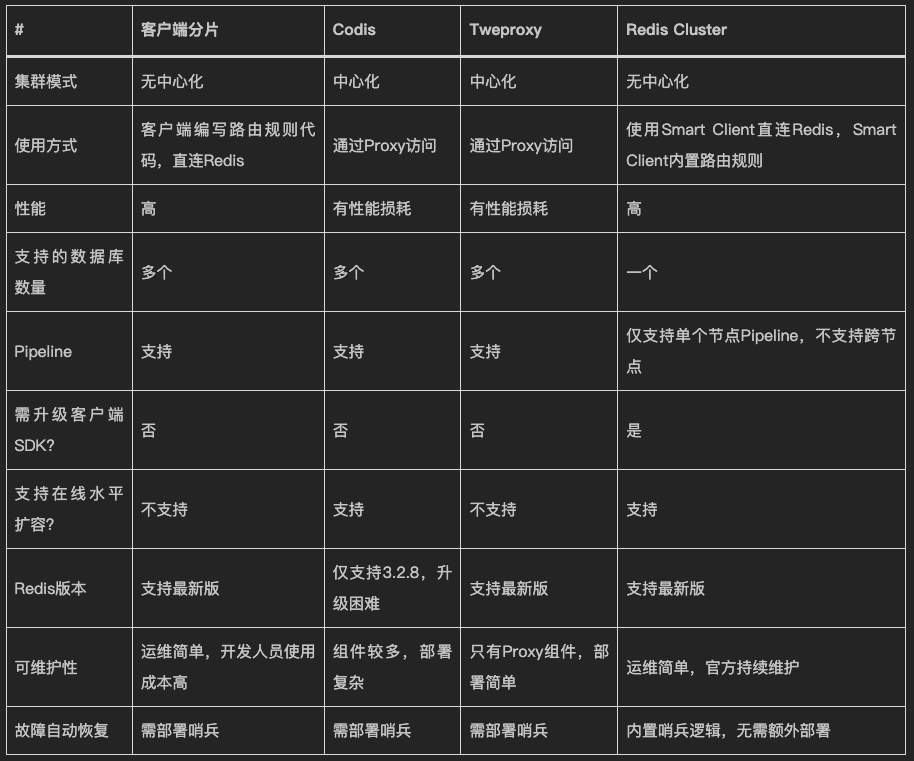
プロキシのパフォーマンスと安定性も問題です。
製品の運用保守や継続的なメンテナンスが難しいため、公式の Redis クラスターの信頼性が高くなります。
条件付きチームは、独自に開発した Tendis などの Redis クラスターの欠点をより詳細に最適化します。
質問 4: 1 つのキーに対する 100 万 qps の周波数制限についてはどうですか? (解決予定)
単一のキーを頻繁に更新する場合、単一のキーはマスター ノードの 1 つのスロットにのみ配置されるため、ノードを追加したりスレーブを追加したりして容量を拡張することは不可能であり、パフォーマンスのボトルネックは CPU によって制限されます。マシンのメモリ読み取りおよび書き込み機能。
単一マシンの最大書き込み速度が 10w であると仮定すると、インターフェースの 100w qps 周波数制限機能を実現するにはどうすればよいでしょうか?
答えを入力してください。。。
アタッチド・ブレイン・ホール: トリソララン人は地球上の人類のほぼ半数を絶滅させるために地球にやって来た (未解決)
トリソラランは、手袋で指を鳴らすだけで生物の半分を滅ぼすことができるサノスとは異なり、すべての人に選択肢を与え、正しいものを選択した人には生き残るチャンスがあります。
この選定方法も非常に簡単ですが、それをサポートするシステムの開発が必要です。
このシステムの開発は、地球上で最も賢いプログラマーであるあなたにかかっています。
うまく発症すれば、あなたとあなたの家族は免疫を獲得して生き残ることができますが、うまく発症しない場合は、ただクリックしてください。
このオプションは次のように説明されます

世界にはトリソララン光球がありますが、デフォルトではオフになっています。

各人は電球の現在の状態 (オフまたはオン) を表示する Trisolaran スイッチを持ち、電球の消灯と点灯を制御する 2 つの操作ボタンがあります。誰もが選択するチャンスは 1 回だけです。2 つのボタンは 1 つのボタンしか選択できず、1 回押します。どのボタンも選択または押されなかった場合、光のボールの最終状態がどのようなものであっても、光のボールは破壊されます。子供、高齢者、障害のある方は、保護者が選択を完了するのを手伝ってください。
システム実装の前提条件と要件
前提条件
1 世界には80億人がおり、選択は同時に1分以内に完了しなければならない(三体の人の切り替え、全世界のリアルタイム状態同期、時間のずれなし、遅延なし)、指定された時間範囲外では操作できません。
2 Tribody は、128 コア、256G メモリ、1T ディスクを備えた 1,000 台のサーバーを提供し、Tribody のスイッチは遅延やネットワーク オーバーヘッドなしでサーバー ネットワークに直接接続されます。
3 世界には 80 億人がおり、各人は 0 から始まり自動的に増加する固有のデジタル ID を持っており、これはトリソラランのスイッチに 1 つずつ対応します。
4 全員の ID%1000 は特定のサーバーを指し、システムが提供するインターフェイス/投票を要求します。
システム要件
関数、この投票インターフェイスを開発します (すべてのリクエストはこの 1 分以内にのみリクエストされます)
/vote?uid=1111&click=1&t=1234143134134134134
パラメータ
uid 長整数、各個人の一意の ID
クリック列挙値、ボタン選択、0 はオフ、1 はオン
t 長整数、演算時間、ナノ秒単位
対処する
1 同時に(同じナノ秒)、複数人が操作した場合は選択数が多い方が有効となり、2人の選択数が同じ場合はステータスは変化しません。例: 2 回オフ、3 回オン、この時点のステータスはオンです。
結果データ
1 最終的な電球の状態 (オフかオンか)。
2 正しい人物を選択します (ID 収集)。
3 間違った人物を選択します(ID 収集)。
4 選択しなかった人(ID設定)
最終執行
トリソラランスがサーバーにインストールしたシステムプログラムを起動し、地球人抹殺計画を完了する。
uidを殺す
Trisolaren のシステムプログラムの呼び出しに遅延はなく、メモリの読み出し効率と同等です。
選択を誤った者と選択しなかった者を1分以内に排除することが求められる。
模擬試験
1 Trisolaran は 1 分以内にテストケースをインポートし、80 億人の選択を完了します。
2 1 分 Kill コールは正しく実行されます。
上記が達成できない場合は失敗します。
答えを入力してください。。。
「MOOC」アカウントへようこそ。私たちは常にオリジナルコンテンツにこだわり、IT界に質の高いコンテンツを提供し、辛口な知識を共有していきます。一緒に成長していきましょう!
この記事は元々 Muke.com で公開されたものです。転載する場合は出典を明記してください。ご協力に感謝します。