1. コンピュータシステムの概要

オペレーティングシステムとは(オペレーティングシステムの概念)※
オペレーティング システム (オペレーティング システム、OS) は、コンピュータ システム全体のハードウェアおよびソフトウェア リソースの制御と管理を指し、コンピュータの作業とリソースの割り当てを合理的に編成およびスケジュールし、ユーザーやその他のソフトウェアに機能を提供します。便利なインターフェースと環境を備えた、コンピュータシステムの最も基本的なシステムソフトウェアです。

オペレーティング システムの目的と機能
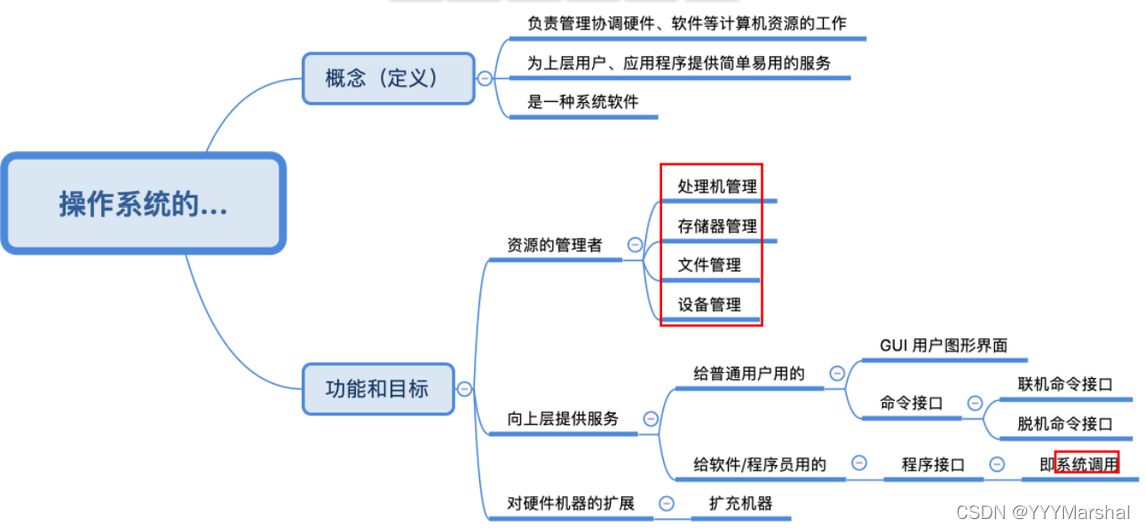
- オペレーティング·システムコンピュータリソースの管理者です
a. プロセッサ管理 (プロセス制御、プロセス同期、プロセス通信、デッドロック処理、プロセッサ スケジューリング)
b. メモリ管理 (メモリ使用率の改善、メモリ割り当てと回復、アドレス マッピング、メモリ保護と共有、メモリ拡張)
c. ファイル管理 (
d. デバイス管理 (ユーザーの I/O 要求を完了し、ユーザーがデバイスを使用できるようにし、デバイスの使用率を向上させます) - オペレーティング·システムコンピュータ ハードウェア システムを使用するためのインターフェイスをユーザーに提供する
a. コマンドインターフェース (ユーザーがコンソールや端末から操作コマンドを入力し、システムにさまざまなサービス要件を提供します)
b. プログラムインターフェース (システムコールで構成され、ユーザーはプログラム内でこれらのシステムコールを使用して、オペレーティングシステムにサービスの提供を要求します) c
. グラフィカル インターフェイス 最も一般的なグラフィカル ユーザー インターフェイス GUI (最終的にはプログラム インターフェイスを呼び出すことで実装されます) - オペレーティング·システム拡張機として使用
ソフトウェアサポートのないコンピュータはベアメタルと呼ばれ、実際にユーザーに提示されるコンピュータシステムは、いくつかの層のソフトウェアによって変形されたコンピュータです。オペレーティング システムは、ベアメタルをより強力で使いやすいマシンに変換します。ソフトウェアがオーバーレイされたマシンを拡張マシンまたは仮想マシンと呼びます。
オペレーティングシステムの役割とそれが提供するサービス(コンピュータシステムにおけるオペレーティングシステムの主な役割は何ですか)※※
- プロセッサ管理
- メモリ管理
- 端末管理
- ファイル管理
- ユーザーインターフェース
OSの4つの特徴※
- 同時実行性
- 共有
- バーチャル
- 非同期
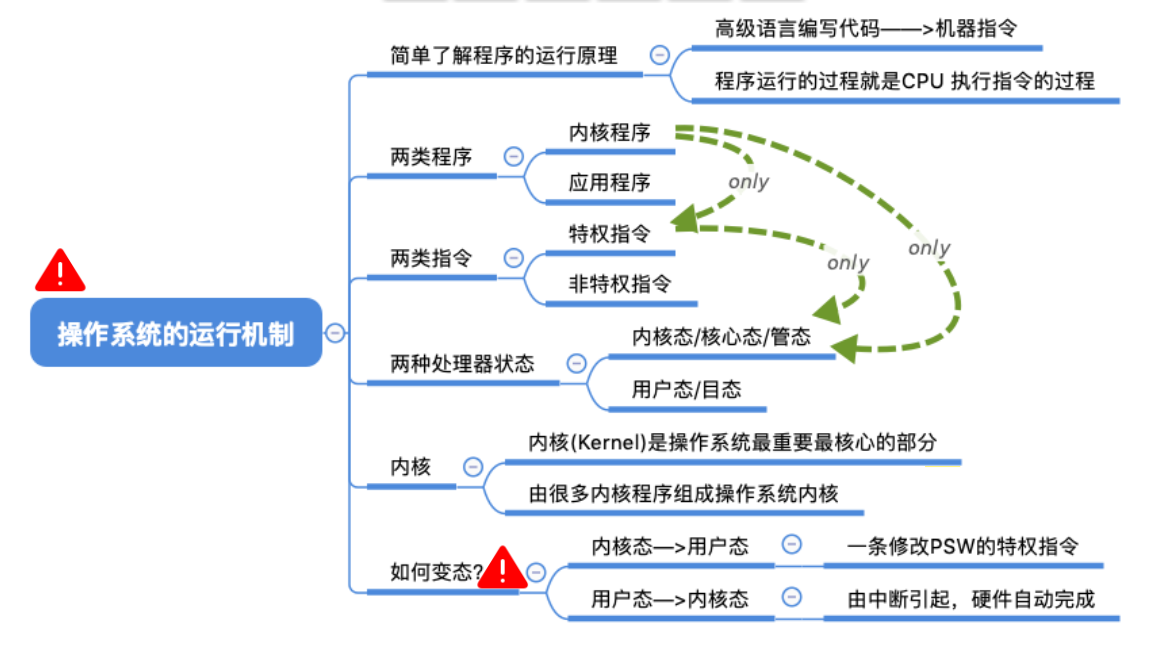
カーネルモードとユーザーモードの違い※
カーネル状態 = コア状態 = 管理状態
ユーザー状態 = ターゲット状態
- ユーザーモードはCPUによって呼び出される非特権命令を実行できます
- カーネルモードは特権命令と非特権命令を実行可能
- ユーザーモードからカーネルモードへの切り替えは割り込みによって実現されます。
- カーネル モードからユーザー モードへの切り替えは、特権命令によって実現されます。
カーネル モード → ユーザー モード: 特権命令を実行します。PSW のフラグ ビットを「ユーザー モード」に変更します。このアクションは、オペレーティング システムが CPU を使用する権利を積極的に放棄することを意味します。 ユーザー モード → カーネル モード: 「割り込み」によってトリガーされます
。 "、ハードウェアは自動的に変換プロセスを完了した後、割り込み信号をトリガーすると、オペレーティング システムが CPU を使用する権利を強制的に取り戻します。
オペレーティングシステムの仕組み
なぜオペレーティング システムは割り込み駆動と言われるのですか?※
リンク
中断は、オペレーティング システムのコア テクノロジの 1 つです。最も重要な理由は、現代のオペレーティング システムが備えなければならないマルチスレッドおよびマルチプロセス テクノロジが、すべて中断テクノロジに基づいているためです。CPU を割り当てる際には、まず、CPU を割り当てる必要があります。システムが CPU 実行時間を取得できるように、タイミング割り込みの参加が必要です。その後、システムは独自のアルゴリズムに従って待機キュー内のプロセスまたはスレッドを開始できます。
リンク
オペレーティング システムは多くのプログラム モジュールの集合であり、これらのプログラム モジュールは 3 つのカテゴリに分類されます。最初のカテゴリは、
システムの起動後にユーザー モード プログラムと並行してアクティブに実行され、すべての同時プログラムは割り込みによって駆動されます
。カテゴリは、システム コール命令を通じてユーザーに「受動的に」サービスを提供し、システム コール命令の実行は割り込みメカニズムによって処理される一部のプログラムです。3 番目のカテゴリはオペレーティング システム内に隠されており、アクティブには実行されず、実行されます。最初の 2 種類のプログラムによって呼び出されるユーザー モード プログラム。上記に基づいて、利用可能なオペレーティング システムは割り込みによって駆動されます。
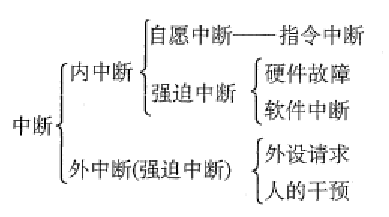
割り込み※
- 割り込みの導入 - CPU とデバイス間の並列動作をサポートするために、
割り込みは外部割り込みとも呼ばれます。これは、I/O 終了割り込みやクロック割り込みなど、CPU によって実行される命令以外のイベントの発生を指します。デバイスによって発行されます。このタイプの割り込みは通常、現在実行中の命令とは無関係のイベントです。 - 割り込みが発生すると、CPU はすぐにカーネル モードに移行します。
- 割り込みが発生すると、現在のプロセスが一時停止され、オペレーティング システムのカーネルが割り込みを処理します。
- 異なる割り込み信号に対して異なる処理が実行されます。
- 割り込みは内部割り込みと外部割り込みに分けられます。
異常な
例外の導入 - CPU が命令自体を実行するときに発生する問題を意味します。
内部割り込み、例外、またはトラップとも呼ばれる異常とは、CPU による命令の実行に起因するイベントを指します。プログラム、アドレス範囲外、算術オーバーフロー、およびページフォルト例外が待機します。例外の処理は通常、現在のプログラムの実行サイトに依存するため、シールドすることはできません。
割り込みと例外の関係と違い
システムコール
コンピュータ システムのさまざまなハードウェア リソースは限られています。これらのリソースを適切に管理するために、プロセスは直接動作することはできません。これらのリソースへのすべてのアクセスは、オペレーティング システムによって制御される必要があります。つまり、オペレーティング システムはこれらのリソースを使用する唯一のエントリであり、このエントリはオペレーティング システムによって提供されるシステム コールです。一般にシステムコールは割り込みによって実現され、例えば Linux の割り込み番号 0x80 はシステムコールです。
オペレーティング システムは、ユーザー モード プロセスがハードウェア デバイスと対話するための一連のインターフェイス (システム コール) を提供します: 1. ユーザーを基盤となるハードウェア プログラミングから解放します; 2. システムのセキュリティを大幅に向上させ、ユーザー プログラムの信頼性を高めます。プログラムと具体的なハードウェアは、抽象的なインターフェイスに置き換えられました。
2. プロセス管理

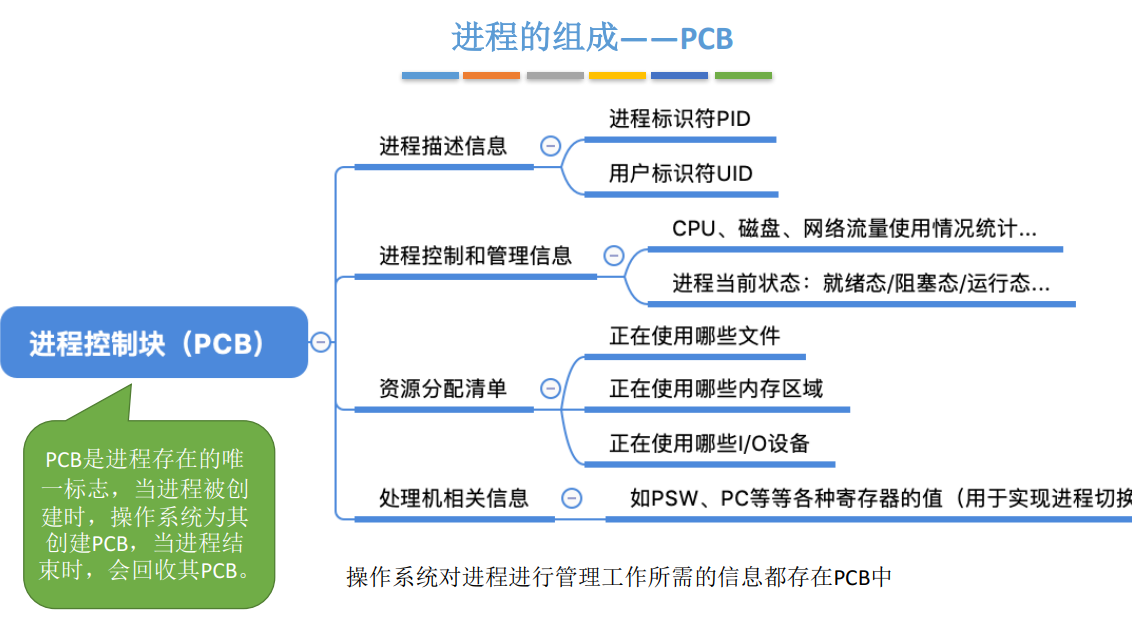
プロセスとPCB※
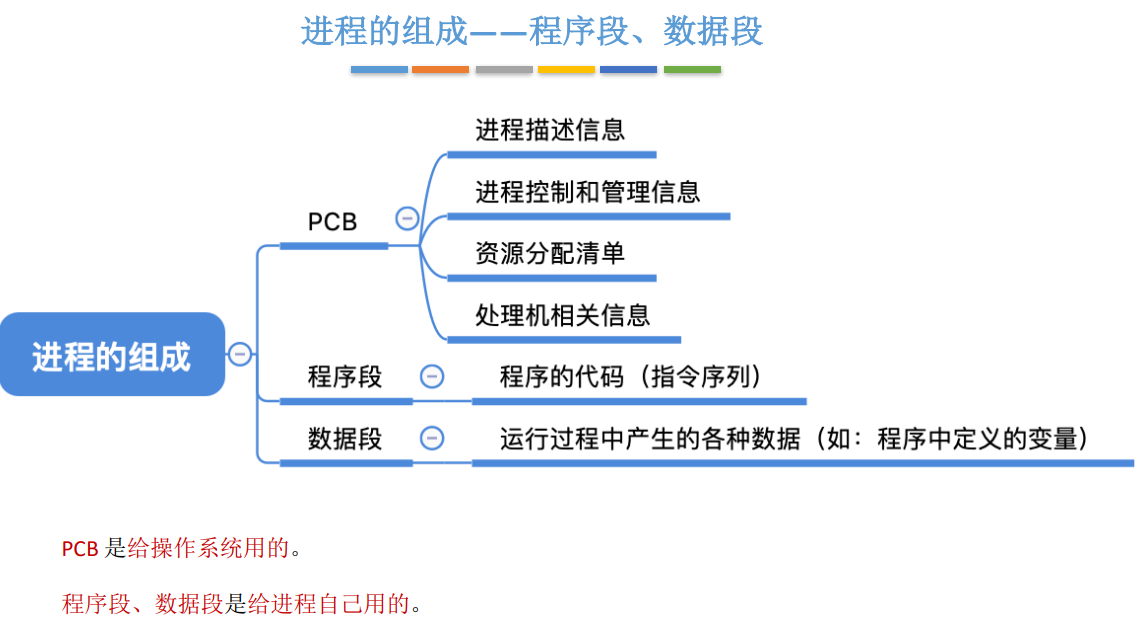
プロセスとスレッドの違い※※※※
- プロセス(プロセス)は、システムはリソースの割り当てとスケジューリングを実行します。糸の基本単位(Thread)は、CPUのスケジューリングと割り当ての基本単位
- スレッドはプロセスに応じて存在し、プロセスには少なくとも 1 つのスレッドが存在します。;
- プロセスには独自の独立したアドレス空間があり、スレッドは属するプロセスのアドレス空間を共有します。;
- プロセスはシステムリソースを所有する独立した単位であり、スレッド自体は基本的にシステムリソースを所有しません。、動作中にはいくつかの重要なリソース (プログラム カウンター、レジスタのセット、スタックなど) のみがあり、このプロセスの関連リソースをメモリ、I/O、CPU などの他のスレッドと共有します。
- プロセスの切り替えでは、現在のプロセス全体の CPU 環境の保存環境の設定と、新しくスケジュールされた CPU 環境の設定が必要になりますが、スレッドの切り替えでは、少数のレジスタの内容を保存して設定するだけでよく、必要はありません。メモリ管理操作が含まれます。プロセス切り替えのオーバーヘッドは、スレッド切り替えのオーバーヘッドよりもはるかに大きい;
- スレッド間の通信がより便利に 同一プロセス配下のスレッドはグローバル変数などのデータを共有しており、プロセス間の通信はプロセス間通信(IPC)の形式で行う必要があります。
- マルチスレッド プログラムで 1 つのスレッドがクラッシュすると、プログラム全体がクラッシュしますが、プロセスには独自の独立したアドレス空間があるため、マルチプロセス プログラムで 1 つのプロセスがクラッシュしても他のプロセスには影響しません。プロセスがより堅牢になります。
プロセスとプログラムの違い※
(1)プログラムは永続的ですが、プロセスは一時的です、データセットに対するプログラムの実行であり、作成とキャンセルがあり、存在は一時的です;
(2)プロシージャは静的でプロセスは動的であるという概念;
(3)プロセスは同時実行されます(4)プロセスは
コンピュータ リソースを争う基本単位ですが、プログラムはそうではありません。
(5) プロセスとプログラムは 1 対 1 に対応していない: プログラムは複数のプロセスに対応することができ、つまり複数のプロセスが同じプログラムを実行することもできるし、プロセスは 1 つまたは複数のプログラムを実行することもできる
ジョブとプロセスの違い※
リンク
プロセスは、データ セットに対するプログラムの実行プロセスであり、リソース割り当ての基本単位です。ジョブとは、ユーザーがコンピュータに実行させる必要がある特定のタスクであり、コンピュータに実行させる必要がある作業の集合です。ジョブの完了には、ジョブの送信、ジョブの封じ込め、ジョブの実行、ジョブの完了という 4 つの段階があります。プロセスは、送信されたプログラムの実行プロセスの記述であり、リソース割り当ての基本単位です。主な違いは次のとおりです。
(1) ジョブとは、ユーザーがコンピュータにタスクを投入するタスクの実体です。ユーザーがジョブをコンピュータに送信すると、システムはそのジョブを外部ストレージ内のジョブ待機キューに入れて実行します。プロセスは、ユーザーのタスクを完了する実行エンティティであり、リソース割り当てのためにシステムに適用される基本単位です。どのプロセスも、作成される限り、対応する部分が常にメモリ内に存在します。
(2) ジョブは複数のプロセスで構成することができ、少なくとも 1 つのプロセスで構成される必要があり、その逆も同様です。
(3) ジョブという概念は主にバッチ処理システムで使われており、UNIX のようなタイムシェアリングシステムにはジョブという概念がありません。プロセスの概念は、ほぼすべてのマルチプログラミング システムで使用されます。
プロセス通信方式※
- 共有メモリ
名前が示すように、共有メモリとは、2 つのプロセスが 1 つのメモリを同時に共有し、通信の目的を達成するためにこのメモリ上のデータを変更したり、一緒に読み取ったりできることを意味します。 - 名前のないパイプ
名前なしパイプは半二重通信方式であり、アフィニティ (アフィニティとはプロセス間の親子関係、兄弟関係などを指します) を持つプロセス間でのみ使用でき、アフィニティを持つプロセスには名前のないパイプがあります。パイプのハンドルは読み取りと書き込みが可能です。名前のないパイプにはディスク ノードはありませんが、メモリ内にのみ存在し、使い果たされると破棄されます。 - 名前付きパイプ
名前付きパイプは半二重通信方式でもあり、関係のないプロセス間で通信できます。名前付きパイプはディスク ノード上に存在し、対応する FIFO ファイルがあり、このパス内のファイルにアクセスできるすべてのプロセスが通信できます。 - メッセージキュー
メッセージ キューは、カーネルに格納されているメッセージのリンク リストであり、メッセージ キュー識別子によって識別されます。メッセージ キューは、信号送信情報が少ないという欠点を克服し、パイプラインはフォーマットされていないバイト ストリームのみを伝送でき、バッファ サイズは制限されています。 - ソケット
ソケットはネットワーク プログラミングの API です。ソケットを介して、異なるマシン間のプロセスが通信できます。クライアント プロセスとサーバー プロセス間の通信によく使用されます。 - 信号
シグナルは、Unix システムで使用されるプロセス間通信の最も古い方法の 1 つです。オペレーティング システムは、システム内で所定のイベント (一連のイベントの 1 つ) が発生したことを信号を通じてプロセスに通知します。これは、ユーザー プロセス間の通信と同期のための原始的なメカニズムでもあります。キーボードの割り込みまたはエラー状態 (プロセスが仮想メモリ内の存在しない場所にアクセスしようとしているなど) が信号を生成する場合があります。シェルは、シグナルを使用してジョブ制御シグナルをその子プロセスに送信します。
プロセスの5つの状態と遷移プロセス※

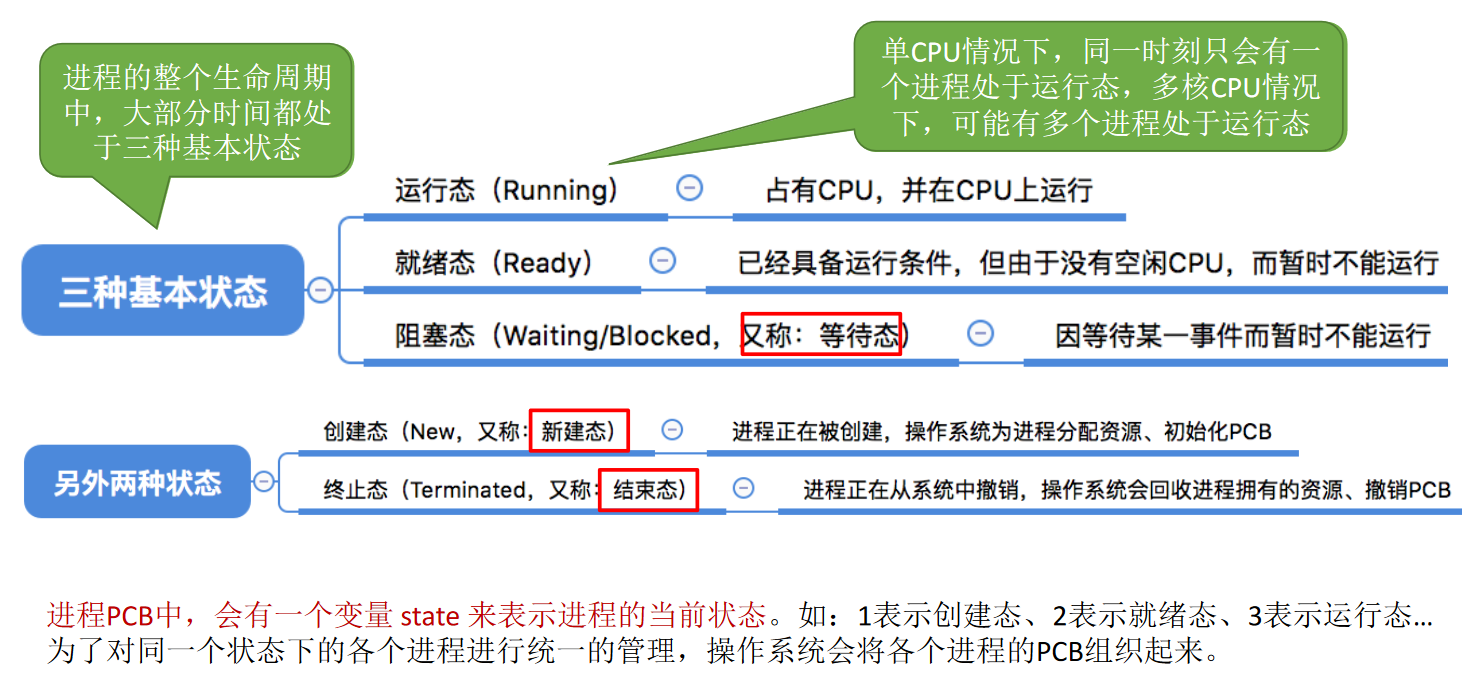
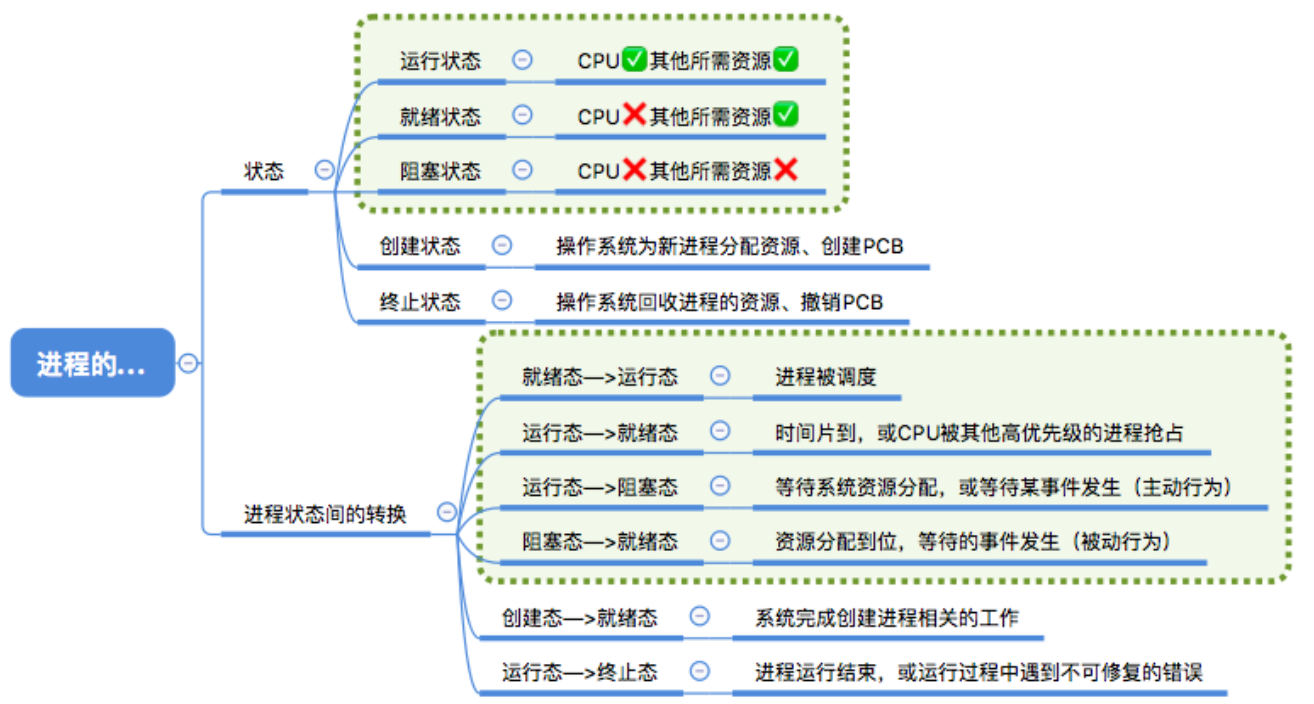
プロセス (ジョブ) のスケジューリング アルゴリズムは何ですか?※※※※
- 早い者勝ち先着順サーバー (FCFS) は、
リクエストの順序でスケジュールします。非プリエンプティブ、低いオーバーヘッド、スタベーションの問題なし、応答時間は不確実 (遅い可能性がある)、
短いプロセスには適さず、IO 集中型のプロセスには適していません。 - まずは短い仕事最短ジョブ優先 (SJF) では、
推定実行時間が短い順にジョブをスケジュールします。非プリエンプティブ、高スループット、高オーバーヘッドは、飢餓の問題を引き起こす可能性があります。
短いプロセスには良好な応答時間を提供しますが、長いプロセスには適していません。常に短いジョブが来る場合、長いジョブはスケジュールされません。 - 最高の応答優先度
応答率 = 1+待ち時間/処理時間。同時に待ち時間の長さや予想実行時間の長さも考慮され、長い処理と短い処理のバランスがとれます。非プリエンプティブ、高スループット、潜在的に高オーバーヘッド、良好な応答時間、スタベーションの問題なし。 - 優先スケジューリングアルゴリズム
各プロセスに優先度を割り当て、優先度に応じてスケジュールを設定します。優先度の低いプロセスがスケジュールされるまで待機しないようにするために、待機しているプロセスの優先度を時間の経過とともに高めることができます。 - タイムスライスの回転
FCFS の原理に従って、準備が完了したすべてのプロセスをキューに配置し、タイム スライスを使い果たしたプロセスがキューの最後に配置されます。プリエンプティブ (タイム スライスが使い果たされた場合)、オーバーヘッドが低く、ハングの問題がなく、短いプロセスの応答時間は良好です。
タイム スライスが小さい場合は、プロセスの切り替えが頻繁でスループットが低くなります。タイム スライスが長すぎる場合は、リアルタイム性は保証できません。 - マルチレベルフィードバックキュースケジューリングアルゴリズム
優先順位を下げ、タイム スライスを増やして、複数のレディ キュー 1、2、3... を設定します。現在のキュー内のプロセスは、優先度の高いキューが空になるまでのみスケジュールされます。プロセスが現在のキューのタイム スライスを使い果たし、実行が完了していない場合、プロセスは次のキューに移動されます。
プリエンプティブ (タイム スライスが使い果たされたとき) では、オーバーヘッドが大きくなる可能性があり、これは IO タイプのプロセスにとって有益であり、スタベーションの問題が発生する可能性があります。
プロセス同期※
プロセス同期が必要な理由: プロセスは、メモリ、データベースなどの一部のリソースを他のプロセスと共有することがあります。複数のプロセスが同じ共有リソースを同時に読み書きすると、競合が発生する可能性があります。そのため、プロセスの同期が必要となり、複数のプロセスが順番にリソースにアクセスします。
ミューテックス ミューテックス:
ミューテックスはカーネル オブジェクトであり、ミューテックス オブジェクトを所有するスレッドのみがミューテックス リソースにアクセスする権利を持ちます。ミューテックス オブジェクトは 1 つだけであるため、ミューテックス リソースが複数のスレッドによって同時にアクセスされないことが保証されます。現在ミューテックス オブジェクトを所有しているスレッドは、タスクの処理後にミューテックス オブジェクトを引き渡す必要があるため、他のスレッドはミューテックス オブジェクトを所有します。スレッドはリソースにアクセスできます;
セマフォ セマフォ:
セマフォは、複数のスレッドが同じリソースに同時にアクセスできるようにするカーネル オブジェクトですが、このリソースに同時にアクセスするスレッドの最大数を制御する必要があります。セマフォ オブジェクトは、最大リソース数と現在使用可能なリソース数を保存します。スレッドが共有リソースにアクセスするたびに、現在使用可能なリソース数は 1 ずつ減ります。現在使用可能なリソース数が 0 より大きい限り、セマフォ信号は0 の場合、スレッドをキューに入れて待機します。スレッドが共有リソースの処理を終了した後、終了中に ReleaseSemaphore 関数を通じて現在利用可能なリソースの数に 1 を追加する必要があります。セマフォの値が 0 または 1 のみの場合、セマフォはミューテックスになります。
イベント イベント:
タスクの処理後に、スレッドが別のスレッドをアクティブに起動してタスクを実行できるようにします。イベントは、手動リセット イベントと自動リセット イベントに分けられます。手動リセット イベントがアクティブ状態に設定されると、待機中のすべてのスレッドがウェイクアップされ、プログラムが非アクティブ状態にリセットするまでアクティブ状態のままになります。自動リセット イベントが起動状態に設定されると、待機中のスレッドが起動され、自動的に未起動状態に戻ります。
クリティカル セクション:
リソースにアクセスするコード部分を指し、常に 1 つのスレッドのみがクリティカル リソースにアクセスできます。クリティカル セクション オブジェクトを所有するスレッドはクリティカル リソースにアクセスでき、リソースにアクセスしようとしている他のスレッドは、クリティカル セクション オブジェクトが解放されるまで一時停止されます。
デッドロック※
意味※
デッドロックとは、複数のプロセスが実行中にリソースの奪い合いにより待ち状態となり、外部からの力がなければ先に進めなくなる現象を指します。このとき、システムがデッドロック状態にある、またはシステム内でデッドロックが発生しているといい、このように常に待ち続けているプロセスをデッドロックプロセスと呼びます。
デッドロックの原因
①システムリソース不足(譲れないリソースの奪い合い)
②不適切な進行順序(P1がAを所有しBを申請、P2がBを所有しAを申請)
デッドロックが発生するための必要条件※
① 相互排除条件とは、
割り当てられたリソースをプロセスが排他的に使用すること、つまり、一定のリソースが一定期間内に 1 つのプロセスによってのみ占有されることを指します。
② リクエストアンドホールド状態とは
、プロセスが少なくとも 1 つのリソースを保持しているが、新たなリソース要求を行い、そのリソースが他のプロセスによって占有されている状態を意味します。このとき、要求元のプロセスはブロックされていますが、依然としてリソースを保持しています。取得したその他のリソース。
③ 非剥奪条件と
は、プロセスが獲得したリソースを指し、使い果たされるまで剥奪することはできず、使い切った場合にのみ自ら解放することができます。 ④ ループ待ち条件とは、デッドロックが発生した場合
に
、プロセス リソースのリング チェーンになります。
デッドロックに対処するための基本的なアプローチ
① デッドロックを防ぐ
比較的シンプルで直感的な事前予防方法です。その方法は、デッドロックに必要な 4 つの条件のうち 1 つまたは複数を破壊するために一定の制限を設定することで、デッドロックを回避するというものです。デッドロック防止は、実装が簡単な方法であり、広く使用されています。ただし、課される制限は多くの場合厳しすぎるため、システム リソースの使用率とシステム スループットの低下につながる可能性があります。
② デッドロックを回避する
この方法も事前の予防戦略ですが、デッドロックの 4 つの必要条件を破壊するために事前にさまざまな制限措置を講じる必要はありませんが、リソースを動的に割り当てる過程で、何らかの方法を使用してデッドロックの発生を回避します。システムが危険な状態に陥るのを防ぎ、デッドロックを回避します。
③ デッドロック検知
事前の制限措置や危険領域への進入の確認を必要とせず、運用中にシステムがデッドロックする可能性がある方法です。しかし、システムが設定した検出メカニズムは、デッドロックの発生を適時に検出し、デッドロックに関連するプロセスとリソースを正確に判断し、発生したデッドロックをシステムから除去するための適切な措置を講じることができます。
④デッドロック解除
デッドロック検出と合わせた対策です。システム内でデッドロックが発生したことが検知された場合、プロセスはデッドロック状態を解除する必要がある。一般的な実装方法は、一部のリソースを再利用するために一部のプロセスを取り消すか一時停止し、その後、これらのリソースをすでにブロック状態にあるプロセスに割り当てて、実行を継続できる状態にできるようにすることです。
3. メモリ管理

メモリ拡張技術 ― オーバーレイ技術とスワップ技術※
オーバーレイ技術
大きなプログラムを一連のオーバーレイに分割します。各オーバーレイは比較的独立したプログラム単位であり、プログラムの実行時に同時にメモリにロードする必要のないオーバーレイのグループを形成し、オーバーレイ セグメントを形成します。このオーバーレイセグメントは同じストレージ領域に割り当てられ、このストレージ領域がカバレッジ領域となり、カバレッジセグメントに 1 つずつ対応します。オーバーレイ セグメントのサイズは、オーバーレイ セグメント内の最大のオーバーレイによって決まります。(メモリ容量が少なすぎるという問題を解決するために、プログラムを実行する前にプログラムのすべての情報をメモリにロードする必要があるという制限が破られます)
スイッチング技術
一時的に使用されないプログラムやデータの一部を内部メモリから外部メモリに移動して必要なメモリ空間を確保したり、外部メモリから指定されたプログラムやデータを対応するメモリに読み出して制御を引き継ぎます。 He は、システム上での実行を可能にするメモリ拡張テクノロジです。プロセッサの中間レベルのスケジューリングには、スイッチング テクノロジが使用されます。
相違点:
① カバレッジ技術と比較して、スワップ技術はプログラマが指定したプログラムセグメント間のカバレッジ構造を必要としません; ② スワップ技術は
主にプロセスとジョブ間で実行され、カバレッジ技術は主にプロセス内で実行されます。同一のプロセスまたはジョブ; 交換技術は主にプロセスとジョブ間で実行され、カバー技術は主に同じプロセスまたはジョブ内で実行されます; ③ カバー技術は、カバー対象と無関係なプログラムセグメントのみをカバーでき
ますプログラムセグメントであり、交換プロセスはスワップアウトとスワップインの 2 つのプロセスで構成されます。カバー技術は、カバーされるプログラムセグメントに無関係なプログラムセグメントのみをカバーでき、交換プロセスはスワップアウトとスワップインの 2 つのプロセスで構成されます。
ページネーションとセグメンテーションの違い※
リンク
ページとセグメンテーション システムには多くの類似点がありますが、主に次の点で概念がまったく異なります。
1. ページは情報です。物理単位、ページングは、メモリの外部部分を削減し、メモリの使用率を向上させるために、個別の割り当てを実現することです。または、ページングは、ユーザーのニーズではなく、システム管理のニーズのみによるものです。
セグメントは有益です論理ユニット、これには、意味が比較的完全な一連の情報が含まれています。セグメンテーションの目的は、ユーザーのニーズをより適切に満たすことです。
2、ページ サイズは固定されており、システムによって決定されます。、論理アドレスは、ページ番号とマシン ハードウェアによって実現されるページ アドレスの 2 つの部分に分割されるため、システムは 1 つのサイズのページしか持つことができません。
セグメントの長さは固定されていませんは、ユーザーが作成したプログラムに依存し、通常、編集プログラムがソースプログラムを編集する際に、情報の性質に応じて分割されます。
3.ページングされたジョブのアドレス空間は 1 次元です、これは単一の線形スペースであるため、プログラマはアドレスを表すために 1 つのニーモニックを使用するだけで済みます。
セグメント化されたジョブのアドレス空間は 2 次元です, プログラマがアドレスを特定するときは、セグメント名 (セグメント番号) とセグメント内のアドレス (セグメント アドレス) の両方を指定する必要があります。
CPUアドレッシングモード※
リンク
アドレッシングモードとは、プロセッサが命令内に与えられたアドレス情報に基づいて実効アドレスを見つけ、この命令のデータアドレスと次に実行する命令のアドレスを決定する方式です。メモリにおけるオペランドや命令語の書き込みや読み出しの方法には、アドレス指定、連想記憶、スタックアクセスなどがあります。ほとんどすべてのコンピュータはメモリ内のアドレス指定を使用します。アドレス指定方式を使用する場合、オペランドや命令のアドレスを構成する方式をアドレッシング方式といいます。
アドレッシングモードは命令アドレッシングモードとデータアドレッシングモードの2つに分類され、前者は比較的単純であり、後者はより複雑です。従来設計のコンピュータでは、メモリ内の命令のアドレス指定とデータのアドレス指定が交互に行われることに注意してください。
命令のアドレス指定:
- シーケンシャルアドレッシング
- アドレス指定をスキップする
データのアドレス指定:
- 暗黙的なアドレス指定
- すぐに住所を指定する
- 直接アドレス指定
- 間接アドレス指定
- 相対アドレス指定
- ベースアドレス指定
- インデックス付きアドレス指定
ヒープとスタックの違い※※
リンク
(1) 管理方法が異なります。
スタック コンパイラはプログラマによる手動制御なしで自動的に管理しますが、ヒープ領域の適用と解放はプログラマによって制御されるため、メモリ リークが発生しやすくなります。
(2) 空間の大きさが違う。
スタックとは、下位アドレスまで続く連続したメモリ領域のデータ構造です。この文は、スタックの先頭アドレスとスタックの最大容量がシステムによってあらかじめ決められており、要求された領域がスタックの残りの領域を超えると、オーバーフローが発生することを意味します。したがって、ユーザーがスタックから取得できるスペースは少なくなります。
ヒープとは、上位アドレスに拡張されるデータ構造であり、不連続なメモリ領域です。これは、システムがリンク リストを使用して空きメモリ アドレスを格納し、リンク リストのトラバース方向が下位アドレスから上位アドレスに向かうためです。ヒープによって得られるスペースは、より柔軟でより大きいことがわかります。スタック内の要素は 1 対 1 に対応しており、スタックの途中からメモリブロックがポップされることはありません。
(3) フラグメントが生成されるかどうか。
ヒープの場合、malloc/free (新規/削除) が頻繁に行われると、必然的にメモリ空間に不連続性が生じ、その結果、多数のフラグメントが発生し、プログラムの効率が低下します (ただし、プログラムの終了後にオペレーティング システムがメモリを再利用します)。 。スタックの場合、この問題は存在しません。
(4) 成長方向が異なる。
ヒープの成長方向は上向き、つまりメモリ アドレスが増加する方向であり、スタックの成長方向は下向き、つまりメモリ アドレスが減少する方向です。
(5) 配布方法が異なります。
ヒープはプログラム内の malloc() 関数によって動的に割り当てられ、free() 関数によって解放されます。スタックの割り当てと解放はコンパイラによって行われ、スタックの動的割り当ては alloca() によって行われます。関数ですが、スタックの動的割り当てはヒープとは異なり、手動で実装することなくコンパイラーによって適用および解放されます。
(6) 分配効率が異なります。
スタックはマシン システムによって提供されるデータ構造であり、コンピューターは最下層でスタックのサポートを提供します。つまり、スタックのアドレスを格納する特殊なレジスタを割り当て、スタックをプッシュおよびポップします。また、スタックをプッシュおよびポップするための特別な命令もあります。実行する。ヒープは C 関数ライブラリによって提供されます。そのメカニズムは非常に複雑です。たとえば、メモリを割り当てるために、ライブラリ関数は特定のアルゴリズム (特定のアルゴリズム) に従って十分な大きさのメモリをヒープ メモリから検索します。アルゴリズムはデータ構造/オペレーティング システムを参照できます) 十分なスペースがない場合 (メモリの断片化が多すぎることが原因である可能性があります)、オペレーティング システムは十分なメモリを割り当てる機会があるようにメモリ スペースを再配置する必要があります。戻る。明らかに、ヒープはスタックよりも効率がはるかに低くなります。
再帰スタックはオーバーフローしますか?その理由は?※
再帰呼び出しを連鎖させると
、関数は最終エンドポイントに到達した後でのみ終了でき、占有されたスタック領域は最終エンドポイントに到達するまで解放されません。再帰呼び出しが多すぎると、スタックリソースが占有される可能性があります。スレッドの最大値を超えるとスタック オーバーフローが発生し、プログラムが異常終了します。
リンク
スタックのエントリと終了の規則は、先に入ってからアウトです。最初のエントリがスタックからポップアウトできない場合、そのエントリは常にスタック領域に存在することになり、スタックがいっぱいになってオーバーフローする可能性が高くなります。
スタックリークとは何ですか※
リンク
スタックのオーバーフローとは、制限長を超えたデータをスタックに書き込むことを指し、オーバーフローしたデータはスタック内の他のデータを上書きし、プログラムの動作に影響を与えます。
4. 文書管理
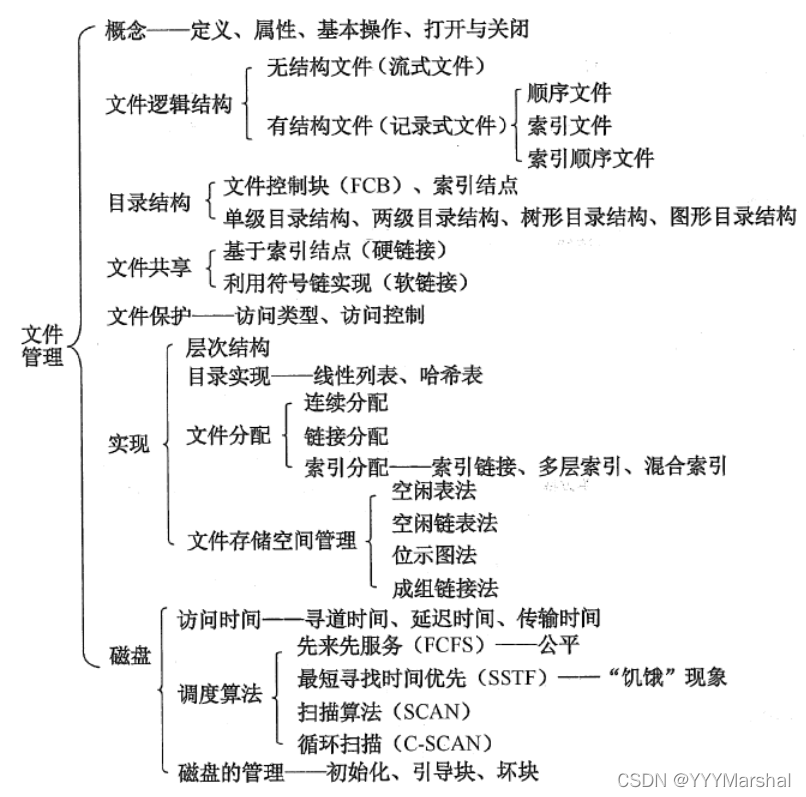
ディスク スケジュール アルゴリズムとは何ですか? ※※
1、早い者勝ちアルゴリズム(FCFS) 先着順サービス
これは、比較的単純なディスク スケジューリング アルゴリズムです。プロセスがディスクへのアクセスを要求する順序に従ってスケジュールを設定します。
このアルゴリズムの利点は、公平かつシンプルであり、各プロセスの要求を順番に処理することができ、特定のプロセスの要求を長時間満たせないという事態が発生しないことです。
このアルゴリズムはシークを最適化しないため、多数のディスク アクセス要求の場合、このアルゴリズムはデバイス サービスのスループットを低下させ、平均シーク時間は長くなりますが、データを取得するための各プロセスの応答時間は長くなります。サービス 変化は少ないです。
2、最短シーク時間の最初のアルゴリズム(SSTF) Shortest Seek Time First
このアルゴリズムは、アクセスするトラックが現在のヘッドが配置されているトラックに最も近いことを必要とするようなプロセスを選択し、毎回シーク時間が最短になるようにします。このアルゴリズムはさらに改善される可能性があります。ただし、平均シーク時間が最短になるという保証はありません。欠点は、ユーザーのサービス要求に応答する可能性が均等ではないため、応答時間に大きなばらつきが生じることです。多数のサービス リクエストの場合、内側および外側のエッジ トラックへのリクエストは無期限に遅延し、一部のリクエストの応答時間は予測不可能になります。
3.スキャン アルゴリズム (SCAN) エレベーターのスケジュール設定
走査アルゴリズムでは、アクセスされるトラックと現在のトラックの間の距離だけでなく、磁気ヘッドの現在の移動方向も考慮されます。たとえば、磁気ヘッドが内側から外側に移動している場合、スキャン アルゴリズムによって選択される次のアクセス オブジェクトは、アクセスしたいトラックが現在のトラックの外側にあるだけでなく、最も近いトラックである必要があります。このように内側から外側にアクセスすると、アクセスする外側の磁気トラックがなくなるまで、磁気アームが反転して外側から内側に移動します。このときも、アクセス対象のトラックがカレントトラック内である場合には、その都度、このようなプロセスを選択してスケジューリングすることにより、スタベーションの発生を回避することができる。このアルゴリズムにおける磁気ヘッドの動きはエレベータの動作によく似ているため、エレベータスケジューリングアルゴリズムとも呼ばれます。このアルゴリズムは、基本的に、サービスが中間トラックに集中し、応答時間が大きく異なるという最短シーク時間優先アルゴリズムの欠点を克服し、最短シーク時間優先アルゴリズムの利点、つまりスループットが大きく、平均応答時間は小さいですが、ウォブルスキャン方式のため、両側のトラックへのアクセス頻度は中央のトラックに比べて依然として低いです。
4.サイクリック スキャン アルゴリズム (CSCAN)
サイクル スキャン アルゴリズムは、スキャン アルゴリズムを改良したものです。トラックへのアクセス要求が均等に分散されている場合、ヘッドがディスクの一端に到達して反対方向に移動する際にヘッドに遅れるアクセス要求は比較的少数になります。これは、これらのトラックが処理されたばかりで、ディスクのもう一方の端での要求密度が非常に高く、これらのアクセス要求の待ち時間が比較的長いためです。この状況を解決するために、サイクリック スキャン アルゴリズムでは、ヘッドが一方向に動きます。例えば、内周から外周への移動のみで、ヘッドがアクセス対象の最外周トラックに移動すると、すぐにアクセス対象の最内周トラックに戻ります。つまり、最小のトラック番号とそれに続く最大のトラック番号が構成されます。スキャンのサイクル。
5. 入出力管理
