記事ディレクトリ
序文
開発プロセスでは、パフォーマンスをテストするため、運用環境でページの見栄えを良くするため、または特定の知識ポイントを検証する方法を学ぶために、テスト データが必要になることがよくあります。 10行でも20行でも大丈夫です 多すぎると死んでしまいます 次によく使われるMySQLのテストデータ一括生成方法を2つ紹介します
- 収納方法+機能
- Navicat データの生成
1. 表
テーブルを2つ用意しました
-
役割テーブル:
- ID:自己成長
- role_name: ランダムな文字列、繰り返しは許可されません
- 注文: 1-1000 任意の数
-
ユーザーテーブル:
- ID:自己成長
- ユーザー名: ランダムな文字列、繰り返しは許可されません
- パスワード: ランダムな文字列、繰り返し可能
- role_id: 1 ~ 10w の任意の数値
-
テーブル作成ステートメント:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(255) DEFAULT NULL COMMENT '用户名',
`role_id` int(11) DEFAULT NULL COMMENT '角色id',
`password` varchar(255) DEFAULT NULL COMMENT '密码',
`salt` varchar(255) DEFAULT NULL COMMENT '盐',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
CREATE TABLE `role` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`role_name` varchar(255) DEFAULT NULL COMMENT '角色名',
`orders` int(11) DEFAULT NULL COMMENT '排序权重\r\n',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
次に、関数を使用して生成します。
ストアド プロシージャを通じて迅速に挿入し、関数を通じてデータが繰り返されないようにします
設定により関数を作成できるようになります
MySQL で関数の作成が許可されているかどうかを確認する
SHOW VARIABLES LIKE 'log_bin_trust_function_creators';
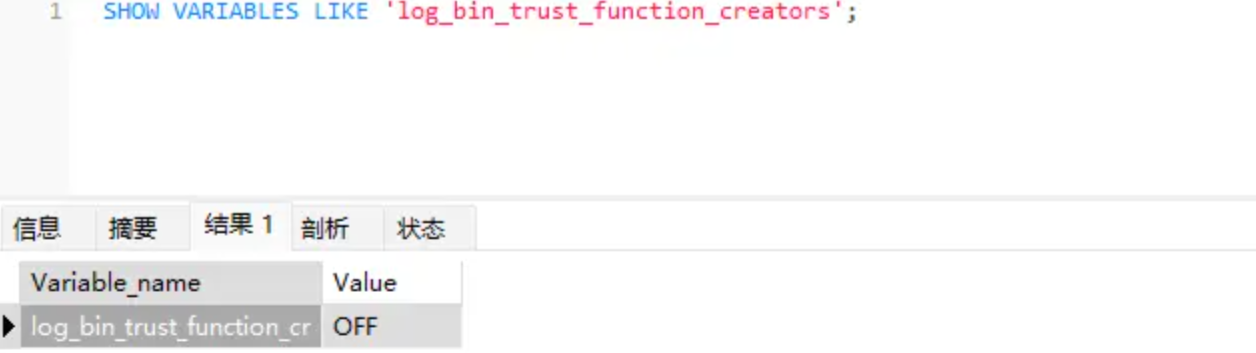
結果は図に示されており、次のコマンドを使用して作成関数機能を有効にします(グローバルすべてのセッションが有効になります)。
SET GLOBAL log_bin_trust_function_creators=1;
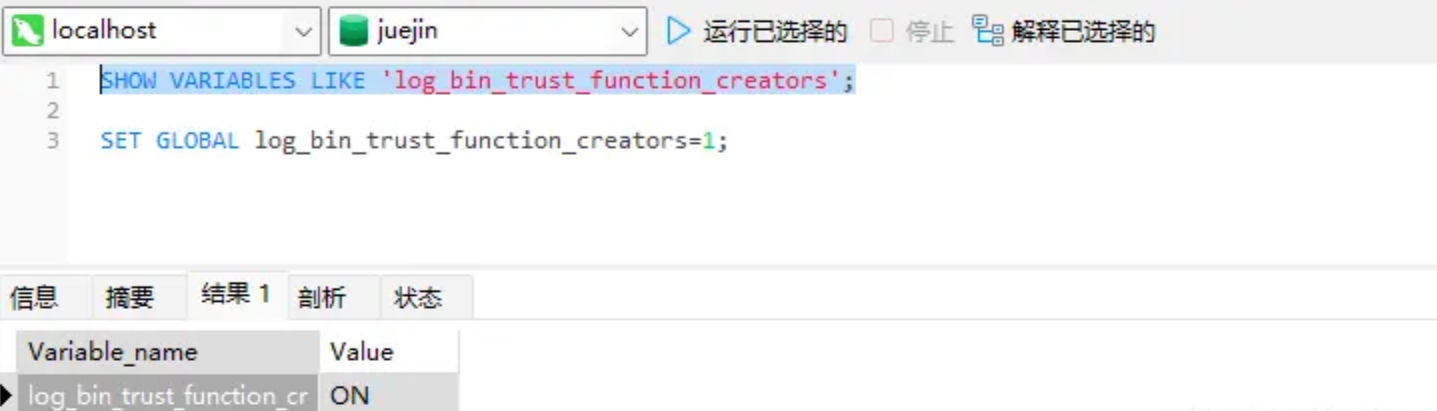
この時点で、別のクエリにより、そのクエリが開かれたことが表示されます。
ランダムな文字列を生成する
-- 随机产生字符串
DELIMITER $$
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END $$
-- 假如要删除
-- drop function rand_string;
乱数を生成する
-- 用于随机产生区间数字
DELIMITER $$
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num -from_num+1));
RETURN i;
END$$
-- 假如要删除
-- drop function rand_num;
3. ストアド プロシージャを作成する
役割テーブルを挿入
-- 插入角色数据
DELIMITER $$
CREATE PROCEDURE insert_role(max_num INT)
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO role ( role_name,orders ) VALUES (rand_string(8),rand_num(1,5000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END$$
-- 删除
-- DELIMITER ;
-- drop PROCEDURE insert_role;
ユーザーテーブルを挿入
-- 插入用户数据
DELIMITER $$
CREATE PROCEDURE insert_user(START INT, max_num INT)
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO user (username, role_id, password, salt ) VALUES (rand_string(8) ,rand_num(1,100000), rand_string(10), rand_string(10));
UNTIL i = max_num
END REPEAT;
COMMIT;
END$$
-- 删除
-- DELIMITER ;
-- drop PROCEDURE insert_user;
4 番目に、ストアド プロシージャを実行します。
-- 执行存储过程,往dept表添加10万条数据
CALL insert_role(100000);
-- 执行存储过程,往emp表添加100万条数据,编号从100000开始
CALL insert_user(100000,1100000);
まとめ
100,000 データの実行には 30 分近くかかり、1,000,000 データの実行には 20 分以上かかりましたが、同時にユーザーのストレージは長時間スタックしたままでした...最終的には正常に追加されましたが、
自動-increment の値と行数が一致していませんでした。理由はわかりません...

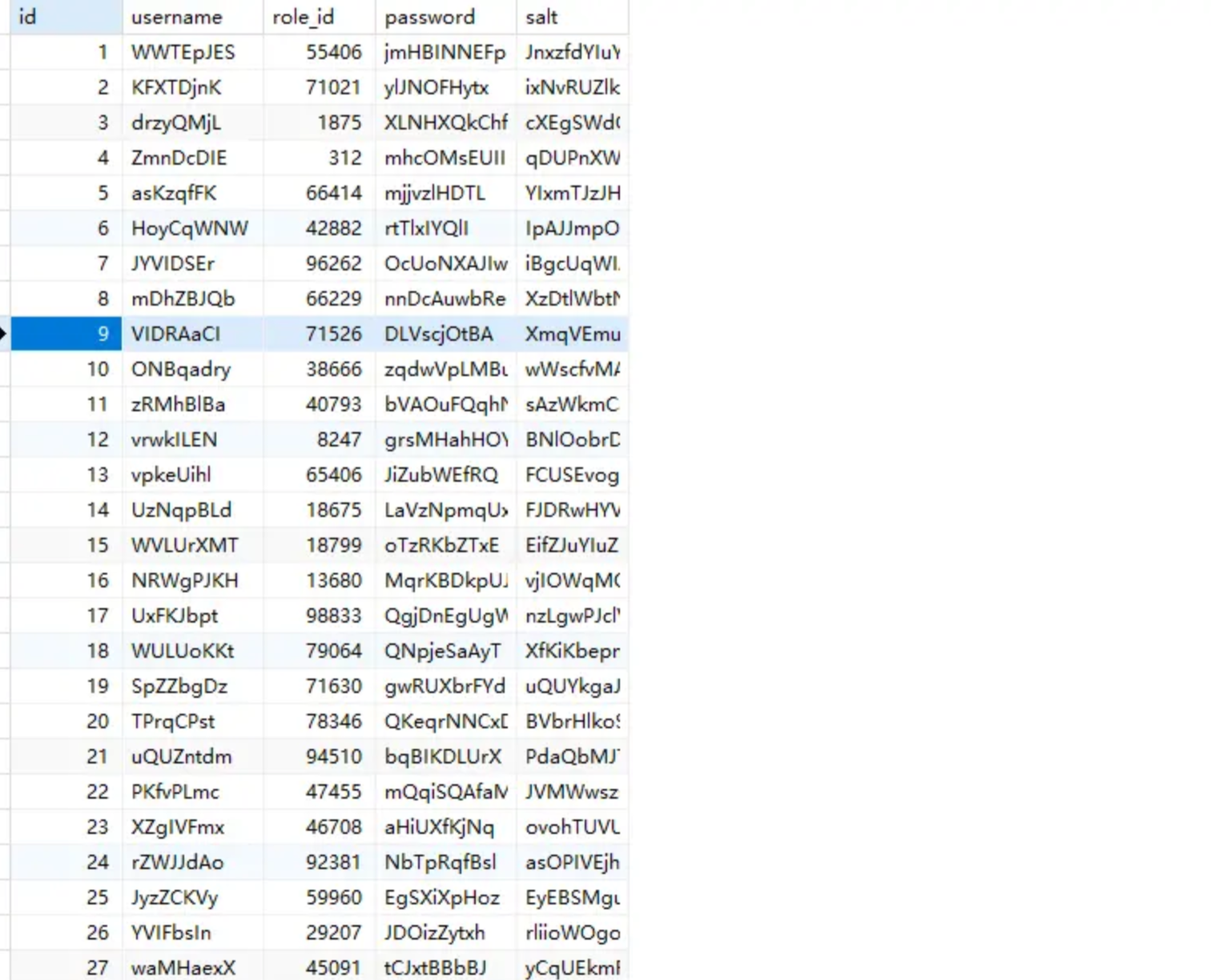
データ表示
- role表
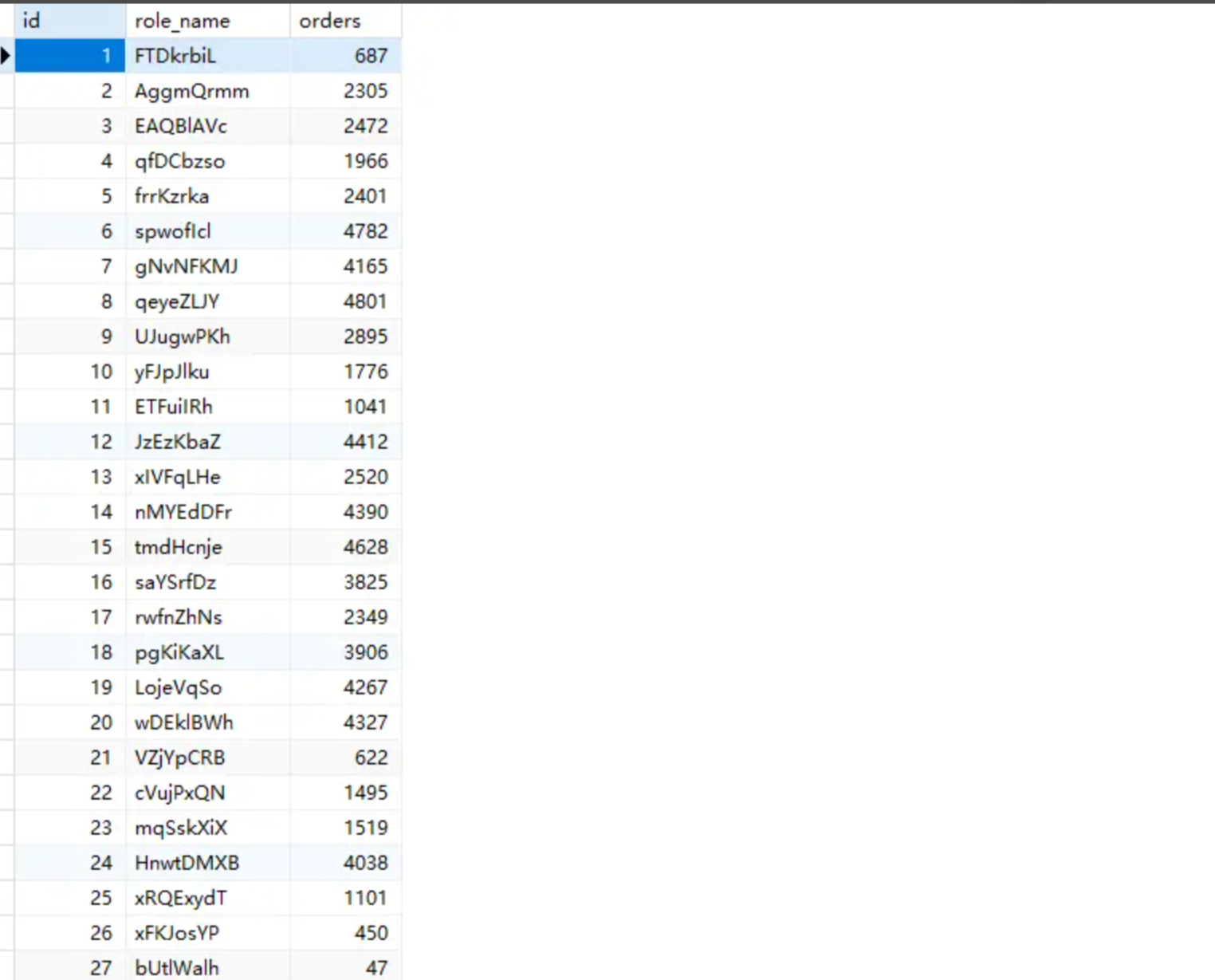
- user表
5. Navicat に付属のデータ生成を使用する
次に Navicat のデータ生成を使用します。
次のステップに直接進み、対応する 2 つのテーブルを選択して行数と対応する生成ルールを生成します。前の実行速度に基づいて、今回はロールが 10,000 個のデータを生成し、ユーザーが 10,000 個のデータを生成します。文字列の
場合フィールドをタイプすると、ランダムなデータ ジェネレーターを設定し、必要に応じて選択できます
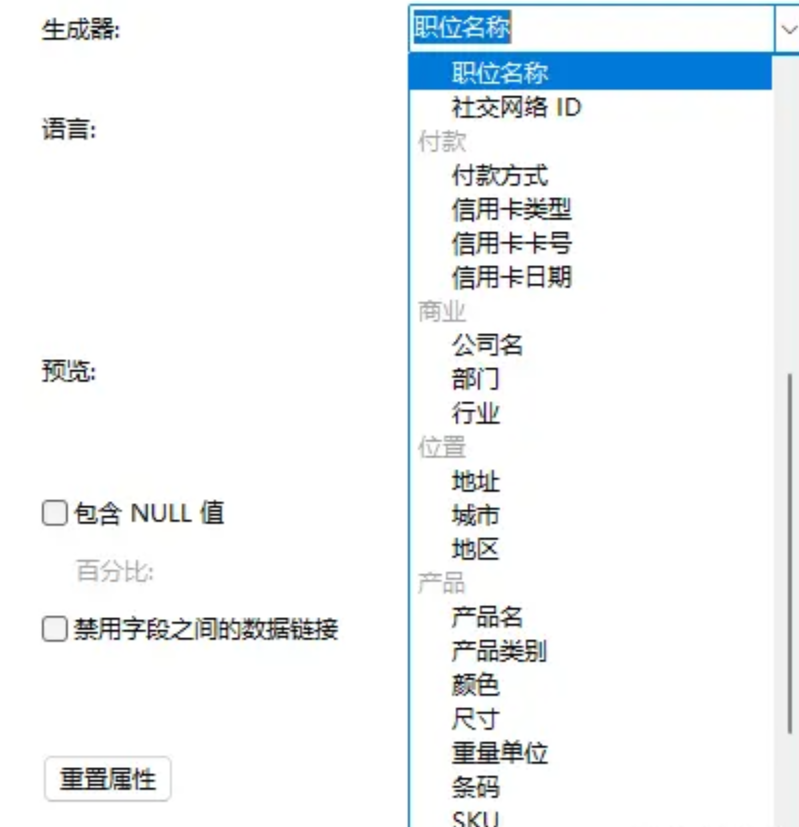
たとえば、ロール名、役職を選択した場合は、null を含めるかどうかなども選択できます。
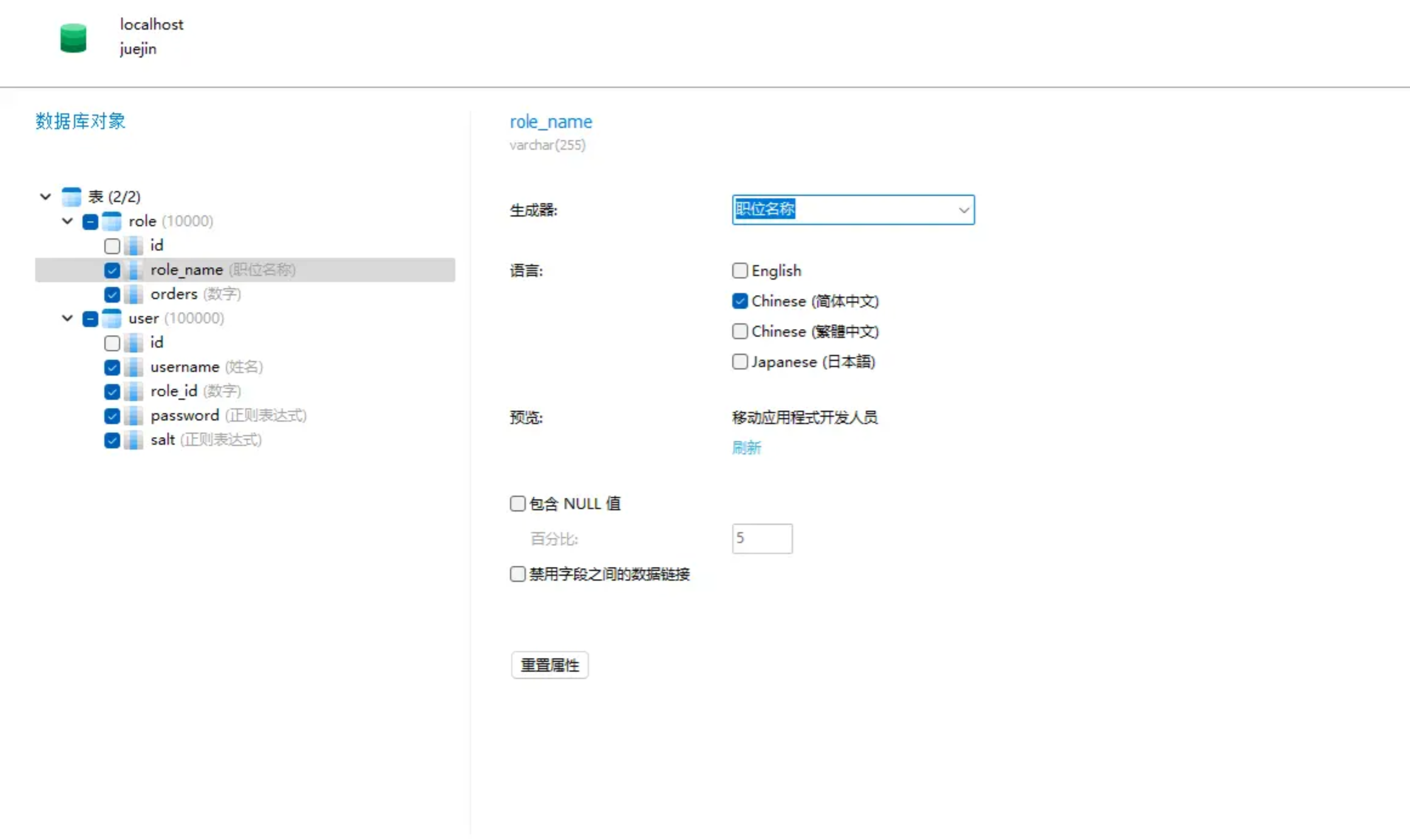
ただし、名前の場合は、一意であるかどうかを選択できます。
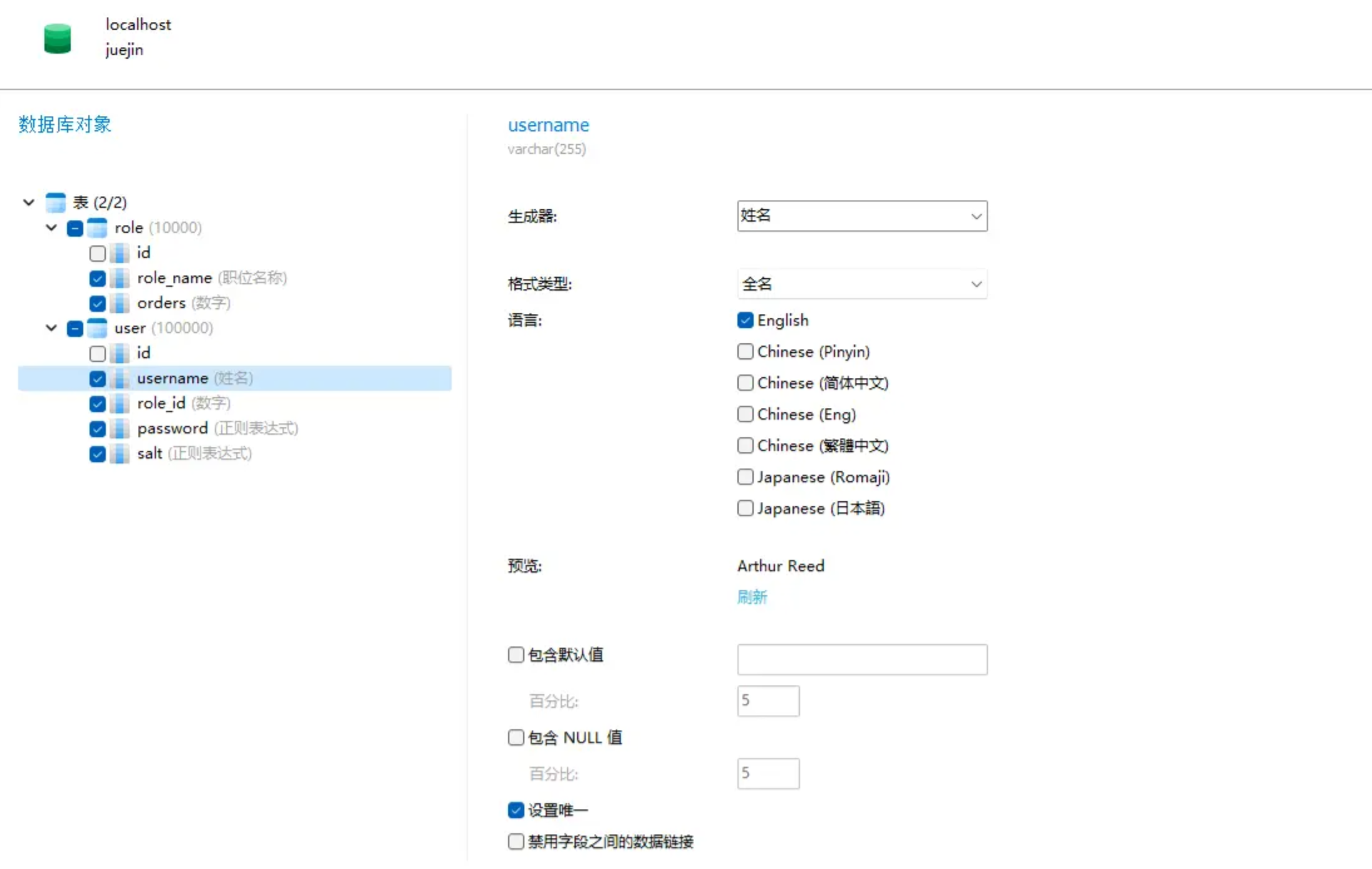
数字の単語を使用すると、範囲やデフォルト値などを選択できます。
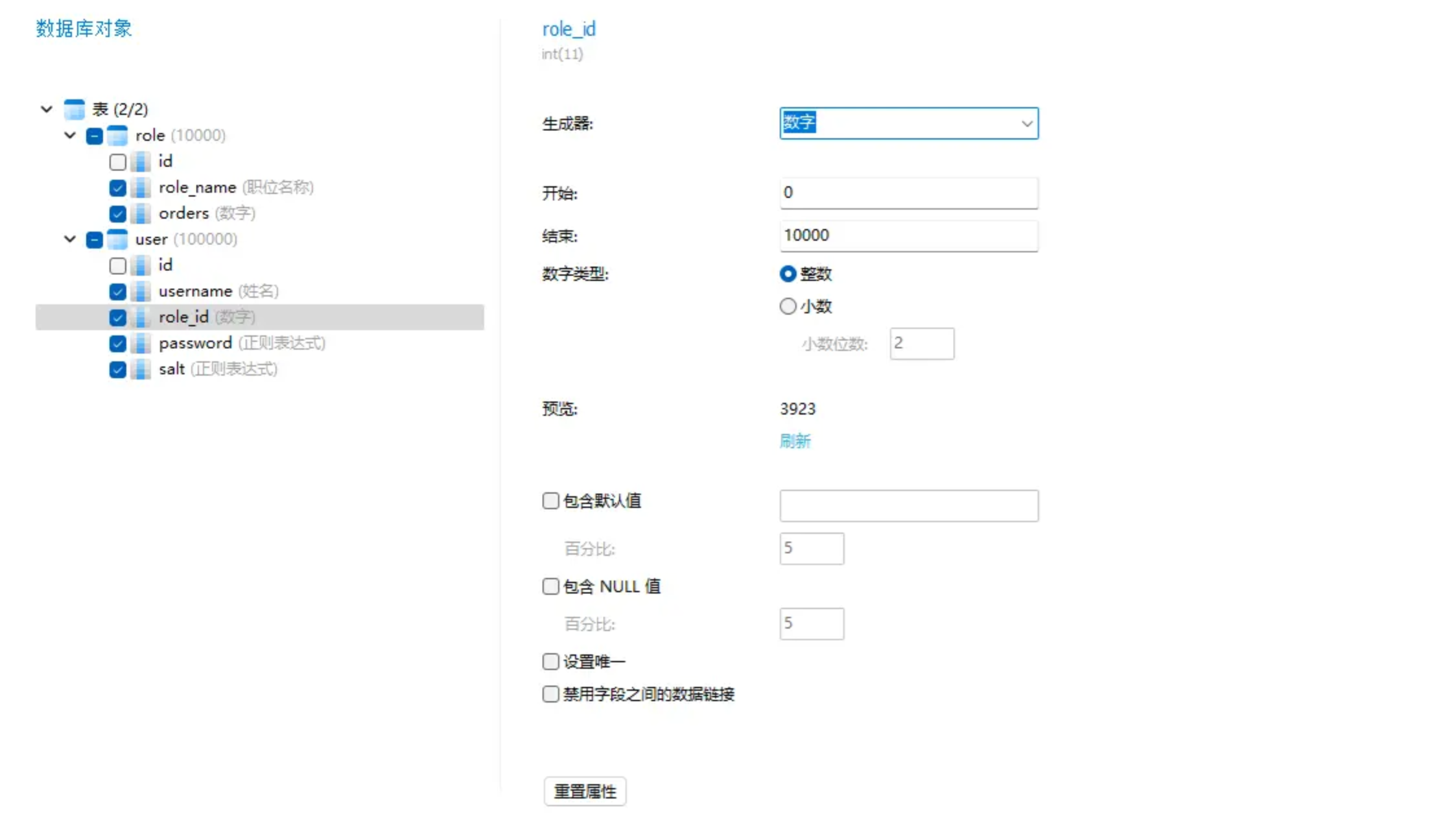
確認したら、右下隅をクリックしてランダムなテスト データを生成します。

結果から、110,000 個のテスト データを生成するのに 11 秒かかり、最初の方法よりもはるかに高速であることがわかります。