GPT-4 は、ディープ ラーニングをスケーリングする OpenAI の取り組みにおけるマイルストーンです。
GPT-4 は、大規模なマルチモーダル モデル(画像とテキストの入力を受け入れ、テキスト出力を発行する) であり、多くの現実世界のシナリオでは人間よりも劣っていますが、さまざまな専門的および学術的なベンチマークで人間レベルのパフォーマンスを示しています。たとえば、司法試験の模擬試験に合格し、受験者の上位 10% のスコアを獲得したのに対し、GPT-3.5 は下位 10% のスコアを獲得しました。OpenAI の敵対的テスト手順と ChatGPT から学んだ教訓を使用して、GPT-4 を反復的に調整するのに OpenAI 6 か月を要し、リアリズムと操作性に関してこれまでで最高の結果 (完全にはほど遠いものの) をもたらしました。
過去 2 年間、OpenAI チームはディープ ラーニング スタック全体を再構築し、Azure と協力して、OpenAI のワークロード用にゼロからスーパーコンピューターを共同設計しました。1 年前、OpenAI はシステムの最初の「試運転」として GPT-3.5 をトレーニングしました。いくつかのバグが発見されて修正され、理論的基礎が改善されました。その結果、GPT-4 トレーニングの実行は (少なくとも私たちにとっては!) 前例のないほど安定しており、OpenAI が事前にトレーニング パフォーマンスを正確に予測できた最初の大規模モデルになりました。OpenAI が信頼性の高いスケーリングに注力し続ける中、GPT-4 はますます事前に将来を予測して準備します。
いずれにしても、GPT-3.5と GPT-4 の違いは微妙です。タスクの複雑さが十分なしきい値に達すると、違いが現れます。GPT-4 は、GPT-3.5 よりも信頼性が高く、より創造的であり、よりきめ細かい指示を処理できます。
2 つのモデルの違いを確認するために、OpenAI は、もともと人間用に設計された模擬試験を含む、さまざまなベンチマークでテストしました。OpenAI は、最新の公開テスト (オリンピアードと AP の自由回答問題の場合) を使用するか、2022 年から 2023 年版の模擬試験を購入することで継続します。OpenAI は、これらの試験に固有のトレーニングを提供していません。モデルはトレーニング中に試験から少数の質問を見ましたが、OpenAI は結果を代表的なものと見なします -詳細についてはテクニカル レポートを参照してください。
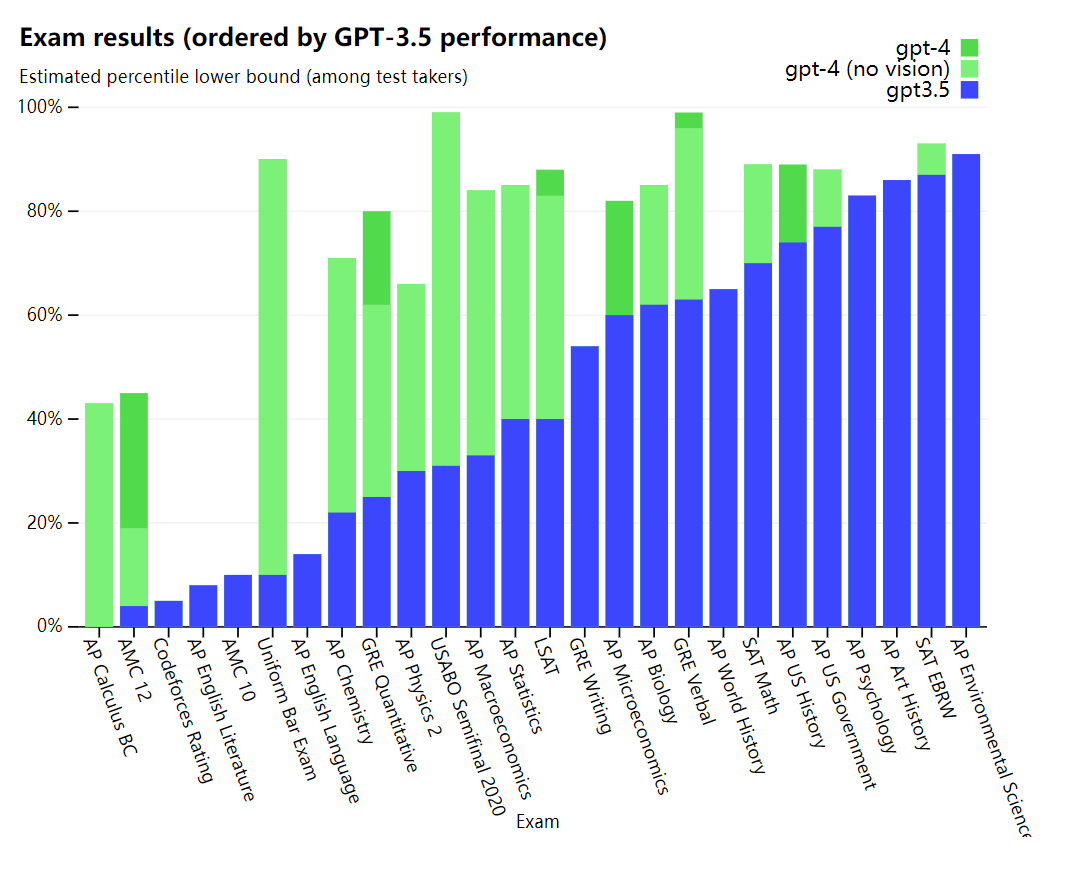
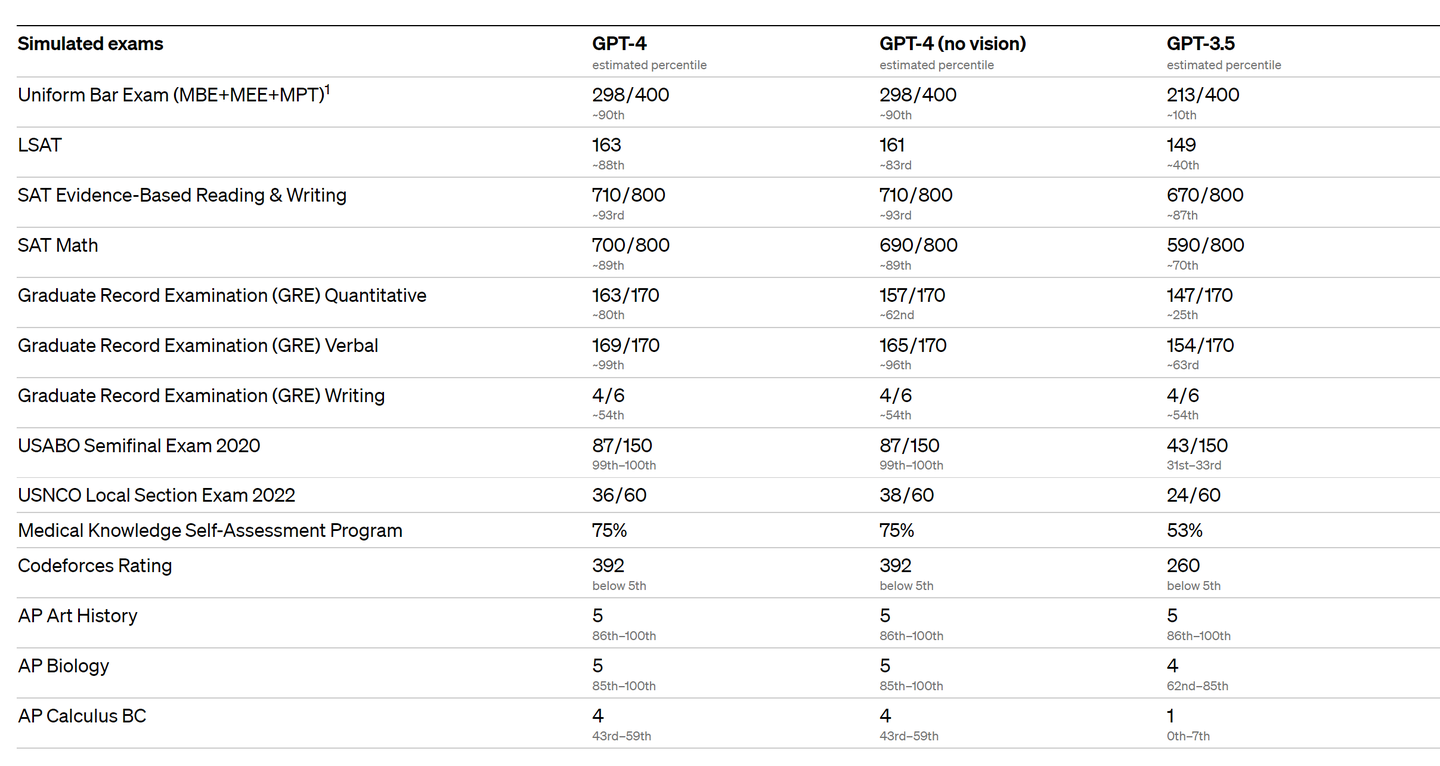
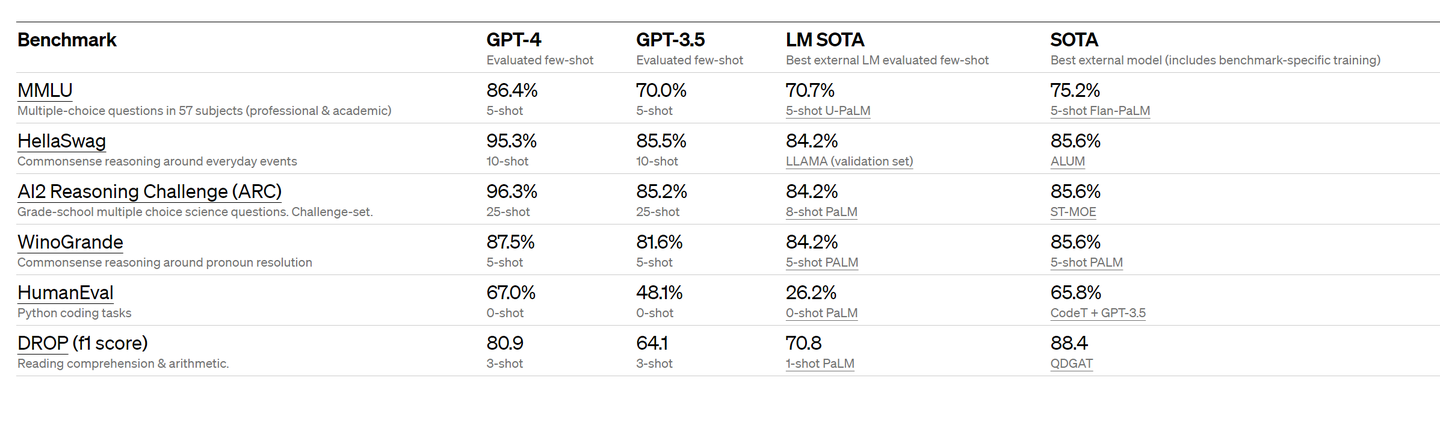
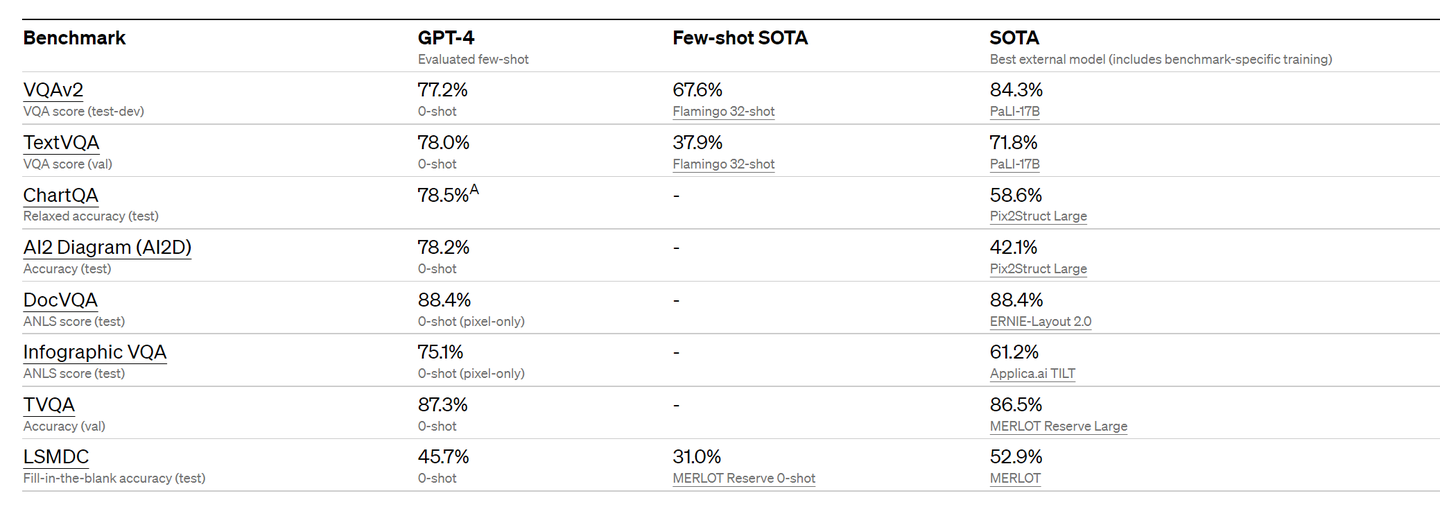
OpenAI はまた、機械学習モデル用に設計された従来のベンチマークで GPT-4 を評価しました。GPT-4 は、既存の大規模な言語モデルや、ベンチマーク固有の手作りや追加のトレーニング プロトコルを含む可能性のある最先端 (SOTA) モデルよりも大幅に優れています。
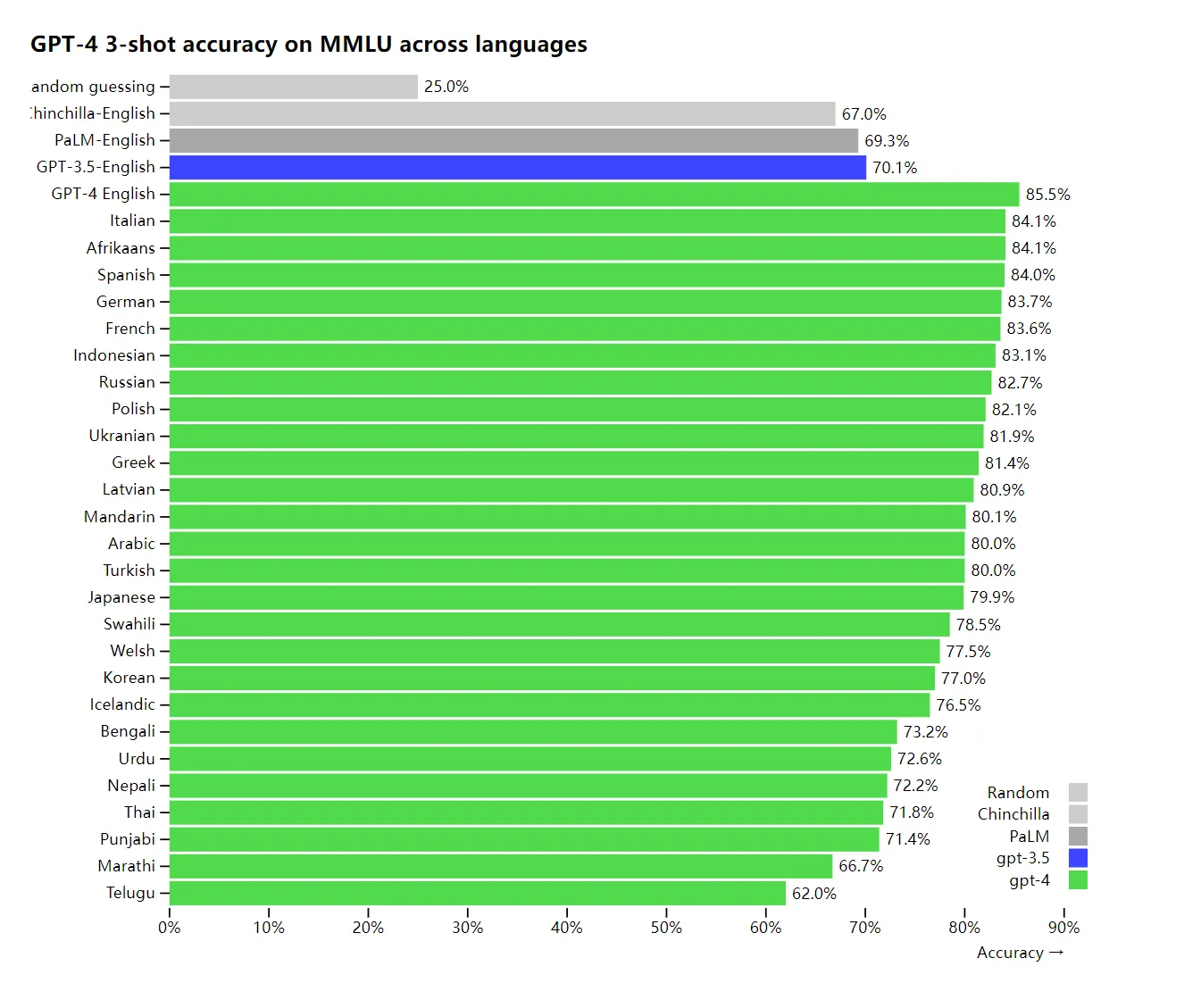
既存の ML ベンチマークの多くは英語で記述されています。他の言語の機能を最初に確認するために、OpenAI は Azure Translate を使用して MMLU ベンチマーク (57 の科目をカバーする 14,000 の多肢選択問題のセット) をさまざまな言語に翻訳しました (付録を参照)。GPT-4 は、ラトビア語、ウェールズ語、スワヒリ語などのリソースの少ない言語を含む、テストされた 26 の言語のうち 24 の英語で、GPT-3.5 および他の LLM (チンチラ、PaLM) よりも優れています。
OpenAI は内部でも GPT-4 を使用しており、サポート、販売、コンテンツ モデレート、プログラミングなどの機能に大きな影響を与えています。また、人間が人工知能の出力を評価するのを支援するためにも使用しており、調整戦略の第 2 段階を開始しています。
視覚入力
GPT-4 は、テキストのみのセットアップと同様に、テキストと画像の両方の手がかりを受け入れることができるため、ユーザーは視覚的または言語的なタスクを指定できます。具体的には、散在するテキストと画像で構成される特定の入力に対して、テキスト出力 (自然言語、コードなど) を生成します。テキストと写真、図またはスクリーンショットを含むドキュメントを含むさまざまなドメインで、GPT-4 はプレーンテキスト入力と同様の機能を示しました。さらに、プレーンテキスト言語モデル用に開発されたテスト時の手法によって拡張できます。これには、少数ショットや思考連鎖のヒントが含まれます。画像入力はまだ研究プレビューであり、公開されていません。
ビジュアル入力: VGA 充電器

OpenAI は、標準的なアカデミック ビジョン ベンチマークの狭いセットで GPT-4 を評価することにより、GPT-4 のパフォーマンスをプレビューします。ただし、OpenAI はモデルが処理できる新しいエキサイティングなタスクを常に発見しているため、これらの数値はその機能の範囲を完全には表していません。OpenAI は、さらなる分析と評価のデータを近日中に公開し、テスト時の手法の影響を徹底的に調査する予定です。
限界
GPT-4 は強力ですが、以前の GPT モデルと同様の制限があります。その上、まだ完全に信頼できるわけではありません (事実を「幻覚」にし、推論エラーを起こします)。言語モデルの出力を使用する場合、特にハイ ステーク コンテキストで、特定のユース ケースのニーズに一致する正確なプロトコルを使用する場合は注意が必要です (たとえば、人間によるレビュー、追加のコンテキストの基礎、またはハイ ステークスの使用を完全に回避するなど)。まだ
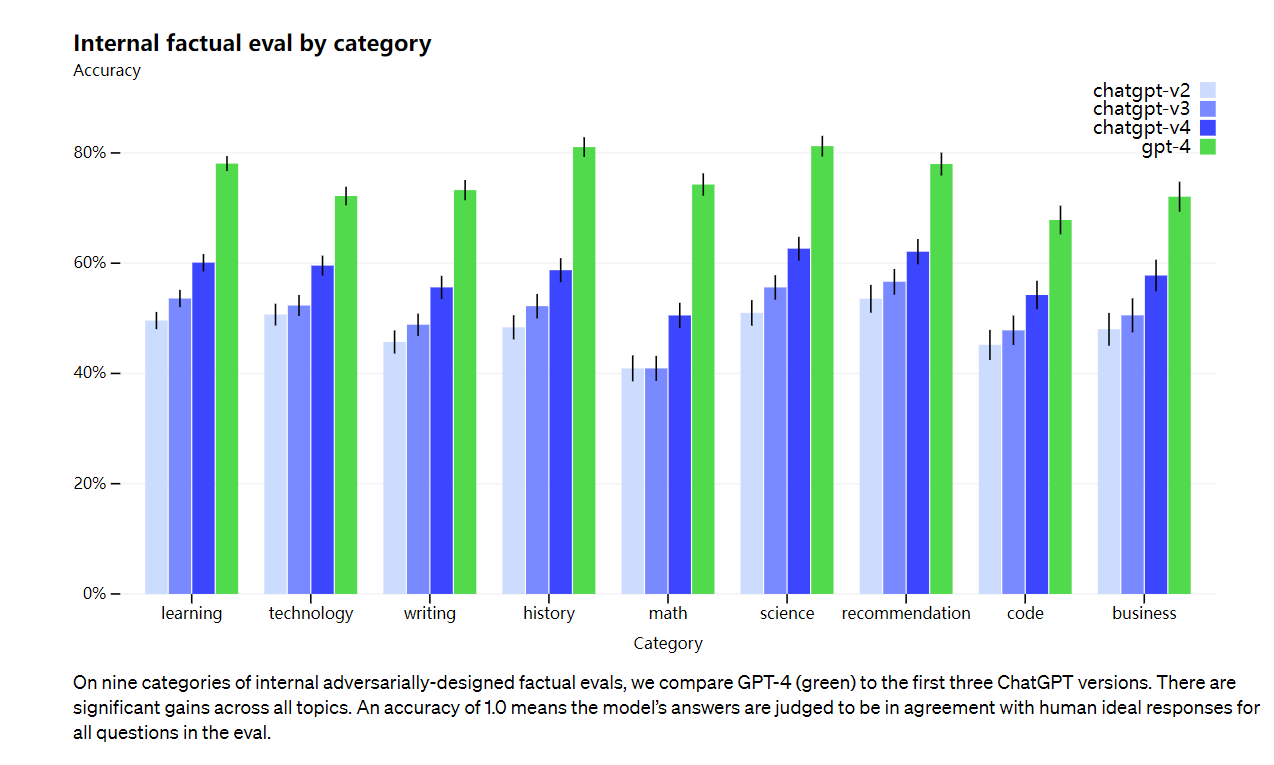
本当の問題ですが、GPT-4は以前のモデルと比較して幻覚を大幅に減らします(それ自体は反復ごとに改善されました). OpenAI の内部敵対的リアリズム評価では、GPT-4 は最新の GPT-3.5 よりも 40% 高いスコアを獲得しています。
OpenAI は、TruthfulQA などの外部ベンチマークで進歩を遂げました。TruthfulQA は、敵対的に選択された一連の虚偽表示から事実を分離するモデルの能力をテストします。これらの質問は、統計的に魅力的な、事実に反する回答と組み合わされていました。
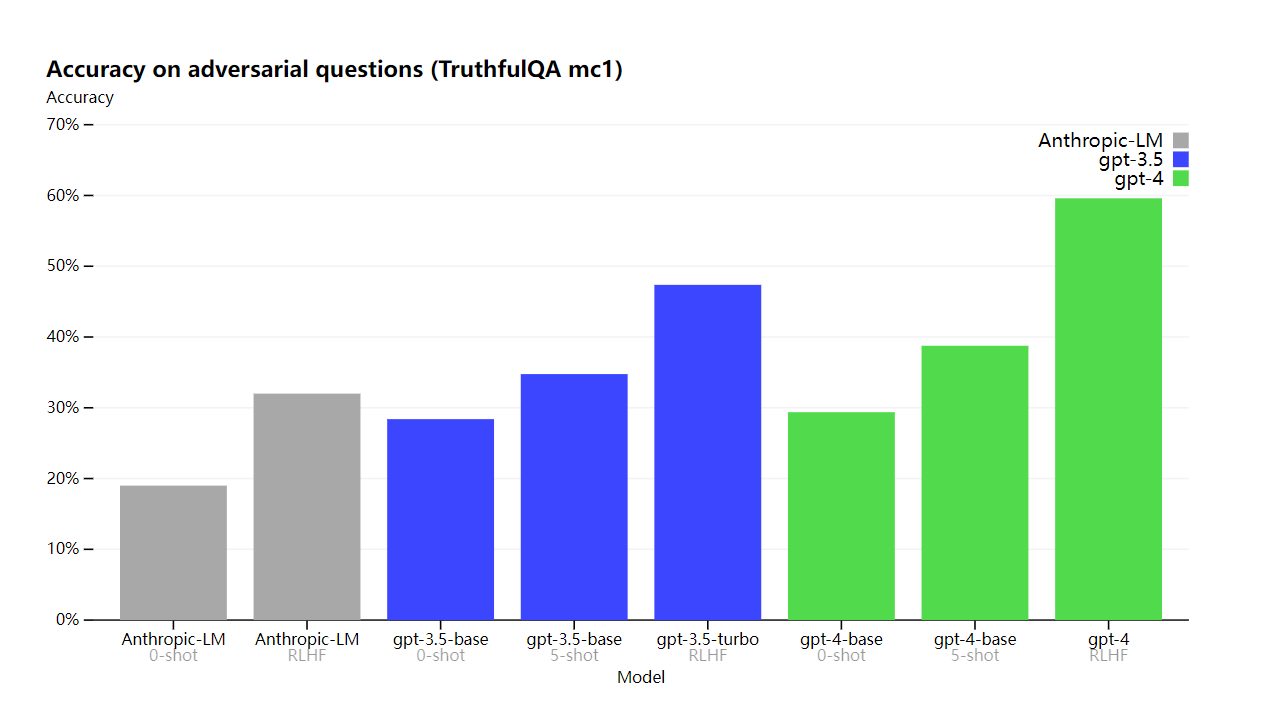
GPT-4 ベース モデルは、このタスクで GPT-3.5 よりわずかに優れているだけですが、RLHF のポスト トレーニング (GPT-3.5 と同じ手順を適用) の後では、大きなギャップがあります。以下のいくつかの例を調べると、GPT-4 は口語表現を拒否します (老犬に新しいトリックを教えることはできません) が、それでも微妙な詳細は見逃しています (エルヴィスは俳優の息子ではありませんでした)。

モデルの出力にはさまざまなバイアスが存在する可能性があります。OpenAI はこれらの分野で進歩を遂げましたが、まだやるべきことが残っています。最近の OpenAI ブログ投稿によると、OpenAI の目標は、私たちが構築する AI システムが、幅広いユーザーの価値観を反映する賢明なデフォルトの動作を持ち、これらのシステムを幅広い範囲でカスタマイズできるようにし、一般に公開することです。それらの範囲がどうあるべきかについての意見。
GPT-4 は一般に、大部分のデータ停止 (2021 年 9 月) の後に何が起こったのかを理解しておらず、その経験から学んでいません。複数のドメインにわたる能力に比例しないように見える単純な推論エラーを作成したり、ユーザーからの明らかな虚偽の説明を受け入れるのにあまりにも信憑性があります. 生成するコードにセキュリティ ホールを導入するなど、人間のような難しい問題で失敗することがあります。
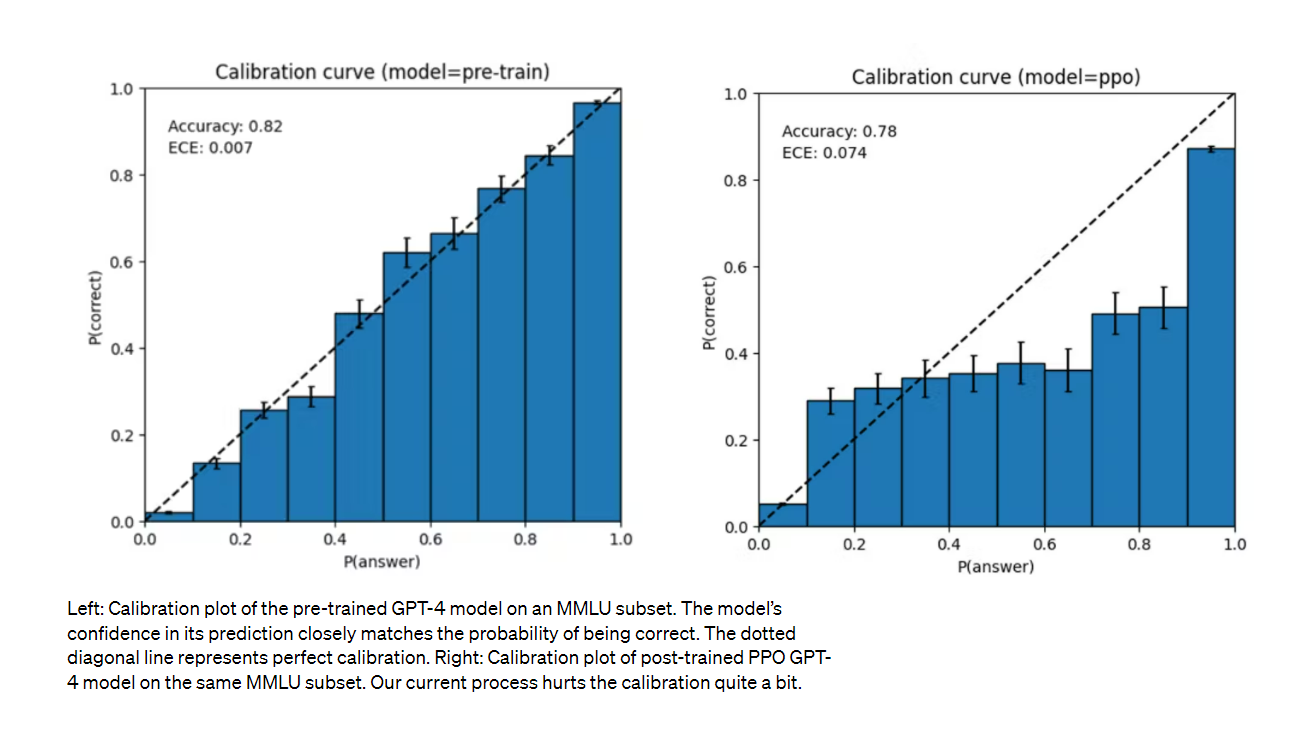
GPT-4 は、間違っている可能性がある場合にその作業を再確認することに注意を払わずに、自信を持って予測を誤ることもあります。興味深いことに、基礎となる事前トレーニング済みモデルは高度に調整されています (通常、回答に対する予測信頼度は正しい確率と一致します)。ただし、現在のトレーニング後のプロセスでは、キャリブレーションが削減されます。
リスクと緩和
OpenAI は、トレーニング前のデータの選択とフィルタリング、評価と専門家の参加、モデルの安全性の改善、監視と実施など、GPT-4 をトレーニングの開始時からより安全で一貫性のあるものにするために反復処理を行ってきました。
GPT-4 は、有害な提案、間違ったコード、または不正確な情報を生成するなど、以前のモデルと同様のリスクをもたらします。ただし、GPT-4 の追加機能により、新しいリスク サーフェスが導入されます。これらのリスクの範囲を理解するために、OpenAI は、AI 整合リスク、サイバーセキュリティ、バイオリスク、信頼と安全、国際セキュリティなどの分野で 50 人以上の専門家を雇って、モデルを敵対的にテストしました。彼らの調査結果により、OpenAI は、評価に専門知識を必要とするリスクの高いドメインでモデルの動作をテストできるようになりました。これらの専門家からのフィードバックとデータは、モデルを軽減および改善するために OpenAI によって使用されます。たとえば、OpenAI は、危険な化学物質の合成方法に関する要求を拒否する GPT-4 の機能を改善するために、追加のデータを収集しました。
GPT-4 は、RLHF トレーニング中に追加の安全報酬信号を組み込んで、そのようなコンテンツのリクエストを拒否するようにモデルをトレーニングすることにより、有害な出力 (OpenAI の使用ガイドラインで定義されている) を減らします。報酬は、GPT-4 ゼロ ショット分類器によって提供されます。GPT-4 ゼロ ショット分類器は、安全な境界を判断し、安全関連の手がかりに基づいて完了する方法を決定します。モデルが有効なリクエストを拒否するのを防ぐために、OpenAI はさまざまなソース (ラベル付けされた生産データ、ヒューマン レッド チーム、モデルによって生成されたヒントなど) から多様なデータセットを収集し、許可されたカテゴリと許可されていないカテゴリに (正または負の値を持つ) 安全報酬シグナルを適用します。
OpenAI の緩和策により、GPT-3.5 と比較して GPT-4 のセキュリティ機能の多くが大幅に改善されます。OpenAI によると、GPT-3.5 と比較して、OpenAI はモデルが許可されていないコンテンツのリクエストに応答する傾向を 82% 減らし、GPT-4 は機密性の高いリクエスト (医療アドバイスや自傷行為など) に応答する頻度が 29% 高くなりました。ポリシー。
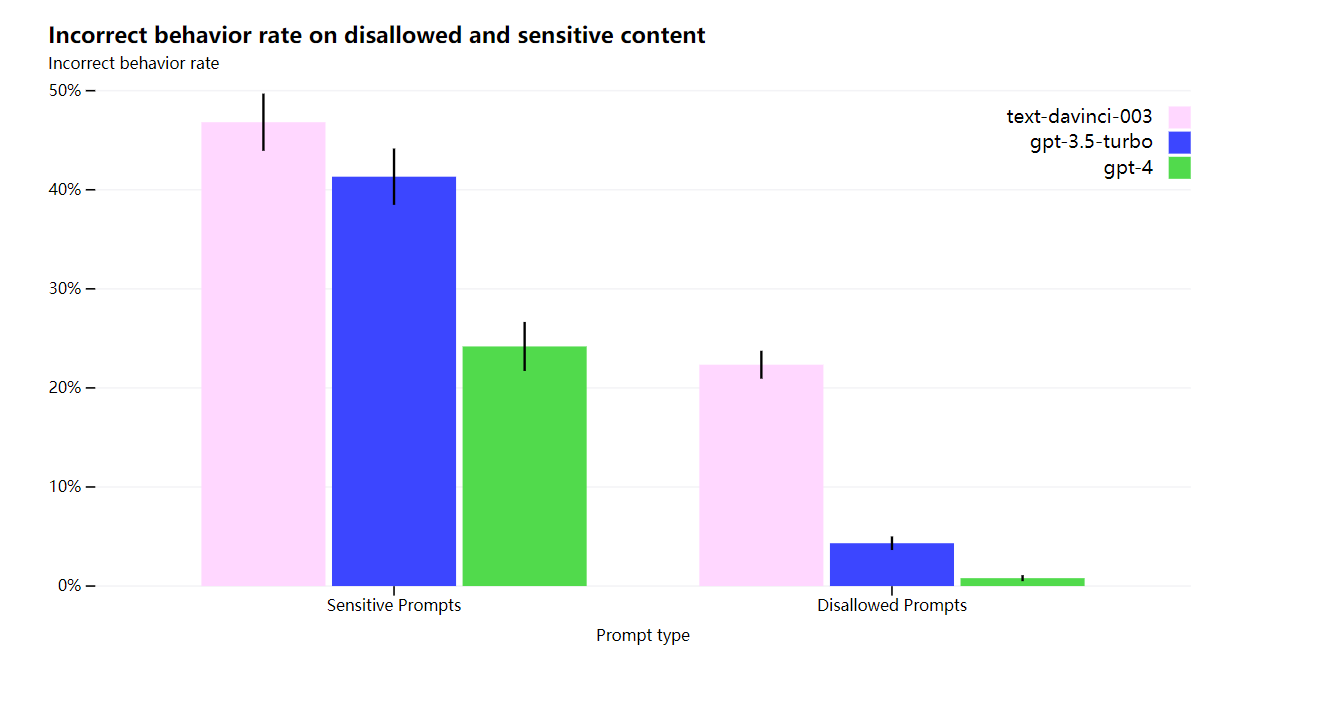

全体として、OpenAI のモデル レベルの介入により、悪い動作を誘発することは難しくなりますが、それでも可能です。さらに、OpenAI の使用ガイドラインに違反するコンテンツを生成する「脱獄」がまだ存在します。AI システムの「トークンごとのリスク」が高まるにつれて、これらの介入で極度の信頼性を実現することが重要になります。現時点では、これらの制限を、悪用の監視などの展開時のセキュリティ技術で補うことが重要です。
GPT-4 以降のモデルは、有益な方法と有害な方法の両方で社会に大きな影響を与える可能性があります。OpenAI は外部の研究者と協力して、OpenAI が潜在的な影響を理解し評価する方法、および将来のシステムで潜在的に危険な機能を評価する方法を改善しています。OpenAI は、GPT-4 およびその他の AI システムの潜在的な社会的および経済的影響について、より多くの考えをすぐに共有します。
トレーニングプロセス
以前の GPT モデルと同様に、GPT-4 基本モデルは、ドキュメント内の次の単語を予測するようにトレーニングされ、インターネット データなどの公開データや OpenAI がライセンスを取得したデータを使用してトレーニングされます。これらのデータは、数学の問題に対する正しい解決策と誤った解決策、弱い推論と強い推論、矛盾した一貫したステートメントを含む Web スケールのデータのコーパスであり、さまざまなイデオロギーとアイデアを表しています。
したがって、質問が表示されると、基になるモデルは、ユーザーの意図とはかけ離れたさまざまな方法で応答する可能性があります。ガードレール内でユーザーの意図に合わせるため、OpenAI は強化学習とヒューマン フィードバック (RLHF) を使用してモデルの動作を微調整します。
モデルの能力は主にトレーニング前のプロセスに由来するように見えることに注意してください - RLHF はテストのスコアを改善しません (積極的に取り組まなければ、実際にはテストのスコアを減らします)。しかし、モデルのターンはトレーニング後のプロセスから発生します。基礎となるモデルは、質問に答えるはずであることを知るために間に合うように設計する必要があります。
予測可能な拡大
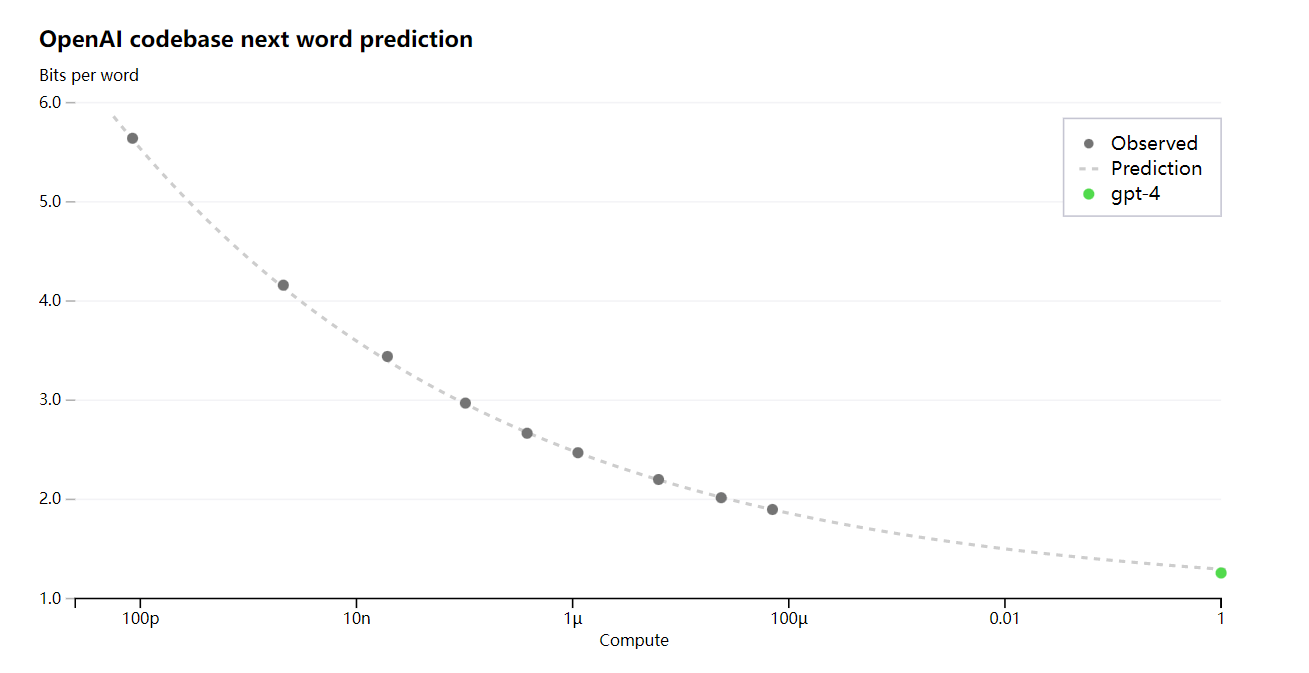
GPT-4 プロジェクトの大きな焦点は、予測どおりにスケーリングするディープ ラーニング スタックを構築することです。主な理由は、GPT-4 のような非常に大規模なトレーニングの実行では、広範なモデル固有の調整が実行できないためです。OpenAI によって開発されたインフラストラクチャと最適化は、複数のスケールにわたって非常に予測可能な動作をします。このスケーラビリティを検証するために、OpenAI は OpenAI の内部コードベース (トレーニング セットの一部ではない) での GPT-4 の最終的な損失を、同じ方法でトレーニングされたモデルから推測することで正確に予測しましたが、使用する計算は 10,000 分の 1 でした。
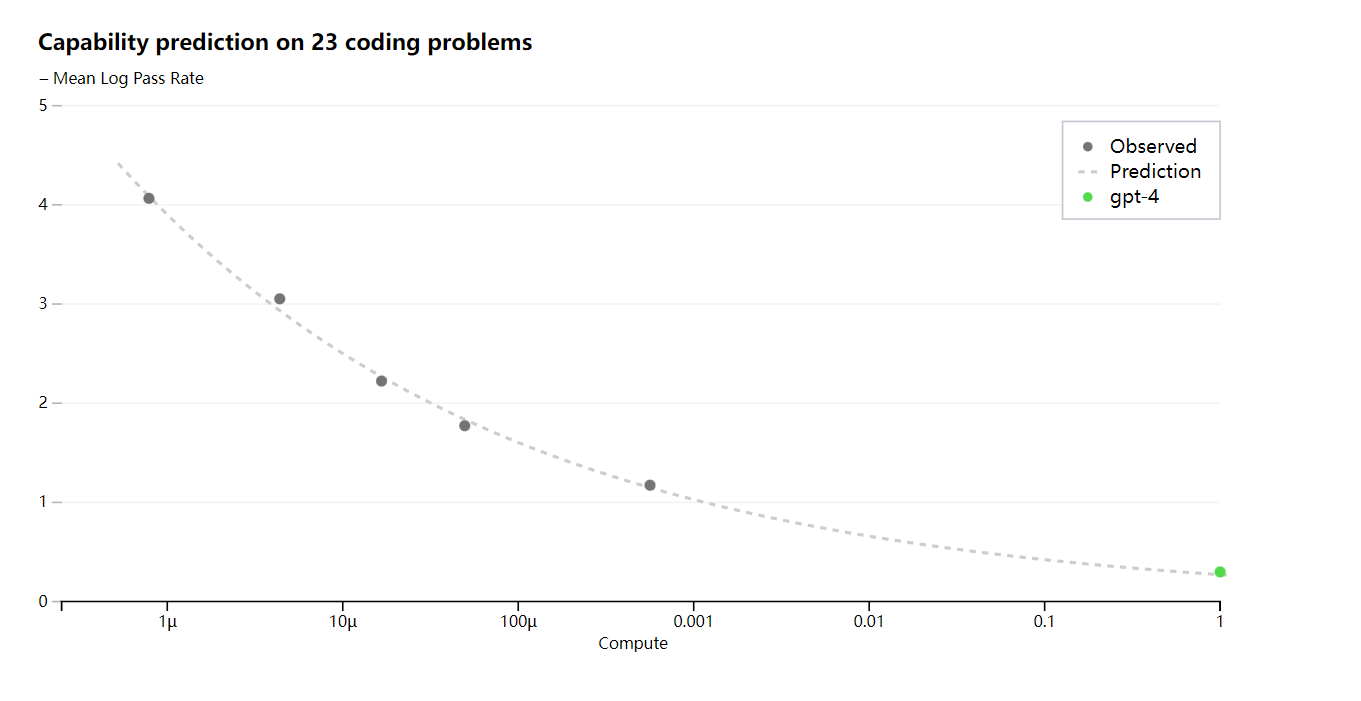
OpenAI がトレーニング中に最適化したメトリック (損失) を正確に予測できるようになったので、OpenAI はより解釈可能なメトリックを予測する方法の開発を開始しました。たとえば、OpenAI は HumanEval データセットのサブセットの合格率を正常に予測し、計算負荷が 1,000 分の 1 のモデルから外挿します。
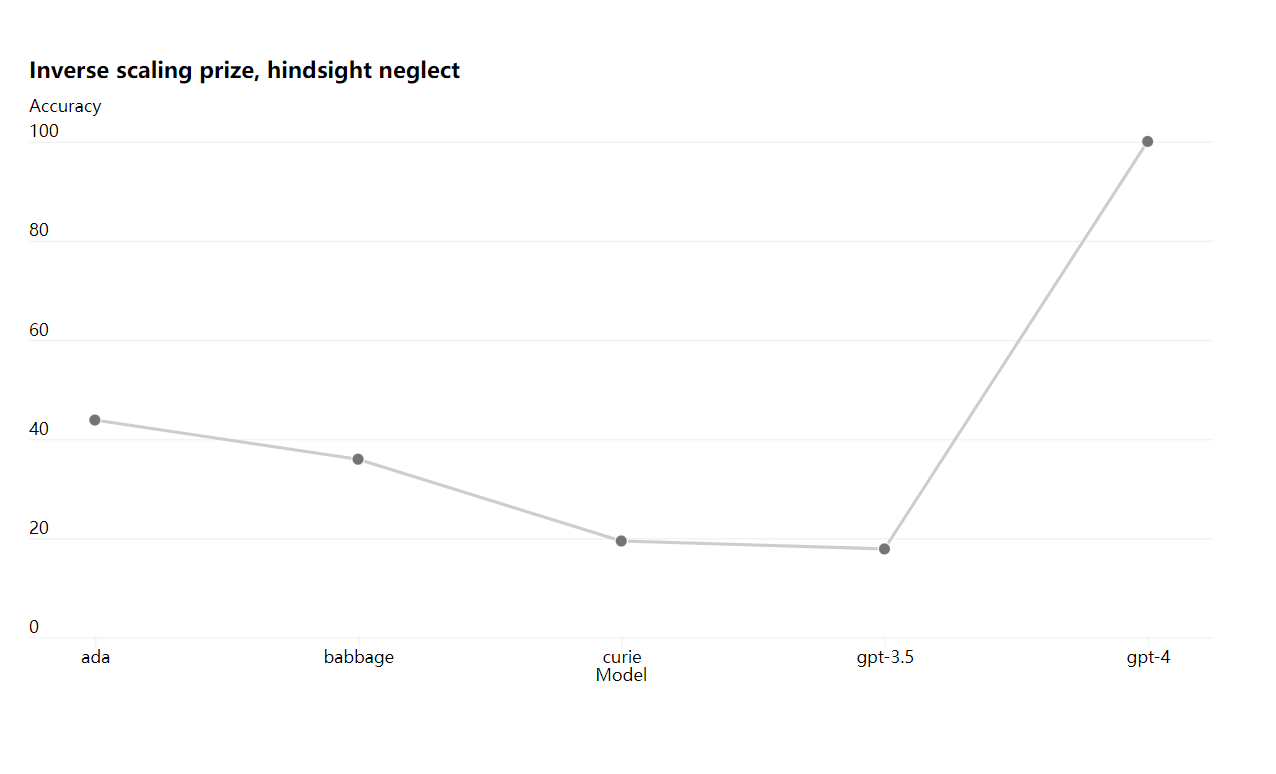
一部の能力はまだ予測できません。たとえば、Inverse Scaling Prize は、モデルの計算負荷が高くなるにつれて悪化するメトリクスを見つけるコンテストであり、Hindsight Neglect は受賞者の 1 人でした。別の最近の結果と同様に、GPT-4 は傾向を逆転させました。
OpenAI は、未来を正確に予測する機械学習の能力はセキュリティの重要な部分であると考えていますが、その潜在的な影響に比べて十分な注目を集めていません。OpenAI は、将来のシステムに何を期待するかについて、より良いガイダンスを社会に提供するための方法を開発するための取り組みを強化しています。OpenAI は、この分野における共通の目標になることを望んでいます。