記事ディレクトリ
1.文法形式を提出する

- Spark は、作成された Spark アプリケーションを Spark クラスターに送信するために使用できるクライアント アプリケーション送信ツール spark-submit を提供します。
- spark-submit の使用形式は次のとおりです。 $ bin/spark-submit [オプション] [アプリ オプション]
- options は、spark-submit に渡される制御パラメーターを表します。
- app jar は、送信されたプログラム JAR パッケージ (または Python スクリプト ファイル) の場所を示します。
- app options は、main() メソッドで渡す必要があるパラメーターなど、jar プログラムが渡す必要があるパラメーターを示します。
2、spark-submit 共通パラメータ
--master パラメーターに加えて、spark-submit は、リソースの使用とランタイム環境を制御するためのいくつかのパラメーターも提供します。
| パラメータ | 説明 |
|---|---|
| -マスター | マスター ノードの接続アドレス。値は spark://host:port、mesos://host:port、yarn、k8s://https://host:port または local (デフォルトは local[*]) です。 |
| –展開モード | 送信方法。値はクライアントまたはクラスターです。client はローカル クライアントで Driver プログラムを開始することを意味し、cluster はクラスター内の作業ノードで Driver プログラムを開始することを意味します。デフォルトは client です。 |
| -クラス | アプリケーションのメイン クラス (Java または Scala プログラム) |
| -名前 | Spark Web UI に表示されるアプリケーション名 |
| –瓶 | アプリケーションが依存するサードパーティ JAR パッケージのカンマ区切りのリスト |
| –ファイル | アプリケーションの作業ディレクトリに配置するファイルのカンマ区切りリスト。このパラメーターは通常、各ノードに配布する必要があるデータ ファイルを格納するために使用されます。 |
| –conf | 「プロパティ名=プロパティ値」の形式でSparkConf構成プロパティを設定します |
| –プロパティファイル | キーと値のペアを含む外部プロパティ ファイルを読み込みます。指定しない場合、Spark インストール ディレクトリの conf/spark-defaults.conf ファイルの構成がデフォルトで読み取られます。 |
| –ドライバーメモリー | ドライバ プロセスが使用するメモリの量 (512MB または 1GB など)。単位は大文字と小文字を区別しません。デフォルトは 1GB です。 |
| –executor-memory | 各 Executor プロセスが使用するメモリの量。たとえば、512MB または 1GB の場合、単位は大文字と小文字が区別されず、デフォルトは 1GB です。 |
| –ドライバーコア | ドライバ プロセスが使用する CPU コアの数。クラスタ モードでのみ使用されます。デフォルトは 1 です。 |
| -executor-cores | 各 Executor プロセスで使用される CPU コアの数。デフォルトは 1 です |
| num-executor | Executor プロセスの数。デフォルトは 2 です。動的割り当てが有効になっている場合、初期 Executor の数は、少なくともこのパラメーターで構成された数になります。このパラメーターは、Spark On YARN モードでのみ使用されることに注意してください。 |
3.ケースデモンストレーション - Sparkに付属の円周率計算プログラムを提出
Sparkのインストールディレクトリを入力してください
(1) スタンドアローンモード、クライアント提出方式を使用
次のコマンドを実行して、Spark に付属する pi プログラムをクラスターに送信します。
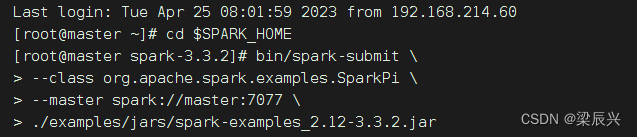
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077 \
./examples/jars/spark-examples_2.12-3.3.2.jar
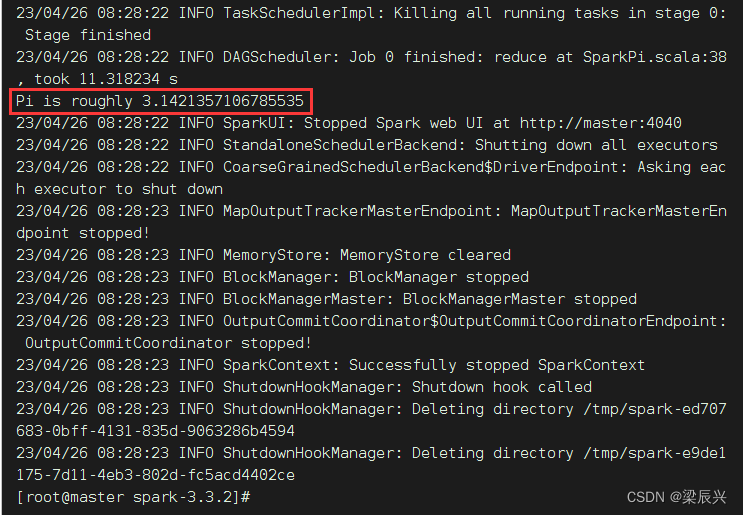
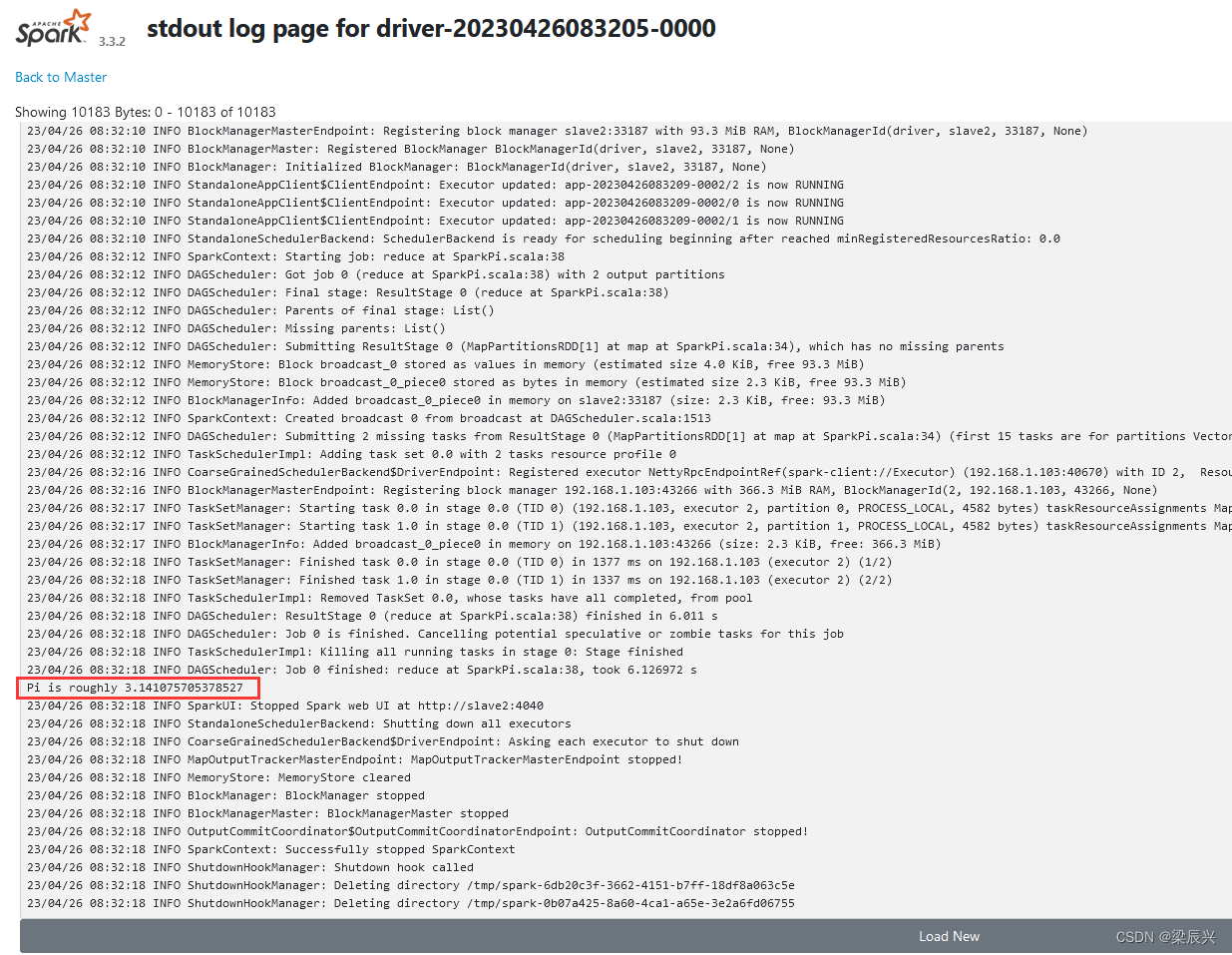
Spark ジョブを送信した後、Spark クラスター管理インターフェイスを観察します。ここで、「実行中のアプリケーション」リストは、現在の Spark クラスターがジョブを計算していることを示しています。実行の数秒後、インターフェイスを更新します。完了したアプリケーション フォームの下に表示されます。現在のアプリケーションが実行されることを確認し、制御に戻ります。ステーションの出力情報を確認すると、「Pi はおよそ 3.1424157120785603」と表示され、Pi 値が計算されたことを示します。
上記のコマンドの –master パラメーターは、マスター ノードの接続アドレスを指定します。このパラメーターの値は、Spark クラスターのモードによって異なります. 一般的な値を次の表に示します.
| 価値 | 説明 |
|---|---|
| spark://ホスト:ポート | スタンドアロン モードでのマスター ノードの接続アドレス。デフォルト ポートは 7077 です。 |
| 糸 | YARN クラスターに接続します。ResourceManager の開始アドレスが YARN で指定されていない場合、ResourceManager が配置されているノードでアプリケーションを送信する必要があります。そうしないと、ResourceManager が見つからないため、送信が失敗します。 |
| 地元 | 1 つの CPU コアを使用して、ローカル モードを実行します。 |
| ローカル [N] | N 個の CPU コアを使用して、ローカル モードを実行します。たとえば、local[2] は、2 つの CPU コアを使用してプログラムを実行することを意味します。 |
| 地元[*] | できるだけ多くの CPU コアを使用して、ローカル モードを実行します。 |
--master パラメーターが追加されていない場合、デフォルトでローカル モード local[*] で実行されます。
(2) スタンドアロンモード、クラスタサブミッション方式を使用
Standalone モードでは、Spark に付属の pi 計算プログラムをクラスターに投入し、Driver プロセスが使用するメモリを 512MB、各 Executor プロセスが使用するメモリを 1GB、各 Executor プロセスが使用する CPU コアの数を設定します。 2 への送信方法 クラスターの場合 (Driver プロセスはクラスターの作業ノードで実行されます)、次のようにコマンドを実行します。

bin/spark-submit \
--master spark://master:7077 \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
--driver-memory 512m \
--executor-memory 1g \
--executor-cores 2 \
./examples/jars/spark-examples_2.12-3.3.2.jar
一行で書ける
bin/spark-submit --master spark://master:7077 --deploy-mode cluster --class org.apache.spark.SparkPi --driver-memory 512m --executor-memory 1g --executor-cores 2 ./examples/jars/spark-examples_2.12-3.3.2.jar
コマンドの実行後、State of driver-20230406114733-0000 が RUNNING であることが表示された場合は、操作が成功したことを意味します。それ以外の場合は、State of driver-20230406114733-0000 が FAILED と表示されます Spark WebUI インターフェイスで実行結果を表示するに

は、http://master: 8080 にアクセスします。
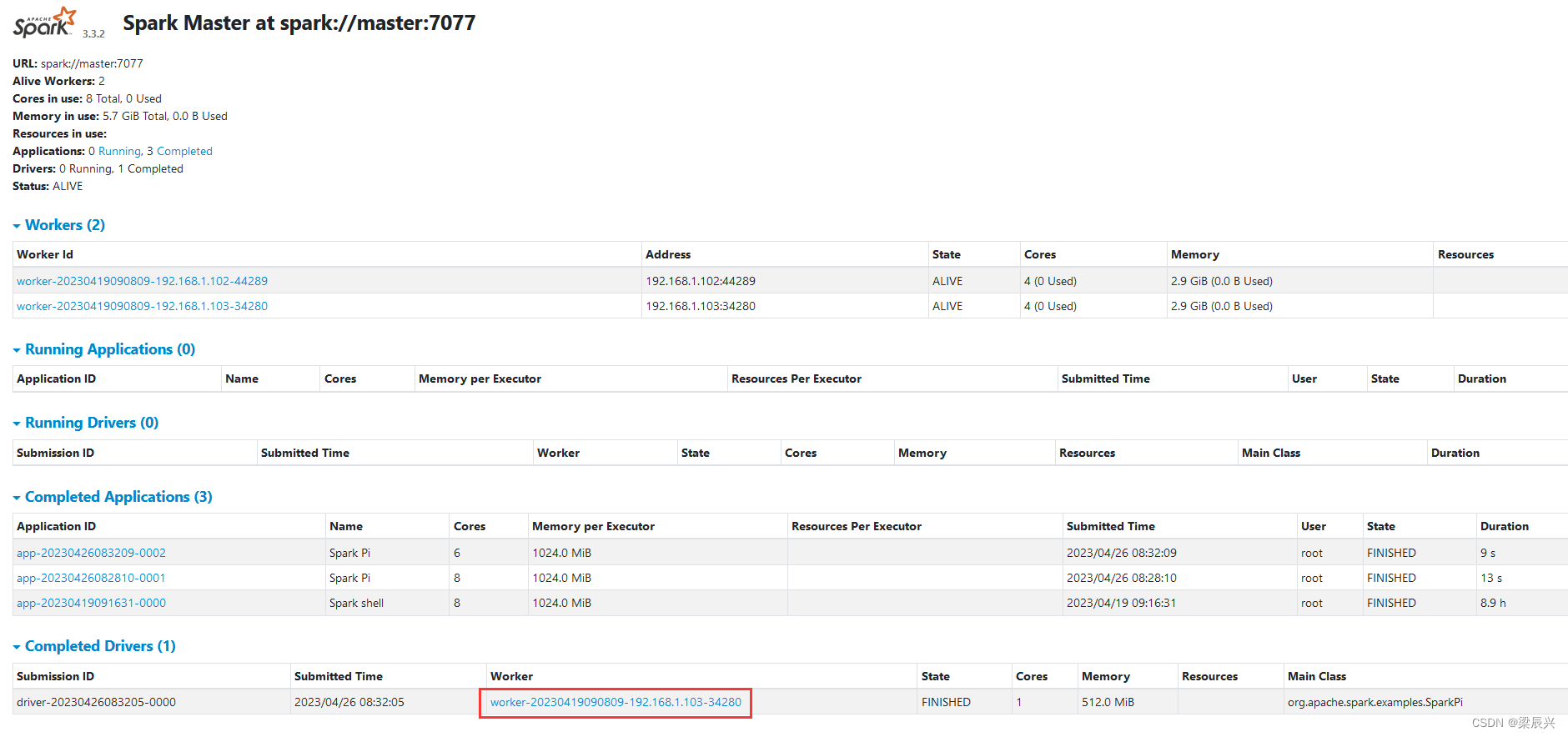
赤い丸で囲まれた Worker ハイパーリンクをクリックします - worker-20230406114652-192.168.1.103-34280
注: プライベート IP アドレスは、ホスト名 slave1 または対応するフローティング IP アドレスに変更する必要があります。
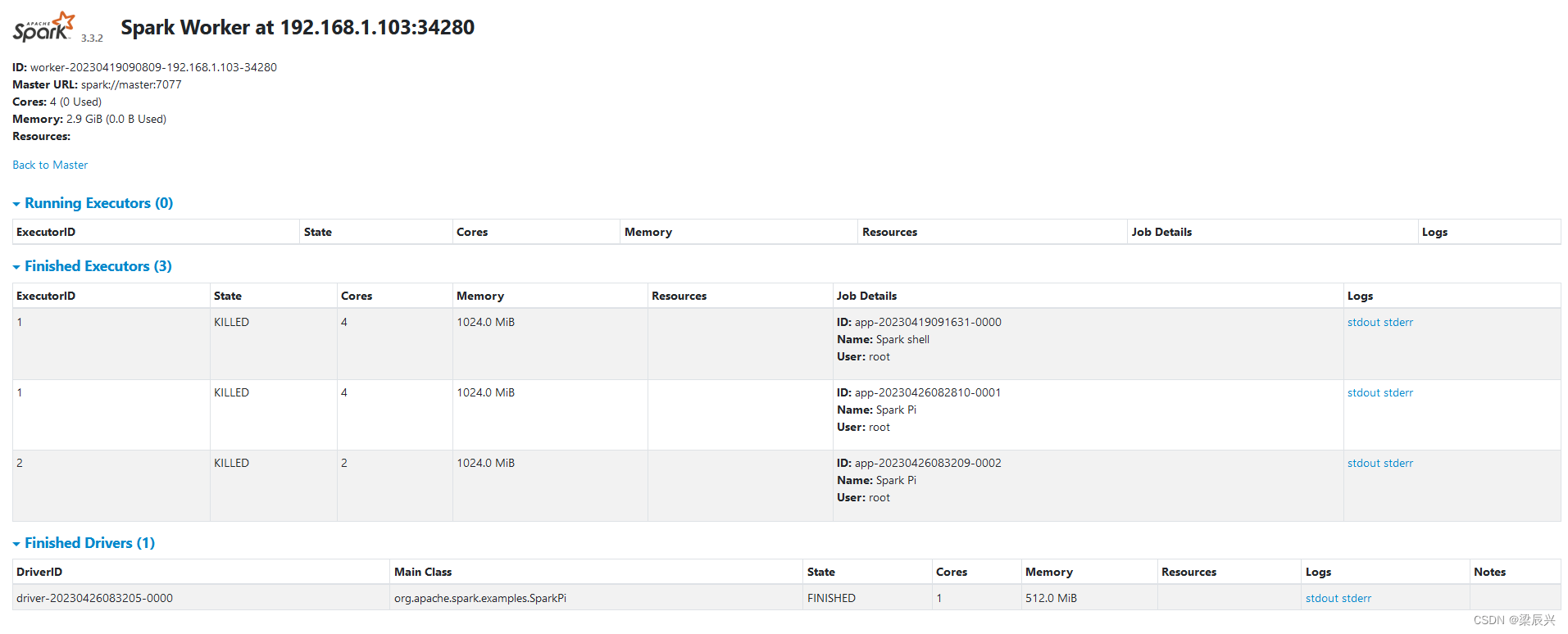
Pi の計算結果を表示するには、stdout ハイパーリンクをクリックします。
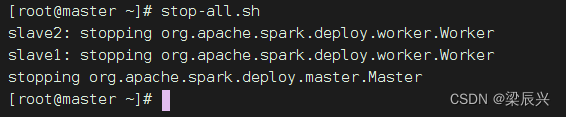
(3) Sparkクラスターサービスを停止する
マスター ノードで次のコマンドを実行します: stop-all.sh