下のカードをクリックして、「CVer」公式アカウントをフォローしてください
AI/CV 重乾物、初回配送
クリックして入力 —>【Computer Vision】WeChat Technology Exchange Group
転載元:CSIG文書画像解析・認識専門委員会

この記事では、ICLR 2023 に採択された論文「StrucTexTv2: Masked Visual-Textual Prediction for Document Image Pre-training」の主な作業を簡単に紹介します。ドキュメント画像とOCR結果を同時に入力する必要がある現在の主流のマルチモーダルドキュメント理解事前トレーニングモデルを考慮して、エンドツーエンドの表現能力の欠如と低い推論効率をもたらし、この論文は新しい目的を提案します。 -to-end ドキュメント イメージ マルチモーダル表現学習事前トレーニング フレームワーク StrucTexTv2。フレームワークは、単語粒度の画像領域マスクに基づいてマルチモーダル自己教師付き事前トレーニング タスク (MIM+MLM) を設計します。これは、画像の単一モーダル入力のみを必要とするため、エンコーダー ネットワークは大規模なラベルなしで完全に実行できます。ドキュメント画像. 視覚的および言語的特徴表現を組み合わせて学習し、複数のダウンストリーム タスクの公開ベンチマークで SOTA パフォーマンスを達成します。
1. 研究の背景
ドキュメント分類、フォーマット分析、フォーム理解、OCR、および情報抽出などのビジュアル リッチ ドキュメント理解テクノロジは、ドキュメント インテリジェンスの分野で徐々にホットな研究トピックになっています。これらのタスクを効果的に処理するために、ほとんどの最先端の方法では、視覚的およびテキストの手がかりを使用して、画像、テキスト、レイアウトなどの情報をパラメーター ネットワークに入力し、大規模な事前トレーニングに基づいてドキュメントのマルチモーダル機能をマイニングします。スケールデータ。図 1 に示すように、視覚と言語には大きなモーダルの違いがあるため、事前トレーニング方法を理解する主流のドキュメントは、大まかに 2 つのカテゴリに分けることができます。 a) マスク言語モデリング (マスク言語モデリング) [9]、入力マスクされたテキスト トークンは言語モデリングに使用され、ランタイム テキストの取得は OCR エンジンに依存します.システム全体のパフォーマンスの向上には、OCR エンジンとドキュメント理解モデルの 2 つのコンポーネントの同時最適化が必要です; b) マスクされた画像モデリング(Masked Image Modeling) [10], 入力マスク画像ブロック領域でピクセル再構成を実行する. このタイプの方法は、画像分類やレイアウト分析などのタスクに適用される傾向があり、ドキュメントの強力なセマンティクスを理解する能力は高くありません.良い。上記の 2 つの事前トレーニング スキームによって提示されるボトルネックを目指して、このホワイト ペーパーでは StrucTexTv2 を提案します。
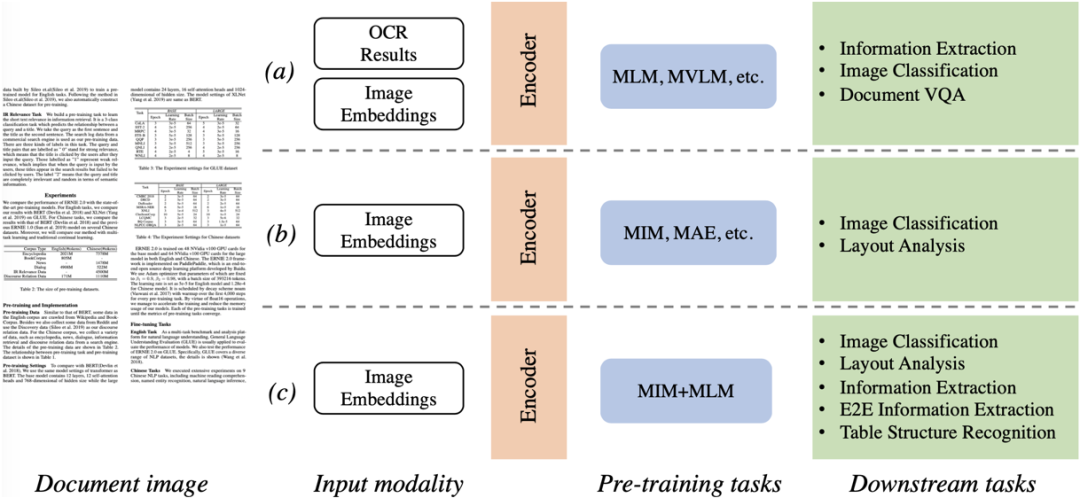
図 1 主流のドキュメント画像理解事前トレーニング フレームワークの比較
2. 方法の原理の簡単な説明
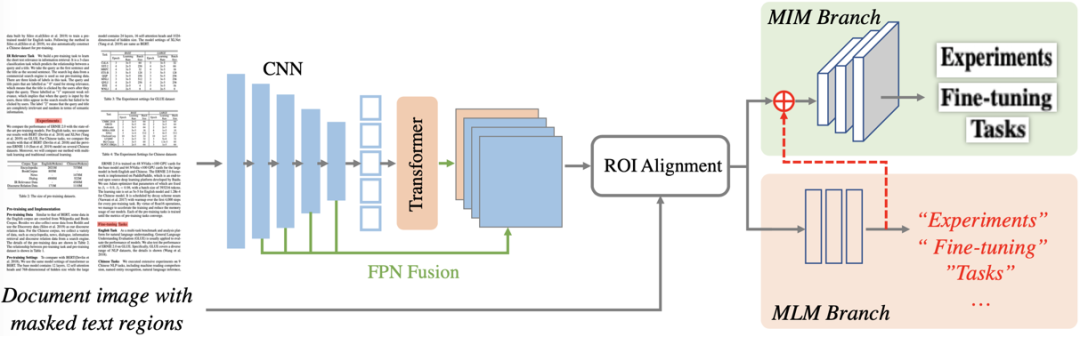
図2 全体フレーム図
図 2 は、StrucTexTv2 の全体的なフレームワークを示しています。これには主に、エンコーダー ネットワークと事前トレーニング タスク ブランチの 2 つの部分が含まれます。エンコーダー ネットワークは、主に CNN コンポーネントおよび Transformer コンポーネントと直列の FPN 構造で構成され、事前トレーニング ブランチには、マスク言語モデリング (MLM) およびマスク画像モデリング (MIM) のデュアル事前トレーニング タスク ヘッドが含まれます。
2.1 エンコーダネットワーク
StrucTexTv2 は、CNN と Transformer の連結エンコーダーを使用して、ドキュメント画像の視覚的および意味的特徴を抽出します。ドキュメント画像は最初に ResNet ネットワークを通過し、1/4 から 1/32 までの 4 つの異なる縮尺の特徴マップを取得します。次に、標準の Transformer ネットワークを使用して最小スケールの特徴マップを受け取り、1D 位置エンコード ベクトルを追加して、グローバル コンテキストを含む意味特徴を抽出します。特徴が 2D 形式に再変換された後、FPN [6] を介して CNN の残りの 3 つのスケール特徴マップと融合され、4 回ダウンサンプリングされた特徴マップが形成されます。これは、画像全体のマルチモーダル特徴表現として使用されます。 .
2.2 事前トレーニング戦略
MLM と MIM をモデル化する 2 つのモーダル事前トレーニング方法を統合するために、この論文では、視覚的および言語の共同特徴表現を学習するための単語粒度画像領域マスク予測方法を提案します。最初に、単語粒度 OCR 予測結果の 30% をランダムに選別し (トレーニング前の段階でのみ使用)、OCR 位置情報に従って元の画像の対応する位置ピクセルに対してマスキング操作を直接実行します (0 値を埋めるなど)。 )。次に、マスクされたドキュメント画像がエンコーダネットワークに直接送信され、画像全体のマルチモーダル特徴表現が取得されます。最後に、再び選択された OCR 位置情報に従って、ROIAlign [11] 操作を使用して、各マスク領域のマルチモーダル ROI 特徴を取得します。
マスクされた言語モデリング: BERT[9] によって構築されたマスクされた言語モデルのアイデアに基づいて、言語モデリング ブランチは 2 層 MLP を使用して、クロス エントロピー損失監視を使用して、単語領域の ROI 特徴を定義済みの語彙カテゴリにマッピングします。同時に、ボキャブラリを使用してテキスト シーケンスをトークン化するときに、単一のフレーズを複数のサブワードに分割することによって引き起こされる 1 対多の一致の問題を回避するために、この論文では、単語の分割後に各単語の最初のサブワードを使用します。分類ラベル。この設計によってもたらされる利点は、StrucTexTv2 の言語モデリングが入力としてテキストを必要としないことです。
マスク画像モデリング: 画像パッチベースのマスク再構成がドキュメントの事前トレーニングである程度の可能性を示していることを考慮すると、パッチ粒状の特徴表現でテキストの詳細を復元することは困難です。したがって、この論文では、単語の粒状性マスクを同時に画像再構成として使用します。つまり、マスクされた領域の元のピクセル値を予測します。単語領域の ROI 特徴は、最初にグローバル プーリング操作によって特徴ベクトルに圧縮されます。第二に、画像再構成の視覚効果を改善するために、この論文は、言語モデリングの後に確率的特徴を接合し、機能をプールして、画像モデリングの「コンテンツ」情報を導入し、画像の事前トレーニングが「スタイル」の復元に集中できるようにします。テキストエリア部分。画像モデリング ブランチは、3 つの完全な畳み込みブロックで構成されています。各ブロックには、Kernel=2×2、Stride=4 のデコンボリューション レイヤー、Kernel=1×1、および 2 つの Kernel=3×1 畳み込みレイヤーが含まれます。最後に、プールされた各単語のベクトルを 64×64×3 のサイズの画像にマッピングし、元の画像領域を使用してピクセルごとに MSE 損失を実行します。
この論文は、Small と Large の 2 つのパラメーター仕様を持つモデルを提供し、Baidu の汎用高精度 OCR テキスト認識結果を使用して、IIT-CDIP データセットでエンコード ネットワークを事前トレーニングします。
3. 実験結果
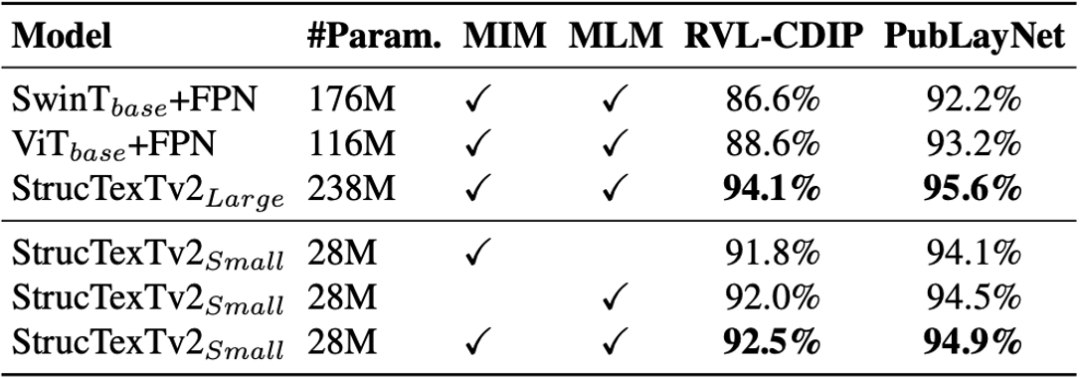
この論文では、モデルがドキュメントを理解する能力を 4 つのベンチマーク データセットでテストし、異なるヘッドを使用して 5 つのダウンストリーム タスクで微調整を実行し、実験的な結論を示しています。表 1 は、RVL-CDIP [13] における文書画像分類に対するモデルの効果を示しています。画像の単峰性入力に基づく方法 DiT[4] と比較して、StrucTexTv2 はより少ないパラメーターでより高い分類精度を達成します。
表 1 RVL-CDIP データセットでの文書画像分類の実験結果
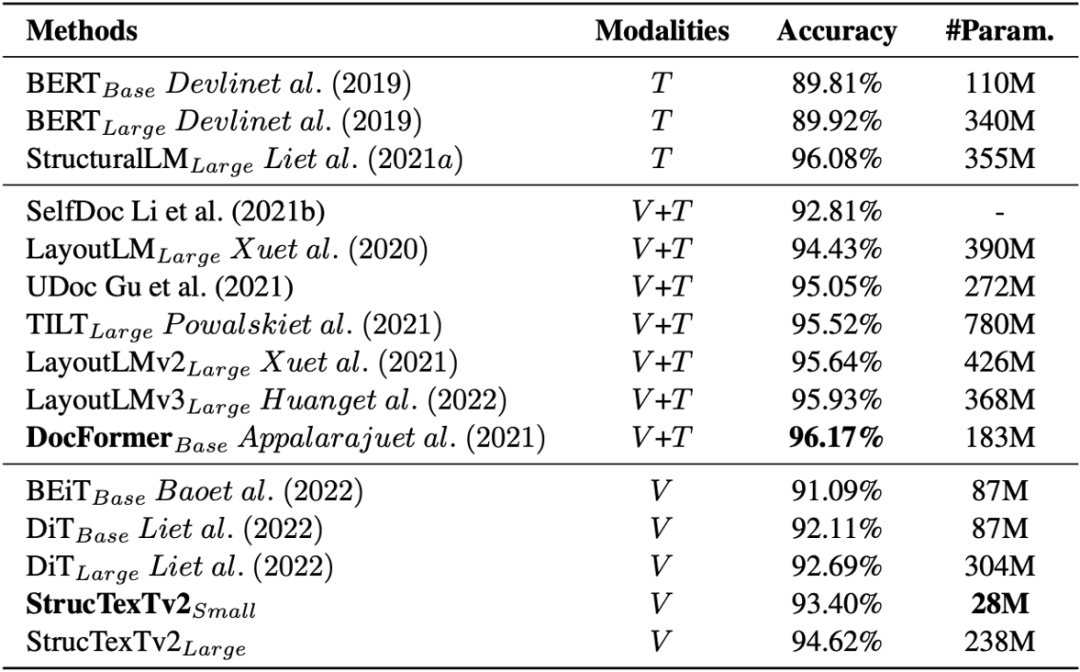
表 2 と表 3 に示すように、論文では事前トレーニング モデルと Cascade R-CNN[1] フレームワークを組み合わせて微調整し、PubLaynet[8] と WWW でドキュメント内のレイアウト要素とテーブル構造を検出します。 [12] データセット 現在の最高のパフォーマンスを達成しました。
表 2 PubLaynet データセットのレイアウト解析の検出結果
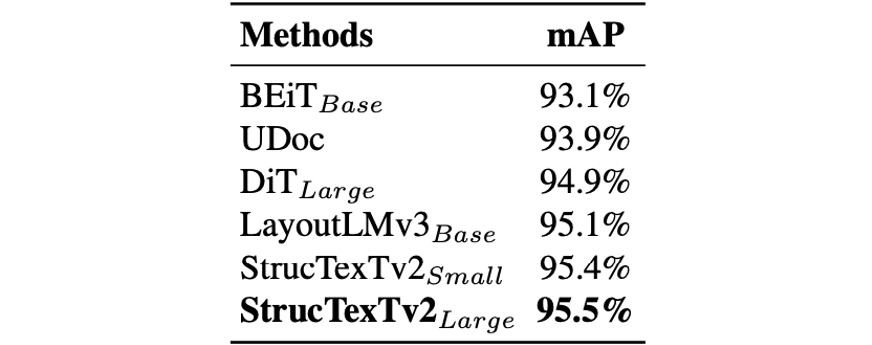
表 3 WWW データセットにおける表構造認識の性能比較

表 4 では、論文は FUNSD [3] データ セットに対してエンド ツー エンドの OCR と情報抽出の 2 つの実験を同時に実行し、ベンチマーク テストで同じ期間に最高の結果を達成しました。StrucTexTv1[5] や LayoutLMv3[2] などの OCR+文書理解の 2 段階の手法について、提案手法の end-to-end 最適化の優位性が証明されています。
表 4 FUNSD データセットに対するエンドツーエンドの OCR および情報抽出実験

次に、SwinTransformer[7]、ViT[10]、StrucTexTv2 のコーディング ネットワークを比較します。表 5 の比較結果から、この論文では、CNN + Transformer のシリアル構造が事前トレーニング タスクをより効果的にサポートできることを提案しています。同時に、この論文は、文書画像分類とレイアウト分析において異なる事前トレーニング構成を持つモデルのパフォーマンスの向上を示し、2 つのモーダル事前トレーニングの有効性を検証します。
表 5 エンコーダ構造の事前トレーニング タスクとアブレーション実験
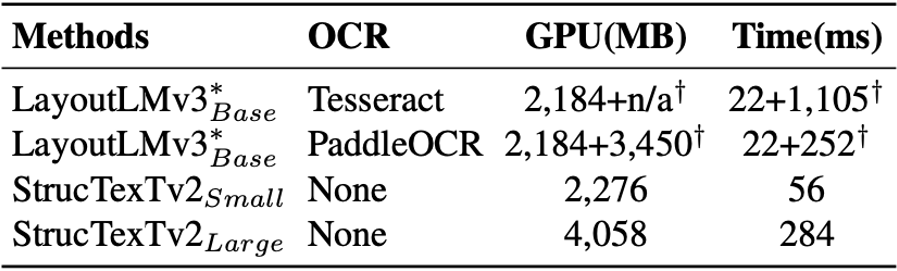
同時に、この論文では、予測中のモデルの時間とメモリのオーバーヘッドを評価しています。表 6 は、2 つの OCR エンジンによってもたらされるオーバーヘッドを示し、現在の最適なマルチモーダル メソッド LayoutLMv3 と比較しています。
表 6 2 段階方式 LayoutLMv3 とのリソース オーバーヘッドの比較
最後に、この論文では、表 7 に示す画像再構成の事前トレーニングでさまざまなマスキング方法を使用した場合のダウンストリーム タスクへの影響を評価しています。RVL-CDIP と PubLaynet の 2 つのデータ セットでは、単語粒度マスクに基づく戦略により、より効果的な視覚的セマンティック機能が得られ、パフォーマンスが向上します。
表 7 エンコーダ構造の事前トレーニング タスクとアブレーション実験

まとめと考察
この論文で提案されている StructTexTv2 モデルは、文書画像の視覚的および言語的特徴表現をエンドツーエンドで学習するために使用され、単一モーダル画像入力の条件下で効率的な文書理解を達成できます。この論文で提案されている事前トレーニング方法は、単語粒度イメージ マスクに基づいており、対応するビジュアル コンテンツとテキスト コンテンツを同時に予測できます.さらに、提案されたエンコーダ ネットワークは、大規模なドキュメント イメージ情報をより効果的にマイニングできます. 実験では、StructTexTv2 が以前の方法と比較してモデル サイズと推論効率を大幅に改善したことが示されています。メソッドの原理の紹介と実験の詳細については、論文の原文を参照してください。
関連リソース
論文アドレス: https://openreview.net/forum?id=HE_75XY5Ljh
コードアドレス: https://github.com/PaddlePaddle/VIMER/tree/main/StrucTexT/v2/
参考文献
[1] Zhaowei Cai と Nuno Vasconcelos。Cascade R-CNN: 高品質のオブジェクト検出を掘り下げます。CVPR、pp. 6154–6162、2018 年。
[2] Yupan Huang、Tengchao Lv、Lei Cui、Yutong Lu、Furu Wei。Layoutlmv3: テキストと画像のマスキングを統合したドキュメント AI の事前トレーニング。ACM マルチメディア、2022 年。
[3] ギヨーム・ジャウメ、ハジム・ケマル・エケネル、ジャン=フィリップ・ティラン。FUNSD: ノイズの多いスキャンされたドキュメントのフォームを理解するためのデータセット。
[4] Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei. Dit: Self-supervised pre-training for document image Transformer. In ACM Multimedia, pp. 3530–3539, 2022.
[5] Yulin Li, Yuxi Qian, Yuechen Yu, Xiameng Qin, Chengquan Zhang, Yan Liu, Kun Yao, Junyu Han, Jingtuo Liu, and Errui Ding. 構造テキスト: マルチモーダル トランスフォーマーによる構造化テキストの理解. In ACM Multimedia, pp . 1912–1920、2021c。
[6] Tsung-Yi Lin、Piotr Dolla ́r、Ross B. Girshick、Kaiming He、Bharath Hariharan、Serge J. Belongie。オブジェクト検出のための機能ピラミッド ネットワーク。CVPR、pp.936–944、2017年。
[7] Ze Liu、Yutong Lin、Yue Cao、Han Hu、Yixuan Wei、Zheng Zhang、Stephen Lin、Baining Guo. Swin Transformer: シフト ウィンドウを使用した階層型ビジョン トランスフォーマー. In ICCV, pp. 9992–10002, 2021.
[8] Xu Zhong、Jianbin Tang、Antonio Jimeno-Yepes。Publinet: ドキュメント レイアウト分析用のこれまでで最大のデータセット。ICDAR、pp. 101-1 Rev. 1015–1022。
[9] ジェイコブ・デブリン、ミンウェイ・チャン、ケントン・リー、クリスティーナ・トゥタノワ。BERT: 言語理解のためのディープ双方向トランスフォーマーの事前トレーニング。NAACL-HLT、pp. 4171–4186、2019 年。
[10] 何開明、チェン・シンレイ、シエ・サイニン、ヤンハオ・リー、ピオトル・ダラー、ロス・B・ガーシック。マスクされたオートエンコーダーは、スケーラブルな視覚学習器です。CVPR、pp. 15979–15988、2022 年。
[11] Kaiming He、Georgia Gkioxari、Piotr Dolla ́r、Ross B. Girshick。R-CNN をマスクします。ICCV, pp. 2980–2988, 2017.
[12] Rujiao Long, Wen Wang, Nan Xue, Feiyu Gao, Zhibo Yang, Yongpan Wang, and Gui-Song Xia. Parsing table structure in the wild. In ICCV, pp. 924–932, 2021.
[13] Adam W. Harley、Alex Ufkes、および Konstantinos G. Derpanis。ドキュメント画像の分類と検索のための深い畳み込みネットの評価。ICDAR、pp. 991–995、2015年。
原作者: Yu Yuechen, Yulin Li, Chengquan Zhang, Xiaoqiang Zhang, Zengyuan Guo, Xiamen Qin, Kun Yao, Junyu Han, Errui Ding, Jingdong Wang
著者: Yu Yuechen, Yulin Li, Chengquan Zhang, Xiaoqiang Zhang, Zengyuan Guo, Xiameng Qin, Kun Yao, Junyu Han, Errui Ding, Jingdong Wang
作詞:李玉林 編曲:ガオ・シュエ
レビュアー: 陰飛 出版社: ジン リアンウェン
クリックして入力 —>【Computer Vision】WeChat Technology Exchange Group
最新の CVPP 2023 論文とコードのダウンロード
背景の返信: CVPR2023。CVPR 2023 の論文とコード オープン ソースの論文のコレクションをダウンロードできます。
バックグラウンドでの返信: Transformer レビュー、最新の 3 つの Transformer レビュー PDF をダウンロードできます
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看