このシステムは、協調フィルタリング アルゴリズムに基づく Django ムービー レコメンデーション システムです。クリックすると、次の詳細にジャンプします。
技術紹介
- フロントエンド: bootstrap3 + jquery.js
- バックエンド: django 2.2.1 + djangorestframework (API 部分を担当)
- データベース: mysql5.7 / sqlite3
- アルゴリズム: ユーザーベースの協調フィルタリング/アイテムベースの協調フィルタリング
データセットの紹介
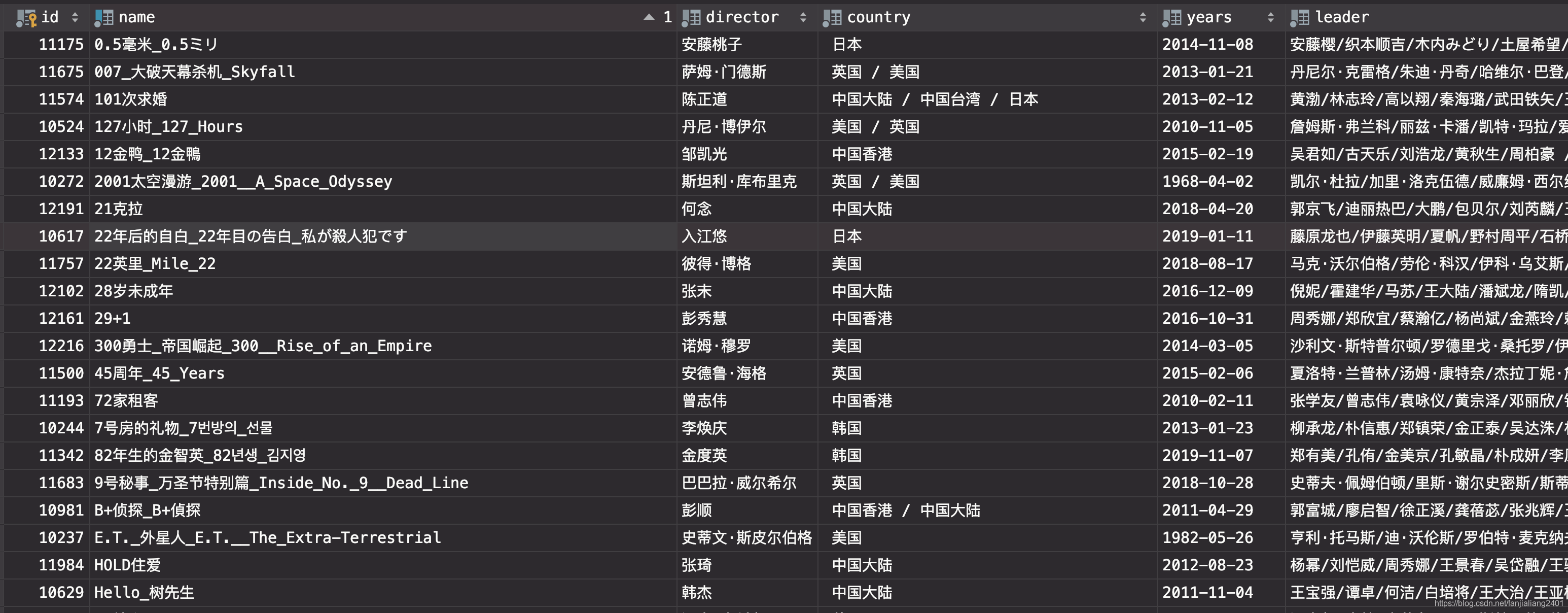
豆板データセット
総計2250本の動画情報を含む豆板動画の動画情報を取得するリクエストに基づくpythonクローラー。
データ属性:
id、title、image_link、country、years、director_description、leader、star、description、all_tags、imdb、language、time_length
スコアリング: ランダムにデータを生成するスクリプトにより、指定された数のユーザーとユーザー評価をランダムに生成できます
ムービーレンズ データセット
movielens 100k データセット + 写真
データの次元: movieId、タイトル、ジャンル、画像
映画の数: 37544
評価の数: 93202 +
movielens データセット + 写真 + ユーザー データと評価データ + csv ストレージ
特徴
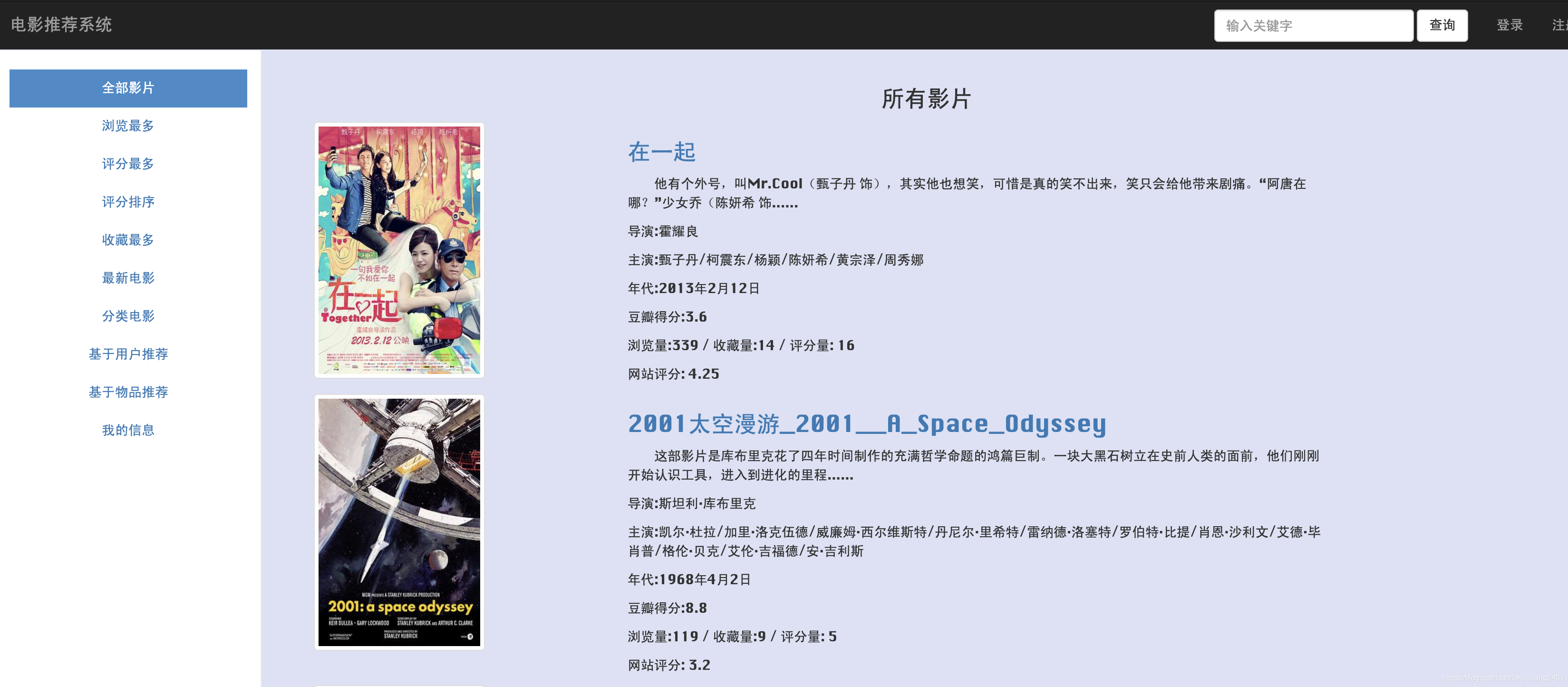
動画表示、動画検索、タグ分類
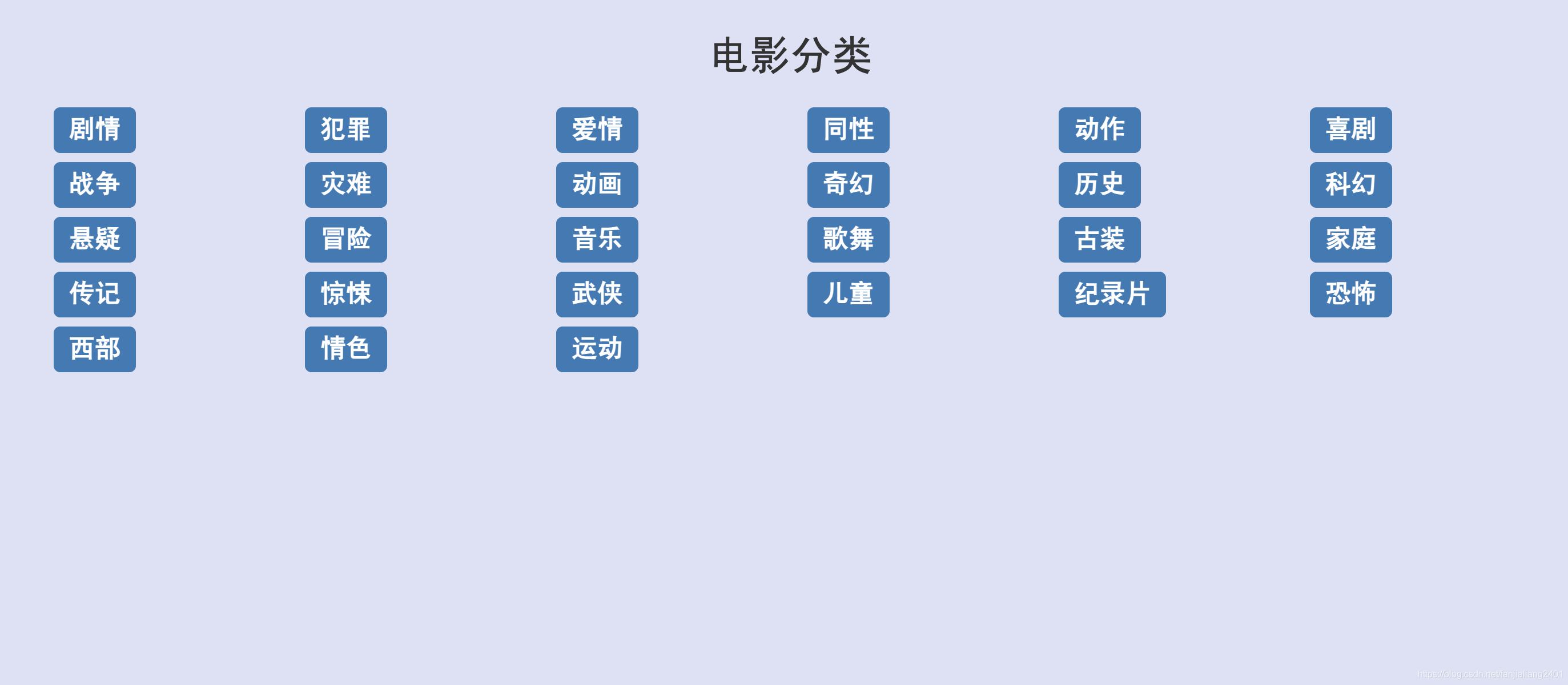
ラベル分類
ユーザーのログイン、登録、および変更情報
ユーザー登録インターフェース

ユーザーログインインターフェース
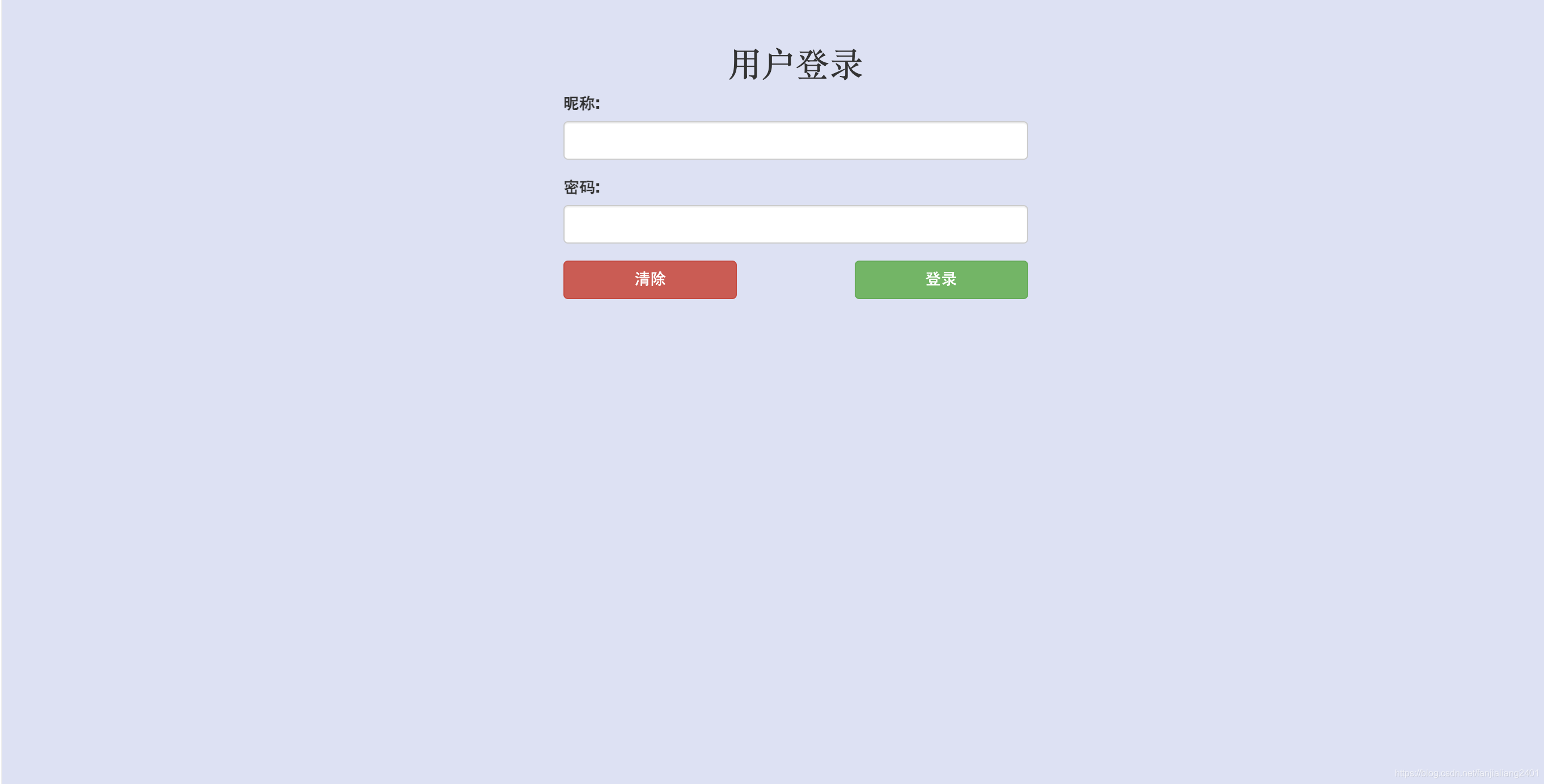
ユーザーの個人情報
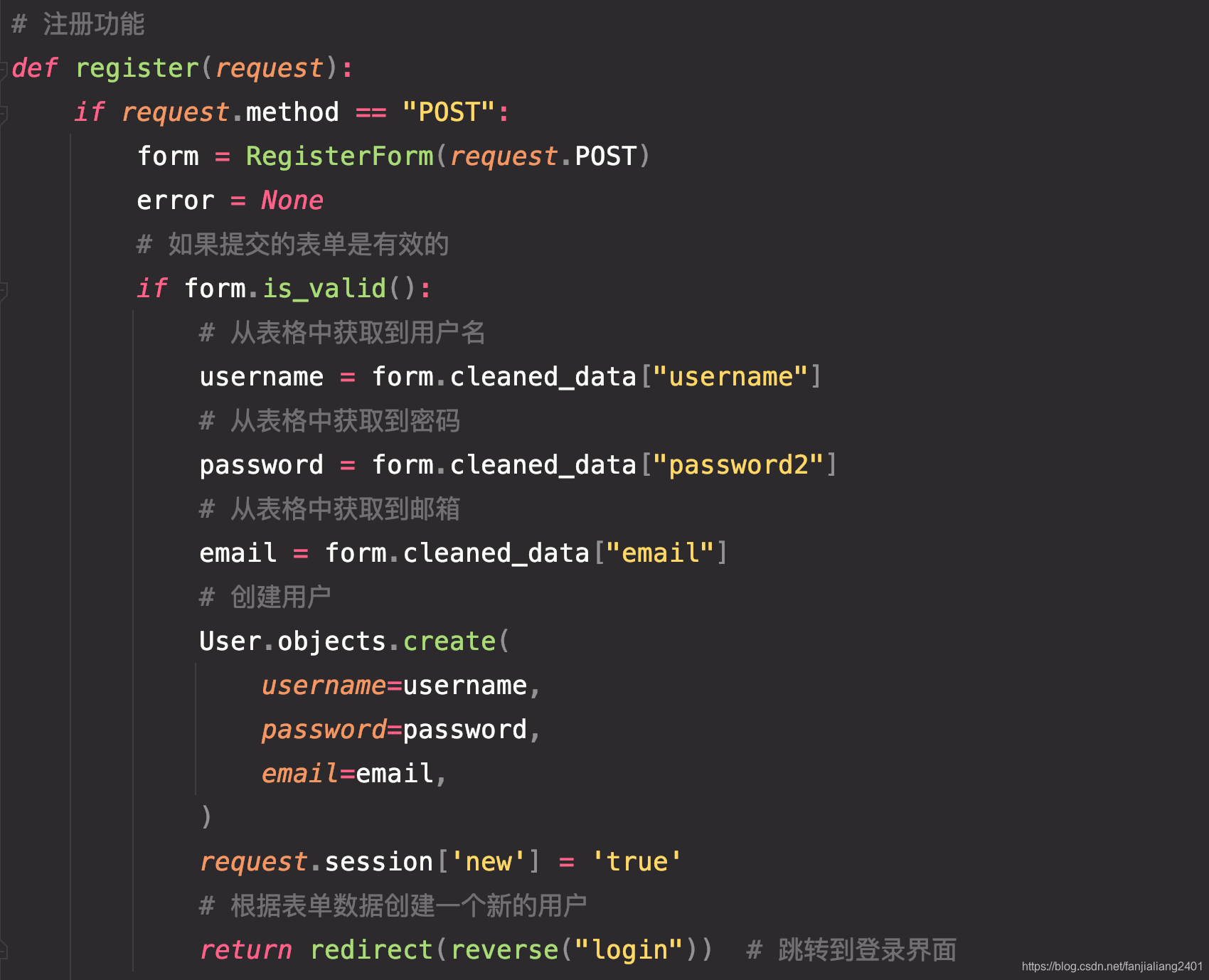
ユーザー登録コード
映画、お気に入り、映画の詳細ページのユーザー評価

ユーザーとアイテムに基づいて、ユーザーが見たい映画をレコメンドする協調フィルタリング レコメンデーション アルゴリズム
ユーザー推奨インターフェース

コードのユーザー推奨部分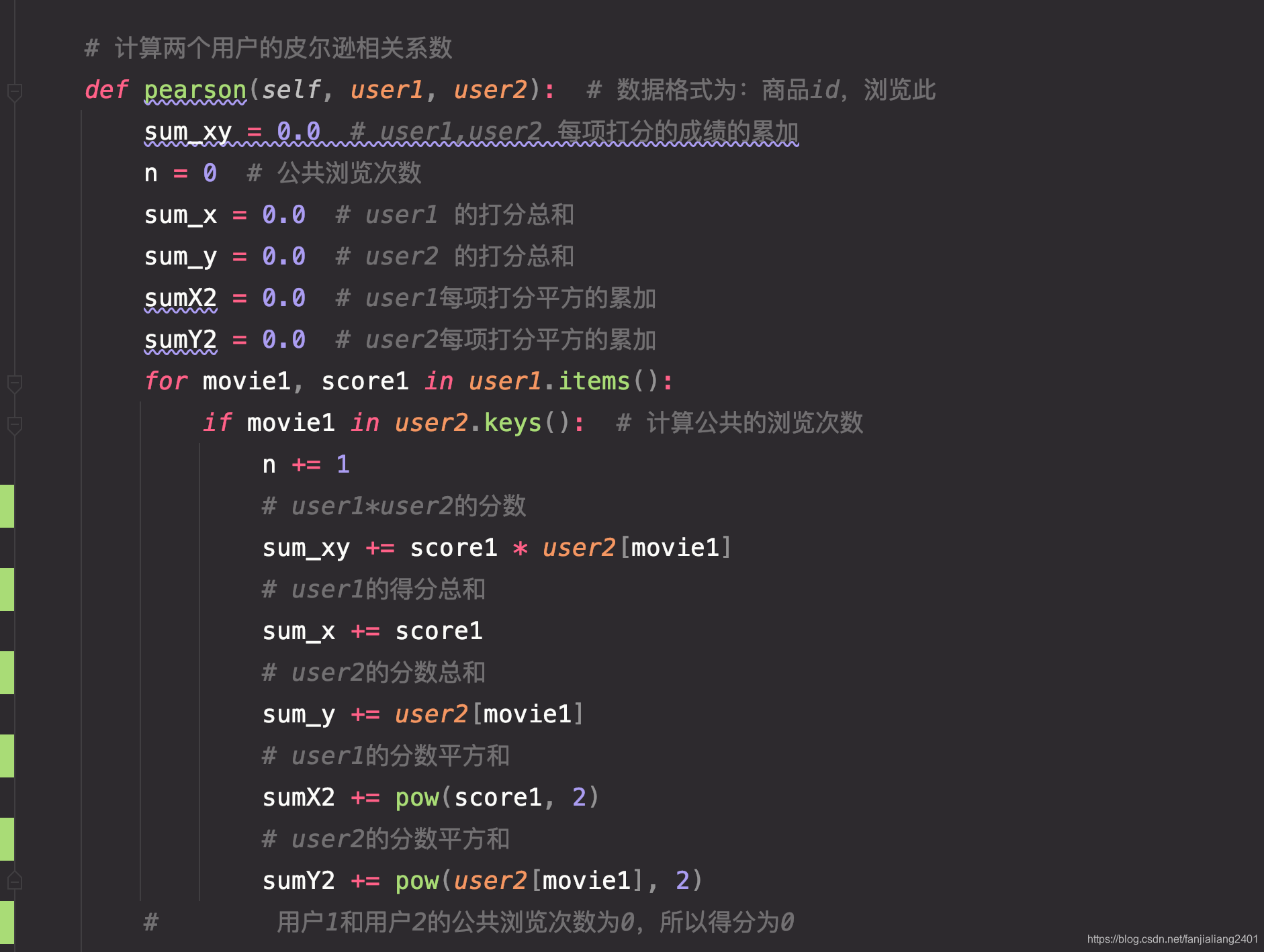
アイテム推奨インターフェース

アイテム推奨部品コード
動画情報の追加・削除・修正・確認ができるバックグラウンド管理システム

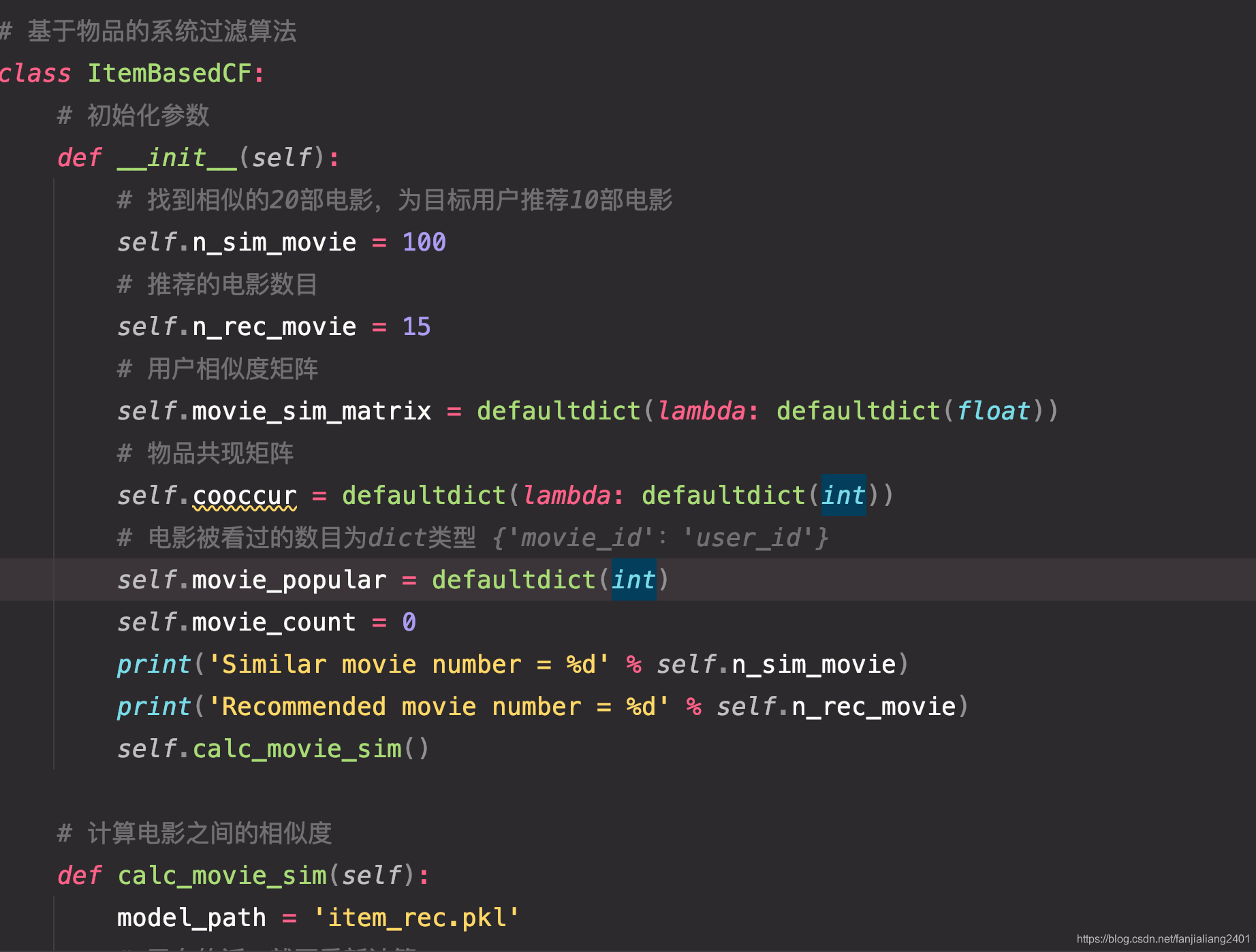
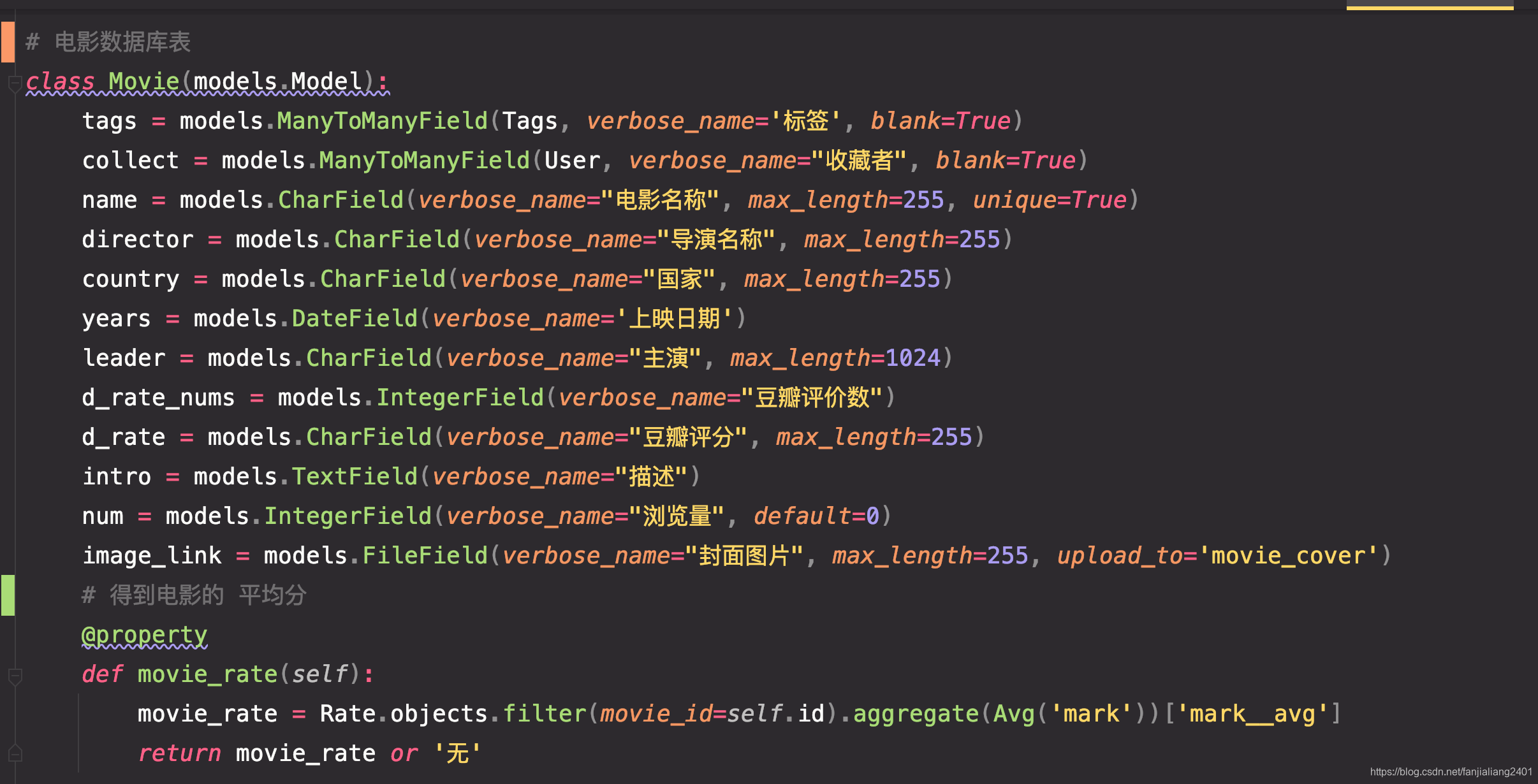
データベース モデル コード
アルゴリズムの紹介
コールドスタート問題解決
ユーザーが初めて登録すると、目的のラベル選択インターフェイスが表示されます。そして、ユーザーが評価していない場合は、ユーザーが好きなラベルの映画がユーザーに推薦されます。
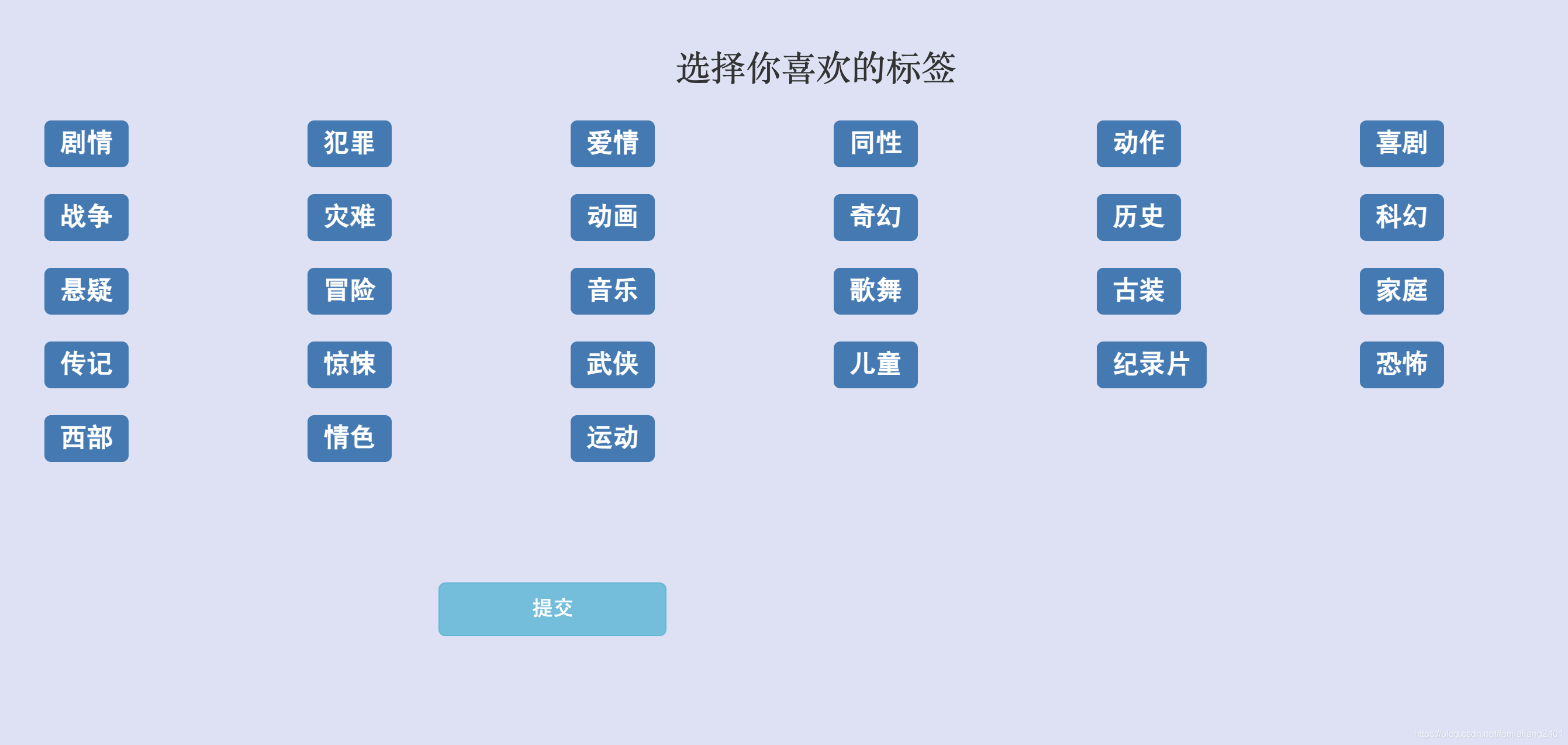
レコメンデーションアルゴリズムの改善 - タグと組み合わせた協調フィルタリングレコメンデーション
ユーザーがコールド スタート ページでタグを選択した後、これらのタグに対するユーザーの設定値を 5 に設定します。
ユーザーが映画にスコアを付けた後、タグに対するユーザーの好みのスコアは、映画のタグに従って更新されます。協調フィルタリングによってユーザーのおすすめ動画を取得した後、おすすめ動画が 15 件未満の場合は、ユーザーのお気に入りタグから一部の動画を選択して、タグのお気に入り値をお気に入り値に
更新する戦略を立てます。
テーブル。
ユーザーベースの協調フィルタリング
アルゴリズム: 協調フィルタリング、ユーザー スコアに基づく推奨事項の作成。評価されたすべてのユーザーから現在のユーザーに最も近い n 人のユーザーを見つけ、n 人のユーザーが評価した映画から現在のユーザーが視聴していない 15 の映画を見つけます。
最近接距離アルゴリズムは、協調フィルタリングによって実装されます。
レコメンデーション アルゴリズム - 協調フィルタリング - ショート ブックこのプロジェクトでは、ピアソン相関係数を使用して類似度を計算します。ユーザーベースの協調フィルタリング (Neighbor-based Collaborative Filtering) を採用します。
ピアソン距離式:

アイテムベースの協調フィルタリング
アイテム間の類似度を計算し、類似度に基づいてレコメンドする
アイテム間の共起行列、2 つのアイテムを n ユーザーが同時に購入
アイテム間の類似度

類似度: N の共起値/類似値/ M の類似値の根
推奨値: 類似度
スコア ユーザーが気に入った商品に基づいて、類似性の推奨を検索します。
それぞれの好きなアイテムとすべての嫌いなアイテムの間のスコアを計算します。スコア=類似度×スコア値
スコアが高いほど類似度が高い。その後、結果を返します
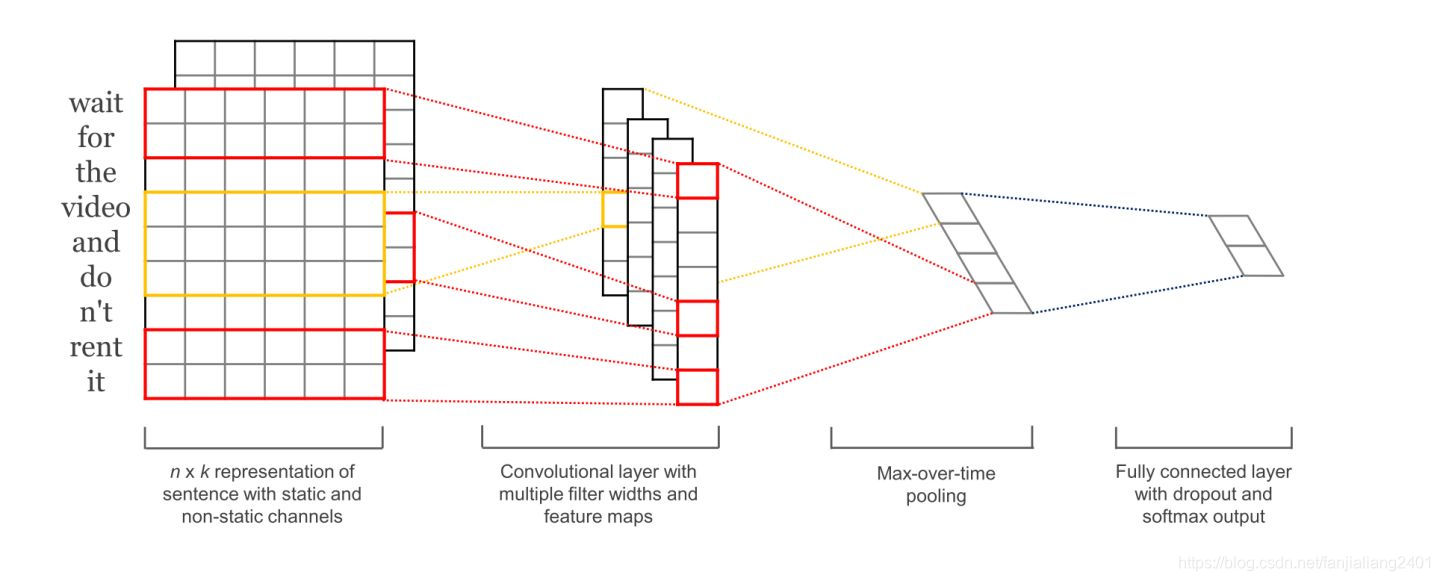
テンソルフロー/テキスト畳み込みネットワークに基づくレコメンデーション
movielensが提供するユーザー情報:年齢・性別・職業。これら 3 つのデータ ディメンションは、ユーザー データ情報を記述するために使用されます。次に、モデルを生成するためにテキスト畳み込みネットワークが構築されます。ユーザーは、年齢/性別およびその他の特性情報に基づいて、パーソナライズされたおすすめを取得できます。
ネットワークの最初の層は単語埋め込み層です。これは、各単語の埋め込みベクトルで構成される埋め込み行列です。次の層は、異なるサイズ (ウィンドウ サイズ) の複数の畳み込みカーネルを使用して、埋め込み行列で畳み込みを実行します. ウィンドウ サイズは、各畳み込みでカバーされる単語の数を表します. これは画像の畳み込みと同じではありません. 画像の畳み込みは通常 2x2, 3x3, 5x5 などのサイズを使用します. テキストの畳み込みは単語全体の埋め込みベクトルをカバーする必要があるため, サイズは (単語数, ベクトルの次元), Forたとえば、一度に 3 つ、4 つ、または 5 つの単語をスライドさせます。ネットワークの第 3 層は最大プーリングで長いベクトルを取得し、最後にドロップアウトを使用して正則化を行い、最後に映画のタイトルの特徴を取得します。