取引の特徴
A (Atomic): トランザクションを構成するすべての操作が実行されるか、まったく実行されないかのいずれかであり、部分的に成功し、部分的に失敗することが不可能な原子性。
C (一貫性): 一貫性、トランザクション実行の前後で、データベースの一貫性制約が破られていません。例: 張三が李思に 100 元を送金し、その前後のデータが正しいことを一貫性といい、張三が 100 元を送金しても李思の口座が 100 元増えない場合、 data error. 整合性が取れていません。
I (Isolation): Isolation. データベース内のトランザクションは一般に同時実行されます. Isolation は、2 つの同時トランザクションの実行が互いに干渉しないことを意味します. 1 つのトランザクションは、他のトランザクションの中間状態を見ることができません. トランザクション分離レベルを構成することで、ダーティ リードや繰り返し読み取りなどの問題を回避できます。
D (耐久性): 持続性. トランザクションが完了した後、トランザクションによってデータに加えられた変更はデータベースに持続され、ロールバックされません。
分類
スタンドアロントランザクション: データベース自体のトランザクション特性を利用して実現されるリレーショナルデータベースによるトランザクションの制御
分散トランザクション: トランザクション参加者、トランザクションをサポートするサーバー、リソース サーバー、およびトランザクション マネージャーは、異なる分散システムの異なるノードに配置され、異なるアプリケーションに属します. 分散トランザクションは、これらの操作がすべて成功するか、すべて失敗することを保証する必要があります. 本質的に、分散トランザクションは、異なるデータベースでデータの一貫性を確保することです。
分散トランザクション理論
キャップ
この定理の内容は、分散システムでは、Consistency (一貫性)、Availability (可用性)、Partition tolerance (パーティションのフォールト トレランス) を組み合わせることはできないということです。
一貫性 (C)
分散システム内のすべてのデータ バックアップが同時に同じ値を持つかどうか。(同じ最新のデータ コピーにアクセスするすべてのノードに相当)
可用性 (A)
クラスタ内の一部のノードに障害が発生した後、クラスタ全体がクライアントの読み取りおよび書き込み要求に引き続き応答できるかどうか。(データ更新の高可用性)
分割耐性 (P)
実際には、パーティショニングは、通信の制限時間要件に相当します。システムが制限時間内にデータの整合性を達成できない場合は、パーティションが発生したことを意味し、現在の操作について C と A のいずれかを選択する必要があります。
ベース理論
BASEは、基本的に利用可能(基本的に利用可能)、ソフト状態(ソフト状態)、最終的に一貫性(最終的な一貫性)の3つのフレーズの頭字語です。CAP における一貫性と可用性のトレードオフの結果である BASE 理論は、大規模なインターネット システムの分散型の実践をまとめたものであり、CAP 理論に基づいて徐々に進化しています。BASE理論の核となる考え方は、たとえ強整合性が達成できなくても、各アプリケーションはそれぞれのビジネス特性に応じて適切な方法を使用して、システムに最終的な整合性を達成させることができるというものです。
基本的に利用可能
基本的な可用性とは、予測できない障害が発生した場合に、分散システムがその可用性の一部を失うことが許されることを意味します。これは、システムが使用できないことと決して同等ではないことに注意してください。例えば:
(1) 応答時間の損失。通常、オンライン検索エンジンは対応するクエリ結果を 0.5 秒以内にユーザーに返す必要がありますが、障害により、クエリ結果の応答時間が 1 ~ 2 秒長くなります。
(2) システム機能の喪失: 通常の状況では、消費者は e コマース Web サイトで買い物をするとき、ほぼすべての注文をスムーズに完了することができますが、安定性を保護するために、消費者の買い物行動が急増するため、休日の買い物のピーク時に発生します。一部の消費者は、ショッピング システムのダウングレード ページに誘導される可能性があります。
ソフト状態
ソフト状態とは、システム内のデータが中間状態を持つことが許可されていることを意味し、この中間状態の存在はシステムの全体的な可用性に影響を与えないと考えられています。つまり、許可のプロセスに遅延があります。異なるノードのデータ コピー間でデータを同期するためのシステム
結果整合性
最終整合性は、すべてのデータ コピーが一定期間の同期の後、最終的に整合性のある状態に到達できることを強調しています。したがって、最終的な一貫性の本質は、システムが最終的なデータの一貫性を確保できることを保証する必要があることであり、リアルタイムでシステム データの強力な一貫性を保証する必要はありません。
SEATAの紹介
公式ウェブサイト: https://seata.io/zh-cn/docs/overview/what-is-seata.html
Seata は、高性能で使いやすい分散トランザクション サービスの提供に特化したオープン ソースの分散トランザクション ソリューションです。Seata は、AT、TCC、SAGA、および XA トランザクション モードをユーザーに提供し、ユーザー向けのワンストップ分散ソリューションを作成します。

TC (トランザクション コーディネーター) - トランザクション コーディネーター
グローバルおよびブランチ トランザクションの状態を維持し、グローバル トランザクションのコミットまたはロールバックを推進します。
TM (トランザクション マネージャー) - トランザクション マネージャー
グローバル トランザクションのスコープを定義します。グローバル トランザクションの開始、グローバル トランザクションのコミットまたはロールバック。
RM (リソース マネージャー) - リソース マネージャー
ブランチ トランザクションのリソースを管理し、TC と対話してブランチ トランザクションを登録し、ブランチ トランザクションのステータスを報告し、ブランチ トランザクションをコミットまたはロールバックさせます。
シートダウンロード
公式ダウンロードアドレス: https://seata.io/zh-cn/blog/download.html
シータサーバー構成
conf ディレクトリにある registry.conf ファイルを開きます。
シータの登録センターと構成センターをナコスに改造

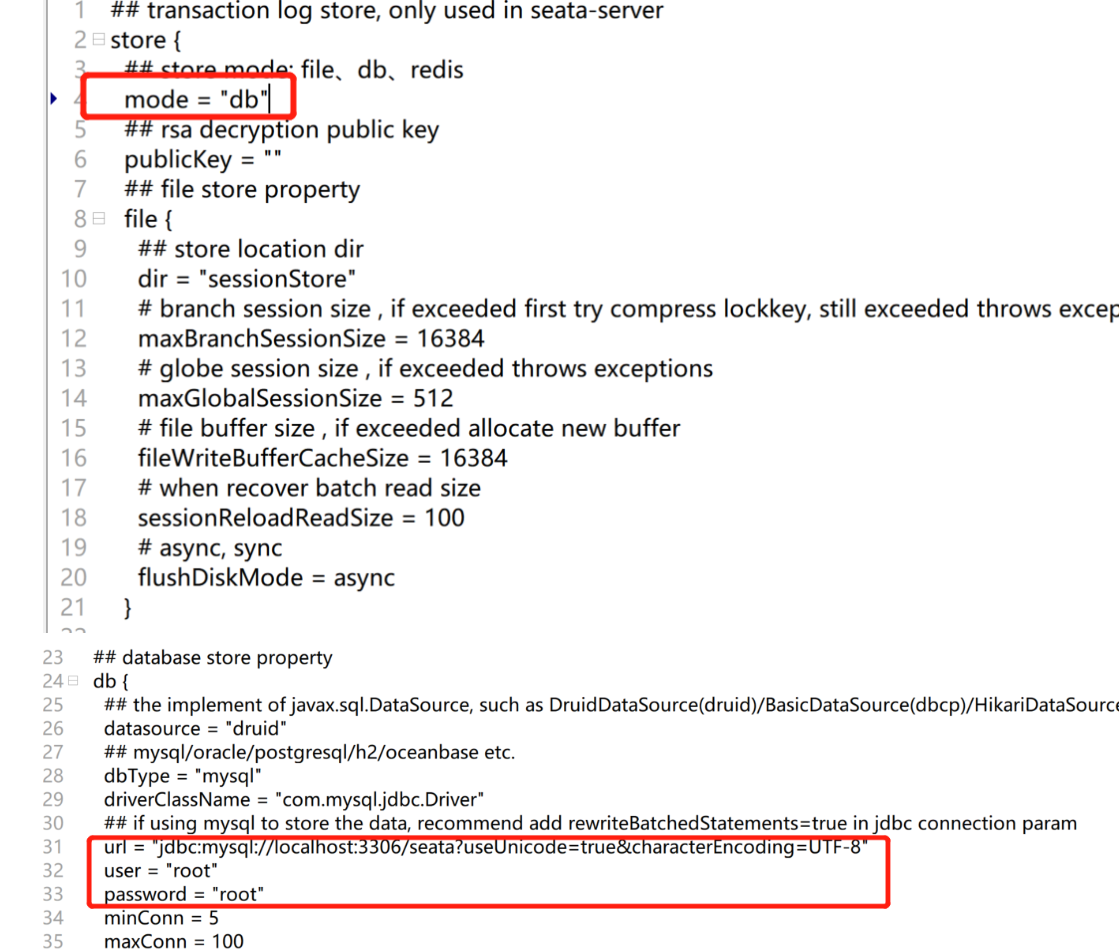
Seata のストレージ モードを変更し、file.conf ファイルを変更し、Seata のデフォルトのストレージ モードをデータベース「DB」に変更し、JDBC を構成する必要もあります。
起動
最初に nacos を起動し、次に Seata-Server を起動します
Seata-Server の起動方法は非常に簡単で、seata-server.bat をダブルクリックするだけです。
その後、nacos コンソールで Seata-Server を確認できます。
seata のデフォルトのポートは 8091 です
サーバー側のストレージ モード (store.mode) は 3 つをサポートします。
file: スタンドアロン モード。グローバル トランザクション セッション情報がメモリ内で読み書きし、ローカル ファイル root.data を高パフォーマンスで保持します (デフォルト)。
DB: 高可用性モード、グローバル トランザクション セッション情報は DB を介して共有され、パフォーマンスは比較的低い
redis: Seata-Server 1.3 以降でサポートされており、パフォーマンスが高く、トランザクション情報が失われるリスクがあるため、実際のシナリオと組み合わせて使用する必要があります。
file.conf で構成された seata データベース、および対応する global_table、branch_table、および lock_table はすべて自分で構築する必要があります。

建表语句地址: https://github.com/seata/seata/blob/develop/script/server/db/mysql.sql
完成以后需要重启seata
配置nacos
Seata支持注册服务到Nacos,以及支持Seata所有配置放到Nacos配置中心,在Nacos中统一维护;
高可用模式下就需要配合Nacos来完成

注册中心
Seata-server端配置注册中心,在registry.conf中加入配置注册中心nacos
注意:确保client与server的注册处于同一个namespace和group,不然会找不到服务。
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "SEATA_GROUP" # 这里的配置要和客户端保持一致
namespace = "" # 这里的配置要和客户端保持一致
cluster = "default"
username = "nacos"
password = "nacos"
}配置中心
Seata-Server配置配置中心,在registry.conf中加入配置使用nacos作为配置中心
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "nacos"
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = ""
password = ""
dataId = "seataServer.properties"
}我们需要把Seata的一些配置上传到Nacos中,配置比较多,所以官方给我们提供了一个config.txt,我们下载并且修改其中参数,上传到Nacos中
下载地址:https://github.com/seata/seata/tree/develop/script/config-center
具体修改:
注意:事务分组:用于防护机房停电,来启用备用机房,或者异地机房,容错机制,当然如果Seata-Server配置了对应的事务分组,Client也需要配置相同的事务分组
service.vgroupMapping.可以自定义=default
default这里必须等于 registry.config 中的cluster="default"(当然可以更改 )
修改好这个文件以后,我们就需要把这个文件放到seata目录下
此时我们需要把这些配置一个个的加入到Nacos配置中,所以我们需要一个脚本来进行执行,官方已经提供好了
地址为:https://github.com/seata/seata/blob/develop/script/config-center/nacos/nacos-config.sh
我们需要在seata-server-1.4.2文件夹中新建一个脚本文件nacos-config.sh,然后把脚本内容复制进去
利用git来进行执行命令:
sh nacos-config.sh -h localhost -p 8848 -g SEATA_GROUP -t 命名空间 -u nacos -w nacos
参数说明:
-h:host,默认值localhost
-p:port,默认值8848
-g:配置分组,默认为SEATA_GROUP
-t:租户信息,对应Nacos的命名空间ID,默认为空
在执行naocs-config文件的时候要注意,它默认寻找config.txt的路径和我们的路径不同,所以要打开naocs-config文件进行修改,否则无法执行。

当以上的这些配置完成以后,我们就可以启动nacos和seata-server了,此时我们查看Nacos的配置中心,就会看到我们传入的所有配置信息
AT模式(常用)
AT模式是一种无侵入的分布式事务解决方案,在 AT 模式下,用户只需关注自己的“业务 SQL”,用户的 “业务 SQL” 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
通过Seata的AT模式解决分布式事务
首先增加对应的Seata依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>在对应的微服务数据库上加上undo_log表,此表用于数据的回滚
具体的建表语句
https://github.com/seata/seata/blob/master/script/client/at/db/mysql.sql
配置yml(8801和8802Seata的配置保持一致)
server:
port: 8801
spring:
application:
name: seata-order
cloud:
nacos:
discovery:
server-addr: localhost:8848
alibaba:
seata:
tx-service-group: mygroup # 事务组, 随便写
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/test_at?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
seata:
tx-service-group: mygroup # 事务组名称,要和服务端对应
service:
vgroup-mapping:
mygroup: default # key是事务组名称 value要和服务端的机房名称保持一致在order8801(TM)的Controller上添加注解
@GlobalTransactional,加在TM上
@RestController
public class OrderController {
@Autowired
private OrderService orderService;
@GetMapping("/order/create")
@GlobalTransactional// 开启分布式事务
public String create(){
orderService.create();
return "生成订单";
}
}把8801和8802都跑起来,当然Nacos和Seata都要进行启动
这个时候我们进行访问Order的REST接口:http://localhost:8801/order/create,我们就会发现此时已经解决了分布式事务问题
XA模式
在 Seata 定义的分布式事务框架内,利用事务资源(数据库、消息服务等)对 XA 协议的支持,以 XA 协议的机制来管理分支事务的一种 事务模式。
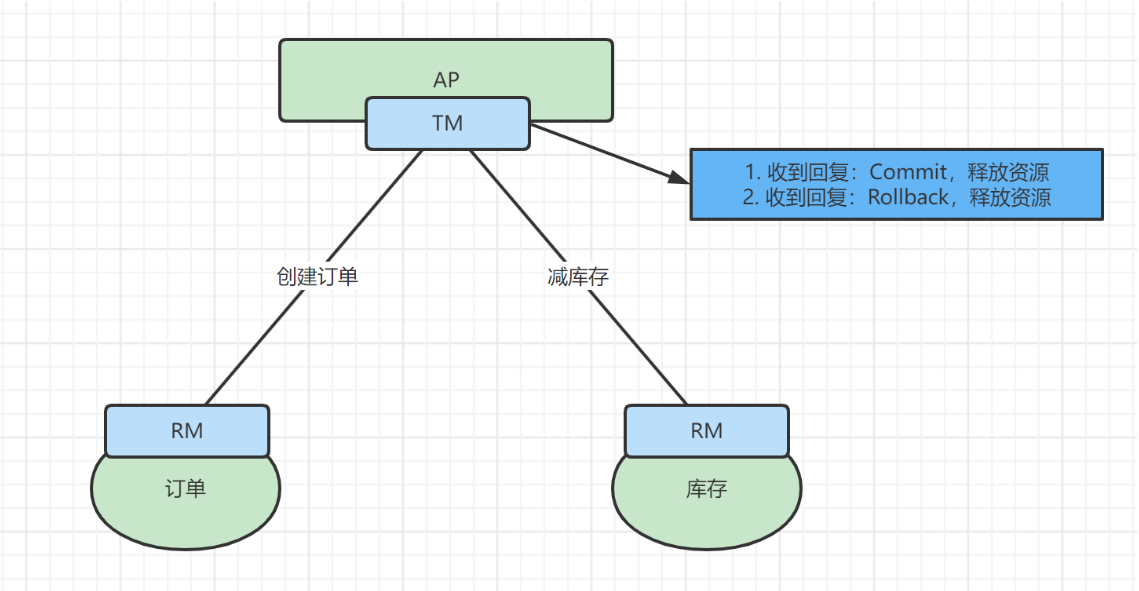
应用程序(AP)持有订单库和商品库两个数据源。
应用程序(AP)通过TM通知订单库(RM)和商品库(RM),来创建订单和减库存,RM此时未提交事务,此时商品和订单资源锁定。
TM收到执行回复,只要有一方失败则分别向其他RM发送回滚事务,回滚完毕,资源锁释放。
TM收到执行回复,全部成功,此时向所有的RM发起提交事务,提交完毕,资源锁释放。
XA协议的痛点
如果一个参与全局事务的资源 “失联” 了(收不到分支事务结束的命令),那么它锁定的数据,将一直被锁定。进而,甚至可能因此产生死锁。
这是 XA 协议的核心痛点,也是 Seata 引入 XA 模式要重点解决的问题。

与AT不同的是,XA没有undo_log表;
AT利用undo log实现了最终一致性,会有中间状态(可能会导致脏读);
XA实现了强一致性,没有中间状态,利用数据库自带的事务进行回滚
XA模式优点:
业务无侵入:和 AT 一样,XA 模式将是业务无侵入的,不给应用设计和开发带来额外负担。
数据库的支持广泛:XA 协议被主流关系型数据库广泛支持,不需要额外的适配即可使用。
多语言支持容易:因为不涉及 SQL 解析,XA 模式对 Seata 的 RM 的要求比较少。
传统基于 XA 应用的迁移:传统的,基于 XA 协议的应用,迁移到 Seata 平台,使用 XA 模式将更平滑。

从编程模型上,XA 模式与 AT 模式保持完全一致。
在样例中,上层编程模型与 AT 模式完全相同。只需要修改数据源代理,即可实现 XA 模式与 AT 模式之间的切换。
@Bean("dataSource")
public DataSource dataSource(DruidDataSource druidDataSource) {
// DataSourceProxy for AT mode
// return new DataSourceProxy(druidDataSource);
// DataSourceProxyXA for XA mode
return new DataSourceProxyXA(druidDataSource);
}TCC模式
TCC 是分布式事务中的二阶段提交协议,它的全称为 Try-Confirm-Cancel,即资源预留(Try)、确认操作(Confirm)、取消操作(Cancel),他们的具体含义如下:
1. Try:对业务资源的检查并预留;
2. Confirm:对业务处理进行提交,即 commit 操作,只要 Try 成功,那么该步骤一定成功;
3. Cancel:对业务处理进行取消,即回滚操作,该步骤回对 Try 预留的资源进行释放。
TCC和AT的区别是TCC不依赖数据库本身的ACID,都是调用自定义的方法;
侵入性比较强,并且需要自己实现相关事务控制逻辑
在整个过程基本没有锁,性能较强
SAGA模式
Saga模式是SEATA提供的长事务解决方案,在Saga模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。

适用场景:
业务流程长、业务流程多
参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口
优势:
一阶段提交本地事务,无锁,高性能
事件驱动架构,参与者可异步执行,高吞吐
补偿服务易于实现
缺点:
不保证隔离性(应对方案见后面文档)
Saga的实现:
基于状态机引擎的 Saga 实现:
目前SEATA提供的Saga模式是基于状态机引擎来实现的,机制是:
通过状态图来定义服务调用的流程并生成 json 状态语言定义文件
状态图中一个节点可以是调用一个服务,节点可以配置它的补偿节点
状态图 json 由状态机引擎驱动执行,当出现异常时状态引擎反向执行已成功节点对应的补偿节点将事务回滚
注意: 异常发生时是否进行补偿也可由用户自定义决定
可以实现服务编排需求,支持单项选择、并发、子流程、参数转换、参数映射、服务执行状态判断、异常捕获等功能