1.YOLOV4ネットワーク構造
以上で V1、V2、V3 の話は終わりましたが、YOLOV4 と V3 のネットワークの違いは、CSP と PAN 構造が多く、SSP が 1 つあることです。ネットワーク図を投稿します。

まず、ネットワーク構造に現れるさまざまなコンポーネントを紹介しましょう。
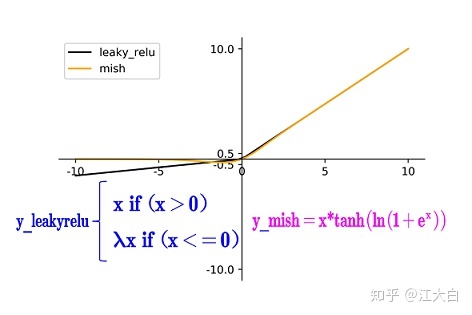
CBM: Conv+BN+Mish活性化関数で構成されています.V3との違いはここの活性化関数がLeaky_reluのMishに置き換わっていることです.
CBL:このコンポーネントは YOLOV3 で最小のコンポーネントですが、ここで V4 は CBL をバックボーンではなくネック モジュールに配置します。
Res unit:ネットワークをより深く構築できるように、Resnet ネットワークの残差構造から学習します。
CSPX: CSPNet ネットワーク構造を利用して、畳み込み層と X Res ユニット モジュール Concate で構成されます。
SPP:マルチスケール融合には 1×1、5×5、9×9、13×13 の最大プーリング方法を使用します。
ここで言う必要があるのは、Concate 操作と Add 操作を分離する必要があるということです。
これらのコンポーネントを紹介すると、YOLOV4 のモデル全体が 4 つの主要なブロックに分割され、各ブロックにいくつかのトリックがあることがわかります。
入力側:モザイク データ強化、cmBN、SAT 自己敵対的トレーニングなど、いくつかのデータ強化方法を次に示します。
バックボーン: CSPDarknet53、ミッシュ起動機能、Dropblockに置き換え。
ネック:ターゲット検出ネットワークは、Yolov4 の SPP モジュールや FPN+PAN 構造など、BackBone と最終出力レイヤーの間にいくつかのレイヤーを挿入することがよくあります。
予測:出力層のアンカー フレーム メカニズムは Yolov3 と同じです. 主な改善点は、トレーニング中の損失関数 CIOU_Loss であり、予測フレーム スクリーニングの nms は DIOU_nms になります.
作者の描写を見てください。

2. 入力側のイノベーション
ここでは主に Mosaic データ強調方法について説明します. この強調方法は, 実際には, ランダムズーム, ランダムトリミング, ランダム配置によって画像を継ぎ合わせることです. ここでは, 4 つの画像を継ぎ合わせに使用します. 詳細は次の図に示すとおりです.
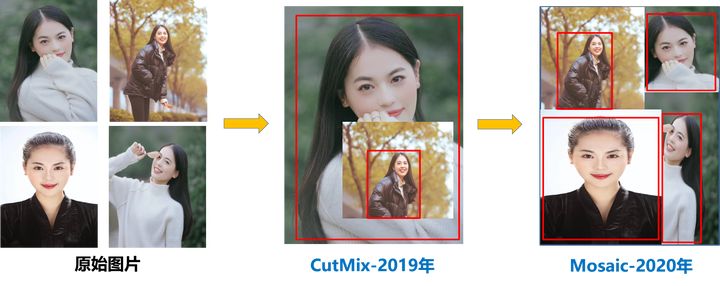
データ拡張は、特にデータ セットが小さい場合に非常に効果的な方法です。しかし、YOLOV4 でのモザイク データ拡張の利点は主に次のとおりです。
- 強化されたデータ セット: 4 つの画像をランダムに使用し、それらをランダムにスケーリングし、スプライシングのためにランダムに分散します。これにより、検出データ セットが大幅に強化されます。特に、ランダム スケーリングにより多くの小さなターゲットが追加され、ネットワークがより堅牢になります。
- GPU削減:ランダムスケーリングや通常のデータ強調もできるという人もいるかもしれませんが、筆者は多くの人がGPUを1つしか持っていない可能性があると考えているため、Mosaicでトレーニングを強化すると、4枚の画像のデータを直接計算できるようになり、ミニバッチ サイズ 非常に大きくする必要はありません。GPU を使用すると、より良い結果が得られます。
3. バックボーンの革新
まず、全体のフレームワークを見てみましょう全体のフレームワークは、YOLOV3のDarknet53をベースに、CSPNetの考え方を応用し、CSPをResユニットに置き換えたものです。

CSPNet の正式名称は Cross Stage Paritial Network で、主にネットワーク構造設計の観点から推論における大量の計算の問題を解決します。CSPNet の作成者は、高推論計算の問題は、ネットワーク最適化における勾配情報の重複によるものであると考えています。したがって、CSPモジュールを使用して、最初にベースレイヤーの特徴マップを2つの部分に分割し、次にクロスステージ階層を介してそれらをマージします。これにより、計算量を削減しながら精度を確保できます. そのため、Yolov4 はバックボーン ネットワーク Backbone に CSPDarknet53 ネットワーク構造を採用しています。これには、CNN の学習能力の向上、精度を維持しながら軽量化、コンピューティングのボトルネックの削減、メモリ コストの削減という 3 つの主な利点があります。
2 つ目の変更点は、バックボーンに Mish 関数を適用することです.leaky_relu との具体的な違いは、次の図に示されています。
3 つ目は Dropblock の適用です. 特定の機能は, ネットワークを単純にするためにいくつかのニューロンをランダムに破棄することです. これと Dropout の違いは, Dropout はいくつかのニューロンをランダムに破棄することですが, この方法は畳み込み層にはありません. 非常に敏感です.畳み込み層は隣接する活性化ユニットから同じ情報を学習できるため、完全に接続された層のドロップアウトは畳み込み層には適用されません。具体的には次の図のようになります。

4. ネックの革新
まず第一に、SPP コンポーネントの追加です. SPP の主な原則は、K={1*1, 5*5, 9*9, 13*13} の最大プーリングを使用して Concat 操作を実行することです異なる縮尺の特徴マップ。ここでは、同じサイズの特徴マップにパディング方法を使用して、プーリング後の特徴マップが以前と同じサイズになるようにします。
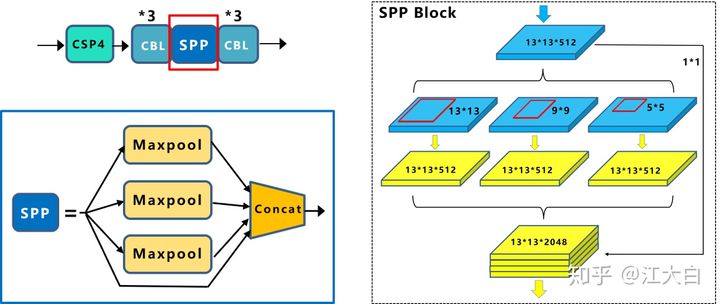
この方法により、バックボーン ネットワークの機能範囲をより効果的に拡大できます。
2つ目の変更点は、YOLOV3との最大の違いでもあるFPN+PANの採用です。具体的な構造図を見てみましょう。

各 CSP モジュールの前にある畳み込みカーネルのサイズは 3*3 で、ステップ サイズは 2 で、これはダウンサンプリング操作に相当します。したがって、3 つの紫色の矢印の特徴マップは 76*76、38*38、19*19 です。YOLOV3 との違いは、FPN 構造だけでなく、大きな特徴マップと小さな特徴マップを組み合わせる方法にもあることがわかります.これが PAN です.具体的な写真は次のとおりです。
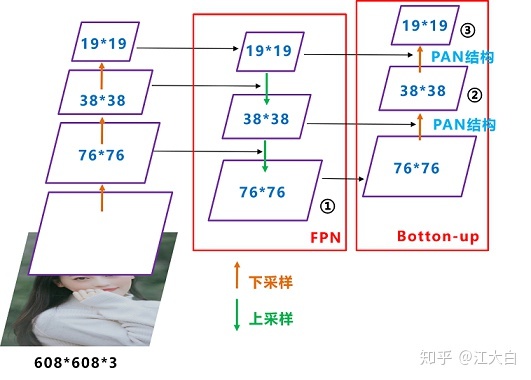
これの利点は、大きな特徴マップにはより強力な位置決め特徴が含まれているため、オブジェクトの回帰フレームをより適切にマークでき、より深い特徴マップは音声情報を送信し、2 つの組み合わせがより効果的であることです。
5、予測
ターゲット検出タスクの損失関数は、通常、分類損失 (分類損失関数) とバウンディング ボックス回帰損失 (回帰損失関数) の 2 つの部分で構成されます。近年の Loss of Bounding Box Regeression の開発プロセスは、 Smooth L1 Loss -> IoU Loss (2016) -> GIOU Loss (2019) -> DIOU Loss (2020) -> CIoU Loss (2020) です。最も一般的に使用される IOU_Loss から始めて、逆アセンブル比較分析を行い、Yolov4 が CIOU_Loss を選択する理由を見てみましょう。
a.IOU_Loss


最初の図では、IOU が非常に単純であることがわかります.実際には交差/結合ですが、下の図には 2 つの問題があります.
質問 1:つまり、状態 1 の場合、予測フレームとターゲット フレームが互いに素である場合、IOU=0 であり、2 つのフレーム間の距離を反映できません.このとき、損失関数は導出できず、 IOU_Loss は、2 つのフレームがばらばらであるケースを最適化できません。
質問 2:状態 2 と状態 3 の場合、2 つの予測フレームが同じサイズで、2 つの IOU が同じ場合、IOU_Loss は 2 つの交点の違いを区別できません。
そのため、GIOU_Loss は改善されたように見えました。
b.GIOU_Loss


右側の GIOU_Loss では、交差スケールの測定方法が追加されていることがわかります。これにより、純粋な IOU_Loss の恥ずかしさが軽減されます。しかし、なぜ緩和と言うのでしょうか?まだ欠点があるので: 状態 1, 2, 3 はすべて予測フレームがターゲット フレームの内側にあり、予測フレームのサイズが同じ場合です. このとき、予測フレームとターゲットの差分はフレームは同じなので、3 つの状態GIOU の値も同じです このとき、GIOU は IOU に縮退し、相対的な位置関係は区別できません。この問題に基づいて、 DIOU_Loss が
提案されました。
c.DIOU_Loss
適切なターゲット ボックス回帰関数では、重なり合う領域、中心点の距離、縦横比の3 つの重要な幾何学的要素を考慮する必要があります。IOU と GIOU の問題に対応して、著者は 2 つの側面を考慮します。予測フレームとターゲット フレームの間の正規化された距離をどのように最小化するか? 2: 予測フレームとターゲット フレームが重なったときに回帰をより正確にする方法は? 最初の質問では、DIOU_Loss (Distance_IOU_Loss) が提案されています。


DIOU_Loss は重なる領域と中心点の距離を考慮します. 対象フレームが予測フレームをラップする場合, 2 つのフレーム間の距離を直接測定するため, DIOU_Loss はより速く収束します. しかし、以前の良いオブジェクト ボックスの回帰関数で述べたように、縦横比は考慮されていません。たとえば、上記の 3 つのケースでは、ターゲット フレームが予測フレームをラップし、DIOU_Loss が機能します。しかし、予測フレームの中心点の位置は同じなので、DIOU_Loss の計算式によれば、3 つの値は同じです。この問題に対応して、CIOU_Loss が提案されました。
d.CIOU_損失
CIOU_Loss と DIOU_Loss の前の式は同じですが、これに基づいて、予測ボックスとターゲット ボックスの縦横比を考慮して、インパクト ファクターが追加されます。
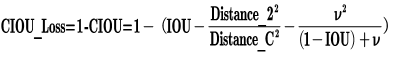
ここで、v はアスペクト比の一貫性を測定するパラメーターであり、次のように定義することもできます。

このように、CIOU_Loss は、ターゲット フレームの回帰関数で 3 つの重要な幾何学的要因を考慮に入れます: オーバーラップ エリア、中心点の距離、およびアスペクト比です。
さまざまな損失関数の違いを包括的に見てみましょう。
IOU_Loss:主に検知枠と対象枠の重なり領域を考慮します。
GIOU_Loss: IOU に基づいて、バウンディング ボックスが一致しない場合の問題を解決します。
DIOU_Loss: IOU と GIOU に基づいて、バウンディング ボックスの中心点からの距離の情報を考慮します。
CIOU_Loss: DIOU に基づいて、バウンディング ボックスのアスペクト比のスケール情報を考慮します。
Yolov4 ではCIOU_Loss回帰法が採用されており、予測フレーム回帰がより高速かつ正確になります。
参考:Yoloシリーズの中心となるYolov3&Yolov4&Yolov5&Yoloxの基礎知識を徹底解説 - ナレッジ