pip install xxx -i https://pypi.tuna.tsinghua.edu.cn/simple など、pip インストールには国内のソースを使用することをお勧めします。
目次
1. Conda env 環境の作成
conda create -n py39 python=3.9
2.pytorchをインストールする
最初にcudaのバージョンを確認してから、pytorchのバージョンに対応します
システムのnvidiaドライバーのバージョンが最高のcudaバージョンをサポートしていることを確認してください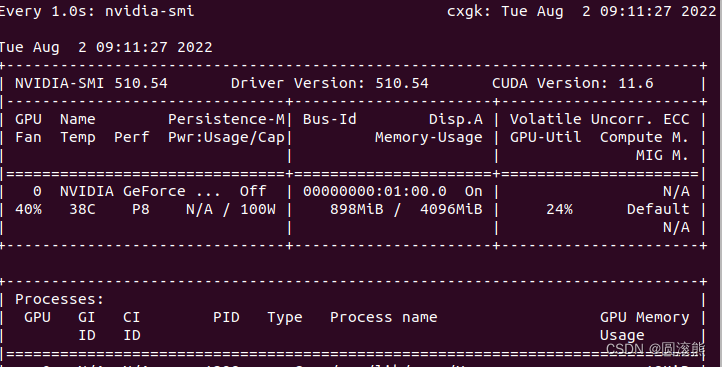
現在の cuda バージョンを表示する

対応する cuda バージョンに従って pytorch torchvision をインストールします
ソース py39 をアクティブ化
conda install pytorch torchvision cudatoolkit=11.3 -c pytorch
3. fvcore をインストールする
pip install git+https://github.com/facebookresearch/fvcore
4. simplejson をインストールします
pip インストール simplejson

5. gcc のバージョンを確認する
gcc -v
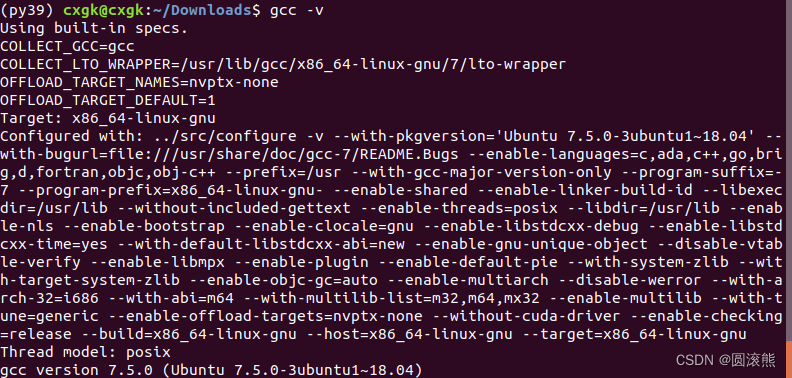
バージョンは 7.5.0 です
6.PyAV
conda install av -c conda-forge
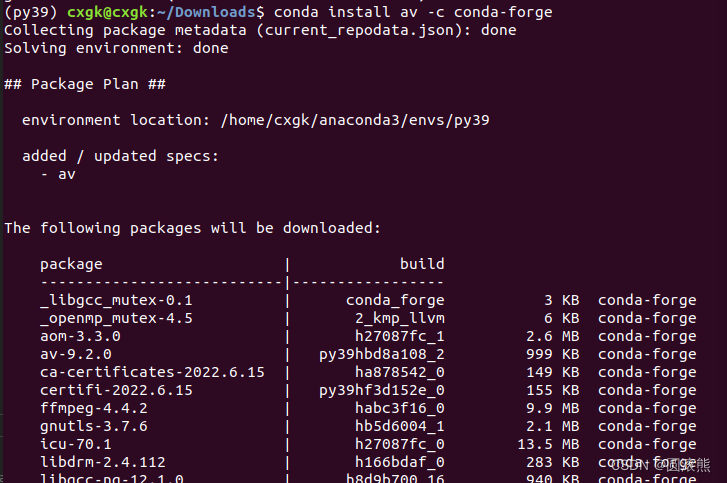
7.PyAV を使用した ffmpeg
ピップインストールオフ
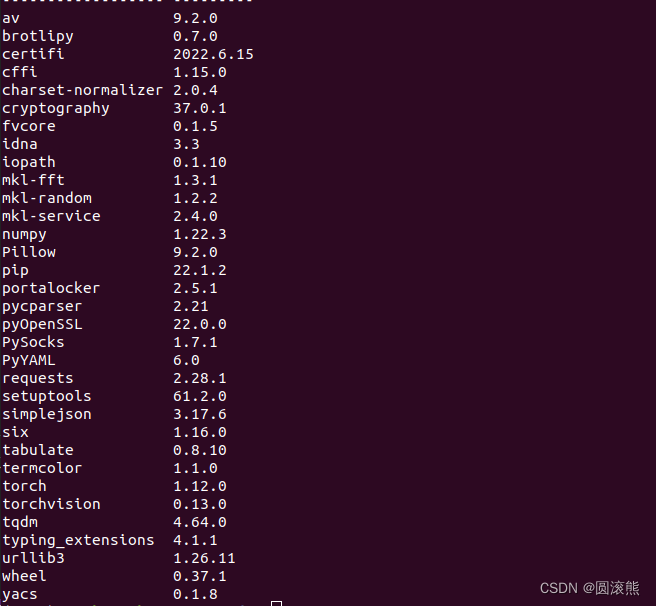
8. PyYaml、tqdm
pip リスト fvcore
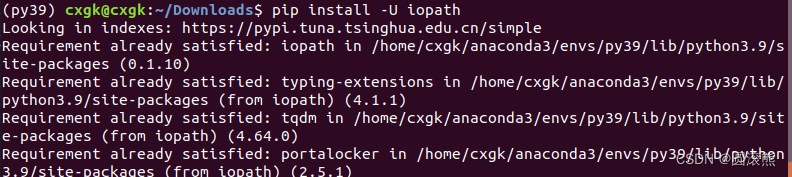
9.iopath
pip install -U iopath
10.psutil
pip インストール psutil
11.opencv
pip install opencv-python
12.テンソルボード
テンソルボードがインストールされているかどうかを確認します。
コンダリストテンソルボード
テンソルボードがインストールされていません
pip インストールテンソルボード
13. ムービーピー
pip install moviepy
14. PyTorchビデオ
pip install pytorchvideo

15.ディテトロン2
git クローン https://github.com/facebookresearch/detectron2 detectron2_repo
pip install -e detectron2_repo
16.フェアスケール
pip install git+https://github.com/facebookresearch/fairscale
17.スローファスト
cd SlowFast
python setup.py ビルド 開発
デモ テスト モデルを実行する
python3 ツール/run_net.py --cfg デモ/AVA/SLOWFAST_32x2_R101_50_50.yaml
インストールプロセス中に発生したいくつかのエラー
エラー0
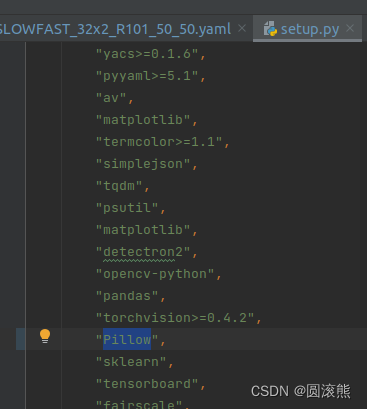
PILが見つからない
回避策: setup.py の PIL を Pillow に変更します。
エラー1
from pytorchvideo.layers.distributed import ( # noqa
ImportError: cannot import name 'cat_all_gather' from 'pytorchvideo.layers.distributed' (/home/cxgk/anaconda3/envs/sf/lib/python3.9/site-packages/pytorchvideo/レイヤー/分散.py)
解決:
方法 1 :メインの facebookresearch/pytorchvideo GitHub ファイルにある pytorchvideo/pytorchvideo の内容を、仮想環境に対応するファイルにコピーします。 /pytorchvideo/
方法 2:
次のコンテンツをlayers/distributed.pyに追加します
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
"""Distributed helpers."""
import torch
import torch.distributed as dist
from torch._C._distributed_c10d import ProcessGroup
from torch.autograd.function import Function
_LOCAL_PROCESS_GROUP = None
def get_world_size() -> int:
"""
Simple wrapper for correctly getting worldsize in both distributed
/ non-distributed settings
"""
return (
torch.distributed.get_world_size()
if torch.distributed.is_available() and torch.distributed.is_initialized()
else 1
)
def cat_all_gather(tensors, local=False):
"""Performs the concatenated all_reduce operation on the provided tensors."""
if local:
gather_sz = get_local_size()
else:
gather_sz = torch.distributed.get_world_size()
tensors_gather = [torch.ones_like(tensors) for _ in range(gather_sz)]
torch.distributed.all_gather(
tensors_gather,
tensors,
async_op=False,
group=_LOCAL_PROCESS_GROUP if local else None,
)
output = torch.cat(tensors_gather, dim=0)
return output
def init_distributed_training(cfg):
"""
Initialize variables needed for distributed training.
"""
if cfg.NUM_GPUS <= 1:
return
num_gpus_per_machine = cfg.NUM_GPUS
num_machines = dist.get_world_size() // num_gpus_per_machine
for i in range(num_machines):
ranks_on_i = list(
range(i * num_gpus_per_machine, (i + 1) * num_gpus_per_machine)
)
pg = dist.new_group(ranks_on_i)
if i == cfg.SHARD_ID:
global _LOCAL_PROCESS_GROUP
_LOCAL_PROCESS_GROUP = pg
def get_local_size() -> int:
"""
Returns:
The size of the per-machine process group,
i.e. the number of processes per machine.
"""
if not dist.is_available():
return 1
if not dist.is_initialized():
return 1
return dist.get_world_size(group=_LOCAL_PROCESS_GROUP)
def get_local_rank() -> int:
"""
Returns:
The rank of the current process within the local (per-machine) process group.
"""
if not dist.is_available():
return 0
if not dist.is_initialized():
return 0
assert _LOCAL_PROCESS_GROUP is not None
return dist.get_rank(group=_LOCAL_PROCESS_GROUP)
def get_local_process_group() -> ProcessGroup:
assert _LOCAL_PROCESS_GROUP is not None
return _LOCAL_PROCESS_GROUP
class GroupGather(Function):
"""
GroupGather performs all gather on each of the local process/ GPU groups.
"""
@staticmethod
def forward(ctx, input, num_sync_devices, num_groups):
"""
Perform forwarding, gathering the stats across different process/ GPU
group.
"""
ctx.num_sync_devices = num_sync_devices
ctx.num_groups = num_groups
input_list = [torch.zeros_like(input) for k in range(get_local_size())]
dist.all_gather(
input_list, input, async_op=False, group=get_local_process_group()
)
inputs = torch.stack(input_list, dim=0)
if num_groups > 1:
rank = get_local_rank()
group_idx = rank // num_sync_devices
inputs = inputs[
group_idx * num_sync_devices : (group_idx + 1) * num_sync_devices
]
inputs = torch.sum(inputs, dim=0)
return inputs
@staticmethod
def backward(ctx, grad_output):
"""
Perform backwarding, gathering the gradients across different process/ GPU
group.
"""
grad_output_list = [
torch.zeros_like(grad_output) for k in range(get_local_size())
]
dist.all_gather(
grad_output_list,
grad_output,
async_op=False,
group=get_local_process_group(),
)
grads = torch.stack(grad_output_list, dim=0)
if ctx.num_groups > 1:
rank = get_local_rank()
group_idx = rank // ctx.num_sync_devices
grads = grads[
group_idx
* ctx.num_sync_devices : (group_idx + 1)
* ctx.num_sync_devices
]
grads = torch.sum(grads, dim=0)
return grads, None, Noneエラー2
scipy.ndimage からインポート gaussian_filter
ModuleNotFoundError: 'scipy' という名前のモジュールがありません
解決:
pip インストール scipy
エラー3
from av._core import time_base, library_versions
ImportError: /home/cxgk/anaconda3/envs/sf/lib/python3.9/site-packages/av/../../.././libgnutls.so.30: シンボル mpn_copyi バージョン HOGWEED_6 がファイルで定義されていませんlibhogweed.so.6 とリンク時の参照
解決:
最初にavパッケージに移動
pipを使ってインストール
ピップインストールオフ
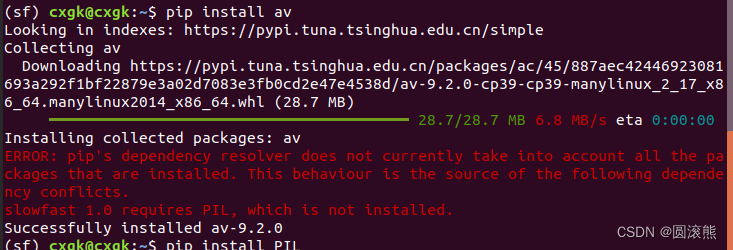
エラー4
ファイル "/media/cxgk/Linux/work/SlowFast/slowfast/models/losses.py"、11 行目、
pytorchvideo.losses.soft_target_cross_entropy インポート (
ModuleNotFoundError: No module named 'pytorchvideo.losses'から)
解決:
「/home/cxgk/anaconda3/envs/sf/lib/python3.9/site-packages/pytorchvideo/ loss 」を開き、フォルダーの下に新しいsoft_target_cross_entropy.pyを作成し、それを開いて次のコードを追加します。
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
import torch
import torch.nn as nn
import torch.nn.functional as F
from pytorchvideo.layers.utils import set_attributes
from pytorchvideo.transforms.functional import convert_to_one_hot
class SoftTargetCrossEntropyLoss(nn.Module):
"""
Adapted from Classy Vision: ./classy_vision/losses/soft_target_cross_entropy_loss.py.
This allows the targets for the cross entropy loss to be multi-label.
"""
def __init__(
self,
ignore_index: int = -100,
reduction: str = "mean",
normalize_targets: bool = True,
) -> None:
"""
Args:
ignore_index (int): sample should be ignored for loss if the class is this value.
reduction (str): specifies reduction to apply to the output.
normalize_targets (bool): whether the targets should be normalized to a sum of 1
based on the total count of positive targets for a given sample.
"""
super().__init__()
set_attributes(self, locals())
assert isinstance(self.normalize_targets, bool)
if self.reduction not in ["mean", "none"]:
raise NotImplementedError(
'reduction type "{}" not implemented'.format(self.reduction)
)
self.eps = torch.finfo(torch.float32).eps
def forward(self, input: torch.Tensor, target: torch.Tensor) -> torch.Tensor:
"""
Args:
input (torch.Tensor): the shape of the tensor is N x C, where N is the number of
samples and C is the number of classes. The tensor is raw input without
softmax/sigmoid.
target (torch.Tensor): the shape of the tensor is N x C or N. If the shape is N, we
will convert the target to one hot vectors.
"""
# Check if targets are inputted as class integers
if target.ndim == 1:
assert (
input.shape[0] == target.shape[0]
), "SoftTargetCrossEntropyLoss requires input and target to have same batch size!"
target = convert_to_one_hot(target.view(-1, 1), input.shape[1])
assert input.shape == target.shape, (
"SoftTargetCrossEntropyLoss requires input and target to be same "
f"shape: {input.shape} != {target.shape}"
)
# Samples where the targets are ignore_index do not contribute to the loss
N, C = target.shape
valid_mask = torch.ones((N, 1), dtype=torch.float).to(input.device)
if 0 <= self.ignore_index <= C - 1:
drop_idx = target[:, self.ignore_idx] > 0
valid_mask[drop_idx] = 0
valid_targets = target.float() * valid_mask
if self.normalize_targets:
valid_targets /= self.eps + valid_targets.sum(dim=1, keepdim=True)
per_sample_per_target_loss = -valid_targets * F.log_softmax(input, -1)
per_sample_loss = torch.sum(per_sample_per_target_loss, -1)
# Perform reduction
if self.reduction == "mean":
# Normalize based on the number of samples with > 0 non-ignored targets
loss = per_sample_loss.sum() / torch.sum(
(torch.sum(valid_mask, -1) > 0)
).clamp(min=1)
elif self.reduction == "none":
loss = per_sample_loss
return エラー5
sklearn.metricsインポートから混乱_マトリックス
ModuleNotFoundError:「sklearn」という名前のモジュールがありません
解決:
pip インストールscikit-learn
エラー6
raise KeyError("存在しない構成キー: {}".format(full_key))
KeyError: '存在しない構成キー: TENSORBOARD.MODEL_VIS.TOPK'
解決:
次の 3 行をコメントアウトします。
テンソルボード
モデル_VIS
TOPK
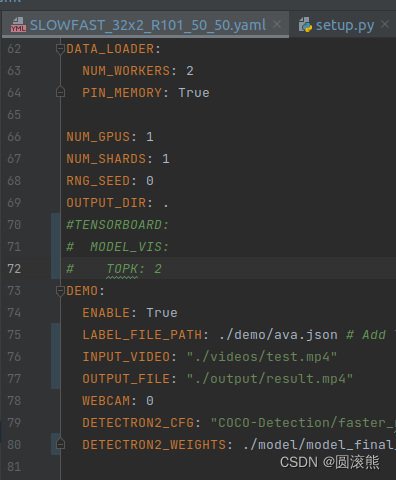
エラー7
RuntimeError: CUDA のメモリが不足しています。20.00 MiB を割り当てようとしました (GPU 0; 3.94 GiB の総容量; 2.83 GiB は既に割り当てられています; 25.44 MiB は空きです; PyTorch によって合計で 2.84 GiB が予約されています) メモリ管理と PYTORCH_CUDA_ALLOC_CONF のドキュメントを参照してください
解決:
yaml のフレーム数を減らします。
データ:
フレーム数: 16
参照:
https://github.com/facebookresearch/pytorchvideo/blob/main/pytorchvideo