論文リンク: https://ui.adsabs.harvard.edu/abs/2020arXiv200707296R/abstract
コードリンク: https://github.com/rand2ai/fedboosting
まとめ:
革新:
(1) プライバシー保護と勾配保護のために、フェデレーテッド ラーニング フレームワークを使用する
(2) 非独立で同一分布のデータの存在により、重み発散現象が発生し、FL 強調アルゴリズムが提案されます。
(3) 勾配リーク攻撃を防御するために、準同型暗号と差分プライバシーに基づく勾配共有セキュリティ プロトコルが提案されています。
1 はじめに
第一段落:
まず第一に、データプライバシーの問題の制限により、従来の機械学習は実現できず、分散トレーニングが必要であり、連合学習につながります
2 番目: 連合学習について簡単に説明し、それを説明する文献を引用します
最後に、文献を使用して、記事で解決する主な問題、つまり勾配問題を紹介し、引用文献を使用して説得力を高めます
個人データ保護とプライバシー保護の問題は、特に研究者の注目を集めています [1]、[2]、[3]、[4]、[5]、[6]、[7]。データ共有の制限により、一般的な機械学習方法では、モデル トレーニング用のデータを一元化する必要性を達成できない場合があります。したがって、分散型データトレーニング方法は、プライバシー保護とデータセキュリティ保護に関して期待される利点を提供するため、より魅力的です. フェデレーテッド ラーニング (FL) [8]、[9] は、個々のデータ プロバイダーがデータを一元的に集約することなく共有グローバル モデルを共同でトレーニングできるようにするという問題に対処するために提案されました。マクマハンら。[9] は、平均集約に基づくディープ ネットワークの分散型トレーニングの実用的な方法を提案しました。さまざまなデータセットとアーキテクチャで実験的研究が行われ、不均衡で独立した同一分布 (IID) データに対する FL の堅牢性が実証されています。更新方法を頻繁に行うと、一般に予測性能が向上しますが、特に大規模なデータセットの場合、通信コストが劇的に増加します [9]、[10]、[11]、[12]、[13]。Koneˇcn`y et al. [11] は効率問題の解決に焦点を当て、2 つの重み更新方法、フェデレーテッド アベレージング (FedAvg) ベースの構造化更新とスケッチ更新方法を提案して、ローカル マシンから中央サーバーに勾配を転送するアップリンク通信コストを削減します。
2 番目の段落:
フェデレーテッド ラーニングの 2 つの主要な課題を指摘する: 予測パフォーマンスとデータ プライバシー
一方では xx (予測パフォーマンスの議論): ドキュメントの導入は質問の出現につながり、次のドキュメントにつながります (次々とリンク)
あなたがしていることの必要性を説明するために中間に段落を追加してください
一方、xx(プライバシーについて議論):例
予測性能とデータ プライバシーは、FL 研究における 2 つの主要な課題です。 一方で、FL の精度は、独立していない非同一分散 (Non-IID) データでは大幅に低下します [14]。趙ら。[14] は、各ローカル マシン上のクラス分布とグローバル人口分布の間の地球移動距離 (EMD) を使用して、重みの違いを定量的に測定できることを示しました。したがって、彼らは非 IID データのモデルの一般化を改善するために、すべてのエッジ デバイス間でデータのごく一部を共有することを提案しています。ただし、この戦略は、データ共有に制限が設けられている場合には実行できず、プライバシーの侵害につながることがよくあります. 李ら。[15] は、FedAvg の収束特性を研究し、その通信効率と収束速度の間にはトレードオフがあると結論付けました。彼らは、モデルが異種のデータセットにゆっくりと収束すると主張しています。 このホワイト ペーパーの経験的研究に基づいて、特定の非 IID データセットでは、最適解に到達するためにトレーニングにさらに多くの反復が必要であり、多くの場合、収束に失敗することが確認されています。セットでのトレーニング時に多数のエポック後に集約されたグローバル モデルの数。 一方、モデル勾配は、一般に、モデル集約のために FL システム間で安全に共有できると考えられています。ただし、いくつかの研究では、モデルの勾配からトレーニング データ情報を復元できることが示されています。たとえば、フレデリクソンら。[16] とメリスら。[17] は、トレーニング バッチで特定の属性を持つサンプルを識別できる 2 つの方法を報告しました。シタジら。[18]は、他のクライアントのトレーニングデータを知らなくても、他のクライアントから出力されたデータの分布を推定するための敵対的クライアントとして生成的敵対的ネットワーク(GAN)モデルを提案しました。朱ら。[19] と Zhao ら。[20] は、ターゲット クライアントからの勾配が利用可能であると仮定して、データ回復を勾配回帰問題として定式化できることを示しました。これは、ほとんどの FL システムで基本的に有効な仮定です。さらに、Renらによって提案されたGenerative Recurrent Neural Network(GRNN)。[21] は、生成モデルの 2 つのブランチで構成されています。1 つは GAN に基づいて偽のトレーニング データを生成し、もう 1 つは完全に接続されたレイヤーに基づいて対応するラベルを生成します。トレーニング データは、偽のデータと関連するラベルから生成された真の勾配と偽の勾配を回帰することによって明らかになります。
第 3 段落:
このホワイト ペーパーでは、一般的な FL フレームワークでの重みの発散と勾配の漏れに対処する Federated Boosting (FedBoosting) メソッドを提案します。 グローバル モデルを集約する際に個々のローカル モデルを平等に扱うのではなく、収束ステータスと汎化能力の観点からローカル クライアントのデータの多様性を考慮します 。 共有勾配を介したデータ漏えいの潜在的なリスクに対処するために、準同型暗号化 (HE) [22] を使用して勾配を暗号化し、2 層の保護を提供する差分プライバシー (DP) ベースの線形集約方法が提案されています。提案された暗号化スキームは、計算コストのごくわずかな増加のみをもたらします。
第 4 段落:
提案された方法は、公開ベンチマークでのテキスト認識タスクと 2 つのデータセットでのバイナリ分類タスクを使用して評価され、収束速度、予測精度、およびセキュリティの点で優れていることが示されます。暗号化によるパフォーマンス低下も評価されます。私たちの貢献は 4 つあります。
• 重みの分散と勾配の漏れに対処するために、FL の FedBoosting という新しい集約戦略を提案します。 FedBoosting は、従来の方法と同じ通信コストで FedAvg よりも大幅に高速に収束することを経験的に示しています。特に、ローカル モデルが小さなバッチでトレーニングされ、グローバル モデルが多数のエポックの後に集計される場合、この方法では妥当な最適値に収束する可能性がありますが、この場合 FedAvg はしばしば失敗します。
• HE と DP を使用してサーバーとクライアントの間を流れる勾配を暗号化する 2 層保護スキームを導入し、勾配リーク攻撃からデータのプライバシーを保護します。
• 決定境界を視覚的に評価することにより、2 つのデータセットに対するこの方法の実現可能性を示します。さらに、集中型の方法や FedAvg と比較して、複数の大規模な非 IID データセットに対する視覚テキスト認識タスクで優れたパフォーマンスを発揮することも示しています。実験結果は、収束速度と予測精度の点で、私たちの方法が FedAvg よりも優れていることを確認しています。これは、FedBoosting 戦略がプライバシー保護シナリオで他の深層学習 (DL) モデルと統合できることを示しています。
• 提案された FedBoosting の実装は、再現性を確保するために公開されています。また、分散マルチ グラフィックス プロセッシング ユニット (GPU) セットアップで実行することもできます。
3. 方法
3.1. FedBoosting フレームワーク
FedAvg [9] は、ローカル クライアントからの勾配を平均化することによって新しいモデルを生成します。ただし、非 IID データでは、データ分布の不一致により、ローカル モデルの重みが異なる方向に収束する場合があります。したがって、単純な平均化スキームは、特に強い偏りや極端な外れ値がある場合にパフォーマンスが低下します [14]、[15]、[35]。したがって、ブースティング スキーム、つまり FedBoosting を使用して、さまざまなローカル検証データセットでの一般化パフォーマンスに従ってローカル モデルを適応的に組み込むことを提案します。同時に、データのプライバシーを保護するために、分散型クライアントとサーバー間の情報の交換は禁止されています。そのため、クライアント間でデータを交換する代わりに、暗号化されたローカル モデルが中央サーバーを介して交換され、各クライアントで個別に検証されます。図 1 に示すように。
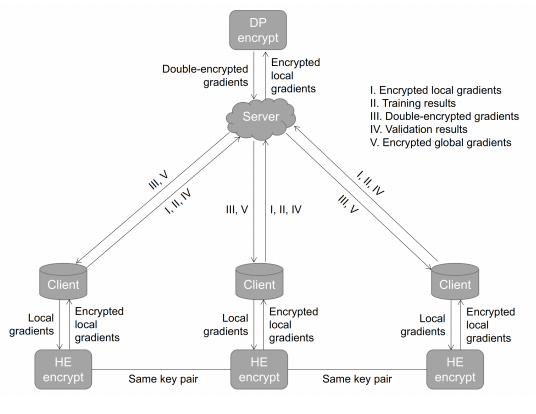
図 1: 提案された FedBoosting と暗号化プロトコルの概略図。デモ用に 2 つのクライアントがありますが、提案された方法は任意の数のローカル クライアントで使用できます。
提案された FedBoosting は、FedAvg と比較して、各クライアント モデルの適応性と一般化パフォーマンスを考慮し、すべてのクライアント モデルで異なる重みを持つグローバル モデルを適応的にマージします。
具体的な内容: (2022 年 8 月 9 日のブログ)
tip:发生了一件特别好玩的事,在网上搜这篇文章,想看下有没有大神针对这篇文章进行解读,发现了文章作者写过解读,特别惊喜,但点开阅读原文后,发现了404;但在页面的第一条文章也是这一篇,我点进去一看,这不是我写的吗(这时我还没反应过来怎么一回事,还心想,这链接不行呀,还跳转错误,把我昨天写的博客给跳出来了,但这日期也不对呀,怎么是22年8月份的呢)(之后才反应过来原来自己在22年的时候已经看过这篇文章了,还写了博客分析,自己给忘了。唉,太笨啦)
(之前心动过的东西,再看仍会心动)