CeresDB は、Rust で記述された高性能の分散型クラウドネイティブ時系列データベースです。同社の開発チームは最近、ほぼ 1 年間のオープン ソースの研究開発を経て、時系列データベース CeresDB 1.0 が正式にリリースされ、製品の可用性基準に達したことを発表しました。
CeresDB 1.0 公式中国語ドキュメント: https://docs.ceresdb.io/cn/
CeresDB 1.0 のコア機能の紹介
ストレージエンジン
-
コラム型ハイブリッド ストレージのサポート
-
効率的な XOR フィルター
クラウドネイティブ分散
-
コンピューティングとストレージの分離を実現 (データストレージとして OSS をサポート、WAL 実装は OBKV、Kafka をサポート)
-
ハッシュパーティションテーブルをサポート
展開とO&M
-
スタンドアロン展開をサポート
-
分散クラスター展開をサポート
-
Prometheus + Grafana をサポートしてセルフモニタリングを構築
読み書きプロトコル
-
SQLクエリと書き込みをサポート
-
CeresDB のビルトイン高性能読み取りおよび書き込みプロトコルを実装し、多言語 SDK を提供
-
Prometheus をサポートし、Prometheus のリモート ストレージとして使用できます。
多言語読み書き SDK
- Java、Python、Go、Rust の 4 つの言語でクライアント SDK を実装
CeresDB アーキテクチャの紹介
CeresDB は時系列データベースです. 従来の時系列データベースと比較して、CeresDB の目標は、時系列モードと分析モードの両方でデータを同時に処理し、効率的な読み取りと書き込みを提供できるようにすることです。
従来の時系列データベースでは、Tag列 (InfluxDB と呼ばれるTag、Prometheusと呼ばれるLabel) は通常、その逆索引を生成しますが、実際の使用では、Tag列のカーディナリティはさまざまなシナリオで異なります —— 一部のシナリオでは、Tagカーディナリティは非常に高く (このシナリオのデータは分析データと呼ばれます)、逆インデックスに基づく読み取りと書き込みは、これに対して高い代償を払います。一方、分析データベースで一般的に使用されているスキャン+プルーニング手法は、このような分析データをより効率的に処理できます。
したがって、CeresDB の基本的な設計コンセプトは、時系列データと分析データを同時に効率的に処理するために、ハイブリッド ストレージ形式と対応するクエリ メソッドを採用することです。
以下の図は、CeresDB のスタンドアロン バージョンのアーキテクチャを示しています。
┌──────────────────────────────────────────┐
│ RPC Layer (HTTP/gRPC/MySQL) │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ SQL Layer │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Parser │ │ Planner │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌───────────────────┐ ┌───────────────────┐
│ Interpreter │ │ Catalog │
└───────────────────┘ └───────────────────┘
┌──────────────────────────────────────────┐
│ Query Engine │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Optimizer │ │ Executor │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ Pluggable Table Engine │
│ ┌────────────────────────────────────┐ │
│ │ Analytic │ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Wal ││ Memtable ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Flush ││ Compaction ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Manifest ││ Object Store ││ │
│ │└────────────────┘└────────────────┘│ │
│ └────────────────────────────────────┘ │
│ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ Another Table Engine │ │
│ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
└──────────────────────────────────────────┘
パフォーマンスの最適化と実験結果
CeresDB は、カラムナ ハイブリッド ストレージ、データ パーティショニング、プルーニング、および効率的なスキャンを組み合わせて使用し、大規模なタイムライン (カーディナリティが高い) での書き込みクエリ パフォーマンスの低下の問題を解決します。
書き込みの最適化
CeresDB は LSM のような (ログ構造のマージ ツリー) 書き込みモデルを採用しており、書き込み時に複雑な転置インデックスを処理する必要がないため、書き込みパフォーマンスが向上します。
クエリの最適化
クエリのパフォーマンスを向上させるために、主に次の技術的手段が使用されます。
剪定:
-
最小/最大プルーニング: 建設コストは比較的低く、特定のシナリオではパフォーマンスが向上します
-
XOR フィルター: parquet ファイルの行グループのフィルター処理の精度を向上させます
効率的なスキャン:
-
複数の SST 間の同時実行: 複数の SST ファイルを同時にスキャン
-
単一の SST の内部同時実行: 複数の行グループを並行してプルする Parquet レイヤーをサポート
-
小さな IO のマージ: OSS 上のファイルの場合、小さな IO リクエストをマージしてプル効率を向上させます。
-
ローカル キャッシュ: OSS によってプルされたキャッシュ ファイル、メモリおよびディスク キャッシュのサポート
性能試験結果
パフォーマンス テストは TSBS を使用して実行されました。圧力測定パラメータは次のとおりです。
-
10 タグ
-
10分野
-
タイムライン(タグ組み合わせ数) 100wレベル
圧力試験機構成:24c90g
InfluxDB バージョン: 1.8.5
セレスDBのバージョン: 1.0.0
書き込み性能比較
InfluxDB の書き込みパフォーマンスは、時間の経過とともにさらに低下します。CeresDB の書き込みが安定した後は、書き込み速度が安定する傾向があり、全体的な書き込みパフォーマンスは InfluxDB の 1.5 倍以上です (一定期間後、ギャップは 2 倍以上になる可能性があります)。
下の図では、1 つの行に 10 個のフィールドが含まれています。
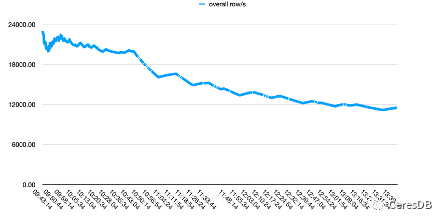
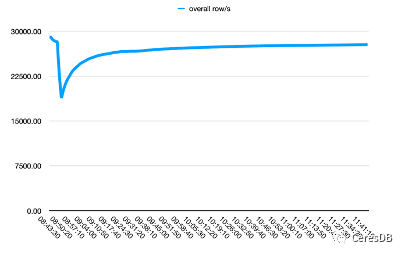
上がInfluxdb、下がCeresDB
クエリのパフォーマンス比較
低スクリーニング条件 (条件: os=Ubuntu15.10)、CeresDB は InfluxDB よりも 26 倍高速であり、具体的なデータは次のとおりです。
-
CeresDB クエリ時間: 15 秒
-
InfluxDB クエリ時間: 6 分 43 秒
高いスクリーニング条件 (データ ヒット数が少ない、条件: hostname=[8]、この時点では理論的には従来の逆インデックスの方が効果的です)、これは InfluxDB がより有利なシナリオであり、現時点では、ウォームアップが完了すると、CeresDB は InfluxDB よりも 5 倍遅くなります。
-
セレスDB:85ms
-
流入DB:15ms
2023 年のロードマップ
開発チームは、2023 年に CeresDB 1.0 がリリースされた後、彼らの作業のほとんどがパフォーマンス、配布、および周囲のエコロジーに集中すると述べました。特に、周囲のエコロジーのドッキング サポートにより、さまざまなユーザーが CeresDB をより簡単に使用できるようになることが期待されています。
周囲の生態
-
PromQL、InfluxdbQL、OpenTSDB などの一般的な時系列データベース プロトコルとの互換性を含む、生態学的な互換性
-
k8sサポート、CeresDB運用保守システム、セルフモニタリングなどの運用保守ツールのサポート
-
データのインポートとエクスポートなどを含む開発者ツール
パフォーマンス
-
新しいストレージ形式を探る
-
さまざまなタイプのインデックスを強化して、さまざまなワークロードでの CeresDB のパフォーマンスを向上させます
分散
-
自動負荷分散
-
可用性と信頼性の向上